


An Instance Segmentation Method for Insulator Defects Based on an Attention Mechanism and Feature Fusion Network

Abstract
1. Introduction
2. Literature Review
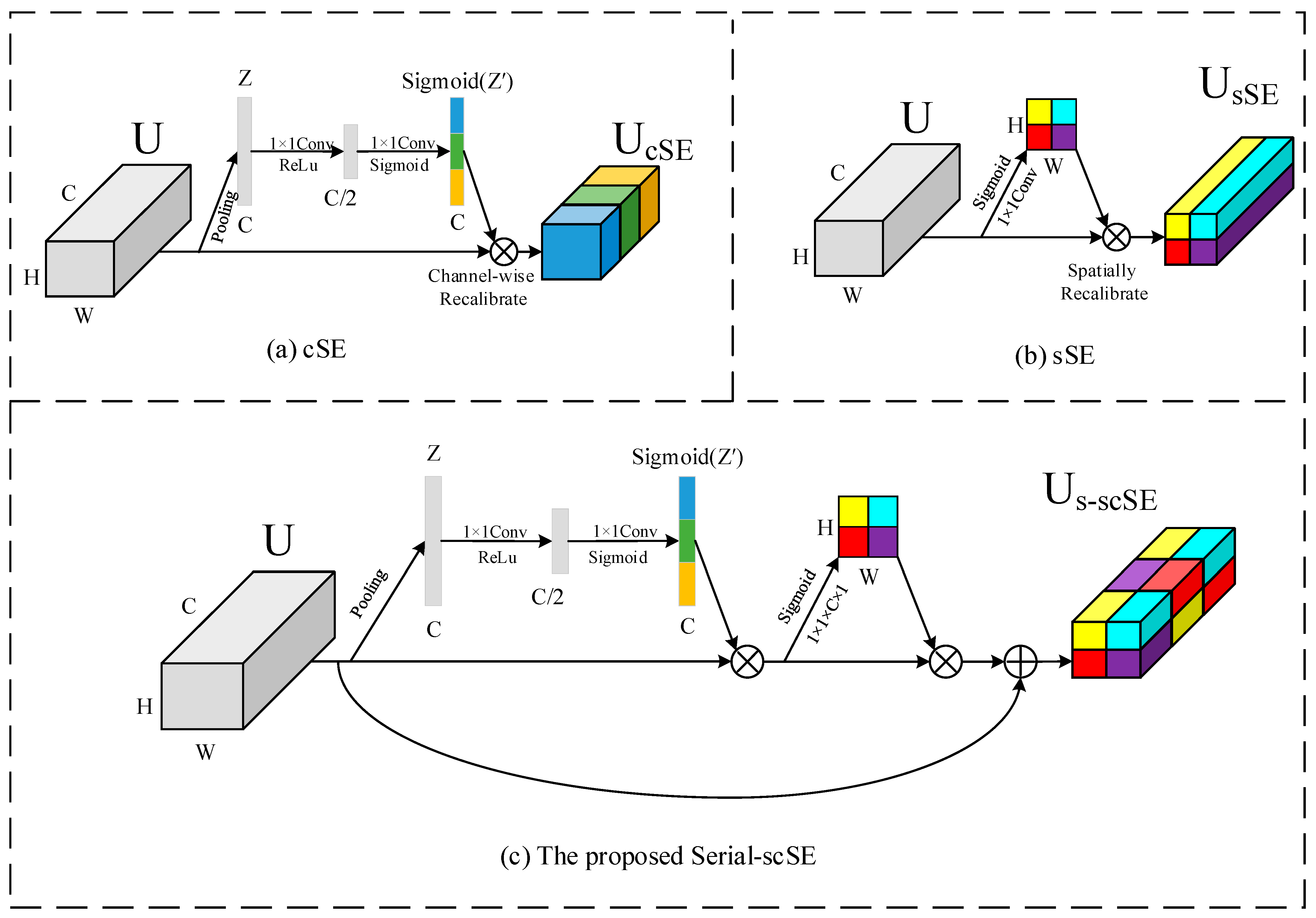
- The backbone network is modified to MobileNetV2, aiming to greatly reduce the computation of the model. Meanwhile, an improved scSE module with a serial structure and skip connections is proposed and embedded into the MobileNetV2 to enhance the feature extraction.
