
Deep Watermarking Based on Swin Transformer for Deep Model Protection


Abstract
1. Introduction
2. Literature Review
3. Materials and Methods
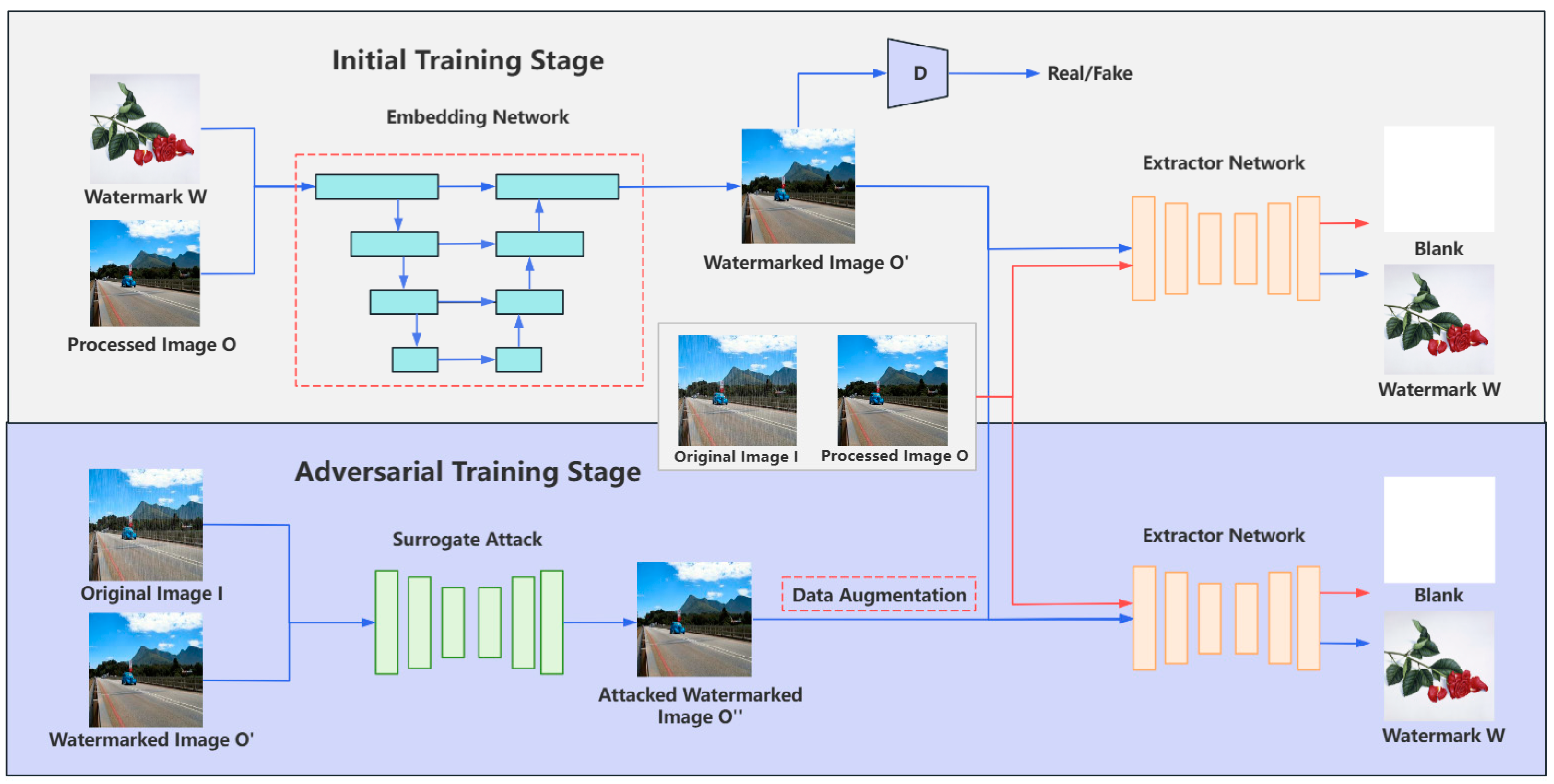
3.1. Overall Organizational Structure
- Embedding Network Upgrade by Replacing UNet with Swin-UNet
- 2.
