


A Review of Current Trends, Techniques, and Challenges in Large Language Models (LLMs)



Abstract
1. Introduction
1.1. Background
1.2. Static Embeddings
1.3. Dynamic Embeddings
1.4. Task-Dependent Architectures
1.5. Task-Agnostic Architecture
2. Language Models and Attention Mechanism
2.1. Language Models
2.2. Attention Layer
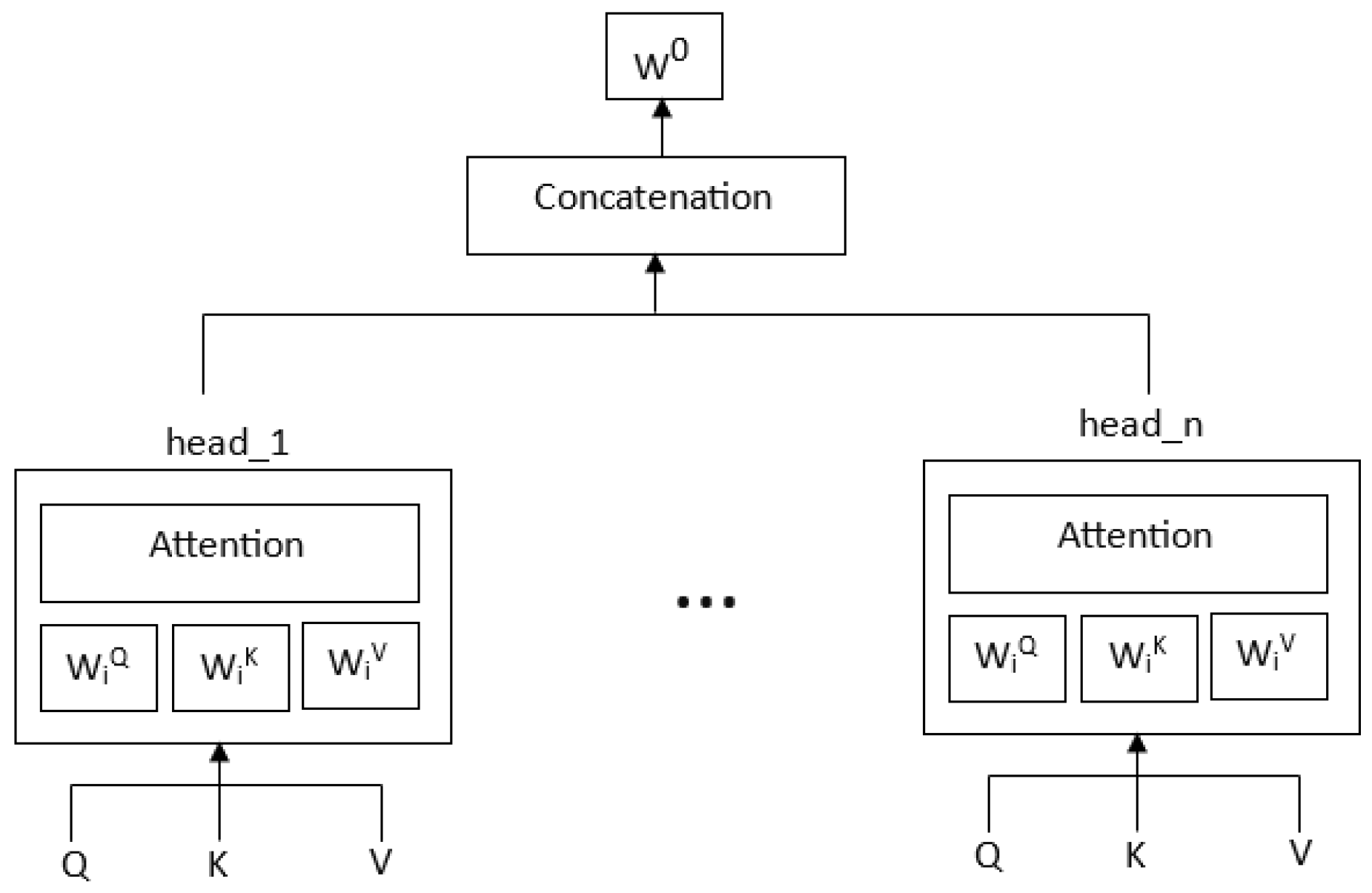
2.3. Multihead Attention
2.4. Attention-Based RNN Models
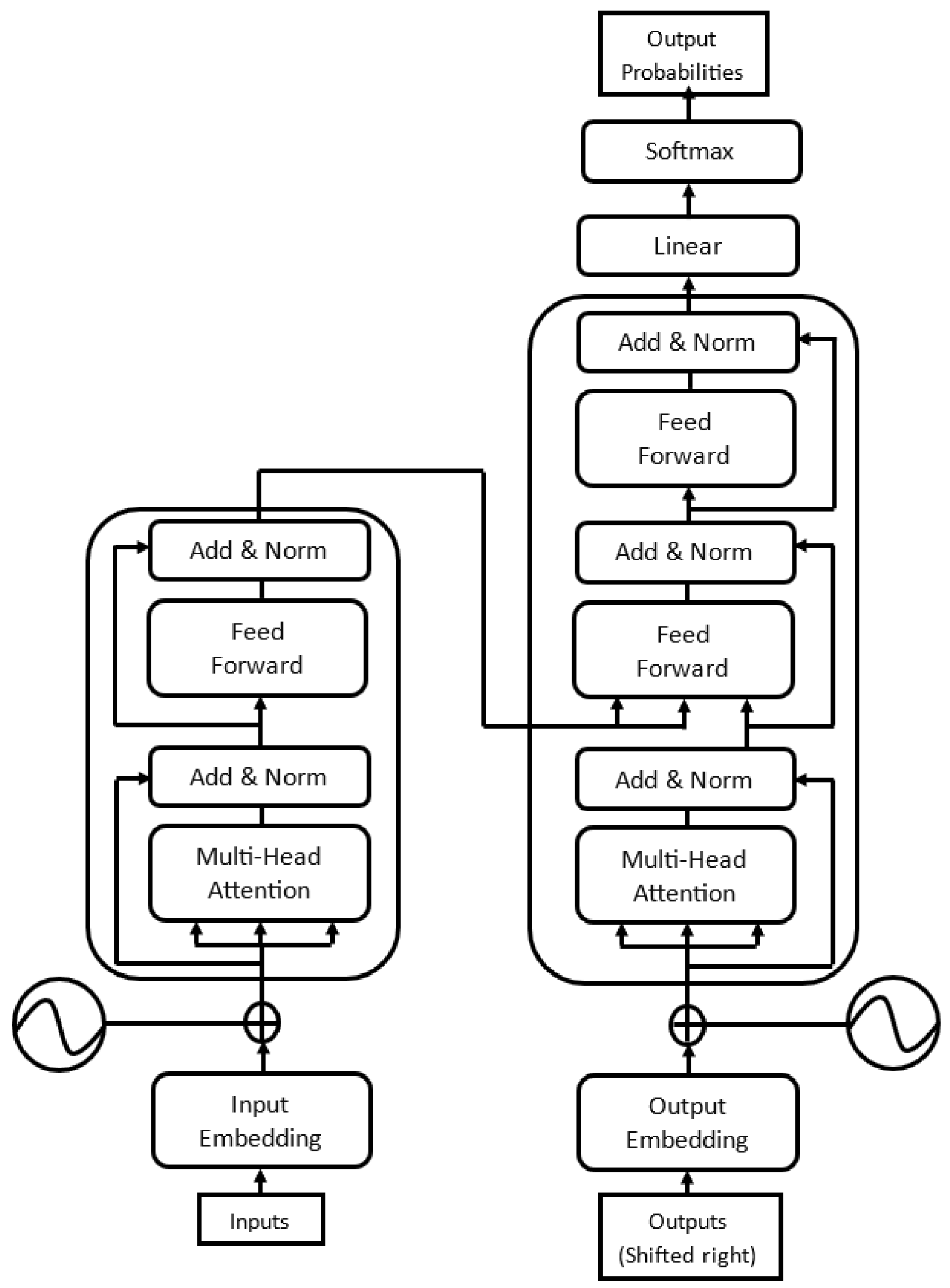
2.5. Attention-Based Transformer Models
