
Automatic Identification and Description of Jewelry Through Computer Vision and Neural Networks for Translators and Interpreters

 , , , ,
, , , ,  and
and 
Abstract
1. Introduction
2. Related Work
2.1. AI and Applied Linguistics
2.2. Computer Vision for Jewelry Analysis
2.3. Neural Networks for Image Captioning
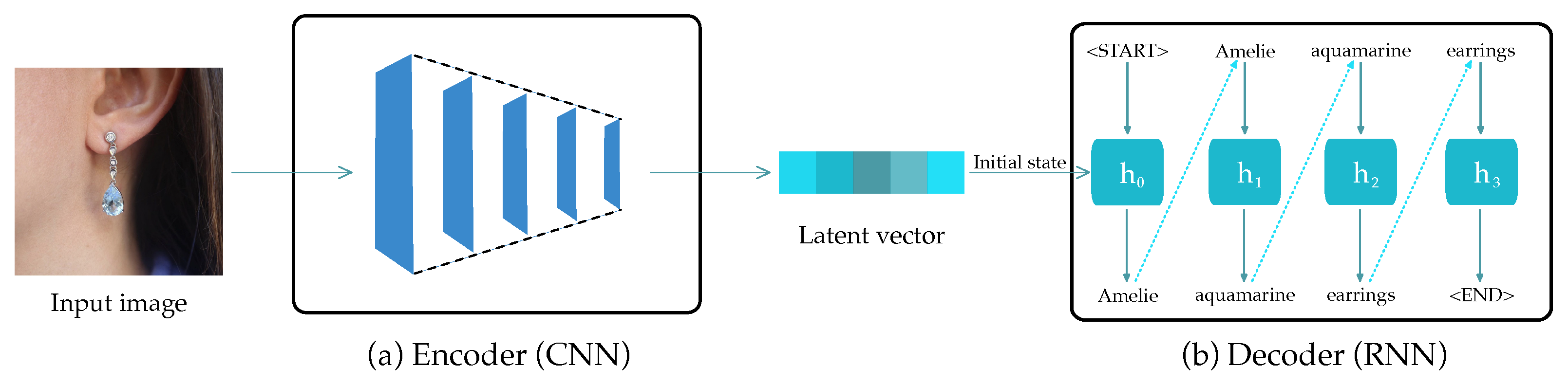
3. Materials and Methods
3.1. Levels and Terminology for the Description of Jewelry
- Basic description: noun + noun.
- -
- Communicative efficiency: This simple format focuses on the essence of the jewelry by combining two key nouns. It provides concise and direct information about the type of jewelry present. In contexts where brevity is essential, this format allows for quick identification of the jewelry type.
- -
- Clarity and simplicity: This is ideal for quickly identifying the type of jewelry without adding unnecessary details. The straightforward structure enhances clarity, making it suitable for scenarios where a quick overview is required.
- Normal description: adjective + noun + adjective + noun.
- -
- Semantic expansion: The inclusion of adjectives allows for a more detailed and nuanced description. It enables conveying specific features such as color, material, or design. This format provides a broader semantic scope, accommodating a richer set of details.
- -
- Aesthetic appeal: By adding adjectives, the beauty and visual attributes of the jewelry are highlighted. This can be relevant in contexts where aesthetics plays a significant role, such as art exhibitions or design showcases.
- Complete description: superlative adjectives + noun + complement.
- -
- Comprehensiveness and specificity: The inclusion of superlative adjectives indicates the exceptional quality of the jewelry, offering a complete and detailed description. This format is essential for describing unique or high-value pieces, providing comprehensive insights.
- -
- Differentiation and valuation: This allows highlighting the unique features that make the jewelry stand out among others. It is especially valuable in contexts where exclusivity is sought, such as luxury markets or bespoke jewelry presentations.
3.2. Fundamentals of Jewelry Terminology
3.3. Creation of the Dataset
3.4. Experimental Design
- Number of neurons in the RNN: This parameter affects the model’s capacity to capture complex linguistic patterns. The values considered were 64, 128, 256, 512, and 1024.
- Batch size: This determines the number of samples processed per training iteration. Tested batch sizes included 4, 8, 32, 128, and 512.
- Learning rate: This regulates the step size during the optimization process and is essential for effective model convergence. The explored values were 0.0001, 0.001, 0.01, and 0.1.
