
Rotation-Invariant Feature Enhancement with Dual-Aspect Loss for Arbitrary-Oriented Object Detection in Remote Sensing

Abstract
1. Introduction
- •
- A rotation-invariant module and a rotated feature fusion module are proposed to enhance the adaptability of FCOS to detect rotated objects, which can better counter the interference of complex backgrounds on foreground objects.
- •
- The dual-aspect RIoU loss function is introduced to improve detection performance by integrating both rotational and horizontal information, addressing the complexities introduced by arbitrary orientations.
- •
2. Related Works
2.1. Anchor-Free Methods for Remote Sensing
2.2. Rotation-Invariant Learning
2.3. Loss Functions for Bounding Box Regression
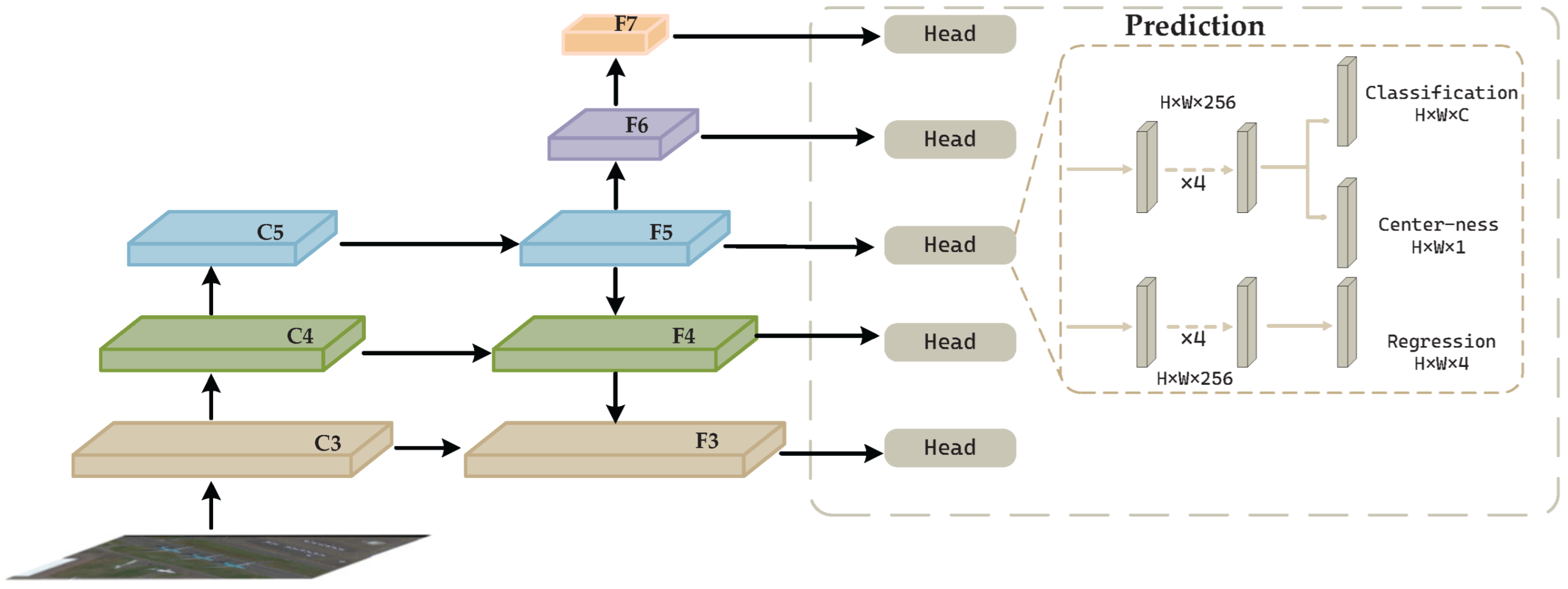
3. Rotational Feature Enhancement FCOS
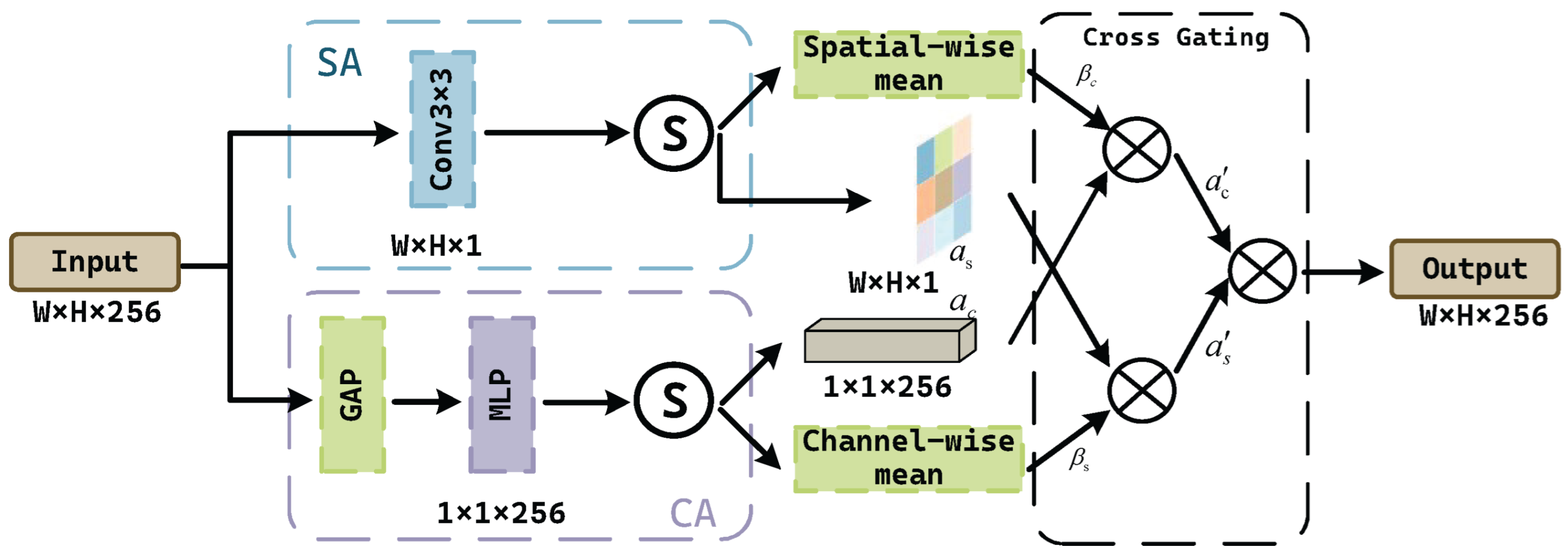
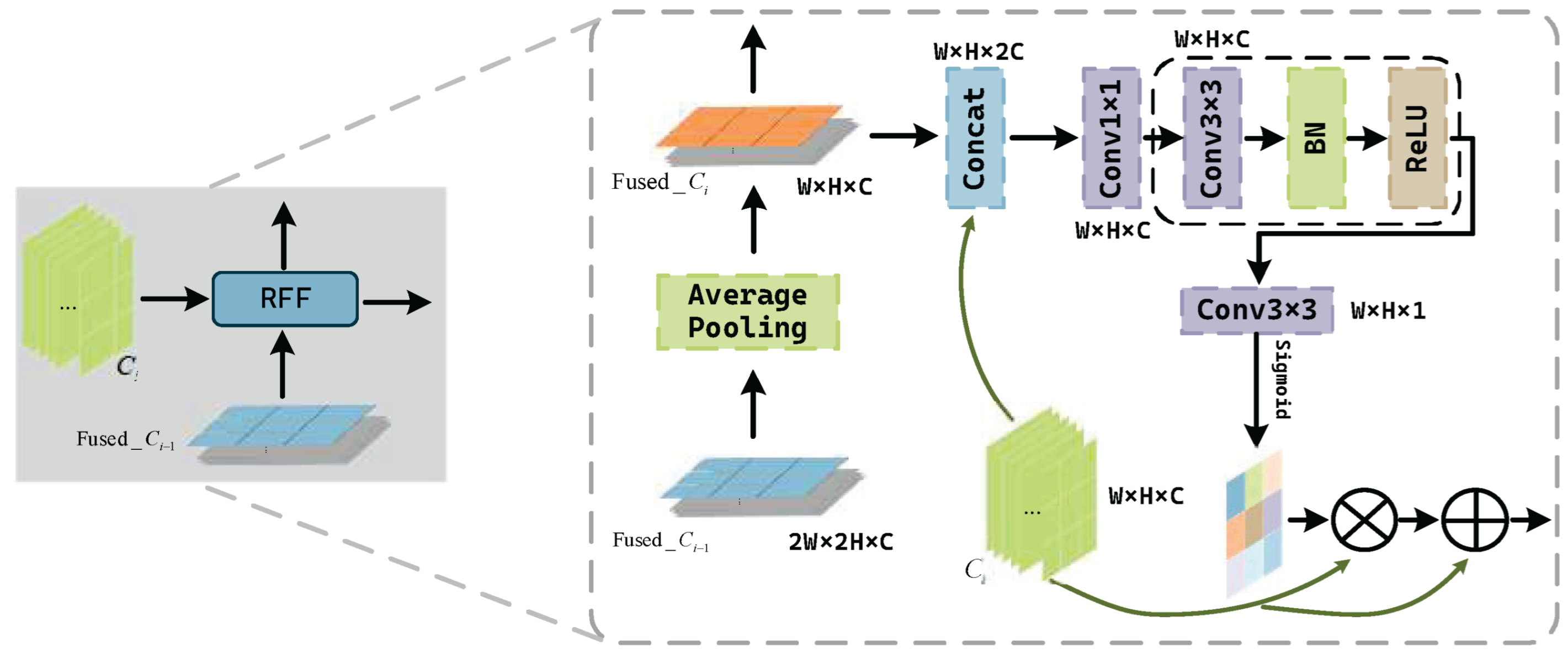
