

Multi-Scale Feature Fusion and Global Context Modeling for Fine-Grained Remote Sensing Image Segmentation


Abstract
1. Introduction
- 1.
- Heterogeneous Multi-Branch Local Feature Extraction: The proposed model establishes a multi-scale local feature extraction network through three parallel convolutional branches. Specifically, the feature extractors perform diverse processing operations within different architectures to better capture comprehensive representations such as high-frequency textures, mesoscale structures, and detail representations for the remote sensing images. By doing this, the aligned and concatenated composite features preserve both sub-pixel edge responses and regional semantic correlations, effectively addressing the feature representation limitations of single convolutional kernels.
- 2.
- Hierarchical Window Attention with Pyramid Pooling: To mitigate the transformer’s local detail loss, we propose an enhanced customized architecture, termed the pyramid self-learning fusion module, by constructing four-level feature pyramids via patch merging. The dynamic shifted window mechanism enables cross-scale context modeling. Innovatively, dual pyramid pooling modules perform multi-granular spatial pooling on local and global features. After bilinear upsampling and convolution-based channel control, this strategy significantly improves vegetation classification by fusing local details with global semantics.
- 3.
- Spatial Graph Convolution-Guided Feature Propagation: The proposed graph fusion module maps local, global, and fused features into high-dimensional graph nodes, constructing spatial topology using four-neighbor adjacency matrices. Three GCN pathways facilitate feature propagation, with learnable weights dynamically aggregating improved node features. This design goes beyond traditional grid limitations, establishing long-range dependencies in the reconstruction space to address semantic discontinuities caused by high-rise occlusions.
2. Related Works
2.1. CNN-Based Remote Sensing Image Segmentation
2.2. Transformer-Based Remote Sensing Semantic Segmentation
2.3. GCN-Based and Other Related Deep Learning Methods
3. Methodology
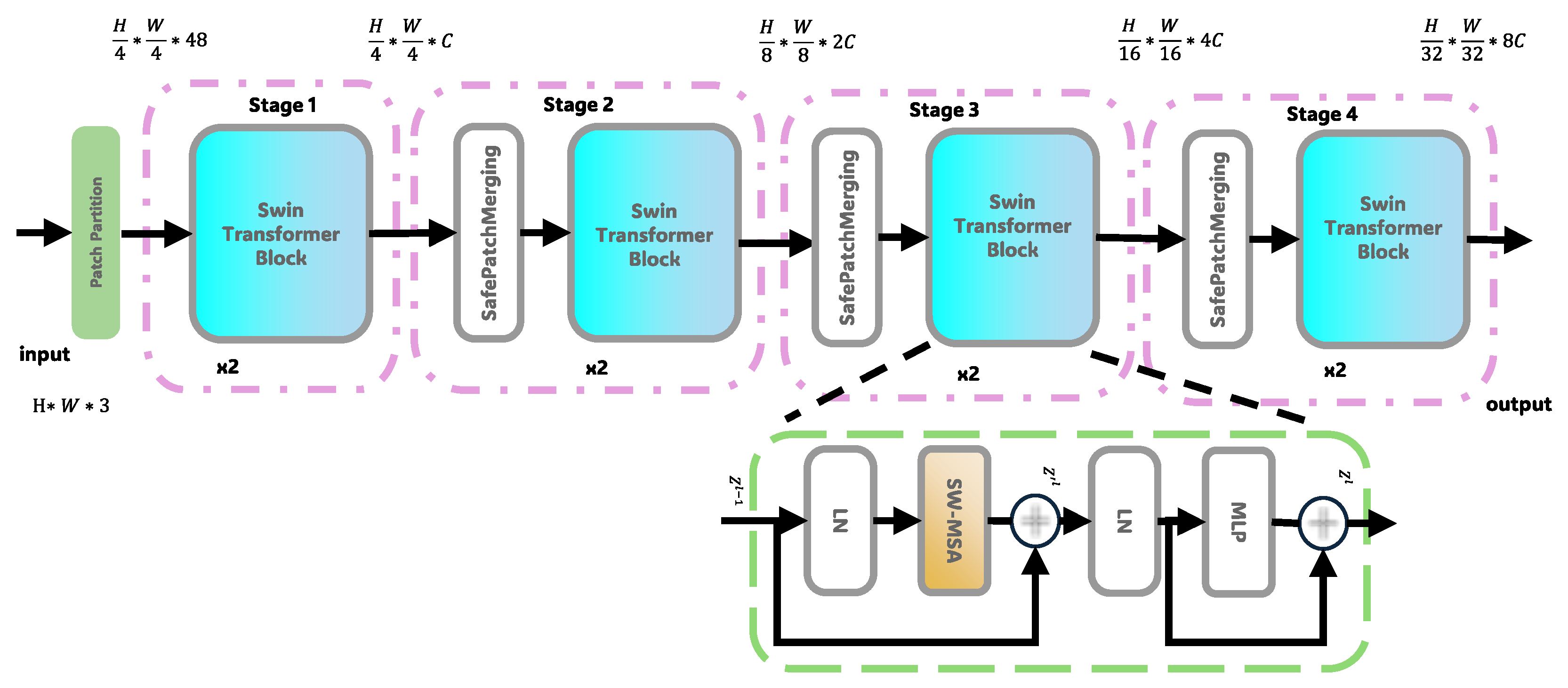
3.1. Overall Architecture
3.2. Parallel Encoding Architecture
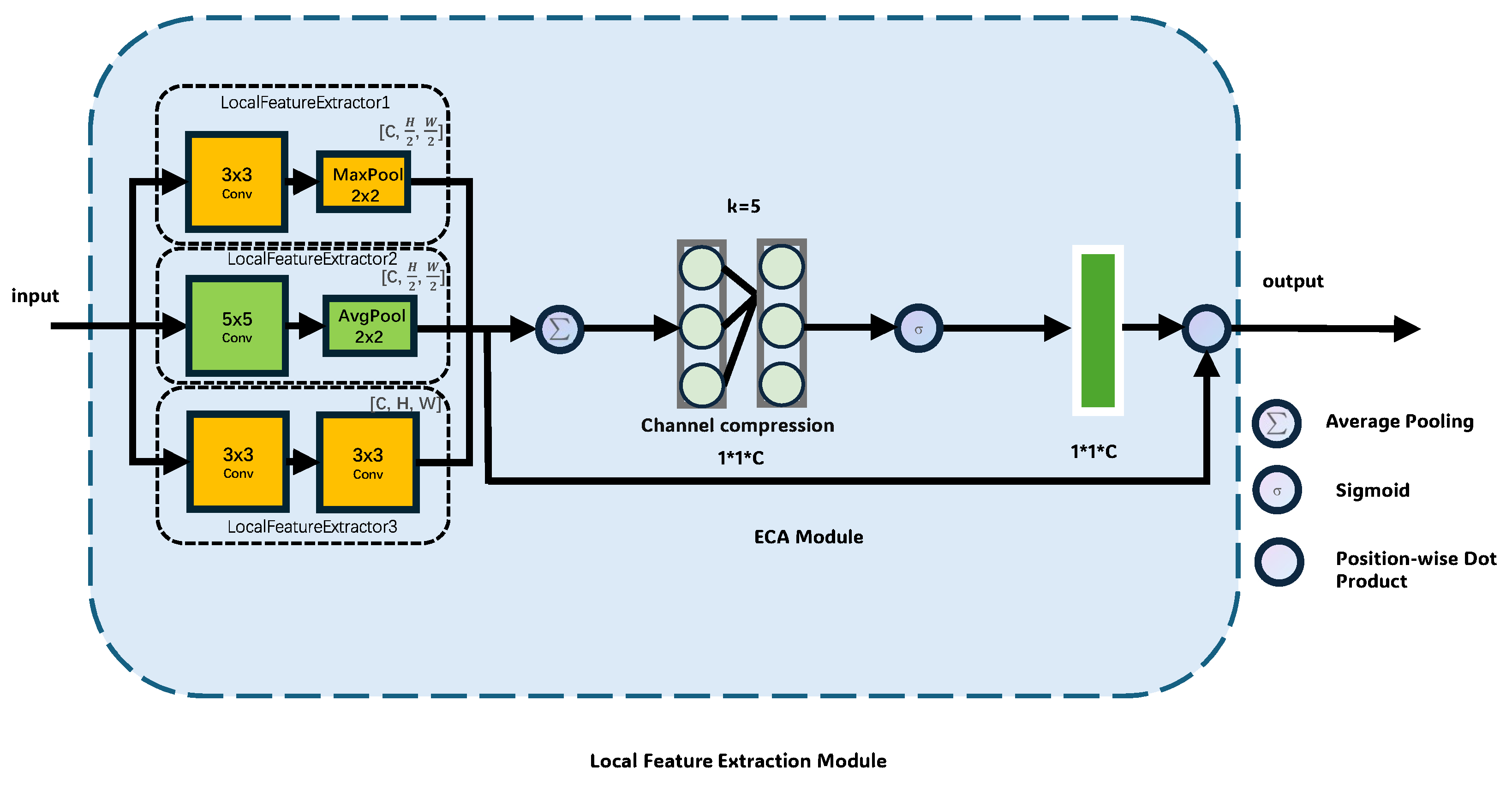
3.3. Pyramid Self-Learning Fusion Module

3.4. Graph Fusion Module

3.5. Loss Function
4. Experiments and Discussion
4.1. Dataset Descriptions
- Vaihingen Dataset: The Vaihingen dataset consists of 16 high-resolution orthophotos, each measuring pixels. Each image includes three spectral channels: near-infrared (NIR), red (R), and green (G), along with a DSM at 9 cm ground sampling distance (GSD). The dataset includes five foreground classes (buildings, trees, low vegetation, cars, and impervious surfaces) and one background class (clutter). In our experiments, 12 images were used for training and 4 for testing, following a commonly used protocol. Additionally, 20% of the training samples were randomly selected as a validation set. All images were divided into non-overlapping patches for training and evaluation.
