
Health Assessment of Rolling Bearings Based on Multivariate State Estimation and Reliability Analysis

Abstract
1. Introduction
- A condition-robust deviation quantification mechanism that synergizes MSET’s nonlinear modeling with Mahalanobis distance’s covariance sensitivity, resolving Euclidean metric’s limitations in handling correlated multivariate bearing parameters and speed variation interference.
- A reliability-informed health evaluation paradigm that dynamically calibrates degradation assessment through statistical failure patterns, achieving service-mileage adaptive precision improvement beyond fixed-parameter assessment frameworks.
- Comprehensive validation through Case Western Reserve University bearing datasets demonstrates two advantages: (1) Inherent resistance to rotational speed fluctuation interference during operation. (2) Physically consistent monotonic degradation progression mapping across fault evolution phases.
2. Modeling of Initial Health Assessment Based on MSET
2.1. Select Feature Indicators
2.2. Establish Health Baseline Based on MSET
2.3. Deviation Distance Measurement Based on Mahalanobis Distance
2.4. Health Mapping Function
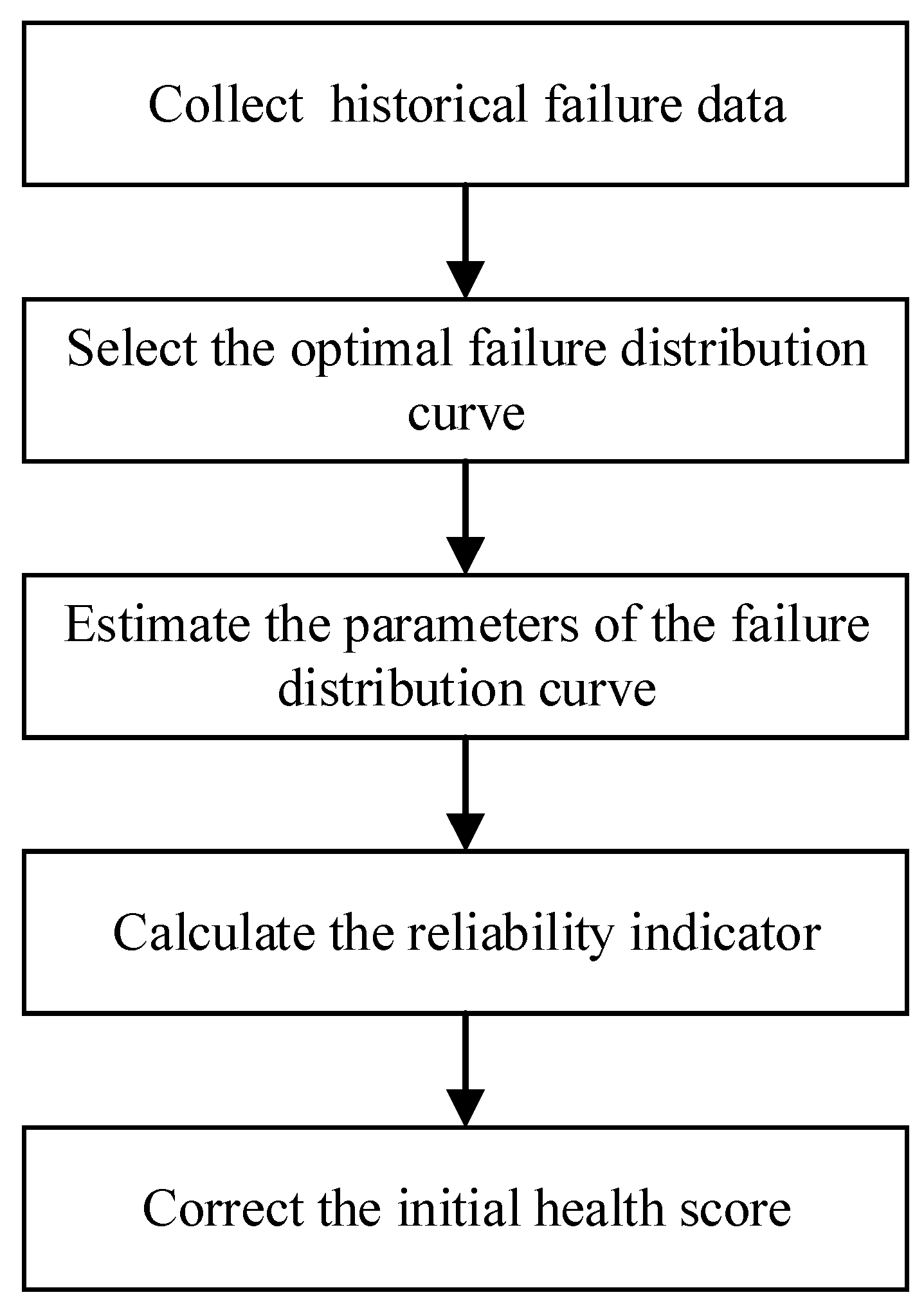
3. Health Score Correction Based on the Reliability Model
3.1. Reliability Indicators
3.2. Commonly Used Failure Distribution Curves
3.2.1. Normal Distribution
3.2.2. Log Normal Distribution
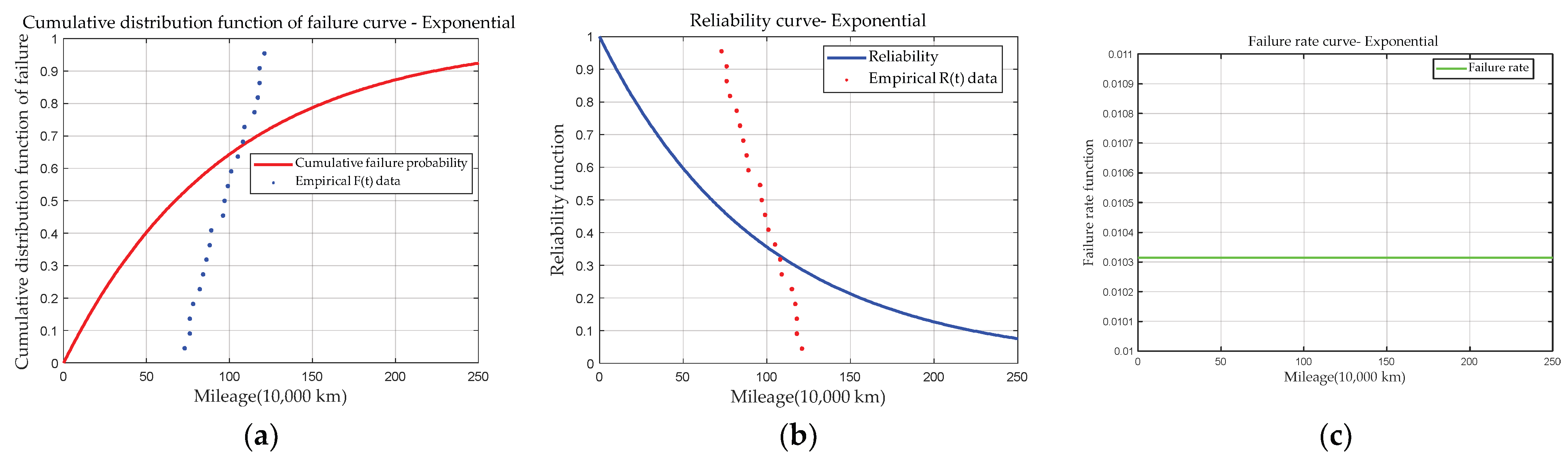
3.2.3. Exponential Distribution
3.2.4. Two-Parameter Weibull Distribution
