
Comparison of Domain Selection Methods for Multi-Source Manifold Feature Transfer Learning in Electroencephalogram Classification


Abstract
1. Introduction
- Investigate the impact of highly beneficial and less-beneficial sources contributing to negative transfer.
- Evaluate the performance of domain selection methods based on two-class, three-class, and four-class cross-subject EEG classification problems.
- A comparative performance analysis is carried out among EMC-MMFT, DTE-MMFT, LSA-MMFT, and ROD-MMFT. The experiment’s results show that EMC-MMFT outperforms all the other domain selection algorithms for all the two-class, three-class, four-class, inter-session, and inter-subject classification problems.
2. Related Work
2.1. Rank of Domain (ROD)
2.2. Domain Transferability Estimation (DTE)
2.3. Label Similarity Analysis MMFT (LSA-MMFT)
2.4. Enhanced Multi-Class MMFT (EMC-MMFT)
3. Materials and Methods
3.1. Dataset Descriptions
3.1.1. BCI Competition IV-A Dataset
3.1.2. Our Own Recorded SSMVEP Dataset
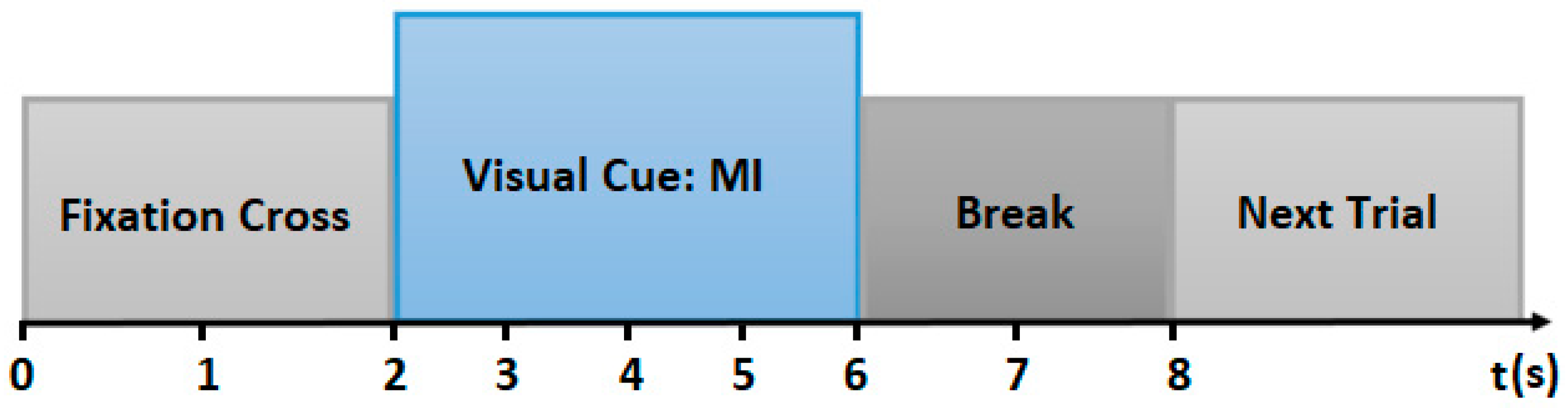
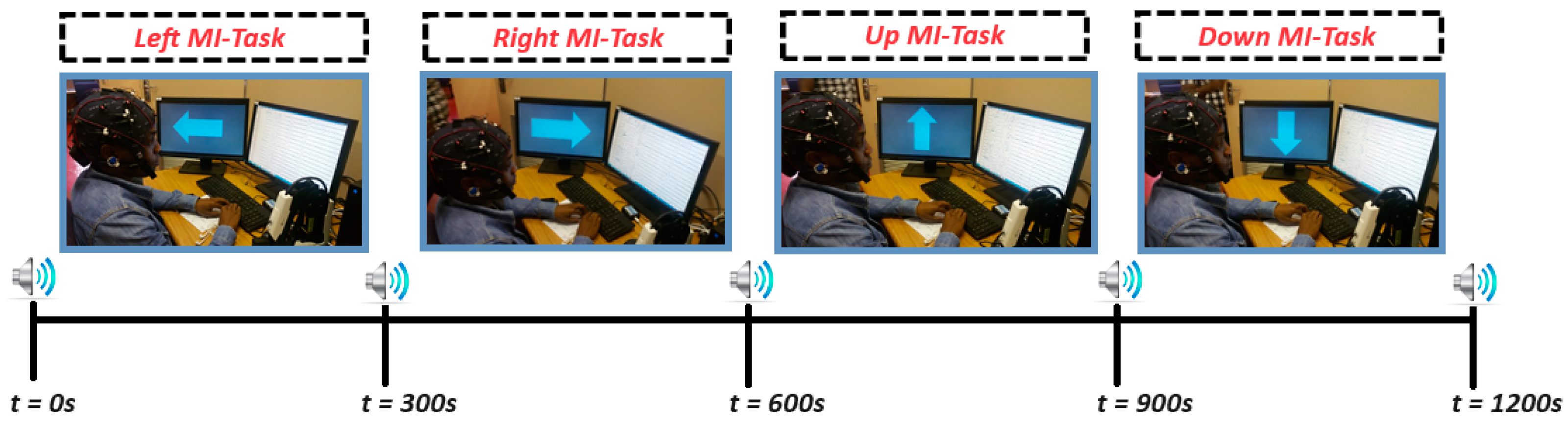
3.1.3. Our Own Recorded Motor Imagery (MI) Dataset
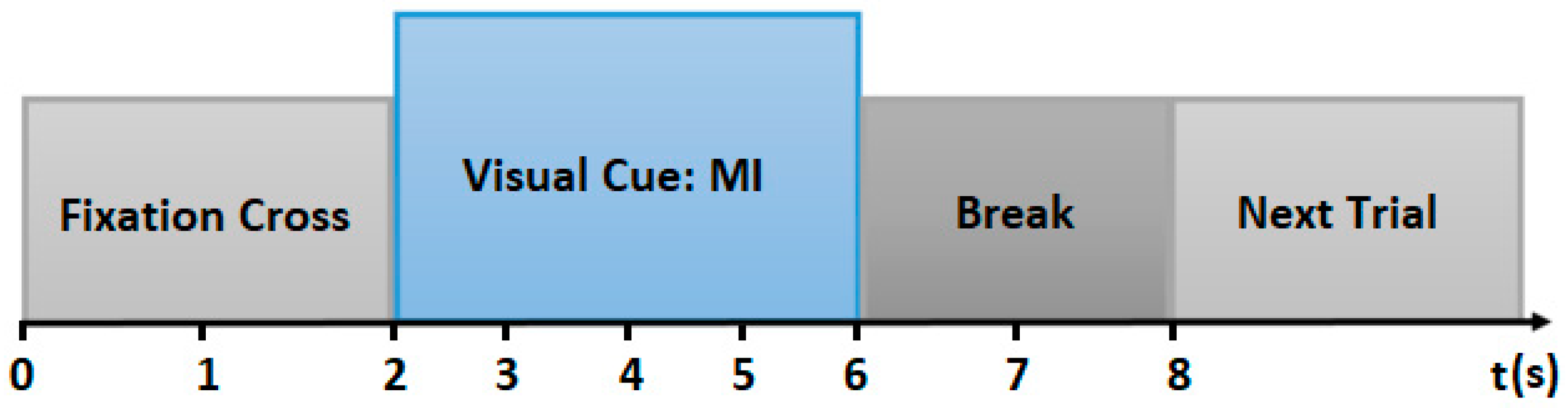
3.2. Data Pre-Processing
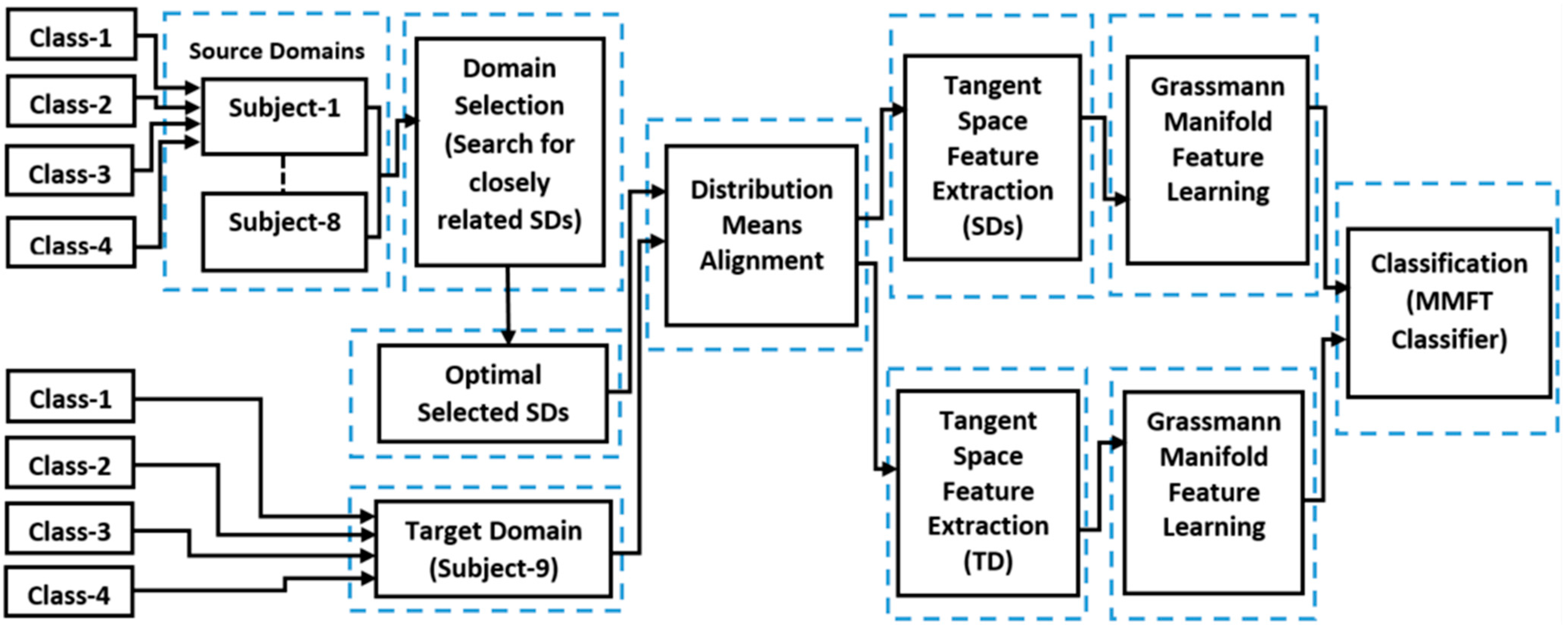
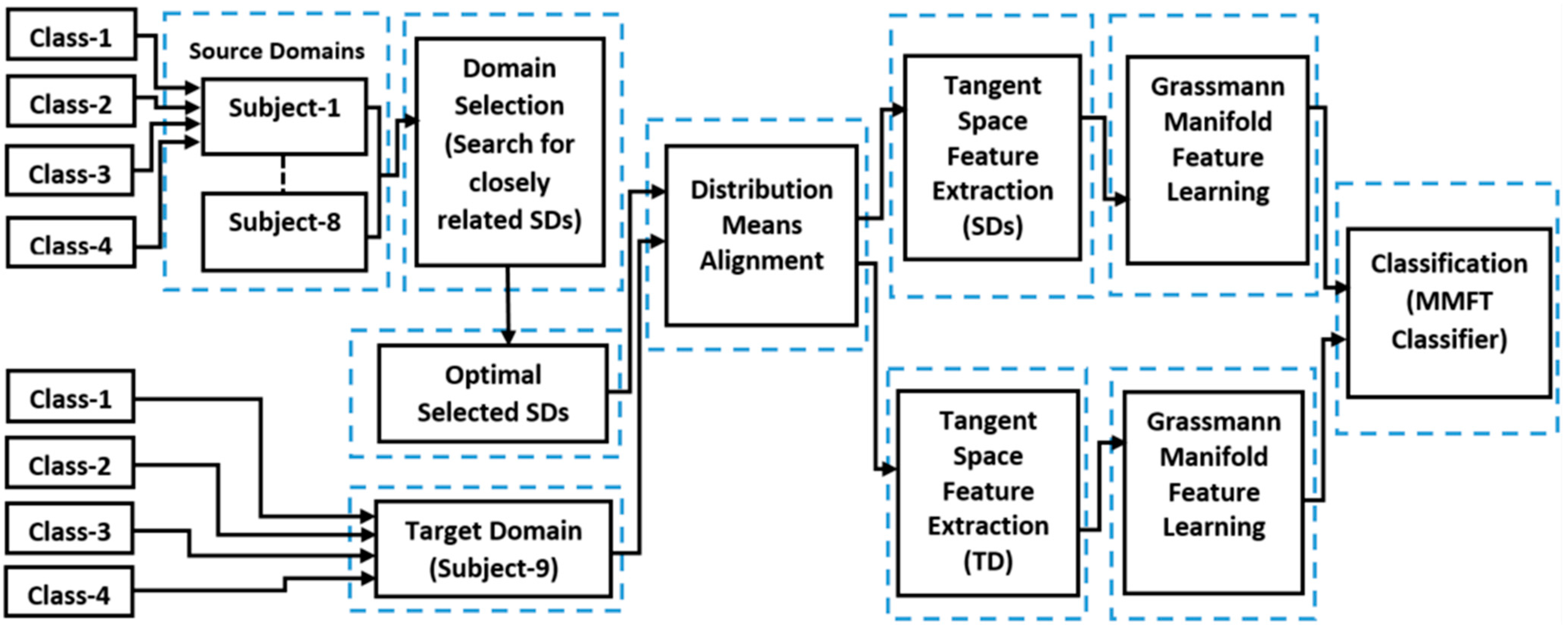
3.3. Experimental Methods
4. Results
4.1. Experiment Setup
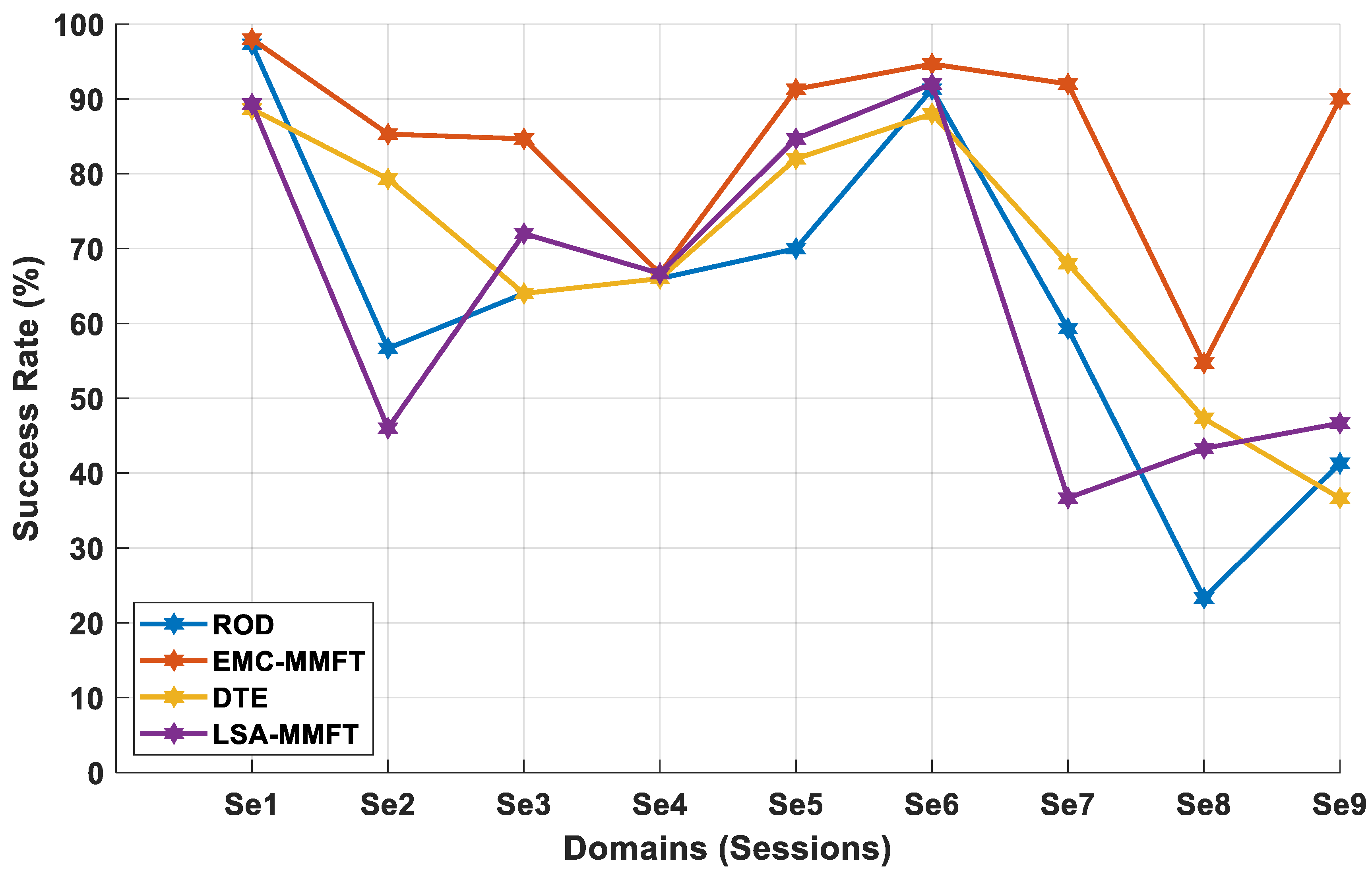
4.1.1. Two-Class Inter-Session and Inter-Subject Classification Scenario
4.1.2. Three-Class Inter-Session and Inter-Subject Classification Scenario
4.1.3. Four-Class Inter-Session and Inter-Subject Classification Scenario
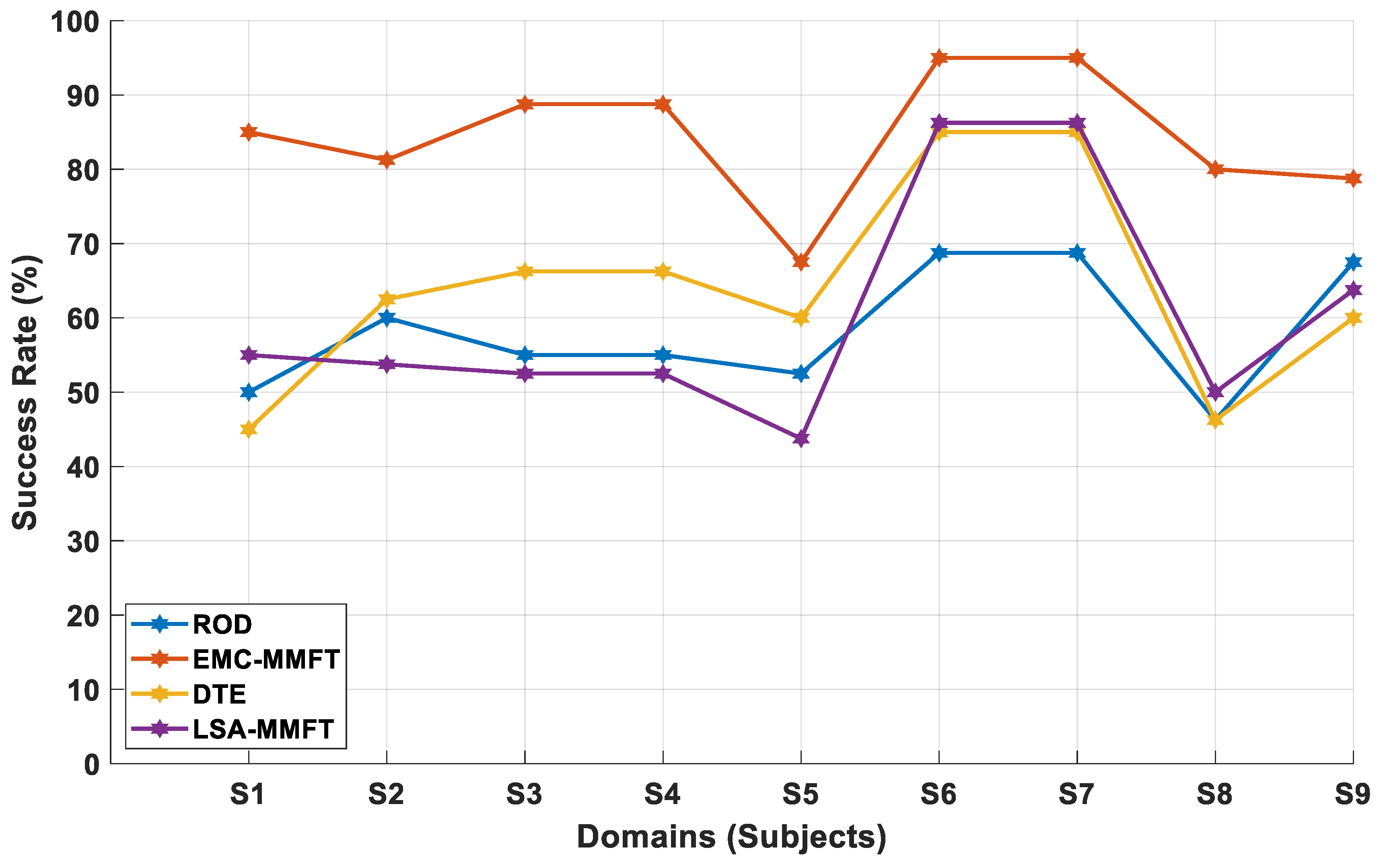
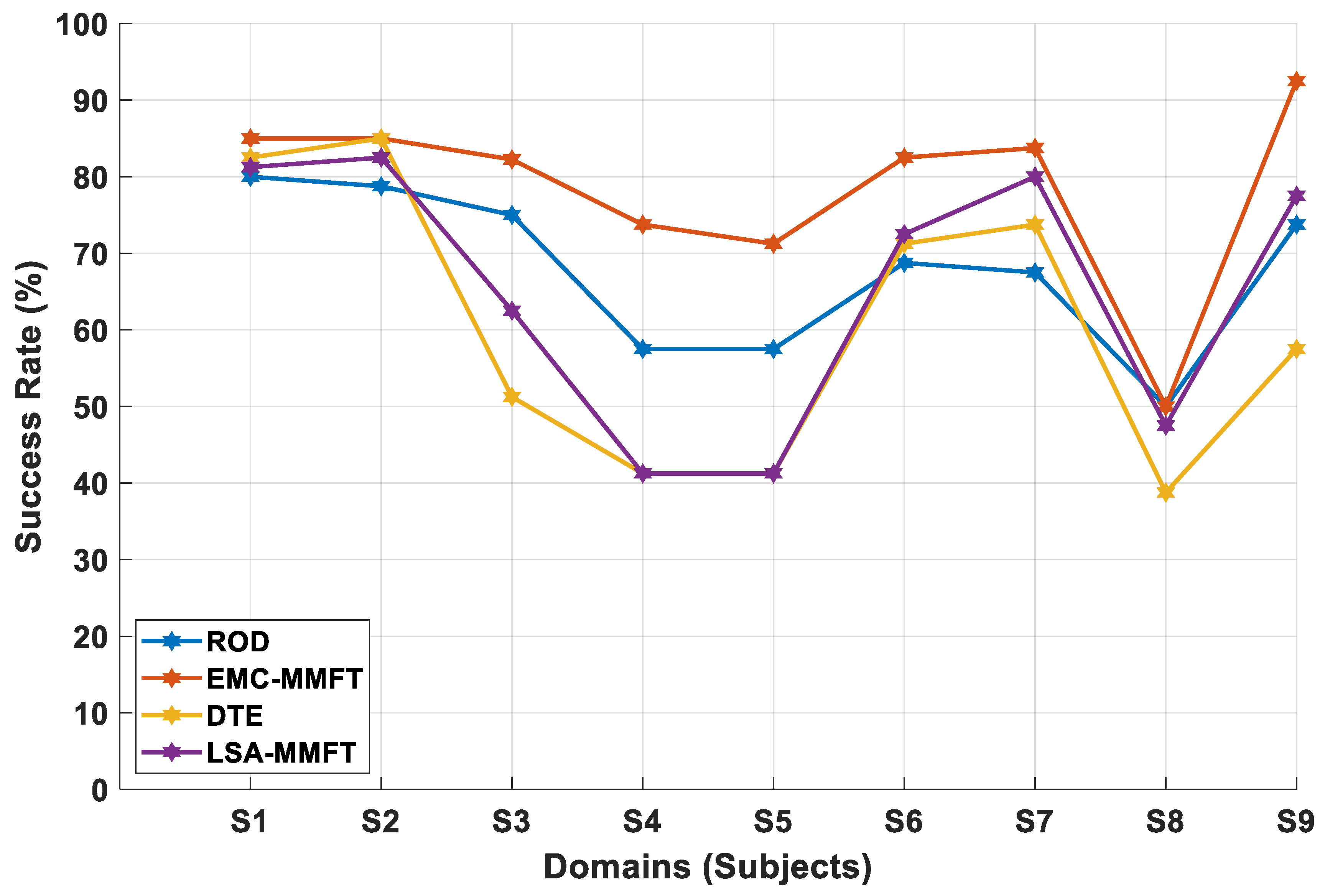
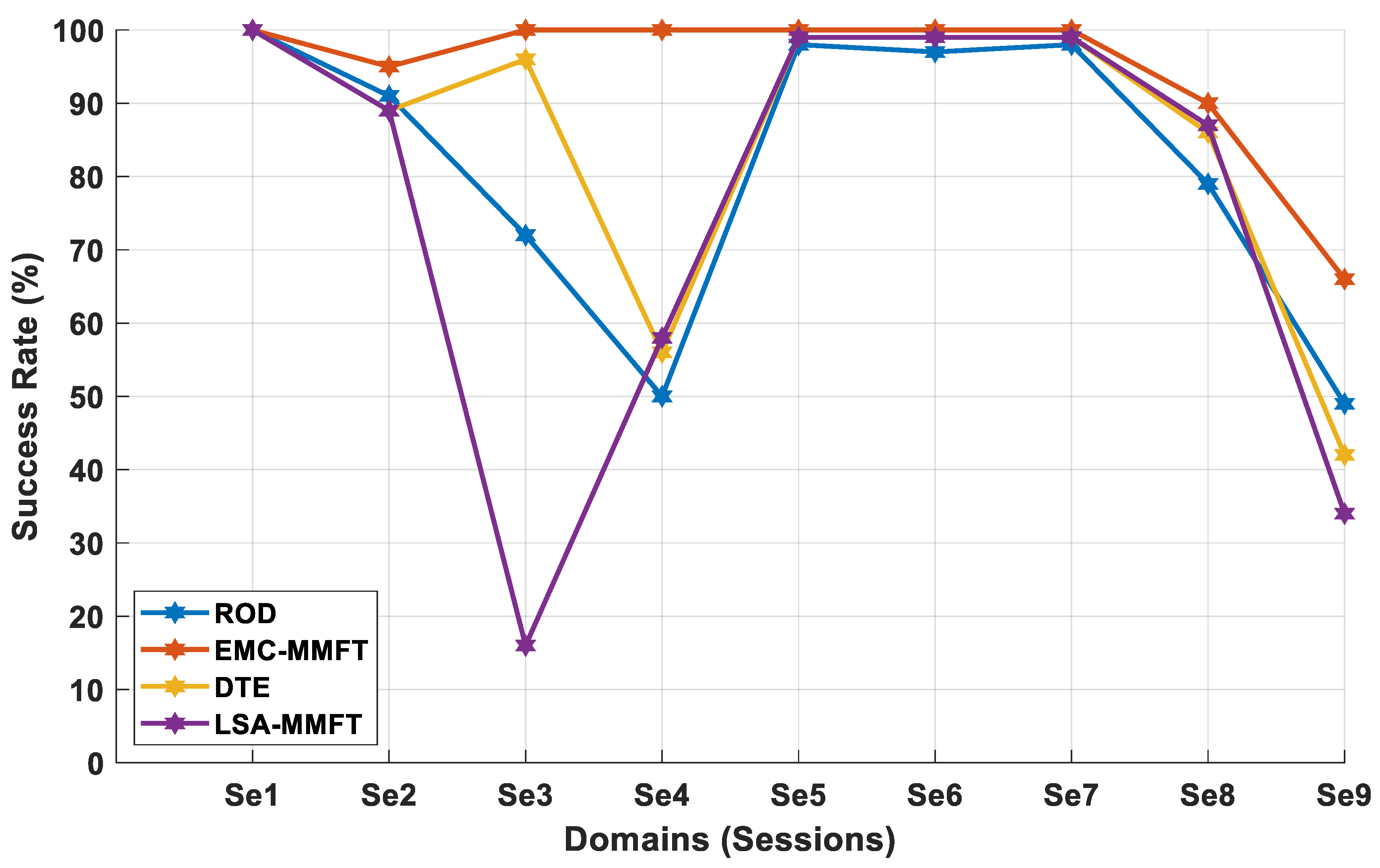
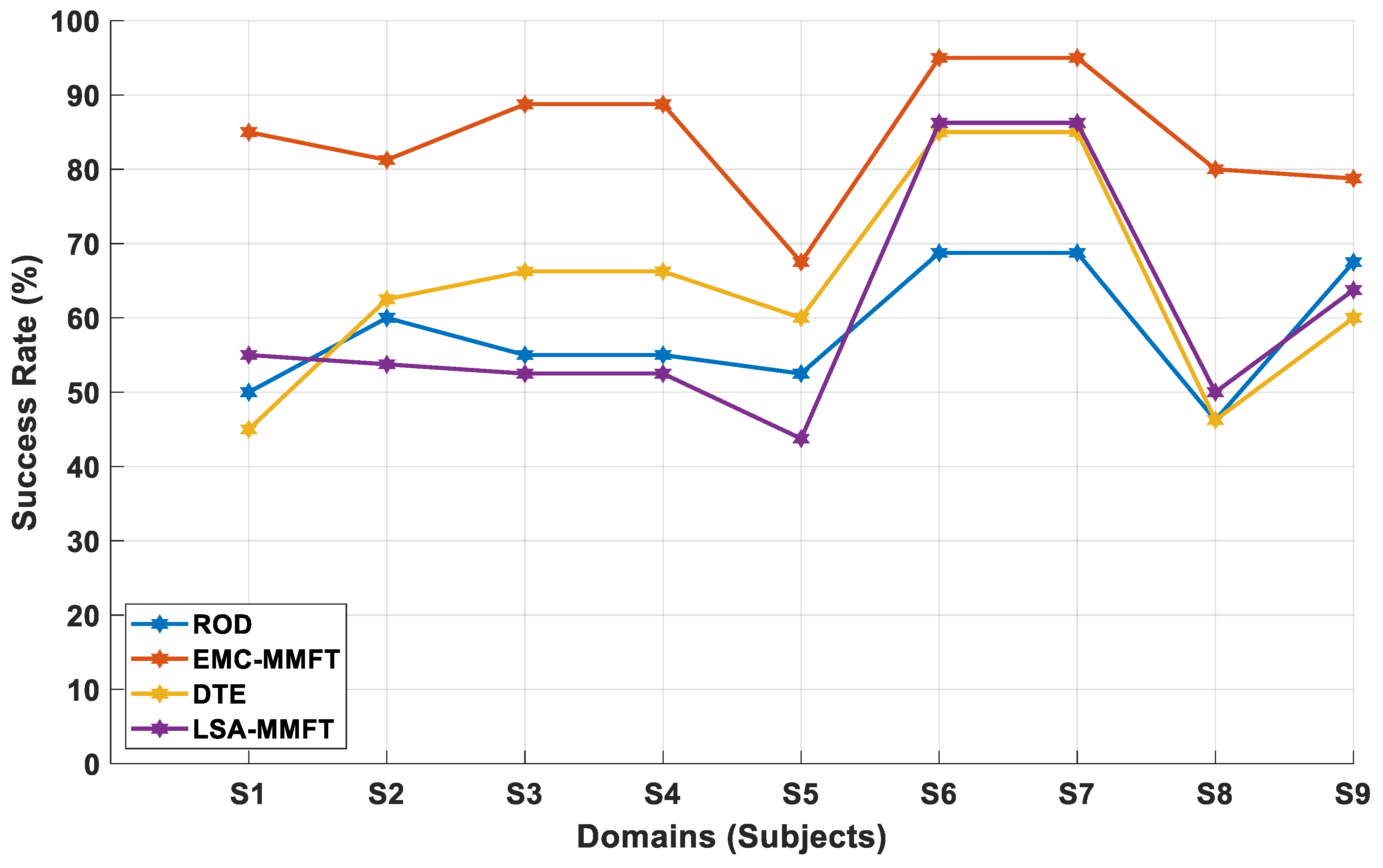
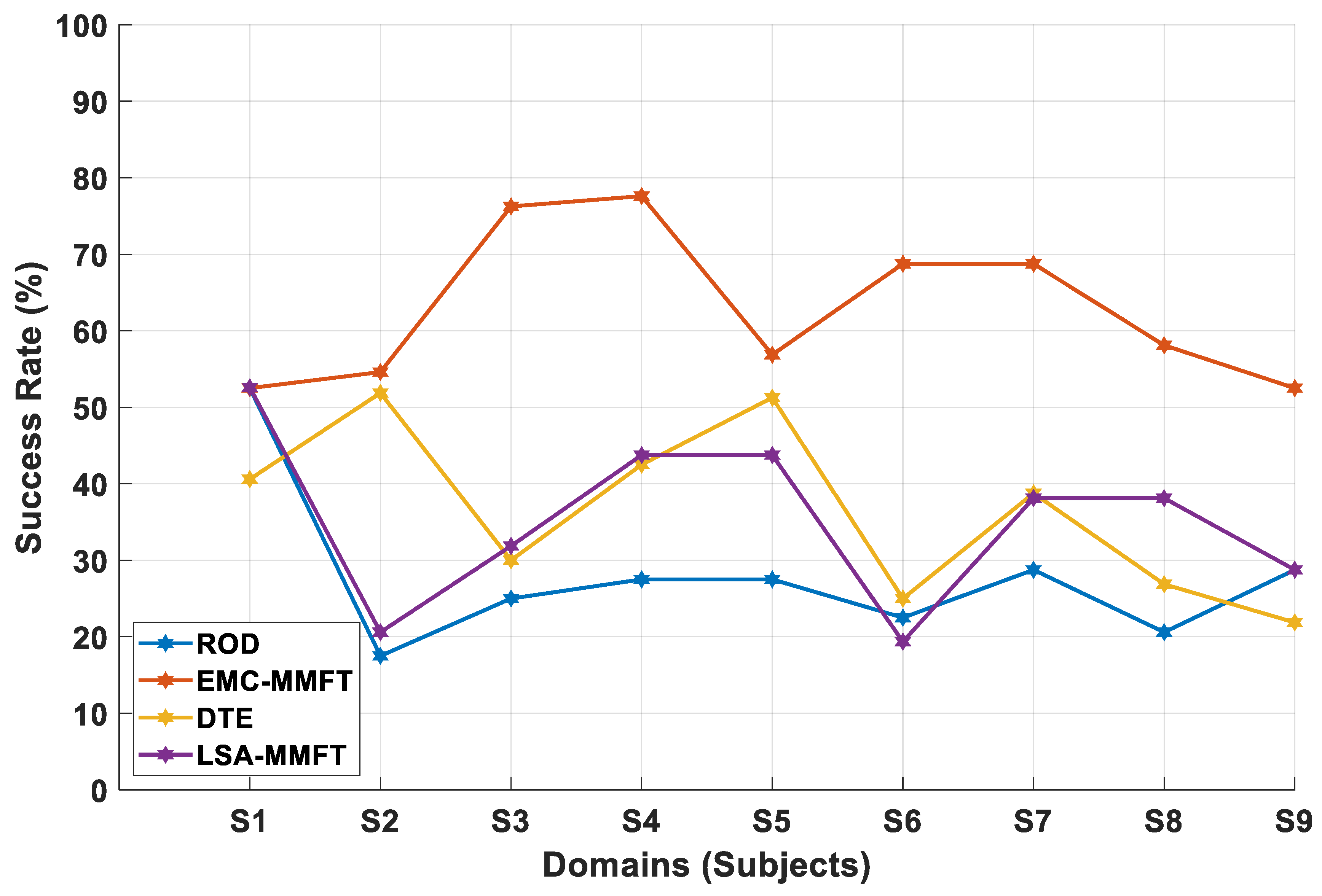
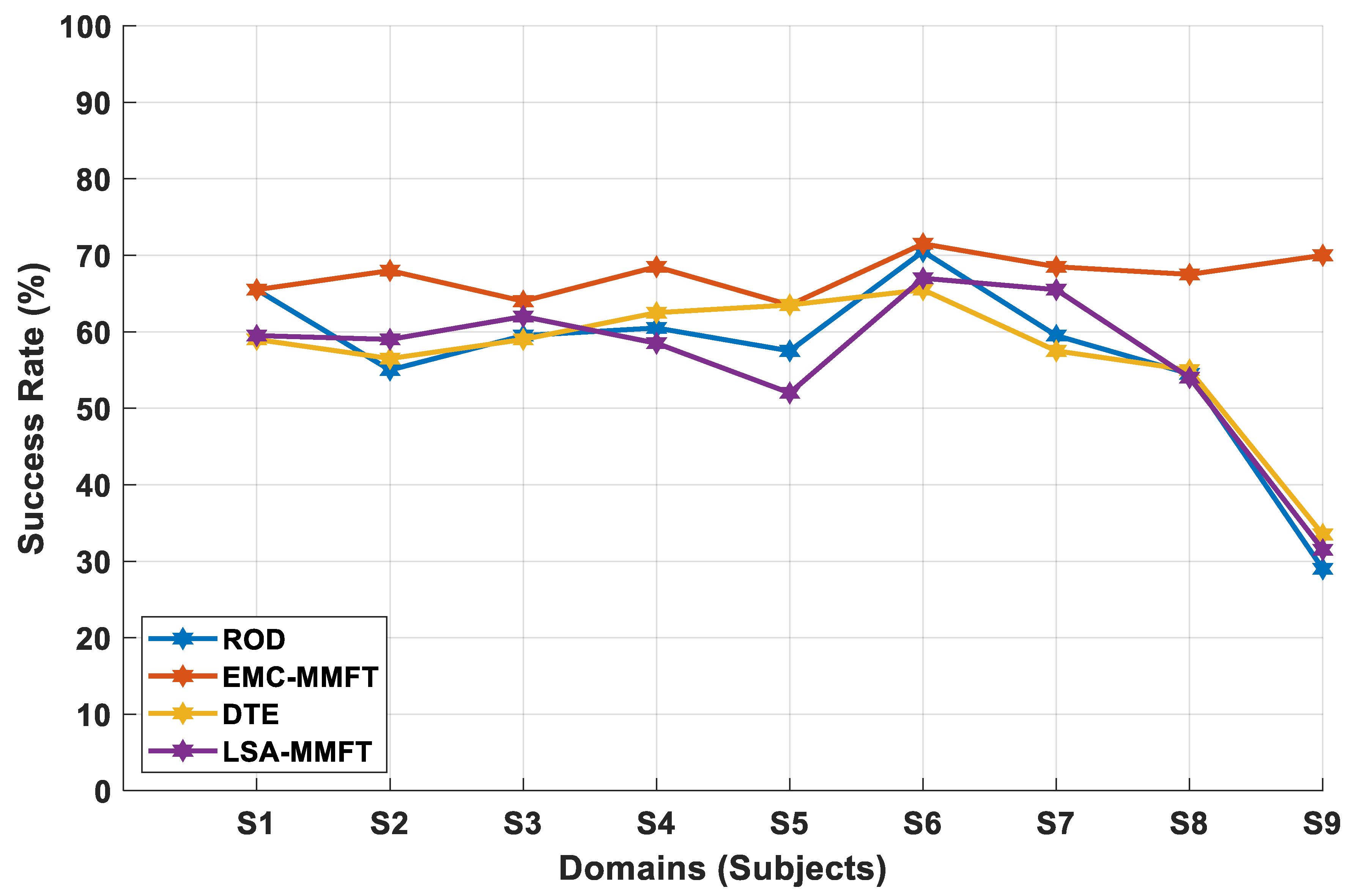
4.2. Experimental Results
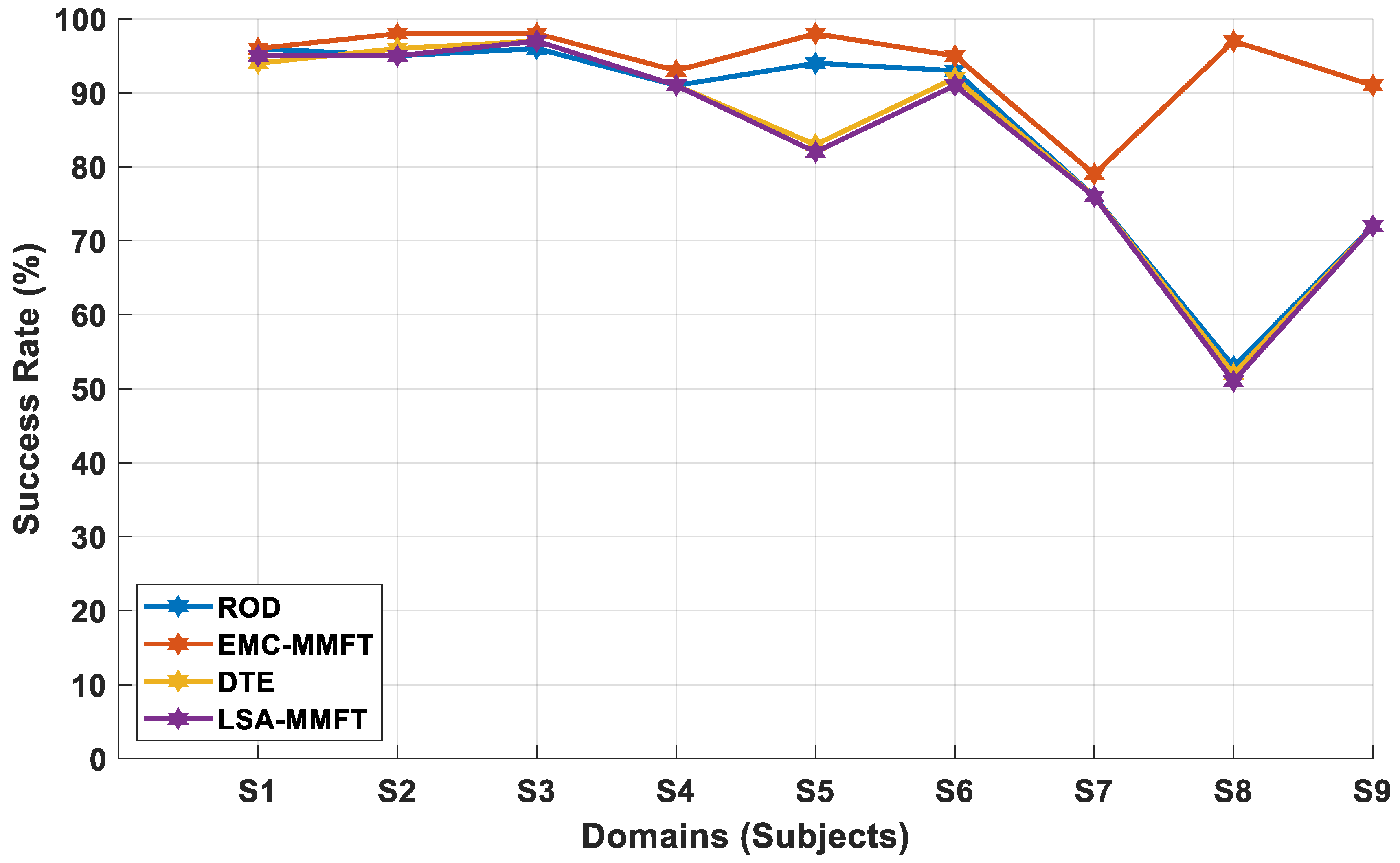
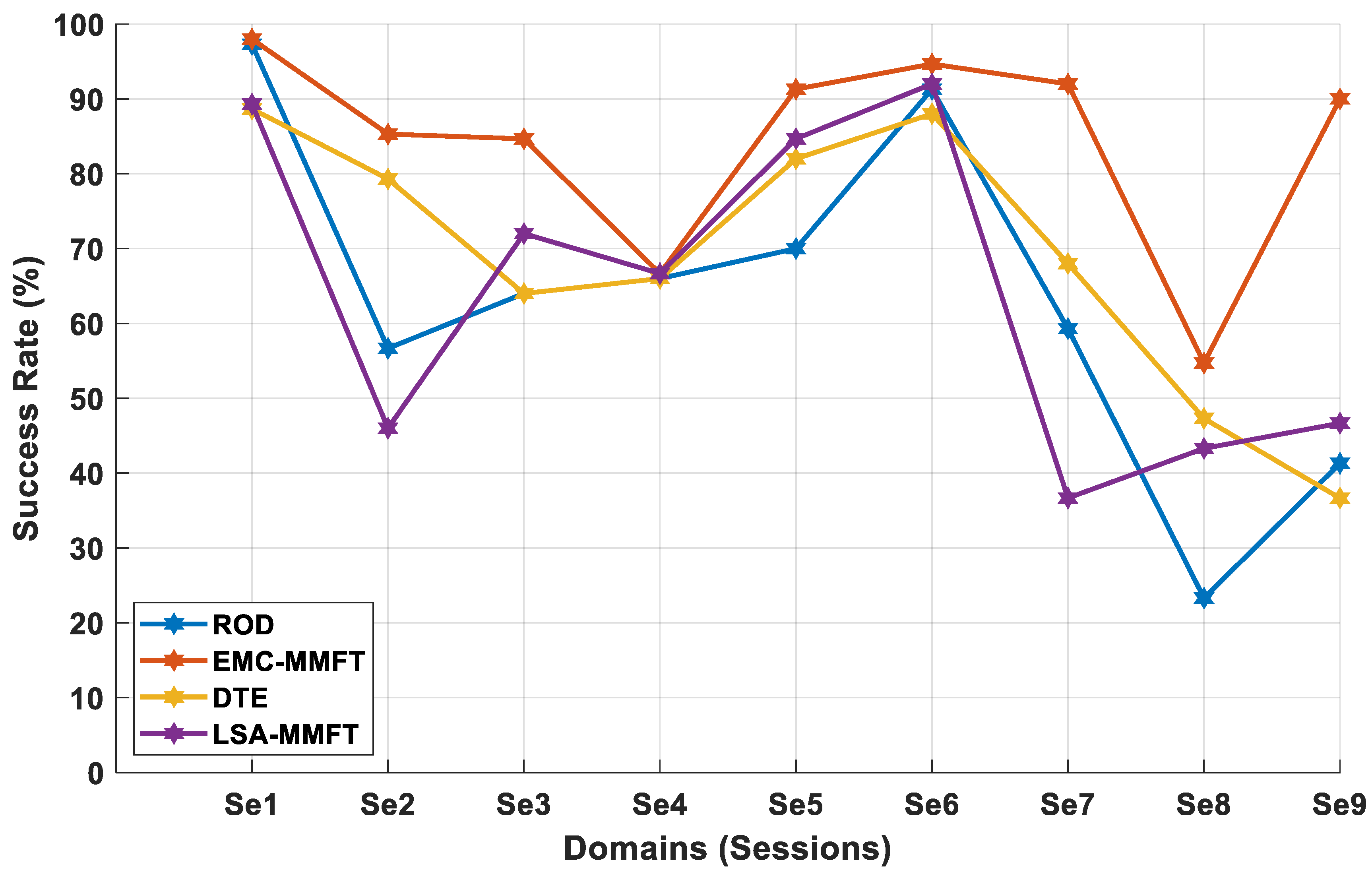
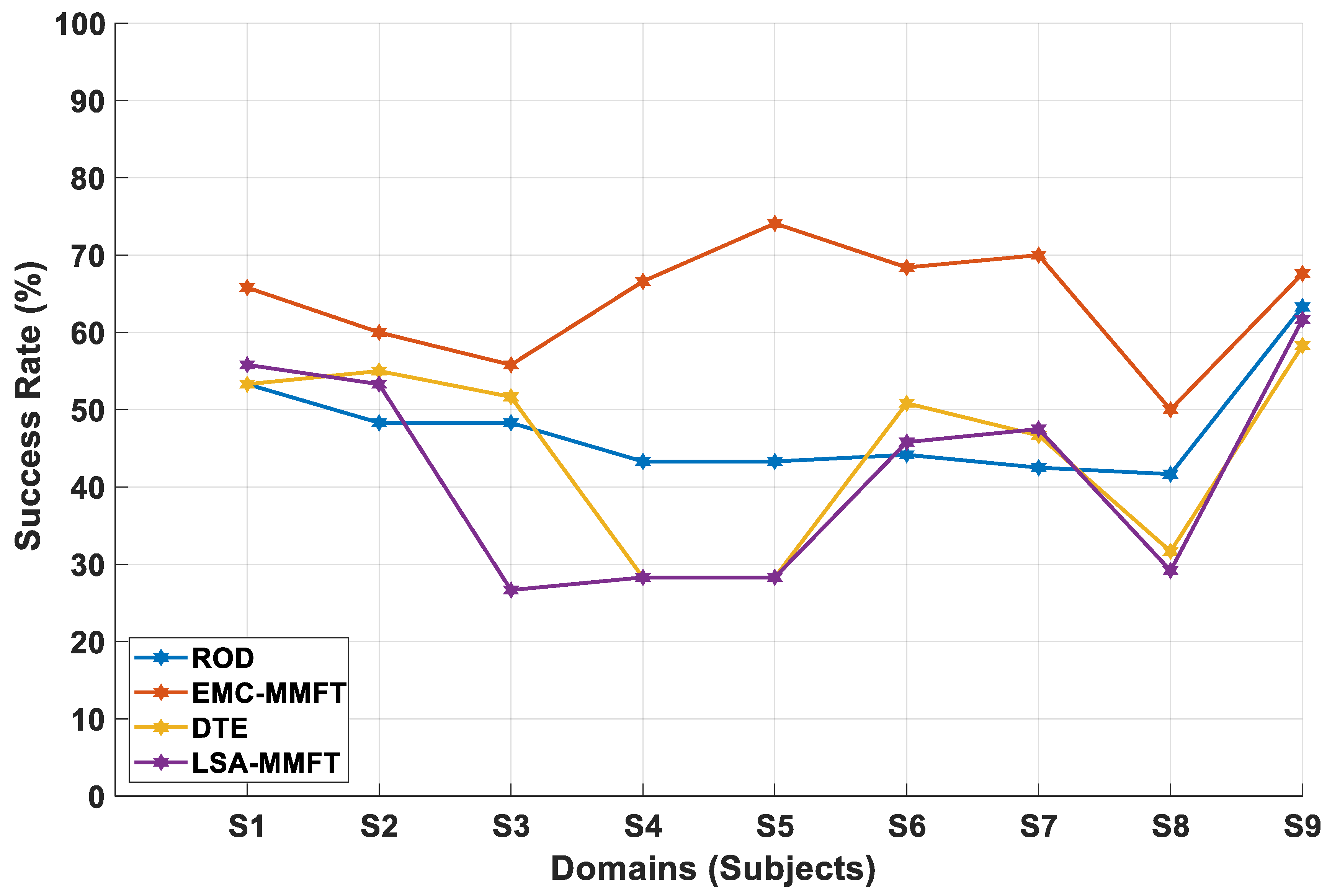
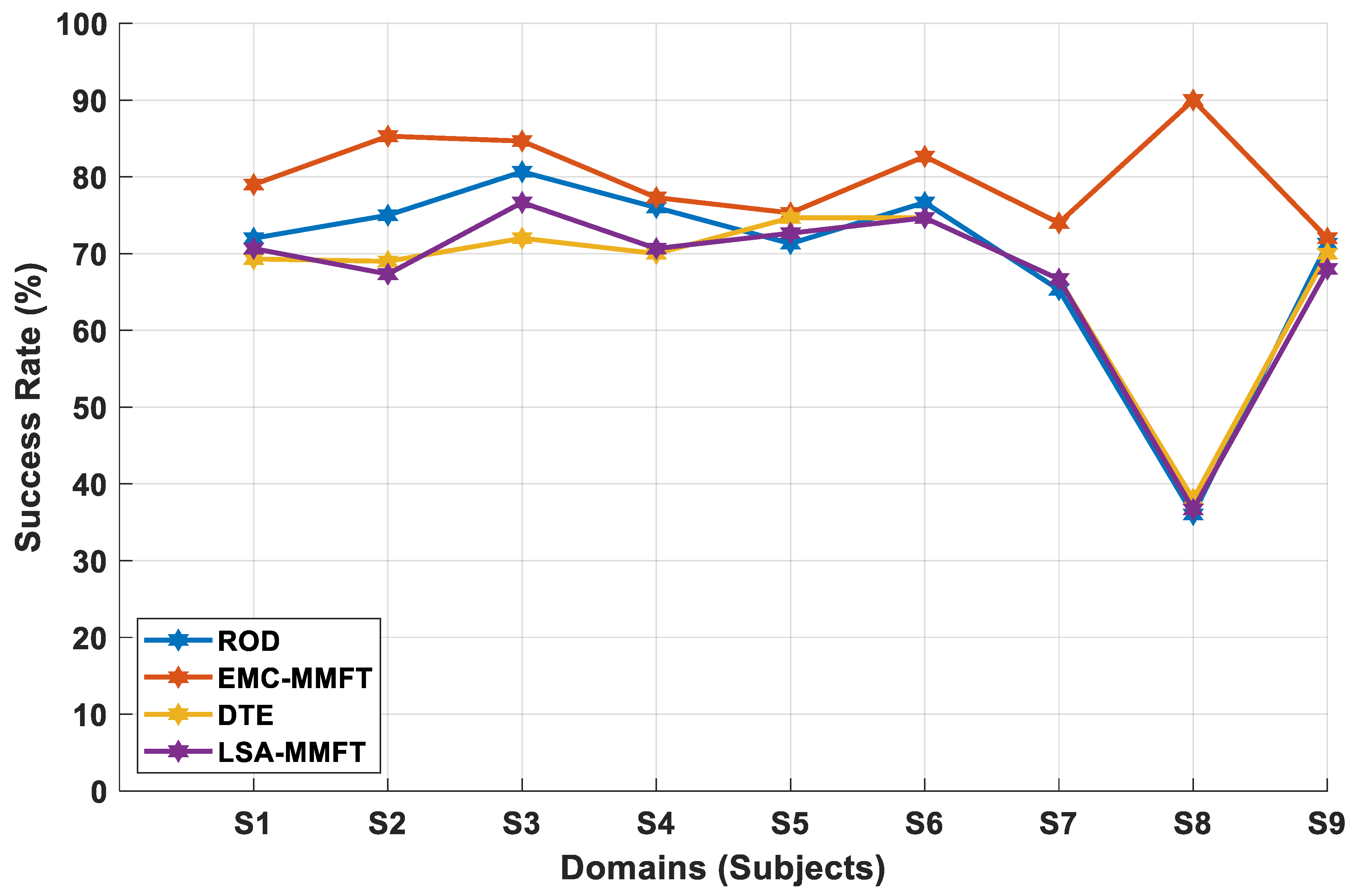
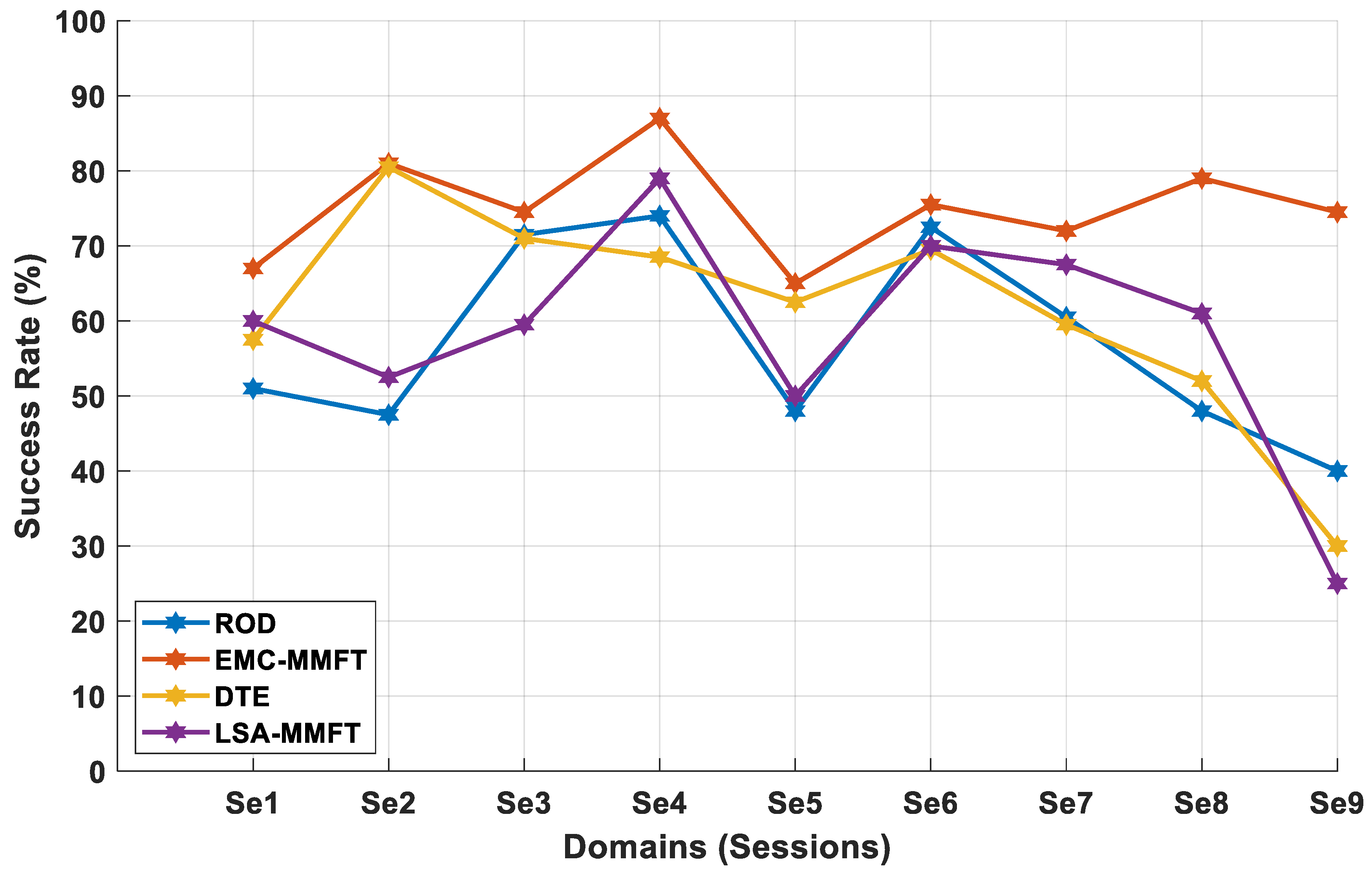
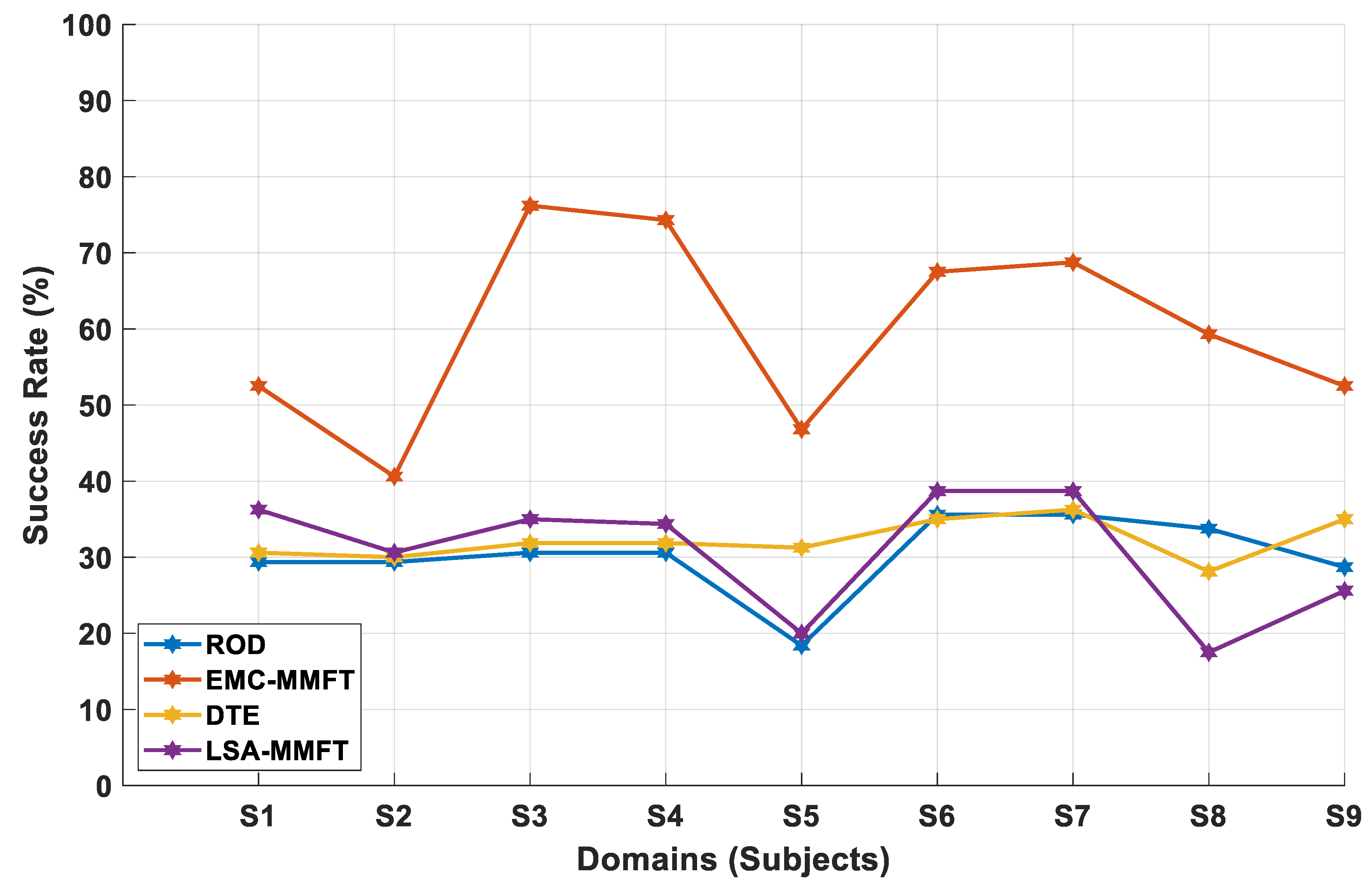
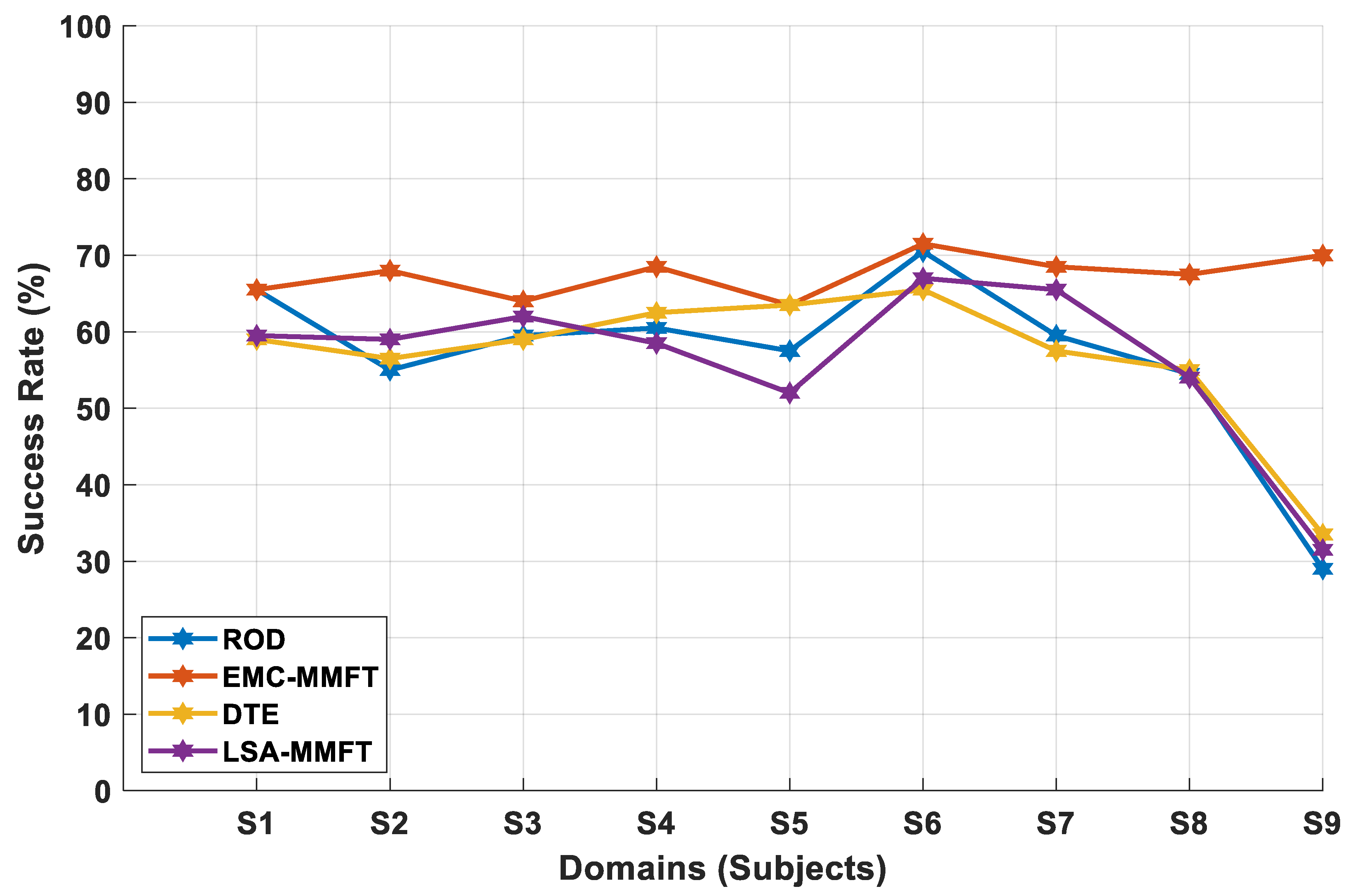
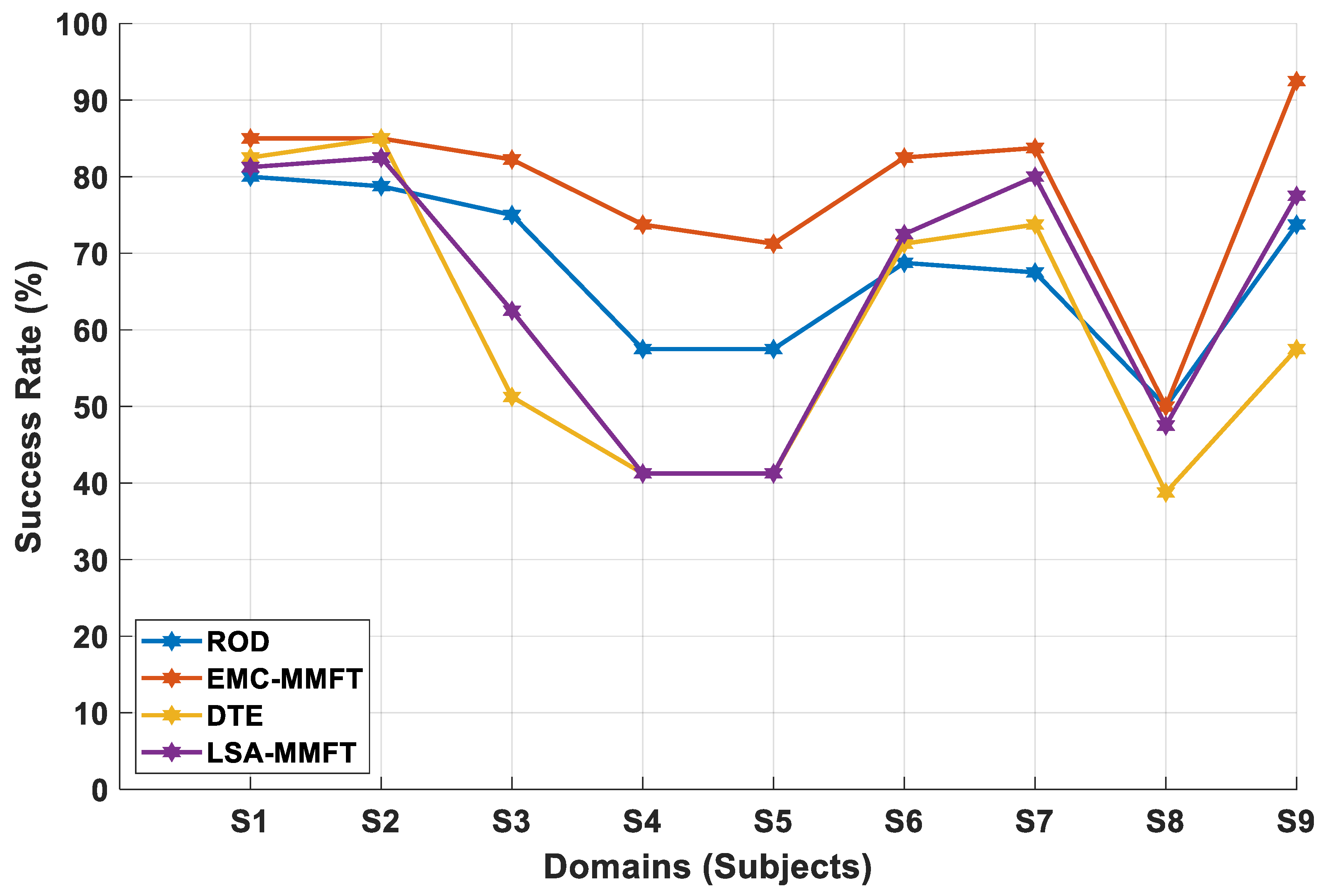