- Potsdam Dataset: The Potsdam dataset contains 24 orthophotos with a resolution of pixels, and four spectral channels: red (R), green (G), blue (B), and infrared (IR), at 5 cm GSD. It shares the same class definitions as the Vaihingen dataset. We adopted the same patch generation and training/validation strategy as used in Vaihingen, with an 80/20% split for training and testing, and 20% of training samples used for validation.
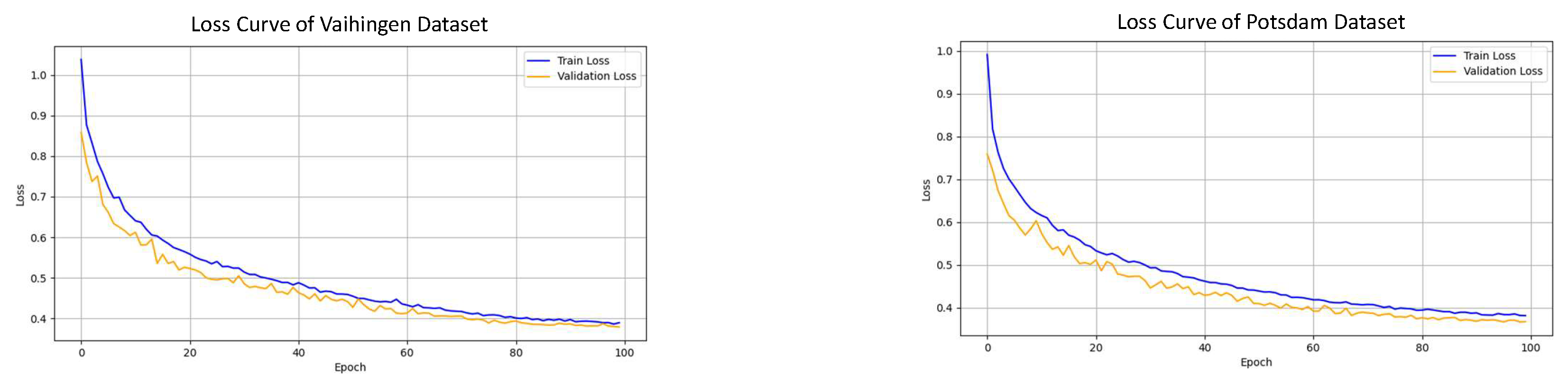
4.2. Experimental Setup
4.3. Evaluation Metrics
- IoU (Intersection over Union): IoU is a standard metric for evaluating image segmentation model performance, calculated as the intersection area of the predicted and ground truth regions divided by their union area. A higher IoU indicates better segmentation accuracy. In the experiments, we computed the IoU for each class and averaged them to obtain the overall IoU. A high IoU value indicates that the model performs well in handling complex boundaries and small objects.
- F1 Score: F1 score is the harmonic mean of precision and recall and is typically used to evaluate models with class imbalance. In remote sensing image segmentation tasks, some classes may have significantly fewer samples than others. The F1 score provides a more comprehensive evaluation of the model’s performance across different object types. A higher F1 score indicates better balance between precision and recall.
