Abstract
Super-resolution (SR) of remote sensing images is essential to compensate for missing information in the original high-resolution (HR) images. Single-image super-resolution (SISR) technique aims to recover high-resolution images from low-resolution (LR) images. However, traditional SISR methods often result in blurred and unclear images due to the loss of high-frequency details in LR images at high magnifications. In this paper, a super-segmental reconstruction model STGAN for remote sensing images is proposed, which fuses the Generative Adversarial Networks (GANs) and self-attention mechanism based on the Reference Super Resolution method (RefSR). The core module of the model consists of multiple CNN-Swin Transformer blocks (MCST), each of which consists of a CNN layer and a specific modified Swin Transformer, constituting the feature extraction channel. In image hypersegmentation reconstruction, the optimized and improved correlation attention block (RAM-V) uses feature maps and gradient maps to improve the robustness of the model under different scenarios (such as land cover change). The experimental results show that the STGAN model proposed in this paper exhibits the best image data perception quality results with the best performance of LPIPS and PI metrics in the test set under RRSSRD public datasets. In the experimental test set, the PSNR reaches 31.4151, the SSIM is 0.8408, and the performance on the RMSE and SAM metrics is excellent, which demonstrate the model’s superior image reconstruction details in super-resolution reconstruction and highlighting the great potential of RefSR’s application to the task of super-scalar processing of remotely sensed images.
1. Introduction
High-resolution (HR) remote sensing images are crucial in several fields, such as geographic information systems (GIS) [1], semantic segmentation [2], urban planning [3], building detection [4,5], etc., as they provide more detailed information about the ground surface. Compared to low-resolution (LR) images, HR images contain more pixels, details, and reliability. However, it is often difficult to actually obtain desirable HR images due to equipment, environmental, and transmission conditions. Although hardware improvement is costly and difficult to implement, using algorithms to enhance image resolution has become a focus of research. Super-resolution (SR) technology reconstructs HR images from LR images through image processing and computer vision algorithms to solve the problems of blurred imaging and poor quality. In the field of image SR reconstruction, traditional techniques are mainly based on interpolation and reconstruction methods. In recent years, the rise of deep learning has revolutionized image SR reconstruction [6], especially the application of convolutional neural networks (CNNs) [7,8,9], which makes it realistic to establish the mapping relationship between LR and HR by analyzing and learning from a large amount of image data [10].
Image SR reconstruction techniques can be categorized into single image super-resolution (SISR) and multi-image super-resolution (MISR) based on the number of images involved in the process [11]. The goal of the SISR technique is to reconstruct the HR image from a single LR image, but due to the loss of high-frequency details in the acquisition process, this technique can lead to blurred and unsharp results when recovering details, especially at high magnifications. To overcome the challenges faced by SISR, Generative Adversarial Network (GAN)-based SISR methods have emerged [12,13,14], which have made significant progress in improving visual quality. GANs are capable of generating more realistic textures and details through an adversarial training process, and thus, solving the blurring and detail loss problems in traditional SISR methods to some extent. However, GAN-based SISR methods also have drawbacks and may sometimes generate unrealistic textures or even introduce artefacts.
With the development of SISR technology, the reference-based super-resolution (RefSR) technique has begun to receive attention [15,16,17,18]. RefSR utilizes an HR reference image similar to the LR image to enhance the details, which compensates for the shortcomings of SISR, and especially excels in processing similar content. However, natural variations, cloud occlusion, and difficulties in acquiring high-resolution reference images challenge the robustness of the model. In order to enhance the usefulness of super-resolution in remote sensing images, we developed a novel RefSR model, STGAN, which is capable of outputting high-quality images stably in various environments.
Contribution:
- We have innovatively designed a remote sensing image RefSR method (STGAN) based on the Generative Adversarial Networks (GANs) and self attention mechanism. STGAN adopts the GAN structure and introduces a specific improved Swin Transformer model. At the same time, it combines the residual network, the self-attention mechanism, and the dual-channel feature extraction of CNN to achieve accurate pixel-level fusion and significantly improve the quality of image reconstruction.
- The experimental results verify the excellent performance of STGAN in the field of super-resolution, which not only excels in many SISR solutions, but also demonstrates obvious advantages in comparison with mainstream RefSR methods. The STGAN is robust to the fluctuation of reference image quality and extends the upper performance limit of the SR task to a certain extent, which fully proves the RefSR method’s great potential of RefSR methods in the field of remote sensing.Our experimental data can be found on https://github.com/hw-star/STGAN, accessed on 27 December 2024.
2. Related Work
2.1. SR for Remote Sensing Images
Since SRCNN [19] first applied convolutional neural networks (CNNs) to the image super-resolution (SR) task and demonstrated superior performance to traditional methods, researchers have proposed numerous deep-learning-based network architectures to further enhance the quality of image reconstruction. For example, Shi et al. [20] introduced subpixel convolution, while Ledig et al. [12] combined ResNet with GANs to propose models such as SRGAN. Pan et al. proposed a single-image super-resolution (SISR) method based on the residual dense backprojection network (RDBPN) [21]. These networks significantly enhance the representation of image features by designing fine-grained deep learning frameworks such as residual blocks [22], dense blocks, and recursive blocks [23]. To improve the perceptual quality of the generated images, some methods introduce adversarial learning. For example, Jiang et al. added an edge enhancement module to the GAN architecture to improve the detail representation of remote sensing images and make the reconstruction results more visually realistic [24]. The TDEGAN [25] paper uses multi-level dense connections, residual connections, and shuffled attention (SA) to improve feature extraction capabilities. Meanwhile, the application of attention mechanism has also become a key technique to enhance the reconstruction fidelity [26,27]. Chen et al. achieved significant improvement in detail reconstruction by employing channel attention and window-based self-attention schemes, which enabled the model to focus more on key regions of the image [28].
