

Transient Analysis of a Selective Partial-Update LMS Algorithm

 , , , , and
, , , , and
Abstract
1. Introduction
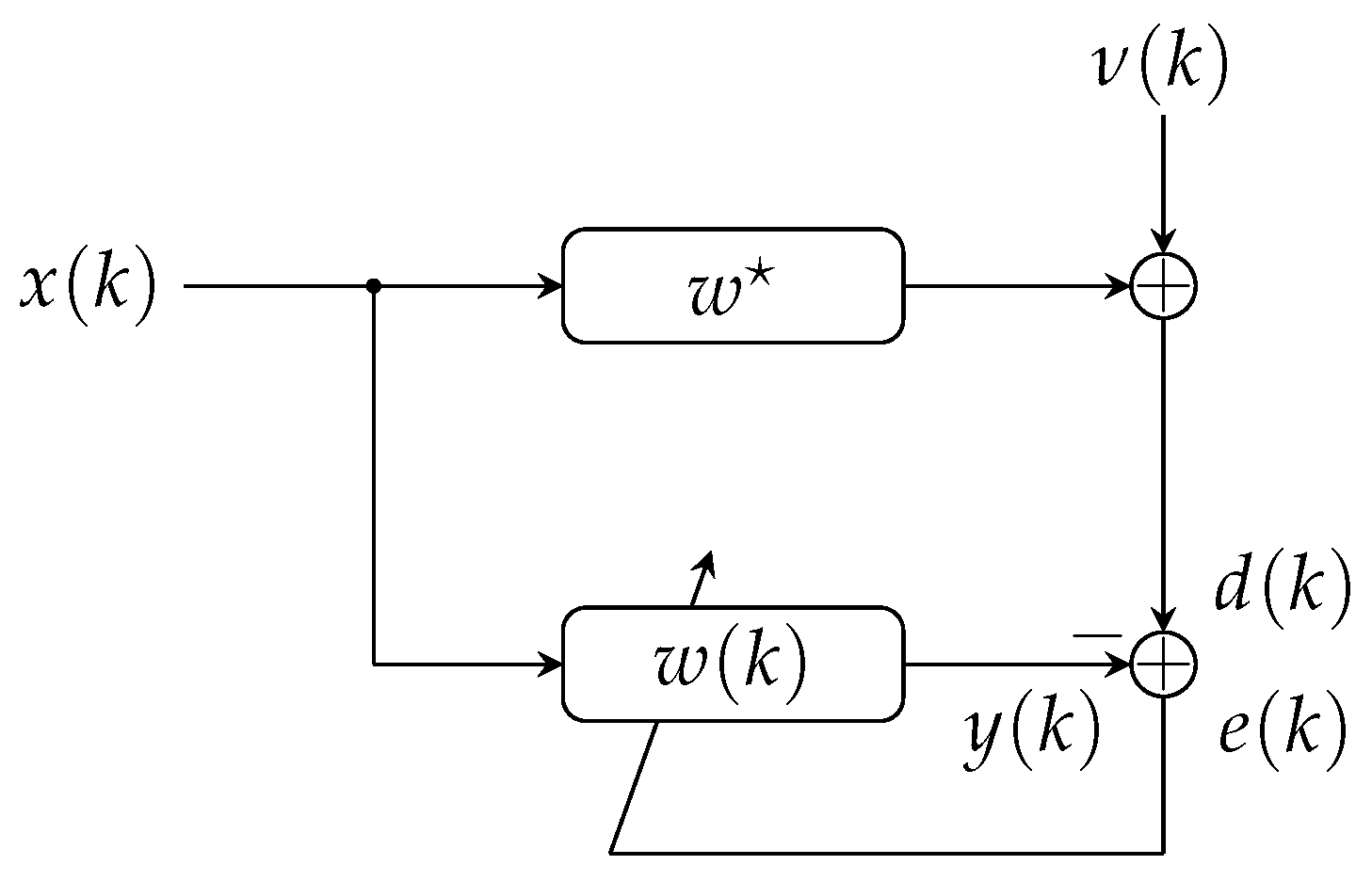
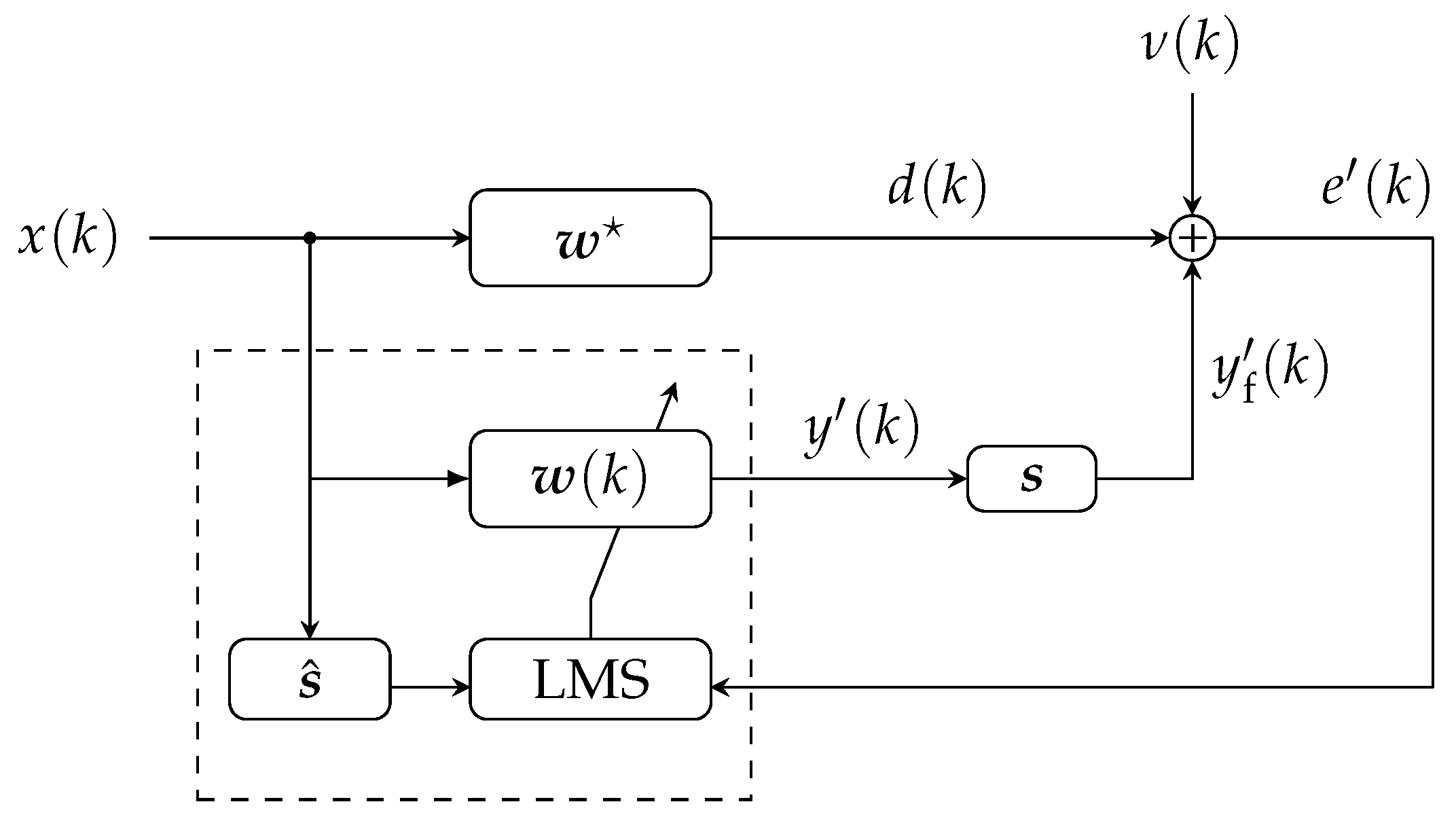
2. Proposed SPU-LMS-M-Min for a Single Block
2.1. Computational Complexity
2.2. SPU-LMS-M-Min for Multiple Blocks
3. Stochastic Modelling of the Proposed Algorithm
3.1. First-Order Analysis
3.2. Second-Order Analysis
3.3. Tracking Analysis
3.4. Deficient-Length Analysis
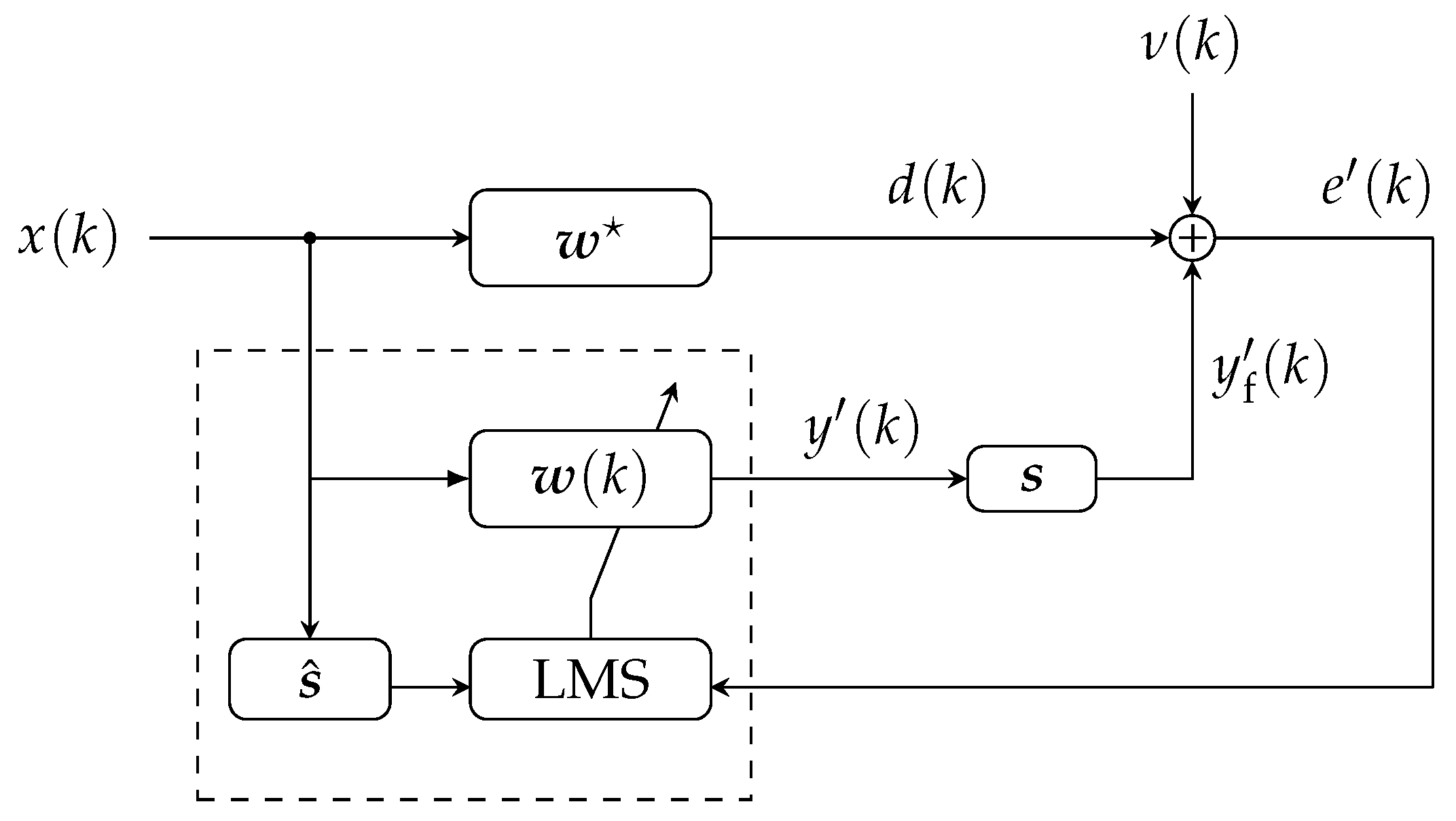
4. Extensions of the Proposed Framework
5. Results
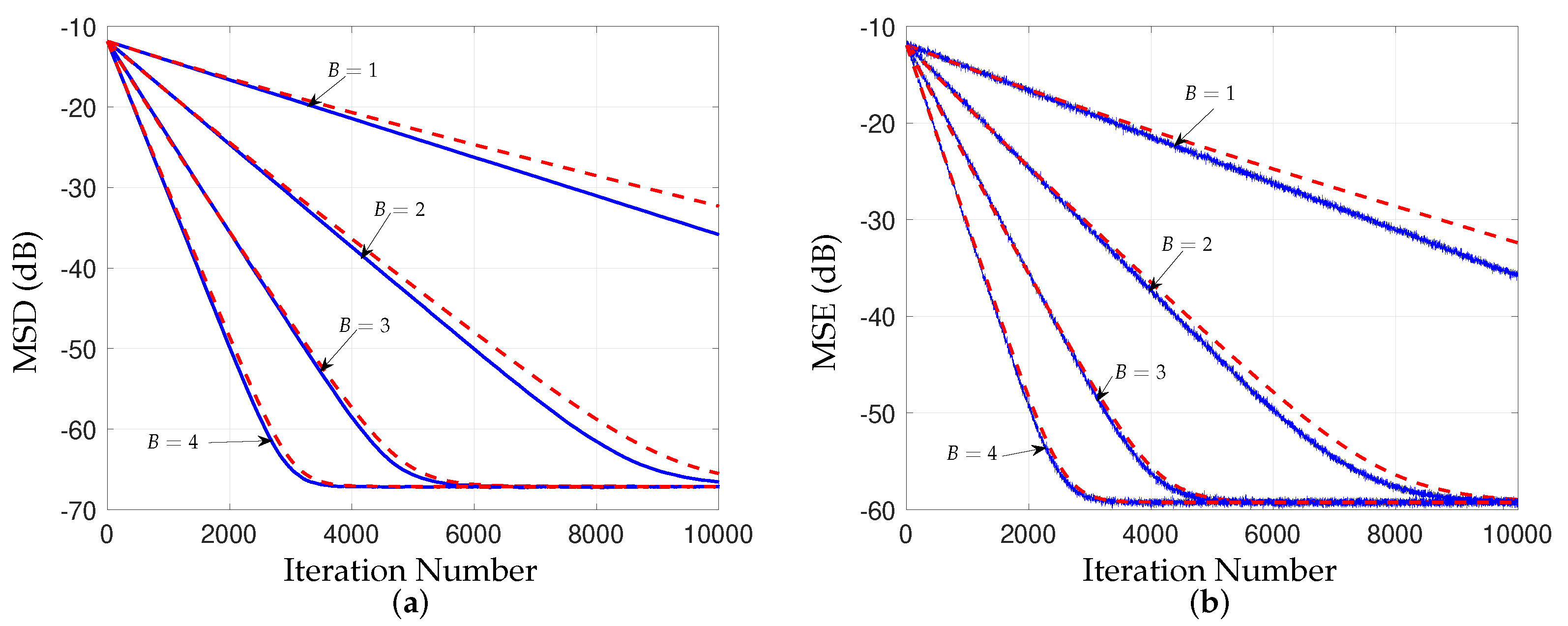
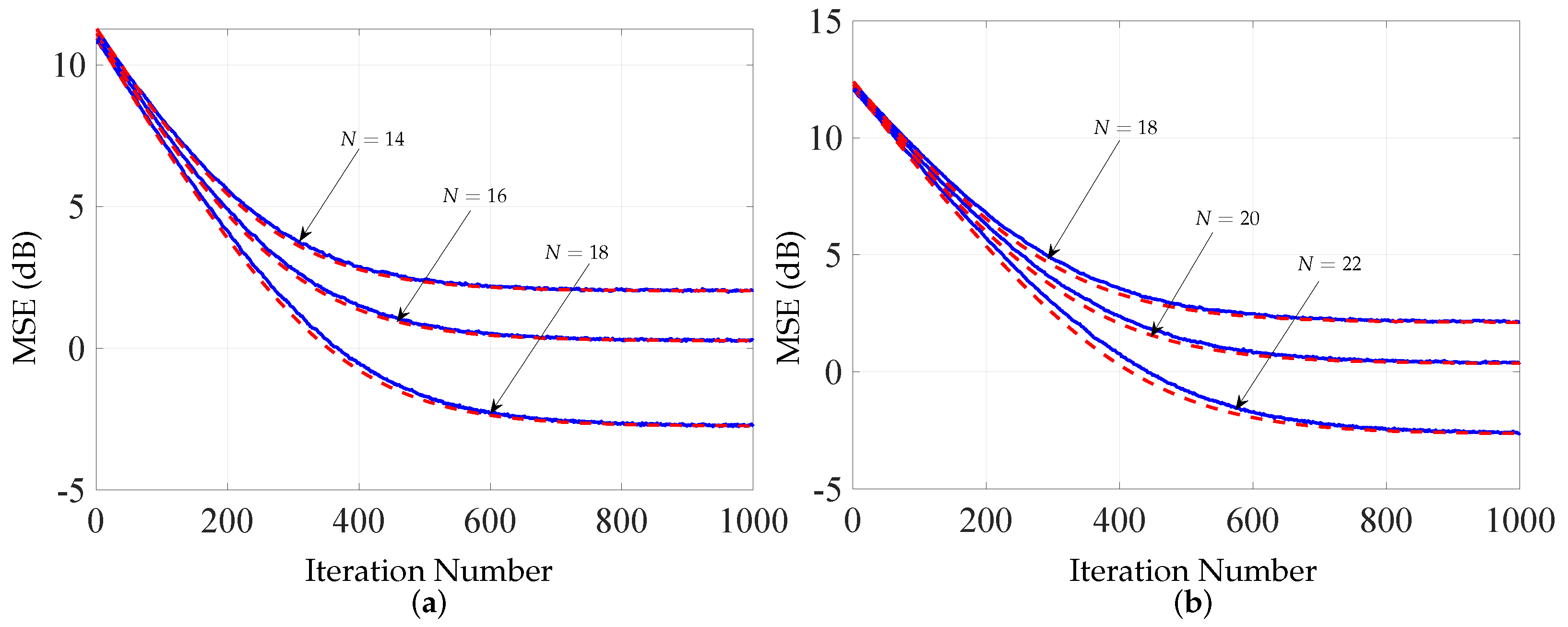
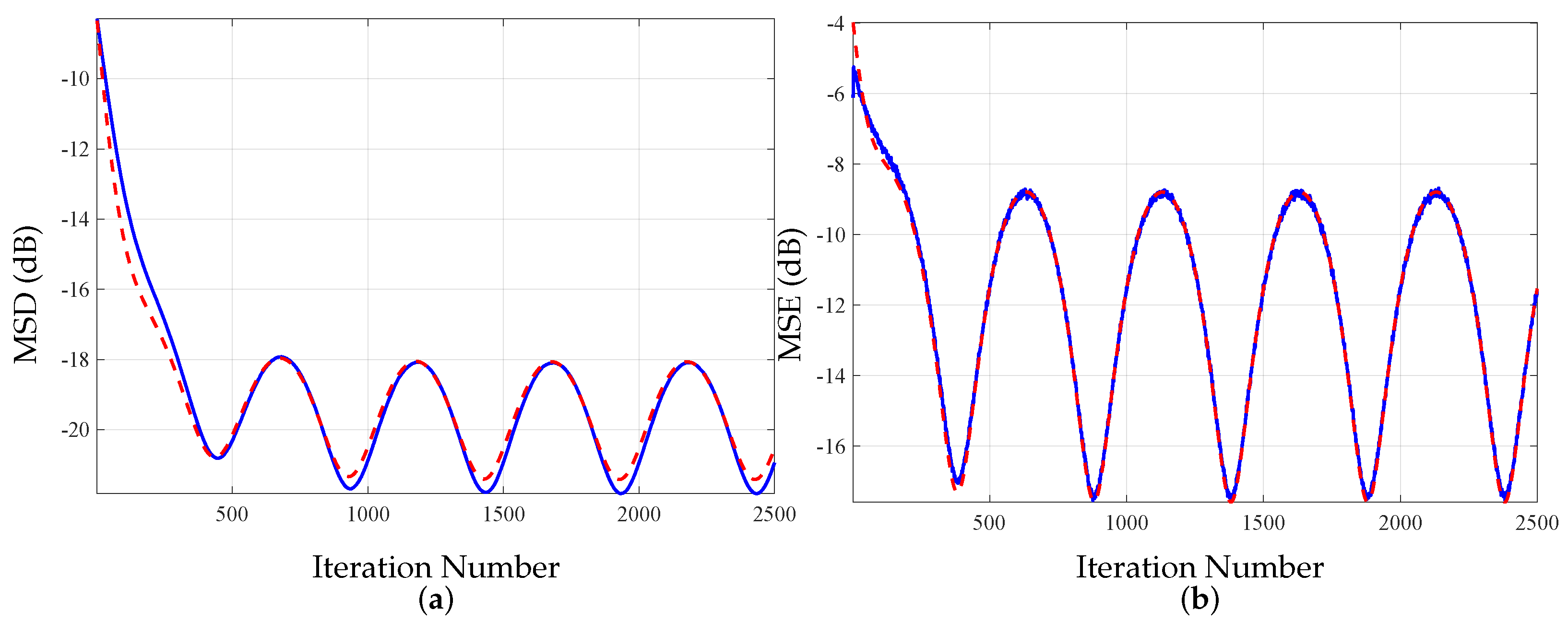
5.1. First-Order Analysis
5.2. Second-Order Analysis
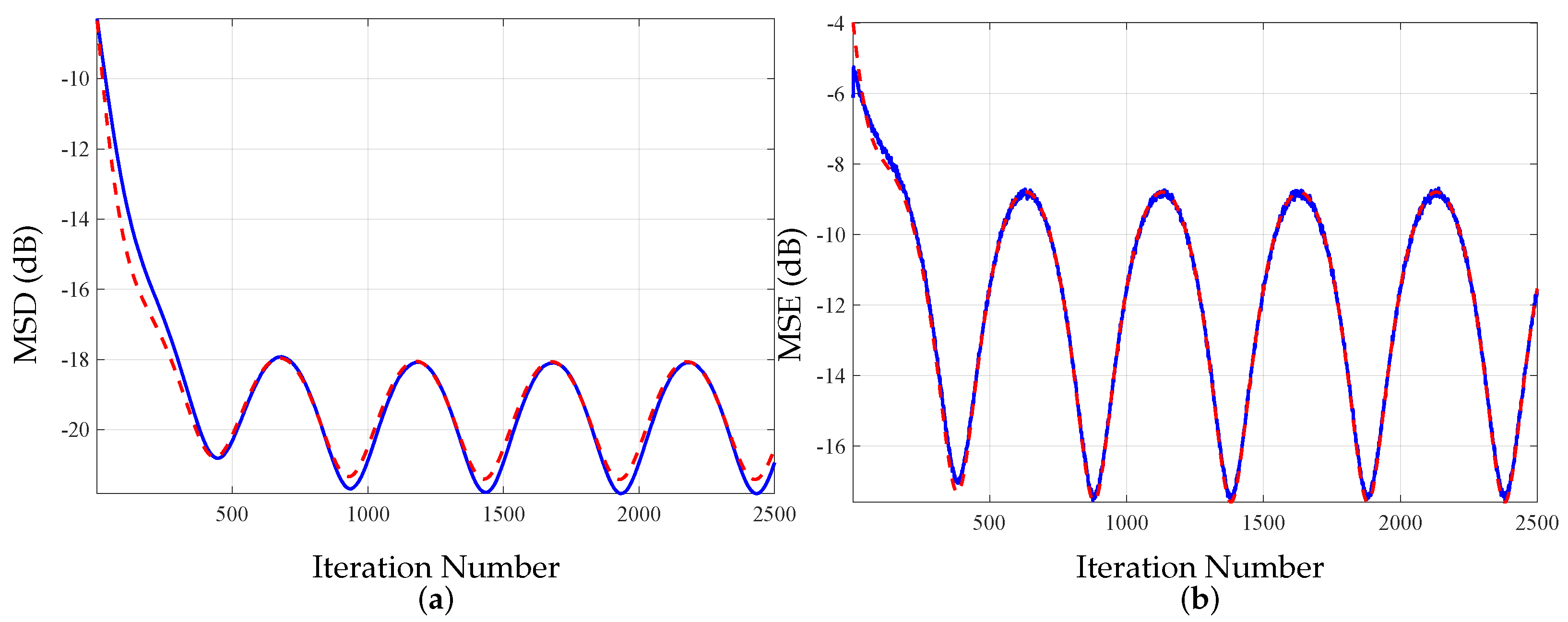
5.3. Tracking Analysis
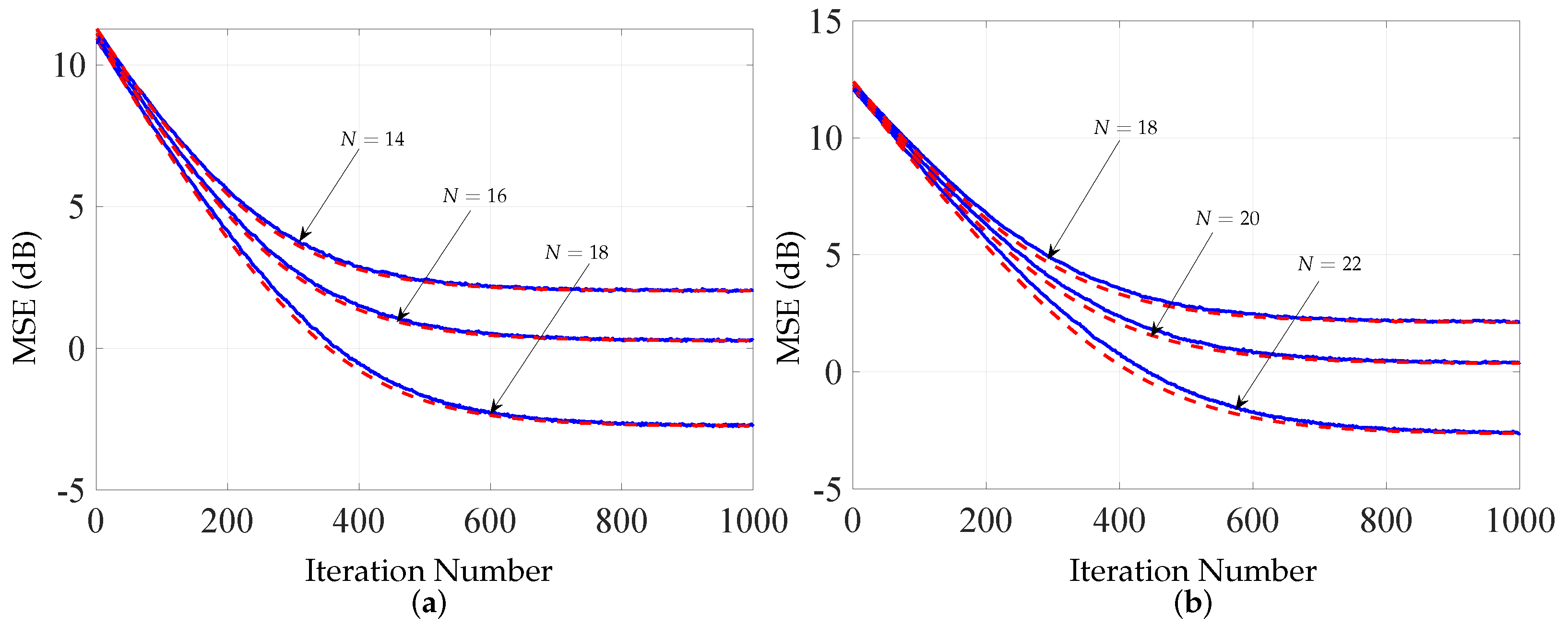
5.4. Deficient-Length Analysis
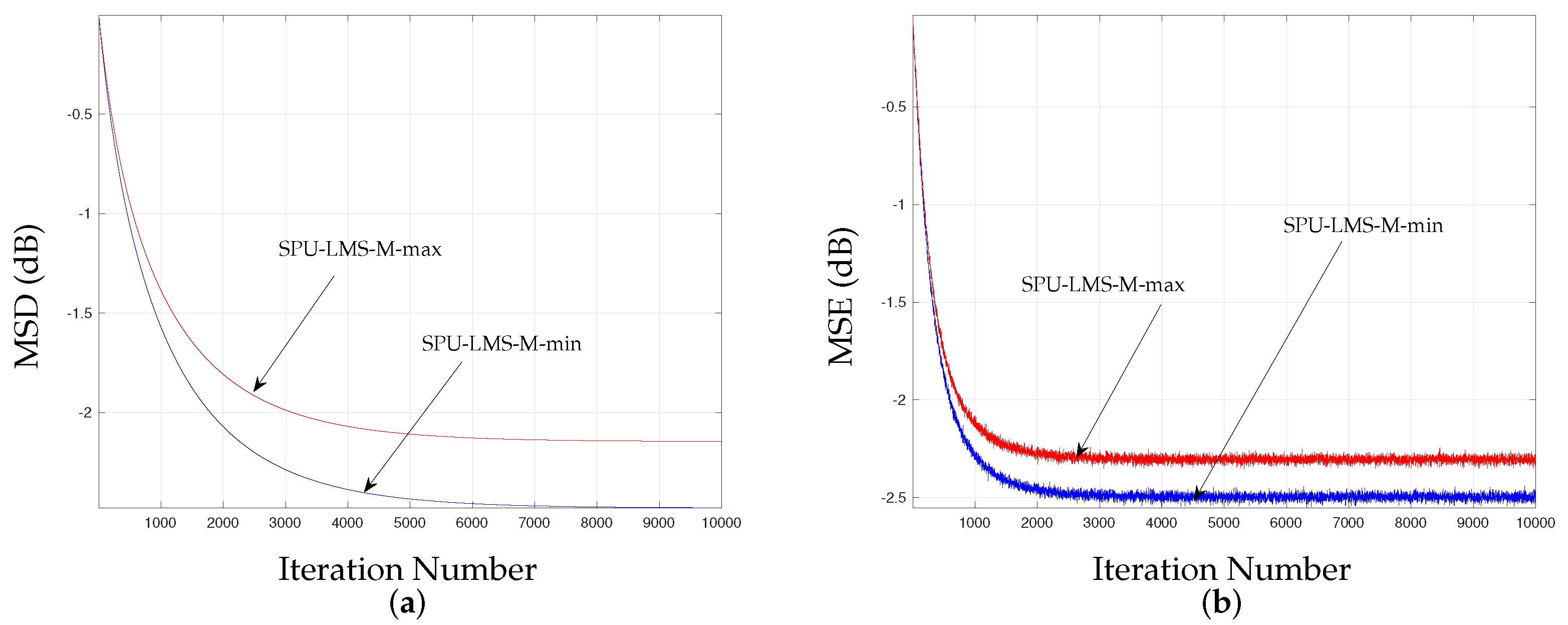
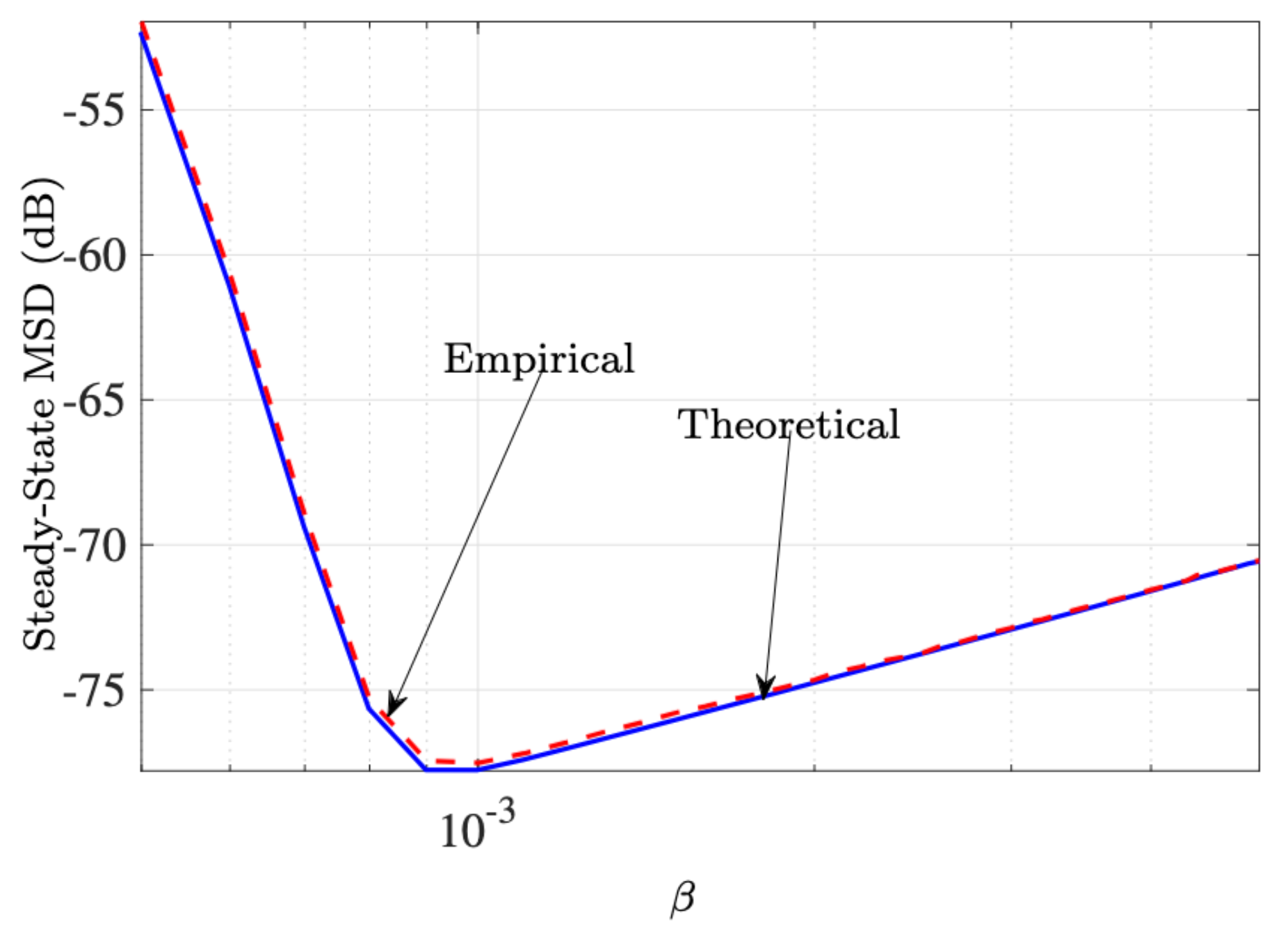
5.5. SPU-LMS-M-Min versus SPU-LMS-M-Max
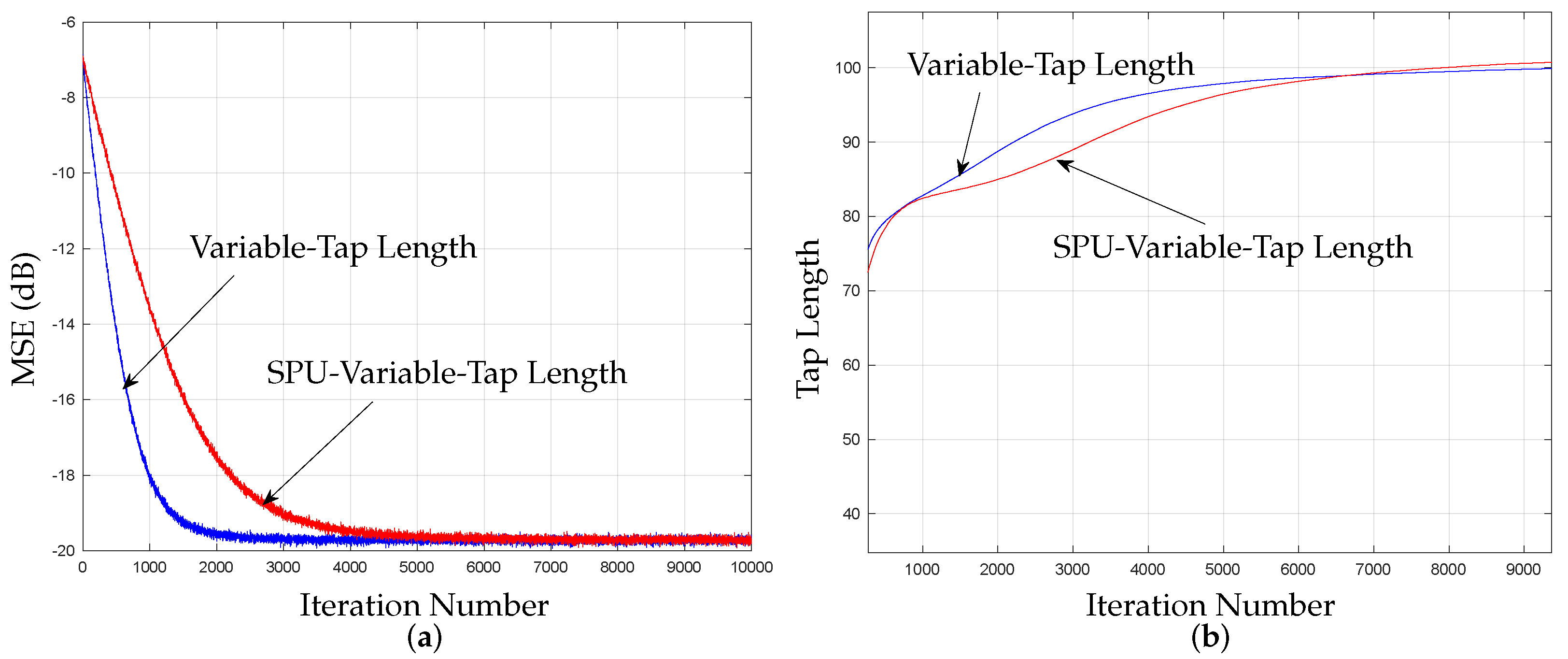
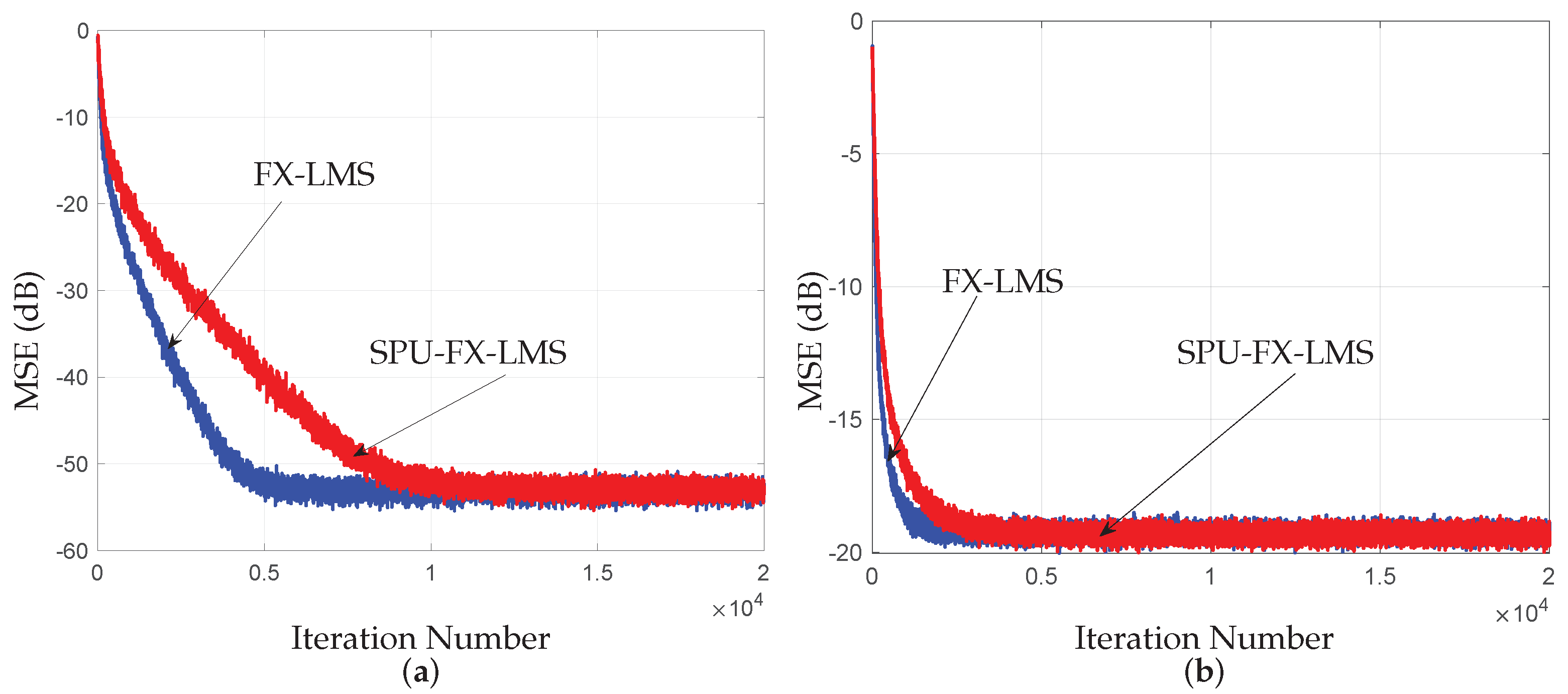