3.2.5. Gamma Distribution
3.3. The Evaluation Criterion for the Optimal Failure Distribution Curve
3.4. The Health Correction Function Based on the Reliability Indicator
4. Experimental Results and Analysis
4.1. Modeling of Initial Health Assessment Model Based on MSET
4.1.1. Brief Description of Case Western Reserve University Bearing Data Set
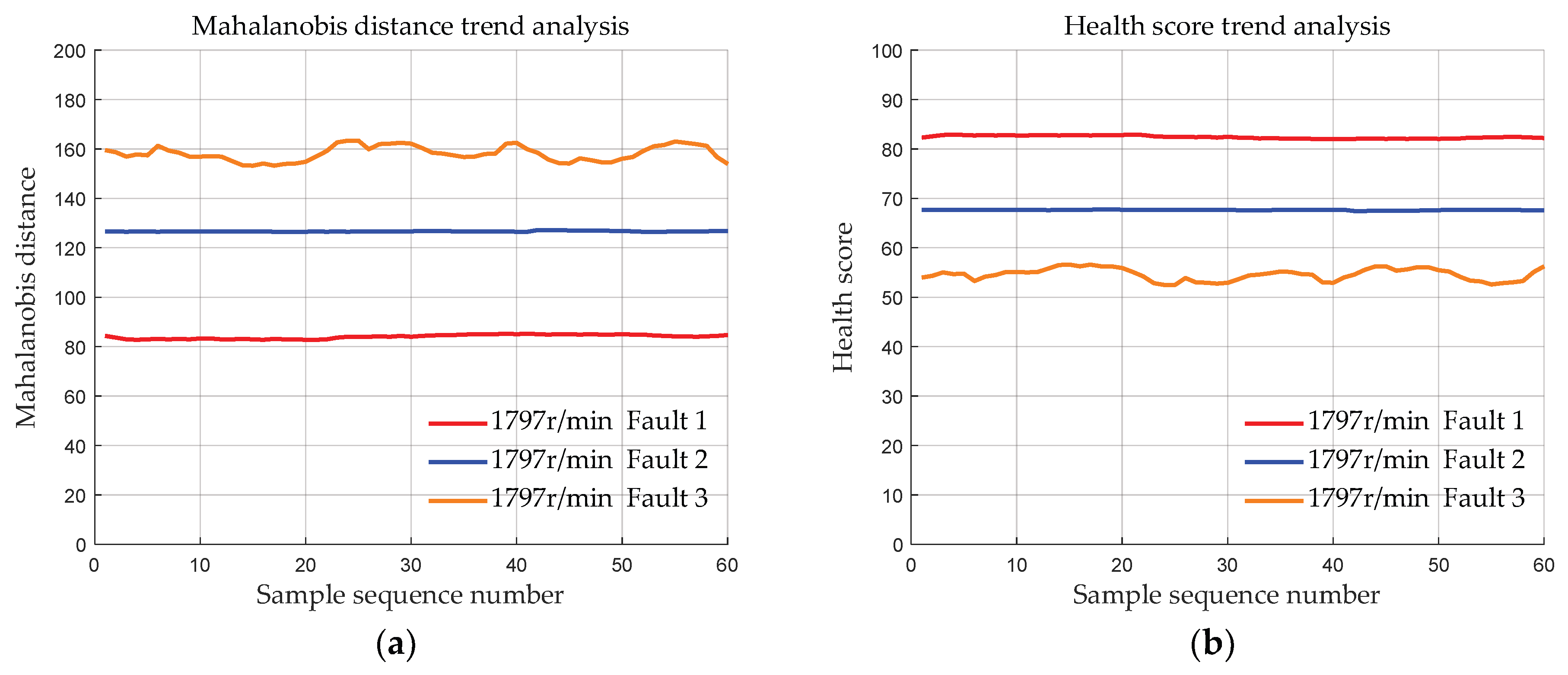
4.1.2. Data with Different Fault Degrees at the Same Speed
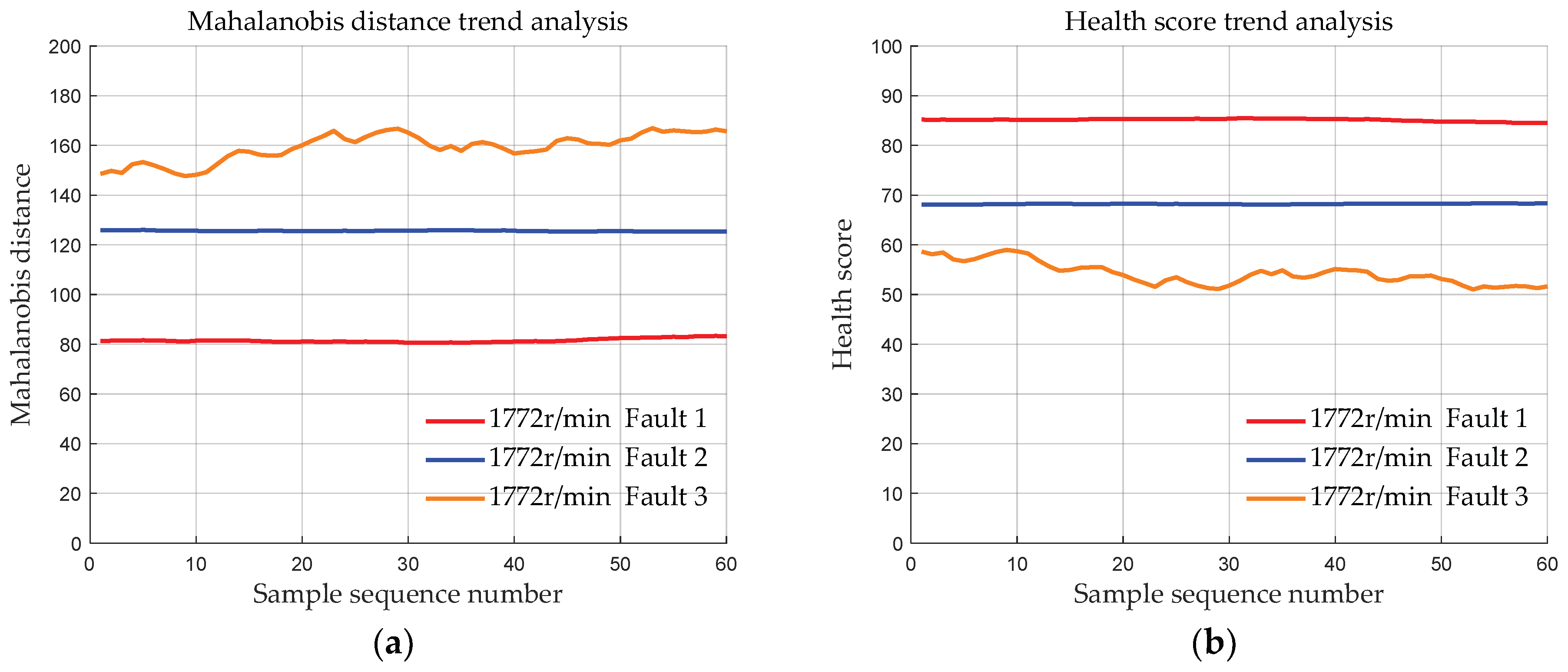