- Data Augmentation to Enhance Robustness Against Surrogate Attacks
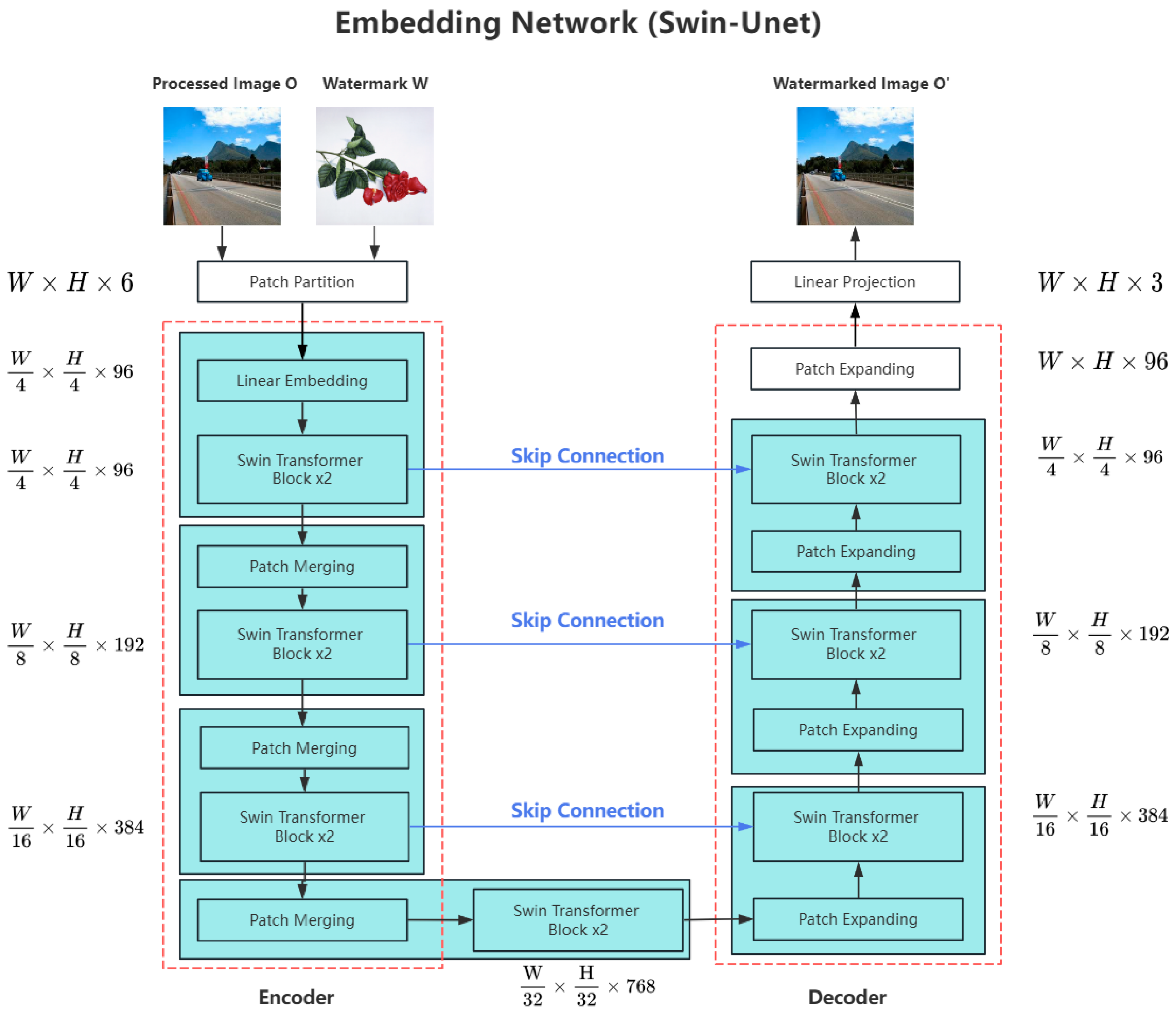
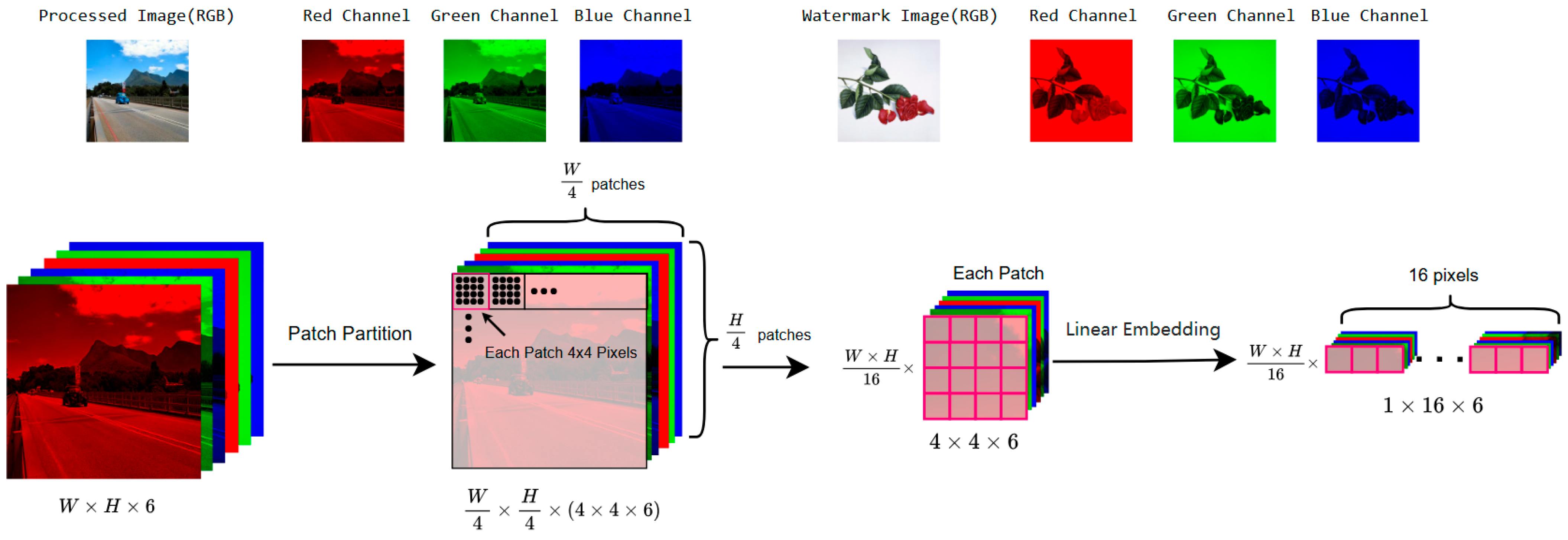
3.2. Embedding Network Based on Swin-Unet
3.3. Data Augmentation for Adversarial Training Stage
4. Results
4.1. Implementation Details
4.2. Visual Quality of Watermarked Image and Extracted Watermark
4.3. Robustness Against Surrogate Attacks
4.4. Comparison with Existing Works
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 26th International Conference on Neural Information Processing Systems-Volume 1, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Parisi, L.; Neagu, D.; Ma, R.; Campean, F. QReLU and m-QReLU: Two novel quantum activation functions to aid medical diagnostics. arXiv 2020, arXiv:2010.08031. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Rush, A.M. Huggingface’s transformers: State-of-the-art natural language processing. arXiv 2019, arXiv:1910.03771. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 506–519. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (sp), San Jose, CA, USA, 22–24 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 39–57. [Google Scholar]
- Uchida, Y.; Nagai, Y.; Sakazawa, S.; Satoh, S. Embedding watermarks into deep neural networks. In Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval, Bucharest, Romania, 6–9 June 2017; pp. 269–277. [Google Scholar]
- Adi, Y.; Baum, C.; Cisse, M.; Pinkas, B.; Keshet, J. Turning Your Weakness Into a Strength: Watermarking Deep Neural Networks by Backdooring. arXiv 2018. [Google Scholar] [CrossRef]
- Dekel, T.; Rubinstein, M.; Liu, C.; Freeman, W.T. On the Effectiveness of Visible Watermarks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6864–6872. [Google Scholar] [CrossRef]
- Choi, K.-C.; Pun, C.-M. Difference Expansion Based Robust Reversible Watermarking with Region Filtering. In Proceedings of the 2016 13th International Conference on Computer Graphics, Imaging and Visualization (CGiV), Beni Mellal, Morocco, 29 March–1 April 2016; pp. 278–282. [Google Scholar] [CrossRef]
- Liu, Y. Multilingual denoising pre-training for neural machine translation. arXiv 2020, arXiv:2001.08210. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision And Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Alomoush, W.; Khashan, O.A.; Alrosan, A.; Attar, H.H.; Almomani, A.; Alhosban, F.; Makhadmeh, S.N. Digital image watermarking using discrete cosine transformation based linear modulation. J. Cloud Comput. 2023, 12, 96. [Google Scholar] [CrossRef]
