
Crack Defect Detection Method for Plunge Pool Corridor Based on the Improved U-Net Network



Abstract
1. Introduction
- Semantic segmentation approaches are capable of achieving detailed identification of specified objects, showcasing notable advantages in concrete crack detection. Yet most current mainstream crack detection networks are tailored for scenarios like building walls, road surfaces, or bridges. Plunge pool corridors, long-term exposed to high-speed water flow erosion, thermal stress, and wet–dry cycles, exhibit concrete cracks with morphological features, spatial distributions, and data distributions that differ substantially from target objects in conventional public datasets. This makes it challenging for generic models to accurately differentiate targets from backgrounds. Additionally, the nonlinear morphology and multi-scale characteristics of cracks in plunge pool corridors render traditional fixed-size convolution kernels ineffective in capturing edge details. While techniques like deformable convolutions attempt to dynamically adjust the receptive field, existing approaches lack the exploitation of crack morphological priors, making them susceptible to feature deviation in complex backgrounds and resulting in segmentation issues such as discontinuities and missed detections.
- To address the aforementioned research gaps, this study develops a specialized dataset for crack segmentation in plunge pool corridors via on-site data collection and presents an improved U-Net model incorporating morphology-aware dynamic convolution and cross-dimensional interactive attention. The contributions of this work are as follows:
- (1)
- Development of a scenario-specific dataset: Using an inspection robot outfitted with a multi-angle vision system, we acquired crack images of plunge pool corridors with complex backgrounds and constructed a high-quality dataset comprising 4075 images via data augmentation techniques, addressing the lack of data for plunge pool corridor scenarios.
- (2)
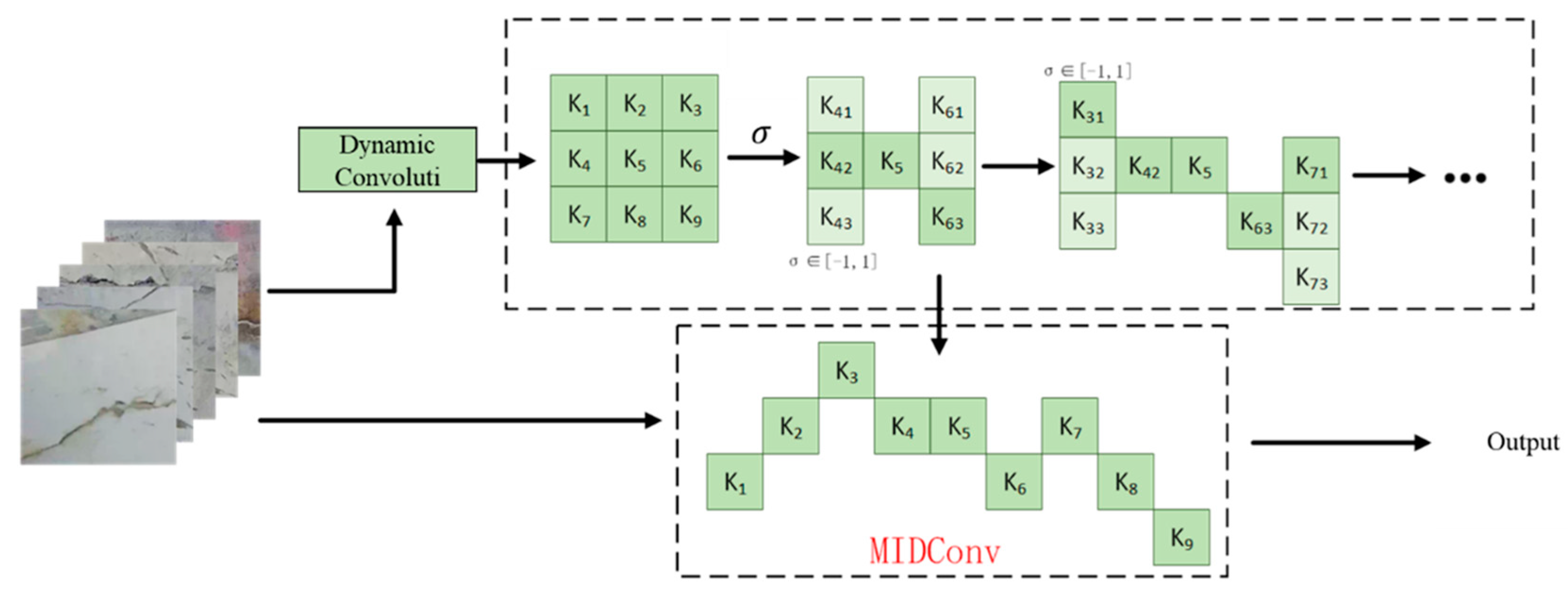
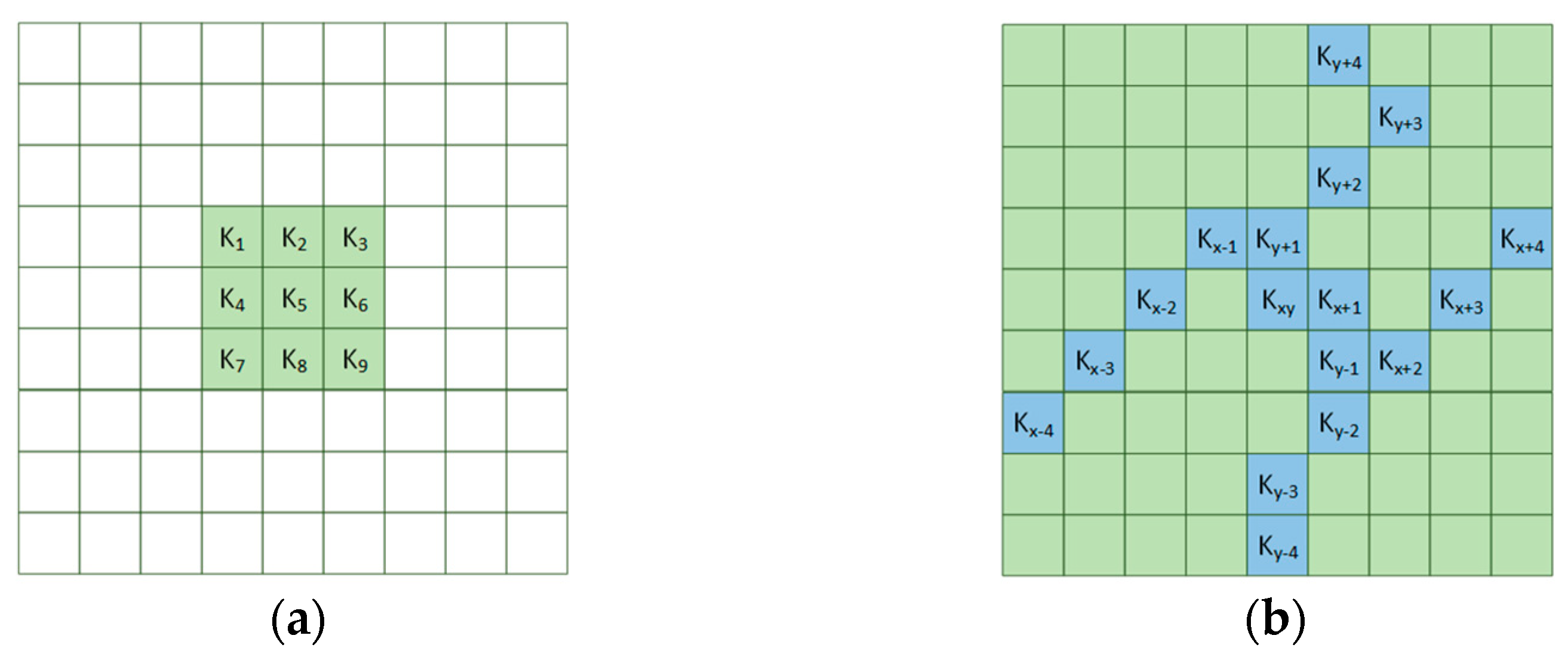
- Proposing morphology-integrated irregular dynamic convolution (MIDConv): By integrating the linear morphological features of cracks and constraining the offset accumulation of deformable convolutions, the receptive field of the convolution kernel is dynamically expanded along the crack orientation, effectively enhancing the ability to extract features of irregular edges.
- (3)
- Development of cross-dimensional interactive attention module (CDIAM): By partitioning channels into groups and introducing a global information calibration mechanism, semantic interaction between channel and spatial dimensions is established, enhancing the model’s capacity to model pixel-level relationships of cracks in complex backgrounds and markedly reducing misdetections and omissions.
