4.2. Methods
CNN architectures come in various dimensions, including 1D, 2D, and 3D formats. Among these, 2D CNNs are most prevalent and are commonly employed for tasks such as image classification, similarity clustering, and object recognition in scenes. The rationale behind the prevalent use of 2D CNNs in image classification stems from the inherently two-dimensional nature of image data [
32]. Conversely, Conv1D architectures are typically applied for analyzing time series data. Given that the vibration data obtained from building structures also exhibit temporal characteristics, Conv1D architectures can be effectively utilized for the classification of acceleration data [
33].
In the context of this research, a convolutional neural network (CNN) model was developed. Although CNNs operate as black box systems, where input batches are processed to yield corresponding outputs, designing effective machine learning models involves selecting appropriate algorithms and techniques, which in turn require decisions regarding specific parameters [
34]. In deep neural network models, designers must determine key factors such as dropout rates, the number of layers, and the quantity of neurons. However, deciding on these parameters is often not a straightforward process, as their optimal values may not be immediately apparent. These parameters, which vary depending on the problem and dataset, are known as hyperparameters. Different combinations of hyperparameters may yield varying levels of model performance, and selecting the most suitable combination is a crucial challenge. Typically, hyperparameter selection relies on the designer’s intuition, past experience, reflection on applications in related fields, current trends, and the inherent design characteristics of the model. However, recent advancements have introduced techniques aimed at systematically identifying the most appropriate hyperparameter combinations for optimal problem solving. The number of hyperparameters in a model can vary significantly, ranging from just a few to several hundred. Examples of hyperparameters include the number of layers and epochs, kernel size, stride, padding batch size, activation function, layer types, and units. Hyperparameter tuning is essential for creating the most effective model for a given dataset, and various methods exist for achieving this goal.
After discussing the basics of convolutional neural networks (CNNs) and their application in vibration-based structural damage detection, it is important to delve into the concept of hyperparameters and their significance in model design and performance optimization. In machine learning models, hyperparameters are parameters whose values are set before the learning process begins. These parameters govern the behavior of the model during training and influence its ability to learn from the data. Some common hyperparameters in CNNs include the following:
Number of Layers: This refers to the depth of the neural network, including convolutional layers, pooling layers, and fully connected layers. Deeper networks can potentially capture more complex patterns but may also be prone to overfitting.
Epochs: An epoch is one complete pass through the entire training dataset. The number of epochs determines how many times the model will see the entire dataset during training.
Kernel Size: In convolutional layers, the kernel size defines the spatial dimensions of the filter applied to the input data. Larger kernels capture broader patterns, while smaller kernels focus on finer details.
Stride: The stride parameter specifies the step size at which the kernel moves across the input data during convolution. A larger stride reduces the spatial dimensions of the output feature maps.
Padding: Padding is used to preserve the spatial dimensions of the input data when applying convolutional filters. It involves adding zeros around the input data to ensure that the output feature maps have the desired size.
Batch Size: The batch size determines the number of samples processed by the model in each training iteration. Larger batch sizes can accelerate training but may require more memory.
Activation Function: Activation functions introduce nonlinearity into the network and enable it to learn complex mappings between inputs and outputs. Common activation functions include ReLU, sigmoid, and tanh.
Dropout: Dropout is a regularization technique used to prevent overfitting by randomly deactivating a fraction of the neurons during training.
Learning Rate: The learning rate controls the step size of the gradient descent algorithm used to update the model weights during training. It influences the speed and stability of the training process.
Through meticulous tuning of these hyperparameters, researchers and practitioners can optimize the performance of CNNs for specific tasks and datasets, thereby enhancing generalization and predictive accuracy. Various techniques, such as grid search, random search, and Bayesian optimization, can be employed to identify the optimal combination of hyperparameters for a given problem.
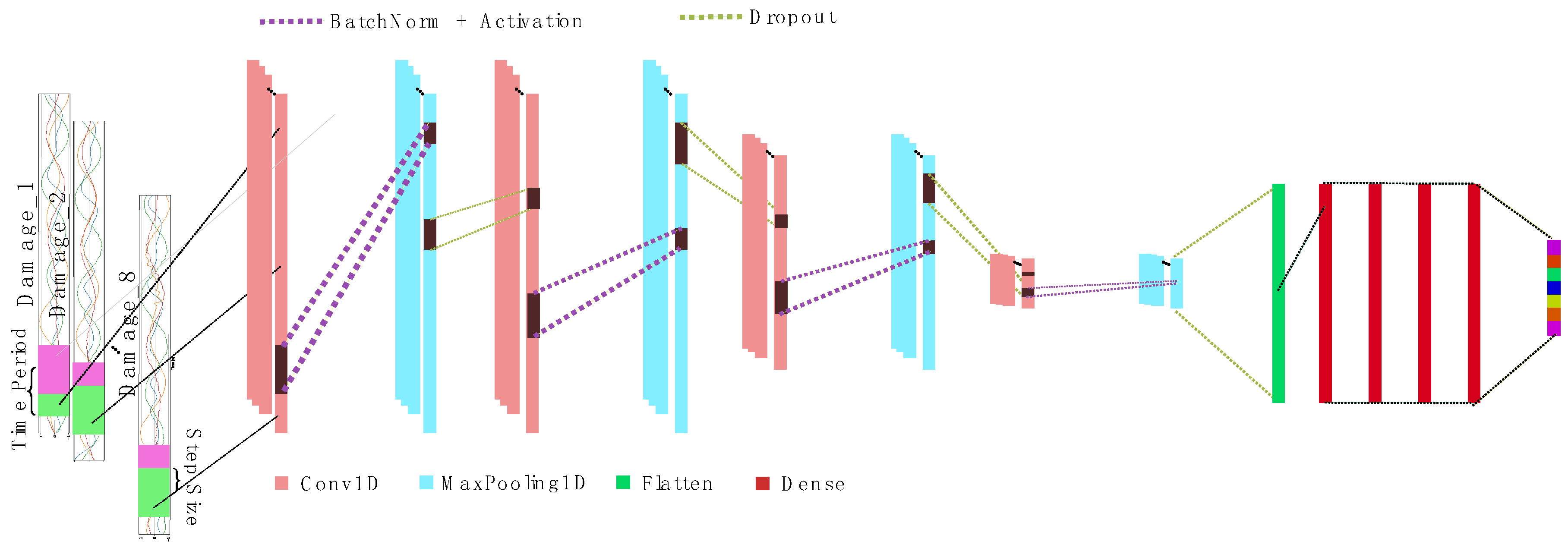
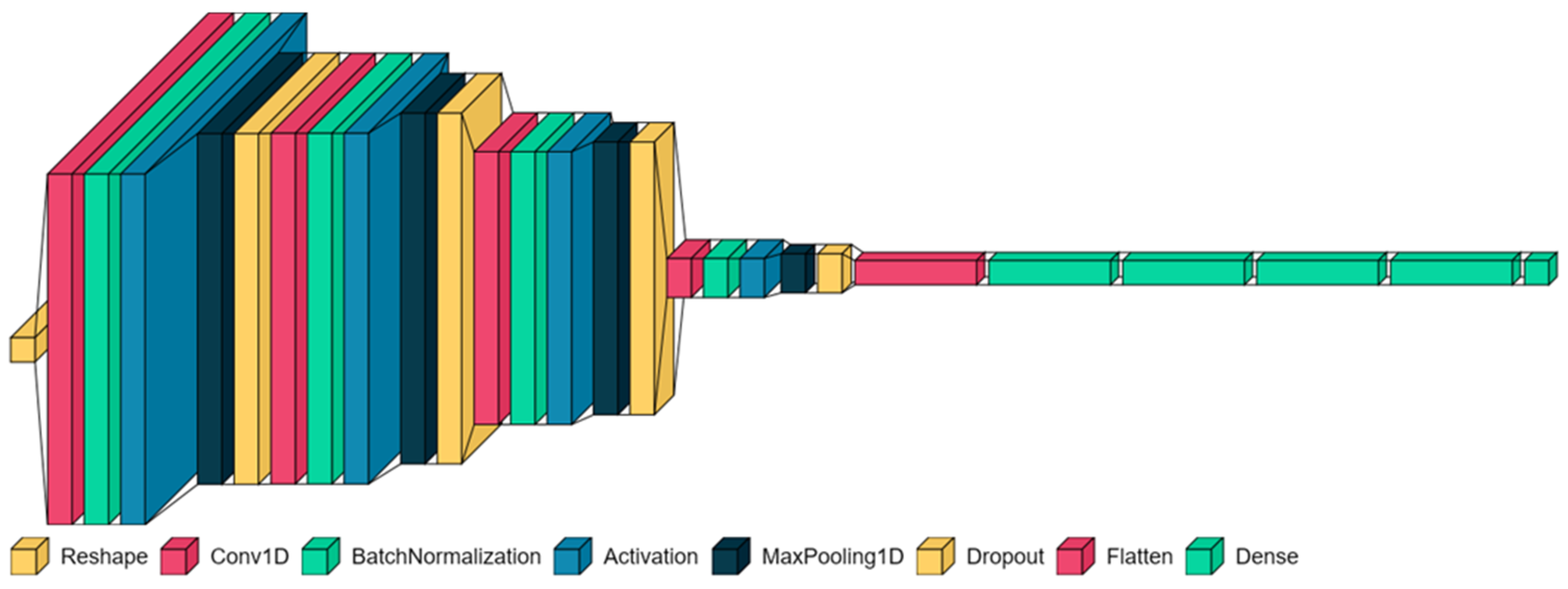
The overall CNN architecture for the current study is illustrated in
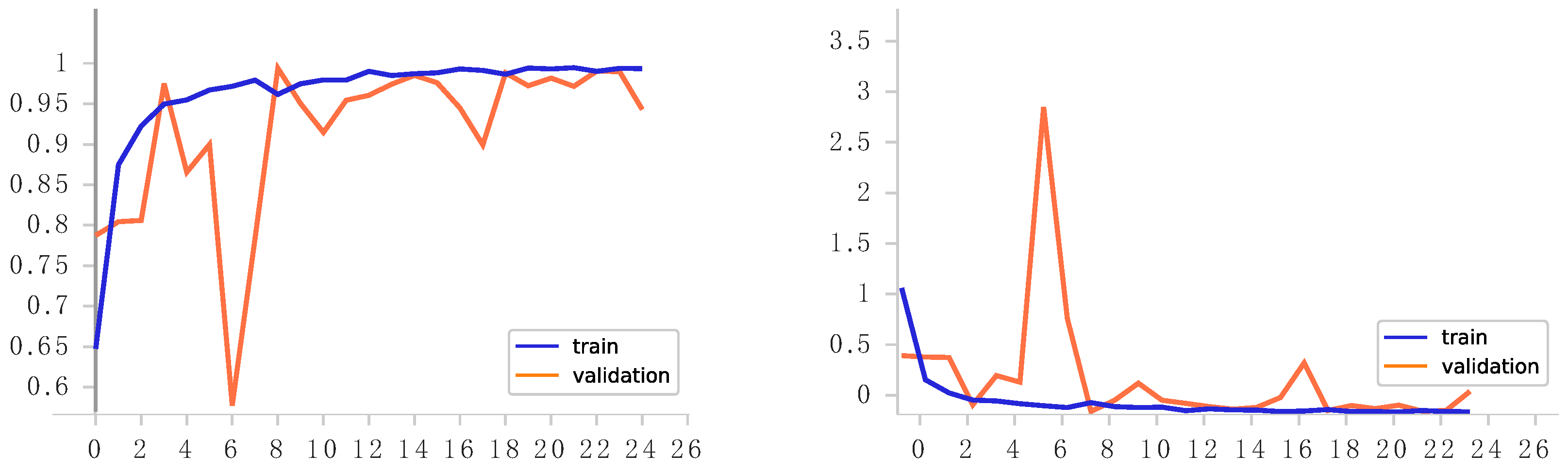
Figure 2. Labeled acceleration data sampled at regular intervals were inputted into 1D convolutional layers. Interspersed between these layers were dropout layers, which served to mitigate overfitting of the neural network structure to the training data. Additionally, batch normalization layers were incorporated to normalize activations in the intermediate layers, thereby improving the accuracy.