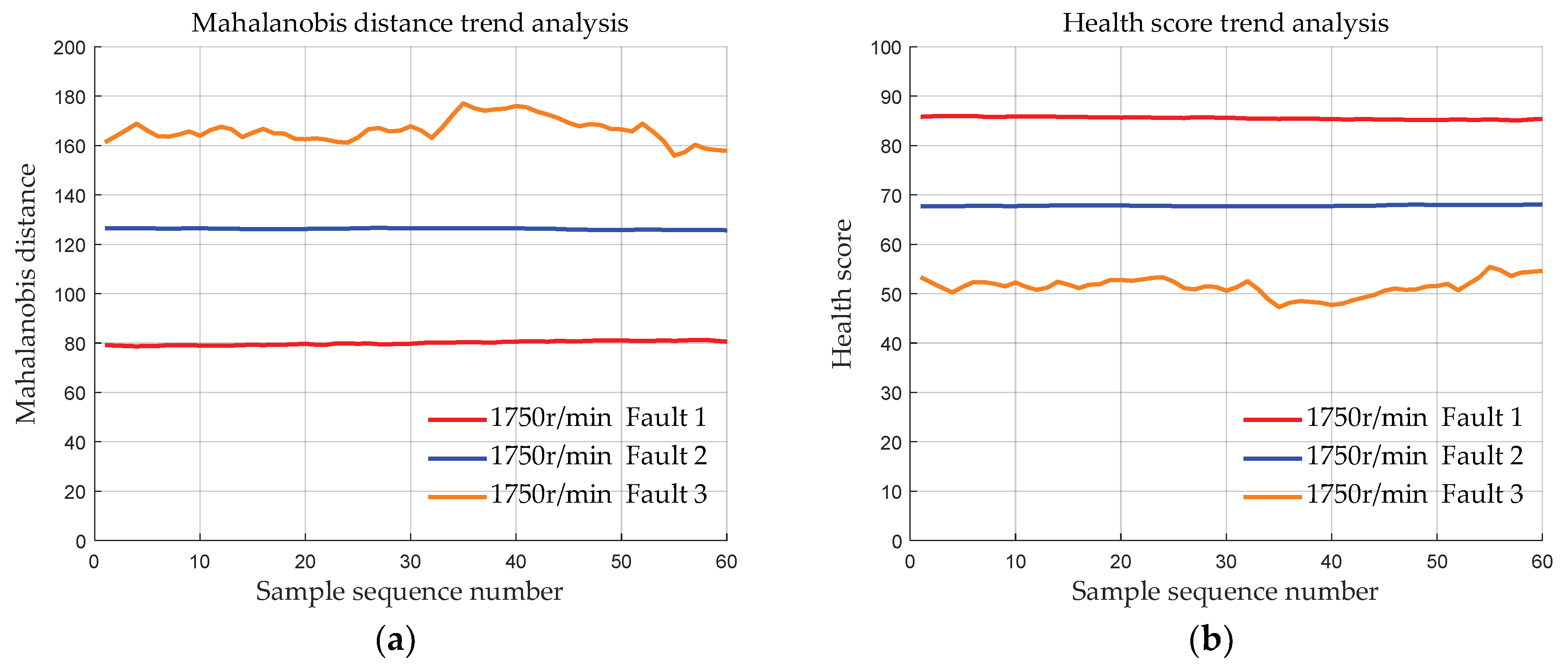
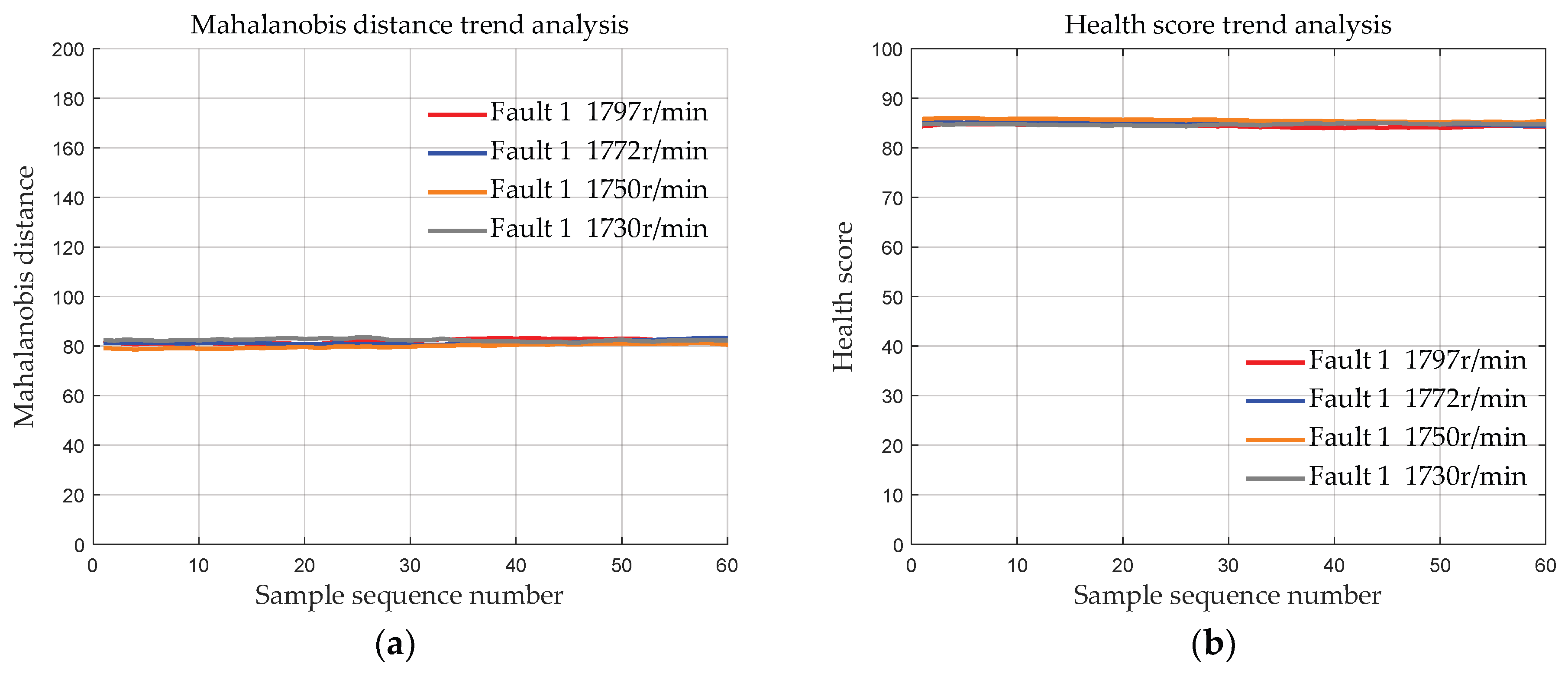
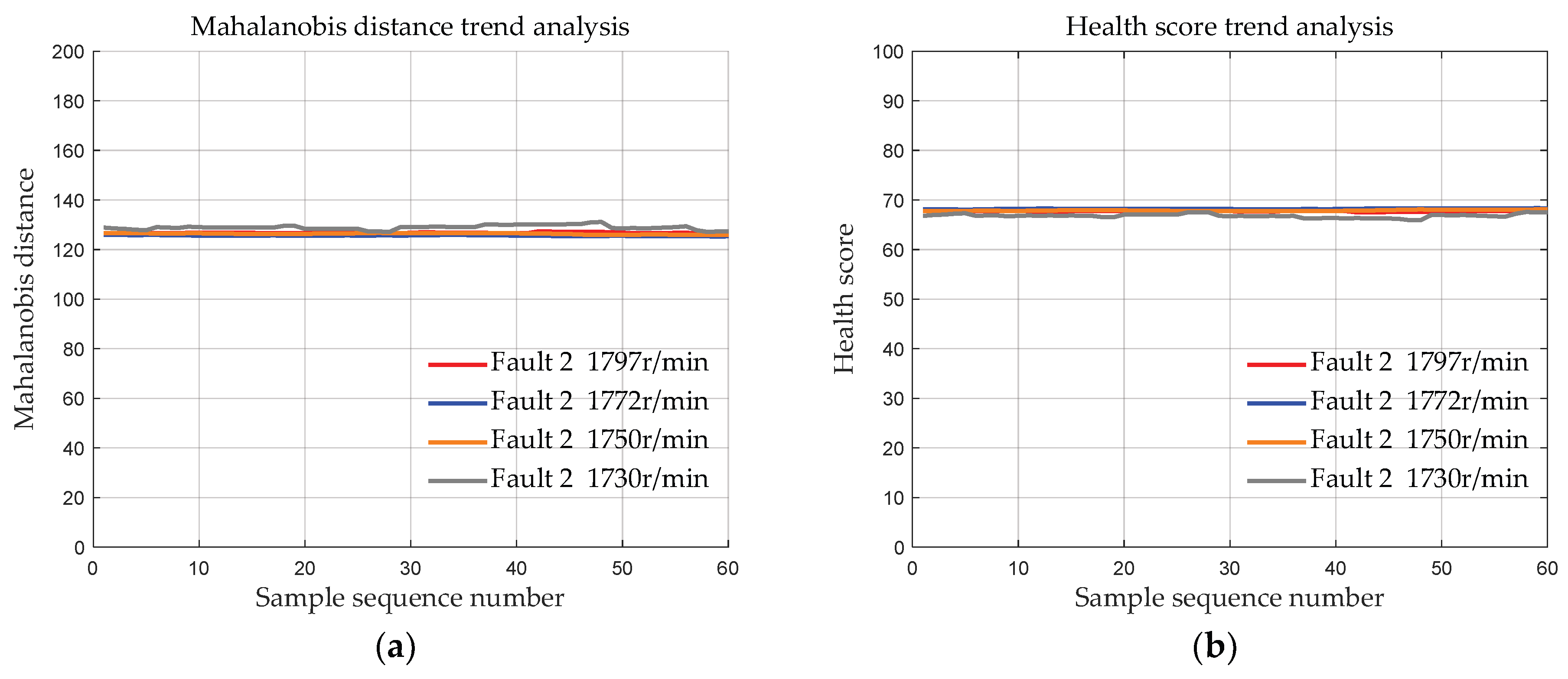
4.1.3. Data with the Same Fault Degree at Different Speeds
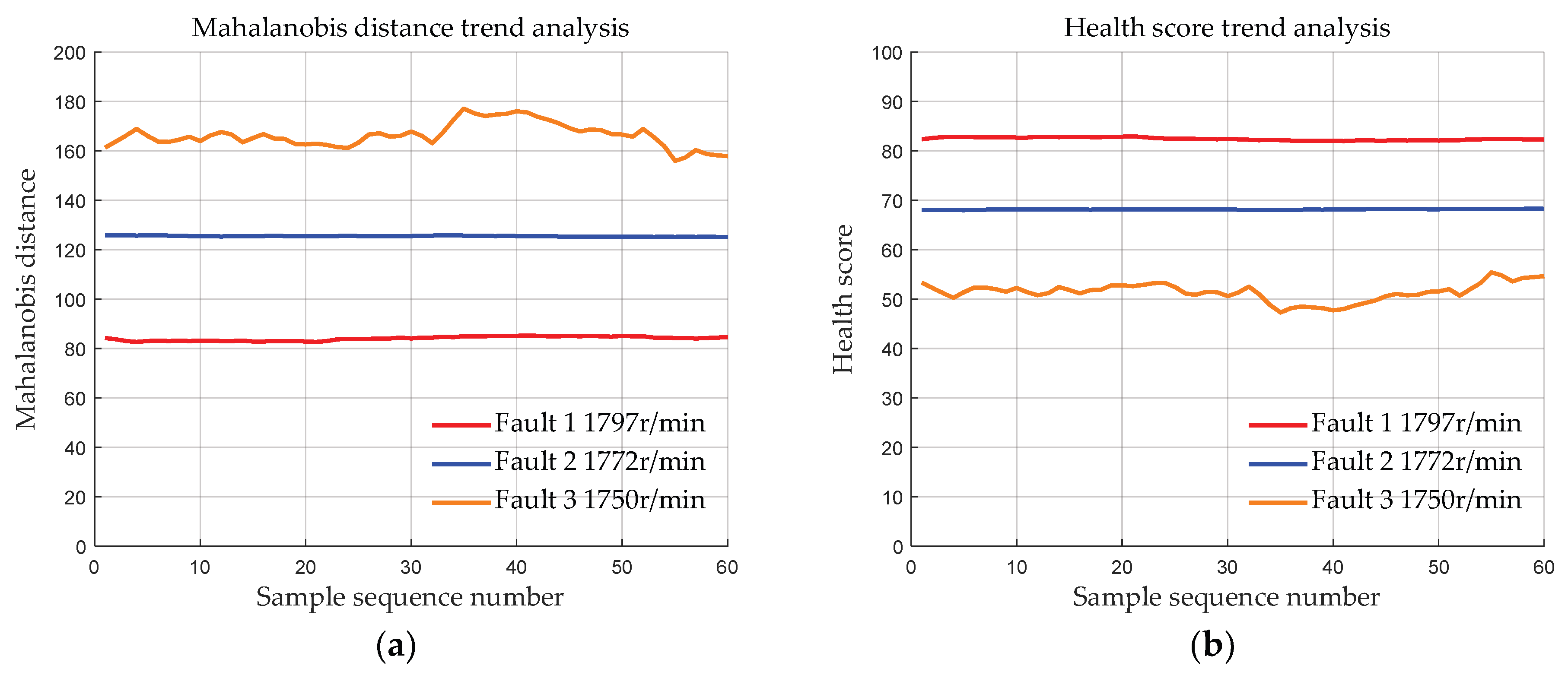
4.1.4. Data with Different Fault Degrees at Different Speeds
4.2. Health Score Correction Based on the Reliability Model
5. Conclusions
- (1)
- Validation was conducted using the bearing dataset from Case Western Reserve University to demonstrate the effectiveness of the initial bearing evaluation model based on MSET. The results show that the deviation distances of the bearing data of the three fault degrees calculated by the proposed method are approximately 83, 127, and 170, respectively. Moreover, the deviation distances of the bearings of each fault degree are basically the same at 4 different speeds, indicating that MSET can reduce the influence of the speed conditions on the bearing health assessment, ensuring that the health score is primarily determined by the fault severity.
