


CoReaAgents: A Collaboration and Reasoning Framework Based on LLM-Powered Agents for Complex Reasoning Tasks

 ,
,
Abstract
1. Introduction
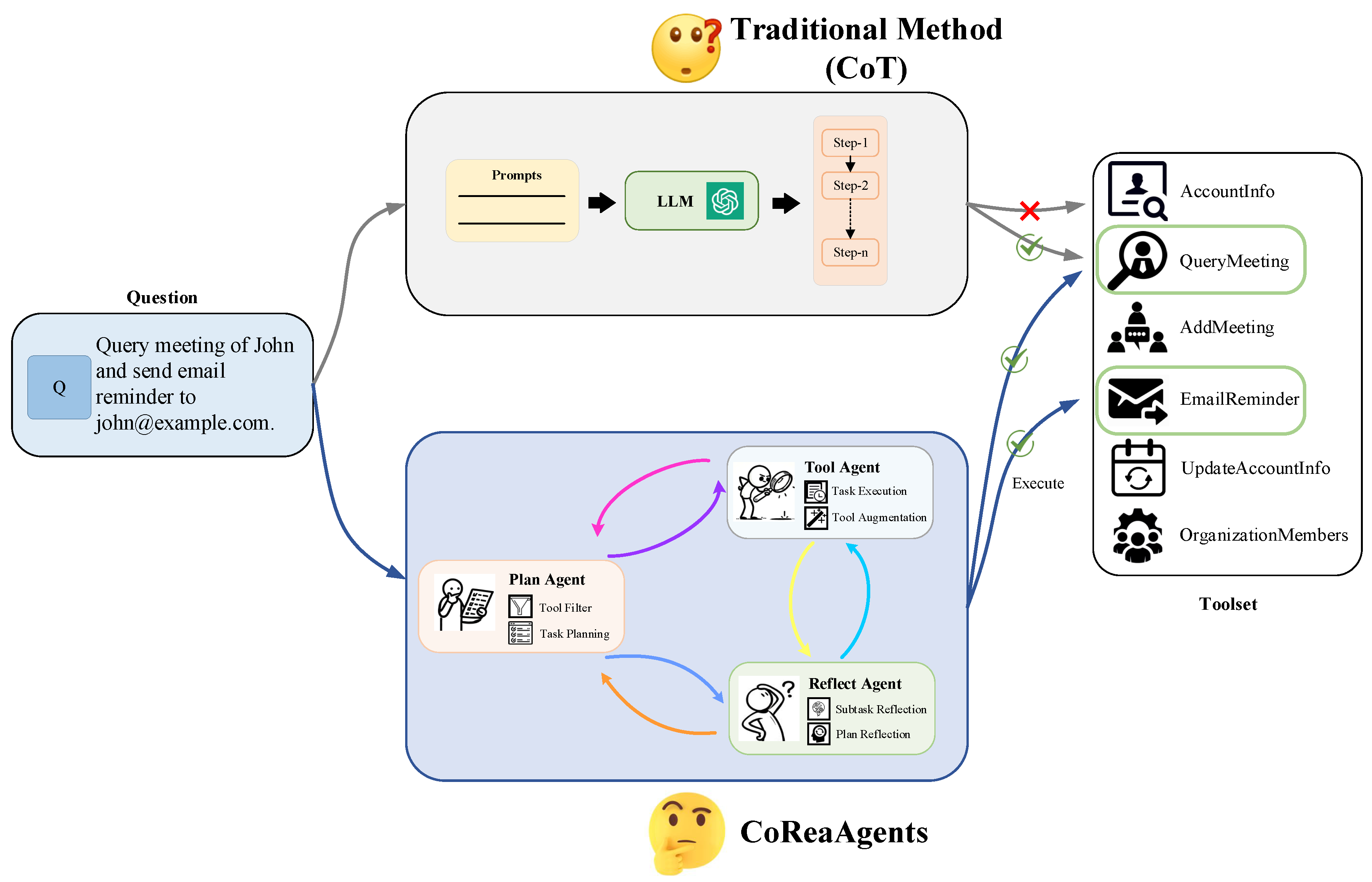
- We propose CoReaAgents, a collaboration and reasoning framework based on LLM-powered agents. This framework simulates social division and cooperation to enhance LLMs’ reasoning and complex task execution capabilities, with a meticulously assembled team of diverse agents.
- Our framework features multiple specialized agents, namely the Plan Agent, which functions as a precise task planner; the Tool Agent, which functions as a proficient tool user; and the Reflect Agent, which functions as an objective task evaluator, thereby effectively targeting complex reasoning tasks.
- Our framework includes multi-agent communication and negotiation mechanisms that facilitate effective exchange and feedback among different agents, addressing the limitations encountered in planning complex tasks that require iterative updates.
- Our approach is experimented with on five open-source and challenging datasets across three different complex reasoning tasks. The results show that the CoReaAgents framework outperforms various comparative methods in both quantity and quality.
2. Related Works
2.1. Complex Reasoning Tasks
2.2. LLM-Powered Agents
3. Method
3.1. Overview
3.2. The Framework of CoReaAgents
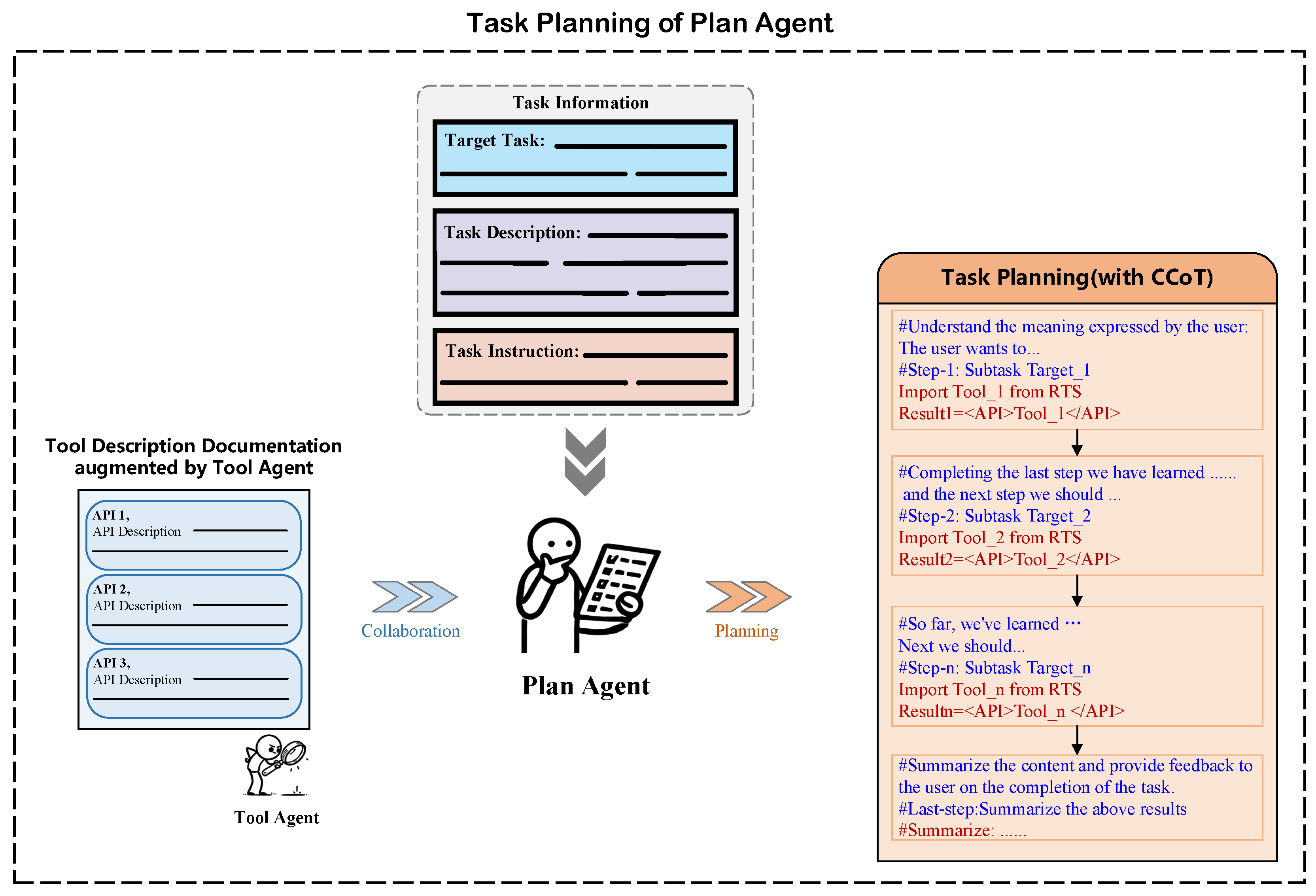
3.2.1. Plan Agent: A Precise Task Planner
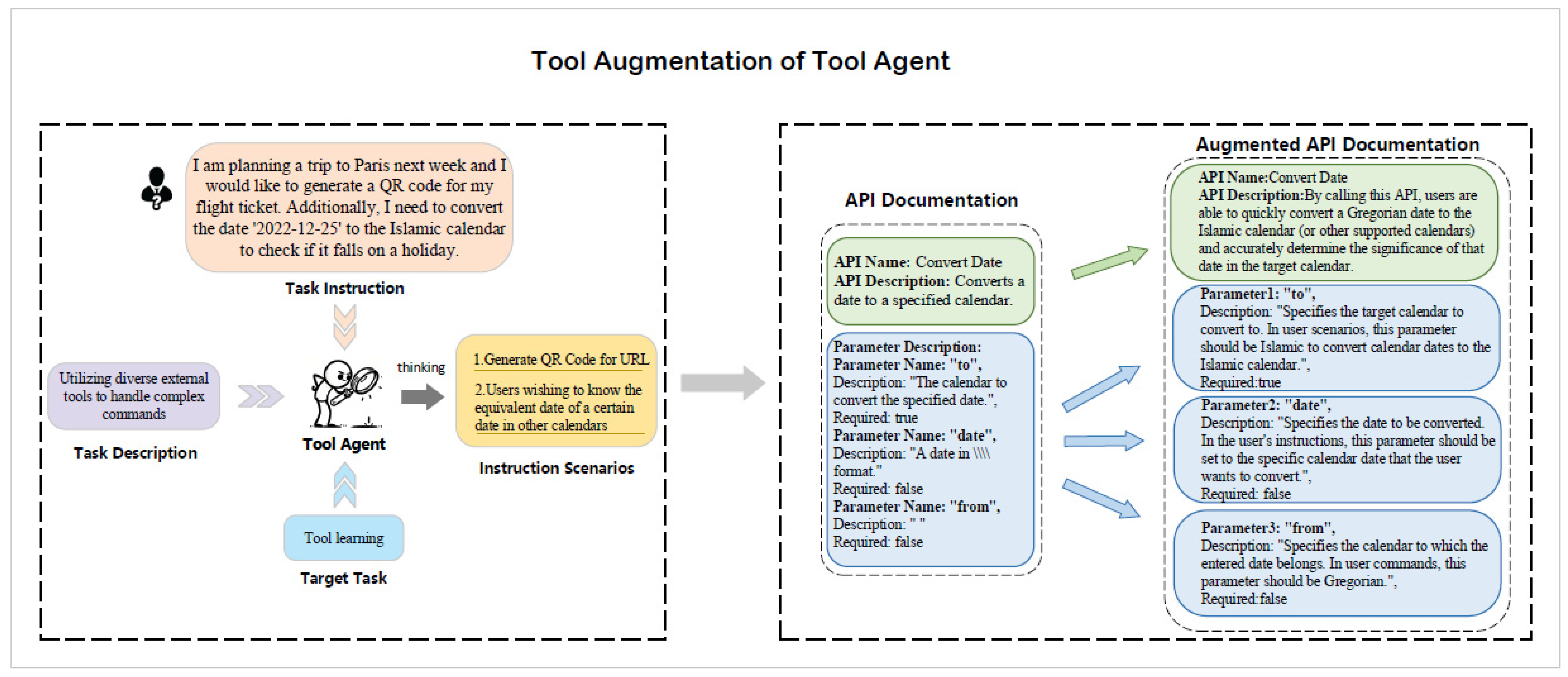
3.2.2. Tool Agent: A Proficient Tool User