In the upcoming section, we will detail a comprehensive strategy for hyperparameter optimization, a critical phase aimed at refining the effectiveness of our network architecture. Through extensive experimentation and systematic adjustment of the hyperparameters, our objective was to identify the optimal configuration that maximized the network’s performance across various metrics. This rigorous process ensured the robustness and adaptability of our model, allowing us to gain valuable insights into the complex interactions among different architectural components and their influence on the network’s predictive abilities.
Hyperparameter Tuning
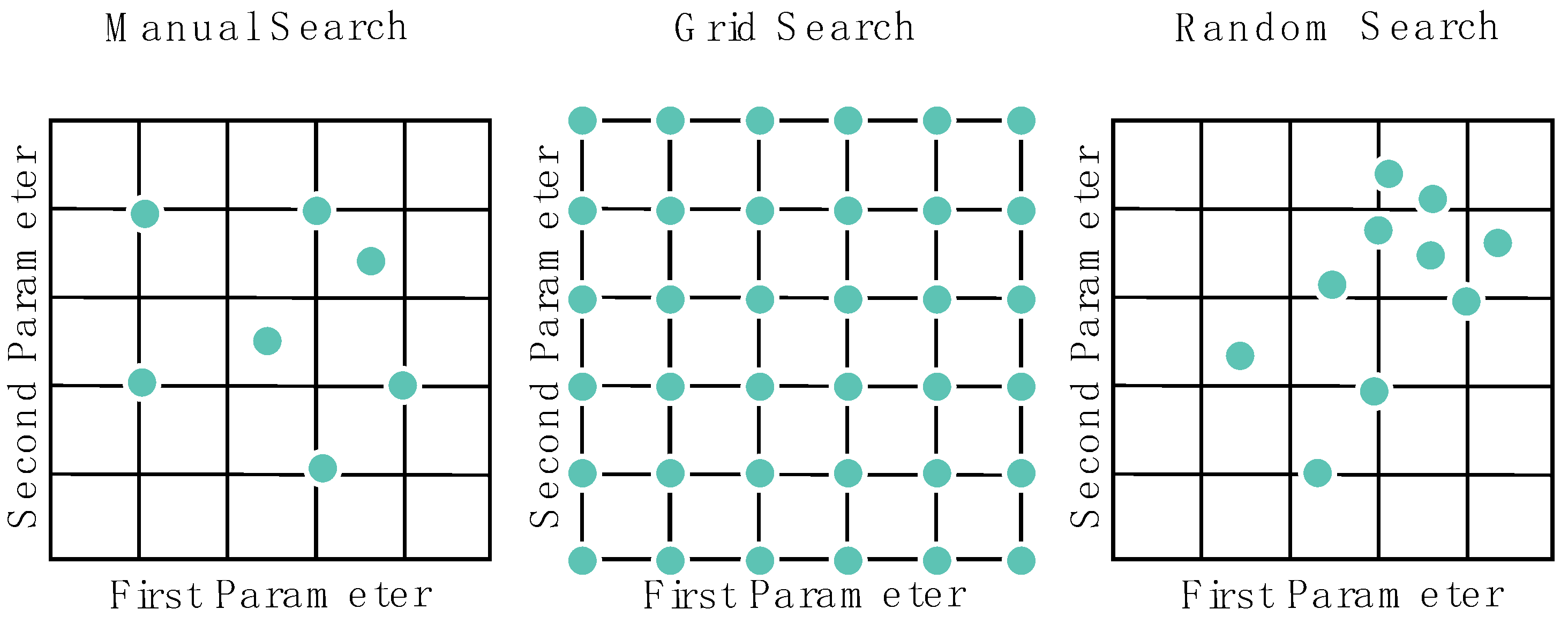
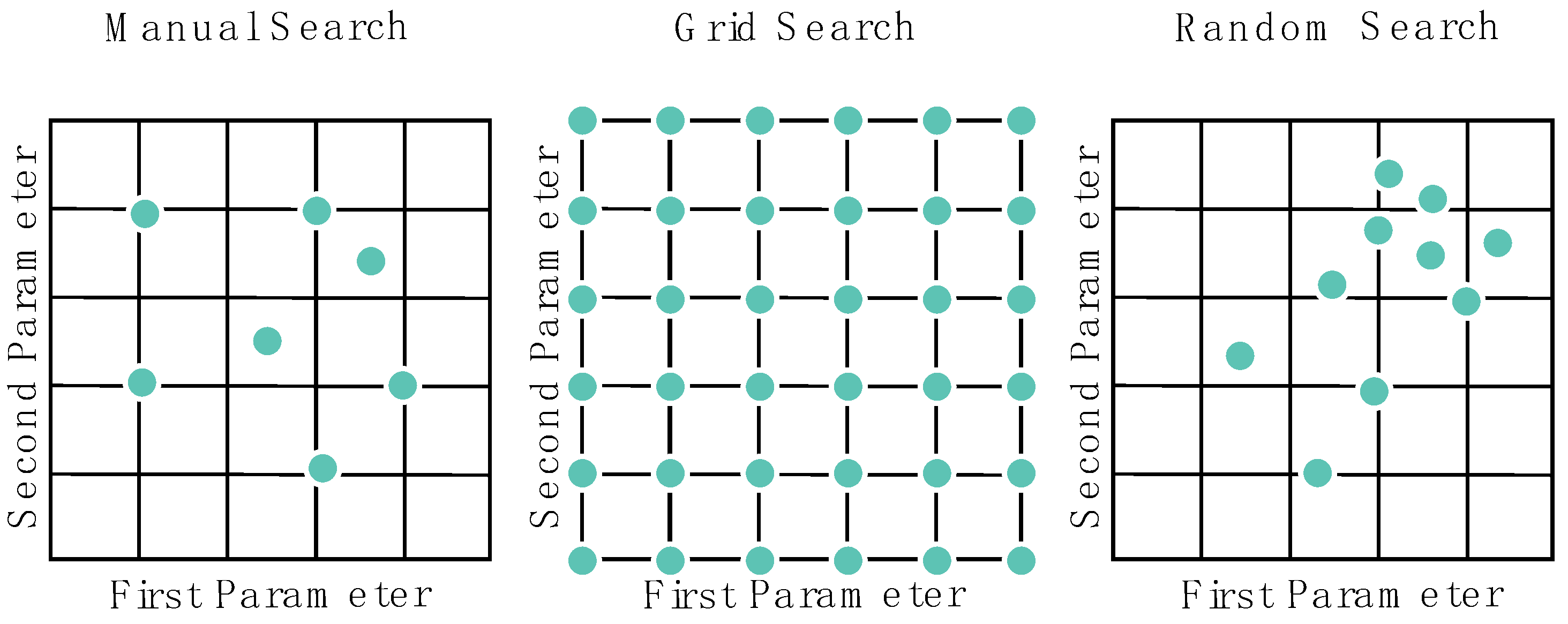
The advent of deep learning introduced complex architectural structures with multiple layers, each governed by a set of hyperparameters determined by the designer. While some hyperparameters, such as optimization algorithms and activation functions, involve straightforward selection from a limited pool of options, others, including the number of layers and neurons, learning rates, and kernel sizes, require meticulous consideration due to their broad range of potential values. Choosing the appropriate hyperparameter values is often an iterative process, as the initial selections may not yield optimal results. Designers typically adjust these parameters iteratively, observing the model’s performance with each change to identify the most suitable hyperparameter combination. Additionally, automated methods exist to streamline this selection process. Two common hyperparameter tuning techniques are random search and grid search. In random search, values are randomly selected from predetermined ranges for each hyperparameter, with iterations continuing until the best-performing combination is found. On the other hand, grid search evaluates all possible combinations within specified ranges to identify the optimal hyperparameter group. The concept of random search for hyperparameter optimization was initially proposed by Bengio et al. [
35]. Similar to grid search, this approach involves predetermining the hyperparameter ranges based on prior knowledge of the problem. However, instead of testing every value within these ranges, random values are selected and evaluated until the best-performing hyperparameter group is discovered or a desired performance level is achieved [