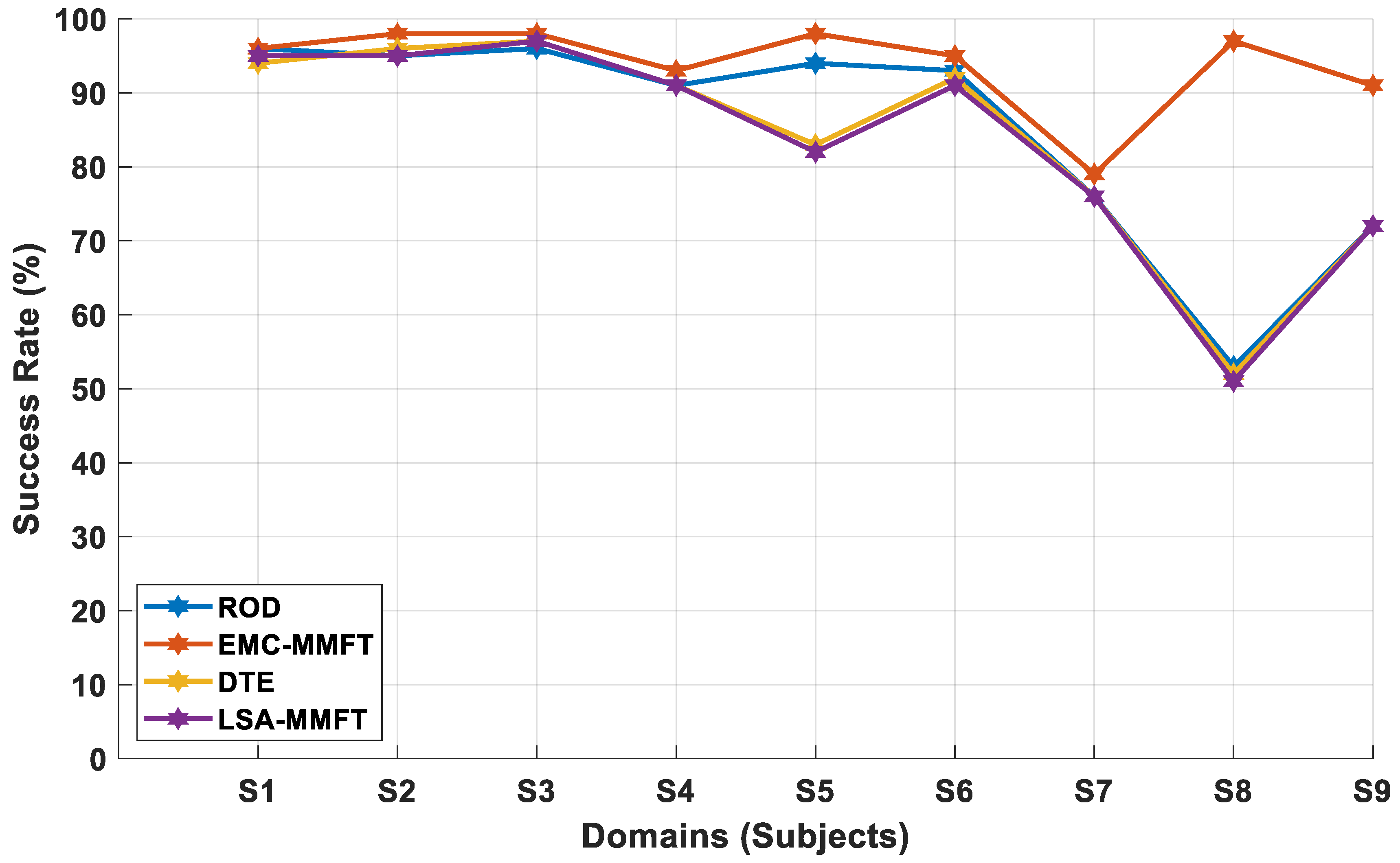
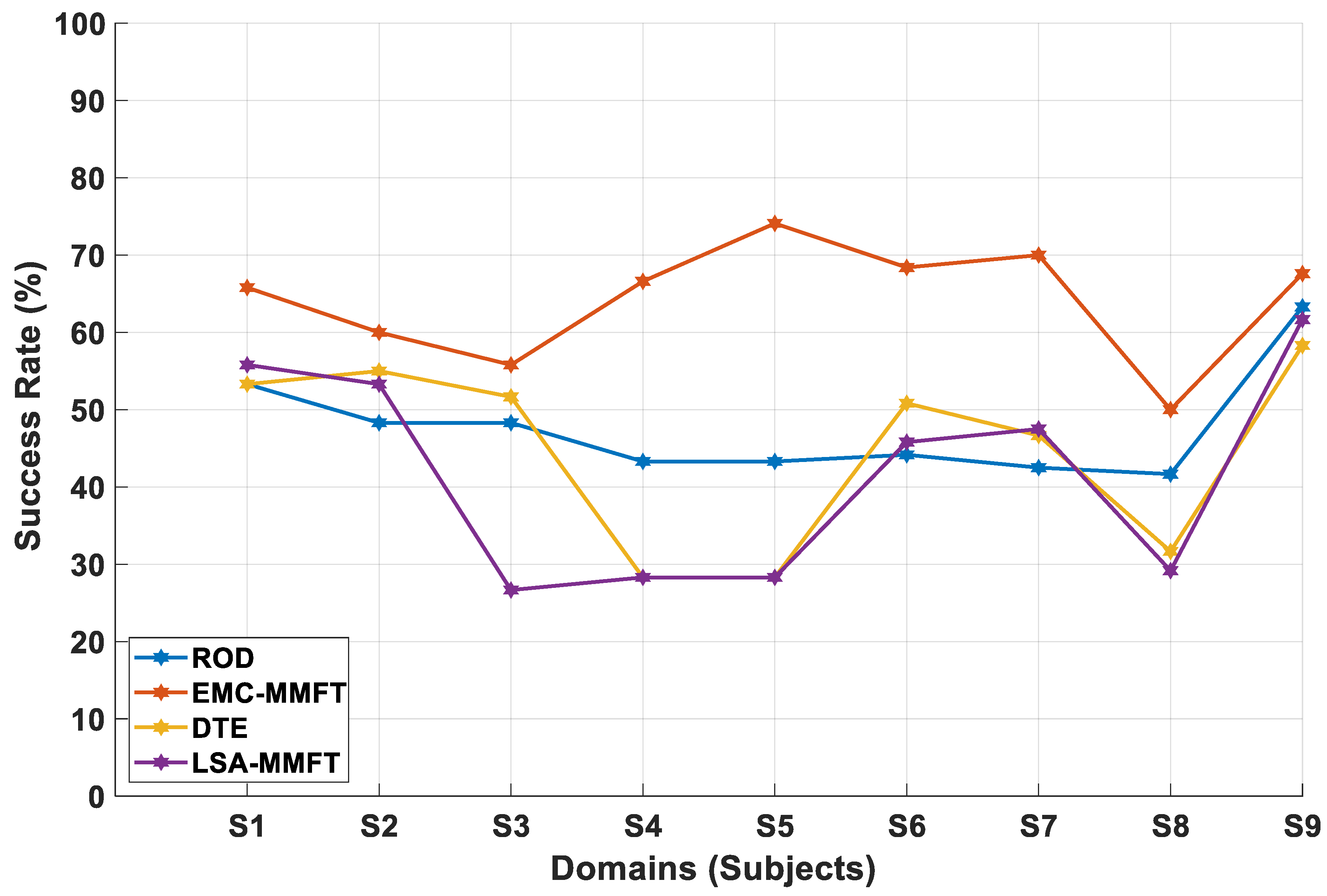
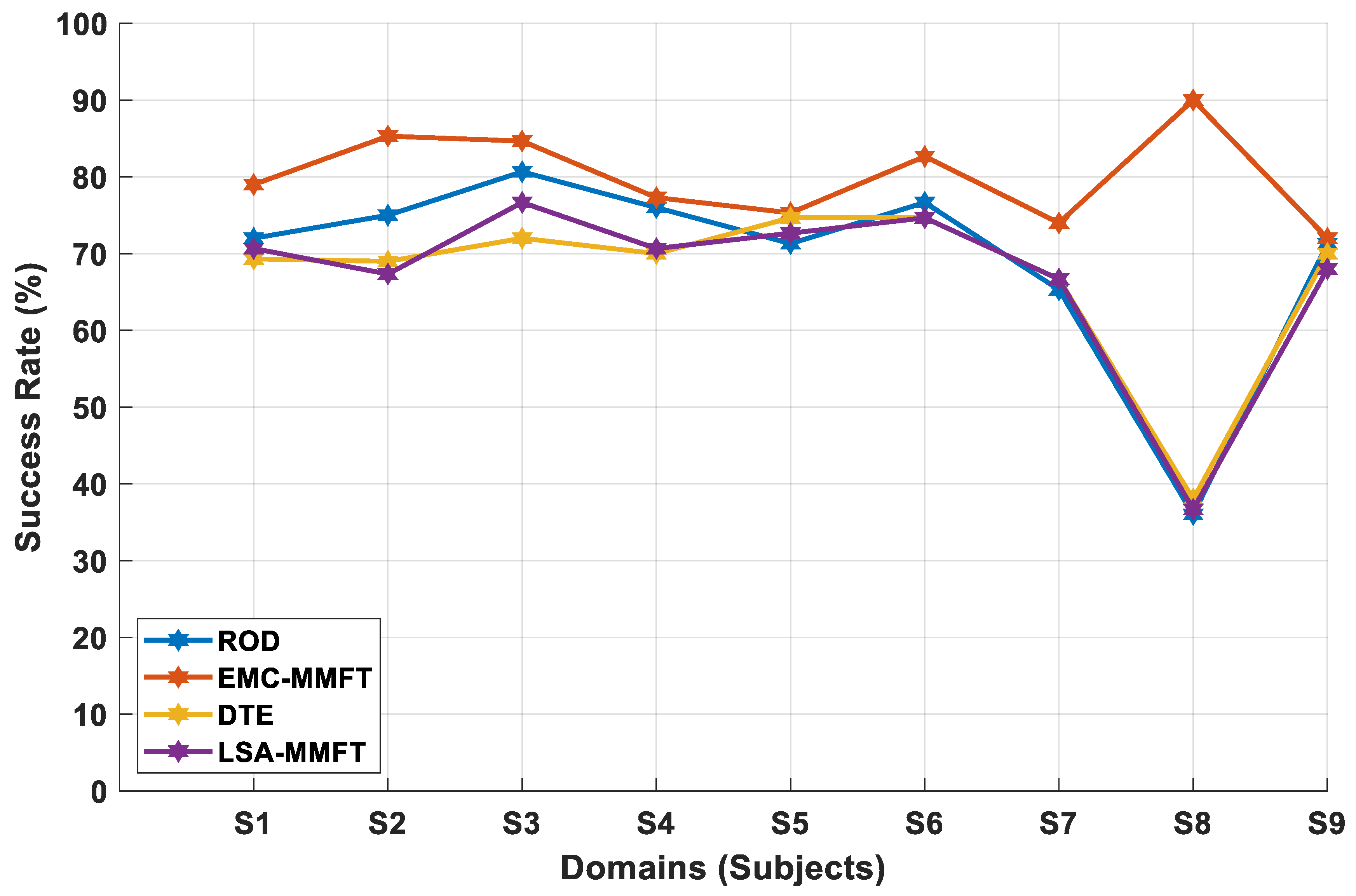
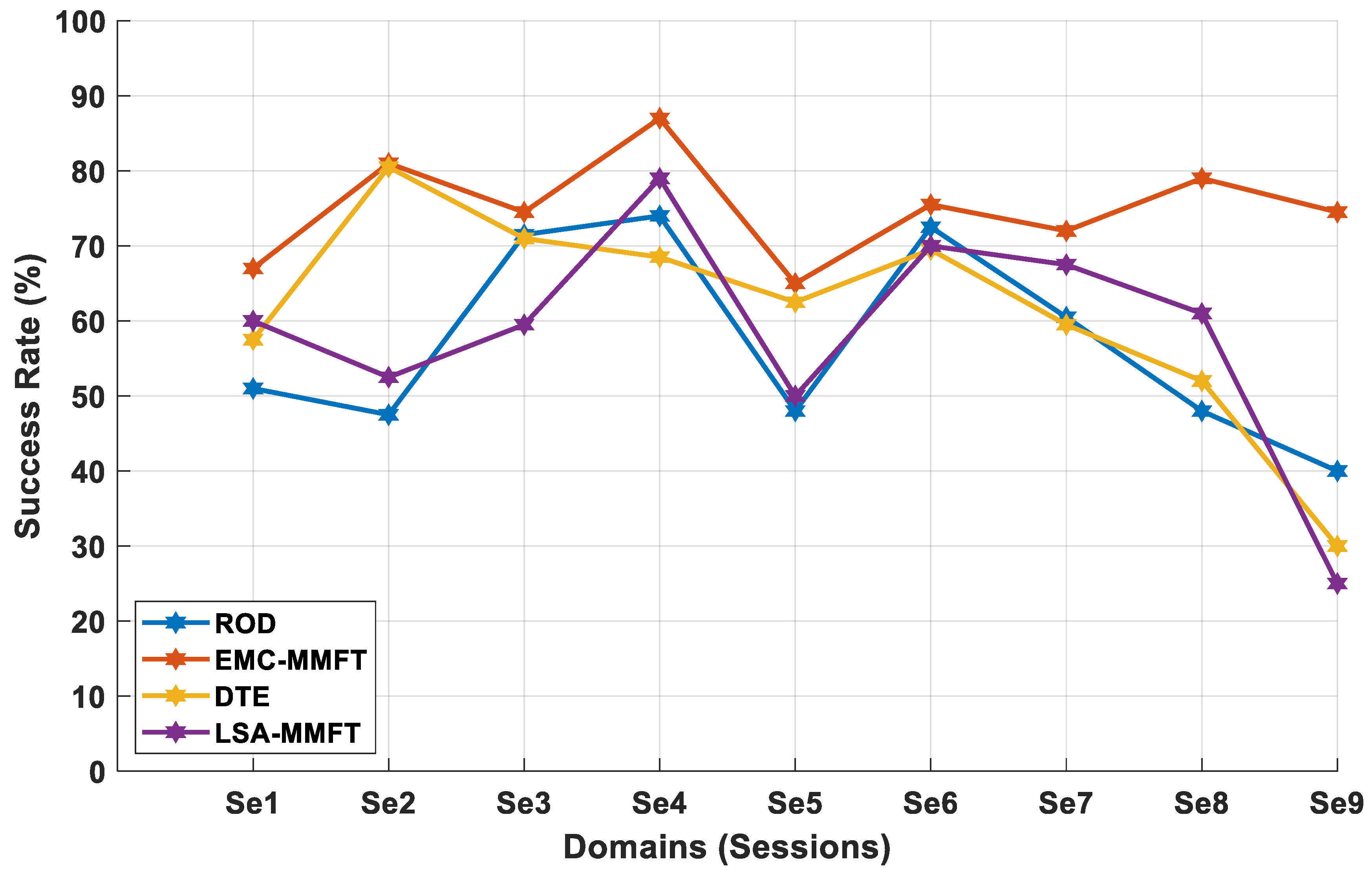
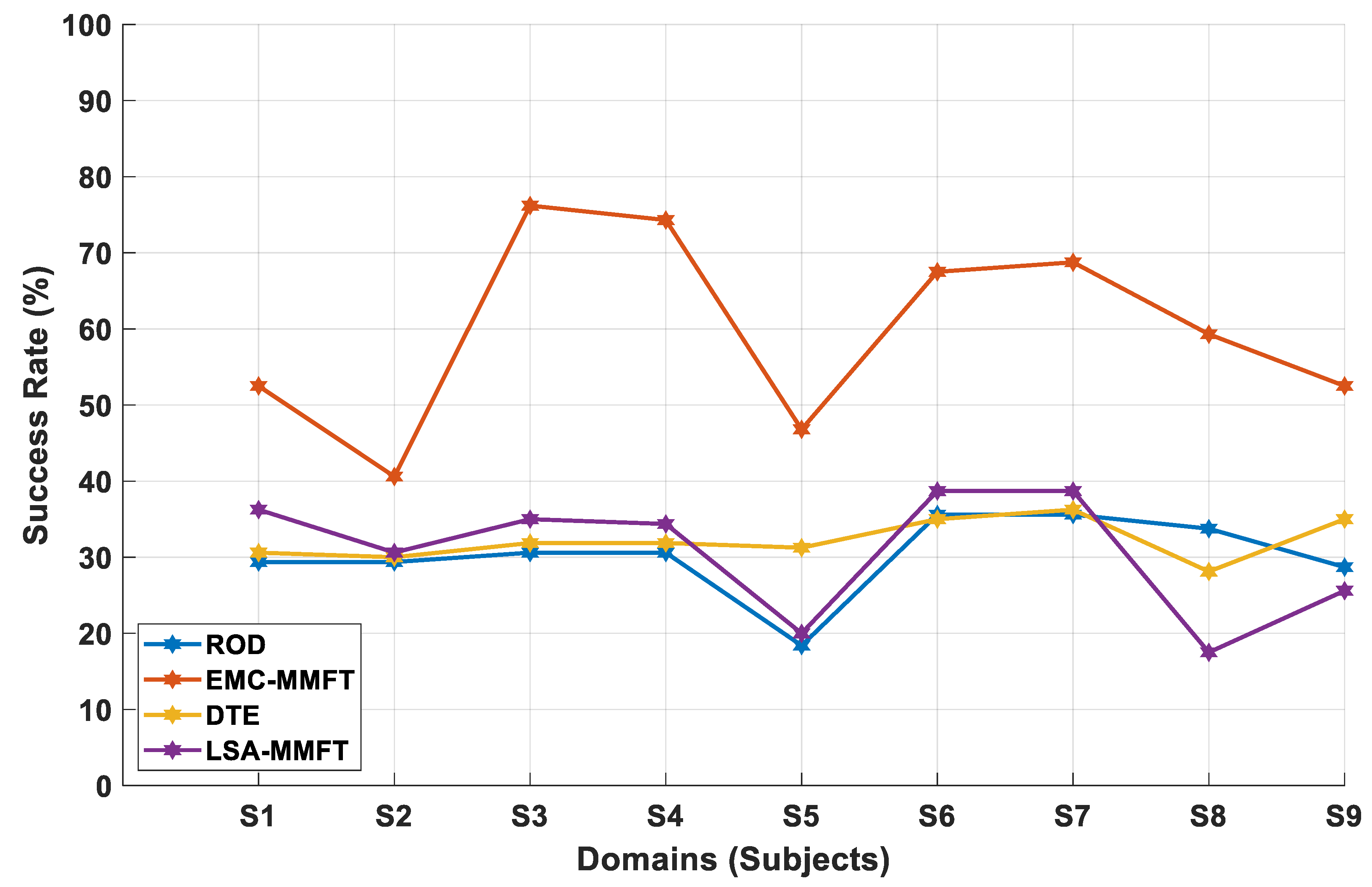
4.2.1. Domain Selection Based on a Two-Class Problem
4.2.2. Domain Selection Based on a Three-Class Problem
4.2.3. Domain Selection Based on a Four-Class Problem
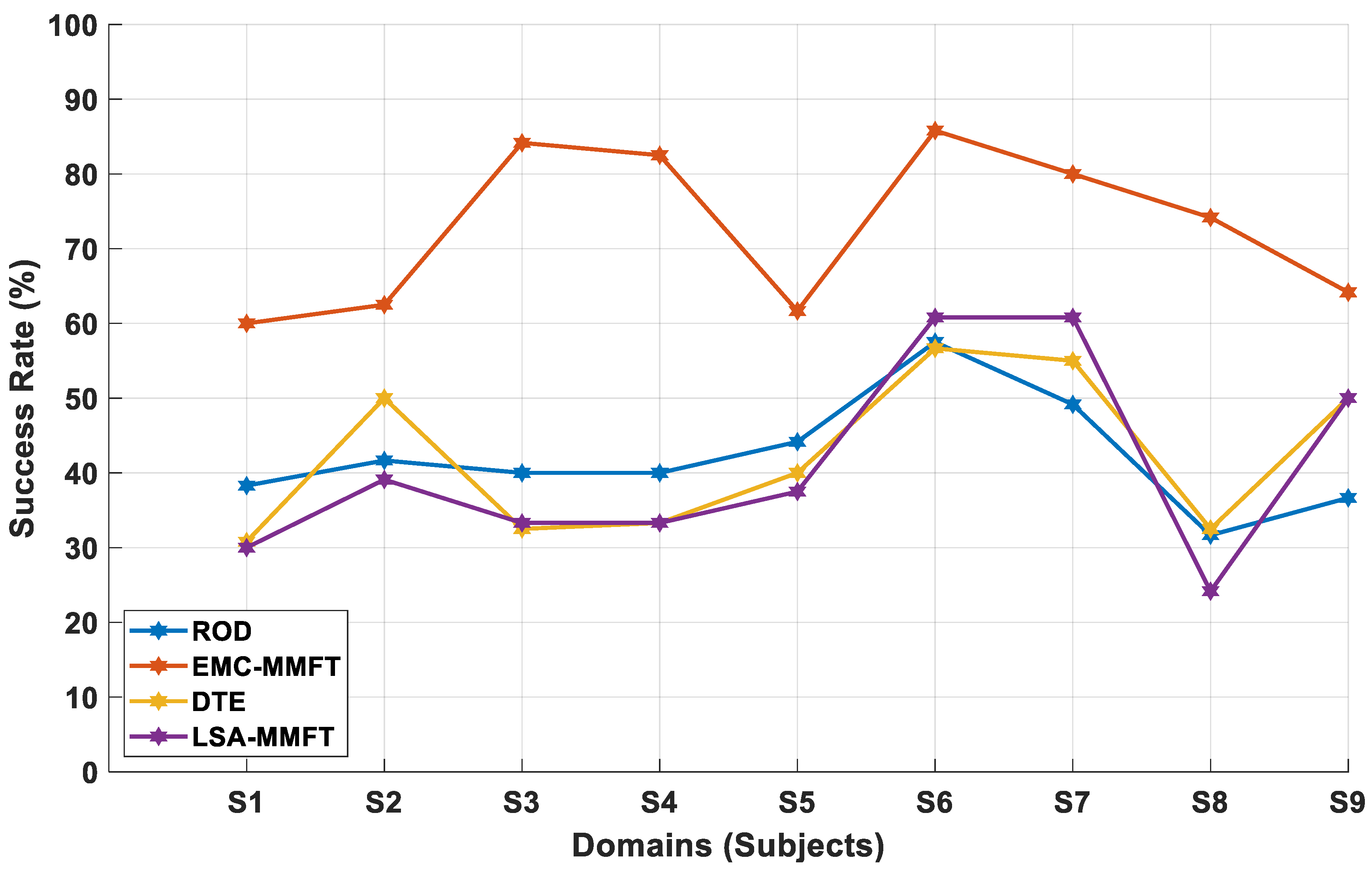
4.2.4. Optimal Combination of Selected Beneficial Sources
Selected Combination of High Beneficial Source Domains Using EMC-MMFT
Number of Removed Low-Beneficial Source Domains Using ROD
Number of Removed Low-Beneficial Source Domains Using DTE
Number of Removed Low-Beneficial Source Domains Using LSA-MMFT
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dai, M.; Wang, S.; Zheng, D.; Na, R.; Zhang, S. Domain Transfer Multiple Kernel Boosting for Classification of EEG Motor Imagery Signals. IEEE Access 2019, 7, 49951–49960. [Google Scholar] [CrossRef]
- Lee, D.-Y.; Jeong, J.-H.; Lee, B.-H.; Lee, S.-W. Motor Imagery Classification Using Inter-Task Transfer Learning via a Channel-Wise Variational Autoencoder-Based Convolutional Neural Network. IEEE Trans. Neural Syst. Rehabil. Eng. 2022, 30, 226–237. [Google Scholar] [CrossRef] [PubMed]
- Saha, S.; Ahmed, K.I.U.; Mostafa, R.; Hadjileontiadis, L.; Khandoker, A. Evidence of Variabilities in EEG Dynamics During Motor Imagery-Based Multiclass Brain–Computer Interface. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 26, 371–382. [Google Scholar] [CrossRef]
- Maswanganyi, R.C.; Tu, C.; Owolawi, P.A.; Du, S. Statistical Evaluation of Factors Influencing Inter-Session and Inter-Subject Variability in EEG-Based Brain Computer Interface. IEEE Access 2022, 10, 96821–96839. [Google Scholar] [CrossRef]
- Zhu, L.; Yang, J.; Ding, W.; Zhu, J.; Xu, P.; Ying, N.; Zhang, J. Multi-Source Fusion Domain Adaptation Using Resting-State Knowledge for Motor Imagery Classification Tasks. IEEE Sens. J. 2021, 21, 21772–21781. [Google Scholar] [CrossRef]
- Cui, J.; Jin, X.; Hu, H.; Zhu, L.; Ozawa, K.; Pan, G.; Kong, W. Dynamic Distribution Alignment with Dual-Subspace Mapping for Cross-Subject Driver Mental State Detection. IEEE Trans. Cogn. Dev. Syst. 2021, 14, 1705–1716. [Google Scholar] [CrossRef]