- (4)
- Substantial enhancement in detection performance: On the self-constructed dataset, the improved model achieves an MIoU, F1-Score, MPA, and accuracy of 84.44%, 93.05%, 89.75%, and 99.46%, reflecting improvements of 5.34%, 4.90%, 3.39%, and 0.36% compared to the original U-Net, effectively resolving the problem of inadequate detection accuracy of traditional methods in complex scenarios. Additionally, to validate the generalization capability of the proposed approach, experiments were performed on two public datasets, both yielding promising results.
2. Methods
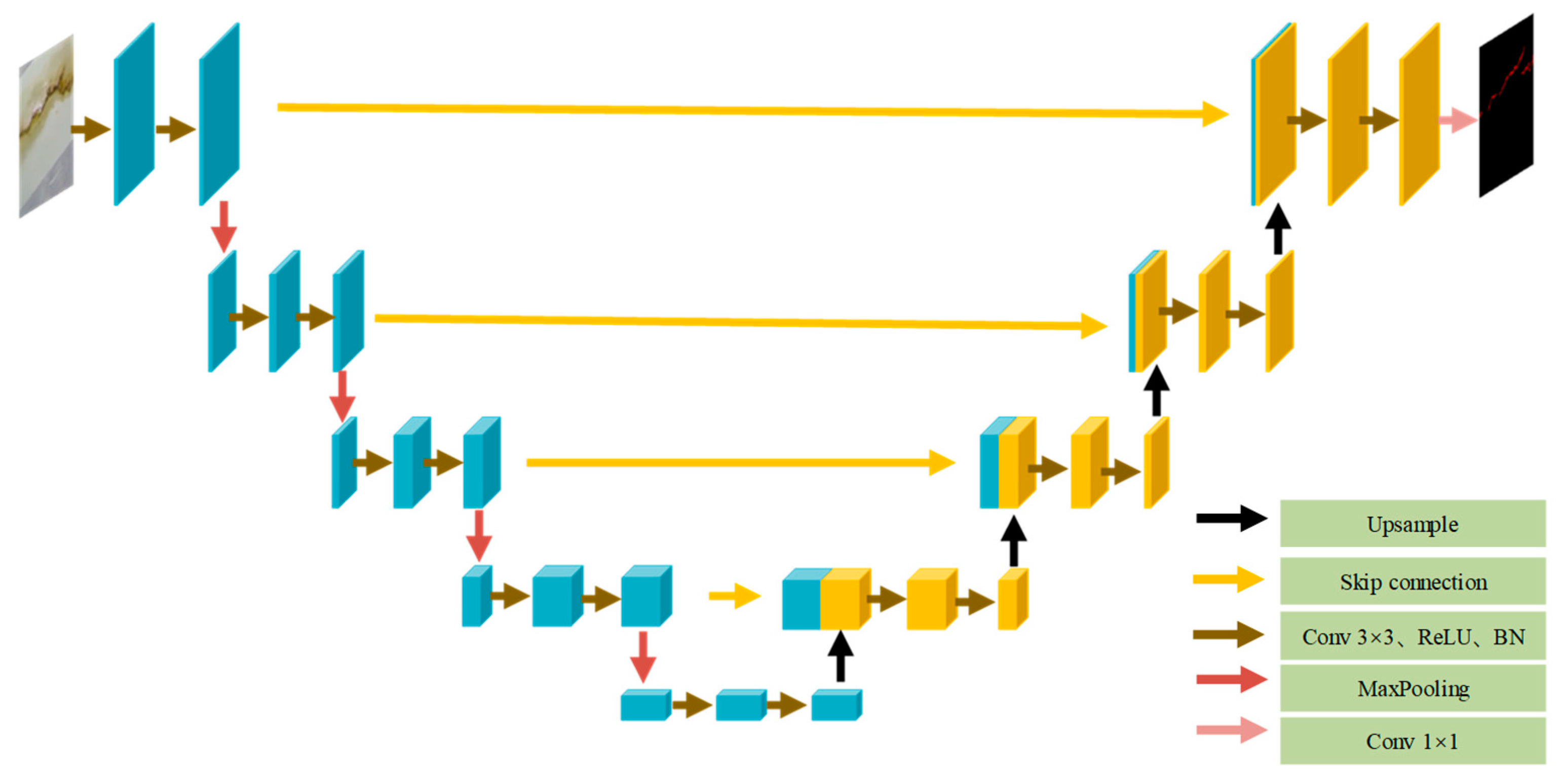
2.1. Crack Segmentation Model for Plunge Pool Corridors Based on the Improved U-Net