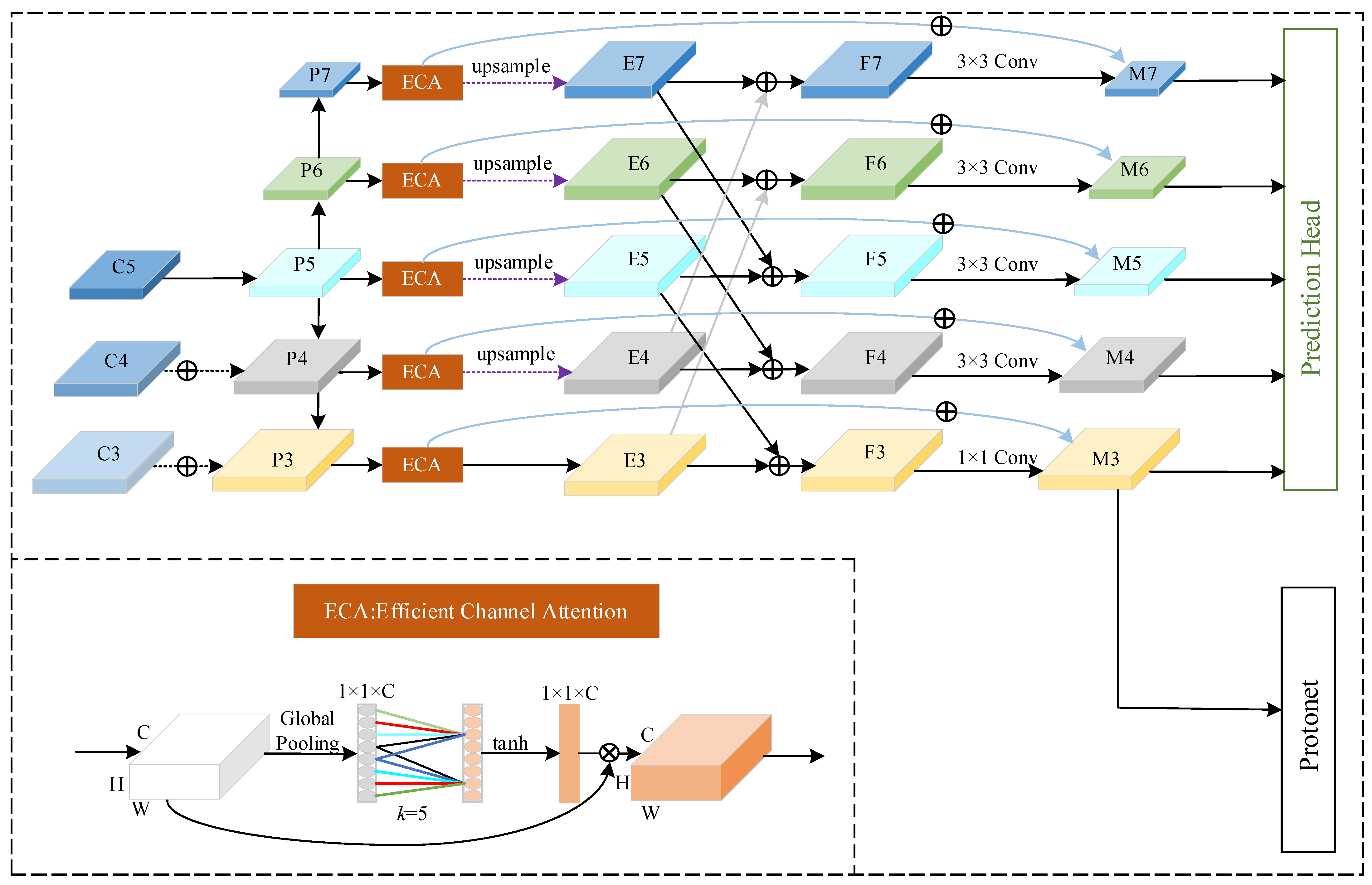
- A feature fusion structure is proposed in the FPN. We first process P3–P7 with ECA-Net and up-sample the feature maps to the same size. Then, P3 and P4 are added to the top layers, while P5–P7 are added to the bottom layers across double layers. After the feature maps are fused, they are down-sampled to the original size for the next modules in the model.
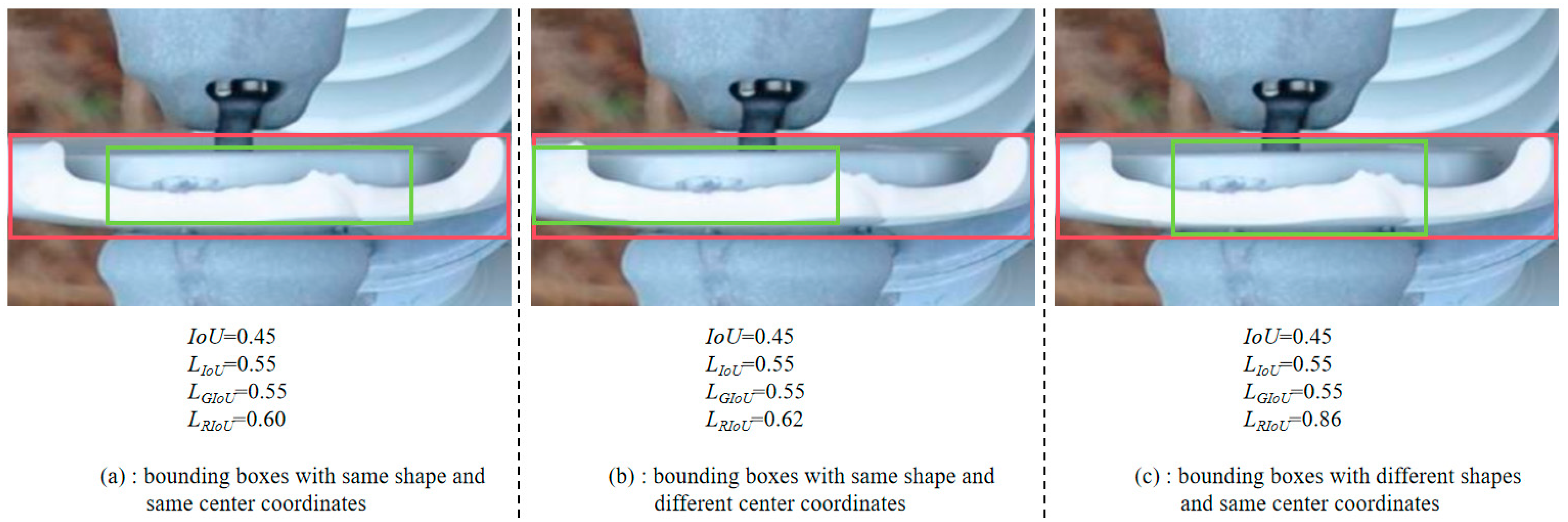
- A bounding box loss function that covers the area deviation, center deviation, and shape deviation is designed to better limit the generation of redundant bounding boxes, namely RIoU Loss. The model is trained to generate bounding boxes more accurately with the new loss function.