5.6. Extensions of the Proposed Framework Simulations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abadi, M.; Mehrdad, V.; Husoy, J. Combining Selective Partial Update and Selective Regressor Approaches for Affine Projection Adaptive Filtering. In Proceedings of the 2009 7th International Conference on Information, Communications and Signal Processing (ICICS), Macau, China, 8–10 December 2009; pp. 1–4. [Google Scholar]
- Sayed, A.H. Adaptive Filters, 1st ed.; Wiley-IEEE Press: Newark, NJ, USA, 2008. [Google Scholar]
- Wittenmark, B. Adaptive Filter Theory: Simon Haykin; Automatica, Elsevier Ltd: Amsterdam, The Netherlands, 1993; pp. 567–568. [Google Scholar]
- Lara, P.; Igreja, F.; Tarrataca, L.D.T.J.; Barreto Haddad, D.; Petraglia, M.R. Exact Expectation Evaluation and Design of Variable Step-Size Adaptive Algorithms. IEEE Signal Process. Lett. 2019, 26, 74–78. [Google Scholar] [CrossRef]
- Aboulnasr, T.; Mayyas, K. Complexity reduction of the NLMS algorithm via selective coefficient update. IEEE Trans. Signal Process. 1999, 47, 1421–1424. [Google Scholar] [CrossRef]