- Optimizer: Optimizers influence parameter updates during training, affecting convergence speed and stability. The following optimizers were evaluated: Adam, Adagrad, Adadelta, and RMSProp.
4. Results and Discussion
- Basic description: ‘A necklace with a pendant’.
- Normal description: ‘A gold necklace with a sapphire pendant’.
- Complete description (after several iterations): ‘This exquisite gold necklace showcases a beautiful sapphire pendant, adding a touch of elegance and sophistication to the accessory’.
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar] [CrossRef]
- Stefanini, M.; Cornia, M.; Baraldi, L.; Cascianelli, S.; Fiameni, G.; Cucchiara, R. From Show to Tell: A Survey on Deep Learning-Based Image Captioning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 539–559. [Google Scholar] [CrossRef] [PubMed]
- Xiao, X.; Wang, L.; Ding, K.; Xiang, S.; Pan, C. Deep Hierarchical Encoder–Decoder Network for Image Captioning. IEEE Trans. Multimed. 2019, 21, 2942–2956. [Google Scholar] [CrossRef]
- Jackendoff, R. Foundations of Language: Brain, Meaning, Grammar, Evolution; Oxford University Press: Oxford, UK, 2002. [Google Scholar] [CrossRef]
- Jackendoff, R.; Wittenberg, E. Linear grammar as a possible stepping-stone in the evolution of language. Psychon. Bull. Rev. 2016, 24, 219–224. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 7–9 July 2015; Volume 37. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the Stanford CoreNLP Natural Language Processing Toolkit, Baltimore, MA, USA, 1 June 2014. [Google Scholar] [CrossRef]
- Bar-Hillel, Y. Language and Information; Addison-Wesley Pub. Co.: Reading, MA, USA, 1964. [Google Scholar]
- Bar-Hillel, Y. Aspects of Language. Br. J. Philos. Sci. 1973, 24, 190–193. [Google Scholar] [CrossRef]
- McShane, M.; Nirenburg, S. Linguistics for the Age of AI; MIT Press: London, UK, 2021. [Google Scholar]
- Li, C.; Kang, Q.; Ge, G.; Song, Q.; Lu, H.; Cheng, J. DeepBE: Learning Deep Binary Encoding for Multi-label Classification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 744–751. [Google Scholar] [CrossRef]
- Chen, S.Y.; Luo, G.J.; Li, X.; Ji, S.M.; Zhang, B.W. The Specular Exponent as a Criterion for Appearance Quality Assessment of Pearllike Objects by Artificial Vision. IEEE Trans. Ind. Electron. 2012, 59, 3264–3272. [Google Scholar] [CrossRef]
- Alcalde-Llergo, J.M.; Yeguas-Bolívar, E.; Zingoni, A.; Fuerte-Jurado, A. Jewelry Recognition via Encoder-Decoder Models. In Proceedings of the 2023 IEEE International Conference on Metrology for eXtended Reality, Artificial Intelligence and Neural Engineering (MetroXRAINE), Milano, Italy, 25–27 October 2023. [Google Scholar] [CrossRef]
- Yu, J.; Li, H.; Hao, Y.; Zhu, B.; Xu, T.; He, X. CgT-GAN: CLIP-guided Text GAN for Image Captioning. In Proceedings of the 31st ACM International Conference on Multimedia, MM ’23, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 2252–2263. [Google Scholar] [CrossRef]
- Shetty, R.; Rohrbach, M.; Hendricks, L.A.; Fritz, M.; Schiele, B. Speaking the Same Language: Matching Machine to Human Captions by Adversarial Training. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4155–4164. [Google Scholar] [CrossRef]
- Chaffin, A.; Kijak, E.; Claveau, V. Distinctive Image Captioning: Leveraging Ground Truth Captions in CLIP Guided Reinforcement Learning. arXiv 2024, arXiv:2402.13936. [Google Scholar] [CrossRef]
- Shi, H.; Li, P.; Wang, B.; Wang, Z. Image captioning based on deep reinforcement learning. In Proceedings of the 10th International Conference on Internet Multimedia Computing and Service, ICIMCS’18, Nanjing, China, 17–19 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Ghandi, T.; Pourreza, H.; Mahyar, H. Deep Learning Approaches on Image Captioning: A Review. ACM Comput. Surv. 2023, 56, 1–39. [Google Scholar] [CrossRef]
