
Modeling Semantic-Aware Prompt-Based Argument Extractor in Documents


Abstract
1. Introduction
- To address the challenges of long-distance dependencies, a document–sentence–entity heterogeneous graph is constructed and graph convolutional networks (GCNs) are employed to model global semantic associations. This approach effectively captures interactions between cross-sentence triggers and arguments, enabling the model to better handle information dispersed across different sentences and paragraphs.
- To tackle the challenges of event co-occurrence, a position-aware semantic role (SRL) attention mechanism is proposed. This mechanism strengthens the association between semantic and positional information, thereby improving the accuracy of argument extraction and allowing the model to more effectively handle the complex relationships between multiple events in a document.
- We conducted comprehensive evaluations of SPARE on two widely recognized benchmark datasets in the field of event argument extraction: RAMS and WikiEvents. The experimental outcome is that SPARE surpasses the latest baseline methods.
2. Related Work
2.1. Pre-Trained Language Models for Event Extraction
2.2. Event Type Recognition
2.3. Document-Level Event Argument Extraction
- (1)
- Traditional classification-based approaches: determining whether a candidate argument acts as an argument for a role by generating candidate arguments and making classification judgments for each role, e.g., Xu et al. [31] modeled chapter semantics using Abstract Semantic Representation Graphs (AMRs), and Liu et al. [32] used the STCP methodology to introduce role correlations to enhance accuracy. In addition, Tan et al. [33] incorporated knowledge distillation with association modeling to improve the capture of argument role dependencies in event structures, thereby enhancing overall model performance.
- (2)
- Span selection-based approaches: avoid the complexity of candidate generation by selecting the text span of an argument directly in the chapter. For example, Ma et al. [34] designed a hint template. This template generates two span selectors for individual characters, which are designed to capture the boundary positions of arguments. Nguyen et al. [35] extended the PAIE approach by introducing soft prompts to more flexibly utilize contextual information. Li et al. [36] went further by constructing a network of dependency-aware graphs within and between events to model the role dependencies in events. Zhang et al. [37] captured long-distance dependencies through a sparse attention mechanism, which effectively improved the extraction accuracy and efficiency. Zhang et al. [38] proposed a hyperspherical multi-prototype model with optimal transport to assign arguments to prototypes, guiding the learning of argument representations for event argument extraction.