2.2. Swin Transformer
Recently, the Transformer [29] model has attracted a lot of attention in the field of computer vision due to its excellent performance in the field of natural language processing (NLP) [30,31,32]. Similarly, in the field of remote sensing, Transformer has been widely used [33]. Transformer is uniquely suited to capture long-range dependencies in images [34,35], which is particularly important for processing complex visual patterns. However, in low-level visual tasks such as image reconstruction, direct application of standard Transformer faces challenges in terms of computational efficiency and memory usage due to the large number of pixels involved. To address these issues, we introduce Swin Transformer [36], an innovative variant designed specifically for image processing. Swin Transformer retains the core strengths of Transformer and optimizes computational efficiency by introducing locality-awareness and hierarchical structure, making it more suitable for pixel-intensive image reconstruction tasks.
2.3. RefSR
The reference-based super-resolution (RefSR) technique utilizes a high-resolution (HR) reference image similar to a low-resolution (LR) image to enhance the quality of image reconstruction. Compared to the traditional single-image super-resolution (SISR) method [37], RefSR is able to recover image details better, and performs excellently, especially in the scenes with similar contents [38,39]. The basic principle of RefSR is to supplement the missing content in LR images by extracting high-frequency information and details from the reference image, which usually involves the steps of feature extraction, alignment, and fusion to achieve more accurate pixel-level reconstruction. Representative models include the following: VDSR [7], which performs super-resolution reconstruction via multilayer convolutional neural networks (CNNs), and laid the foundation for the development of RefSR, although it is mainly used for SISR; SRGAN [12], which introduces generative adversarial networks (GANs) [40] to generate more realistic images, and whose adversarial training mechanism and perceptual loss can be adapted to RefSR; and DRCN [23], which improves the super-resolution effect through recursive structure and deep feature extraction, which is suitable to be used in conjunction with reference images. Recently, RefSR-GAN [41,42], as a specially designed RefSR model, combines the adversarial training of GAN and the reference image feature extraction, aiming to improve the reconstruction quality in remote sensing images. RefSR has a wide range of potential applications in the field of remote sensing image reconstruction.
3. Method
3.1. Overview
This study aims to enhance the quality of low-resolution (LR) images by reference images (Ref) and proposes a new reference-based super-resolution (RefSR) method based on a generative adversarial network (GAN) named STGAN. The overall workflow of the method is shown in Figure 1, which mainly includes a generator and two discriminators. The objective of the generator is to reconstruct the fine texture in the LR image using the reference image to produce a high-resolution (HR) image. To obtain clear and visually satisfactory super-resolution results, we introduce discriminators and in the image and gradient domains, respectively, where the gradient discriminator aims to focus on the local structure of the image to optimize sharpness and detail reconstruction by analyzing the image gradient information. This strategy inspired by RRSGAN [43] helps the model to accurately infer local intensity changes and better preserve geometric details and texture information. The generator learns finer appearance features and avoids distortion of geometric details by receiving feedback from both discriminators simultaneously. In this way, STGAN not only improves the image resolution, but also ensures the naturalness and accuracy of the reconstructed image, thus meeting the demand for high-quality image reconstruction.
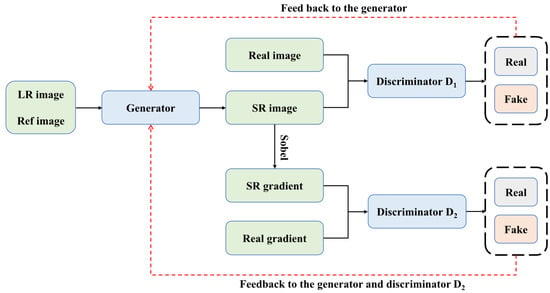
Figure 1.
The overall workflow of STGAN.
3.2. Network Architecture
3.2.1. Generator
As shown in Figure 2, the whole model generator consists of three parts: feature extraction, feature alignment and transfer, and high-quality image reconstruction.
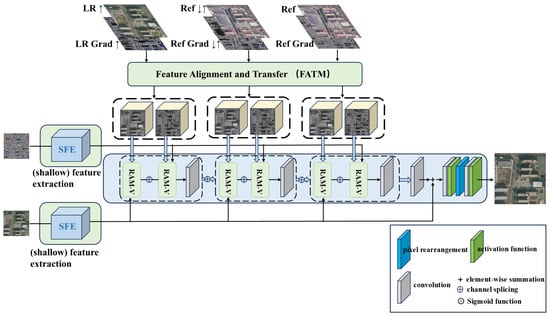
Figure 2.
