
Adversarial Attacks on Medical Segmentation Model via Transformation of Feature Statistics

 ,
,  , , and
, , and 
Abstract
1. Introduction
1.1. Background
1.2. Limitations of Current Works
1.3. Overview of Proposed Method
2. Proposed Methods
2.1. Problem Statement
2.2. Generating Adversarial Images Using Transformation Statistics of Features
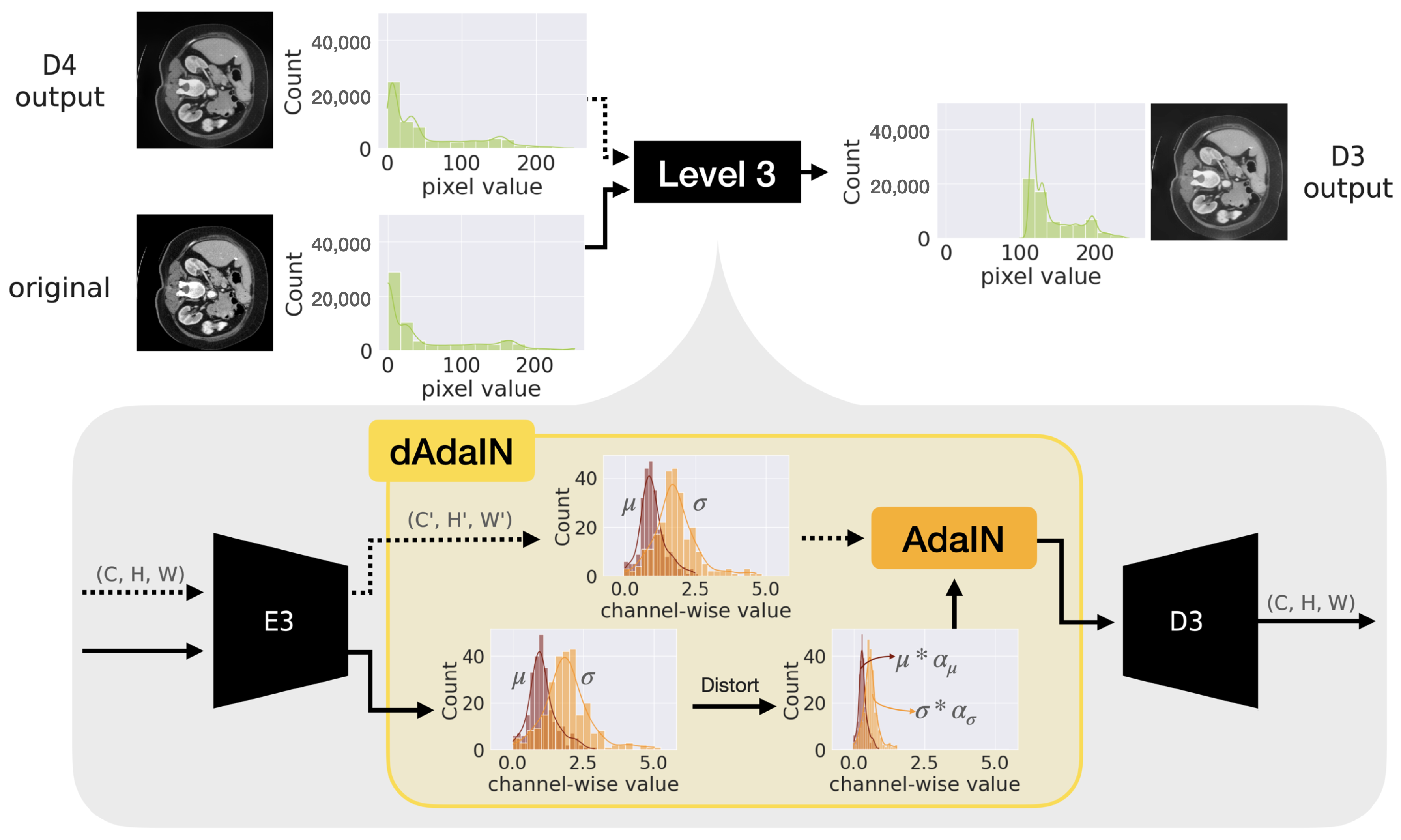
2.3. Generation of Adversarial Sample Using Dynamic Adaptive Instance Normalization
2.3.1. Pre-Processing to Stabilize Statistics of Pixels of Organs
2.3.2. Post-Processing to Generate Realistic Image
3. Experiments
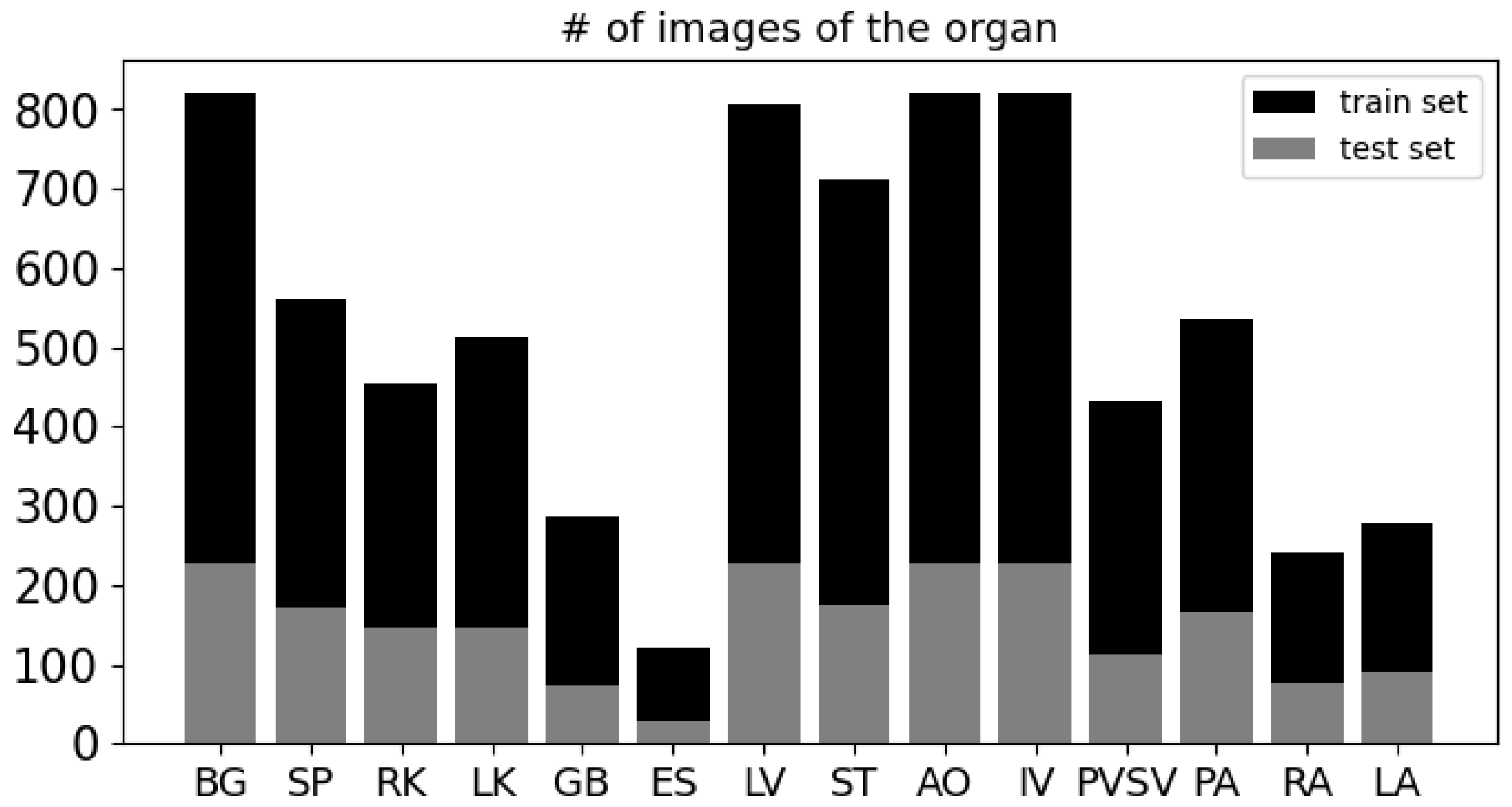
3.1. Data Description and Preprocessing
3.2. Implemented Models
3.2.1. Implemented Target Model
3.2.2. Implemented Attack Methods
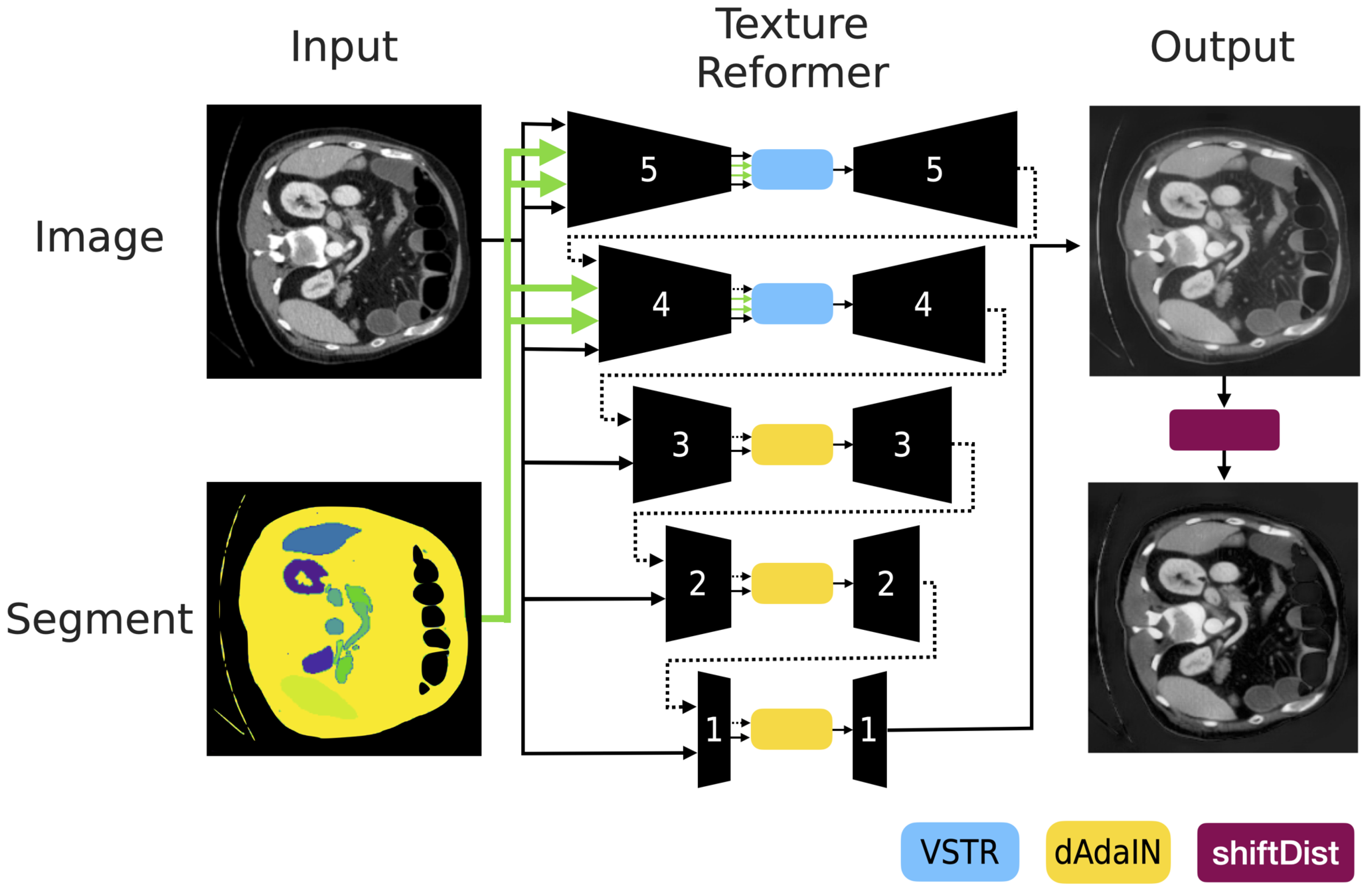
- Our attack method: We adopt the structure of the texture reformer [21] as depicted in Figure 3 and we reimplement the final three levels to transform the statistics as described in Equation (2). The model is based on stacked autoencoders. It contains