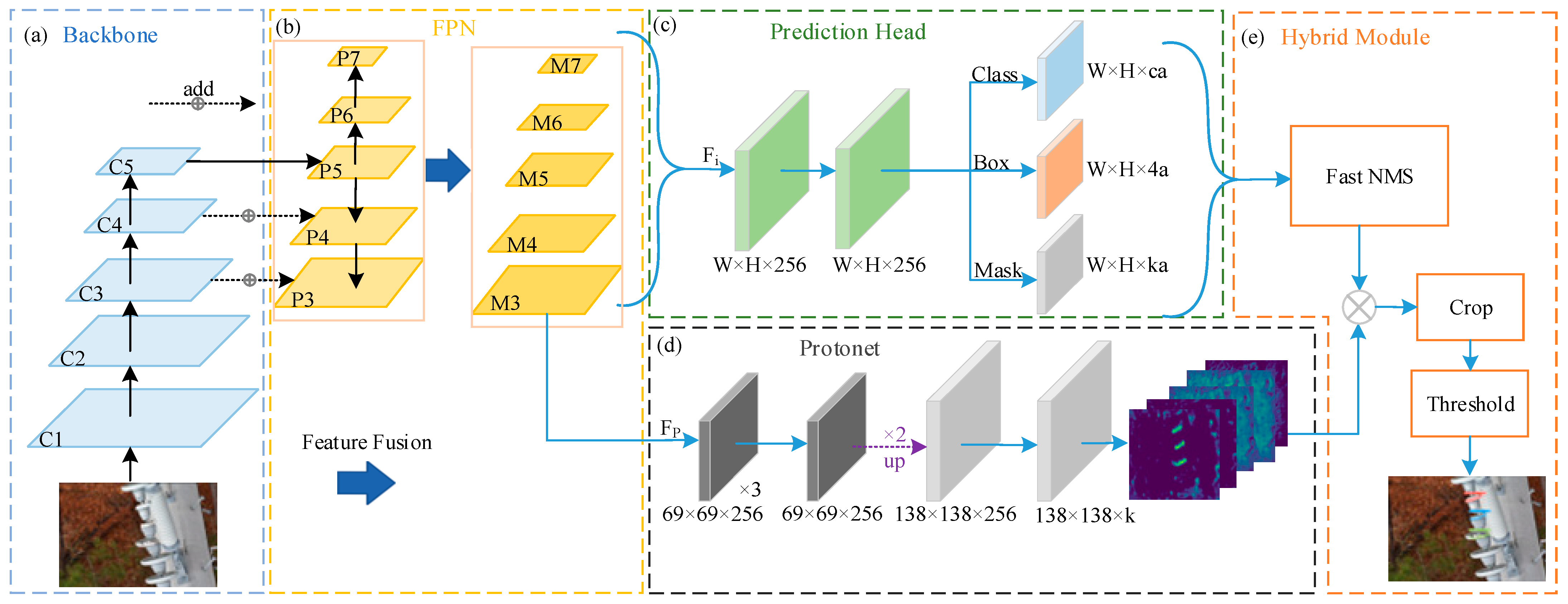
3. Instance Segmentation Framework Based on Improved YOLACT
3.1. MobileNetV2 Embedded with Serial-scSE Attention Module
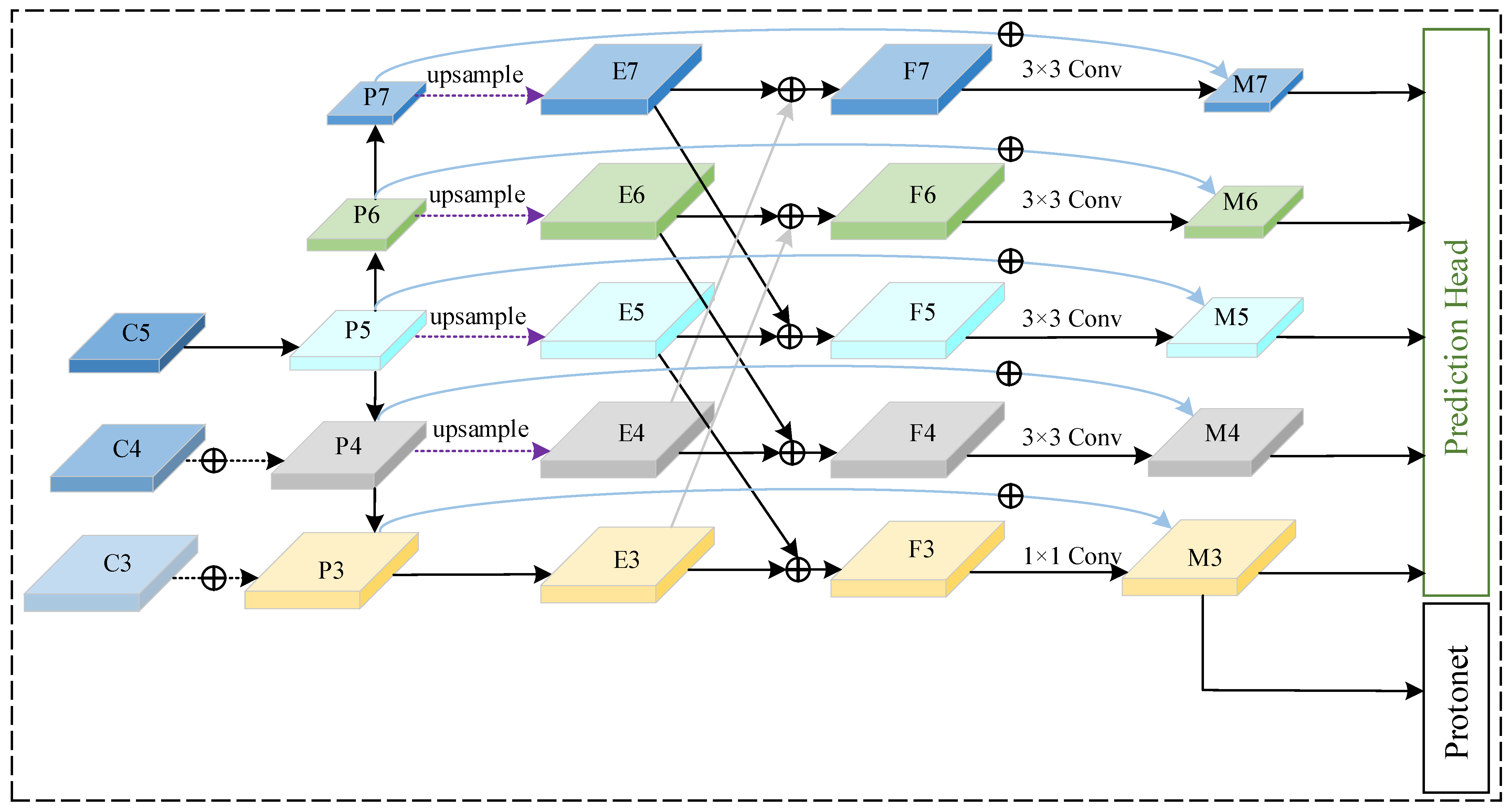
3.2. Modified FPN Based on Feature Fusion
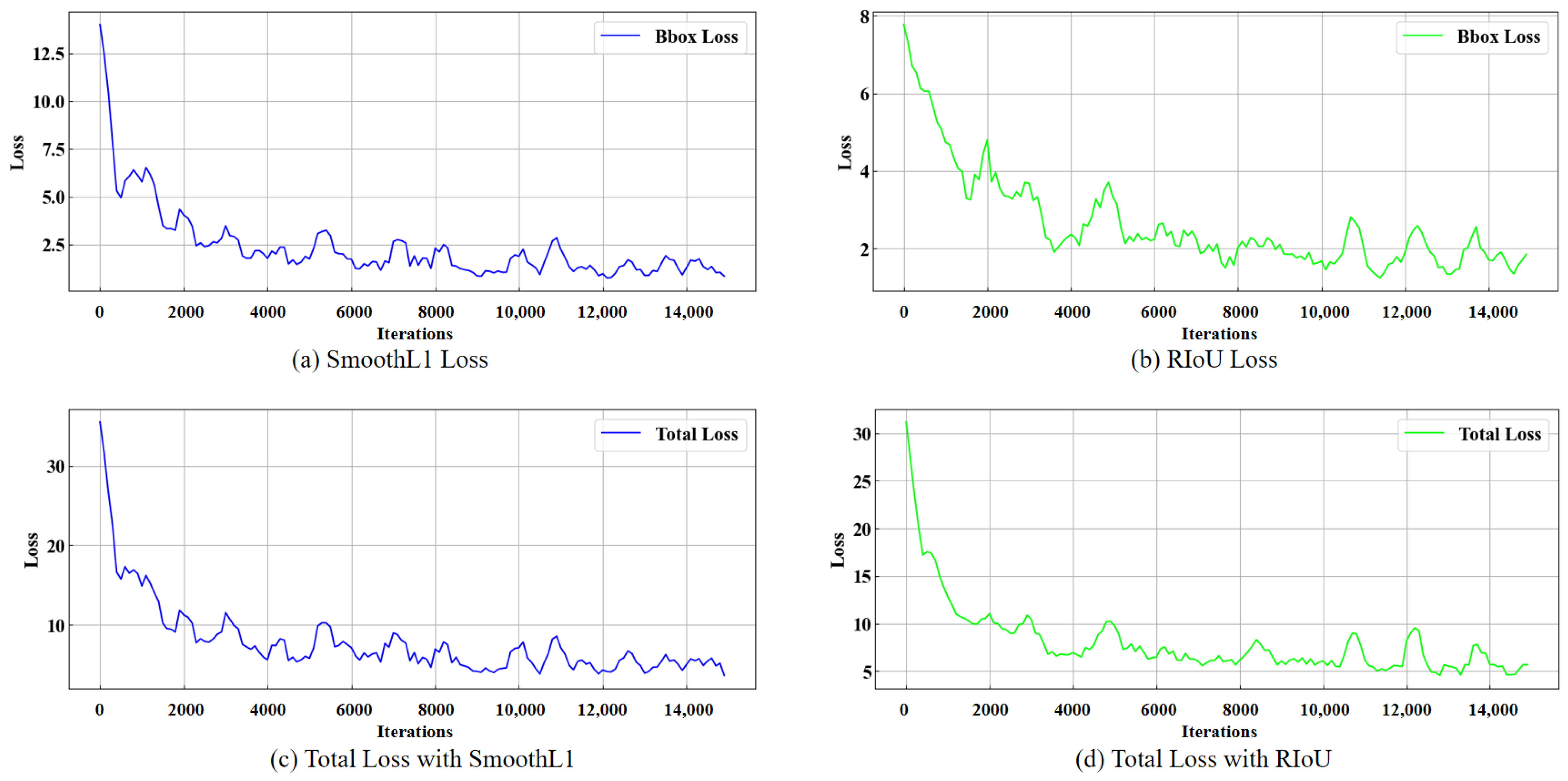
3.3. Improved Bounding Box Loss Function for Redundant Boxes
4. Experiment and Analysis
4.1. Environment and Data Set Settings
4.2. Visualization Results of the Model
4.3. Ablation Experiments
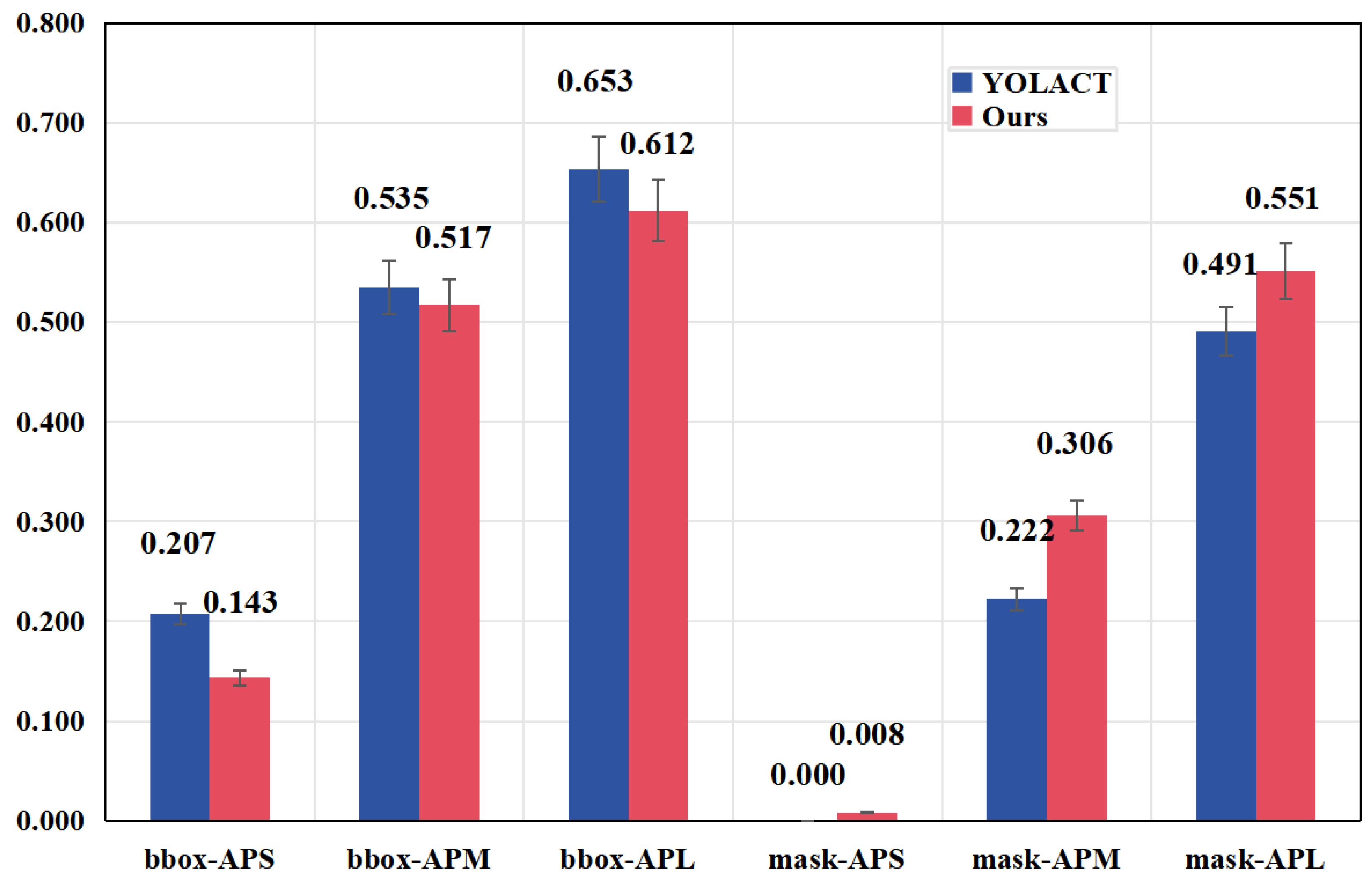
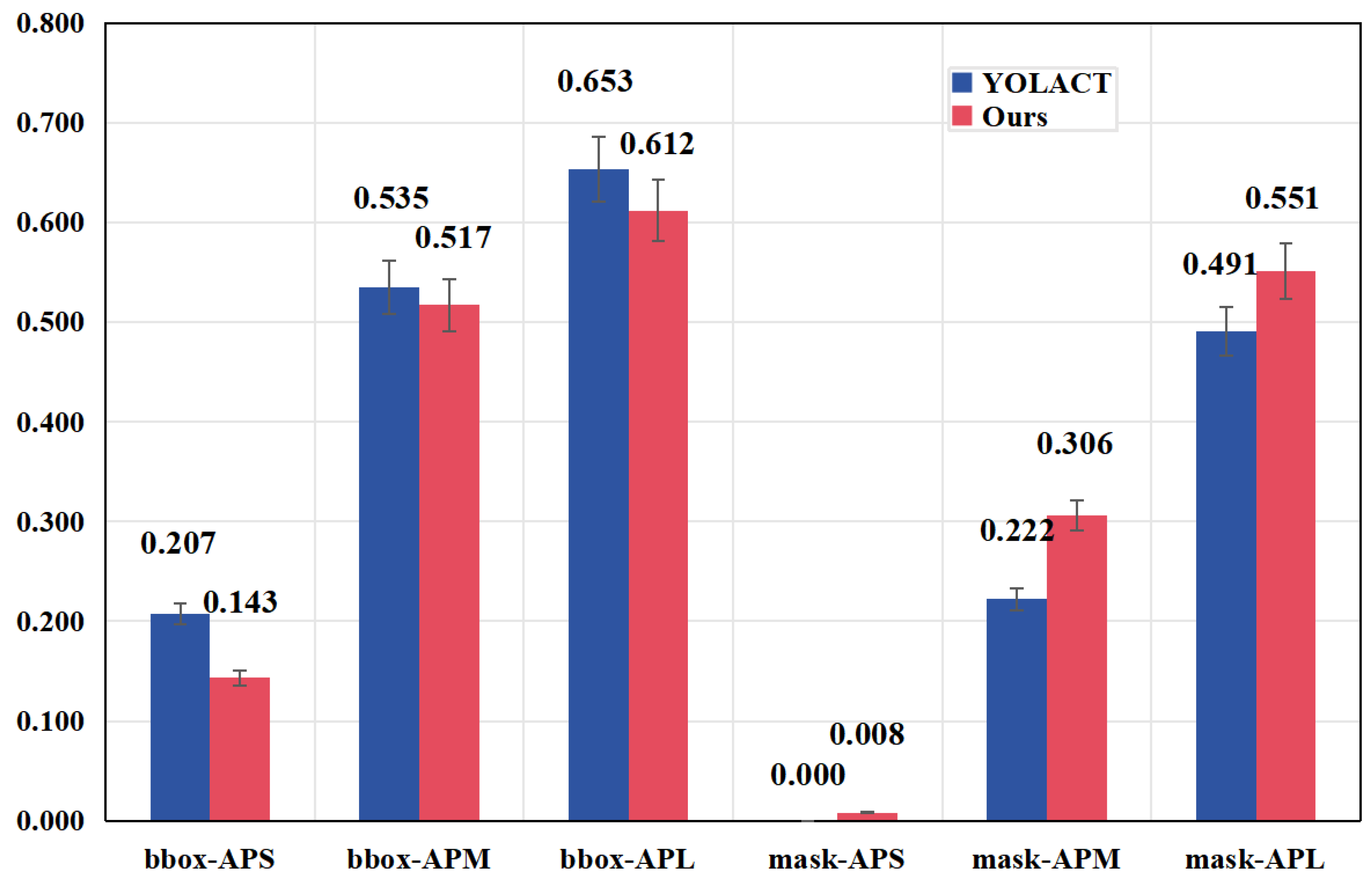
4.4. Comparison with Other Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ma, Y.; Zhang, Y. Insulator detection algorithm based on improved Faster-RCNN. J. Comput. Appl. 2022, 42, 631–637. [Google Scholar]
- Luo, X.; Yu, F.; Peng, Y. UAV power grid inspection defect detection based on deep learning. Power Syst. Prot. Control 2021, 50, 132–139. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, Y.; Wang, L.; Mei, H.; Zhang, Z.; Wen, L. Infrared image segmentation and temperature reading of composite insulator strings based on mask-rcnn algorithm. High Volt. Electr. 2021, 57, 87–94. [Google Scholar] [CrossRef]