The generator of STGAN consists of a feature extraction module, feature alignment and transfer module, and high-quality reconstruction module. The inputs are Ref image and LR image, and the SR image is finally generated by extracting the corresponding features.
- Feature extraction module (SFE):Given a low-quality (LR) input (where H, W, and C are the image height, width, and the number of input channels, respectively), as shown in Figure 3, a convolutional layer (using a 3 × 3 convolutional kernel as well as a Leaky ReLU activation function) is firstly utilized to extract the shallow feature as: , and secondly, the deep feature as:where consists of multiple residual blocks (ResBlocks). Each residual block contains two convolutional layers inside, both of which use a 3 × 3 convolutional kernel and the same number of filters to ensure that the dimensionality of the input and output is consistent. It has been shown [44,45] that deep convolutional networks help to improve super-resolution performance. Finally, the shallow feature and the deep feature are summed up by residual concatenation to obtain the final output feature: . The design of the residual block is crucial when training deep networks, as it effectively mitigates the problems of gradient vanishing and gradient explosion, ensuring that information can be effectively passed through the network. In addition, the role of the SFE module is to perform shallow feature processing, and it is capable of performing image feature extraction and gradient map feature processing independently, respectively.
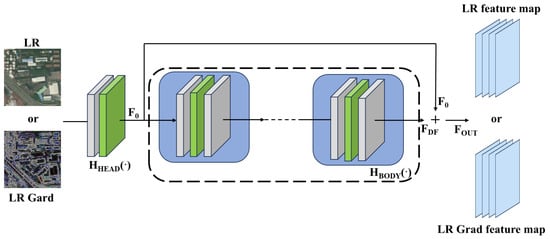 Figure 3. Generator feature extraction module with residual structure; inputs are LR image and LR gradient image.
Figure 3. Generator feature extraction module with residual structure; inputs are LR image and LR gradient image. - Feature alignment and transfer module:In this module, as shown in Figure 4, two CNN-Swin Transformer blocks (MCST) and a fusion convolution block (LFRC) are included. Each MCST block adopts a two-channel design based on CNN and a specific modification of Swin Transformer, respectively. The Patch Convolutional Module (PCM) is adapted with a feature extraction module specifically designed for extracting rich features from the input image as:where consists of multiple residual blocks. PCM is responsible for local feature extraction, capturing basic features such as edges and texture of the image through a series of residual convolutional layers. The input image is first passed through an initial convolutional layer to extract primary features, and then further processed through multiple ResBlocks to capture more complex features. To maintain training stability and facilitate feature transfer, PCM employs residual connections in each ResBlock. Finally, the shallow and deep features integrated through residual concatenation from the final output . Deepened Swin Transformer (DST) is an adaptation of the Swin Transformer architecture based on the 7 × 7 sliding window mechanism, and is specifically designed to capture global detailed features of an image. The module keeps the (S)W-MSA mechanism of Swin Transformer unchanged while adding a convolutional layer at the end of it to further enhance the local feature extraction capability. In addition, DST fixes the size of the feature maps at each stage to improve the stability and consistency of feature extraction while maintaining the global context modeling capability. In this design, PCM and DST extract local and global features independently. To enhance the representational capability of the model, LFRC performs channel-level fusion of the features extracted by PCM and DST to generate a rich feature representation that integrates both global and local information.
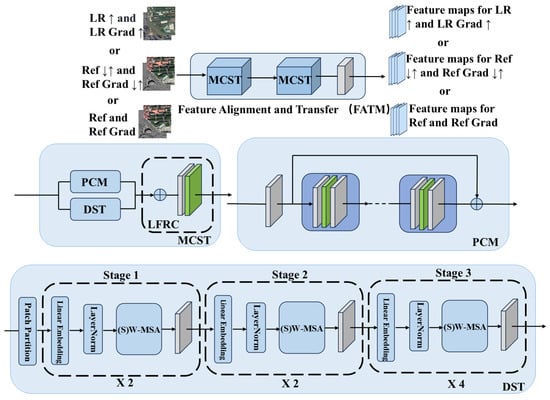 Figure 4. Generator feature alignment and transfer module with dual channels, where the symbol ↑ denotes a dual-triple upsampling process and ↓ denotes a dual-triple downsampling process. X2 represents a cycle of 2 and X4 represents a cycle of 4.In the RefSR method, the module is designed to process multiple input data streams, including low-resolution (LR) images, reference (Ref) images, and their corresponding gradient maps, separately. Processing a set of corresponding images and gradient maps at a time allows the module to simultaneously analyze and integrate information from different sources, thus significantly improving the quality of the super-resolution reconstruction. By fusing local and global information, the module not only enhances the overall performance of the image, but also uses the gradient information to further optimize the edge and texture details, resulting in more accurate feature alignment and generating more natural and realistic visual effects.