3.1. Rotation-Invariant Learning Module
3.1.1. Rotated Feature Refinement Module
3.1.2. Cross-Gated Channel-Spatial Attention Module
3.2. Rotation Feature Fusion Module
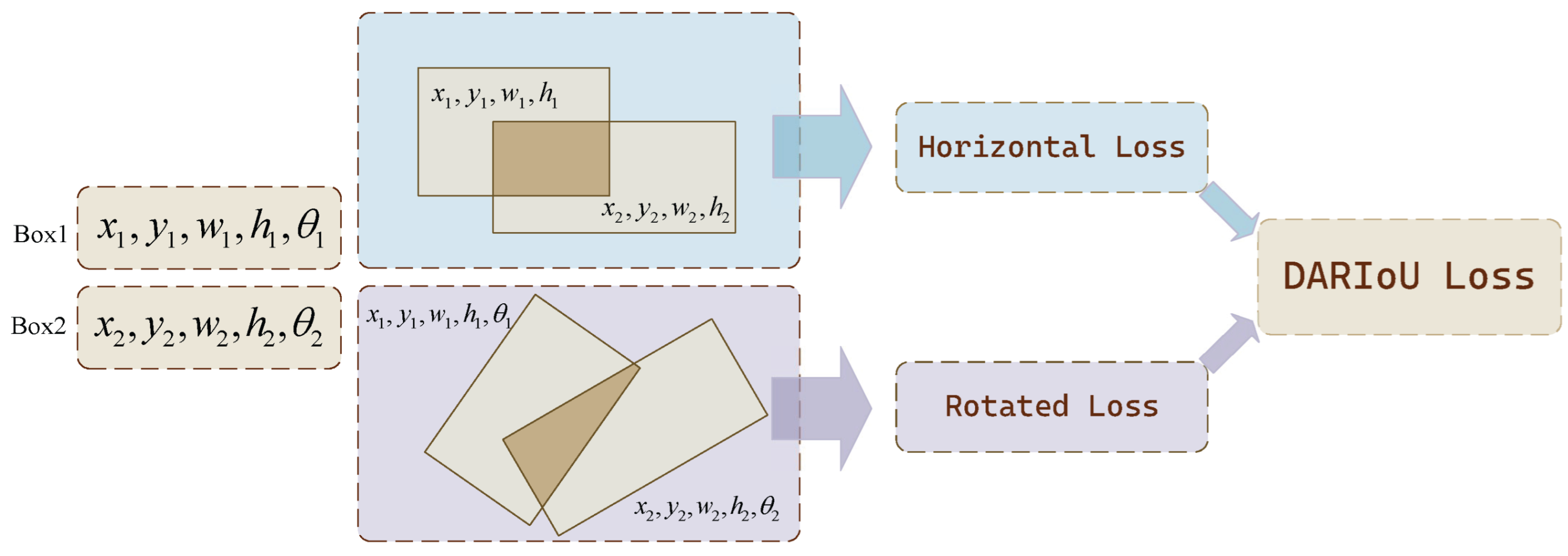
3.3. Dual-Aspect RIoU Loss
3.4. Objective Function
4. Datasets and Experimental Settings
4.1. Dataset
4.2. Experimental Platform and Evaluation Metrics
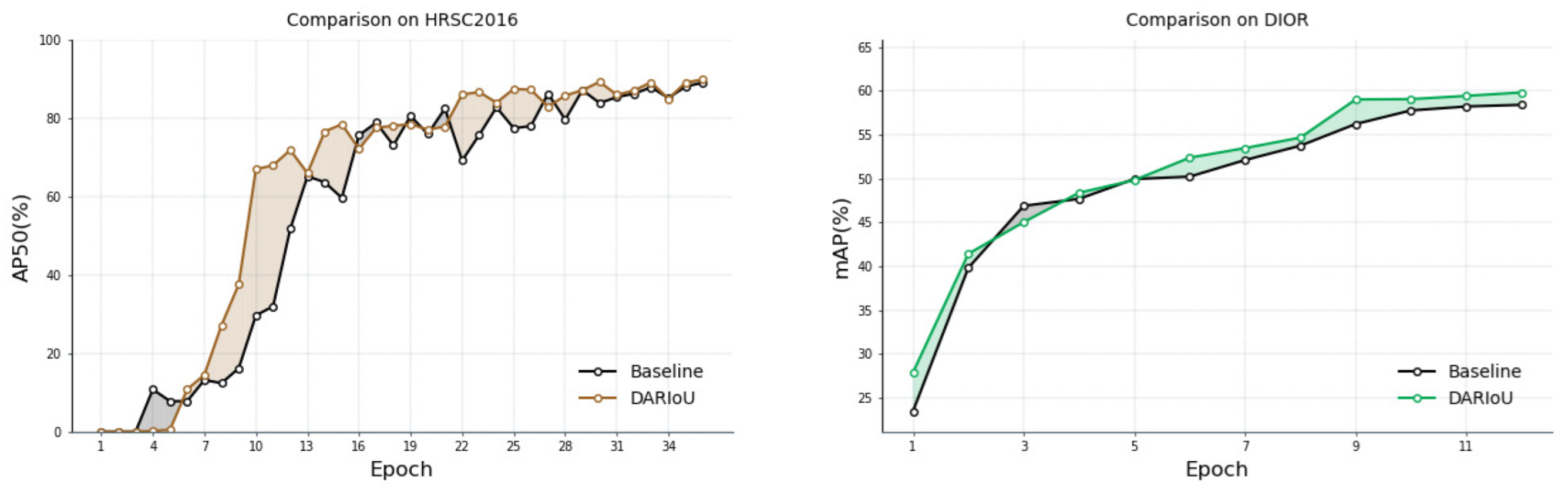
5. Experimental Results and Analysis
5.1. Comparative Experiment
5.2. Ablation Experiment
5.3. Hyperparameter Selection
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Feng, D.; Harakeh, A.; Waslander, S.L.; Dietmayer, K. A review and comparative study on probabilistic object detection in autonomous driving. IEEE Trans. Intell. Transp. Syst. 2021, 23, 9961–9980. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed]
- Pi, Y.; Nath, N.D.; Behzadan, A.H. Convolutional neural networks for object detection in aerial imagery for disaster response and recovery. Adv. Eng. Inf. 2020, 43, 101009. [Google Scholar] [CrossRef]