36]. In addition to the techniques mentioned,
Figure 3 illustrates a comparison of search algorithms, where the axes represent different hyperparameters. Each dot corresponds to a specific combination of hyperparameters evaluated by each method. In this visual representation, the different exploration strategies employed by each method can be observed, as well as how the hyperparameter space is navigated by them.
While random search and grid search are widely used methods, recent advancements like Hyperband have emerged to address the need for more efficient exploration of the hyperparameter space. Hyperband is a hyperparameter optimization technique that aims to efficiently search the hyperparameter space to find the optimal configuration for a machine learning model. It is designed to balance the trade-off between exploration and exploitation during the hyperparameter tuning process. The Hyperband algorithm works by iteratively allocating resources to a set of candidate hyperparameter configurations and then eliminating the poorly performing configurations based on their initial performance. It consists of two main components: random search and successive halving. Hyperband starts with a random sampling of hyperparameter configurations. Each configuration is evaluated using a predetermined amount of computational resources, such as the training time or epochs. This initial random search phase helps identify promising configurations to explore further. Then, Hyperband employs a successive halving strategy to efficiently allocate resources to the most promising configurations. This involves dividing the set of configurations into smaller subsets, or “brackets”, and allocating more resources to the configurations with the highest performance in each bracket. The configurations with worse performance are eliminated at each stage, allowing more resources to be focused on the most promising candidates. By iteratively applying random search and successive halving, Hyperband aims to quickly identify the best-performing hyperparameter configuration with minimal computational resources. It efficiently balances the exploration of the hyperparameter space with the exploitation of promising configurations, making it a popular choice for hyperparameter optimization tasks [
37].