3.2.3. Reflect Agent: An Objective Task Evaluator
3.3. The Multi-Agent Communication and Negotiation Mechanisms in the CoReaAgents Framework
3.3.1. Autonomous Tool Filter and Tool Augmentation Between the Plan Agent and the Tool Agent
3.3.2. From Task Planning by the Plan Agent to Task Execution by the Tool Agent
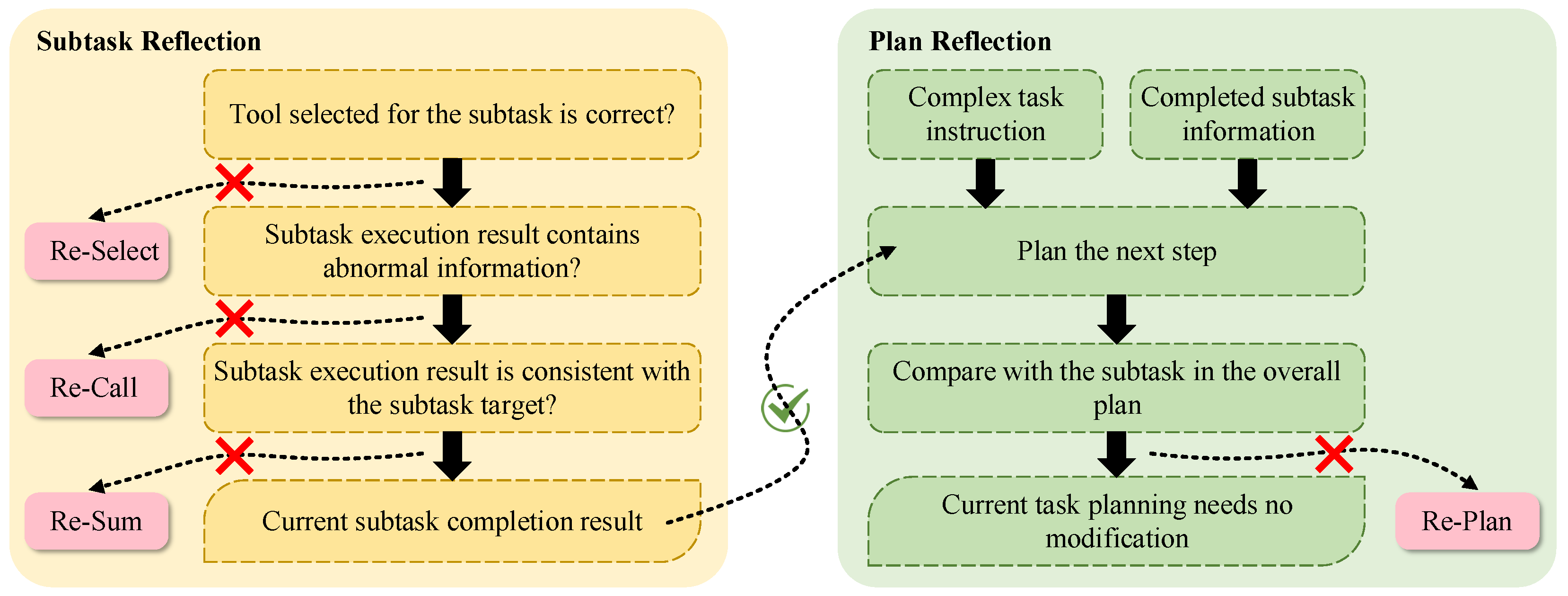
3.3.3. Static and Dynamic Task Planning Combination by the Reflect Agent
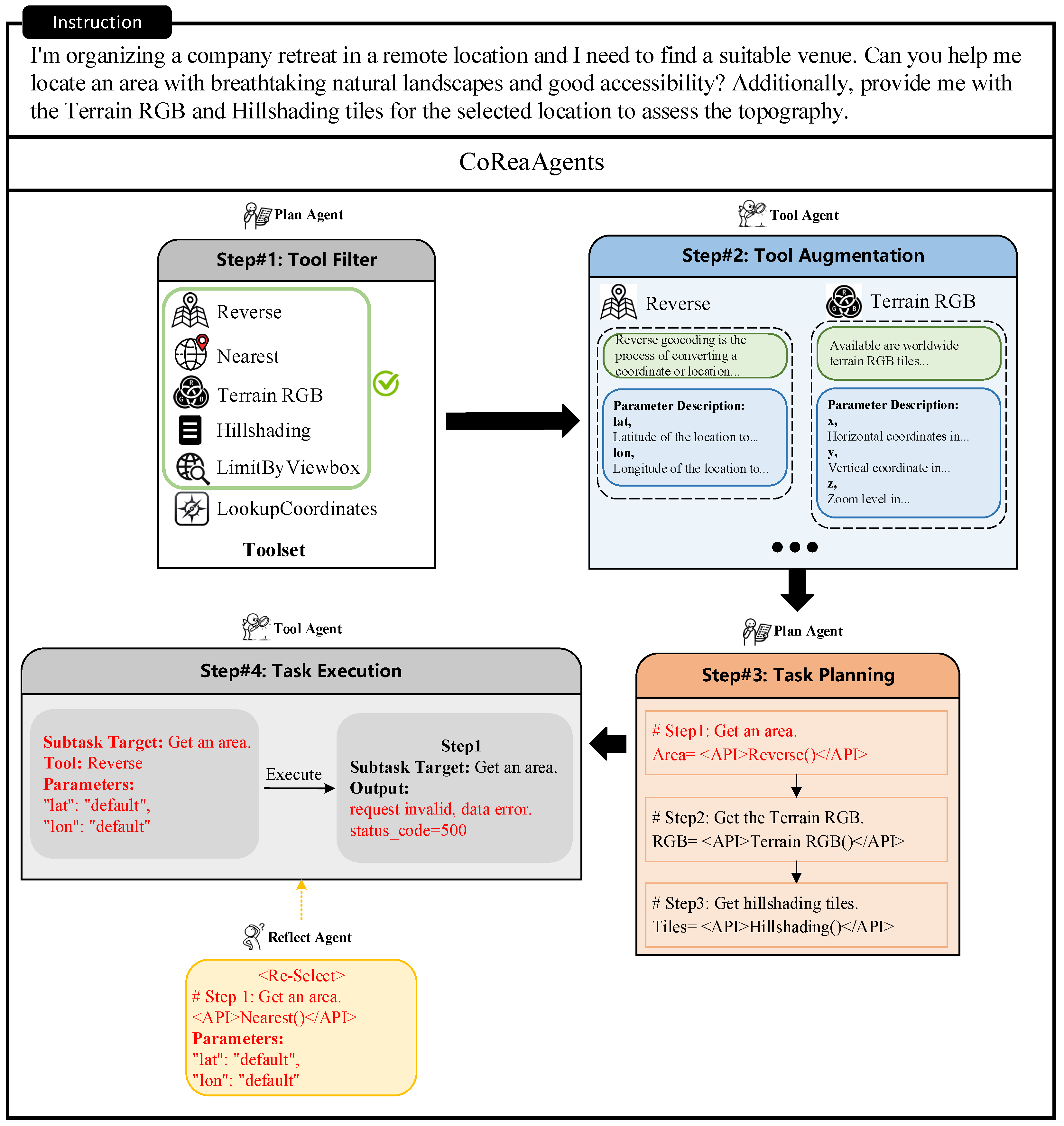
- <Re-Select> indicates that the tool invoked for this subtask needs to be reselected. The Tool Agent needs to reselect the tool and execute it based on the feedback.
- <Re-Call> indicates that the tool call failed and necessitates a reconsideration of the tool parameters. The Tool Agent needs to analyze the parameters of the call again.
- <Re-Sum> indicates that the Tool Agent needs to execute the subtask again and summarize it based on the feedback.
- The Reflect Agent combines information about completed subtasks to plan the next task , drawing inspiration from ReAct [15].
- is compared with the corresponding subtask in the overall plan.
- <Re-Plan> indicates that their task target or invoked tool is inconsistent. the Plan Agent should replan the subsequent tasks.
4. Experiments
4.1. Tool Learning
4.1.1. Settings for Tool Learning