- Islam, S.M.M.; Debnath, R.; Hossain, S.K.A. DWT Based Digital Watermarking Technique and its Robustness on Image Rotation, Scaling, JPEG compression, Cropping and Multiple Watermarking. In Proceedings of the 2007 International Conference on Information and Communication Technology, Dhaka, Bangladesh, 7–9 March 2007; pp. 246–249. [Google Scholar] [CrossRef]
- Kandi, H.; Mishra, D.; Gorthi, S.R.S. Exploring the Learning Capabilities of Convolutional Neural Networks for Robust Image Watermarking. Comput. Secur. 2017, 65, 247–268. [Google Scholar] [CrossRef]
- Vukotic, V.; Chappelier, V.; Furon, T. Are Deep Neural Networks good for blind image watermarking? In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Singapore, 11–13 December 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Quan, Y.; Teng, H.; Chen, Y.; Ji, H. Watermarking Deep Neural Networks in Image Processing. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 1852–1865. [Google Scholar] [CrossRef] [PubMed]
- Jing, J.; Deng, X.; Xu, M.; Wang, J.; Guan, Z. HiNet: Deep Image Hiding by Invertible Network. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 4713–4722. [Google Scholar] [CrossRef]
- Guan, Z.; Jing, J.; Deng, X.; Xu, M.; Jiang, L.; Zhang, Z.; Li, Y. DeepMIH: Deep Invertible Network for Multiple Image Hiding. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 372–390. [Google Scholar] [CrossRef] [PubMed]
- Tancik, M.; Mildenhall, B.; Ng, R. Stegastamp: Invisible hyperlinks in physical photographs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2117–2126. [Google Scholar]
- Wu, H.; Liu, G.; Yao, Y.; Zhang, X. Watermarking Neural Networks With Watermarked Images. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 2591–2601. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, D.; Liao, J.; Zhang, W.; Feng, H.; Hua, G.; Yu, N. Deep model intellectual property protection via deep watermarking. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4005–4020. [Google Scholar] [CrossRef]
- Jain, N.; Joshi, A.; Earles, M. iNatAg: Multi-Class Classification Models Enabled by a Large-Scale Benchmark Dataset with 4.7 M Images of 2959 Crop and Weed Species. arXiv 2025, arXiv:2503.20068. [Google Scholar]
- Yang, R.; Zhang, S. Enhancing Retinal Vascular Structure Segmentation in Images with a Novel Design Two-Path Interactive Fusion Module Model. arXiv 2024, arXiv:2403.01362. [Google Scholar]