- Wu, D.; Xu, Y.; Lu, B.-L. Transfer Learning for EEG-Based Brain–Computer Interfaces: A Review of Progress Made Since 2016. IEEE Trans. Cogn. Dev. Syst. 2020, 14, 4–19. [Google Scholar] [CrossRef]
- Zhang, W.; Deng, L.; Zhang, L.; Wu, D. A survey on negative transfer. IEEE CAA J. Autom. Sin. 2022, 10, 305–329. [Google Scholar] [CrossRef]
- Li, J.; Qiu, S.; Shen, Y.-Y.; Liu, C.-L.; He, H. Multisource Transfer Learning for Cross-Subject EEG Emotion Recognition. IEEE Trans. Cybern. 2019, 50, 3281–3293. [Google Scholar] [CrossRef]
- Zhang, W.; Wu, D. Manifold Embedded Knowledge Transfer for Brain-Computer Interfaces. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 1117–1127. [Google Scholar] [CrossRef]
- She, Q.; Cai, Y.; Du, S.; Chen, Y. Multi-source manifold feature transfer learning with domain selection for brain-computer interfaces. Neurocomputing 2022, 514, 313–327. [Google Scholar] [CrossRef]
- Maswanganyi, R.C.; Tu, C.; Owolawi, P.A.; Du, S. Multi-Class Transfer Learning and Domain Selection for Cross-Subject EEG Classification. Appl. Sci. 2023, 13, 5205. [Google Scholar] [CrossRef]
- Gong, B.; Shi, Y.; Sha, F.; Grauman, K. Geodesic flow kernel for unsupervised domain adaptation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, Providence, RI, USA, 16–21 June 2012; pp. 2066–2073. [Google Scholar]
- Jeng, P.-Y.; Wei, C.-S.; Jung, T.-P.; Wang, L.-C. Low-Dimensional Subject Representation-Based Transfer Learning in EEG Decoding. IEEE J. Biomed. Health Inform. 2020, 25, 1915–1925. [Google Scholar] [CrossRef]
- Liang, Z.; Zheng, Z.; Chen, W.; Wang, J.; Zhang, J.; Chen, J.; Chen, Z. Manifold Trial Selection to Reduce Negative Transfer in Motor Imagery-based Brain–Computer Interface. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 4144–4149. [Google Scholar]
- Kuang, J.; Xu, G.; Tao, T.; Wu, Q. Class-Imbalance Adversarial Transfer Learning Network for Cross-Domain Fault Diagnosis with Imbalanced Data. IEEE Trans. Instrum. Meas. 2021, 71, 3501111. [Google Scholar] [CrossRef]