In the CNN model proposed in this study, after every Conv1D layer, there were max pooling layers and dropout layers. Max pooling layers help with reducing the spatial dimensions of the input data, thereby reducing the computational complexity of the model and extracting the most salient features from the data. This helps with capturing the essential information while discarding redundant or less important features, leading to better generalization and improved performance of the model. The dropout layers, on the other hand, were added to prevent overfitting of the CNN model to the training data. Overfitting occurs when the model learns to memorize the training data instead of generalizing patterns, leading to poor performance on unseen data. By randomly deactivating a fraction of the neurons during training, the dropout layers forced the model to learn more robust and generalized representations, thereby improving its ability to generalize to unseen data.
In the context of hyperparameter optimization, the “search space” refers to the range or set of possible values that each hyperparameter can take. Essentially, it encompasses all the potential options that the optimization algorithm explores when seeking the best-performing combination of hyperparameters. For example, if we consider hyperparameters like the learning rate, number of layers, and dropout rate, then the search space for each would consist of the various values or ranges within which these parameters could be adjusted. In essence, the search space defines the boundaries within which the optimization algorithm operates to find the optimal configuration for the neural network model. Maintaining a consistent search space across different experiments ensures fair comparisons between models trained on different datasets or with different configurations, allowing for a comprehensive evaluation of their performance. For example, if we were optimizing a CNN model using the HyperBand algorithm, then we would explore different configurations by varying the number of filters in the convolutional layers. This hyperparameter determines the number of filters or kernels that are applied to the input data during the convolution operation. Thus, for a specific experiment, we might try using 128 filters in one configuration, 160 filters in another, and so on up to 256 filters. Each configuration would be evaluated to determine its performance on the given dataset, and the algorithm would iteratively search through these options to find the best-performing combination of hyperparameters.