- Li, X.; Liu, B.; Zheng, G.; Ren, Y.; Zhang, S.; Liu, Y.; Gao, L.; Liu, Y.; Zhang, B.; Wang, F. Deep-learning-based information mining from ocean remote-sensing imagery. Natl. Sci. Rev. 2020, 7, 1584–1605. [Google Scholar] [CrossRef] [PubMed]
- Pavel, M.I.; Tan, S.Y.; Abdullah, A. Vision-based autonomous vehicle systems based on deep learning: A systematic literature review. Appl. Sci. 2022, 12, 6831. [Google Scholar] [CrossRef]
- Cerrillo-Cuenca, E.; Bueno-Ramírez, P. Predictive Archaeological Risk Assessment at Reservoirs with Multitemporal LiDAR and Machine Learning (XGBoost): The Case of Valdecañas Reservoir (Spain). Remote Sens. 2025, 17, 1306. [Google Scholar] [CrossRef]
- Durlević, U.; Srejić, T.; Valjarević, A.; Aleksova, B.; Deđanski, V.; Vujović, F.; Lukić, T. GIS-Based Spatial Modeling of Soil Erosion and Wildfire Susceptibility Using VIIRS and Sentinel-2 Data: A Case Study of Šar Mountains National Park, Serbia. Forests 2025, 16, 484. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. Available online: https://openaccess.thecvf.com/content_iccv_2017/html/He_Mask_R-CNN_ICCV_2017_paper.html (accessed on 23 February 2025).
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. Available online: https://openaccess.thecvf.com/content_cvpr_2018/html/Cai_Cascade_R-CNN_Delving_CVPR_2018_paper.html (accessed on 13 February 2025).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. Available online: https://www.cv-foundation.org/openaccess/content_cvpr_2016/html/Redmon_You_Only_Look_CVPR_2016_paper.html (accessed on 8 February 2025).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. Available online: https://link.springer.com/chapter/10.1007/978-3-319-46448-0_2 (accessed on 13 February 2025).