- ToolBench [36] is a dataset with multiple types of data that covers multiple domain application scenarios and contains over 16,000 real-time APIs collected from the RapidAPI Hub (https://rapidapi.com/hub accessed on 30 January 2025) that cover 49 categories. We evaluate our approach using the most complex subset of ToolBench, including intra-category multi-tool instructions (I2) and intra-collection multi-tool instructions (I3). The final evaluation is divided into three subsets for testing, I2-Inst (200 test data), I2-Cat (200 test data) and I3-Inst (100 test data).
- API-Bank [34] is a multi-task benchmark consisting of various tools used to evaluate the performance of tool-augmented LLMs. API-Bank involves the offline usage of multiple API tools. We conduct an evaluation on the test data ranging from level-1 to level-2 of this dataset, which comprises a total of 534 test data.
- ReAct [15] guides LLMs to take appropriate actions at each step to solve a particular problem and carry out reasoning for the actions, iterating the process to finally solve the problem.
- Reflexion [17] enables the LLMs to learn from error information and retry when an error occurs, continuing until the task is successfully completed or the maximum number of reflection attempts is reached.
- DFSDT [36] simulates the Depth-First Search process by constructing a decision tree to explore different solution paths.
- EASYTOOL [42] distills the necessary information from tool documentation and converts it into concise tool descriptions, enhancing LLMs’ ability to select tools more accurately.
- ToolNet [28] organizes the tools into a directed graph, allowing the LLM to start from an initial tool node and iteratively select the next node in the graph until the task is resolved.