- Tian, Y.; Han, J.; Chen, H.; Xi, Y.; Ding, N.; Hu, J. Instruct-ipt: All-in-one image processing transformer via weight modulation. arXiv 2024, arXiv:2407.00676. [Google Scholar]
- Ju, R.-Y.; Chen, C.-C.; Chiang, J.-S.; Lin, Y.-S.; Chen, W.-H. Resolution enhancement processing on low quality images using swin transformer based on interval dense connection strategy. Multimed. Tools Appl. 2024, 83, 14839–14855. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, H.; Patel, V.M. Density-aware single image de-raining using a multi-stream dense network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 695–704. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 1833–1844. [Google Scholar]
- Zhu, J. HiDDeN: Hiding data with deep networks. arXiv 2018, arXiv:1807.09937. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect | CNN | Swin Transformer |
|---|---|---|
| Receptive Field | Local; gradually expanded via layer stacking | Global modeling via self-attention with shifted windows |
| Attention | Optional and limited in scope | Integrated multi-head self-attention with hierarchical design |
| Feature Interaction | Primarily local due to convolutional operations | Enables long-range dependencies through window shifting |
| Downsampling | May result in irreversible information loss | Preserves contextual information via attention mechanisms |
| Computational Cost | Lower per layer; deep networks needed for context | Higher per layer; optimized by window-based computation |
| Data Augmentation | Parameters | Usage Probabilities |
|---|---|---|
| Color jitter | Max. adjustment: 20% | 100% |
| Gaussian noise | Mean: 0; Std: 0.01 | 50% |
| Random masking | Masked area: 5% | 30% |
| JPEG compression | Quality: 70 | 30% |
| Gaussian blur | Kernel size: 3; Sigma range: 0.1 to 1.0 | 50% |
| Task | Watermark | PSNR | SSIM | NC | ||
|---|---|---|---|---|---|---|
| Derain [32] | Flower | Zhang [25] | 41.21 | 0.99 | 0.9999 | 100%/100% |
| Ours | 46.17 ± 3.55 | 0.99 | 0.9999 | 100%/100% | ||
| Lena | Zhang [25] | 42.50 | 0.98 | 0.9999 | 100%/100% | |
| Ours | 47.38 ± 3.49 | 0.99 | 0.9999 | 100%/100% | ||
| Peppers | Zhang [25] | 40.91 | 0.98 | 0.9999 | 100%/100% | |
| Ours | 45.35 ± 3.33 | 0.99 | 0.9999 | 100%/100% | ||
| QR | Zhang [25] | 40.24 | 0.98 | 0.9999 | 100%/100% | |
| Ours | 44.42 ± 3.81 | 0.99 | 0.9999 | 100%/100% | ||
| IEEE | Zhang [25] | 41.76 | 0.98 | 0.9999 | 100%/100% | |
| Ours | 46.28 ± 3.68 | 0.99 | 0.9999 | 100%/100% | ||
| Denoise [33] | Flower | Zhang [25] | 38.90 | 0.98 | 0.9999 | 100%/100% |