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. Available online: https://openaccess.thecvf.com/content_ICCV_2019/html/Tian_FCOS_Fully_Convolutional_One-Stage_Object_Detection_ICCV_2019_paper.html (accessed on 13 February 2025).
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. Isprs. J. Photogramm. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship rotated bounding box space for ship extraction from high-resolution optical satellite images with complex backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 734–750. Available online: https://openaccess.thecvf.com/content_ECCV_2018/html/Hei_Law_CornerNet_Detecting_Objects_ECCV_2018_paper.html (accessed on 13 February 2025).
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. Available online: https://openaccess.thecvf.com/content_ICCV_2019/html/Duan_CenterNet_Keypoint_Triplets_for_Object_Detection_ICCV_2019_paper.html (accessed on 1 February 2025).
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 850–859. Available online: https://openaccess.thecvf.com/content_CVPR_2019/html/Zhou_Bottom-Up_Object_Detection_by_Grouping_Extreme_and_Center_Points_CVPR_2019_paper.html (accessed on 15 February 2025).
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. Reppoints: Point set representation for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9657–9666. Available online: https://openaccess.thecvf.com/content_ICCV_2019/html/Yang_RepPoints_Point_Set_Representation_for_Object_Detection_ICCV_2019_paper.html (accessed on 12 February 2025).
- Dong, Z.; Li, G.; Liao, Y.; Wang, F.; Ren, P.; Qian, C. Centripetalnet: Pursuing high-quality keypoint pairs for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10519–10528. Available online: https://openaccess.thecvf.com/content_CVPR_2020/html/Dong_CentripetalNet_Pursuing_High-Quality_Keypoint_Pairs_for_Object_Detection_CVPR_2020_paper.html (accessed on 22 February 2025).
- Duan, K.; Xie, L.; Qi, H.; Bai, S.; Huang, Q.; Tian, Q. Corner proposal network for anchor-free, two-stage object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 399–416. Available online: https://link.springer.com/chapter/10.1007/978-3-030-58580-8_24 (accessed on 3 February 2025).
- Guo, C.; Ma, Q.; Zhang, L. Spatio-temporal saliency detection using phase spectrum of quaternion fourier transform. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, Alaska, 23–28 June 2008; pp. 1–8. Available online: https://ieeexplore.ieee.org/abstract/document/4587715 (accessed on 9 February 2025).
- Ell, T.A.; Sangwine, S.J. Hypercomplex Fourier transforms of color images. IEEE Trans. Image Process. 2006, 16, 22–35. [Google Scholar] [CrossRef] [PubMed]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the IEEE International Conference on Information Visualization, London, UK, 14–16 July 1999; Volume 2, pp. 1150–1157. Available online: https://link.springer.com/article/10.1023/B:VISI.0000029664.99615.94 (accessed on 15 February 2025).
- Nabati, R.; Qi, H. Rrpn: Radar region proposal network for object detection in autonomous vehicles. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 3093–3097. Available online: https://ieeexplore.ieee.org/abstract/document/8803392 (accessed on 23 February 2025).
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI transformer for oriented object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. Available online: https://openaccess.thecvf.com/content_CVPR_2019/html/Ding_Learning_RoI_Transformer_for_Oriented_Object_Detection_in_Aerial_Images_CVPR_2019_paper.html (accessed on 1 February 2025).
- Han, J.; Ding, J.; Xue, N.; Xia, G.S. Redet: A rotation-equivariant detector for aerial object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2786–2795. Available online: https://openaccess.thecvf.com/content/CVPR2021/papers/Han_ReDet_A_Rotation-Equivariant_Detector_for_Aerial_Object_Detection_CVPR_2021_paper.pdf (accessed on 13 February 2025).
- Cohen, T.; Welling, M. Group equivariant convolutional networks. In Proceedings of the International Conference on Machine Learning PMLR, New York, NY, USA, 20–22 June 2016; pp. 2990–2999. Available online: https://proceedings.mlr.press/v48/cohenc16.html (accessed on 8 February 2025).
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. Available online: https://openaccess.thecvf.com/content_iccv_2015/html/Girshick_Fast_R-CNN_ICCV_2015_paper.html (accessed on 23 February 2025).
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the ACM MM, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 9–11 February 2020; Volume 34, pp. 12993–13000. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/6999 (accessed on 8 February 2025).