- McCoy, K.F.; Carberry, S.; Roper, T.; Green, N.L. Towards generating textual summaries of graphs. In Universal Access in HCI: Towards an Information Society for All, Proceedings of the HCI International ’2001 (the 9th International Conference on Human-Computer Interaction), New Orleans, LA, USA, 5–10 August 2001; Stephanidis, C., Ed.; Lawrence Erlbaum: Mahwah, NJ, USA, 2001; Volume 3, pp. 695–699. [Google Scholar]
- Grice, H.P. Logic and Conversation; Academic Press: Cambridge, MA, USA, 1975; Volume 3, pp. 41–58. [Google Scholar]
- Dijk, T.V. Semantic macro-structures and knowledge frames in discourse comprehension. In Cognitive Processes in Comprehension; Psychology Press: London, UK, 1977; pp. 3–32. [Google Scholar]
- Leech, G. Corpora and theories of linguistic performance. In Directions in Corpus Linguistics. Proceedings of the Nobel Symposium 82; Svartvik, J., Ed.; Trends in Linguistics. Studies and Monographs; Mouton de Gruyter: Berlin, Germany; New York, NY, USA, 1992; Volume 65, pp. 105–122. [Google Scholar]
- Mairal, R.; Ruiz de Mendoza, F. Levels of description and explanation in meaning construction. In Deconstructing Constructions; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2009; Volume 107, pp. 153–198. [Google Scholar] [CrossRef]
- Abdel-Raheem, A. Semantic macro-structures and macro-rules in visual discourse processing Semantic macro-structures and macro-rules in visual discourse processing. Vis. Stud. 2021, 38, 407–424. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems 30 (NIPS 2017), Processing of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar] [CrossRef]
- Bender, E.M.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’21, New York, NY, USA, 3–10 March 2021; pp. 610–623. [Google Scholar] [CrossRef]
- Kozhakhmetova, G.A.; Tazhibayeva, S. Kazakh jewelry: Problems of translation and creation of a multilingual thesaurus. Bull. L.N. Gumilyov Eurasian Natl. Univ. Philol. Ser. 2021, 135, 55–63. [Google Scholar] [CrossRef]
- Demortier, G. Targeting Ion Beam Analysis techniques for gold artefacts. ArchéoSciences 2009, 33, 29–38. [Google Scholar] [CrossRef]
- Yu, Q.; Meng, K.; Guo, J. Research on innovative application of silver material in modern jewelry design. MATEC Web Conf. 2018, 176, 02013. [Google Scholar] [CrossRef]
- Ariza-Montes, A. Plan Estratégico Del Sistema Productivo Local de la Joyería de Córdoba; Universidad de Loyola: Córdoba, Spain, 2006. [Google Scholar]
- Arellano, N.; Espinoza, A.; Perdomo, D.; Carpio, L. Joyería Marthita. DSpace en ESPOL Unidades Académicas Facultad de Ciencias Sociales y Humanísticas. Artículos de Tesis de Grado. 2009. Available online: https://www.dspace.espol.edu.ec/handle/123456789/1361?locale=en (accessed on 12 May 2025).
- Díaz, A.; Aguilar, D.; Blandón, J.; Estela, B. Competitividad entre joyerías y tiendas de bisutería fina legalmente constituidas, 2013. Rev. Cient. Estelí 2014, 9, 35–44. [Google Scholar] [CrossRef]
- Hani, S.; Marwan, A.; Andre, A. The effect of celebrity endorsement on consumer behavior: Case of the Lebanese jewelry industry. Arab Econ. Bus. J. 2018, 13, 190–196. [Google Scholar] [CrossRef]
- Alvarado Hidalgo, C.A. El marketing como factor relevante en la gestión de calidad y plan de mejora en las micro y pequeñas empresas del sector servicio-rubro joyería y perfumería, de la ciudad de Chimbote, 2019. Repositorio Institucional de ULADECH Católica. Trabajo de Investigación. 2021. Available online: https://repositorio.uladech.edu.pe/handle/20.500.13032/24863 (accessed on 12 May 2025).