the five separate encoder-decoder components. Encoder layers consist of convolutional layers similarly VGG19 [31] to extract features from the source image. Decoder layers are structured as flipped encoders using the nearest neighbor interpolation to generate the target image. We exploit open source and pre-trained weights provided by the official implementation (https://github.com/EndyWon/Texture-Reformer, accessed on 25 July 2022). The source code for our framework is available at https://github.com/hyerica-bdml/adversarial-attack-transformation-statistics (accessed on 17 March 2024).
- FGSM: It calculates gradients given input image x and corresponding class y. The gradients act as a direction for maximizing the loss function J of the target model. The direction is added into original image x to generate the adversarial sample . We formulate the attack as below:where is the step size.
- BIM: It is an iterative method while FGSM is a one-step method. The difference is that BIM maximizes the loss repetitively (for instance, K times) and adds stacks of the gradients to the original image. BIM is defined as the following equation for our problem:where initial is the input image x and is the clipping function to avoid exceeding pixel values in the range from to .
- SMIA: It is specialized to fool models in only the medical domain whereas FGSM and BIM are for general purposes. Unlike how those models produce noisy results, SMIA reduces noise. The key idea is that while adversarial samples tend to be noisy, SMIA adds a stabilization function into the loss function to force the noisy sample close to the blurred sample obtained by a Gaussian kernel. The stabilization loss for maximization is formulated for our problem as follows:where W is the Gaussian kernel to convolutional operation with the perturbation noise () and is the scalar balancing factor for the loss terms.
3.3. Evaluation Metric
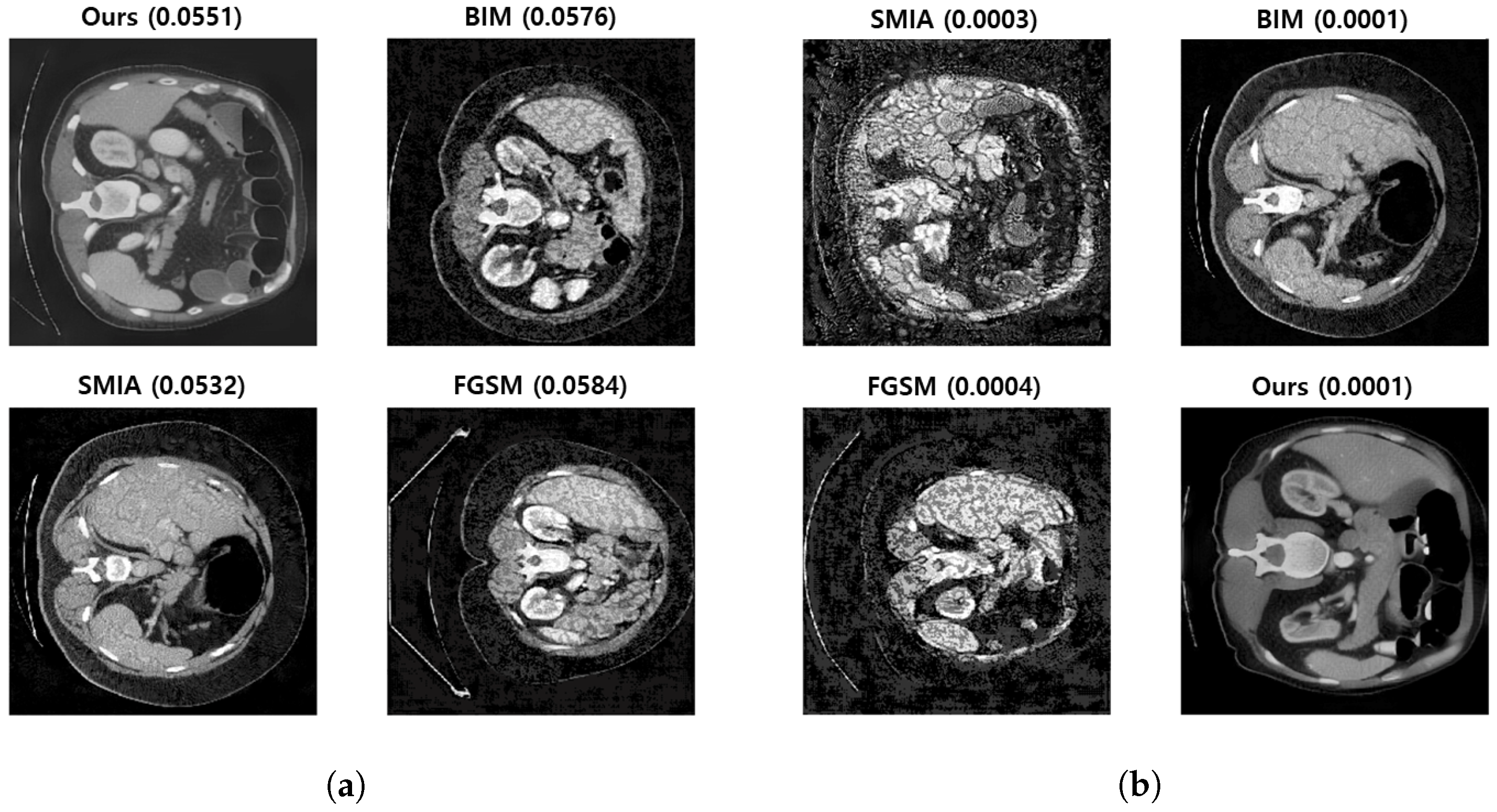
3.4. Qualitative Evaluation by Physicians
- Null hypothesis: The adversarial images produced by our method are no more convincingly realistic than those produced by other methods.