- (3)
- Machine Reading Comprehension (MRC)-based approach: the task is converted to machine reading comprehension. Argument extraction is achieved by asking questions and identifying the answers in the text. For example, Wei et al. [39] enhanced the inference ability of the model by capturing the semantic relationships between arguments and arguments by using other arguments and their roles in the same event as clues.
- (4)
- Text generation-based approach: the task is formulated as text generation to realize event argument extraction. Du et al. [40] extended the generative model to capture the association semantics between multiple events. Ren et al. [41] incorporated retrieval enhancement techniques into the generative model for better generation of argument information, which provides diversified solution ideas for event argument extraction.
2.4. Joint Event Extraction
3. Approach
3.1. Task Definition
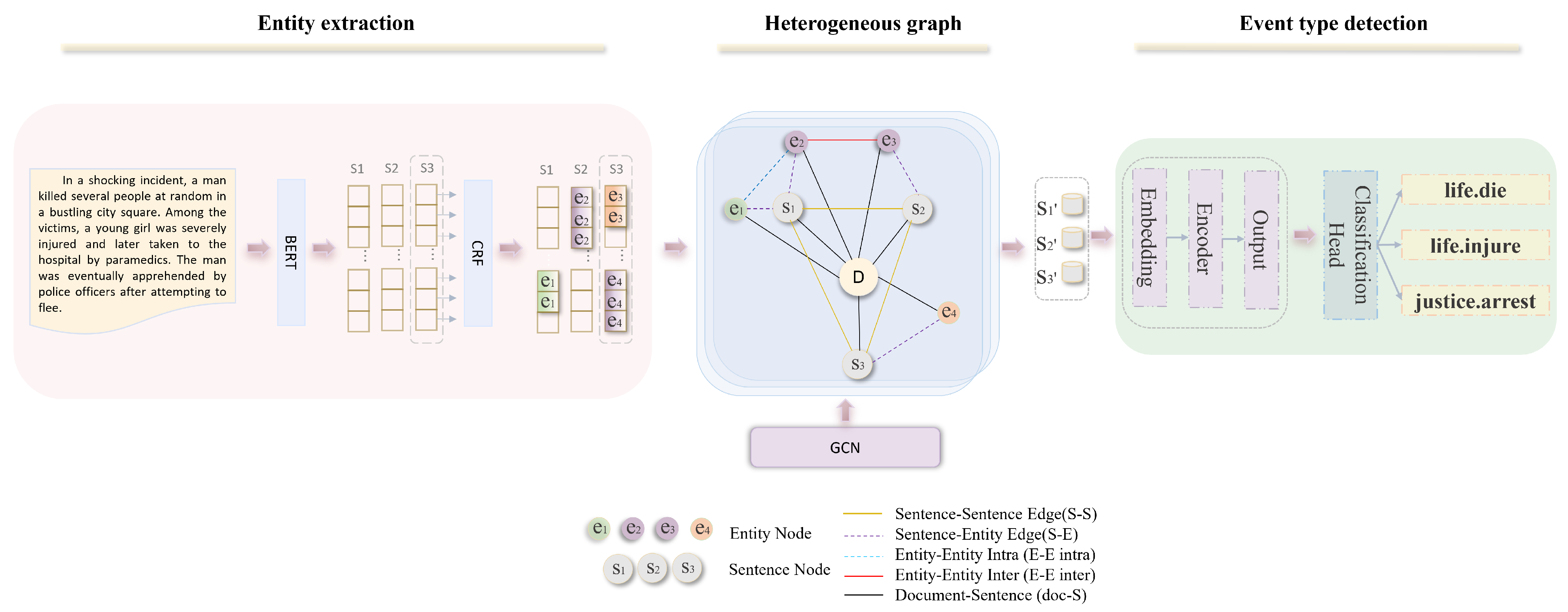
3.2. Model for Dynamic Recognition of Event Types Based on Graph Neural Networks
3.2.1. Entity Extraction
3.2.2. Heterogeneous Graph Construction
- (1)
- Sentence–sentence edges (S-S): These edges connect sentence nodes to model long-distance dependencies between sentences in a document.
- (2)
- Sentence–entity edges (S-E): These edges link sentences to all entities mentioned within them, capturing the contextual information of entities in the sentence.
- (3)
- Intra-sentence entity–entity edges (E-E intra): These edges connect different entities within the same sentence, indicating potential relationships between entities related to the same event.
- (4)
- Inter-sentence entity–entity edges (E-E inter): These edges link occurrences of the same entity across multiple sentences, facilitating the tracking and continuity of entities throughout the document.
- (5)
- Document–sentence edges (doc-S): These edges connect document nodes to sentence nodes, facilitating interactions between documents and sentences.
3.2.3. Event Type Detection
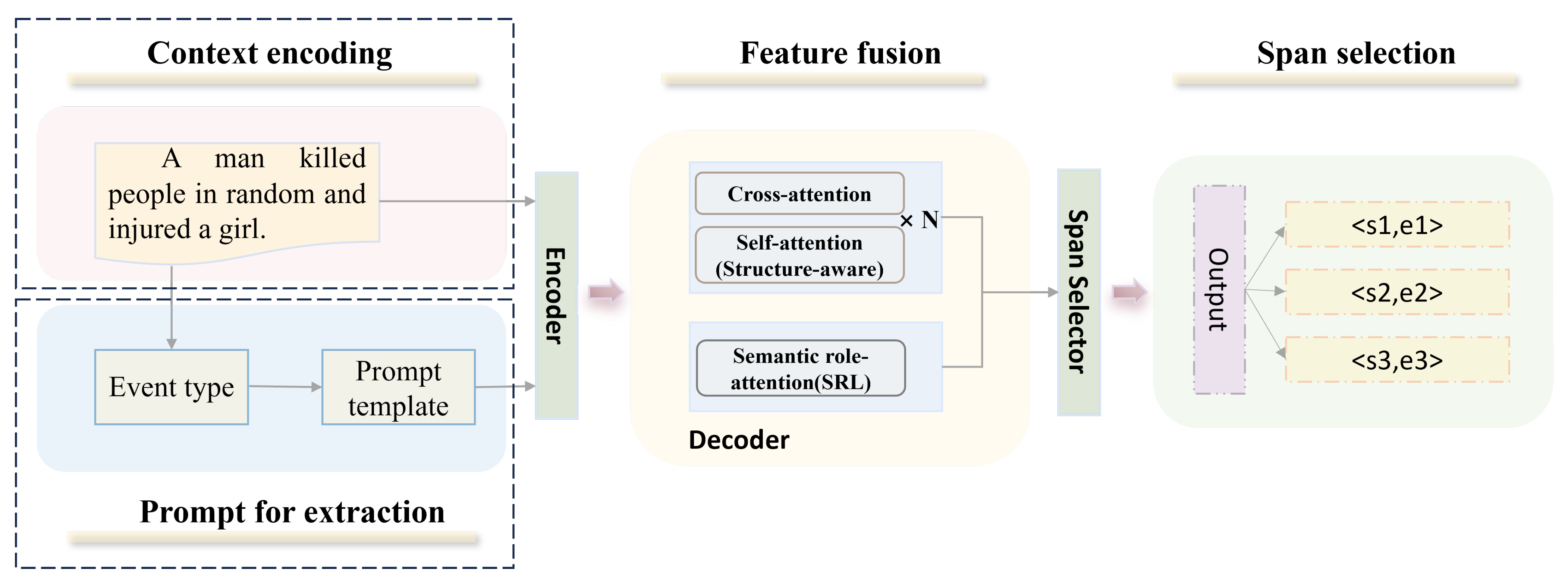
3.3. Event Argument Extraction Model Based on Table Generation
3.3.1. Context Encoding
3.3.2. Prompt for Extraction
3.3.3. Feature Fusion
3.3.4. Span Selection
4. Experiment
4.1. Datasets and Evaluation Metrics
- (1)
- Strict Argument Identification F1 (Arg-I): A predicted event argument is regarded as valid if its range coincides precisely with the limits of any reference argument in the event.