- Yi, J.; Wu, P.; Jiang, M.; Huang, Q.; Hoeppner, D.J.; Metaxas, D.N. Attentive neural cell instance segmentation. Med. Image Anal. 2019, 55, 228–240. [Google Scholar] [CrossRef] [PubMed]
- Panero, M.R.; Schiopu, I.; Cornelis, B.; Munteanu, A. Real-time instance segmentation of traffic videos for embedded devices. Sensors 2021, 21, 275. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Xiao, L.; Liu, Z.; Liu, M.; Fang, P.; Chen, X.; Yu, J.; Liu, J.; Cai, J. SMR-RS: An Improved Mask R-CNN Specialized for Rolled Rice Stubble Row Segmentation. Appl. Sci. 2023, 13, 9136. [Google Scholar] [CrossRef]
- Hafiz, A.M.; Bhat, G.M. A survey on instance segmentation: State of the art. Int. J. Multimed. Inf. Retr. 2020, 9, 171–189. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent spatial and channel ‘squeeze & excitation’in fully convolutional networks. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2018: 21st International Conference, Granada, Spain, 16–20 September 2018; pp. 421–429. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 10 June 2020; pp. 11534–11542. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Simultaneous detection and segmentation. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 297–312. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask scoring r-cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6409–6418. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. Pointrend: Image segmentation as rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 10 June 2020; pp. 9799–9808. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron 2. Available online: https://github.com/facebookresearch/detectron2 (accessed on 15 July 2023).
- Liu, S.; Jia, J.; Fidler, S.; Urtasun, R. Sgn: Sequential grouping networks for instance segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3496–3504. [Google Scholar]
- Gao, N.; Shan, Y.; Wang, Y.; Zhao, X.; Yu, Y.; Yang, M.; Huang, K. Ssap: Single-shot instance segmentation with affinity pyramid. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 642–651. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Chen, H.; Sun, K.; Tian, Z.; Shen, C.; Huang, Y.; Yan, Y. Blendmask: Top-down meets bottom-up for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 10 June 2020; pp. 8573–8581. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: A Simple and Strong Anchor-Free Object Detector. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1922–1933. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Dong, M.; Ren, M.; Wu, Z.; Guo, C.; Zhuang, T.; Pischler, O.; Xie, J. Automatic fault diagnosis of infrared insulator images based on image instance segmentation and temperature analysis. IEEE Trans. Instrum. Meas. 2020, 69, 5345–5355. [Google Scholar] [CrossRef]
- Han, G.; Zhang, M.; Wu, W.; He, M.; Liu, K.; Qin, L.; Liu, X. Improved U-Net based insulator image segmentation method based on attention mechanism. Energy Rep. 2021, 7, 210–217. [Google Scholar] [CrossRef]
- Ma, J.; Qian, K.; Zhang, X.; Ma, X. Weakly supervised instance segmentation of electrical equipment based on RGB-T automatic annotation. IEEE Trans. Instrum. Meas. 2020, 69, 9720–9731. [Google Scholar] [CrossRef]
- Li, T.; Zhou, J.; Song, G.; Wen, Y.; Ye, Y.; Chen, S. Insulator infrared image segmentation algorithm based on dynamic mask and box annotation. In Proceedings of the 2021 11th International Conference on Power and Energy Systems, Shanghai, China, 18–20 December 2021; pp. 432–435. [Google Scholar]