- Alternative hypothesis: The adversarial images produced by our method are significantly more convincing in their resemblance to real images than those produced by other methods.
3.5. Limitations and Comparative Analysis
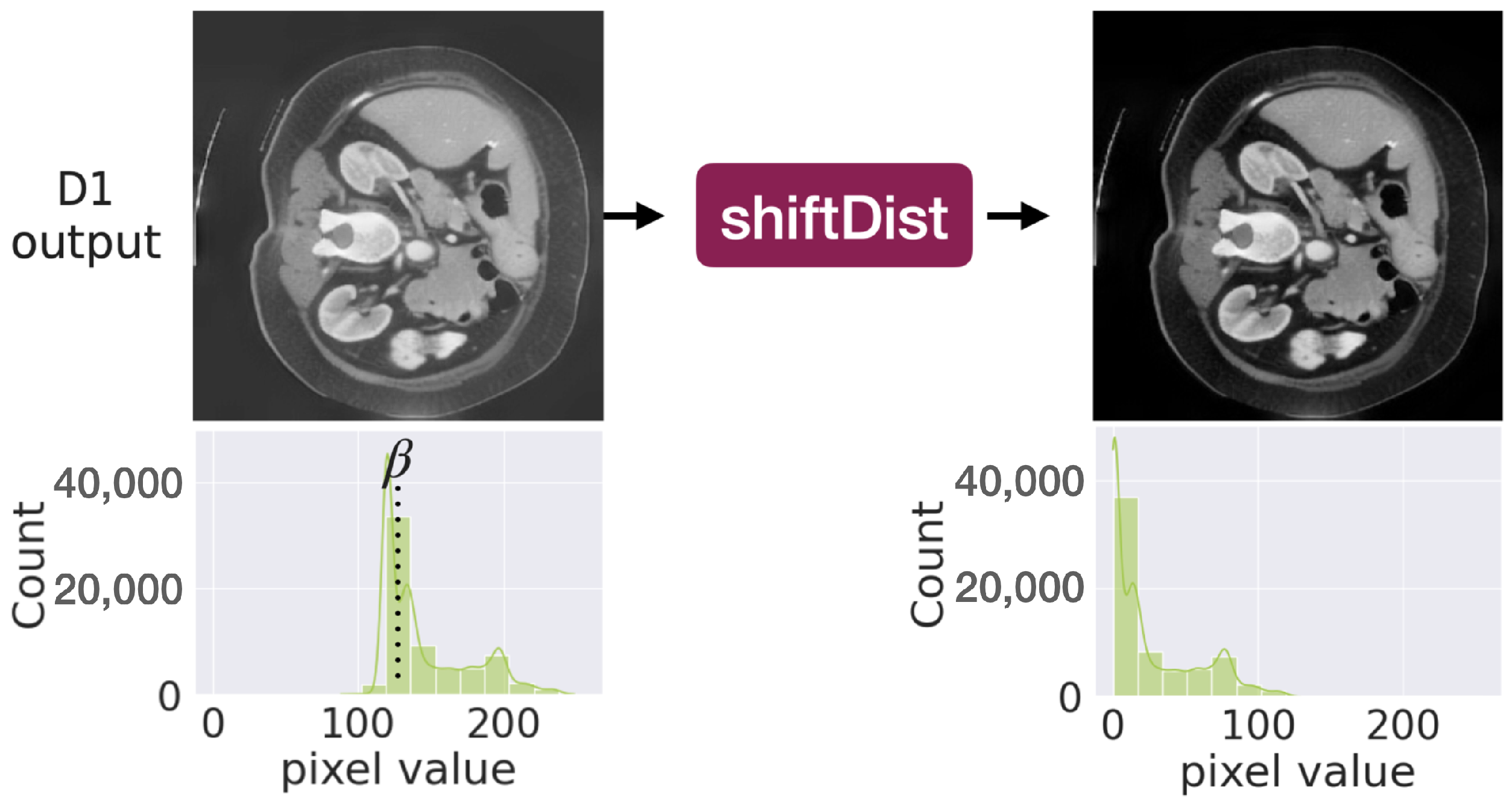
- Some values of transformation factors and tend to create darker samples. By adopting factor values less than 1, the transformed features contribute to a restored image with higher pixel values and smaller variance compared to the input image. This results in a final image adjusted by shiftDist that is darker than the original.