- (2)
- Strict Argument Classification F1 (Arg-C): A predicted event argument is validated as correct solely when its range and designated role category align with those of the reference argument.
4.2. Experimental Parameterization
4.3. Baseline Comparison
- (a)
- BART-Gen [48]: a generation-based approach that relies on input text and templates.
- (b)
- PAIE [34]: a model for efficiently extracting sentence-level and document-level event parameters using pre-trained language models by facilitating inter-parameter interactions through prompt learning.
- (c)
- TSRA [31]: a method that utilizes dual-stream encoding and AMR semantic enhancement maps for extracting arguments.
- (d)
- TARA [50]: by constructing customized AMR graphs and using graph neural networks as link prediction models.
- (e)
- TabEAE [51]: extends prompt-based EAE modeling to a non-autoregressive generative framework to extract arguments from multiple events in parallel.
4.4. Main Results
4.5. Sensitivity Analysis
- Learning Rate (Adam): 5 × 10−5, 3 × 10−5, 2 × 10−5
- Batch Size: 4, 8
- Number of Epochs: 2, 3, 4
- Dropout Rate: 0.05, 0.1, 0.2
4.6. Ablation Experiments
5. Analysis
5.1. Comparative Analysis of BERT and GPT Performance on D-EAE Tasks
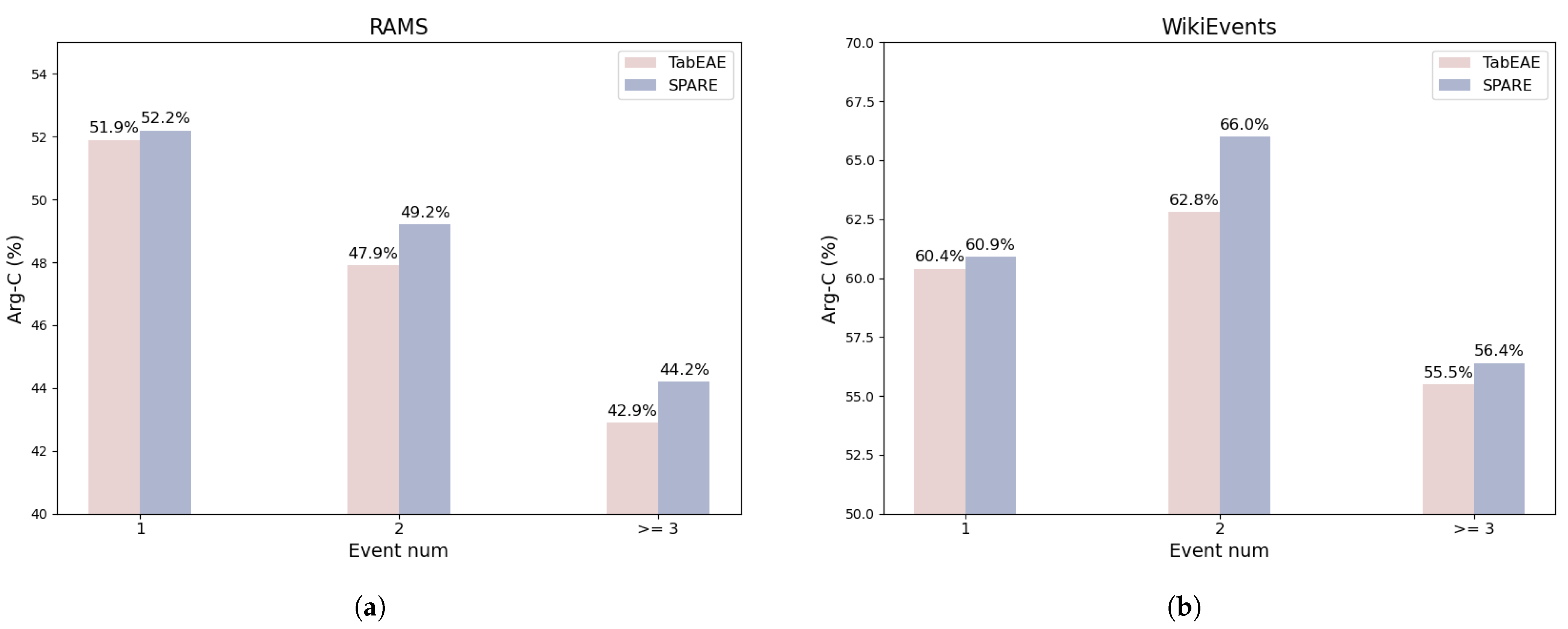
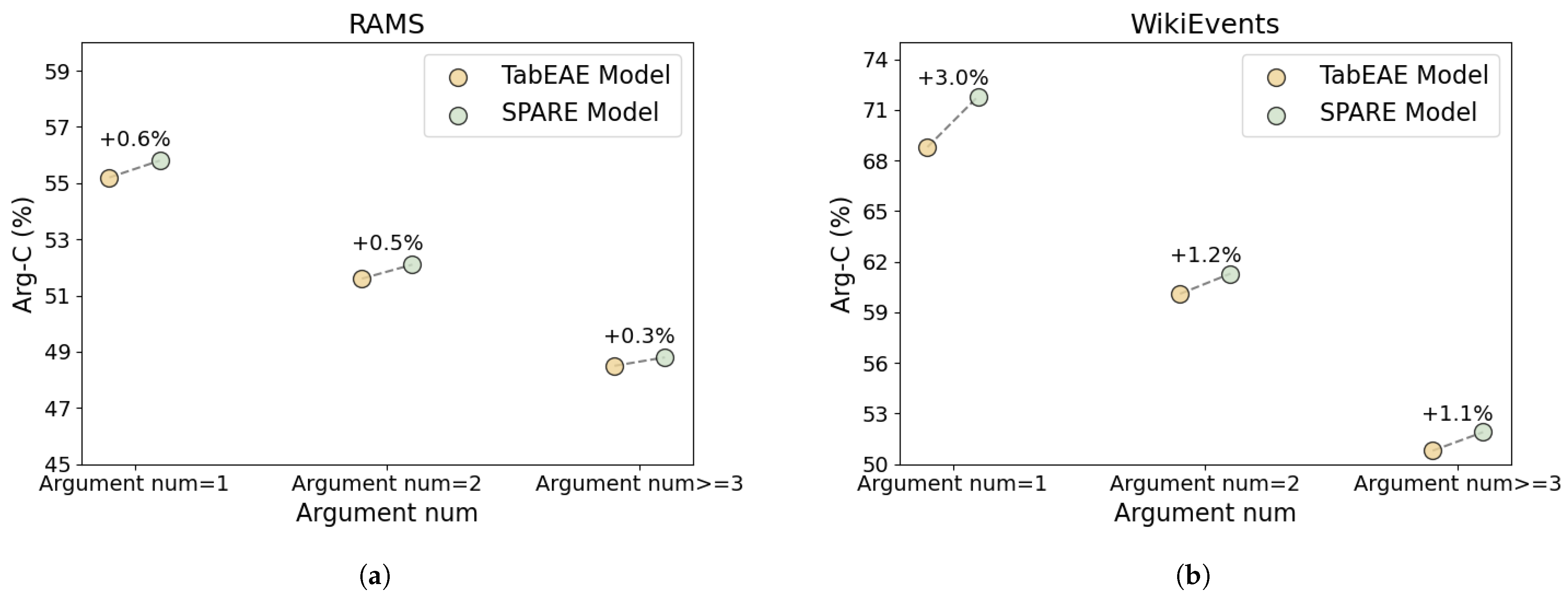
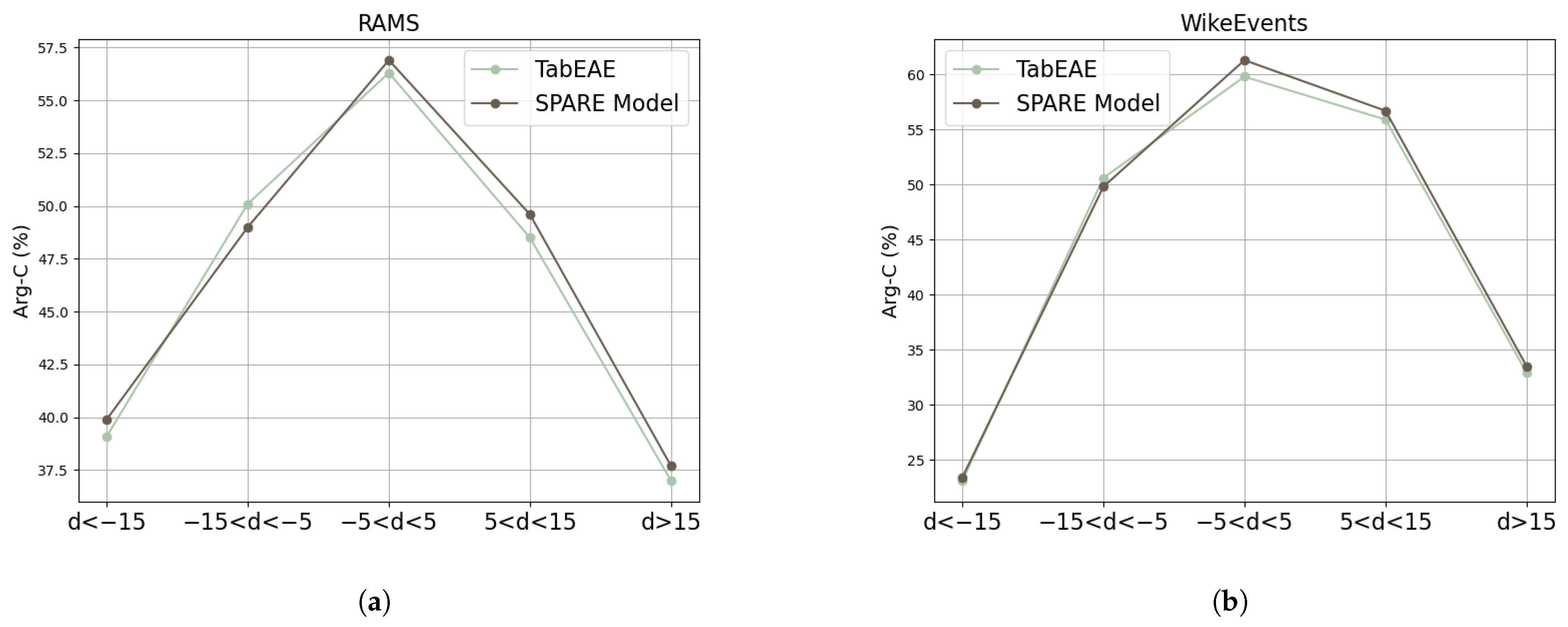
5.2. Cross-Event Correlation Analysis
5.3. Model Semantic Capture Capability: Inter-Event Correlation
5.4. Model Semantic Capture Capability: Intra-Event Correlation
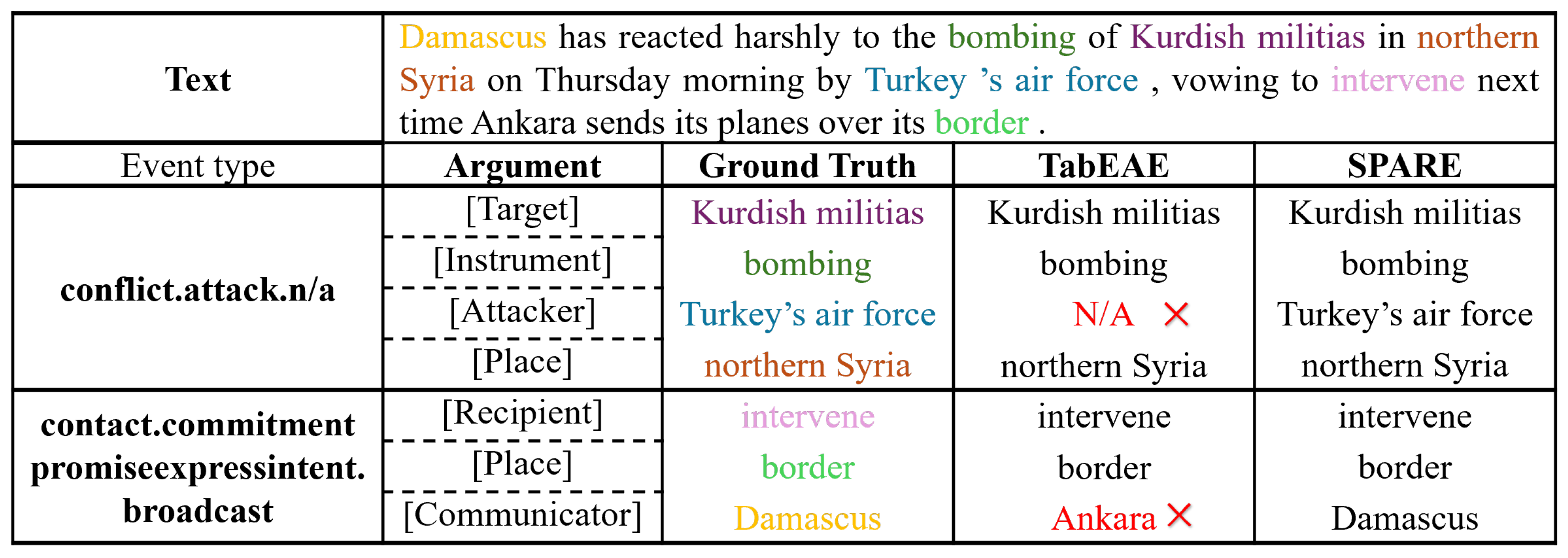
6. Case Studies
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xiang, W.; Wang, B. A Survey of Event Extraction From Text. IEEE Access 2019, 7, 173111–173137. [Google Scholar] [CrossRef]
- Saxena, A. A Survey of Session-Based Recommender Systems. In Proceedings of the 2023 5th International Conference on Advances in Computing, Communication Control and Networking (ICAC3N), Greater Noida, India, 15–16 December 2023; pp. 47–50. [Google Scholar] [CrossRef]
- Jia, R.; Zhang, Z.; Jia, Y.; Papadopoulou, M.; Roche, C. Improved GPT2 Event Extraction Method Based on Mixed Attention Collaborative Layer Vector. IEEE Access 2024, 12, 160074–160082. [Google Scholar] [CrossRef]
- Zheng, S.; Cao, W.; Xu, W.; Bian, J. Doc2EDAG: An End-to-End Document-level Framework for Chinese Financial Event Extraction. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 337–346. [Google Scholar] [CrossRef]