- Tool-Planner [66] performs dynamic solution tree planning based on toolkits, which group APIs with the same functionality into a single toolkit. When tool errors occur, LLMs can reselect tools based on toolkits.
4.1.2. Main Results from Tool Learning
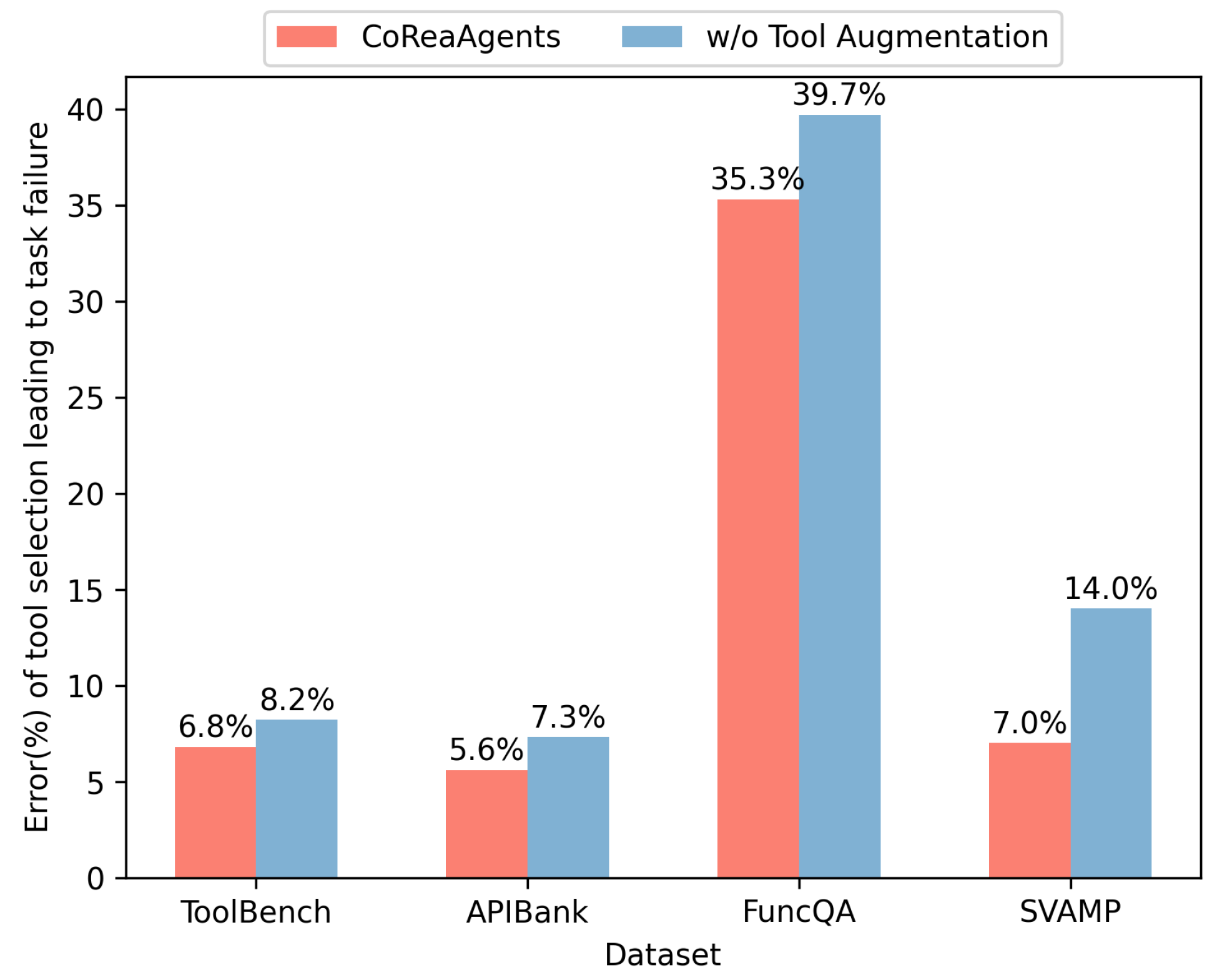
4.1.3. Ablation Study of Tool Learning
- The CoReaAgents framework + w/o TA: the Tool Agent is removed from the CoReaAgents framework, meaning that no tool augmentation and subtask execution are conducted when handling complex tasks.
- The CoReaAgents framework + w/o RA: similarly, the task division of the Reflect Agent, including subtask reflection and plan reflection, is removed from the process.
- The CoReaAgents framework + w/o TA&RA: the Reflect Agent and the Tool Agent are removed from the processing of complex tasks in the CoReaAgents framework, only utilizing the Plan Agent to complete tasks.
4.2. Math Reasoning
4.2.1. Settings for Math Reasoning
- FuncQA [67] involves 13 arithmetic operation tools (e.g., power, sqrt, lcm), which are used to test the reasoning ability of LLMs in complex mathematical problems. We evaluate our approach using multi-hop problems from this dataset. Multi-hop problems consist of 68 math problems that can be solved with multiple tools.
- SVAMP [37] is a dataset of mathematical application problems designed specifically to test the ability of natural language processing models to solve basic mathematical problems. The dataset contains four arithmetic operations: addition, subtraction, multiplication and division. Each problem contains up to two mathematical expressions and one unknown variable. The sample size of the test set for this dataset is 1000 test data.
- CoT [12] improves the performance of LLMs on complex inference tasks by generating intermediate inference steps.
- Self-Consistency [40] samples multiple inference paths and selects the output with the highest consistency as the final answer based on a voting strategy.
- Self-Contrast [41] improves the reflectivity and corrective accuracy of LLMs by creating a diversity of perspectives and comparing the differences in the different perspectives.
- ReAct, Reflexion, EASYTOOL are the same as the baselines in Section 4.1.1.
4.2.2. Main Results from Math Reasoning
4.2.3. Ablation Study of Math Reasoning
4.3. Multi-Hop QA
4.3.1. Settings for Multi-Hop QA
- HotpotQA [43] is a dataset of challenging multi-hop QA tasks. It extracts relevant facts and performs multi-hop reasoning based on article passages from Wikipedia. The answers to the questions in HotpotQA cover a wide range of domains, reflecting its diversity and complexity for QA tasks. We randomly selected 500 questions to construct the test set for evaluation.
- AMOR [48] decomposes the problem solving process into a series of modular steps, each corresponding to a state in a Finite State Machine.
- UALA [68] quantifies the degree of certainty of a language model in answering a question through various existing measures of uncertainty.
- Self-ask [69] allows the model to explicitly ask and answer a series of subquestions before answering the final question. In this way, the model is able to decompose complex questions more systematically and construct the final answer step by step.
- HGOT [49] leverages the planning capabilities of LLMs. It uses a divide strategy to decompose complex queries into subqueries and build dependency graphs at a deeper level.
- CoT, ReAct, Self-Consistency are the same as the baselines in Section 4.1.1 and Section 4.2.1.