Figure 4. Generator feature alignment and transfer module with dual channels, where the symbol ↑ denotes a dual-triple upsampling process and ↓ denotes a dual-triple downsampling process. X2 represents a cycle of 2 and X4 represents a cycle of 4.In the RefSR method, the module is designed to process multiple input data streams, including low-resolution (LR) images, reference (Ref) images, and their corresponding gradient maps, separately. Processing a set of corresponding images and gradient maps at a time allows the module to simultaneously analyze and integrate information from different sources, thus significantly improving the quality of the super-resolution reconstruction. By fusing local and global information, the module not only enhances the overall performance of the image, but also uses the gradient information to further optimize the edge and texture details, resulting in more accurate feature alignment and generating more natural and realistic visual effects. - High-quality remote sensing image reconstruction moduleInstead of simply merging various image features as well as gradient feature map features, we employ a fine-grained feature fusion strategy. Our goal is to enhance the correlation between the two features while suppressing the less correlated information to optimize the texture transfer process. As shown in Figure 5, the first and second set of features are first fused at the channel layer, and then attention maps are generated through a series of convolutional layers. These attention maps are normalized by a sigmoid function and elementwise multiplied with the second set of features to strengthen the correlation between them. Next, the attention maps are again convolved and the results are summed with the previous results to further enrich the features. Finally, the enriched features are fused with the first set of features at the channel level to provide more accurate and enriched information for the subsequent texture transfer process. The Robustness Augmentation Module (RAM-V) is employed, the equation of which can be expressed as:where denotes the summed enriched features, and denote the first set of features and the second set of features, respectively, and and denote the computation including convolutional layers.
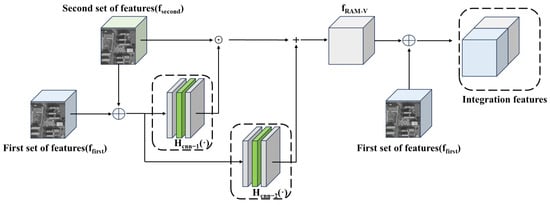 Figure 5. Structure of the RAM-V.
Figure 5. Structure of the RAM-V.
In the high-quality image reconstruction module, the data are first processed by the RAM-V module and CNN, followed by residual concatenation with the low-resolution data. After multiple convolutions and one-pixel rearrangement, the final output is a high-resolution super-resolution image, thus completing the entire super-resolution reconstruction process. In this case, the pixel rearrangement operation is shown in Figure 6.

Figure 6.
The input image size is 4 × 4 and 4 feature maps are generated after CNN convolution. The magnification is r = 2, i.e., the resolution is increased by two times and the final output image size is 8 × 8.
3.2.2. Discriminators
The structure of the discriminator is inspired by the classical VGG [46] network, but simplified and adapted to suit specific input sizes and feature extraction needs. The network consists of a series of convolutional layers, each followed by a Leaky ReLU [47] activation function that introduces nonlinearity to facilitate training. The convolutional layers are designed to gradually increase the number of channels and decrease the spatial dimensions, thus capturing image features from low to high levels. Specifically, the network first expands the number of channels of the input image through two convolutional layers, followed by three additional convolutional layers to further expand the number of channels and gradually reduce the spatial dimensions of the image. The processed feature maps are spread and passed through two fully connected layers, finally outputting a single value for judging the authenticity of the image. In this way, is able to effectively assess the quality of the generated image and provide feedback to the generative model to guide it in generating more realistic images.
The discriminator is based on the classical deep convolutional neural network architecture ResNet-50 [48], with customized modifications: the last two layers of the original model are removed to reduce the depth of the feature map, and a new convolutional layer is introduced to further reduce the number of channels in the feature map to meet the task requirements. During the input phase, the data were normalized to ensure that the inputs matched the expected distribution, a step that is crucial to improve model performance and stability. Subsequently, the normalized data are fed into the discriminator for feature extraction and the final output feature map reflects the high-level semantic information of the image. Through this well-designed feature extraction process, the discriminator is able to effectively capture the key features of the image, providing strong support for the discrimination task.
3.3. Loss Function
In order to generate high-quality images, multiple loss functions are usually combined to train the model. These loss functions include: reconstruction loss () [9], adversarial loss () [49], and perceptual loss () [50]. Due to the incorporation of gradient features, gradient losses are also used, including gradient reconstruction loss and gradient adversarial loss . The total loss is:
- Reconstruction Loss: It is used to measure the similarity between the reconstructed image and the high-resolution image to ensure that the reconstructed image is close to the target high-resolution image at the pixel level. The reconstruction loss is defined as:where denotes the HR image, denotes the SR image, = G(), G(·) denotes the generator, and denotes the LR image.
- Adversarial Loss: The discriminator in the generative adversarial network is used to generate more realistic images, and the generative ability of the model is enhanced by adversarial training. The optimization between generator G and discriminator is as follows:where aims to distinguish between the real and generated .
- Perceptual Loss: By mimicking the properties of the human visual system, a pre-trained network is used to measure the difference in perceptual space between the reconstructed image and the high-resolution image. The perceptual loss is defined as:where denotes the layer i output of ResNet-50.
- Gradient Loss: It is a key component used to maintain the image geometry in super-resolution tasks and ensures the sharpness of image edges and structures by limiting the second-order relationship between neighboring pixels. In the computation process, the gradient loss is obtained by comparing the gradient of a super-resolution image () with that of a high-resolution image (), i.e., by solving for the difference between neighboring pixels. This includes the gradient reconstruction loss () and the gradient adversarial loss (), defined as:where M(·) denotes the gradient operation and aims to distinguish between the real M () and generated M ().