2.2. Morphological Irregular Dynamic Convolution Method
2.3. Cross-Dimensional Interaction Attention Module
3. Dataset
3.1. Data Collection
3.2. Data Augmentation
4. Experiment
4.1. Experimental Environment
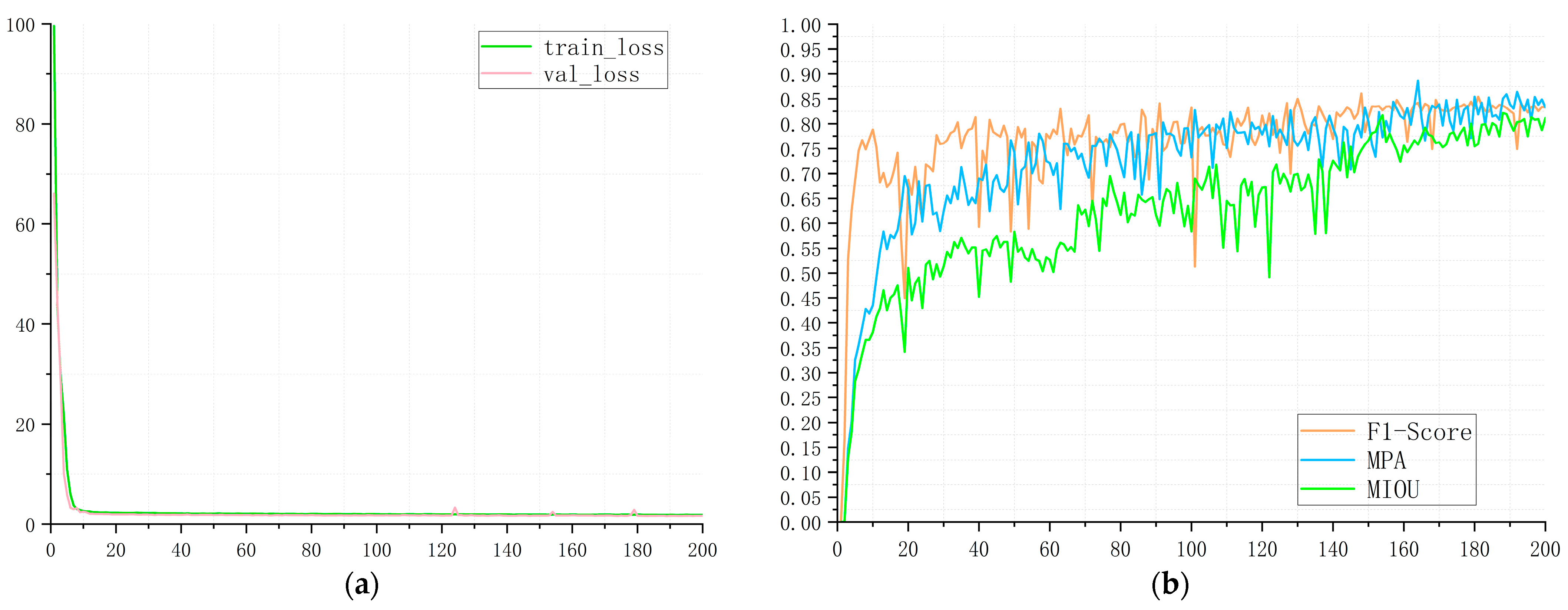
4.2. Evaluation Metrics
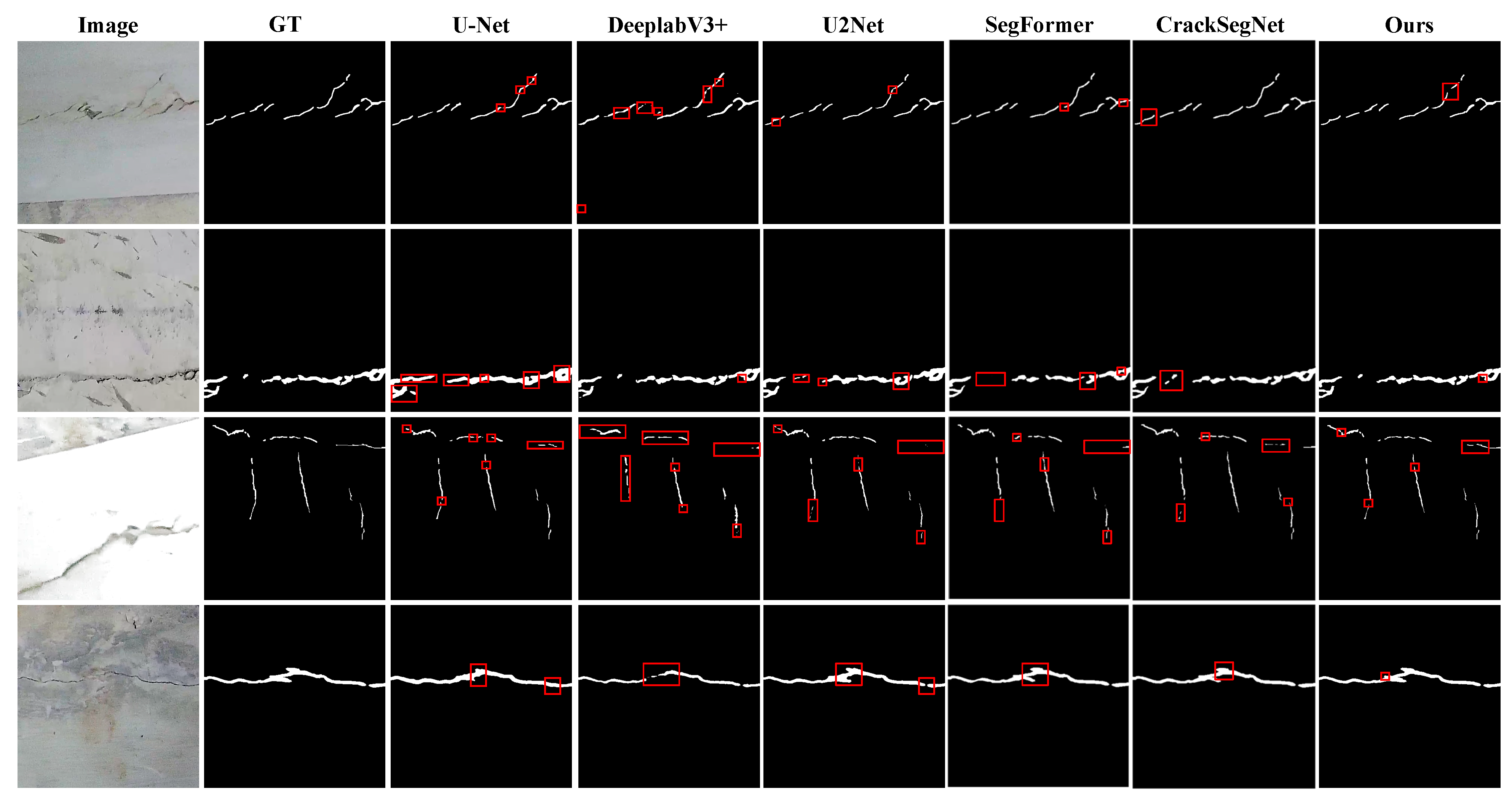
4.3. Comparative Experiment
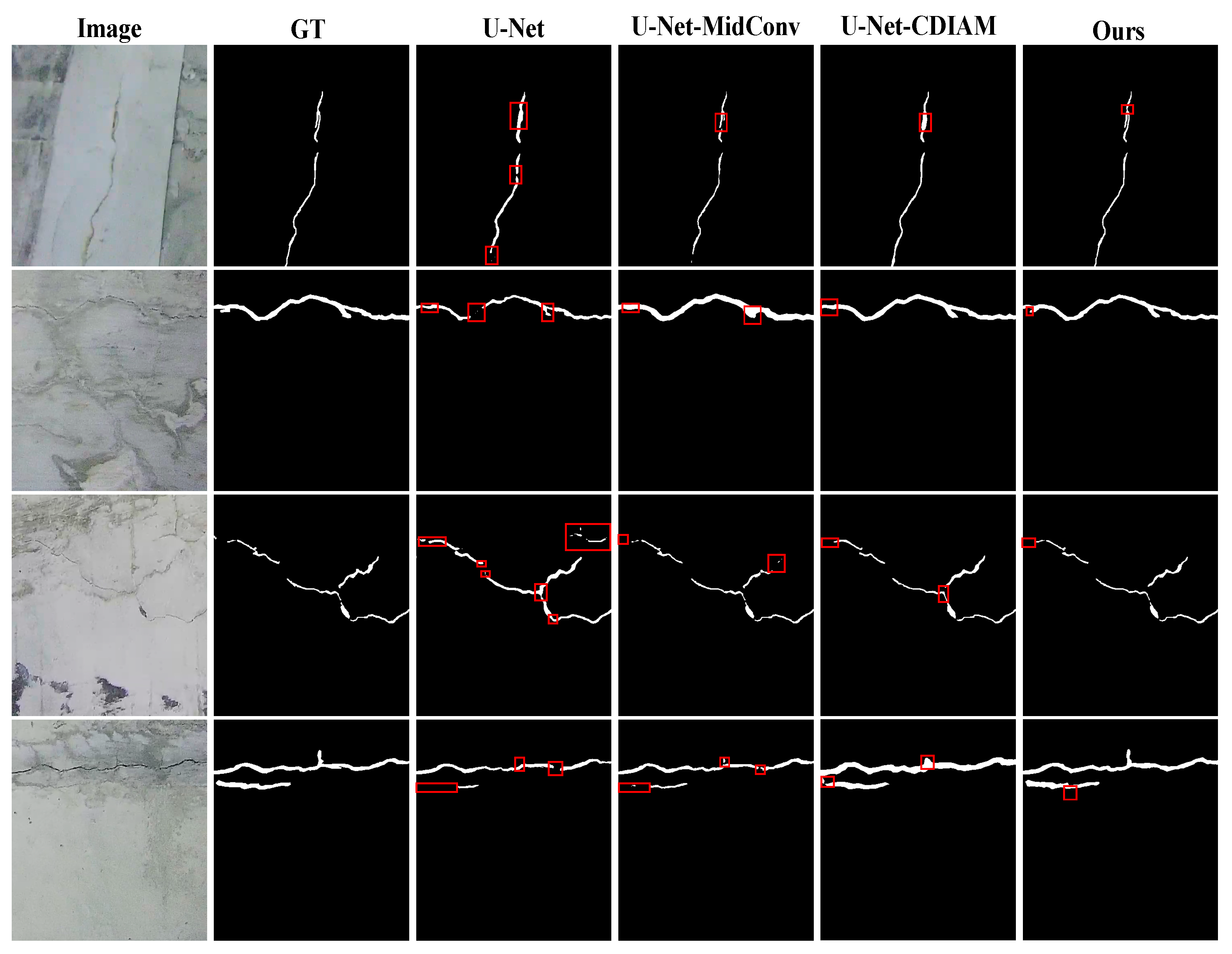
4.4. Ablative Experiment
5. Discussion
5.1. Validity and Scenario Adaptability of Data Acquisition Scheme
5.2. The Synergy of Improved Modules
5.3. Comparison with Existing Methods and Domain Migration Potential
6. Conclusions
- (1)
- Quantitative assessments reveal that the improved model achieves an MIoU, F1-score, MPA, and accuracy of 84.44%, 93.05%, 89.75%, and 99.46%, respectively. When compared with mainstream semantic segmentation models like DeepLabV3+ and U2Net, it exhibits superior fine-grained segmentation capability for overlapping areas between crack regions and backgrounds. The notable enhancement in F1-score signifies that the model has achieved breakthroughs in balancing precision and recall, effectively minimizing the missed detections of slender cracks (e.g., missing bifurcation structures) and misjudgments of complex backgrounds (e.g., stains, uneven lighting areas) of traditional models.
- (2)
- Visual comparisons further disclose that the improved model, through the morphology-integrated irregular dynamic convolution (MIDConv), binds the convolution kernel’s offsets in the X/Y axis directions with the linear morphological features of cracks, allowing the receptive field to dynamically expand along crack orientations and thus fully capture continuous edges. Simultaneously, the cross-dimensional interactive attention module (CDIAM) significantly enhances the capability to model pixel-level semantic relationships by partitioning channels into sub-feature groups and calibrating cross-dimensional weights via global average pooling, effectively suppressing background interference and retaining crack details.