4.3.2. Main Results from Multi-Hop QA
4.3.3. Ablation Study of Multi-Hop QA
4.4. Further Analysis
4.4.1. Specific Analysis of Ablation Study on ToolBench
4.4.2. Analysis of Tool Augmentation by the Tool Agent
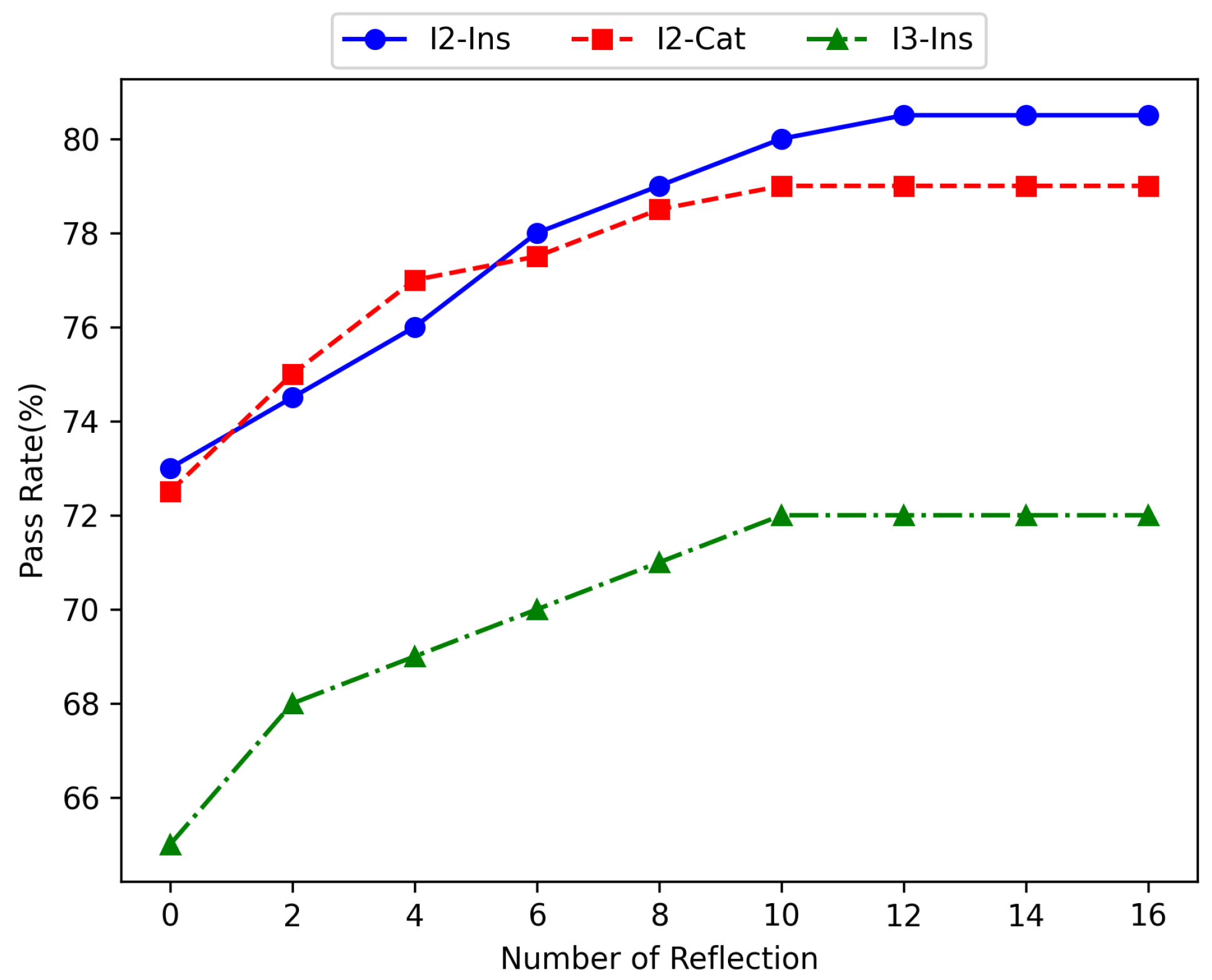
4.4.3. Reflection Frequency Statistics for the Reflect Agent
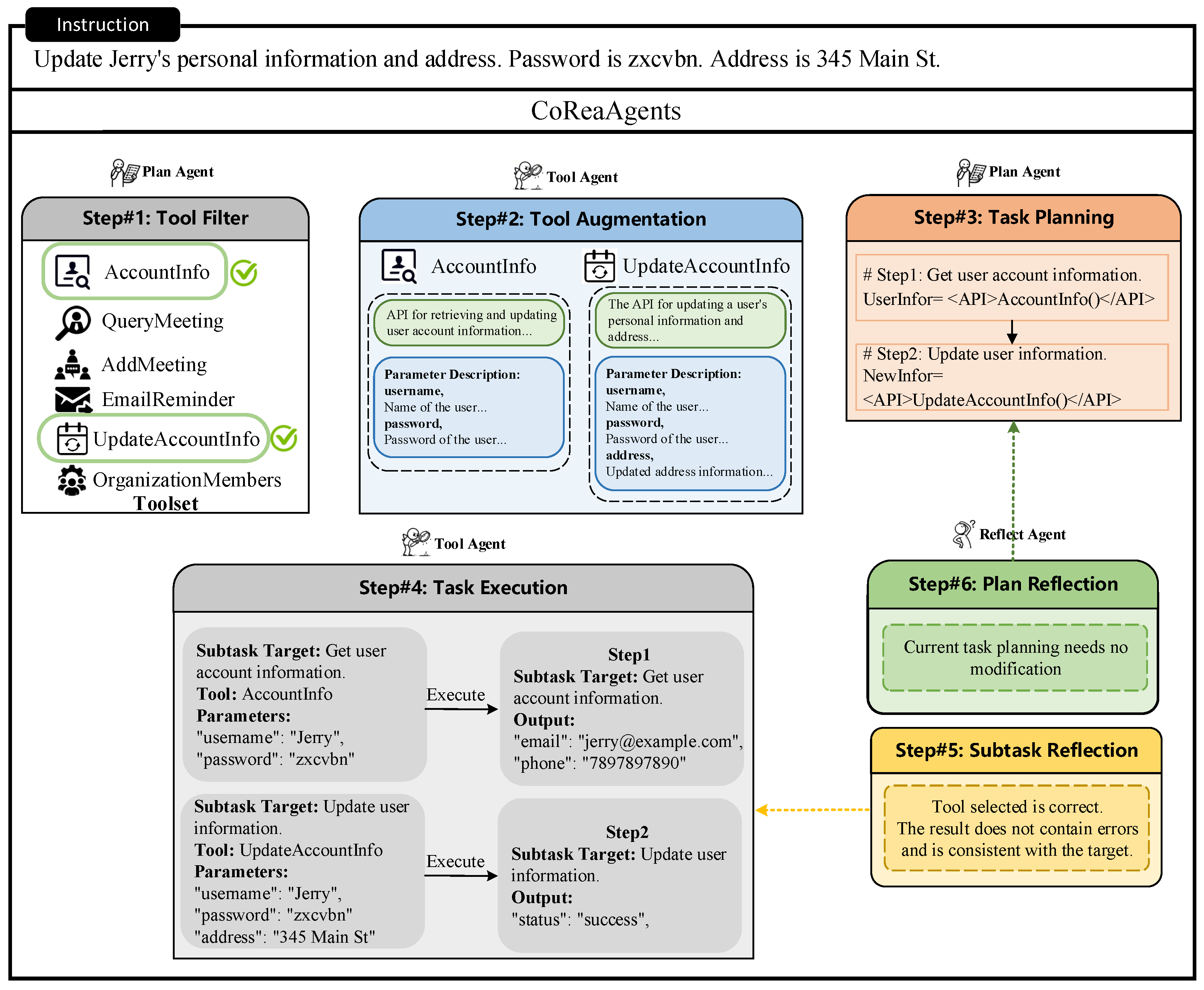
4.4.4. Case Study
4.4.5. Limitations
5. Conclusions
6. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mitchell, M. Debates on the Nature of Artificial General Intelligence. Science 2024, 383, eado7069. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-Level Control through Deep Reinforcement Learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Durante, Z.; Huang, Q.; Wake, N.; Gong, R.; Park, J.S.; Sarkar, B.; Taori, R.; Noda, Y.; Terzopoulos, D.; Choi, Y.; et al. Agent AI: Surveying the Horizons of Multimodal Interaction. arXiv 2024, arXiv:2401.03568. [Google Scholar]
- Heaven, W.D. Google DeepMind Wants to Define What Counts as Artificial General Intelligence. MIT Technology Review, 16 November 2023. Available online: https://www.technologyreview.com/2023/11/16/1083498 (accessed on 1 June 2024).