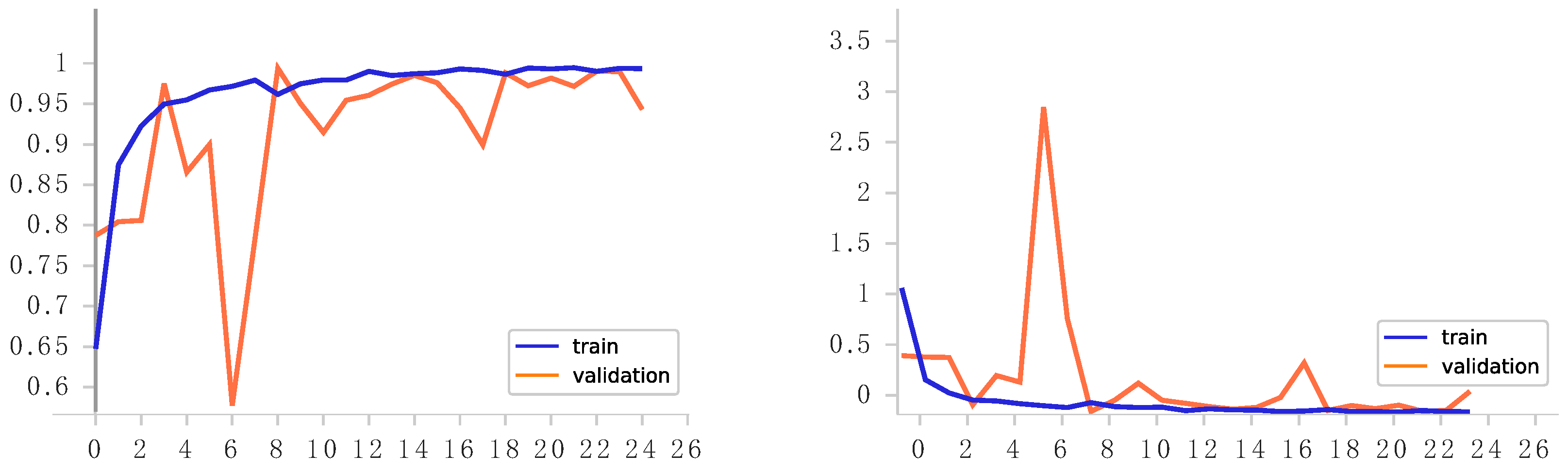
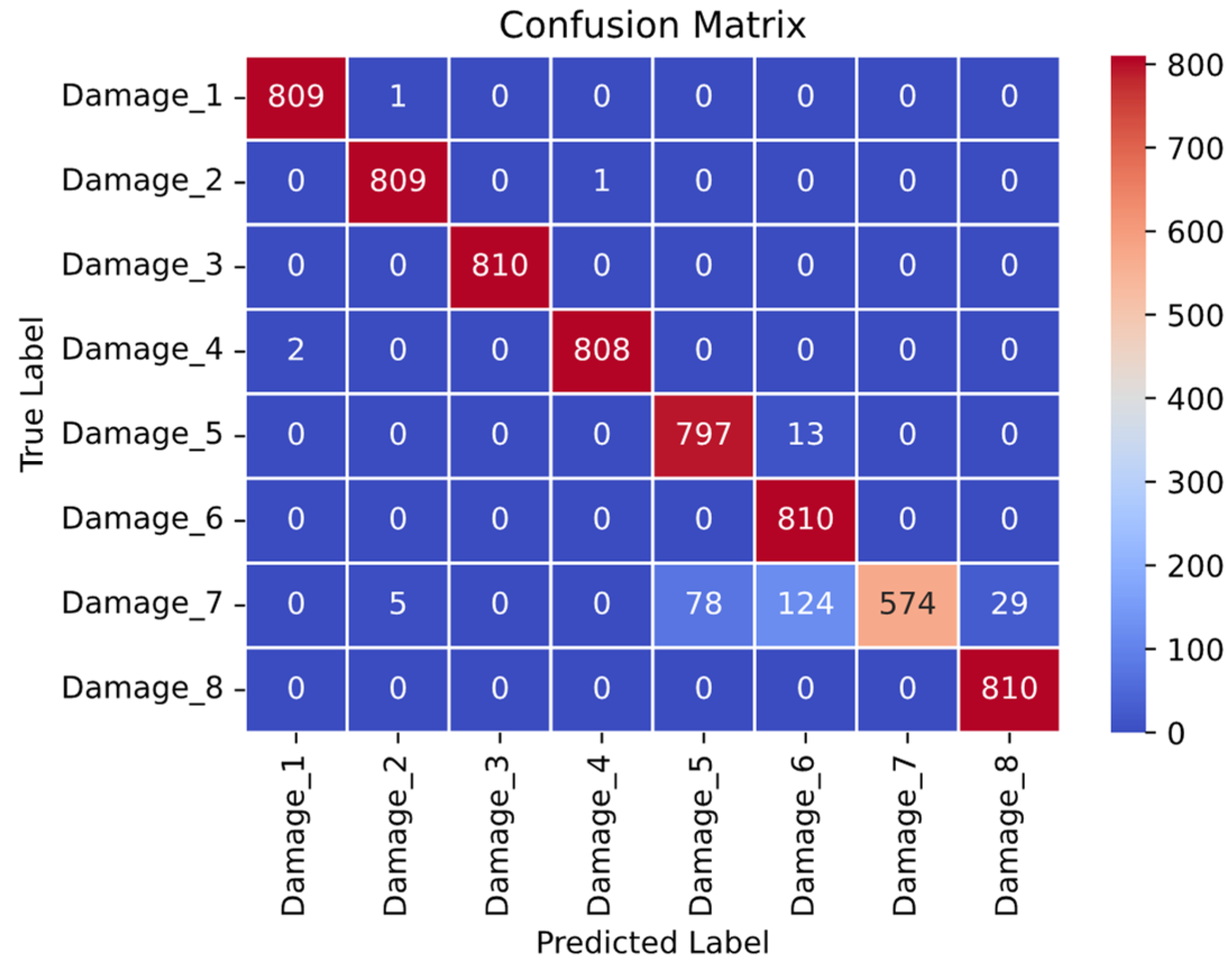
Table 2 displays the search space of the hyperparameters considered in the optimization process. Due to the extensive range of hyperparameters, the optimization algorithm necessitated a total of 9 hours to achieve optimal results. Generally, random search outpaces grid search in speed but often sacrifices performance. However, in this study, a novel approach to random search, termed the HyperBand hyperparameter optimization technique, was leveraged. This innovative method facilitated the attainment of a high level of accuracy in a relatively brief timeframe. Having max pooling layers and dropout layers after every Conv1D layer also meant that the number of Conv1D layers was the same as the number of max pooling layers and dropout layers. But the hyperparameters for the layers and the number of layers changed throughout the hyperparameter optimization procedure. After the best hyperparameters were found using the Hyperband, the model had been trained with the best hyperparamaters.
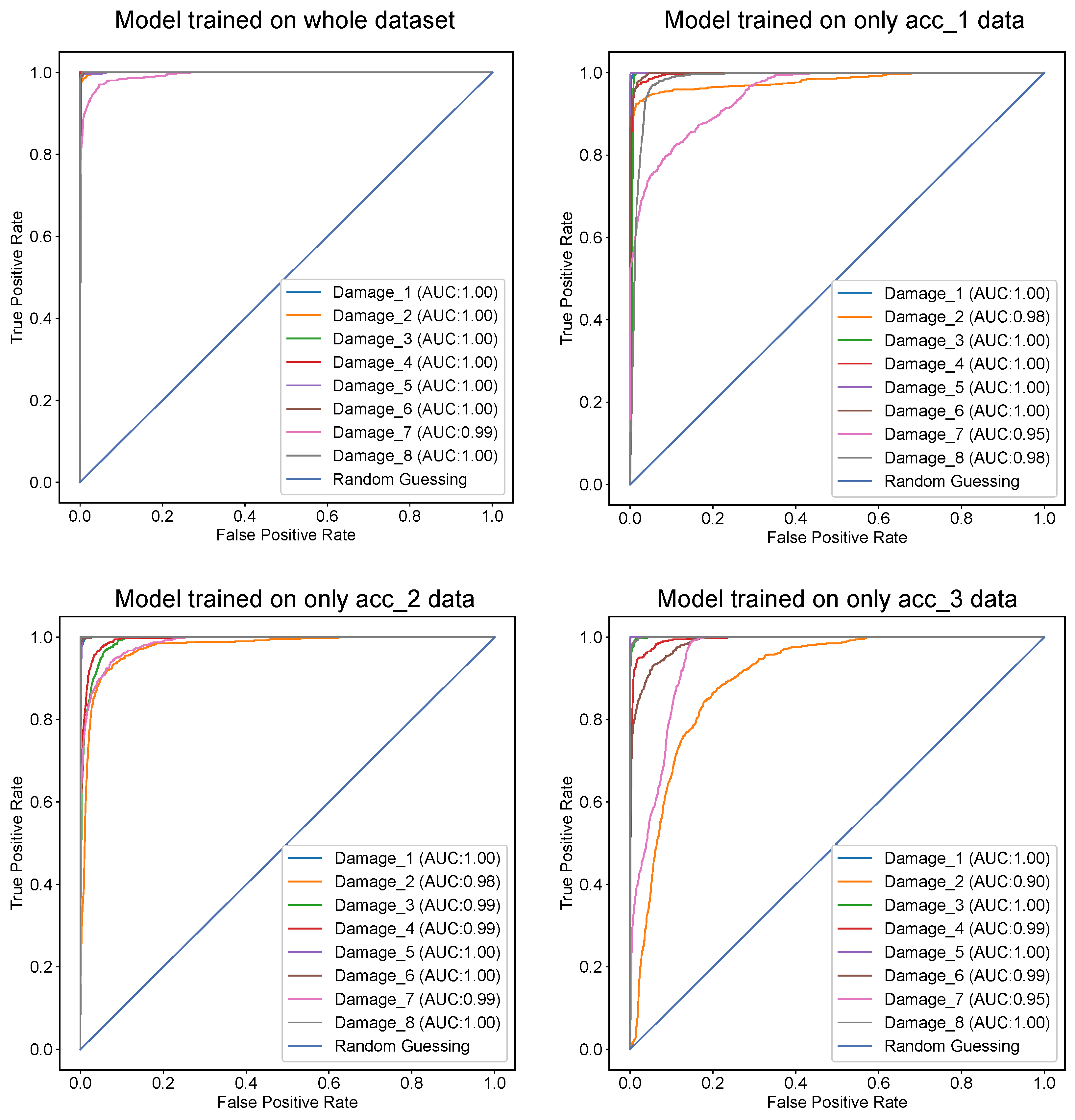