- Wang, S.; Liu, Y.; Qing, Y.; Wang, C.; Lan, T.; Yao, R. Detection of Insulator Defects with Improved ResNeSt and Region Proposal Network. IEEE Access 2020, 8, 184841–184850. [Google Scholar] [CrossRef]
- Qiu, Z.; Zhu, X.; Liao, C.; Shi, D.; Qu, W. Detection of Transmission Line Insulator Defects Based on an Improved Lightweight YOLOv4 Model. Appl. Sci. 2022, 12, 1207. [Google Scholar] [CrossRef]
- Antwi-Bekoe, E.; Liu, G.; Ainam, J.P.; Sun, G.; Xie, X. A deep learning approach for insulator instance segmentation and defect detection. Neural Comput. Appl. 2022, 34, 7253–7269. [Google Scholar] [CrossRef]
- Xuan, Z.; Ding, J.; Mao, J. Intelligent Identification Method of Insulator Defects Based on CenterMask. IEEE Access 2022, 10, 59772–59781. [Google Scholar] [CrossRef]
- Gu, W.; Bai, S.; Kong, L. A review on 2D instance segmentation based on deep neural networks. Image Vis. Comput. 2022, 120, 104401. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lewis, D.; Kulkarni, P. Insulator Defect Detection. Available online: https://ieee-dataport.org/competitions/insulator-defect-detection (accessed on 29 March 2023).