- Liddicoat, A.J.; Curnow, T.J. Language Descriptions; Wiley: Hoboken, NJ, USA, 2004. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. arXiv 2019, arXiv:1911.02685. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, J.; Sun, Y. End-to-End Transformer Based Model for Image Captioning. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence. Assoc Advancement Artificial Intelligence, Virtual Event, 22 February–1 March 2022; pp. 2585–2594. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27 June–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. Int. J. Intell. Sci. 2017. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. ACL Anthol. 2014, 103–111. [Google Scholar] [CrossRef]
- Luo, G.; Cheng, L.; Jing, C.; Zhao, C.; Song, G. A thorough review of models, evaluation metrics, and datasets on image captioning. IET 2022, 16, 311–332. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Level |  |  |  |
|---|---|---|---|
| Basic | Earrings in yellow gold. | Solitaire in rose gold. | Yellow gold bracelet. |
| Normal | Yellow gold and diamond earrings. | Ring in rose gold with central diamond. | Yellow gold bracelet with topazes. |
| Complete | Earrings in sustainable yellow gold adorned with exquisite, brilliant-cut diamonds and featuring a secure push-back clasp. | Iris solitaire in rose gold with central diamond. | Sustainable yellow gold bracelet adorned with dazzling sky topazes. |
| CNN | RNN | Neurons | Val. CCR | Val. Loss | Test CCR |
|---|---|---|---|---|---|
| InceptionV3 | GRU | 1024 | 0.9187 | 0.1026 | 0.9161 |
| VGG-16 | GRU | 512 | 0.9314 | 0.0390 | 0.9464 |
| MobileNet | GRU | 64 | 0.8851 | 0.2696 | 0.8802 |
| InceptionV3 | LSTM | 1024 | 0.9487 | 0.0301 | 0.9193 |
| VGG-16 | LSTM | 512 | 0.9597 | 0.0542 | 0.9227 |
| MobileNet | LSTM | 64 | 0.8811 | 0.2208 | 0.8775 |
| Accessory | Precision | Recall | F1-Score |
|---|---|---|---|
| Necklaces | 0.9452 | 0.9087 | 0.9131 |
| Rings | 0.9276 | 0.9173 | 0.9343 |
| Earrings | 0.9452 | 0.9675 | 0.9674 |
| Bracelets | 0.9420 | 0.8298 | 0.8807 |
| CNN | RNN | Neurons | Val. CCR | Val. Loss | Test CCR |
|---|---|---|---|---|---|
| InceptionV3 | LSTM | 512 | 0.9307 | 0.0615 | 0.8439 |
| VGG-16 | LSTM | 512 | 0.9270 | 0.0881 | 0.9036 |
| InceptionV3 | GRU | 256 | 0.9483 | 0.0921 | 0.8354 |
| VGG-16 | GRU | 256 | 0.9633 | 0.0706 | 0.9345 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alcalde-Llergo, J.M.; Ruiz-Mezcua, A.; Ávila-Ramírez, R.; Zingoni, A.; Taborri, J.; Yeguas-Bolívar, E. Automatic Identification and Description of Jewelry Through Computer Vision and Neural Networks for Translators and Interpreters. Appl. Sci. 2025, 15, 5538. https://doi.org/10.3390/app15105538
Alcalde-Llergo JM, Ruiz-Mezcua A, Ávila-Ramírez R, Zingoni A, Taborri J, Yeguas-Bolívar E. Automatic Identification and Description of Jewelry Through Computer Vision and Neural Networks for Translators and Interpreters. Applied Sciences. 2025; 15(10):5538. https://doi.org/10.3390/app15105538
Chicago/Turabian StyleAlcalde-Llergo, José Manuel, Aurora Ruiz-Mezcua, Rocío Ávila-Ramírez, Andrea Zingoni, Juri Taborri, and Enrique Yeguas-Bolívar. 2025. "Automatic Identification and Description of Jewelry Through Computer Vision and Neural Networks for Translators and Interpreters" Applied Sciences 15, no. 10: 5538. https://doi.org/10.3390/app15105538
APA StyleAlcalde-Llergo, J. M., Ruiz-Mezcua, A., Ávila-Ramírez, R., Zingoni, A., Taborri, J., & Yeguas-Bolívar, E. (2025). Automatic Identification and Description of Jewelry Through Computer Vision and Neural Networks for Translators and Interpreters. Applied Sciences, 15(10), 5538. https://doi.org/10.3390/app15105538