- De Souza, J.V.G.; Henriques, F.D.R.; Siqueira, N.N.; Tarrataca, L.; Andrade, F.A.A.; Haddad, D.B. Stochastic Modeling of the Set-Membership- Sign-NLMS Algorithm. IEEE Access 2024, 12, 32739–32752. [Google Scholar] [CrossRef]
- Wang, W.; Dogancay, K. Convergence Issues in Sequential Partial-Update LMS for Cyclostationary White Gaussian Input Signals. IEEE Signal Process. Lett. 2021, 28, 967–971. [Google Scholar] [CrossRef]
- Wen, H.X.; Yang, S.Q.; Hong, Y.Q.; Luo, H. A Partial Update Adaptive Algorithm for Sparse System Identification. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 240–255. [Google Scholar] [CrossRef]
- Wang, W.; Doğançay, K. Partial-update strictly linear, semi-widely linear, and widely linear geometric-algebra adaptive filters. Signal Process. 2023, 210, 109059. [Google Scholar] [CrossRef]
- Dogancay, K.; Tanrikulu, O. Adaptive filtering algorithms with selective partial updates. IEEE Trans. Circuits Syst. Analog. Digit. Signal Process. 2001, 48, 762–769. [Google Scholar] [CrossRef]
- Akhtar, M.T.; Ahmed, S. A robust normalized variable tap-length normalized fractional LMS algorithm. In Proceedings of the 2016 IEEE 59th International Midwest Symposium on Circuits and Systems (MWSCAS), Abu Dhabi, United Arab Emirates, 16–19 October 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Gong, Y.; Cowan, C. An LMS style variable tap-length algorithm for structure adaptation. IEEE Trans. Signal Process. 2005, 53, 2400–2407. [Google Scholar] [CrossRef]
- Li, N.; Zhang, Y.; Zhao, Y.; Hao, Y. An improved variable tap-length LMS algorithm. Signal Process. 2009, 89, 908–912. [Google Scholar] [CrossRef]
- Zhang, Y.; Chambers, J. Convex Combination of Adaptive Filters for a Variable Tap-Length LMS Algorithm. IEEE Signal Process. Lett. 2006, 13, 628–631. [Google Scholar] [CrossRef]
- Chang, D.C.; Chu, F.T. Feedforward Active Noise Control With a New Variable Tap-Length and Step-Size Filtered-X LMS Algorithm. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 542–555. [Google Scholar] [CrossRef]