- Xu, J.; Fei, H.; Pan, L.; Liu, Q.; Lee, M.-L.; Hsu, W. Faithful Logical Reasoning via Symbolic Chain-of-Thought. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 11–16 August 2024; Association for Computational Linguistics: Kerrville, TX, USA, 2024; pp. 13326–13365. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Driessche, G.V.D.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Liu, R.; Yang, R.; Jia, C.; Zhang, G.; Zhou, D.; Dai, A.M.; Yang, D.; Vosoughi, S. Training Socially Aligned Language Models in Simulated Human Society. arXiv 2023, arXiv:2305.16960. [Google Scholar]
- Sumers, T.R.; Yao, S.; Narasimhan, K.; Griffiths, T.L. Cognitive Architectures for Language Agents. arXiv 2023, arXiv:2309.02427. [Google Scholar]
- Hong, S.; Zhuge, M.; Chen, J.; Zheng, X.; Cheng, Y.; Wang, J.; Zhang, C.; Wang, Z.; Yau, S.K.S.; Lin, Z.; et al. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Xie, J.; Chen, Z.; Zhang, R.; Wan, X.; Li, G. Large Multimodal Agents: A Survey. arXiv 2024, arXiv:2402.15116. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2022; Volume 35, pp. 24824–24837. [Google Scholar]
- Yao, S.; Yu, D.; Zhao, J.; Shafran, I.; Griffiths, T.; Cao, Y.; Narasimhan, K. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2023; Volume 36. [Google Scholar]
- Zhang, Y.; Sun, R.; Chen, Y.; Pfister, T.; Zhang, R.; Arik, S. Chain of Agents: Large Language Models Collaborating on Long-Context Tasks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2024; Volume 37, pp. 132208–132237. [Google Scholar]
- Yao, S.; Zhao, J.; Yu, D.; Du, N.; Shafran, I.; Narasimhan, K.; Cao, Y. ReAct: Synergizing Reasoning and Acting in Language Models. In Proceedings of the International Conference on Learning Representations (ICLR), Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Shen, W.; Li, C.; Chen, H.; Yan, M.; Quan, X.; Chen, H.; Zhang, J.; Huang, F. Small LLMs Are Weak Tool Learners: A Multi-LLM Agent. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024), Miami, FL, USA, 12–16 November 2024; Association for Computational Linguistics: Kerrville, TX, USA, 2024; pp. 16658–16680. [Google Scholar]
- Shinn, N.; Cassano, F.; Gopinath, A.; Narasimhan, K.; Yao, S. Reflexion: Language Agents with Verbal Reinforcement Learning. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2023; Volume 36. [Google Scholar]
- Wang, Z.; Mao, S.; Wu, W.; Ge, T.; Wei, F.; Ji, H. Unleashing the Emergent Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboration. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Mexico City, Mexico, 16–21 June 2024; pp. 257–279. [Google Scholar]
- Li, G.; Hammoud, H.; Itani, H.; Khizbullin, D.; Ghanem, B. Camel: Communicative Agents for “Mind” Exploration of Large Language Model Society. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2023; Volume 36, pp. 51991–52008. [Google Scholar]
- Qiao, S.; Zhang, N.; Fang, R.; Luo, Y.; Zhou, W.; Jiang, Y.E.; Lv, C.; Chen, H. AutoAct: Automatic Agent Learning from Scratch for QA via Self-Planning. In Proceedings of the ICLR 2024 Workshop on Large Language Model (LLM) Agents, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Bo, X.; Zhang, Z.; Dai, Q.; Feng, X.; Wang, L.; Li, R.; Chen, X.; Wen, J.-R. Reflective Multi-Agent Collaboration Based on Large Language Models. In Proceedings of the Thirty-Eighth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 9–15 December 2024. [Google Scholar]
- Yang, R.; Song, L.; Li, Y.; Zhao, S.; Ge, Y.; Li, X.; Shan, Y. Gpt4tools: Teaching Large Language Model to Use Tools via Self-Instruction. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2023; Volume 36. [Google Scholar]
- Patil, S.G.; Zhang, T.; Wang, X.; Gonzalez, J.E. Gorilla: Large Language Model Connected with Massive APIs. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2024; Volume 37, pp. 126544–126565. [Google Scholar]
- Gou, Z.; Shao, Z.; Gong, Y.; Shen, Y.; Yang, Y.; Huang, M.; Duan, N.; Chen, W. Tora: A Tool-Integrated Reasoning Agent for Mathematical Problem Solving. arXiv 2023, arXiv:2309.17452. [Google Scholar]
- Song, Y.; Xiong, W.; Zhu, D.; Wu, W.; Qian, H.; Song, M.; Huang, H.; Li, C.; Wang, K.; Yao, R.; et al. RestGPT: Connecting Large Language Models with Real-World RESTful APIs. arXiv 2023, arXiv:2306.06624. [Google Scholar]
- Schick, T.; Dwivedi-Yu, J.; Dessí, R.; Raileanu, R.; Lomeli, M.; Hambro, E.; Zettlemoyer, L.; Cancedda, N.; Scialom, T. Toolformer: Language Models Can Teach Themselves to Use Tools. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2023; Volume 36. [Google Scholar]
- Lu, P.; Peng, B.; Cheng, H.; Galley, M.; Chang, K.; Wu, Y.N.; Zhu, S.; Gao, J. Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2023; Volume 36. [Google Scholar]
- Liu, X.; Peng, Z.; Yi, X.; Xie, X.; Xiang, L.; Liu, Y.; Xu, D. ToolNet: Connecting Large Language Models with Massive Tools via Tool Graph. arXiv 2024, arXiv:2403.00839. [Google Scholar]
- Li, W.; Wu, W.-J.; Wang, H.-M.; Cheng, X.-Q.; Chen, H.-J.; Zhou, Z.-H.; Ding, R. Crowd Intelligence in AI 2.0 Era. Front. Inf. Technol. Electron. Eng. 2017, 18, 15–43. [Google Scholar] [CrossRef]
- Wang, S.; Liu, Z.; Zhong, W.; Zhou, M.; Wei, Z.; Chen, Z.; Duan, N. From LSAT: The Progress and Challenges of Complex Reasoning. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 2201–2216. [Google Scholar] [CrossRef]
- Liu, J.; Cui, L.; Liu, H.; Huang, D.; Wang, Y.; Zhang, Y. LogiQA: A Challenge Dataset for Machine Reading Comprehension with Logical Reasoning. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI-20), California, CA, USA, 7–15 January 2021; pp. 3622–3628. [Google Scholar]
- Talmor, A.; Herzig, J.; Lourie, N.; Berant, J. CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Kerrville, TX, USA, 2019; pp. 4149–4158. [Google Scholar]