- (2)
- Considering the natural performance degradation of bearings over service mileage, the reliability model was introduced to correct the initial health assessment of the bearings. Based on historical failure data and using AIC as the evaluation standard, the fitting performance of five commonly used failure distribution models was compared. With the Gamma distribution providing the smallest AIC value (178.592) among candidate distributions, the Gamma distribution was the best fit. As the service mileage increases, the corrected health score of the bearing gradually declines from 99.9 to 70.97, indicating the performance degradation of the bearing.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| Root mean square acceleration, in g. | |
| Peak acceleration, in g. | |
| K | Kurtosis of acceleration. |
| Time-series of feature indicators for the component at tj. | |
| The observation vector. | |
| D | The memory matrix. |
| The estimation vector. | |
| W | The weight vector. |
| ε | The residue between the observation vector and the estimation vector. |
| ⊗ | The nonlinear operator. |
| Cumulative failure probability. | |
| Failure probability density. | |
| Reliability. | |
| Failure rate. |
References
- He, M.; Guo, W. An integrated approach for bearing health indicator and stage division using improved Gaussian mixture model and confidence value. IEEE Trans. Ind. Inform. 2021, 18, 5219–5230. [Google Scholar] [CrossRef]
- Braun, S. The extraction of periodic waveforms by time domain averaging. Acustica 1975, 32, 69–77. [Google Scholar]
- Chaturvedi, G.K.; Thomas, D.W. Bearing fault detection using adaptive noise canceling. J. Sound Vib. 1982, 104, 280–289. [Google Scholar]
- Tan, J.Y.; Chen, X.F.; He, Z.J. Adaptive detection method of random resonance for impulse signals. J. Mech. Eng. 2010, 46, 61–67. [Google Scholar] [CrossRef]
- Yao, D.C. Fault Diagnosis Technology of Rail Transit Bearing; China Railway Publishing House: Beijing, China, 2017; pp. 45–47. ISBN 978-7-113-22353-3. [Google Scholar]
- Tang, D.Y. Generalized Resonance, Resonance Demodulation Fault Diagnosis and Safety Engineering Urban Rail Traffic; China Railway Publishing House: Beijing, China, 2013; pp. 17–18. ISBN 978-7-113-17412-5. [Google Scholar]
- Noman, K.; Li, Y.; Peng, Z.; Wang, S. Continuous health monitoring of bearing by oscillatory sparsity indices under non stationary time varying speed condition. IEEE Sens. J. 2022, 22, 4452–4462. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, S.; Li, W. Bearing performance degradation assessment using long short-term memory recurrent network. Comput. Ind. 2019, 106, 14–29. [Google Scholar] [CrossRef]
- Shao, X.; Kang, X.W.; Cao, X.R.; Wang, X.P.; Yuan, X.J.; Sun, L. Research on Gearbox Health Assessment Method Based on SOM Neural Network. J. Ord. Equip. Eng. 2021, 7, 246–251. [Google Scholar]
- Qifeng, Y.; Longsheng, C.; Naeem, M.T. Hidden Markov Models based intelligent health assessment and fault diagnosis of rolling element bearings. PLoS ONE 2024, 19, e0297513. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Huang, W.Y.; Xiong, G.L.; Cao, Q.S. Assessment of Rolling Bearing Performance Degradation Using Gauss Mixture Model and Multi-domain Features. China Mech. Eng. 2014, 22, 3066–3072. [Google Scholar]
- Gao, T.; Li, Y.; Huang, X.; Wang, C. Data-driven method for predicting remaining useful life of bearing based on Bayesian theory. Sensors 2020, 21, 182. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, R.Z.; Zhou, J.M.; Yi, J.Y.; Xu, T.P.; Wang, L.; Zou, M. Time Series multivariate State Estimation Method of Rolling Bearing Performance Degradation. Vib. Test Diagn. 2021, 6, 1096–1104+1235–1236. [Google Scholar] [CrossRef]
- Yu, J.M.; Zhai, X.F.; Wei, S.Y.; Zhao, Q.B.; Cai, Y.B. Early Fault Monitoring Method of Rotating Equipment Based on Multivariate State Estimation. J. Autom. Appl. 2022, 8, 42–45. [Google Scholar] [CrossRef]
- Zou, H.B.; Zhang, X.Y.; Li, Q.L. Turbine Fault Warning Algorithm Based on Association Rules and Multiple State Estimation. J. Jilin Univ. 2024, 11, 3283–3288. [Google Scholar]
- Wang, Z.; Liu, C. Wind turbine condition monitoring based on a novel multivariate state estimation technique. Measurement 2021, 168, 108388. [Google Scholar] [CrossRef]
- Zeng, Y.; Zhang, Y.; Yan, X.; Miao, Q. EMA health indicator extraction based on improved multivariate state estimation technique with a composite operator. IEEE Sens. J. 2023, 23, 19894–19904. [Google Scholar] [CrossRef]
- Fan, T.; Tian, S.; Hu, Z.; Fan, X.; Wang, S. Correlation-aware sport training evaluation for players with trust based on Mahalanobis distance. IEEE Access 2021, 10, 16898–16905. [Google Scholar] [CrossRef]