4.4. Comparative Experiments
4.5. Ablation Experiments
4.5.1. Performance Analysis from Different Modules
4.5.2. Performance Variations on Diverse Losses
4.5.3. Parameter Sensitivity Study on Compound Loss
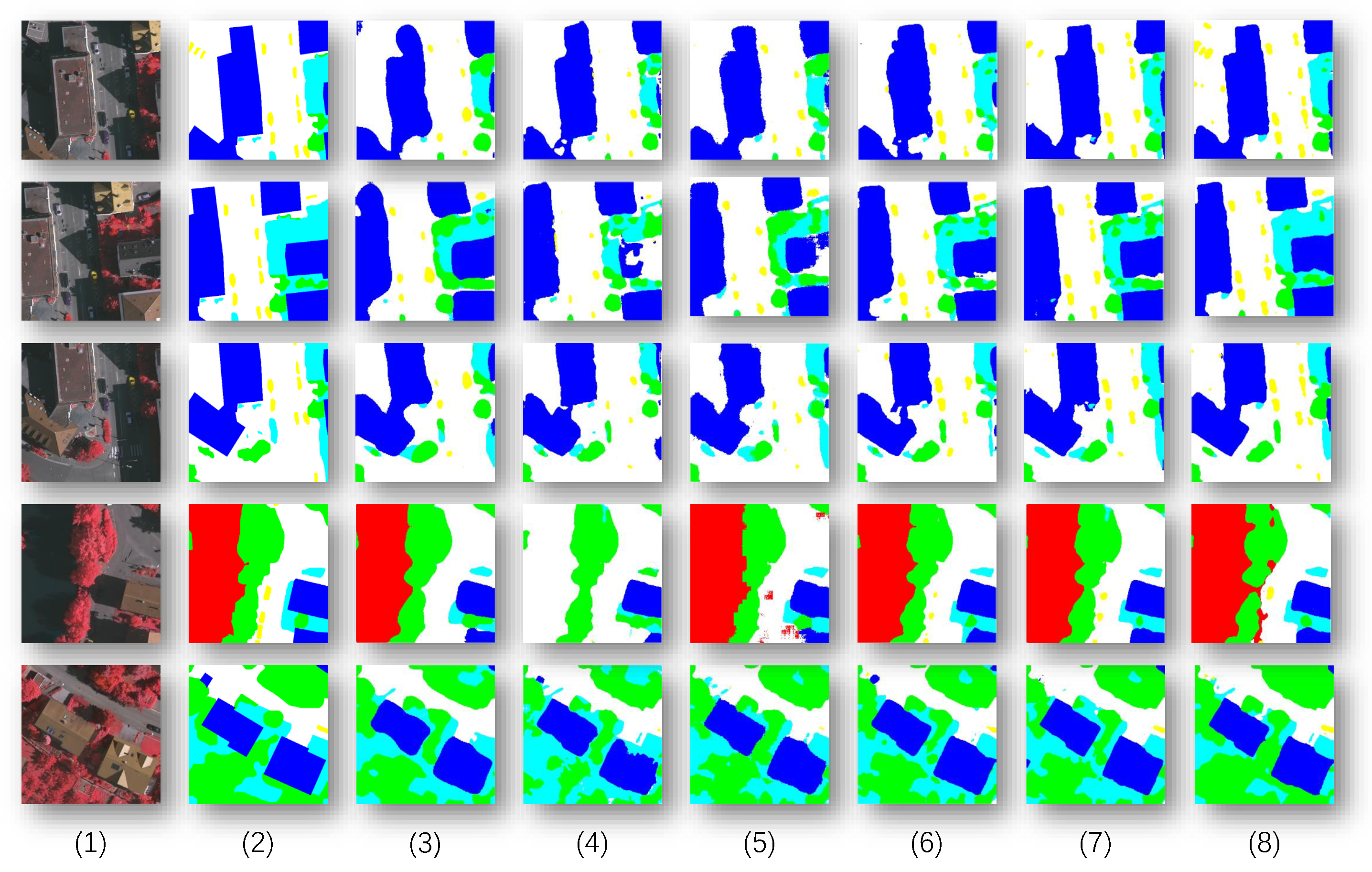
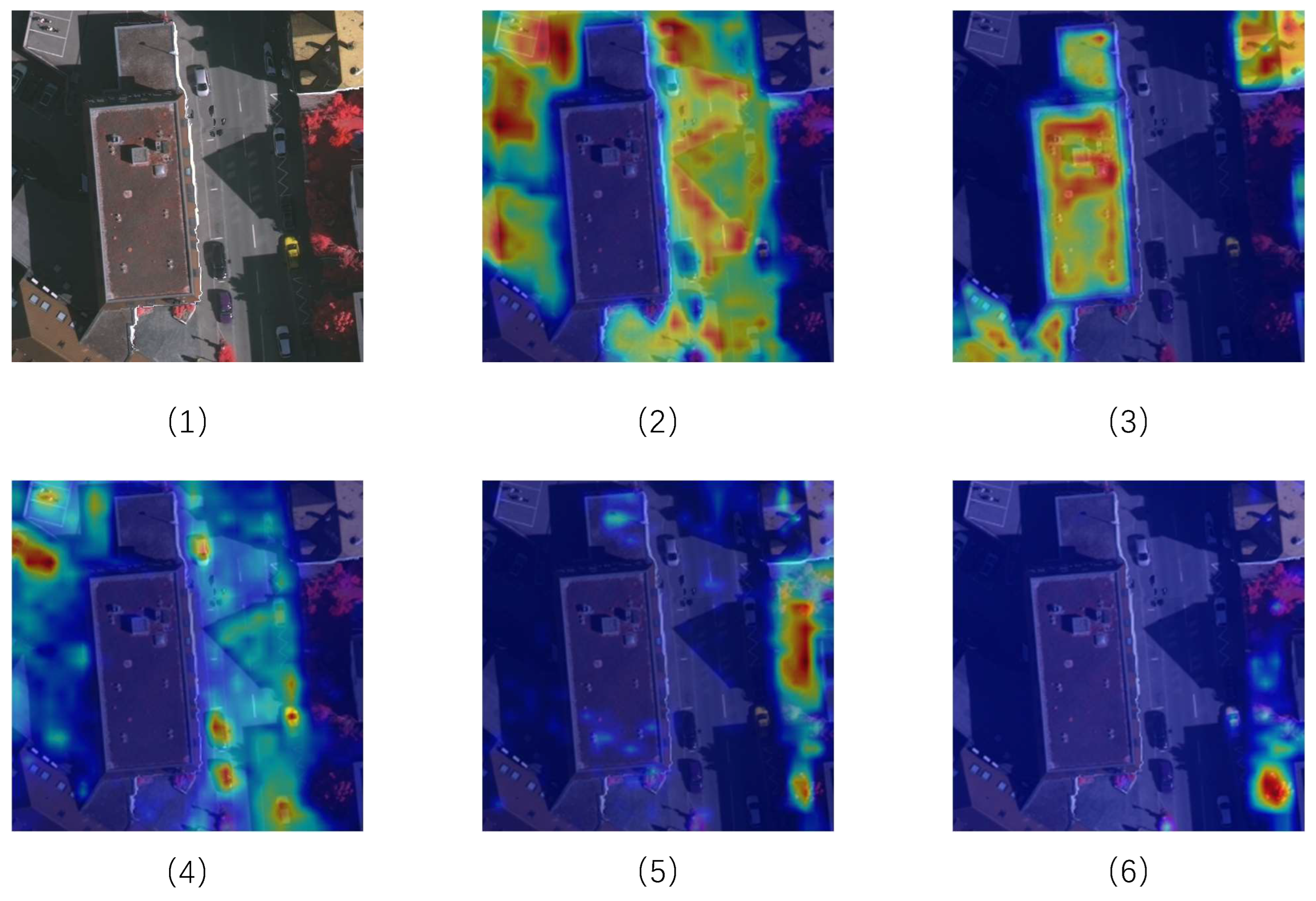
4.5.4. Visualization Analysis
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fu, K.; Lu, W.X.; Liu, X.Y.; Deng, C.B.; Yu, H.F.; Sun, X. A comprehensive survey and assumption of remote sensing foundation modal. Natl. Remote Sens. Bull. 2024, 28, 1667–1680. [Google Scholar] [CrossRef]
- Yuan, T.; Hu, B. REU-Net: A Remote Sensing Image Building Segmentation Network Based on Residual Structure and the Edge Enhancement Attention Module. Appl. Sci. 2025, 15, 3206. [Google Scholar] [CrossRef]
- He, Y.; Seng, K.P.; Ang, L.M.; Peng, B.; Zhao, X. Hyper-CycleGAN: A New Adversarial Neural Network Architecture for Cross-Domain Hyperspectral Data Generation. Appl. Sci. 2025, 15, 4188. [Google Scholar] [CrossRef]
- Zhang, L.P.; Zhang, L.F.; Du, B. Deep Learning for Remote Sensing Data: A Technical Tutorial on the State of the Art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Kazerouni, A.; Karimijafarbigloo, S.; Azad, R.; Velichko, Y.; Bagci, U.; Merhof, D. FuseNet: Self-Supervised Dual-Path Network For Medical Image Segmentation. In Proceedings of the 2024 IEEE International Symposium on Biomedical Imaging (ISBI), Athens, Greece, 27–30 May 2024; pp. 1–5. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models from Natural Language Supervision. In Proceedings of the International Conference on Machine Learning, Salt Lake City, UT, USA, 18–24 July 2021. [Google Scholar]
- Yuan, L.; Chen, D.; Chen, Y.L.; Codella, N.C.F.; Dai, X.; Gao, J.; Hu, H.; Huang, X.; Li, B.; Li, C.; et al. Florence: A New Foundation Model for Computer Vision. arXiv 2021, arXiv:2111.11432. [Google Scholar]
- Bao, H.; Dong, L.; Piao, S.; Wei, F. BEiT: BERT PreTraining of Image Transformers. In Proceedings of the The Tenth International Conference on Learning Representations, Vienna, Austria, 25–29 April 2022. [Google Scholar]
- Sherrah, J. Fully convolutional networks for dense semantic labelling of high-resolution aerial imagery. arXiv 2016, arXiv:1606.02585. [Google Scholar]
- Guo, Y.; Jia, X.; Paull, D. Effective sequential classifier training for SVM-based multitemporal remote sensing image classification. IEEE Trans. Image Process. 2018, 27, 3036–3048. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2007, 26, 217–222. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y. A New Paradigm of Remote Sensing Image Interpretation by Coupling Knowledge Graph and Deep Learning. Geomat. Inf. Sci. Wuhan Univ. 2022, 47, 1176–1190. [Google Scholar] [CrossRef]