- Zhou, Y.; Chen, Y.; Zhao, J.; Wu, Y.; Xu, J.; Li, J. What the Role is vs. What Plays the Role: Semi-Supervised Event Argument Extraction via Dual Question Answering. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI, Virtual Event, 2–9 February 2021; pp. 14638–14646. [Google Scholar] [CrossRef]
- Wang, J.; Jatowt, A.; Färber, M.; Yoshikawa, M. Improving question answering for event-focused questions in temporal collections of news articles. Inf. Retr. J. 2021, 24, 29–54. [Google Scholar] [CrossRef]
- Hong, Z.; Liu, J. Towards Better Question Generation in QA-based Event Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 9025–9038. [Google Scholar] [CrossRef]
- Jin, Y.; Jiang, W.; Yang, Y.; Mu, Y. Zero-Shot Video Event Detection With High-Order Semantic Concept Discovery and Matching. IEEE Trans. Multimed. 2022, 24, 1896–1908. [Google Scholar] [CrossRef]
- Li, P.; Zhou, G. Joint Argument Inference in Chinese Event Extraction with Argument Consistency and Event Relevance. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 612–622. [Google Scholar] [CrossRef]
- You, T.; Li, Z.; Fan, Z.; Yin, C.; He, Y.; Cai, J.; Fu, J.; Wei, Z. An Iterative Framework for Document-Level Event Argument Extraction Assisted by Long Short-Term Memory. In Proceedings of the Natural Language Processing and Chinese Computing, Hangzhou, China, 1–3 November 2024. [Google Scholar]
- Chen, J.; Long, K.; Li, S.; Tang, J.; Wang, T. FineCSDA: Boosting Document-Level Event Argument Extraction with Fine-Grained Data Augmentation. In Proceedings of the Natural Language Processing and Chinese Computing—13th National CCF Conference, NLPCC 2024, Proceedings, Part II, Hangzhou, China, 1–3 November 2024; Wong, D.F., Wei, Z., Yang, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2024; Volume 15360, pp. 3–15. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://api.semanticscholar.org/CorpusID:49313245 (accessed on 8 March 2025).
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Shi, G.; Su, Y.; Ma, Y.; Zhou, M. A Hybrid Detection and Generation Framework with Separate Encoders for Event Extraction. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, Dubrovnik, Croatia, 2–4 May 2023; Vlachos, A., Augenstein, I., Eds.; 2023; pp. 3163–3180. [Google Scholar] [CrossRef]