- Gu, X.; Cai, W.; Gao, M.; Jiang, Y.; Ning, X.; Qian, P. Multi-Source Domain Transfer Discriminative Dictionary Learning Modeling for Electroencephalogram-Based Emotion Recognition. IEEE Trans. Comput. Soc. Syst. 2022, 9, 1604–1612. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, H.; Dong, H.; Dai, Z.; Chen, X.; Li, Z. Transfer learning algorithm design for feature transfer problem in motor imagery brain-computer interface. China Commun. 2022, 19, 39–46. [Google Scholar] [CrossRef]
- Rodrigues, P.L.C.; Jutten, C.; Congedo, M. Riemannian Procrustes Analysis: Transfer Learning for Brain–Computer Interfaces. IEEE Trans. Biomed. Eng. 2018, 66, 2390–2401. [Google Scholar] [CrossRef] [PubMed]
- Cao, J.; Hu, D.; Wang, Y.; Wang, J.; Lei, B. Epileptic Classification with Deep-Transfer-Learning-Based Feature Fusion Algorithm. IEEE Trans. Cogn. Dev. Syst. 2021, 14, 684–695. [Google Scholar] [CrossRef]
- Li, Y.; Wei, Q.; Chen, Y.; Zhou, X. Transfer Learning Based on Hybrid Riemannian and Euclidean Space Data Alignment and Subject Selection in Brain-Computer Interfaces. IEEE Access 2021, 9, 6201–6212. [Google Scholar] [CrossRef]
- Maswanganyi, C.; Tu, C.; Owolawi, P.; Du, S. Factors influencing low intension detection rate in a non-invasive EEG-based brain computer interface system. Indones. J. Electr. Eng. Comput. Sci. 2020, 20, 167–175. [Google Scholar] [CrossRef]
- Duan, T.; Chauhan, M.; Shaikh, M.A.; Chu, J.; Srihari, S. Ultra efficient transfer learning with meta update for cross subject EEG classification. arXiv 2020, arXiv:2003.06113. [Google Scholar]
- Gao, Y.; Liu, Y.; She, Q.; Zhang, J. Domain Adaptive Algorithm Based on Multi-Manifold Embedded Distributed Alignment for Brain-Computer Interfaces. IEEE J. Biomed. Health Inform. 2022, 27, 296–307. [Google Scholar] [CrossRef]
- Samanta, K.; Chatterjee, S.; Bose, R. Cross-Subject Motor Imagery Tasks EEG Signal Classification Employing Multiplex Weighted Visibility Graph and Deep Feature Extraction. IEEE Sens. Lett. 2019, 4, 7000104. [Google Scholar] [CrossRef]
- Demsy, O.; Achanccaray, D.; Hayashibe, M. Inter-Subject Transfer Learning Using Euclidean Alignment and Transfer Component Analysis for Motor Imagery-Based BCI. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, 17–20 October 2021; p. 3176. [Google Scholar]