- (3)
- Independently introducing the MIDConv or CDIAM module elevates the MIoU to 82.78% and 82.36%, respectively, whereas their combination further boosts the metric to 84.44%, demonstrating significant complementarity between dynamic feature extraction and cross-dimensional semantic enhancement. In generalization capability tests, the improved model validates its accuracy–efficiency balance advantage—achieved via structured feature group partitioning and convolution kernel offset constraints—on public datasets.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tian, W.; Shen, H.; Li, X.; Shi, L. Research on corridor surface crack detection technology based on image processing. Electron. Des. Eng. 2020, 5, 148–151. (In Chinese) [Google Scholar] [CrossRef]
- Yu, S.N.; Jang, J.H.; Han, C.S. Auto inspection system using a mobile robot for detecting concrete cracks in a tunnel. Autom. Constr. 2007, 16, 255–261. [Google Scholar] [CrossRef]
- Li, G.; He, S.; Ju, Y.; Du, K. Long-distance precision inspection method for bridge cracks with image processing. Autom. Constr. 2014, 41, 83–95. [Google Scholar] [CrossRef]
- Li, G.; Zhao, X.; Du, K.; Ru, F.; Zhang, Y. Recognition and evaluation of bridge cracks with modified active contour model and greedy search-based support vector machine. Autom. Constr. 2017, 78, 51–61. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings Part III 18. Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Fan, H.; Liu, X. Concrete Crack Detection Based on ST-UNet and Target Features. Comput. Syst. Appl. 2024, 33, 77–84. (In Chinese) [Google Scholar]
- Pan, Y.; Zhou, S.; Yang, D. Research on Concrete Crack Segmentation Based on Improved Unet Model. J. East China Jiaotong Univ. 2024, 41, 11–19. (In Chinese) [Google Scholar]
- Meng, Q.; Li, M.; Wan, D.; Hu, L.; Wu, H.; Qi, X. Real-time segmentation algorithm of concrete cracks based on M-Unet. J. Civ. Environ. Eng. 2024, 46, 215–222. (In Chinese) [Google Scholar]
- Zhang, H.; Ma, L.; Yuan, Z.; Liu, H. Enhanced concrete crack detection and proactive safety warning based on I-ST-UNet model. Autom. Constr. 2024, 166, 105612. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Liang, D.; Li, Y.; Zhang, S. Identification of cracks in concrete bridges through fusing improved ResNet-14 and RS-Unet models. J. Beijing Jiaotong Univ. 2023, 47, 10–18. (In Chinese) [Google Scholar]
- Zhou, T.; Zhou, Z.; Wu, Y.; Wen, X.; Pu, Q. Self-detection method of concrete bridge cracks based on improved U-Net network. Sichuan Cem. 2023, 47, 10–18. (In Chinese) [Google Scholar]
- Ma, Y.; Sun, W.; He, Y.; Wang, L. Surface crack identification method of concrete bridge based on DC-Unet. J. Chang’Univ. (Nat. Sci. Ed.) 2024, 44, 66–75. (In Chinese) [Google Scholar] [CrossRef]
- Shi, M.; Gao, J. Research on Pavement Crack Detection Based on Improved U-Net Algorithm. Autom. Instrum. 2022, 37, 52–55+67. (In Chinese) [Google Scholar] [CrossRef]
- Hui, B.; Li, Y. A Detection Method for Pavement Cracks Based on an Improved U-Shaped Network. J. Transp. Inf. Saf. 2023, 41, 105–114. (In Chinese) [Google Scholar] [CrossRef]
- Zhao, Z.; Hao, Z.; He, P. Combining attention mechanism with GhostUNet method for pavement crack detection. Electron. Meas. Technol. 2023, 46, 164–171. (In Chinese) [Google Scholar] [CrossRef]
- Zhang, M.; Xu, J.; Liu, X.; Zhang, Y.; Zhang, C. Improved U-Net pavement crack detection method. Comput. Eng. Appl. 2024, 60, 306–313. (In Chinese) [Google Scholar]
- Sun, Y.; Bi, F.; Gao, Y.; Chen, L.; Feng, S. A multi-attention UNet for semantic segmentation in remote sensing images. Symmetry 2022, 14, 906. [Google Scholar] [CrossRef]
- Chen, S.; Feng, Z.; Xiao, G.; Chen, X.; Gao, C.; Zhao, M.; Yu, H. Pavement Crack Detection Based on the Improved Swin-Unet Model. Buildings 2024, 14, 1442. [Google Scholar] [CrossRef]
- Al-Huda, Z.; Peng, B.; Riyadh, N.A.A.; Mugahed, A.A.; Rabea, A.; Omar, A.; Zhai, D. Asymmetric dual-decoder-U-Net for pavement crack semantic segmentation. Autom. Constr. 2023, 156, 105138. [Google Scholar] [CrossRef]