- Wan, Q.; Wan, C.; Xiao, K.; Liu, D.; Li, C.; Zheng, B.; Liu, X.; Hu, R. Joint Document-Level Event Extraction via Token-Token Bidirectional Event Completed Graph. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; pp. 10481–10492. [Google Scholar] [CrossRef]
- Gao, J.; Zhao, H.; Yu, C.; Xu, R. Exploring the Feasibility of ChatGPT for Event Extraction. arXiv 2023, arXiv:2303.03836. [Google Scholar]
- Wei, X.; Cui, X.; Cheng, N.; Wang, X.; Zhang, X.; Huang, S.; Xie, P.; Xu, J.; Chen, Y.; Zhang, M.; et al. Zero-Shot Information Extraction Via Chatting with ChatGPT. arXiv 2023, arXiv:2302.10205. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Red Hook, NY, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. arXiv 2004, arXiv:2004.05150. [Google Scholar]
- Zaheer, M.; Guruganesh, G.; Dubey, A.; Ainslie, J.; Alberti, C.; Ontanon, S.; Pham, P.; Ravula, A.; Wang, Q.; Yang, L.; et al. Big bird: Transformers for longer sequences. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NIPS ’20), Red Hook, NY, USA, 6–12 December 2020. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–61. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. PaLM: Scaling Language Modeling with Pathways. J. Mach. Learn. Res. 2023, 24, 1–113. [Google Scholar]
- Huang, L.; Cassidy, T.; Feng, X.; Ji, H.; Voss, C.R.; Han, J.; Sil, A. Liberal Event Extraction and Event Schema Induction. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 258–268. [Google Scholar] [CrossRef]
- Chambers, N. Event Schema Induction with a Probabilistic Entity-Driven Model. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, DC, USA, 18–21 October 2013; pp. 1797–1807. [Google Scholar]
- Cheung, J.C.K.; Poon, H.; Vanderwende, L. Probabilistic Frame Induction. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 837–846. [Google Scholar]
- Shen, J.; Zhang, Y.; Ji, H.; Han, J. Corpus-based Open-Domain Event Type Induction. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 5427–5440. [Google Scholar] [CrossRef]
- Huang, L.; Ji, H. Semi-supervised New Event Type Induction and Event Detection. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 718–724. [Google Scholar] [CrossRef]
- Li, S.; Ji, H.; Han, J. Open Relation and Event Type Discovery with Type Abstraction. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 6864–6877. [Google Scholar] [CrossRef]