| Ours | 57.52 ± 2.93 | 0.99 | 0.9999 | 100%/100% | ||
| Lena | Zhang [25] | 39.19 | 0.98 | 0.9999 | 100%/100% | |
| Ours | 59.66 ± 2.82 | 0.99 | 0.9999 | 100%/100% | ||
| Peppers | Zhang [25] | 38.70 | 0.98 | 0.9999 | 100%/100% | |
| Ours | 56.39 ± 2.73 | 0.99 | 0.9999 | 100%/100% | ||
| QR | Zhang [25] | 38.91 | 0.98 | 0.9999 | 100%/100% | |
| Ours | 53.73 ± 3.19 | 0.99 | 0.9999 | 100%/100% | ||
| IEEE | Zhang [25] | 40.12 | 0.99 | 0.9999 | 100%/100% | |
| Ours | 57.50 ± 3.22 | 0.99 | 0.9999 | 100%/100% | ||
| Task | Task | CNet | Res9 | Res16 | UNet | L2 + Ladv | L1 | L1 + Ladv | Lperc + Ladv |
|---|---|---|---|---|---|---|---|---|---|
| Derain [32] | Zhang [25] | 100%/100% | 100%/100% | 100%/100% | 100%/100% | 99%/100% | 100%/100% | 100%/100% | 100%/100% |
| Ours† | 100%/100% | 100%/100% | 100%/100% | 99%/100% | 93%/100% | 100%/100% | 100%/100% | 100%/100% | |
| Ours | 100%/100% | 100%/100% | 100%/100% | 100%/100% | 99%/100% | 100%/100% | 100%/100% | 100%/100% | |
| Denoise [33] | Zhang [25] | 99%/100% | 100%/100% | 99%/100% | 100%/100% | 97%/100% | 100%/100% | 97%/100% | 99%/100% |
| Ours† | 100%/100% | 100%/100% | 100%/100% | 100%/100% | 99%/100% | 100%/100% | 100%/100% | 100%/100% | |
| Ours | 100%/100% | 100%/100% | 100%/100% | 100%/100% | 100%/100% | 100%/100% | 100%/100% | 100%/100% |
| Method | PSNR | SSIM | NC | CNet | Res9 | Res16 | UNet |
|---|---|---|---|---|---|---|---|
| HiNet [21] | 21.71 | 0.4562 | 0.9999 | 0% | 0% | 0% | 0% |
| HiDDeN [34] | 39.19 | 0.97 | 0.7182 | 0% | 0% | 0% | 0% |
| HiDDeN† [34] | 37.81 | 0.96 | 0.9109 | 0% | 0% | 0% | 0% |
| Zhang [25] | 39.74 | 0.99 | 0.9999 | 99% | 99% | 100% | 99% |
| Ours | 53.23 | 0.99 | 0.9999 | 100% | 100% | 100% | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Un, C.-H.; Choi, K.-C. Deep Watermarking Based on Swin Transformer for Deep Model Protection. Appl. Sci. 2025, 15, 5250. https://doi.org/10.3390/app15105250
Un C-H, Choi K-C. Deep Watermarking Based on Swin Transformer for Deep Model Protection. Applied Sciences. 2025; 15(10):5250. https://doi.org/10.3390/app15105250
Chicago/Turabian StyleUn, Cheng-Hin, and Ka-Cheng Choi. 2025. "Deep Watermarking Based on Swin Transformer for Deep Model Protection" Applied Sciences 15, no. 10: 5250. https://doi.org/10.3390/app15105250
APA StyleUn, C.-H., & Choi, K.-C. (2025). Deep Watermarking Based on Swin Transformer for Deep Model Protection. Applied Sciences, 15(10), 5250. https://doi.org/10.3390/app15105250