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. Available online: https://openaccess.thecvf.com/content_CVPR_2019/html/Rezatofighi_Generalized_Intersection_Over_Union_A_Metric_and_a_Loss_for_CVPR_2019_paper.html (accessed on 20 February 2025).
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE T. Cybern 2021, 52, 8574–8586. Available online: https://ieeexplore.ieee.org/abstract/document/9523600 (accessed on 19 February 2025). [CrossRef] [PubMed]
- Raisi, Z.; Naiel, M.A.; Younes, G.; Wardell, S.; Zelek, J.S. Transformer-based text detection in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, online, 20–25 June 2021; pp. 3162–3171. Available online: https://openaccess.thecvf.com/content/CVPR2021W/VOCVALC/html/Raisi_Transformer-Based_Text_Detection_in_the_Wild_CVPRW_2021_paper.html (accessed on 20 March 2025).
- Zhou, Y.; Yang, X.; Zhang, G.; Wang, J.; Liu, Y.; Hou, L.; Jiang, X.; Liu, X.; Yan, J.; Lyu, C.; et al. Mmrotate: A rotated object detection benchmark using pytorch. In Proceedings of the ACM MM, Lisboa, Portugal, 10–14 October 2022; pp. 7331–7334. Available online: https://dl.acm.org/doi/abs/10.1145/3503161.3548541 (accessed on 21 March 2025).
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. Available online: https://openaccess.thecvf.com/content_iccv_2017/html/Lin_Focal_Loss_for_ICCV_2017_paper.html (accessed on 24 March 2025).
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.S.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef] [PubMed]
- Ming, Q.; Miao, L.; Zhou, Z.; Yang, X.; Dong, Y. Optimization for arbitrary-oriented object detection via representation invariance loss. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Ming, Q.; Miao, L.; Zhou, Z.; Dong, Y. CFC-Net: A critical feature capturing network for arbitrary-oriented object detection in remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Qian, W.; Yang, X.; Peng, S.; Yan, J.; Guo, Y. Learning modulated loss for rotated object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, online, 11–15 October 2021; Volume 35, pp. 2458–2466. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/16347 (accessed on 2 March 2025).
- Yang, X.; Yan, J. Arbitrary-oriented object detection with circular smooth label. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 677–694. Available online: https://link.springer.com/chapter/10.1007/978-3-030-58598-3_40 (accessed on 13 March 2025).