- Lin, J.; Liang, L.; Han, X.; Yang, C.; Chen, X.; Gao, X. Cross-target transfer algorithm based on the volterra model of SSVEP-BCI. Tsinghua Sci. Technol. 2021, 26, 505–522. [Google Scholar] [CrossRef]
- Chen, C.; Li, Z.; Wan, F.; Xu, L.; Bezerianos, A.; Wang, H. Fusing Frequency-Domain Features and Brain Connectivity Features for Cross-Subject Emotion Recognition. IEEE Trans. Instrum. Meas. 2022, 71, 2508215. [Google Scholar] [CrossRef]
- Chen, Y.; Yang, R.; Huang, M.; Wang, Z.; Liu, X. Single-Source to Single-Target Cross-Subject Motor Imagery Classification Based on Multisubdomain Adaptation Network. IEEE Trans. Neural Syst. Rehabil. Eng. 2022, 30, 1992–2002. [Google Scholar] [CrossRef]
- Gaur, P.; Chowdhury, A.; McCreadie, K.; Pachori, R.B.; Wang, H. Logistic Regression with Tangent Space-Based Cross-Subject Learning for Enhancing Motor Imagery Classification. IEEE Trans. Cogn. Dev. Syst. 2021, 14, 1188–1197. [Google Scholar] [CrossRef]
- Kim, D.-K.; Kim, Y.-T.; Jung, H.-R.; Kim, H. Sequential Transfer Learning via Segment After Cue Enhances the Motor Imagery-based Brain-Computer Interface. In Proceedings of the 2021 9th International Winter Conference on Brain-Computer Interface (BCI), Gangwon, Republic of Korea, 22–24 February 2021; pp. 1–5. [Google Scholar]
- Samek, W.; Kawanabe, M.; Muller, K.-R. Divergence-Based Framework for Common Spatial Patterns Algorithms. IEEE Rev. Biomed. Eng. 2013, 7, 50–72. [Google Scholar] [CrossRef] [PubMed]
- Wei, M.; Yang, R.; Huang, M. Motor imagery EEG signal classification based on deep transfer learning. In Proceedings of the 2021 IEEE 34th International Symposium on Computer-Based Medical Systems (CBMS), IEEE, Aveiro, Portugal, 7–9 June 2021; pp. 85–90. [Google Scholar]
- Shajil, N.; Sasikala, M.; Arunnagiri, A. Faisal, Inter-Subject Deep Transfer Learning for Motor Imagery EEG Decoding. In Proceedings of the 2021 10th International IEEE/EMBS Conference on Neural Engineering (NER), IEEE, Virtual, Italy, 4–6 May 2021; pp. 21–24. [Google Scholar]
- Shajil, N.; Sasikala, M.; Arunnagiri, A.M. Deep Learning Classification of two-class Motor Imagery EEG signals using Transfer Learning. In Proceedings of the 2020 International Conference on e-Health and Bioengineering (EHB), Iasi, Romania, 29–30 October 2020; pp. 1–4. [Google Scholar]