- Ren, Y.; Huang, J.; Hong, Z. Image-based concrete crack detection in tunnels using deep fully convolutional networks. Constr. Build. Mater. 2020, 234, 117367. [Google Scholar] [CrossRef]
- Qing, S.; Yingqi, W.; Xueshi, X.; Lu, Y.; Min, Y.; Hongming, C. Real-Time Tunnel Crack Analysis System via Deep Learning. IEEE Access 2019, 7, 64186–64197. [Google Scholar] [CrossRef]
- Choi, W.; Cha, Y.-J. SDDNet: Real-Time Crack Segmentation. IEEE Trans. Ind. Electron. 2020, 67, 8016–8025. [Google Scholar] [CrossRef]
- Yahui, L.; Jian, Y.; Xiaohu, L.; Renping, X.; Li, L. DeepCrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar]
- Ju, H.; Li, W.; Tighe, S.; Xu, Z.; Zhai, J. CrackU-net: A novel deep convolutional neural network for pixelwise pavement crack detection. Struct. Control Health Monit. 2020, 27, e2551. [Google Scholar]
- Cao, H.; Gao, Y.; Cai, W.; Xu, Z.; Li, L. Segmentation Detection Method for Complex Road Cracks Collected by UAV Based on HC-Unet++. Drones 2023, 7, 189. [Google Scholar] [CrossRef]
- Sun, X.; Xie, Y.; Jiang, L.; Cao, Y.; Liu, B. DMA-Net: DeepLab With Multi-Scale Attention for Pavement Crack Segmentation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18392–18403. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar] [CrossRef]
- Vaswani, A. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems—NIPS’17, Red Hook, NY, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Li, X.; Sun, X.; Meng, Y.; Liang, J.; Wu, F.; Li, J. Dice Loss for Data-imbalanced NLP Tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 2020. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; George, P.; Florian, S.; Hartwig, A. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In European Conference on Computer Vision; Springer: Cham, Switzerland; Glasgow, KY, USA, 2018. [Google Scholar] [CrossRef]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Ran, R.; Xu, X.; Qiu, S.; Cui, X.; Wu, F. Crack-SegNet: Surface Crack Detection in Complex Background Using Encoder-Decoder Architecture. In Proceedings of the 2021 4th International Conference on Sensors, Signal and Image Processing (SSIP’21). Association for Computing Machinery, New York, NY, USA, 15–17 October 2021; pp. 15–22. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | MIOU (%) | MPA (%) | F1-Score (%) | Accuracy (%) |
|---|---|---|---|---|
| U-Net | 79.1 | 87.15 | 84.36 | 99.1 |
| DeepLabV3+ | 80.5 | 88.04 | 84.79 | 99.2 |
| U2Net | 82.11 | 89.45 | 85.52 | 99.11 |
| SegFormer | 82.64 | 89.69. | 85.78 | 99.32 |
| CrackSegNet | 81.37 | 88.53 | 84.94 | 99.23 |
| Ours | 84.44 | 92.05 | 87.75 | 99.46 |
| Model | MIOU (%) | MPA (%) | F1-Score (%) | Accuracy (%) |
|---|---|---|---|---|
| U-Net | 79.1 | 87.15 | 84.36 | 99.1 |
| U-Net+CDIAM | 82.36 | 89.54 | 85.68 | 99.27 |
| U2Net+MIDConv | 82.78 | 91.56 | 87.02 | 99.30 |
| Ours | 84.44 | 92.05 | 87.75 | 99.46 |
| Dataset | MIOU (%) | MPA (%) | F1-Score (%) | Accuracy (%) |
|---|---|---|---|---|
| DeepCrack | 83.64 | 88.83 | 86.34 | 99.37 |
| Crack500 | 84.37 | 89.20 | 87.36 | 99.41 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, C.; Liu, Z.; Xia, F.; Zhou, X.; Shui, Y.; Li, Y. Crack Defect Detection Method for Plunge Pool Corridor Based on the Improved U-Net Network. Appl. Sci. 2025, 15, 5225. https://doi.org/10.3390/app15105225
Hou C, Liu Z, Xia F, Zhou X, Shui Y, Li Y. Crack Defect Detection Method for Plunge Pool Corridor Based on the Improved U-Net Network. Applied Sciences. 2025; 15(10):5225. https://doi.org/10.3390/app15105225
Chicago/Turabian StyleHou, Chunyao, Zhihui Liu, Fan Xia, Xun Zhou, Yuhang Shui, and Yonglong Li. 2025. "Crack Defect Detection Method for Plunge Pool Corridor Based on the Improved U-Net Network" Applied Sciences 15, no. 10: 5225. https://doi.org/10.3390/app15105225
APA StyleHou, C., Liu, Z., Xia, F., Zhou, X., Shui, Y., & Li, Y. (2025). Crack Defect Detection Method for Plunge Pool Corridor Based on the Improved U-Net Network. Applied Sciences, 15(10), 5225. https://doi.org/10.3390/app15105225