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined single-stage detector with feature refinement for rotating object. In Proceedings of the AAAI Conference on Artificial Intelligence, online, 11–15 October 2021; Volume 35, pp. 3163–3171. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/16426 (accessed on 9 March 2025).
- Yang, X.; Yang, X.; Yang, J.; Ming, Q.; Wang, W.; Tian, Q.; Yan, J. Learning high-precision bounding box for rotated object detection via kullback-leibler divergence. Adv. Neural Inf. Process. Syst. 2021, 34, 18381–18394. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Description |
|---|---|
| Operating System | Linux (Ubuntu 16.04) |
| GPU | NVIDIA GTX 3080Ti |
| Deep learning environment | PyTorch 1.10.0 + CUDA 11.3 |
| Framework | MMRotate [35] |
| Dataset | Epochs | Learning Rate | Momentum | Weight Decay |
|---|---|---|---|---|
| DIOR-R | 12 | 0.005 | 0.9 | 0.0001 |
| HRSC2016 | 36 |
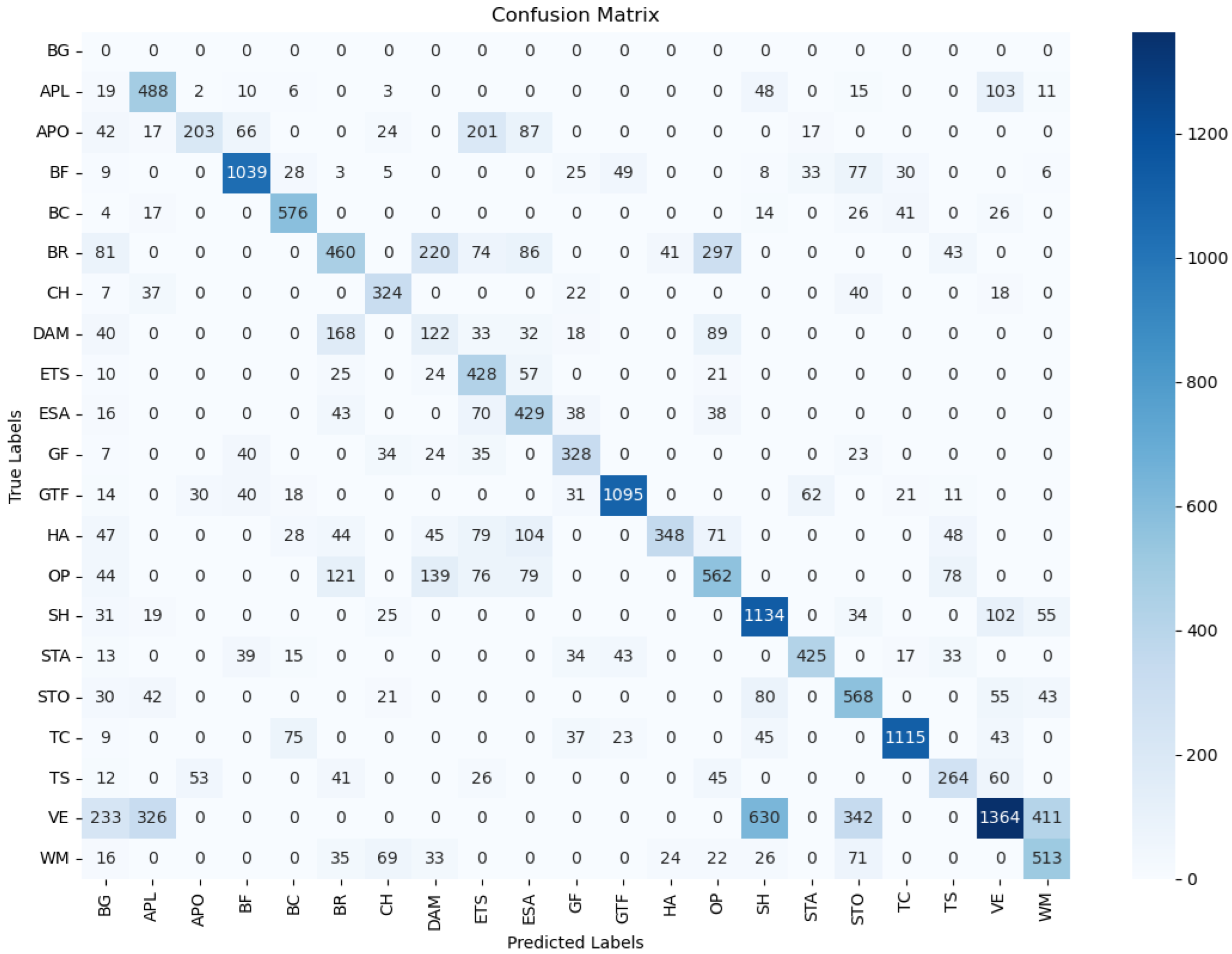
| Method | Backbone | APL | APO | BF | BC | BR | CH | DAM | ETS | ESA | GF | GTF | HA | OP | SH | STA | STO | TC | TS | VE | WM | mAP | FPS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FCOS-O [13] | R-50-FPN | 62.01 | 33.62 | 74.81 | 81.31 | 28.36 | 72.60 | 23.45 | 75.17 | 55.78 | 74.24 | 79.17 | 34.82 | 43.92 | 77.22 | 66.54 | 53.96 | 81.43 | 47.65 | 40.07 | 62.24 | 58.42 | 26.5 |
| RetinaNet-O [36] | R-50-FPN | 61.49 | 28.52 | 73.57 | 81.17 | 23.98 | 72.54 | 19.94 | 72.39 | 58.20 | 69.25 | 79.54 | 32.14 | 44.87 | 77.71 | 67.57 | 61.09 | 81.46 | 47.33 | 38.01 | 60.24 | 57.55 | 23.0 |
| Faster RCNN-O [8] | R-50-FPN | 62.79 | 26.80 | 71.72 | 80.91 | 34.20 | 72.57 | 18.95 | 66.45 | 65.75 | 66.63 | 79.24 | 34.95 | 48.79 | 81.14 | 64.34 | 71.21 | 81.44 | 47.31 | 50.46 | 65.21 | 59.54 | 19.0 |
| Gliding Vertex [37] | R-50-FPN | 65.35 | 28.87 | 74.96 | 81.33 | 33.88 | 74.31 | 19.58 | 70.72 | 64.70 | 72.30 | 78.68 | 37.22 | 49.64 | 80.22 | 69.26 | 61.13 | 81.49 | 44.76 | 47.71 | 65.04 | 60.06 | 15.2 |
| RIDet [38] | R-50-FPN | 62.90 | 32.43 | 77.58 | 81.09 | 37.27 | 72.58 | 24.42 | 64.95 | 76.17 | 55.22 | 81.12 | 43.61 | 50.88 | 81.05 | 73.16 | 60.45 | 81.49 | 49.02 | 43.35 | 62.48 | 60.56 | - |
| CFC-Net [39] | R-50-FPN | 64.49 | 33.43 | 75.16 | 81.25 | 36.14 | 71.75 | 18.01 | 63.57 | 70.13 | 68.15 | 80.82 | 41.58 | 52.30 | 80.95 | 68.72 | 69.61 | 83.73 | 47.06 | 47.91 | 57.86 | 60.65 | - |