- Tang, J.; Lin, H.; Li, Z.; Lu, Y.; Han, X.; Sun, L. Harvesting Event Schemas from Large Language Models. arXiv 2023, arXiv:2305.07280. [Google Scholar]
- Xu, R.; Wang, P.; Liu, T.; Zeng, S.; Chang, B.; Sui, Z. A Two-Stream AMR-enhanced Model for Document-level Event Argument Extraction. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, DC, USA, 10–15 July 2022; pp. 5025–5036. [Google Scholar] [CrossRef]
- Liu, W.; Cheng, S.; Zeng, D.; Hong, Q. Enhancing Document-level Event Argument Extraction with Contextual Clues and Role Relevance. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 12908–12922. [Google Scholar] [CrossRef]
- Tan, L.; Hu, Y.; Cao, J.; Tan, Z. AssocKD: An Association-Aware Knowledge Distillation Method for Document-Level Event Argument Extraction. Mathematics 2024, 12, 2901. [Google Scholar] [CrossRef]
- Ma, Y.; Wang, Z.; Cao, Y.; Li, M.; Chen, M.; Wang, K.; Shao, J. Prompt for Extraction? PAIE: Prompting Argument Interaction for Event Argument Extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 6759–6774. [Google Scholar] [CrossRef]
- Nguyen, C.; Man, H.; Nguyen, T. Contextualized Soft Prompts for Extraction of Event Arguments. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 4352–4361. [Google Scholar] [CrossRef]
- Li, H.; Cao, Y.; Ren, Y.; Fang, F.; Zhang, L.; Li, Y.; Wang, S. Intra-Event and Inter-Event Dependency-Aware Graph Network for Event Argument Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; pp. 6362–6372. [Google Scholar] [CrossRef]
- Zhang, M.; Chen, H. Document-Level Event Argument Extraction with Sparse Representation Attention. Mathematics 2024, 12, 2636. [Google Scholar] [CrossRef]
- Zhang, G.; Zhang, H.; Wang, Y.; Li, R.; Tan, H.; Liang, J. Hyperspherical Multi-Prototype with Optimal Transport for Event Argument Extraction. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 11–16 August 2024; pp. 9271–9284. [Google Scholar] [CrossRef]
- Wei, K.; Sun, X.; Zhang, Z.; Zhang, J.; Zhi, G.; Jin, L. Trigger is Not Sufficient: Exploiting Frame-aware Knowledge for Implicit Event Argument Extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 4672–4682. [Google Scholar] [CrossRef]
- Du, X.; Li, S.; Ji, H. Dynamic Global Memory for Document-level Argument Extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 5264–5275. [Google Scholar] [CrossRef]