3.4. Implementation Details
We downsampled the high-resolution (HR) images by double-cubic interpolation [51] and set the downsampling factor r = 4 to generate the low-resolution (LR) images required in the training phase. Each input batch contains four images, where the LR images have a size of 120 × 120 pixels and the corresponding HR images have a size of 480 × 480 pixels. During the training process, the weight hyperparameters , , , and were set for the different loss functions, which were 0.1, 0.001, 1, and 0.001, respectively. The Adam optimizer [52] was chosen for the model optimization, with parameters set to = 0.9, = 0.999, and . For both the generator and the discriminator, we set the learning rate to be , and halved it at 40 k, 60 k, and 80 k iterations during training. At the beginning of training, we perform a warm-up of 20 k iterations, applying only the reconstruction loss and the gradient reconstruction loss . After that, all the loss functions are combined and applied to the training of the model, with a total of 120 k iterations in the whole process. Our model is implemented based on the PyTorch v2.0.1 framework and trained using a single NVIDIA A100 GPU (NVIDIA, Santa Clara, CA, USA) to ensure computational efficiency and model performance.
4. Experiments
4.1. Datasets
In this study, we used the RRSSRD [43] public dataset as the training set, as shown in Figure 7. This dataset extensively covers a wide range of typical remote sensing scenarios, such as airports, bare ground, beaches, etc., with a total of 19 different categories, consisting of 4047 pairs of high-resolution (HR) reference images (Ref) in RGB bands, and the detailed dataset information is shown in Table 1.

Figure 7.
Selected RSSRD public datasets.

Table 1.
Information on RRSSRD public datasets.
To evaluate the performance of the model across different sources and geographic locations, we constructed four independent test datasets, each containing 40 pairs of HR-Ref images. The Ref images in all test sets were obtained from Google Earth 2019, maintaining a consistent spatial resolution of 0.6 m. The LR images were obtained by four-fold double-triple downsampling of the corresponding HR images, ensuring a uniform size of 120 × 120 pixels. To match the size of the HR image, the reference image was adjusted to 480 × 480 pixels. This setup ensured consistency and validity during the training and testing phases.
4.2. Assessment of Indicators
PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index) are standard evaluation metrics commonly used in the field of image super-resolution (SR) [53]. In order to evaluate the model performance more comprehensively, we also introduced metrics such as Perceptual Index (PI) [54], Learned Perceptual Image Patch Similarity (LPIPS) [55], Root Mean Square Error (RMSE), and Spectral Angle Mapping (SAM) [56], which are used to better measure the perceptual quality, reconstruction accuracy, and spectral consistency of an image.
- PSNR measures the image quality by calculating the mean square error (MSE) between the original image and the processed image, and its value is measured in decibels (dB), which reflects the pixel-level difference of the image, and usually, a higher PSNR value indicates a better-quality image. The PSNR is calculated as:where N is the total number of pixels in the image, are the values of the original and reconstructed images at the ith pixel, respectively, R is the maximum possible pixel value (for 8-bit images, R = 255), and MSE is the mean square error.
- SSIM further takes into account the brightness, contrast, and structural information of an image and evaluates the similarity of two images by comparing their differences in these aspects, with a value between 0 and 1, with the closer to 1 indicating the better quality of the image. The formula for calculating SSIM is:where and are the mean values of the images x and y, and are their variances, is their covariance, and and are small constants introduced to avoid a zero denominator.
- PI and Natural Image Quality Evaluator (NIQE) [57] can be used as metrics for the evaluation of real images. NIQE and PI were originally introduced as nonreference image quality assessment methods based on low-level statistical features [58]. NIQE is obtained by computing 36 identical Natural Scene Statistical (NSS) features from the same-sized patches in an image. PI is calculated by merging the criteria of Ma et al. and NIQE [59] as follows:
- LPIPS is a full reference metric that measures perceptual image similarity using a pre-trained deep network. We use the AlexNet [60] model to compute the distance in feature space. LPIPS can be computed using a given image y and the real image as follows:where and denote the height and width of layer lth, respectively, and denote the features corresponding to y and of layer lth at position (h, w), respectively, is the learned weight vector, and ⊙ is the elementwise multiplication operation.
- SAM is mainly used to measure the consistency between the reconstructed image and the original image in terms of spectral information, which calculates the angle between the spectral vectors of the reconstructed image and the corresponding pixels of the real image; the smaller the angle is, the more similar the spectral distributions of the two are, and the better the spectral information is retained. The formula is as follows:where M is the dimension (i.e., number of bands) of each spectral vector, and denote the value of the jth band at the ith pixel for image 1 and image 2, respectively, and N is the total number of pixels in the image.
- RMSE calculates the pixel error between the reconstructed image and the original high-resolution image; the smaller the value, the closer the reconstructed image is to the real image and the smaller the error. The formula is as follows:where N is the total number of data points, is the actual observed value, and is the model predicted value.
4.3. Quantitative and Qualitative Comparison of Different Methods
In this section, we provide a comprehensive comparison of the proposed method with the current state-of-the-art single-image super-resolution (SISR) and reference-based super-resolution (RefSR) methods on multiple test datasets. The SISR methods involved in the comparison include Bicubic, ESRGAN [13], SPSR [14], etc., whereas among the RefSR methods, we chose RRSGAN for the comparison to represent the state-of-the-art in the field. We aim to demonstrate the performance and advantages of the methods under different remote sensing scenarios and image quality evaluation metrics.