| Ours | R-50-FPN | 69.28 | 30.95 | 79.19 | 81.58 | 35.33 | 72.25 | 24.39 | 75.73 | 67.69 | 66.89 | 82.81 | 42.70 | 51.15 | 81.00 | 68.66 | 67.94 | 82.74 | 52.70 | 41.25 | 63.37 | 61.88 | 25.9 |
| Ours | R-101-FPN | 67.78 | 33.21 | 79.80 | 84.27 | 36.54 | 75.82 | 24.61 | 76.19 | 67.54 | 69.96 | 83.46 | 43.99 | 50.52 | 81.65 | 68.19 | 68.47 | 83.39 | 51.10 | 39.55 | 60.87 | 62.35 | 23.2 |
| Method | RoI-Transformer [26] | Gliding Vertex [37] | RSDet [40] | CSL [41] | R3Det [42] | KLD [43] | FCOS-O [13] | Ours | |
|---|---|---|---|---|---|---|---|---|---|
| Backbone | R101 + FPN | R101 + FPN | R101 + FPN | R101 + FPN | R101 + FPN | R50 + FPN | R50 + FPN | R50 + FPN | R101 + FPN |
| AP(%) | 86.20 | 88.20 | 86.50 | 89.62 | 89.20 | 89.97 | 89.11 | 90.03 | 90.20 |
| FPS | 9.1 | 9.4 | - | 17.2 | 9.5 | 18.2 | 20.8 | 20.2 | 17.5 |
| Baseline | Different Setting of Our Method | mAP(%) |
|---|---|---|
| FCOS-O [13] | None | 58.42 |
| RIL + RFF | 60.66 | |
| DARIoU | 59.83 | |
| RIL + RFF + DARIoU | 61.88 | |
| RetinaNet-O [36] | None | 57.55 |
| RIL + RFF | 58.89 | |
| DARIoU | 58.22 | |
| RIL + RFF + DARIoU | 59.94 |
| Loss Function | IoU Loss | GIoU Loss | DIoU Loss | CIoU Loss | DARIoU Loss |
|---|---|---|---|---|---|
| 89.11 | 89.52 | 89.86 | 89.64 | 89.92 | |
| 72.82 | 73.55 | 74.73 | 73.98 | 75.40 | |
| 0.30 | 0.80 | 1.00 | 0.50 | 2.50 |
| 1.0 | 1.5 | 0.7 | 0.3 | 1.0 | 1.0 | 1.0 | 1.0 | |
| 1.0 | 1.0 | 1.0 | 1.0 | 0.7 | 0.3 | 0.1 | 0.05 | |
| mAP(%) | 61.39 | 60.94 | 61.72 | 61.88 | 61.79 | 61.73 | 61.68 | 61.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Z.; Meng, X.; Liu, X.; Sun, Z. Rotation-Invariant Feature Enhancement with Dual-Aspect Loss for Arbitrary-Oriented Object Detection in Remote Sensing. Appl. Sci. 2025, 15, 5240. https://doi.org/10.3390/app15105240
Hu Z, Meng X, Liu X, Sun Z. Rotation-Invariant Feature Enhancement with Dual-Aspect Loss for Arbitrary-Oriented Object Detection in Remote Sensing. Applied Sciences. 2025; 15(10):5240. https://doi.org/10.3390/app15105240
Chicago/Turabian StyleHu, Zhao, Xiangfu Meng, Xinsong Liu, and Zhuxiang Sun. 2025. "Rotation-Invariant Feature Enhancement with Dual-Aspect Loss for Arbitrary-Oriented Object Detection in Remote Sensing" Applied Sciences 15, no. 10: 5240. https://doi.org/10.3390/app15105240
APA StyleHu, Z., Meng, X., Liu, X., & Sun, Z. (2025). Rotation-Invariant Feature Enhancement with Dual-Aspect Loss for Arbitrary-Oriented Object Detection in Remote Sensing. Applied Sciences, 15(10), 5240. https://doi.org/10.3390/app15105240