- Zhang, S.; Wu, G.; Gu, J.; Han, J. Pruning convolutional neural networks with an attention mechanism for remote sensing image classification. Electronics 2020, 9, 1209. [Google Scholar] [CrossRef]
- Dong, R.; Pan, X.; Li, F. DenseU-net-based semantic segmentation of small objects in urban remote sensing images. IEEE Access 2019, 7, 65347–65356. [Google Scholar] [CrossRef]
- Zhou, X.; Wu, G.; Sun, X.; Hu, P.; Liu, Y. Attention-Based Multi-Kernelized and Boundary-Aware Network for image semantic segmentation. Neurocomputing 2024, 597, 127988. [Google Scholar] [CrossRef]
- Sun, X.; Chen, C.; Wang, X.; Dong, J.; Zhou, H.; Chen, S. Gaussian dynamic convolution for efficient single-image segmentation. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 2937–2948. [Google Scholar] [CrossRef]
- Li, Z.; Wu, G.; Liu, Y. Prototype Enhancement for Few-Shot Point Cloud Semantic Segmentation. In Proceedings of the International Conference on Algorithms and Architectures for Parallel Processing, Macau, China, 29–31 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 270–285. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the NIPS, Red Hook, NY, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- An, W.; Wu, G. Hybrid spatial-channel attention mechanism for cross-age face recognition. Electronics 2024, 13, 1257. [Google Scholar] [CrossRef]
- Lv, Q.; Sun, X.; Chen, C.; Dong, J.; Zhou, H. Parallel complement network for real-time semantic segmentation of road scenes. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4432–4444. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the ICCV, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wan, Y.; Zhou, D.; Wang, C.; Liu, Y.; Bai, C. Multi-scale medical image segmentation based on pixel encoding and spatial attention mechanism. Sheng Wu Yi Xue Gong Cheng Xue Za Zhi 2024, 41, 511–519. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the MICCAI, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chen, Y.; Wang, Y.; Jiao, P.; Feng, M. A self-attention CNN for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3155–3169. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1155–1167. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the NIPS, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the Proc. ICLR, Vienna, Austria, 4 May 2021. [Google Scholar]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin transformer embedding UNet for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, L. Multi-scale spatial context-aware transformer for remote sensing image segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar]