- Sun, B.Y. Research on Fault Early Warning Method of Induced Draft Fan Based on Multivariate State Estimation. Master’s Thesis, North China Electric Power University, Beijing, China, 2021. [Google Scholar] [CrossRef]
- Tu, W.B.; Liang, J.; Zhou, J.M.; Yang, J.W.; Yang, B.M. Sensitivity Analysis of Rolling Bearing Vibration Characteristic Evaluation Index. Noise Vib. Control 2022, 4, 93–99+131. [Google Scholar] [CrossRef]
- Sun, J.Z. Research on Unit Oriented Aero Engine Health State Evaluation and Prediction Method. Ph.D. Thesis, Nanjing University of Aeronautics and Astronautics, Nanjing, China, 2012. [Google Scholar]
- Yu, X.G.; Wang, L.C.; Zeng, J.; Wei, X.; Qiu, B.B. Failure early warning and positioning method based on dynamic memory matrix and weighted multivariate state estimation. Ther. Power Gen. 2025, 3, 140–149. [Google Scholar] [CrossRef]
- Song, Y.; Zhang, Z.L. Steam Turbine Condition Monitoring Based on Multivariate State Estimation Technique and Hyper-ellipsoid Analysis. J. Chin. Soc. Power Eng. 2020, 2, 138–144. [Google Scholar] [CrossRef]
- Wu, T.; Wang, Y.; Liu, Z.; Luo, R.; Liu, F.; Li, Y.; Li, M.; Shi, L. Coal mill fault warning based on multi-state estimation-analytic hierarchy process. Ther. Power Gen. 2023, 5, 14–21. [Google Scholar] [CrossRef]
- Cao, S.; Qiu, C.; Ding, C.; Wang, Y. Application of Multiple State Estimation Model Based on Improved entropy weight Method in Turbine energy efficiency Monitoring. J Ther. Energy Power Eng. 2023, 7, 185–193. [Google Scholar] [CrossRef]
- Duan, D.; Han, S.; Wang, Z.; Pang, C.; Yao, L.; Liu, W.; Yang, J.; Zheng, C.; Gao, X. Multivariate state estimation-based condition monitoring of slurry circulating pumps for wet flue gas desulfurization of power plants. Eng. Fail. Anal. 2024, 159, 108099. [Google Scholar] [CrossRef]
- Wu, Z.Y.; Sun, B. Life Evaluation of digital-analog Linkage Rolling Bearing Based on Mahalanobis Distance. J. Autom. Appl. 2024, 8, 207–210. [Google Scholar] [CrossRef]
- Ma, X.B. Reliability Statistical Analysis; Beijing Aerospace University Press: Beijing, China, 2020; pp. 1–5. ISBN 978-7-5124-3217-8. [Google Scholar]
- Cheng, J.W.; Liu, X.G.; Dong, H.G.; Zhu, Z.X. Model of Vehicle Failure Rate. J. Mil. Transp. 2015, 1, 38–42. [Google Scholar] [CrossRef]
- Smith, W.A.; Randall, R.B. Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study. Mech. Syst. Signal Process. 2015, 64–65, 100–131. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault Degree | Fault 1 | Fault 2 | Fault 3 |
|---|---|---|---|
| Fault diameter (mm) | 0.1778 | 0.3556 | 0.5334 |
| Motor Load | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| Approximate motor speed (r/min) | 1797 | 1772 | 1750 | 1730 |
| No. | Mileage (10,000 km) | Empirical Cumulative Distribution Function Value | Empirical Reliability Function Value |
|---|---|---|---|
| 1 | 73 | 0.0455 | 0.9545 |
| 2 | 76 | 0.0909 | 0.9091 |
| 3 | 76 | 0.1364 | 0.8636 |
| 4 | 78 | 0.1818 | 0.8182 |
| 5 | 82 | 0.2273 | 0.7727 |
| 6 | 84 | 0.2727 | 0.7273 |
| 7 | 86 | 0.3182 | 0.6818 |
| 8 | 88 | 0.3636 | 0.6364 |
| 9 | 89 | 0.4091 | 0.5909 |
| 10 | 96 | 0.4545 | 0.5455 |
| 11 | 97 | 0.5000 | 0.5 |
| 12 | 99 | 0.5455 | 0.4545 |
| 13 | 101 | 0.5909 | 0.4091 |
| 14 | 105 | 0.6364 | 0.3636 |
| 15 | 108 | 0.6818 | 0.3182 |
| 16 | 109 | 0.7273 | 0.2727 |
| 17 | 115 | 0.7727 | 0.2273 |
| 18 | 117 | 0.8182 | 0.1818 |
| 19 | 118 | 0.8636 | 0.1364 |
| 20 | 118 | 0.9091 | 0.0909 |
| 21 | 121 | 0.9545 | 0.0455 |
| Failure Distribution Model | Normal | Log-Normal | Exponential | Weibull | Gamma |
|---|---|---|---|---|---|
| AIC value | 178.5920 | 178.6018 | 236.1172 | 178.7564 | 178.4728 |
| Service Mileage | 500,000 km | 600,000 km | 700,000 km | 800,000 km | 900,000 km |
|---|---|---|---|---|---|
| Corrected health score | 99.9 | 99.67 | 96.99 | 87.46 | 70.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.; Liu, L. Health Assessment of Rolling Bearings Based on Multivariate State Estimation and Reliability Analysis. Appl. Sci. 2025, 15, 5396. https://doi.org/10.3390/app15105396
Chen C, Liu L. Health Assessment of Rolling Bearings Based on Multivariate State Estimation and Reliability Analysis. Applied Sciences. 2025; 15(10):5396. https://doi.org/10.3390/app15105396
Chicago/Turabian StyleChen, Chunjun, and Lizhi Liu. 2025. "Health Assessment of Rolling Bearings Based on Multivariate State Estimation and Reliability Analysis" Applied Sciences 15, no. 10: 5396. https://doi.org/10.3390/app15105396
APA StyleChen, C., & Liu, L. (2025). Health Assessment of Rolling Bearings Based on Multivariate State Estimation and Reliability Analysis. Applied Sciences, 15(10), 5396. https://doi.org/10.3390/app15105396