Six standard metrics, namely PSNR, SSIM, LPIPS, PI, RMSE, and SAM, were used to quantitatively evaluate the super-resolution (SR) results to ensure accuracy and comprehensiveness. In the results presentation, the best performing values in each row are highlighted in dark blue font. As shown in Table 2, STGAN performs best in several of the evaluated metrics, and in particular, it obtains the lowest values in all test sets of LIPIS and PI, indicating the best perceived quality. Secondly, it also outperforms the other models in terms of RMSE and SAM, especially with the lowest RMSE value and the smallest error.
Table 2.
Quantitative comparison of the different methods. ↓ indicates that the lower the value of the indicator the better and ↑ indicates that the higher the value of the indicator the better.
The results of the visual comparison are shown in Figure 8, providing a visual complement to the quantitative assessment. It is observed that the traditional bicubic interpolation, although capable of enlarging the image, is unable to create additional details, resulting in limited quality improvement. Conversely, deep-learning-based methods, especially CNN-based SISR techniques such as SPSR, VDSR, and ESRGAN, although capable of reconstructing texture details to a certain extent, often face the problem of blurring outlines. Taken together, STGAN performs excellently in terms of perceptual quality, image details, structural similarity, and spectral consistency, demonstrating its advantages in super-resolution reconstruction tasks.

Figure 8.
Visual contrast of the different methods, while the red box is a magnification of the localized area.
In the mean square error (MAE) difference between the output panchromatic sharpening results and the ground truth, as shown in Figure 9, the red areas indicate poorer generation while the blue areas indicate better results. Compared to other competing methods, our model exhibits smaller values of spatial and spectral distortion, further validating the effectiveness of the method. The experimental results show that the method successfully reduces the information redundancy and significantly improves the quality of the pan-sharpening results.

Figure 9.
Visual comparison of MAE for different models. MAE represents the mean absolute error for each spectral band.
4.4. Ablation Experiments
In this section, we validate the effectiveness of the key components of the proposed method, including the analysis of RefSR, the Robustness Augmentation Module (RAM-V), the use of specific gradient losses, and the hyperparametric tuning of the weights.
- Analysis of the effectiveness of the RefSR:To validate the effectiveness of the RefSR method, we conducted comparison experiments, keeping the same training strategy and network parameters. In the comparison experiments, the baseline method is constructed using only a convolutional neural network without the self-attention mechanism, while the STGAN(SISR) model removes all the reference image inputs and simulates the traditional SISR method by using only the LR images and their corresponding gradient maps for super-resolution reconstruction. The experimental results, as shown in Table 3, show that the RefSR method significantly improves the performance of super-resolution reconstruction through the synergistic effect of multiple image inputs and outperforms the SISR method and the baseline method. In addition, the gradual introduction of more depth-referenced features further enhances the reconstruction effect. Based on this, our method employs three levels of reference features to maximize the utilization of multi-image information, thus achieving better super-resolution reconstruction performance.
Table 3. Experiments on the effectiveness of the RefSR method, where STGAN (RefSR) is the model designed in this paper and STGAN (SISR) is the single-input (LR) version of STGAN.
- Effectiveness of RAM-V:In order to verify the effectiveness of RAM-V, we removed RAM-V in the feature transfer process and replaced it with direct channel-level fusion of the inputs and processed them through a convolutional neural network instead. As shown in Table 4, the use of RAM-V significantly improves the robustness of the model in different scenarios. This is because RAM-V is able to suppress the influence of irrelevant information in Ref features and focuses on the relevant regions between LR images and Ref images. Thus, RAM-V significantly improves the robustness of the model by suppressing irrelevant information and enhancing the correlation between the two.
Table 4. The effect of the RAM-V ablation experiment, which contains RAM-V, is the complete design of the STGAN in this paper.
- Effectiveness of gradient loss:We analyze the impact of gradient loss. “Baseline” refers to the use of only common SR loss functions, including reconstruction loss , adversarial loss , and perceptual loss . We added gradient-based reconstruction loss and gradient-based adversarial loss in turn. As shown in Table 5, the gradient loss significantly improves the PI and LPIPS compared to the baseline model, suggesting that it produces more realistic visuals.
Table 5. Gradient loss effect ablation experiments, where the complete SATGAN designed in this paper contains and .
- Hyperparameter Tuning of Loss Weight:In our experiments, we used the same training strategy and network parameters, only adjusting the values of ///. As shown in Table 6, the model using the parameter combination /// = 0.1/0.001/1/0.001 performs well on several key metrics. On PSNR and SSIM metrics, the parameter combination achieves the best results on different test sets several times, indicating that the model is able to effectively improve the quality of image reconstruction and maintain structural consistency. Meanwhile, the excellent performance on the LPIPS metric further validates the model’s advantage in perceptual quality. These results indicate that the parameter combination has good robustness and wide adaptability, and is capable of achieving high-quality image super-resolution reconstruction in a variety of scenarios.