- Kar, A.; Swamy, M. Tap-length optimization of adaptive filters used in stereophonic acoustic echo cancellation. Signal Process. 2017, 131, 422–433. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, N.; Chambers, J.; Sayed, A. Steady-State Performance Analysis of a Variable Tap-Length LMS Algorithm. IEEE Trans. Signal Process. 2008, 56, 839–845. [Google Scholar] [CrossRef]
- Pitas, I. Fast algorithms for running ordering and max/min calculation. IEEE Trans. Circuits Syst. 1989, 36, 795–804. [Google Scholar] [CrossRef]
- Boudiaf, M.; Benkherrat, M.; Boudiaf, M. Partial-update adaptive filters for event-related potentials denoising. In Proceedings of the IET 3rd International Conference on Intelligent Signal Processing (ISP 2017), London, UK, 4–5 December 2017; pp. 1–6. [Google Scholar]
- Lara, P.; Tarrataca, L.D.; Haddad, D.B. Exact expectation analysis of the deficient-length LMS algorithm. Signal Process. 2019, 162, 54–64. [Google Scholar] [CrossRef]
- Silva, M.T.M.; Nascimento, V.H. Convex Combination of Adaptive Filters with Different Tracking Capabilities. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP ’07, Honolulu, HI, USA, 15–20 April 2007; Volume 3, pp. III–925–III–928. [Google Scholar]