- Ren, Y.; Cao, Y.; Guo, P.; Fang, F.; Ma, W.; Lin, Z. Retrieve-and-Sample: Document-level Event Argument Extraction via Hybrid Retrieval Augmentation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; pp. 293–306. [Google Scholar] [CrossRef]
- Wang, X.; Jia, S.; Han, X.; Liu, Z.; Li, J.; Li, P.; Zhou, J. Neural Gibbs Sampling for Joint Event Argument Extraction. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, Suzhou, China, 4–7 December 2020; pp. 169–180. [Google Scholar] [CrossRef]
- Sheng, J.; Guo, S.; Yu, B.; Li, Q.; Hei, Y.; Wang, L.; Liu, T.; Xu, H. CasEE: A Joint Learning Framework with Cascade Decoding for Overlapping Event Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 164–174. [Google Scholar] [CrossRef]
- Xu, R.; Liu, T.; Li, L.; Chang, B. Document-level Event Extraction via Heterogeneous Graph-based Interaction Model with a Tracker. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 3533–3546. [Google Scholar] [CrossRef]
- Wan, Q.; Wan, C.; Xiao, K.; Xiong, H.; Liu, D.; Liu, X.; Hu, R. Token-Event-Role Structure-Based Multi-Channel Document-Level Event Extraction. ACM Trans. Inf. Syst. 2024, 42, 1–27. [Google Scholar] [CrossRef]
- Forney, G. The viterbi algorithm. Proc. IEEE 1973, 61, 268–278. [Google Scholar] [CrossRef]
- Ebner, S.; Xia, P.; Culkin, R.; Rawlins, K.; Van Durme, B. Multi-Sentence Argument Linking. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8057–8077. [Google Scholar] [CrossRef]
- Li, S.; Ji, H.; Han, J. Document-Level Event Argument Extraction by Conditional Generation. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 894–908. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Yang, Y.; Guo, Q.; Hu, X.; Zhang, Y.; Qiu, X.; Zhang, Z. An AMR-based Link Prediction Approach for Document-level Event Argument Extraction. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; pp. 12876–12889. [Google Scholar] [CrossRef]
- He, Y.; Hu, J.; Tang, B. Revisiting Event Argument Extraction: Can EAE Models Learn Better When Being Aware of Event Co-occurrences? In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; pp. 2542–12556. [Google Scholar] [CrossRef]
- Shuang, K.; Zhouji, Z.; Wang,, Q.; Guo, J. Energizing LLMs’ Emergence Capabilities for Document-Level Event Argument Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 5520–5532. [Google Scholar]