Table 6. Results for different ///. In each row, the best results are highlighted in dark blue font.
5. Conclusions
In this paper, we explore the use of reference (Ref) images to reconstruct low-resolution (LR) images for remote sensing missions. We innovatively design STGAN, a hypersegmented reconstruction model for remote sensing images that fuses Generative Adversarial Networks (GANs) with a self-attention mechanism. The model provides an end-to-end network architecture that integrates a feature extraction module for residual structure and a dual-channel feature alignment and transfer mechanism based on CNN and Swin Transformer. This mechanism is able to accurately extract and align the features of Ref images, which effectively enhances the texture details of LR images and achieves high-quality super-resolution reconstruction of remote sensing images. Through extensive experimental validation, the STGAN model demonstrates good effectiveness and robustness on several standard datasets, proving the significant potential of the STGAN model in super-resolution reconstruction of remote sensing images. In the next step, we will investigate the performance of the RefSR method in improving the image quality with the existing scaling factors, and explore its efficiency and effectiveness in dealing with larger scaling factors. In addition, we will work on optimizing the computational efficiency of the model to improve utility and scalability while maintaining high-quality output.
Author Contributions
Conceptualization, W.H. and X.Z.; methodology, W.H. and X.Z.; software, W.H. and Y.Z.; validation, X.Z. and S.Y.; formal analysis, W.H.; investigation, W.H. and X.Z.; resources, X.Z., S.Y. and Y.Z.; writing—original draft preparation, W.H. and X.Z.; writing—review and editing, W.H., Q.Z. and N.H.; project administration, X.Z.; funding acquisition, X.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Qinghai Province Applied Basic Research Program project (2024-ZJ-716).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article; further inquiries can be directed to the corresponding author.
Acknowledgments
The authors are grateful for the support of the Qinghai Provincial Laboratory for Intelligent Computing and Application platform.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chaminé, H.I.; Pereira, A.J.; Teodoro, A.C.; Teixeira, J. Remote sensing and GIS applications in earth and environmental systems sciences. SN Appl. Sci. 2021, 3, 870. [Google Scholar] [CrossRef]
- Pan, B.; Shi, Z.; Xu, X.; Shi, T.; Zhang, N.; Zhu, X. CoinNet: Copy initialization network for multispectral imagery semantic segmentation. IEEE Geosci. Remote Sens. Lett. 2018, 16, 816–820. [Google Scholar] [CrossRef]
- Mathieu, R.; Freeman, C.; Aryal, J. Mapping private gardens in urban areas using object-oriented techniques and very high-resolution satellite imagery. Landsc. Urban Plan. 2007, 81, 179–192. [Google Scholar] [CrossRef]
- Li, W.; He, C.; Fang, J.; Zheng, J.; Fu, H.; Yu, L. Semantic segmentation-based building footprint extraction using very high-resolution satellite images and multi-source GIS data. Remote Sens. 2019, 11, 403. [Google Scholar] [CrossRef]
- Yuan, S.; Dong, R.; Zheng, J.; Wu, W.; Zhang, L.; Li, W.; Fu, H. Long time-series analysis of urban development based on effective building extraction. In Proceedings of the Geospatial Informatics X; SPIE: Bellingham, WA, USA, 2020; Volume 11398, pp. 192–199. [Google Scholar]
- Yang, W.; Zhang, X.; Tian, Y.; Wang, W.; Xue, J.H.; Liao, Q. Deep learning for single image super-resolution: A brief review. IEEE Trans. Multimed. 2019, 21, 3106–3121. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Yu, J.; Fan, Y.; Yang, J.; Xu, N.; Wang, Z.; Wang, X.; Huang, T. Wide activation for efficient and accurate image super-resolution. arXiv 2018, arXiv:1808.08718. [Google Scholar]
- Wang, P.; Bayram, B.; Sertel, E. A comprehensive review on deep learning based remote sensing image super-resolution methods. Earth-Sci. Rev. 2022, 232, 104110. [Google Scholar] [CrossRef]
- Yue, L.; Shen, H.; Li, J.; Yuan, Q.; Zhang, H.; Zhang, L. Image super-resolution: The techniques, applications, and future. Signal Process. 2016, 128, 389–408. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Aitken, A.; Tejani, A.; Wang, Z.; Shi, W. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 4681–4690. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ma, C.; Rao, Y.; Cheng, Y.; Chen, C.; Lu, J.; Zhou, J. Structure-preserving super resolution with gradient guidance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7769–7778. [Google Scholar]
- Liu, Z.S.; Siu, W.C.; Chan, Y.L. Reference based face super-resolution. IEEE Access 2019, 7, 129112–129126. [Google Scholar] [CrossRef]
- Zheng, H.; Ji, M.; Wang, H.; Liu, Y.; Fang, L. Crossnet: An end-to-end reference-based super resolution network using cross-scale warping. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 88–104. [Google Scholar]
- Zhang, Z.; Wang, Z.; Lin, Z.; Qi, H. Image super-resolution by neural texture transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7982–7991. [Google Scholar]