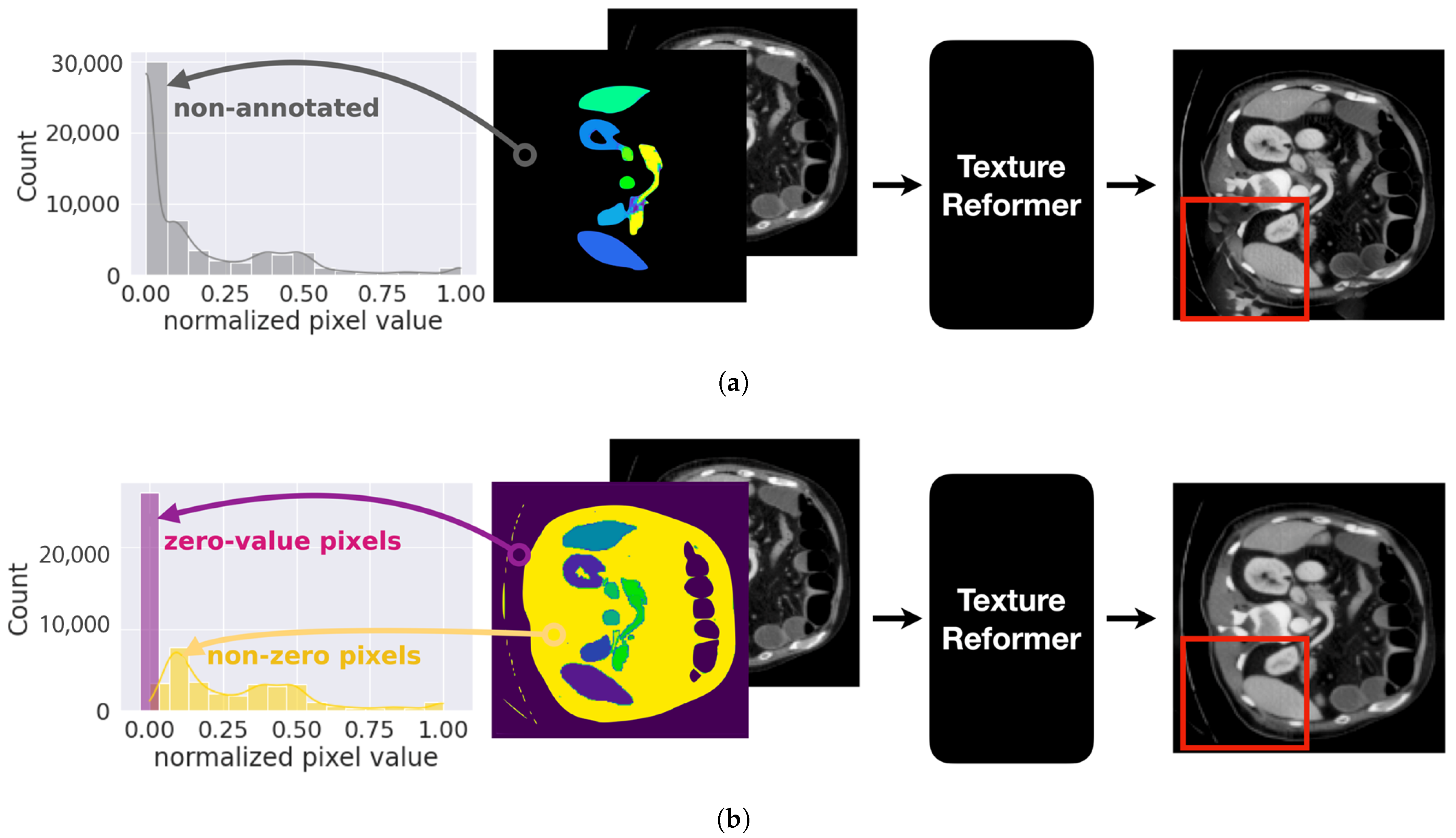
- The instances of white noise and blurring appear to stem from the high variance seen in the non-zero pixel values in regions that were not annotated, as evidenced by the yellow bars in the histogram in Figure 4b. This leads the VSTR modules of the texture reformer to blend the pixel values of the bone and the organ.