- Jiang, Z.; Chung, F.-L.; Wang, S. Recognition of Multiclass Epileptic EEG Signals Based on Knowledge and Label Space Inductive Transfer. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 630–642. [Google Scholar] [CrossRef] [PubMed]
- Azab, A.M.; Mihaylova, L.; Ang, K.K.; Arvaneh, M. Weighted Transfer Learning for Improving Motor Imagery-Based Brain–Computer Interface. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 1352–1359. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.; Zhao, W.; Meng, M.; Zhang, Q.; She, Q.; Zhang, J. Cross-Subject Emotion Recognition Based on Domain Similarity of EEG Signal Transfer Learning. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 31, 936–943. [Google Scholar] [CrossRef] [PubMed]
- Jeon, E.; Ko, W.; Suk, H.-I. Domain Adaptation with Source Selection for Motor-Imagery based BCI. In Proceedings of the 2019 7th International Winter Conference on Brain-Computer Interface (BCI), IEEE, Gangwon, Republic of Korea, 18–20 February 2019; pp. 1–4. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TD | Two-Class (SDs) | Three-Class (SDs) | Four-Class (SDs) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| X-Se | X-S1 | X-S2 | X-S3 | X-Se | X-S1 | X-S2 | X-S3 | X-Se | X-S1 | X-S2 | X-S3 | |
| 1 | 2, 3, 4, 5, 8 | 2, 3, 5, 7, 8 | 2, 4 | 2, 3, 7 | 4, 5, 6, 7, 8 | 3, 8, 9 | 2, 3, 4, 7 | 5, 7, 8, 9 | 2, 3, 5, 6 | 2, 7, 9 | 2, 3, 4, 5 | 2, 3, 4, 5 |
| 2 | 1, 4, 6, 8, 9 | 3, 8 | 3, 5, 6, 7 | 1, 5, 6, 7 | 3, 4, 6, 7, 8 | 3, 7, 8 | 3, 7 | 1, 9 | 1, 3, 5, 7 | 5, 8 | 1, 3, 4, 5, 6 | 3, 5, 7 |
| 3 | 1, 5, 8 | 4, 5, 8, 9 | 2, 4, 7 | 2, 4, 5, 6, 8 | 5 | 2, 7, 8 | 4 | 1, 4, 8, 9 | 1, 2, 5, 9 | 6, 7, 8 | 2, 4 | 2, 4 |
| 4 | 2, 3, 5, 7, 8 | 7, 8 | 1, 3, 6, 9 | 5 | 5, 7, 8, 9 | 5, 8 | 2, 3 | 5, 9 | 7, 8 | 1, 2 | 3, 6 | 3 |
| 5 | 1, 4, 6, 7, 8 | 9 | 2, 9 | 3, 4, 9 | 3, 6 | 1, 7, 8 | 2, 8 | 4 | 2, 3 | 4 | 1, 6, 7, 8, 9 | 1, 6, 7, 8, 9 |
| 6 | 1, 2, 7, 8 | 2, 7, 8, 9 | 2, 4, 7, 9 | 1, 2, 4, 9 | 1, 2, 5, 7, 9 | 8, 9 | 7 | 1, 2, 3, 7 | 3, 4, 8 | 3, 7 | 2, 4, 7, 8 | 4, 5, 7 |
| 7 | 1, 3, 9 | 2, 3, 4, 5 | 2, 4, 6, 9 | 1, 4, 6 | 2, 4, 6, 8 | 2, 5, 9 | 1, 6 | 1, 2, 5 | 3, 4, 6, 9 | 3, 8 | 4, 5, 6 | 3, 5, 6 |