- Bazi, Y.; Bashmal, L.; Al Rahhal, M.M.; Dayil, R.A.; Ajami, N. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Liu, C.; Wu, H.; Li, Y.; Li, X. SwinFCN: A spatial attention Swin transformer backbone for semantic segmentation of high-resolution aerial images. Remote Sens. 2022, 14, 1075. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Liang, J.; Deng, Y.; Zeng, D. A deep neural network combined CNN and GCN for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4325–4338. [Google Scholar] [CrossRef]
- Chen, Z.; Badrinarayanan, V.; Lee, C.Y.; Rabinovich, A. GradNet: Gradient-guided network for visual object tracking. In Proceedings of the ICCV, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6162–6171. [Google Scholar]
- Sun, F.; Li, W.; Guan, X.; Liu, H.; Wu, J.; Gao, Y. Dual attention graph convolutional network for semantic segmentation of very high resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar]
- Zhang, Z.; Wang, L.; Zhang, Y. Multi-scale graph convolutional network for remote sensing image segmentation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Li, Z.; Luo, Y.; Wang, Z.; Zhang, B. MAT-GCN: A multi-scale attention guided graph convolutional network for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Liu, M.; Dan, J.; Lu, Z.; Yu, Y.; Li, Y.; Li, X. CM-UNet: Hybrid CNN-Mamba UNet for Remote Sensing Image Semantic Segmentation. arXiv 2024, arXiv:2405.10530. [Google Scholar]
- Zhang, Q.; Li, Z.; Xu, H. Multimodal fusion for remote sensing image segmentation using Mamba model. J. Appl. Remote Sens. 2022, 16, 19–32. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 779–788. [Google Scholar]
- Gao, Y.; Liu, Z.; Zhang, X. Real-time remote sensing image change detection using YOLO. J. Remote Sens. Technol. 2019, 20, 89–101. [Google Scholar]
- Vennerød, C.; Kjærran, A.; Bugge, E. Long Short-term Memory RNN. arXiv 2021, arXiv:2105.06756. [Google Scholar]
- Chen, J.; Zhang, Y.; Liu, Q. Remote sensing image segmentation based on LSTM for urban change detection. Int. J. Remote Sens. 2020, 41, 2048–2061. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. In Proceedings of the ECCV Workshops, Milan, Italy, 29 September–4 October 2021. [Google Scholar]
- Chen, Y.; Lin, G.; Li, S.; Bourahla, O.E.; Wu, Y.; Wang, F.; Feng, J.; Xu, M.; Li, X. BANet: Bidirectional Aggregation Network With Occlusion Handling for Panoptic Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3792–3801. [Google Scholar]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Xiang, J.; Liu, J.; Chen, D.; Xiong, Q.; Deng, C. CTFuseNet: A Multi-Scale CNN-Transformer Feature Fused Network for Crop Type Segmentation on UAV Remote Sensing Imagery. Remote Sens. 2023, 15, 1151. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Wei, S.; Jiang, Y.; Du, B.; Tan, M.; Xu, M.; Lian, W.; Zhang, G. Large-Scale Combined Adjustment of Optical Satellite Imagery and ICESat-2 Data through Terrain Profile Elevation Sequence Similarity Matching. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 19771–19785. [Google Scholar] [CrossRef]