- Liu, W.; Zhou, L.; Zeng, D.; Xiao, Y.; Cheng, S.; Zhang, C.; Lee, G.; Zhang, M.; Chen, W. Beyond Single-Event Extraction: Towards Efficient Document-Level Multi-Event Argument Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 9470–9487. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | RAMS | WikiEvents | ||
|---|---|---|---|---|
| Event types | 139 | 50 | ||
| Args per event | 2.33 | 1.40 | ||
| Events per text | 1.25 | 1.78 | ||
| Roles | 65 | 80 | ||
| Split | #Doc | #Event | #Doc | #Event |
| Train | 3194 | 7329 | 206 | 3241 |
| Dev | 399 | 924 | 20 | 345 |
| Test | 400 | 871 | 20 | 365 |
| Parameters | Values |
|---|---|
| Training Steps | 10,000 |
| Warmup Ratio | 0.1 |
| Learning Rate | 2 × 10−5 |
| Dropout Rate | 0.1 |
| Epoch | 2 |
| Batch size | 4 |
| Context Window Size | 250 |
| Max Span Length | 10 |
| Model | RAMS | WikiEvents | ||
|---|---|---|---|---|
| Arg-I | Arg-C | Arg-I | Arg-C | |
| BART-Gen | 48.64 | 51.2 | 67.62 | 61.17 |
| PAIE | 53.2 | 48.0 | 69.3 | 63.4 |
| TSRA | 53.01 | 48.06 | 67.52 | 60.11 |
| TARA | 52.34 | 48.06 | 68.76 | 62.18 |
| TabEAE | 56.4 | 51.5 | 70.0 | 65.6 |
| SPARE | 57.3 | 52.9 | 73.8 | 69.1 |
| Gain over TabEAE | +0.9 | +1.4 | +3.8 | +3.5 |
| Model | RAMS | WikiEvents | ||
|---|---|---|---|---|
| Arg-I | Arg-C | Arg-I | Arg-C | |
| w/o Event type | 56.5 | 52.2 | 73.1 | 68.5 |
| w/o SRL Attention | 56.1 | 51.6 | 72.3 | 67.7 |
| w/o Prompts | 55.8 | 51.3 | 72.0 | 67.4 |
| w/o PET | 54.1 | 49.1 | 69.8 | 64.9 |
| SPARE | 57.3 | 52.9 | 73.8 | 69.1 |
| Method | RAMS | |
|---|---|---|
| Arg-I | Arg-C | |
| GPT3.5 | 46.2 | 40.4 |
| GPT4 | 50.4 | 42.8 |
| SPARE | 57.3 | 52.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Fan, J.; Zhang, Q.; Zhu, L.; Sun, X. Modeling Semantic-Aware Prompt-Based Argument Extractor in Documents. Appl. Sci. 2025, 15, 5279. https://doi.org/10.3390/app15105279
Zhou Y, Fan J, Zhang Q, Zhu L, Sun X. Modeling Semantic-Aware Prompt-Based Argument Extractor in Documents. Applied Sciences. 2025; 15(10):5279. https://doi.org/10.3390/app15105279
Chicago/Turabian StyleZhou, Yipeng, Jiaxin Fan, Qingchuan Zhang, Lin Zhu, and Xingchen Sun. 2025. "Modeling Semantic-Aware Prompt-Based Argument Extractor in Documents" Applied Sciences 15, no. 10: 5279. https://doi.org/10.3390/app15105279
APA StyleZhou, Y., Fan, J., Zhang, Q., Zhu, L., & Sun, X. (2025). Modeling Semantic-Aware Prompt-Based Argument Extractor in Documents. Applied Sciences, 15(10), 5279. https://doi.org/10.3390/app15105279