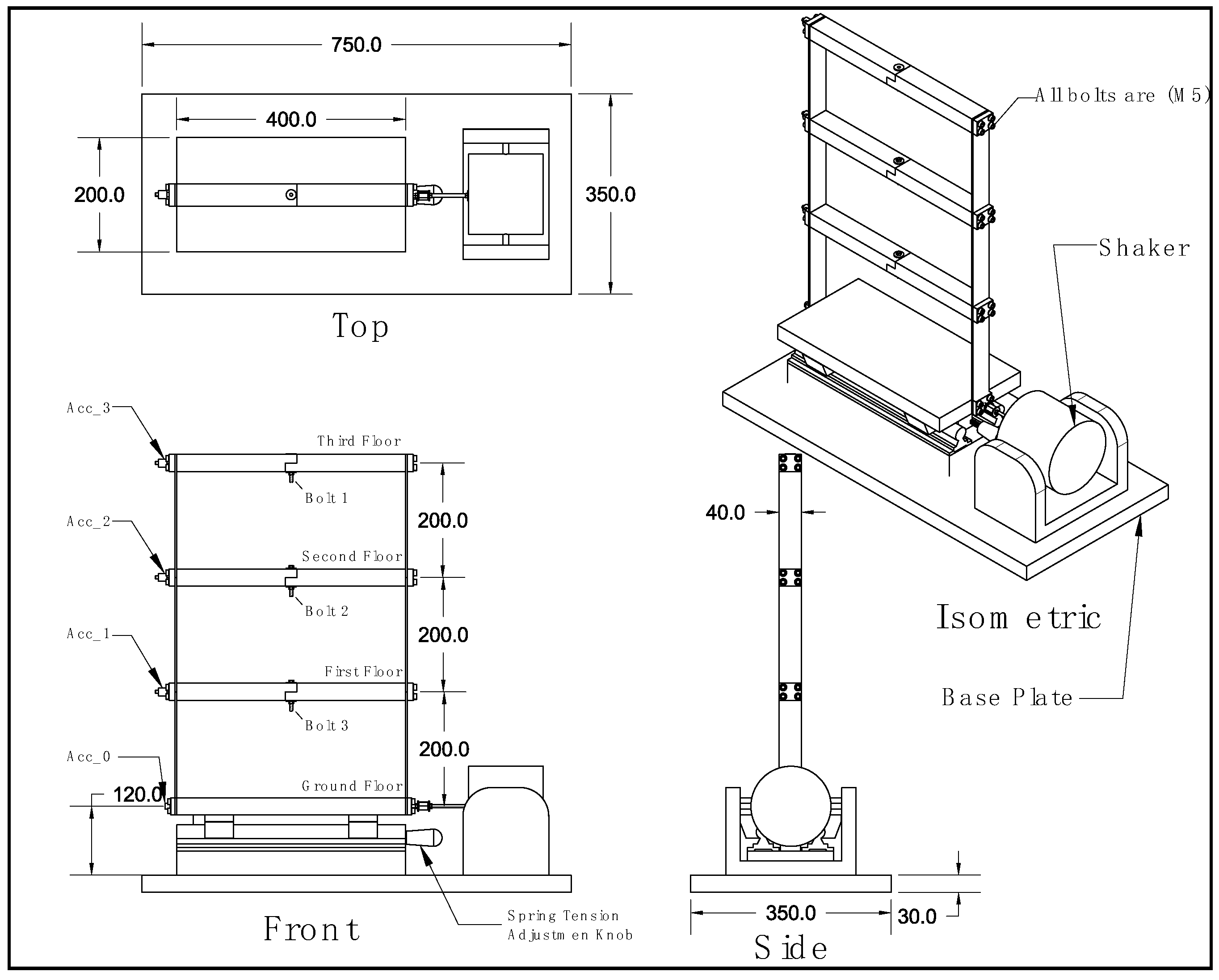
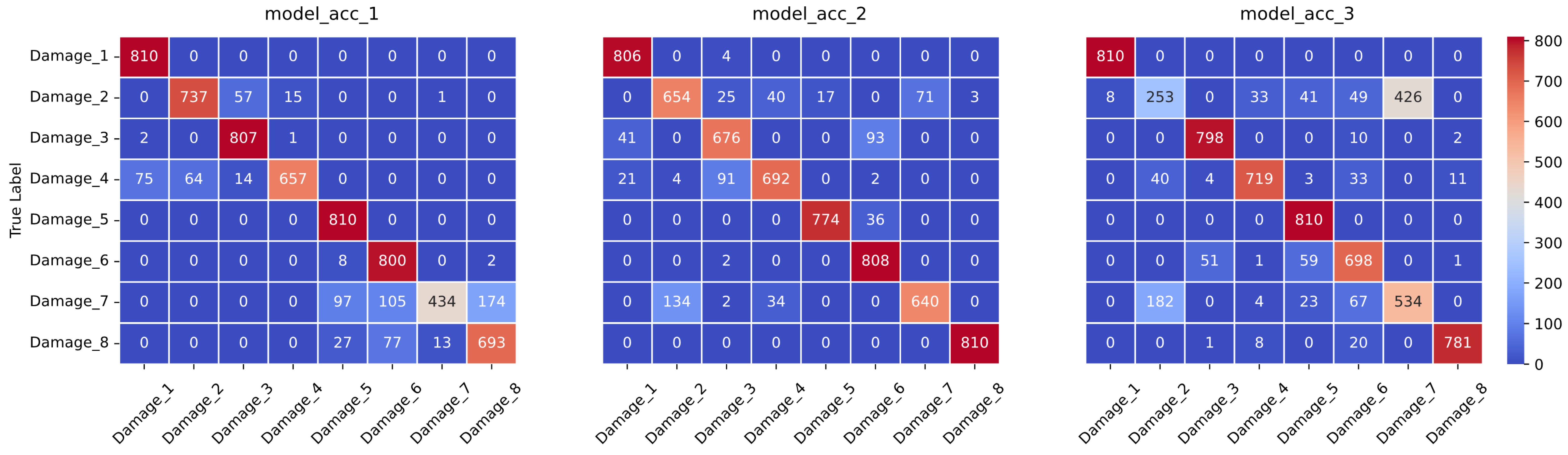
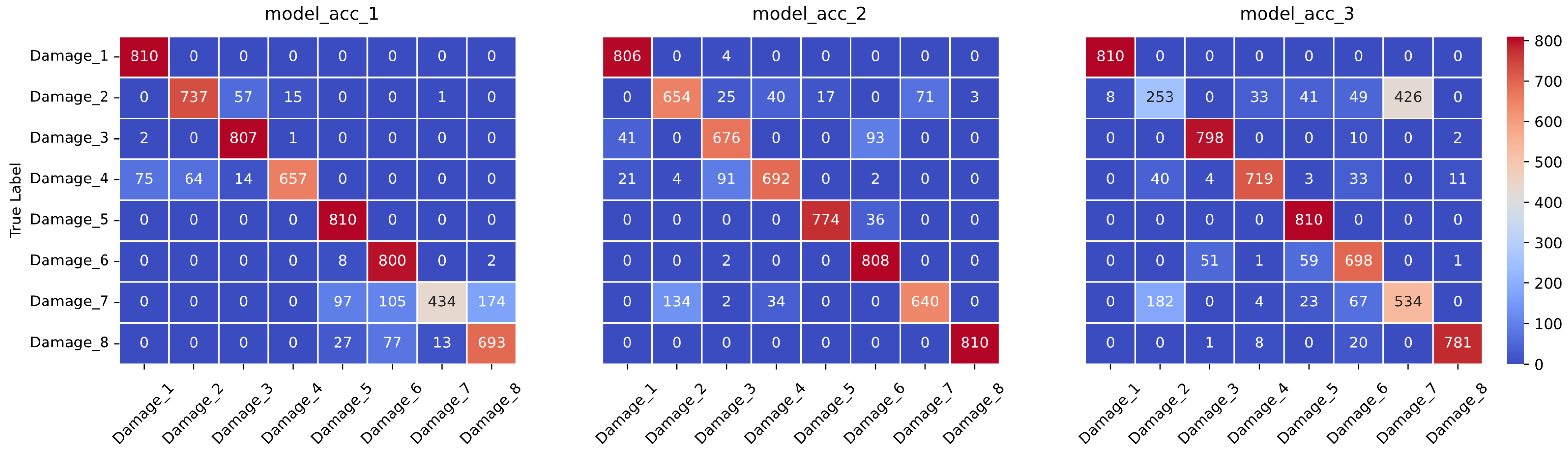
In this study, the presence of accelerometers on every story of the building facilitated comprehensive data collection for structural health monitoring. However, constraints such as scarcity of accelerometers or technical limitations may necessitate working with fewer sensors in some scenarios. Consequently, to address this variability in data availability, separate neural networks were trained using data from single accelerometers in addition to the complete dataset. This approach enabled a comparative analysis of the accuracy levels between the models trained on the entire dataset and those trained on subsets with fewer sensors. To ensure a fair comparison among these neural networks, the search space of the hyperparameters, optimization type, and other relevant parameters remained constant across all experiments. Detailed results, including the accuracy and loss values for each combination of hyperparameters and datasets, are provided in the
Appendix A,
Appendix B and
Appendix C for thorough examination and comparison.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}