- Ornes, S. The Unpredictable Abilities Emerging from Large AI Models. Quanta Magazine, 16 March 2023. [Google Scholar]
- Li, M.; Zhao, Y.; Yu, B.; Song, F.; Li, H.; Yu, H.; Li, Z.; Huang, F.; Li, Y. API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; Association for Computational Linguistics: Kerrville, TX, USA, 2023; pp. 3102–3116. [Google Scholar]
- Qu, C.; Dai, S.; Wei, X.; Cai, H.; Wang, S.; Yin, D.; Xu, J.; Wen, J.-R. Tool learning with large language models: A survey. Front. Comput. Sci. 2025, 19, 198343. [Google Scholar] [CrossRef]
- Qin, Y.; Liang, S.; Ye, Y.; Zhu, K.; Yan, L.; Lu, Y.; Lin, Y.; Cong, X.; Tang, X.; Qian, B.; et al. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. In Proceedings of the ICLR 2024, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Patel, A.; Bhattamishra, S.; Goyal, N. Are NLP Models Really Able to Solve Simple Math Word Problems? In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Mexico City, Mexico, 6–11 June 2021; pp. 2080–2094. [Google Scholar]
- Cobbe, K.; Kosaraju, V.; Bavarian, M.; Chen, M.; Jun, H.; Kaiser, L.; Plappert, M.; Tworek, J.; Hilton, J.; Nakano, R.; et al. Training Verifiers to Solve Math Word Problems. arXiv 2021, arXiv:2110.14168. [Google Scholar]
- Ling, W.; Yogatama, D.; Dyer, C.; Blunsom, P. Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Kerrville, TX, USA, 2017; pp. 158–167. [Google Scholar]
- Wang, X.; Wei, J.; Schuurmans, D.; Le, Q.; Chi, E.; Narang, S.; Chowdhery, A.; Zhou, D. Self-Consistency Improves Chain of Thought Reasoning in Language Models. arXiv 2022, arXiv:2203.11171. [Google Scholar]
- Zhang, W.; Shen, Y.; Wu, L.; Peng, Q.; Wang, J.; Zhuang, Y.; Lu, W. Self-Contrast: Better Reflection Through Inconsistent Solving Perspectives. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 11–16 August 2024; Association for Computational Linguistics: Kerrville, TX, USA, 2024; pp. 3602–3622. [Google Scholar]
- Yuan, S.; Song, K.; Chen, J.; Tan, X.; Shen, Y.; Ren, K.; Li, D.; Yang, D. EASYTOOL: Enhancing LLM-based Agents with Concise Tool Instruction. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Albuquerque, NM, USA, 29 April–4 May 2025; Association for Computational Linguistics: Kerrville, TX, USA, 2025; pp. 951–972. [Google Scholar]
- Yang, Z.; Qi, P.; Zhang, S.; Bengio, Y.; Cohen, W.; Salakhutdinov, R.; Manning, C.D. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2369–2380. [Google Scholar]
- Peng, C.; Xia, F.; Naseriparsa, M.; Osborne, F. Knowledge Graphs: Opportunities and Challenges. Artif. Intell. Rev. 2023, 56, 13071–13102. [Google Scholar] [CrossRef]
- Ding, M.; Zhou, C.; Chen, Q.; Yang, H.; Tang, J. Cognitive Graph for Multi-Hop Reading Comprehension at Scale. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Kerrville, TX, USA, 2019; pp. 2694–2703. [Google Scholar]
- Saxena, A.; Tripathi, A.; Talukdar, P. Improving Multi-Hop Question Answering over Knowledge Graphs Using Knowledge Base Embeddings. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4498–4507. [Google Scholar]
- Wu, S.; Yacub, Z.; Shasha, D. DietNerd: A Nutrition Question-Answering System That Summarizes and Evaluates Peer-Reviewed Scientific Articles. Appl. Sci. 2024, 14, 9021. [Google Scholar] [CrossRef]
- Guan, J.; Wu, W.; Wen, Z.; Xu, P.; Wang, H.; Huang, M. AMOR: A Recipe for Building Adaptable Modular Knowledge Agents Through Process Feedback. arXiv 2024, arXiv:2402.01469. [Google Scholar]
- Fang, Y.; Thomas, S.; Zhu, X. HGOT: Hierarchical Graph of Thoughts for Retrieval-Augmented In-Context Learning in Factuality Evaluation. In Proceedings of the 4th Workshop on Trustworthy Natural Language Processing (TrustNLP 2024), Mexico City, Mexico, 21–22 June 2024; Association for Computational Linguistics: Kerrville, TX, USA, 2024; pp. 118–144. [Google Scholar]
- Chen, R.; Jiang, W.; Qin, C.; Rawal, I.S.; Tan, C.; Choi, D.; Xiong, B.; Ai, B. LLM-Based Multi-Hop Question Answering with Knowledge Graph Integration in Evolving Environments. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024), Miami, FL, USA, 12–16 November 2024; Association for Computational Linguistics: Kerrville, TX, USA, 2024; pp. 14438–14451. [Google Scholar]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A Survey of Large Language Models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Wei, J.; Tay, Y.; Bommasani, R.; Raffel, C.; Zoph, B.; Borgeaud, S.; Yogatama, D.; Bosma, M.; Zhou, D.; Metzler, D.; et al. Emergent Abilities of Large Language Models. arXiv 2022, arXiv:2206.07682. [Google Scholar]
- Park, J.S.; O’Brien, J.; Cai, C.J.; Morris, M.R.; Liang, P.; Bernstein, M.S. Generative Agents: Interactive Simulacra of Human Behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, San Francisco, CA, USA, 29 October–1 November 2023; pp. 1–22. [Google Scholar]
- Besta, M.; Blach, N.; Kubicek, A.; Gerstenberger, R.; Podstawski, M.; Gianinazzi, L.; Gajda, J.; Lehmann, T.; Niewiadomski, H.; Nyczyk, P.; et al. Graph of Thoughts: Solving Elaborate Problems with Large Language Models. Proc. AAAI Conf. Artif. Intell. 2024, 38, 17682–17690. [Google Scholar] [CrossRef]
- Ling, C.; Zhao, X.; Lu, J.; Deng, C.; Zheng, C.; Wang, J.; Chowdhury, T.; Li, Y.; Cui, H.; Zhang, X.; et al. Domain Specialization as the Key to Make Large Language Models Disruptive: A Comprehensive Survey. arXiv 2023, arXiv:2305.18703. [Google Scholar]
- Tang, Q.; Deng, Z.; Lin, H.; Han, X.; Liang, Q.; Cao, B.; Sun, L. ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases. arXiv 2023, arXiv:2306.05301. [Google Scholar]
- Talebirad, Y.; Nadiri, A. Multi-Agent Collaboration: Harnessing the Power of Intelligent LLM Agents. arXiv 2023, arXiv:2306.03314. [Google Scholar]