- Siyuan, Z.; Jingxian, D.; Kabika, T.B.; Hongsen, C.; Chervan, A.; Xin, L.; Wenguang, H. LIE-DSM: Leveraging Single Remote Sensing Imagery to Enhance Digital Surface Model Resolution. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5627512. [Google Scholar]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Ma, X.; Zhang, X.; Pun, M.O.; Liu, M. A multilevel multimodal fusion transformer for remote sensing semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5403215. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Imp. Surf. (%) | Building (%) | Car (%) | Low Veg. (%) | Tree (%) | mIoU (%) | mF1 (%) | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | |||
| SwinT | 72.74 | 82.27 | 81.90 | 88.83 | 26.24 | 44.02 | 66.31 | 79.93 | 68.41 | 79.46 | 63.12 | 74.90 |
| Swin UNet | 65.75 | 77.08 | 71.51 | 81.24 | 28.05 | 46.36 | 55.10 | 69.61 | 61.01 | 73.89 | 56.28 | 69.64 |
| BANet | 72.14 | 81.87 | 81.47 | 88.44 | 32.96 | 52.26 | 65.70 | 79.38 | 68.94 | 79.84 | 64.24 | 76.36 |
| FTUNetFormer | 75.91 | 84.60 | 84.49 | 90.38 | 43.71 | 63.99 | 69.06 | 82.33 | 70.28 | 80.88 | 68.69 | 80.44 |
| CTFuse | 77.19 | 85.37 | 78.51 | 87.96 | 56.06 | 71.84 | 73.20 | 84.53 | 72.03 | 83.74 | 71.40 | 82.69 |
| PLGTransformer | 81.46 | 88.45 | 77.64 | 87.41 | 59.05 | 74.26 | 73.38 | 84.65 | 72.74 | 84.22 | 72.85 | 83.80 |
| Model | Imp. Surf. (%) | Building (%) | Car (%) | Low Veg. (%) | Tree (%) | mIoU (%) | mF1 (%) | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | |||
| SwinT | 65.17 | 74.50 | 58.06 | 63.03 | 51.71 | 58.41 | 67.84 | 79.01 | 58.74 | 68.76 | 60.30 | 68.74 |
| Swin UNet | 59.52 | 69.56 | 54.59 | 60.22 | 56.77 | 62.52 | 63.38 | 75.12 | 52.06 | 62.35 | 57.26 | 65.95 |
| BANet | 63.25 | 72.82 | 55.99 | 61.28 | 53.51 | 59.82 | 66.77 | 78.09 | 54.65 | 64.62 | 58.83 | 67.33 |
| FTUNetFormer | 66.87 | 75.78 | 59.23 | 63.96 | 57.66 | 63.24 | 70.16 | 81.14 | 60.25 | 70.30 | 62.83 | 70.88 |
| CTFuse | 67.98 | 76.55 | 68.81 | 81.52 | 59.56 | 74.66 | 77.46 | 87.30 | 61.37 | 76.06 | 67.04 | 79.22 |
| PLGTransformer | 58.90 | 74.14 | 85.21 | 92.01 | 70.44 | 82.66 | 61.11 | 70.40 | 75.14 | 85.81 | 70.16 | 81.00 |
| Model | Imp. Surf. (%) | Building (%) | Car (%) | Low Veg. (%) | Tree (%) | mIoU (%) | mF1 (%) | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | |||
| Base | 65.75 | 77.08 | 71.51 | 81.24 | 18.05 | 26.36 | 45.10 | 59.61 | 61.01 | 73.89 | 52.29 | 63.64 |