- Ibe, O.C. Basic Concepts in Probability. In Markov Processes for Stochastic Modeling; Elsevier: Amsterdam, The Netherlands, 2013; pp. 1–27. [Google Scholar]
- Bershad, N.J.; Bermudez, J.C.M. Stochastic analysis of the LMS algorithm for non-stationary white Gaussian inputs. In Proceedings of the 2011 IEEE Statistical Signal Processing Workshop (SSP), Nice, France, 28–30 June 2011; pp. 57–60. [Google Scholar]
- Mayyas, K. Performance analysis of the deficient length LMS adaptive algorithm. IEEE Trans. Signal Process. 2005, 53, 2727–2734. [Google Scholar] [CrossRef]
- Le, D.C.; Viet, H.H. Filtered-x Set Membership Algorithm With Time-Varying Error Bound for Nonlinear Active Noise Control. IEEE Access 2022, 10, 90079–90091. [Google Scholar] [CrossRef]
- Mossi, M.I.; Yemdji, C.; Evans, N.; Beaugeant, C. A Comparative Assessment of Noise and Non-Linear EchoEffects in Acoustic Echo Cancellation. In Proceedings of the IEEE 10th International Conference on Signal Processing Proceedings, Beijing, China, 24–28 October 2010; pp. 223–226. [Google Scholar]