| 8 | 1, 2, 3, 5, 6 | 3, 5, 6 | 1, 3, 9 | 3, 5 | 1, 2, 5 | 2, 7 | 5, 9 | 1, 4, 5 | 4, 6 | 6, 7, 5 | 5, 9 | 1, 4, 5, 9 |
| 9 | 1 | 6, 7, 8 | 5, 7 | 3, 4, 5, 6, 8 | 5, 6 | 4, 8 | 4, 6, 7 | 2, 3, 4, 5, 6 | 1, 6, 7 | 3, 7, 8 | 1, 2, 3, 4, 6, 7 | 1, 2, 3, 4, 6, 7 |
| TD | Two-Class (SDs) | Three-Class (SDs) | Four-Class (SDs) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| X-Se | X-S1 | X-S2 | X-S3 | X-Se | X-S1 | X-S2 | X-S3 | X-Se | X-S1 | X-S2 | X-S3 | |
| 1 | 33 | 3 | 3 | 4 | 5 | 4 | 7 | 5 | 2 | 5 | 7 | 3 |
| 2 | 6 | 6 | 3 | 2 | 1 | 3 | 3 | 2 | 1 | 5 | 3 | 6 |
| 3 | 3 | 2 | 6 | 6 | 1 | 5 | 5 | 5 | 3 | 6 | 1 | 5 |
| 4 | 2 | 6 | 6 | 3 | 3 | 5 | 5 | 6 | 2 | 6 | 1 | 2 |
| 5 | 1 | 6 | 5 | 3 | 1 | 2 | 7 | 6 | 1 | 6 | 4 | 2 |
| 6 | 4 | 5 | 1 | 3 | 2 | 5 | 6 | 5 | 3 | 6 | 2 | 7 |
| 7 | 1 | 2 | 1 | 3 | 6 | 2 | 1 | 7 | 3 | 2 | 1 | 2 |
| 8 | 1 | 4 | 3 | 3 | 1 | 1 | 7 | 7 | 4 | 4 | 7 | 1 |
| 9 | 6 | 2 | 4 | 1 | 6 | 6 | 1 | 6 | 7 | 2 | 4 | 7 |
| TD | Two-Class (SDs) | Three-Class (SDs) | Four-Class (SDs) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| X-Se | X-S2 | X-S3 | X-S3 | X-Se | X-S1 | X-S2 | X-S3 | X-Se | X-S1 | X-S2 | X-S3 | |
| 1 | 4 | 2 | 5 | 2 | 1 | 7 | 7 | 6 | 7 | 4 | 1 | 6 |
| 2 | 3 | 4 | 5 | 4 | 6 | 2 | 7 | 5 | 6 | 6 | 5 | 7 |
| 3 | 6 | 3 | 3 | 1 | 5 | 4 | 2 | 4 | 3 | 2 | 1 | 5 |
| 4 | 3 | 7 | 3 | 1 | 6 | 4 | 6 | 7 | 1 | 7 | 2 | 3 |
| 5 | 3 | 2 | 7 | 7 | 1 | 6 | 5 | 7 | 5 | 7 | 7 | 5 |
| 6 | 2 | 2 | 3 | 5 | 1 | 7 | 5 | 2 | 3 | 7 | 3 | 7 |
| 7 | 3 | 1 | 3 | 5 | 5 | 2 | 3 | 6 | 1 | 1 | 1 | 5 |
| 8 | 6 | 2 | 1 | 3 | 6 | 7 | 2 | 6 | 2 | 3 | 7 | 4 |
| 9 | 7 | 5 | 1 | 1 | 7 | 7 | 5 | 3 | 6 | 7 | 7 | 1 |
| TD | Two-Class (SDs) | Three-Class (SDs) | Four-Class (SDs) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| X-Se | X-S1 | X-S2 | X-S3 | X-Se | X-S1 | X-S2 | X-S3 | X-Se | X-S1 | X-S2 | X-S3 | |
| 1 | 1 | 7 | 7 | 6 | 6 | 6 | 2 | 4 | 1 | 6 | 7 | 2 |
| 2 | 6 | 4 | 1 | 7 | 2 | 3 | 1 | 3 | 1 | 4 | 2 | 6 |
| 3 | 6 | 6 | 1 | 7 | 6 | 7 | 1 | 7 | 4 | 5 | 3 | 4 |
| 4 | 3 | 4 | 1 | 1 | 5 | 5 | 1 | 7 | 5 | 5 | 2 | 4 |
| 5 | 1 | 1 | 3 | 1 | 6 | 4 | 7 | 7 | 2 | 6 | 7 | 4 |
| 6 | 2 | 1 | 7 | 1 | 1 | 7 | 7 | 5 | 3 | 7 | 6 | 2 |
| 7 | 4 | 4 | 7 | 2 | 7 | 4 | 7 | 4 | 7 | 5 | 6 | 3 |