| Base+PSFM | 67.28 | 78.41 | 78.70 | 86.81 | 6.90 | 11.24 | 50.68 | 64.70 | 61.90 | 74.27 | 53.09 | 63.09 |
| Base+GFM | 70.57 | 80.66 | 79.66 | 87.19 | 29.19 | 39.27 | 53.71 | 67.62 | 67.07 | 78.35 | 60.04 | 70.62 |
| Base+PSFM+GFM | 81.46 | 88.45 | 77.64 | 87.41 | 59.05 | 74.26 | 73.38 | 84.65 | 72.74 | 84.22 | 72.85 | 83.80 |
| Model | Imp. Surf. (%) | Building (%) | Car (%) | Low Veg. (%) | Tree (%) | mIoU (%) | mF1 (%) | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | |||
| Base | 59.52 | 69.56 | 59.72 | 64.58 | 40.61 | 45.91 | 52.27 | 63.12 | 41.01 | 51.08 | 50.63 | 58.85 |
| Base+PSFM | 61.18 | 71.40 | 76.76 | 82.10 | 42.35 | 50.52 | 61.87 | 73.26 | 61.00 | 70.97 | 60.63 | 69.65 |
| Base+GFM | 62.26 | 72.06 | 75.00 | 80.57 | 56.55 | 62.58 | 58.73 | 70.19 | 65.70 | 76.22 | 63.65 | 72.32 |
| Base+PSFM+GFM | 58.90 | 74.14 | 85.21 | 92.01 | 70.44 | 82.66 | 61.11 | 70.40 | 75.14 | 85.81 | 70.16 | 81.00 |
| Setting | mIoU (%) | mF1 (%) | ||
|---|---|---|---|---|
| Baseline | ✔ | ✔ | 72.85 | 83.80 |
| Multi-Class Region Focal Loss Only | ✔ | 61.62 | 70.09 | |
| Multi-Scale Boundary Loss Only | ✔ | 63.43 | 74.06 |
| Parameter Varied | Value | Fixed Parameters | mIoU (%) | mF1 (%) |
|---|---|---|---|---|
| 0.25 | , , | 71.63 | 82.57 | |
| 0.5 | , , | 72.80 | 84.02 | |
| 1.0 | , , | 72.85 | 83.80 | |
| 2.0 | , , | 72.62 | 83.66 | |
| 5.0 | , , | 71.54 | 81.44 | |
| 0.1 | , , | 67.25 | 77.05 | |
| 0.3 | , , | 72.85 | 83.80 | |
| 0.5 | , , | 71.98 | 82.79 | |
| 0.7 | , , | 68.64 | 76.55 | |
| 0.9 | , , | 64.26 | 75.96 | |
| 0.0 | , , | 71.64 | 82.57 | |
| 1.0 | , , | 72.45 | 83.68 | |
| 2.0 | , , | 72.85 | 83.80 | |
| 3.0 | , , | 72.51 | 83.69 | |
| 5.0 | , , | 71.76 | 82.61 | |
| 0.1 | , , | 71.12 | 81.92 | |
| 0.2 | , , | 72.20 | 82.88 | |
| 0.3 | , , | 72.85 | 83.80 | |
| 0.5 | , , | 71.78 | 82.41 | |
| 1.0 | , , | 70.50 | 80.75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Wu, G. Multi-Scale Feature Fusion and Global Context Modeling for Fine-Grained Remote Sensing Image Segmentation. Appl. Sci. 2025, 15, 5542. https://doi.org/10.3390/app15105542
Li Y, Wu G. Multi-Scale Feature Fusion and Global Context Modeling for Fine-Grained Remote Sensing Image Segmentation. Applied Sciences. 2025; 15(10):5542. https://doi.org/10.3390/app15105542
Chicago/Turabian StyleLi, Yifan, and Gengshen Wu. 2025. "Multi-Scale Feature Fusion and Global Context Modeling for Fine-Grained Remote Sensing Image Segmentation" Applied Sciences 15, no. 10: 5542. https://doi.org/10.3390/app15105542
APA StyleLi, Y., & Wu, G. (2025). Multi-Scale Feature Fusion and Global Context Modeling for Fine-Grained Remote Sensing Image Segmentation. Applied Sciences, 15(10), 5542. https://doi.org/10.3390/app15105542