- ITU-T-2004. Digital Network Echo Cancellers (Recommendation); Technical Report G.168, ITU-T: Geneva, Switzerland, 2004. [Google Scholar]
- ITU-T-2015. Digital Network Echo Cancellers (Recommendation); Technical Report G.168, ITU-T: Geneva, Switzerland, 2015. [Google Scholar]
- Sadigh, A.N.; Zayyani, H.; Korki, M. A Robust Proportionate Graph Recursive Least Squares Algorithm for Adaptive Graph Signal Recovery. In IEEE Transactions on Circuits and Systems II: Express Briefs; IEEE: Piscataway, NJ, USA, 2024; p. 1. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Multiplication | Addition | Comparison | Division |
|---|---|---|---|---|
| LMS-Based | ||||
| Standard | 2N + 1 | 2N | − | − |
| M-min | N + + 1 | N + | 2[ + 2 | − |
| Periodic | N + (N + 1)/S | N + N/S | − | − |
| Sequential | N + + 1 | N + | − | − |
| Stochastic | N + + 3 | N + + 2 | − | − |
| M-max | N + + 1 | N + | 2[ + 2 | − |
| Norm. Selective | N + + 2 | N + + 2 | 2[ + 2 | 1 |
| Parameters | Figure 5 |
|---|---|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Siqueira, N.N.; Resende, L.C.; Andrade, F.A.A.; Pimenta, R.M.S.; Haddad, D.B.; Petraglia, M.R. Transient Analysis of a Selective Partial-Update LMS Algorithm. Appl. Sci. 2024, 14, 2775. https://doi.org/10.3390/app14072775
Siqueira NN, Resende LC, Andrade FAA, Pimenta RMS, Haddad DB, Petraglia MR. Transient Analysis of a Selective Partial-Update LMS Algorithm. Applied Sciences. 2024; 14(7):2775. https://doi.org/10.3390/app14072775
Chicago/Turabian StyleSiqueira, Newton N., Leonardo C. Resende, Fabio A. A. Andrade, Rodrigo M. S. Pimenta, Diego B. Haddad, and Mariane R. Petraglia. 2024. "Transient Analysis of a Selective Partial-Update LMS Algorithm" Applied Sciences 14, no. 7: 2775. https://doi.org/10.3390/app14072775
APA StyleSiqueira, N. N., Resende, L. C., Andrade, F. A. A., Pimenta, R. M. S., Haddad, D. B., & Petraglia, M. R. (2024). Transient Analysis of a Selective Partial-Update LMS Algorithm. Applied Sciences, 14(7), 2775. https://doi.org/10.3390/app14072775