| 8 | 6 | 6 | 7 | 7 | 5 | 5 | 2 | 7 | 7 | 2 | 3 | 3 |
| 9 | 1 | 1 | 7 | 7 | 7 | 6 | 5 | 1 | 3 | 6 | 2 | 7 |
| Methods | Two-Class | Three-Class | Four-Class |
|---|---|---|---|
| X-Sessions | X-Sessions | X-Sessions | |
| LSA-MMFT | 75.7 (11.26) | 64.1 (14.24) | 58.3 (6.79) |
| DTE | 85.1 (21.3) | 68.9 (17.93) | 61.2 (14.43) |
| ROD | 81.6 (20.5) | 63.2 (22.73) | 57 (12.88) |
| EMC-MMFT | 94.2 (11.26) | 84.1 (14.24) | 75.06 (6.79) |
| Methods | Two-Class | Three-Class | Four-Class | ||||||
|---|---|---|---|---|---|---|---|---|---|
| X-S1 | X-S2 | X-S3 | X-S1 | X-S2 | X-S3 | X-S1 | X-S2 | X-S3 | |
| LSA-MMFT | 83.3 (6.09) | 60.4 (15.5) | 65.1 (17.5) | 67.1 (5.9) | 40.9 (13.2) | 41.8 (13.8) | 56.6 (2.7) | 30.7 (7.9) | 35.2 (11.1) |
| DTE | 83.7 (14.8) | 64 (14.2) | 60.3 (18.3) | 67.1 (11.2) | 42.3 (10.6) | 44.9 (12.1) | 56.9 (9.4) | 32.2 (2.7) | 36.5 (11.1) |
| ROD | 85.1 (14.9) | 58.2 (8.5) | 67.6 (10.5) | 69.4 (13.2) | 42.1 (7.5) | 47.6 (6.9) | 56.8 (11.6) | 30.2 (5.2) | 27.8 (10) |
| EMC-MMFT | 93.9 (6.09) | 84.5 (8.7) | 78.4 (12.4) | 80 (5.9) | 72.8 (10.7) | 64.3 (7.6) | 67.4 (2.7) | 59.8 (12.6) | 62.9 (10) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maswanganyi, R.C.; Tu, C.; Owolawi, P.A.; Du, S. Comparison of Domain Selection Methods for Multi-Source Manifold Feature Transfer Learning in Electroencephalogram Classification. Appl. Sci. 2024, 14, 2326. https://doi.org/10.3390/app14062326
Maswanganyi RC, Tu C, Owolawi PA, Du S. Comparison of Domain Selection Methods for Multi-Source Manifold Feature Transfer Learning in Electroencephalogram Classification. Applied Sciences. 2024; 14(6):2326. https://doi.org/10.3390/app14062326
Chicago/Turabian StyleMaswanganyi, Rito Clifford, Chungling Tu, Pius Adewale Owolawi, and Shengzhi Du. 2024. "Comparison of Domain Selection Methods for Multi-Source Manifold Feature Transfer Learning in Electroencephalogram Classification" Applied Sciences 14, no. 6: 2326. https://doi.org/10.3390/app14062326
APA StyleMaswanganyi, R. C., Tu, C., Owolawi, P. A., & Du, S. (2024). Comparison of Domain Selection Methods for Multi-Source Manifold Feature Transfer Learning in Electroencephalogram Classification. Applied Sciences, 14(6), 2326. https://doi.org/10.3390/app14062326