3.6. Application of the Proposed Method: Data Augmentation
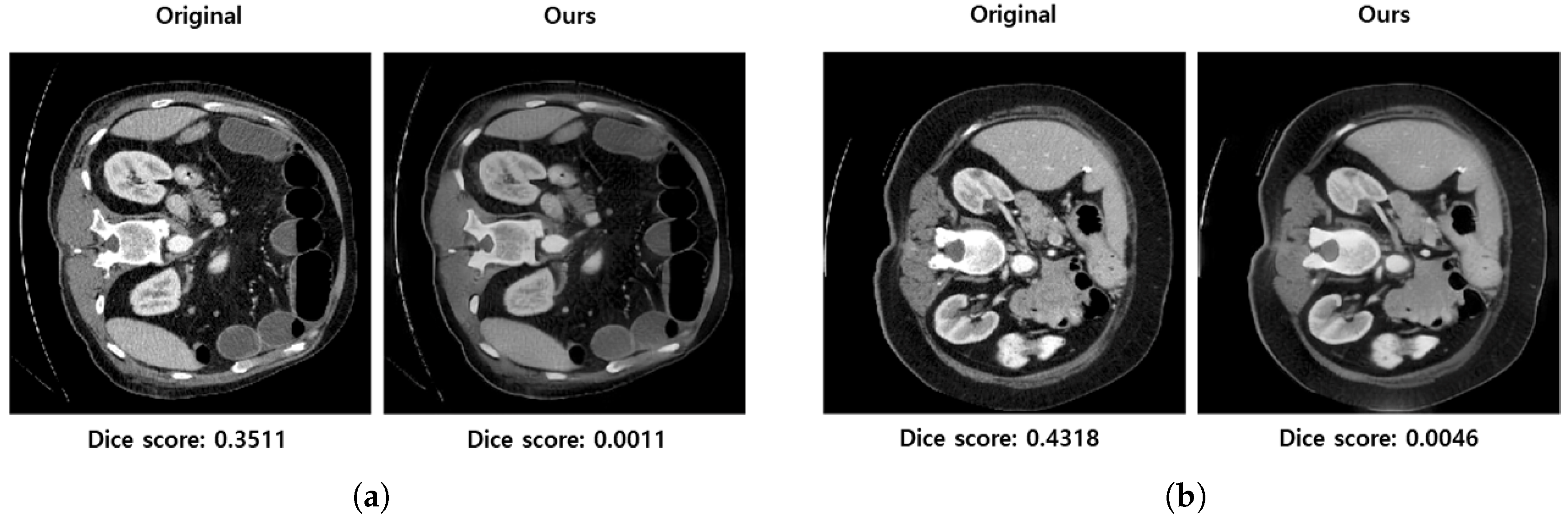
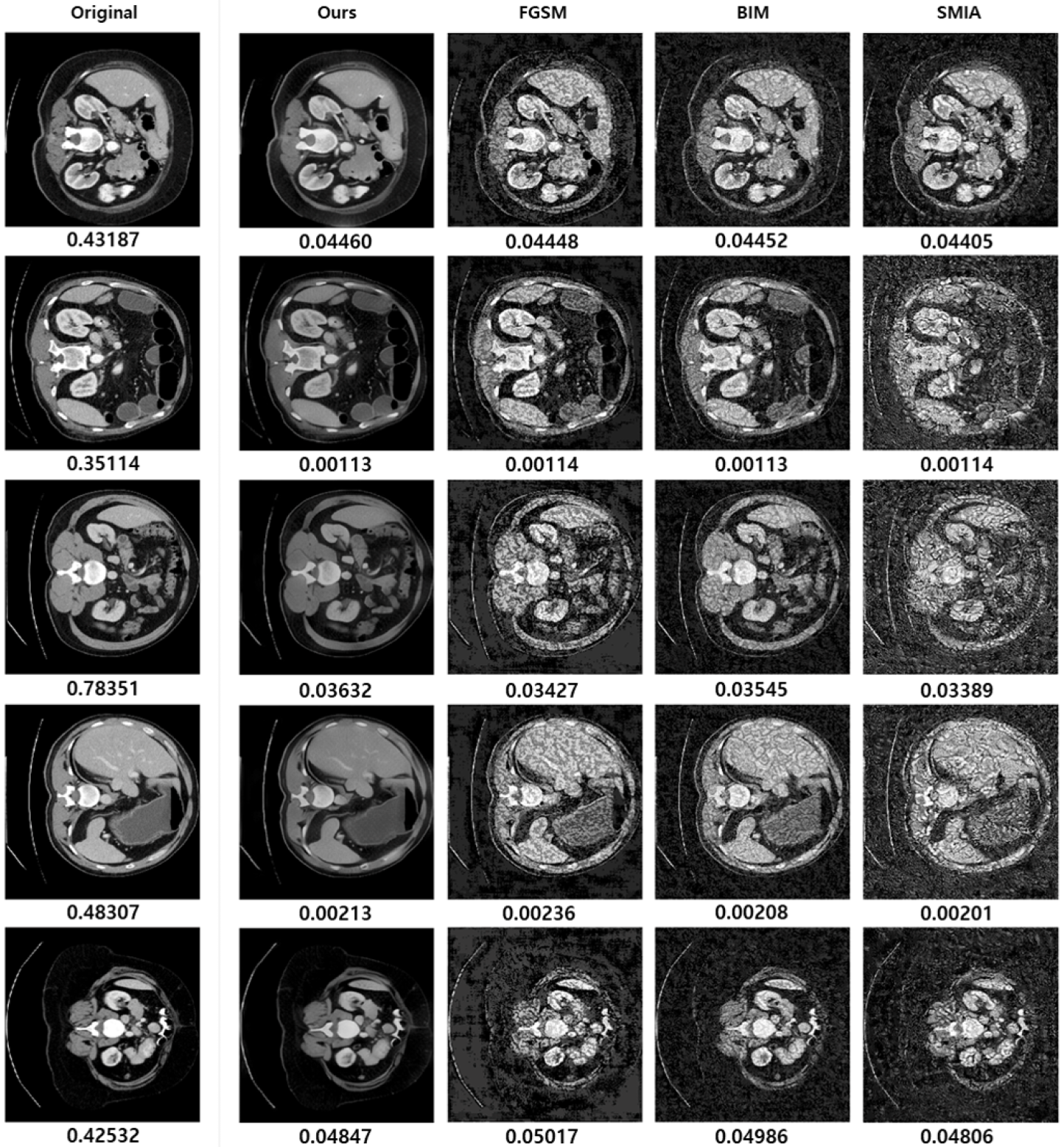
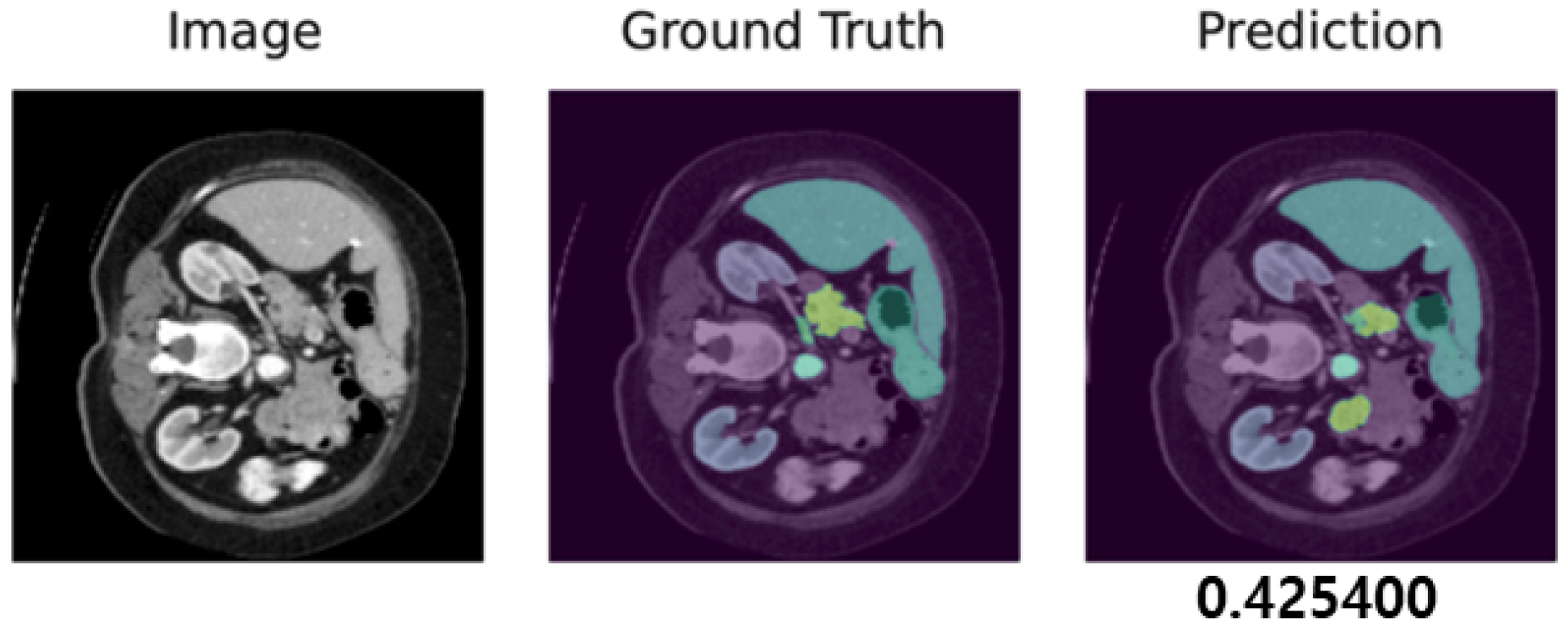
3.7. Case Study: Visualization of Adversarial Samples and Predictions
3.8. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, C.; Ding, C.; Wang, X.; Lu, Z.; Tao, D. One-pass multi-task networks with cross-task guided attention for brain tumor segmentation. IEEE Trans. Image Process. 2020, 29, 4516–4529. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Sui, X.; Luo, X.; Xu, X.; Liu, Y.; Goh, R. Medical image segmentation using squeeze-and-expansion transformers. arXiv 2021, arXiv:2105.09511. [Google Scholar]
- Calisto, F.M.; Nunes, N.; Nascimento, J.C. BreastScreening: On the use of multi-modality in medical imaging diagnosis. In Proceedings of the International Conference on Advanced Visual Interfaces, Ischia, Italy, 28 September–2 October 2020; pp. 1–5. [Google Scholar]
- Zuo, Z.; Li, J.; Xu, H.; Al Moubayed, N. Curvature-based feature selection with application in classifying electronic health records. Technol. Forecast. Soc. Chang. 2021, 173, 121127. [Google Scholar] [CrossRef]
- Tang, Y.; Yang, D.; Li, W.; Roth, H.R.; Landman, B.; Xu, D.; Nath, V.; Hatamizadeh, A. Self-supervised pre-training of swin transformers for 3d medical image analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LO, USA, 18–24 June 2022; pp. 20730–20740. [Google Scholar]
- Isensee, F.; Petersen, J.; Klein, A.; Zimmerer, D.; Jaeger, P.F.; Kohl, S.; Wasserthal, J.; Koehler, G.; Norajitra, T.; Wirkert, S.; et al. nnu-net: Self-adapting framework for u-net-based medical image segmentation. arXiv 2018, arXiv:1809.10486. [Google Scholar]
- Benčević, M.; Galić, I.; Habijan, M.; Babin, D. Training on polar image transformations improves biomedical image segmentation. IEEE Access 2021, 9, 133365–133375. [Google Scholar] [CrossRef]
- Edlund, C.; Jackson, T.R.; Khalid, N.; Bevan, N.; Dale, T.; Dengel, A.; Ahmed, S.; Trygg, J.; Sjögren, R. LIVECell—A large-scale dataset for label-free live cell segmentation. Nat. Methods 2021, 18, 1038–1045. [Google Scholar] [CrossRef] [PubMed]
- Bakkes, T.; van Diepen, A.; De Bie, A.; Montenij, L.; Mojoli, F.; Bouwman, A.; Mischi, M.; Woerlee, P.; Turco, S. Automated detection and classification of patient–ventilator asynchrony by means of machine learning and simulated data. Comput. Methods Programs Biomed. 2023, 230, 107333. [Google Scholar] [CrossRef] [PubMed]