- Fu, Y.; Peng, H.; Khot, T.; Lapata, M. Improving Language Model Negotiation with Self-Play and In-Context Learning from AI Feedback. In Proceedings of the CoRR 2023, Atlanta, GA, USA, 6–9 November 2023. [Google Scholar]
- Qin, Y.; Zhou, E.; Liu, Q.; Yin, Z.; Sheng, L.; Zhang, R.; Qiao, Y.; Shao, J. MP5: A Multi-Modal Open-Ended Embodied System in Minecraft via Active Perception. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 16307–16316. [Google Scholar]
- Xu, Y.; Wang, S.; Li, P.; Luo, F.; Wang, X.; Liu, W.; Liu, Y. Exploring Large Language Models for Communication Games: An Empirical Study on Werewolf. arXiv 2023, arXiv:2309.04658. [Google Scholar]
- Chan, C.-M.; Chen, W.; Su, Y.; Yu, J.; Xue, W.; Zhang, S.; Fu, J.; Liu, Z. ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Li, H.; Mahjoub, H.N.; Chalaki, B.; Tadiparthi, V.; Lee, K.; Moradi-Pari, E.; Lewis, M.; Sycara, K. Language Grounded Multi-agent Reinforcement Learning with Human-interpretable Communication. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2024; Volume 37, pp. 87908–87933. [Google Scholar]
- Wang, Z.; Wang, Y.; Liu, X.; Ding, L.; Zhang, M.; Liu, J.; Zhang, M. AgentDropout: Dynamic Agent Elimination for Token-Efficient and High-Performance LLM-Based Multi-Agent Collaboration. arXiv 2025, arXiv:2503.18891. [Google Scholar]
- Sainz, O.; García-Ferrero, I.; Agerri, R.; de Lacalle, O.L.; Rigau, G.; Agirre, E. GoLLIE: Annotation Guidelines improve Zero-Shot Information-Extraction. In Proceedings of the Twelfth International Conference on Learning Representations (ICLR 2024), Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training Language Models to Follow Instructions with Human Feedback. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2022; Volume 35, pp. 27730–27744. [Google Scholar]
- Liu, Y.; Peng, X.; Zhang, Y.; Cao, J.; Zhang, X.; Cheng, S.; Wang, X.; Yin, J.; Du, T. Tool-Planner: Dynamic Solution Tree Planning for Large Language Model with Tool Clustering. arXiv 2024, arXiv:2406.03807. [Google Scholar]
- Hao, S.; Liu, T.; Wang, Z.; Hu, Z. ToolKengpt: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2023; Volume 36. [Google Scholar]
- Han, J.; Buntine, W.; Shareghi, E. Towards Uncertainty-Aware Language Agent. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024, Bangkok, Thailand, 11–16 August 2024; Association for Computational Linguistics: Kerrville, TX, USA, 2024; pp. 6662–6685. [Google Scholar]
- Press, O.; Zhang, M.; Min, S.; Schmidt, L.; Smith, N.; Lewis, M. Measuring and Narrowing the Compositionality Gap in Language Models. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; Association for Computational Linguistics: Kerrville, TX, USA, 2023; pp. 5687–5711. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Basic Attribute | Notation | Attribute Description |
|---|---|---|
| Current subtask | Logical position in the collection of subtasks | |
| Subtask target | Subtask target expressed through comments | |
| Tool requirement | Tool to be invoked expressed through code | |
| Parameter configuration | Parameters required to invoke the tool | |
| Subtask result | Result of this subtask |
| ToolBench (Pass Rate) | API-Bank (EM) | |||||
|---|---|---|---|---|---|---|
| Methods | I2-Ins | I2-Cat | I3-Ins | Average | Lv1 + Lv2 | Tokens |
| ReAct | 42.5 | 46.5 | 22.0 | 37.0 | 70.0 5100 | |
| Reflexion | 58.0 | 66.0 | 55.0 | 59.7 | 77.0 | 8750 |
| DFSDT | 75.0 | 71.5 | 62.0 | 69.5 | 72.0 | 25,000 |
| DFSDT-EASYTOOL | 77.5 | 74.5 | 65.0 | 72.3 | 76.4 | - |
| ToolNet | - | - | - | - | 75.0 | 4112 |
| ToolNet + Reflexion | - | - | - | - | 83.0 | 7950 |
| Tool-Planner | 75.5 | 78.0 | 66.0 | 73.2 | - | - |
| CoReaAgents | 80.5 | 79.0 | 72.0 | 77.2 | 84.0 | 15,000 |
| w/o TA | 75.0 | 74.0 | 68.0 | 72.3 | 79.8 | |
| w/o RA | 73.0 | 72.5 | 65.0 | 70.2 | 79.5 | |
| w/o TA&RA | 70.5 | 70.0 | 61.0 | 67.2 | 74.5 | |
| Accuracy | |||
|---|---|---|---|
| Methods | FuncQA (Multi-Hop) | SVAMP | Tokens |
| CoT | 17.64 | 79.8 | 433 |
| ReAct | 41.17 | 80.3 | 2260 |
| Reflexion | 42.65 | 80.5 | 2312 |
| Self-Consistency | 45.59 | 84.6 | 5750 |
| EASYTOOL | 48.53 | 84.9 | 1411 |
| Self-Contrast | - | 89.0 | - |
| CoReaAgents | 57.35 | 90.3 | 3900 |
| w/o TA | 50.00 | 87.1 | |
| w/o RA | 47.05 | 85.5 | |
| w/o TA&RA | 44.12 | 82.4 | |
| HotpotQA | ||
|---|---|---|
| Methods | EM | F1 |
| CoT | 34.80 | 42.32 |
| ReAct | 35.47 | 42.18 |
| Self-Consistency | 39.40 | - |
| AMOR | 39.60 | 49.30 |
| UALA | 41.30 | - |
| Self-ask | 43.98 | 54.67 |
| HGOT | 47.37 | 59.48 |
| CoReaAgents | 48.83 | 61.77 |
| w/o TA | 46.64 | 58.28 |
| w/o RA | 44.87 | 56.34 |
| w/o TA&RA | 41.93 | 54.83 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, Z.; Wang, J.; Yan, X.; Jiang, Z.; Zhang, Y.; Liu, S.; Gong, Q.; Song, C. CoReaAgents: A Collaboration and Reasoning Framework Based on LLM-Powered Agents for Complex Reasoning Tasks. Appl. Sci. 2025, 15, 5663. https://doi.org/10.3390/app15105663
Han Z, Wang J, Yan X, Jiang Z, Zhang Y, Liu S, Gong Q, Song C. CoReaAgents: A Collaboration and Reasoning Framework Based on LLM-Powered Agents for Complex Reasoning Tasks. Applied Sciences. 2025; 15(10):5663. https://doi.org/10.3390/app15105663
Chicago/Turabian StyleHan, Zhonghe, Jiaxin Wang, Xiaolu Yan, Zhiying Jiang, Yuanben Zhang, Siye Liu, Qihang Gong, and Chenwei Song. 2025. "CoReaAgents: A Collaboration and Reasoning Framework Based on LLM-Powered Agents for Complex Reasoning Tasks" Applied Sciences 15, no. 10: 5663. https://doi.org/10.3390/app15105663
APA StyleHan, Z., Wang, J., Yan, X., Jiang, Z., Zhang, Y., Liu, S., Gong, Q., & Song, C. (2025). CoReaAgents: A Collaboration and Reasoning Framework Based on LLM-Powered Agents for Complex Reasoning Tasks. Applied Sciences, 15(10), 5663. https://doi.org/10.3390/app15105663