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. Solov2: Dynamic and fast instance segmentation. Adv. Neural Inform. Proc. Syst. 2020, 33, 17721–17732. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT++ Better Real-Time Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1108–1121. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | FPN+ | RIoU Loss | Mask mAP/% | Bbox mAP/% | Mask AP50/% | Bbox AP50/% | FPS |
|---|---|---|---|---|---|---|---|---|
| YOLACT | ResNet-101 | × | × | 31.32 | 55.28 | 74.94 | 95.05 | 34.9 |
| Model1 | MobileNetV2 | × | × | 30.53 | 50.40 | 74.89 | 92.87 | 78.0 |
| Model2 | √ | × | 33.28 | 51.30 | 75.23 | 92.41 | 72.3 | |
| Model3 | × | √ | 34.15 | 51.42 | 75.11 | 92.83 | 78.1 | |
| Ours | √ | √ | 37.14 | 51.98 | 76.82 | 92.55 | 72.3 |
| Model | Backbone | FPN+ | RIoU Loss | Mask mAP/% | Bbox mAP/% | Mask AP50/% | Bbox AP50/% | FPS |
|---|---|---|---|---|---|---|---|---|
| YOLACT | ResNet-101 | × | × | 31.32 | 55.28 | 74.94 | 95.05 | 34.9 |
| Model1 | √ | × | 34.54 | 56.91 | 76.43 | 95.29 | 29.7 | |
| Model2 | × | √ | 34.87 | 57.12 | 76.72 | 95.16 | 34.8 | |
| Model3 | √ | √ | 38.66 | 58.05 | 77.50 | 95.47 | 29.8 |
| Model | Backbone | FPN+ | RIoU Loss | Backbone | FPN | Detect | Others | Total |
|---|---|---|---|---|---|---|---|---|
| YOLACT | ResNet-101 | × | × | 13.13 | 0.87 | 15.47 | 5.11 | 34.58 |
| Model1 | √ | × | 13.25 | 3.22 | 15.50 | 5.10 | 37.07 | |
| Model2 | × | √ | 13.18 | 0.87 | 15.23 | 5.22 | 34.50 | |
| Model3 | √ | √ | 13.19 | 3.21 | 15.58 | 5.25 | 37.23 | |
| Model4 | MobileNetV2 | × | × | 5.66 | 0.90 | 8.01 | 5.10 | 19.67 |
| Model5 | √ | × | 5.48 | 3.20 | 8.03 | 5.22 | 21.93 | |
| Model6 | × | √ | 5.52 | 0.89 | 8.15 | 5.15 | 19.71 | |
| Ours | √ | √ | 5.59 | 3.23 | 8.02 | 5.15 | 21.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Deng, Q.; Xian, R.; Tao, X.; Zhou, Z. An Instance Segmentation Method for Insulator Defects Based on an Attention Mechanism and Feature Fusion Network. Appl. Sci. 2024, 14, 3623. https://doi.org/10.3390/app14093623
Wu J, Deng Q, Xian R, Tao X, Zhou Z. An Instance Segmentation Method for Insulator Defects Based on an Attention Mechanism and Feature Fusion Network. Applied Sciences. 2024; 14(9):3623. https://doi.org/10.3390/app14093623
Chicago/Turabian StyleWu, Junpeng, Qitong Deng, Ran Xian, Xinguang Tao, and Zhi Zhou. 2024. "An Instance Segmentation Method for Insulator Defects Based on an Attention Mechanism and Feature Fusion Network" Applied Sciences 14, no. 9: 3623. https://doi.org/10.3390/app14093623
APA StyleWu, J., Deng, Q., Xian, R., Tao, X., & Zhou, Z. (2024). An Instance Segmentation Method for Insulator Defects Based on an Attention Mechanism and Feature Fusion Network. Applied Sciences, 14(9), 3623. https://doi.org/10.3390/app14093623