- Hatamizadeh, A.; Tang, Y.; Nath, V.; Yang, D.; Myronenko, A.; Landman, B.; Roth, H.R.; Xu, D. Unetr: Transformers for 3d medical image segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 574–584. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1765–1773. [Google Scholar]
- Pal, B.; Gupta, D.; Rashed-Al-Mahfuz, M.; Alyami, S.A.; Moni, M.A. Vulnerability in deep transfer learning models to adversarial fast gradient sign attack for covid-19 prediction from chest radiography images. Appl. Sci. 2021, 11, 4233. [Google Scholar] [CrossRef]
- Chen, L.; Bentley, P.; Mori, K.; Misawa, K.; Fujiwara, M.; Rueckert, D. Intelligent image synthesis to attack a segmentation CNN using adversarial learning. In Proceedings of the International Workshop on Simulation and Synthesis in Medical Imaging, Shenzhen, China, 13 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 90–99. [Google Scholar]
- Li, Y.; Zhu, Z.; Zhou, Y.; Xia, Y.; Shen, W.; Fishman, E.K.; Yuille, A.L. Volumetric medical image segmentation: A 3D deep coarse-to-fine framework and its adversarial examples. In Deep Learning and Convolutional Neural Networks for Medical Imaging and Clinical Informatics; Springer: Berlin/Heidelberg, Germany, 2019; pp. 69–91. [Google Scholar]
- Pervin, M.; Tao, L.; Huq, A.; He, Z.; Huo, L. Adversarial attack driven data augmentation for accurate and robust medical image segmentation. arXiv 2021, arXiv:2105.12106. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Artificial Intelligence Safety and Security; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; pp. 99–112. [Google Scholar]
- Qi, G.; Lijun, G.; Song, Y.; Ma, K.; Zheng, Y. Stabilized medical image attacks. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Aguirre, D.A.; Santosa, A.C.; Casola, G.; Sirlin, C.B. Abdominal wall hernias: Imaging features, complications, and diagnostic pitfalls at multi–detector row CT. Radiographics 2005, 25, 1501–1520. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Zhao, L.; Chen, H.; Li, A.; Zuo, Z.; Xing, W.; Lu, D. Texture reformer: Towards fast and universal interactive texture transfer. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 2624–2632. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Xia, X.; Xue, T.; Lai, W.s.; Sun, Z.; Chang, A.; Kulis, B.; Chen, J. Real-time localized photorealistic video style transfer. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Online, 5–9 January 2021; pp. 1089–1098. [Google Scholar]