- Zhang, L.; Li, X.; He, D.; Li, F.; Wang, Y.; Zhang, Z. Rrsr: Reciprocal reference-based image super-resolution with progressive feature alignment and selection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 648–664. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part IV 13; Springer: Berlin/Heidelberg, Germany, 2014; pp. 184–199. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient subpixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Pan, Z.; Ma, W.; Guo, J.; Lei, B. Super-resolution of single remote sensing image based on residual dense backprojection networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7918–7933. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Wang, G.; Lu, T.; Jiang, J. Edge-enhanced GAN for remote sensing image superresolution. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5799–5812. [Google Scholar] [CrossRef]
- Guo, M.; Xiong, F.; Zhao, B.; Huang, Y.; Xie, Z.; Wu, L.; Chen, X.; Zhang, J. TDEGAN: A Texture-Detail-Enhanced Dense Generative Adversarial Network for Remote Sensing Image Super-Resolution. Remote Sens. 2024, 16, 2312. [Google Scholar] [CrossRef]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Wang, Y.; Liu, Y.; Zhao, S.; Li, J.; Zhang, L. CAMixerSR: Only Details Need More “Attention”. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 25837–25846. [Google Scholar]
- Chen, X.; Wang, X.; Zhou, J.; Qiao, Y.; Dong, C. Activating more pixels in image super-resolution transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22367–22377. [Google Scholar]
- Vaswani, A. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems s (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Mikolov, T. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Sutskever, I. Sequence to Sequence Learning with Neural Networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Sarzynska-Wawer, J.; Wawer, A.; Pawlak, A.; Szymanowska, J.; Stefaniak, I.; Jarkiewicz, M.; Okruszek, L. Detecting formal thought disorder by deep contextualized word representations. Psychiatry Res. 2021, 304, 114135. [Google Scholar] [CrossRef] [PubMed]
- Casini, L.; Marchetti, N.; Montanucci, A.; Orrù, V.; Roccetti, M. A human–AI collaboration workflow for archaeological sites detection. Sci. Rep. 2023, 13, 8699. [Google Scholar] [CrossRef]
- Cao, J.; Liang, J.; Zhang, K.; Li, Y.; Zhang, Y.; Wang, W.; Gool, L.V. Reference-based image super-resolution with deformable attention transformer. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 325–342. [Google Scholar]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning texture transformer network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5791–5800. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Li, K.; Yang, S.; Dong, R.; Wang, X.; Huang, J. Survey of single image super-resolution reconstruction. IET Image Process. 2020, 14, 2273–2290. [Google Scholar] [CrossRef]
- Su, H.; Li, Y.; Xu, Y.; Fu, X.; Liu, S. A review of deep-learning-based super-resolution: From methods to applications. Pattern Recognit. 2024, 157, 110935. [Google Scholar] [CrossRef]
- Zhang, L.; Li, X.; He, D.; Li, F.; Ding, E.; Zhang, Z. LMR: A Large-Scale Multi-Reference Dataset for Reference-based Super-Resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 13118–13127. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative adversarial networks: An overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Tu, Z.; Yang, X.; He, X.; Yan, J.; Xu, T. RGTGAN: Reference-Based Gradient-Assisted Texture-Enhancement GAN for Remote Sensing Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5607221. [Google Scholar] [CrossRef]
- Wang, X.; Sun, L.; Chehri, A.; Song, Y. A review of GAN-based super-resolution reconstruction for optical remote sensing images. Remote Sens. 2023, 15, 5062. [Google Scholar] [CrossRef]
- Dong, R.; Zhang, L.; Fu, H. RRSGAN: Reference-based super-resolution for remote sensing image. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–17. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin transformer embedding UNet for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Xu, J.; Li, Z.; Du, B.; Zhang, M.; Liu, J. Reluplex made more practical: Leaky ReLU. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 8–10 July 2020; pp. 1–7. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14; Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Li, Y.; Qi, F.; Wan, Y. Improvements on bicubic image interpolation. In Proceedings of the 2019 IEEE 4th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chengdu, China, 20–22 December 2019; Volume 1, pp. 1316–1320. [Google Scholar]
- Kingma, D.P. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Irani, M.; Peleg, S. Super resolution from image sequences. In Proceedings of the [1990] Proceedings, 10th International Conference on Pattern Recognition, Atlantic City, NJ, USA, 16–21 June 1990; Volume 2, pp. 115–120. [Google Scholar]
- Blau, Y.; Mechrez, R.; Timofte, R.; Michaeli, T.; Zelnik-Manor, L. The 2018 PIRM challenge on perceptual image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
- Yuhas, R.H.; Goetz, A.F.; Boardman, J.W. Discrimination among semi-arid landscape endmembers using the spectral angle mapper (SAM) algorithm. In Proceedings of the JPL, Summaries of the Third Annual JPL Airborne Geoscience Workshop. Volume 1: AVIRIS Workshop, Pasadena, CA, USA, 1–5 June 1992. [Google Scholar]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Liu, L.; Liu, B.; Huang, H.; Bovik, A.C. No-reference image quality assessment based on spatial and spectral entropies. Signal Process. Image Commun. 2014, 29, 856–863. [Google Scholar] [CrossRef]
- Ma, C.; Yang, C.Y.; Yang, X.; Yang, M.H. Learning a no-reference quality metric for single-image super-resolution. Comput. Vis. Image Underst. 2017, 158, 1–16. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).