- Chandran, P.; Zoss, G.; Gotardo, P.; Gross, M.; Bradley, D. Adaptive convolutions for structure-aware style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 7972–7981. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Landman, B.; Xu, Z.; Igelsias, J.; Styner, M.; Langerak, T.; Klein, A. Miccai multi-atlas labeling beyond the cranial vault–workshop and challenge. In Proceedings of the MICCAI Multi-Atlas Labeling Beyond Cranial Vault—Workshop Challenge, Munich, Germany, 4–9 October 2015; Volume 5, p. 12. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 4–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Dong, J.; Chen, J.; Xie, X.; Lai, J.; Chen, H. Adversarial attack and defense for medical image analysis: Methods and applications. arXiv 2023, arXiv:2303.14133. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Organ | Pre-Augmentation | Post-Augmentation | Difference |
|---|---|---|---|
| Background (BG) | 0.9856 | 0.9861 | +0.0004 |
| Spleen (SP) | 0.6454 | 0.6599 | +0.0145 |
| Right Kidney (RK) | 0.5710 | 0.5708 | −0.0003 |
| Left Kidney (LK) | 0.5618 | 0.5796 | +0.0177 |
| Gallbladder (BG) | 0.1803 | 0.1626 | −0.0177 |
| Esophagus (ES) | 0.0000 | 0.0640 | +0.0640 |
| Liver (LV) | 0.9371 | 0.9379 | +0.0008 |
| Stomach (ST) | 0.4870 | 0.4881 | +0.0011 |
| Aorta (AO) | 0.8744 | 0.8901 | +0.0157 |
| Inferior Vena Cava (IV) | 0.5351 | 0.6405 | +0.1054 |
| Portal and Splenic Vein (PVSV) | 0.2536 | 0.2467 | −0.0069 |
| Pancreas (PA) | 0.3018 | 0.3003 | −0.0015 |
| Right Adrenal Gland (RA) | 0.0000 | 0.1103 | +0.1103 |
| Left Adrenal Gland (LA) | 0.0000 | 0.1098 | +0.1098 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, W.; Ju, M.; Sim, Y.; Jung, Y.K.; Kim, T.H.; Kim, Y. Adversarial Attacks on Medical Segmentation Model via Transformation of Feature Statistics. Appl. Sci. 2024, 14, 2576. https://doi.org/10.3390/app14062576
Lee W, Ju M, Sim Y, Jung YK, Kim TH, Kim Y. Adversarial Attacks on Medical Segmentation Model via Transformation of Feature Statistics. Applied Sciences. 2024; 14(6):2576. https://doi.org/10.3390/app14062576
Chicago/Turabian StyleLee, Woonghee, Mingeon Ju, Yura Sim, Young Kul Jung, Tae Hyung Kim, and Younghoon Kim. 2024. "Adversarial Attacks on Medical Segmentation Model via Transformation of Feature Statistics" Applied Sciences 14, no. 6: 2576. https://doi.org/10.3390/app14062576
APA StyleLee, W., Ju, M., Sim, Y., Jung, Y. K., Kim, T. H., & Kim, Y. (2024). Adversarial Attacks on Medical Segmentation Model via Transformation of Feature Statistics. Applied Sciences, 14(6), 2576. https://doi.org/10.3390/app14062576