3. Transformer
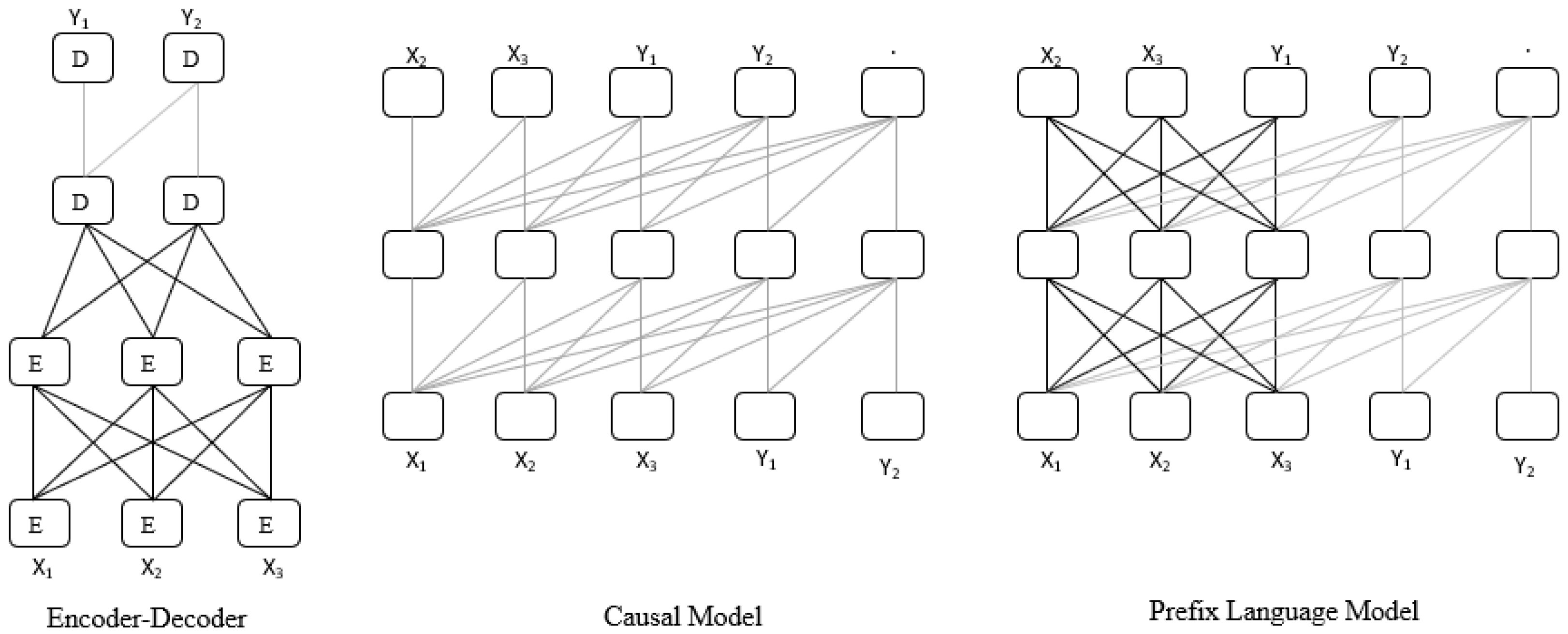
3.1. Encoder–Decoder-Based Model
3.2. Encoder-Only-Based Model
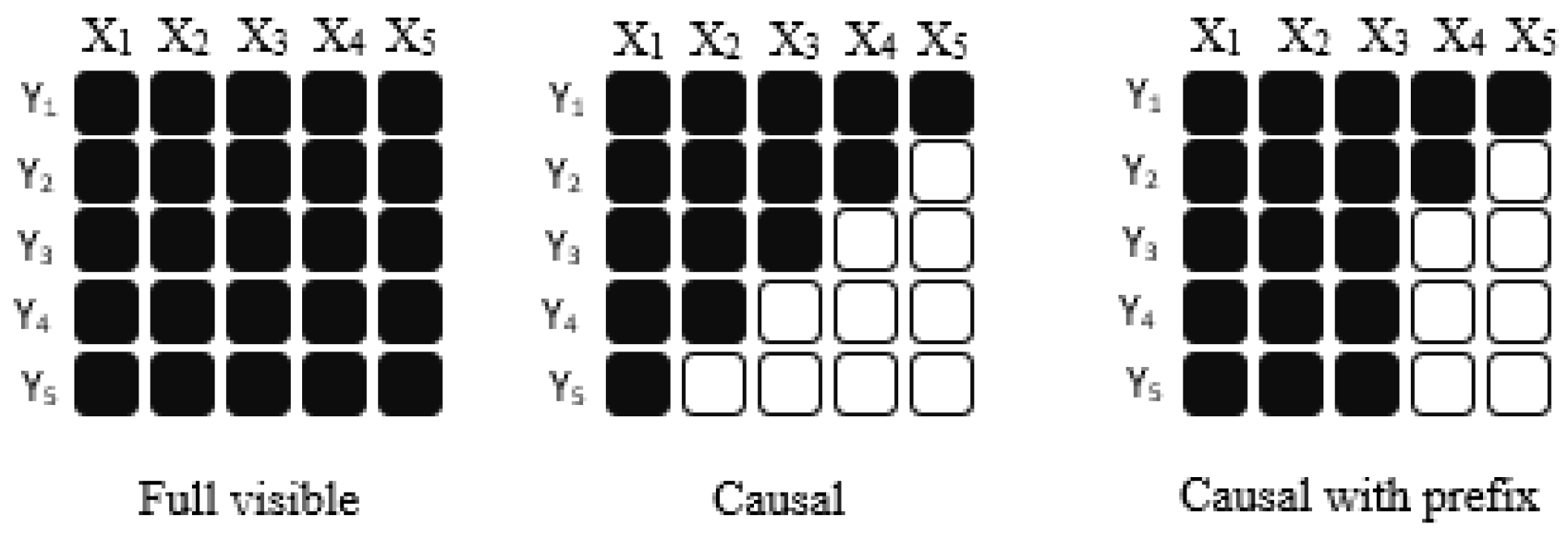
3.3. Decoder-Only (Causal)-Based Model
3.4. Prefix (Non-Causal) Language Model
3.5. Mask Types
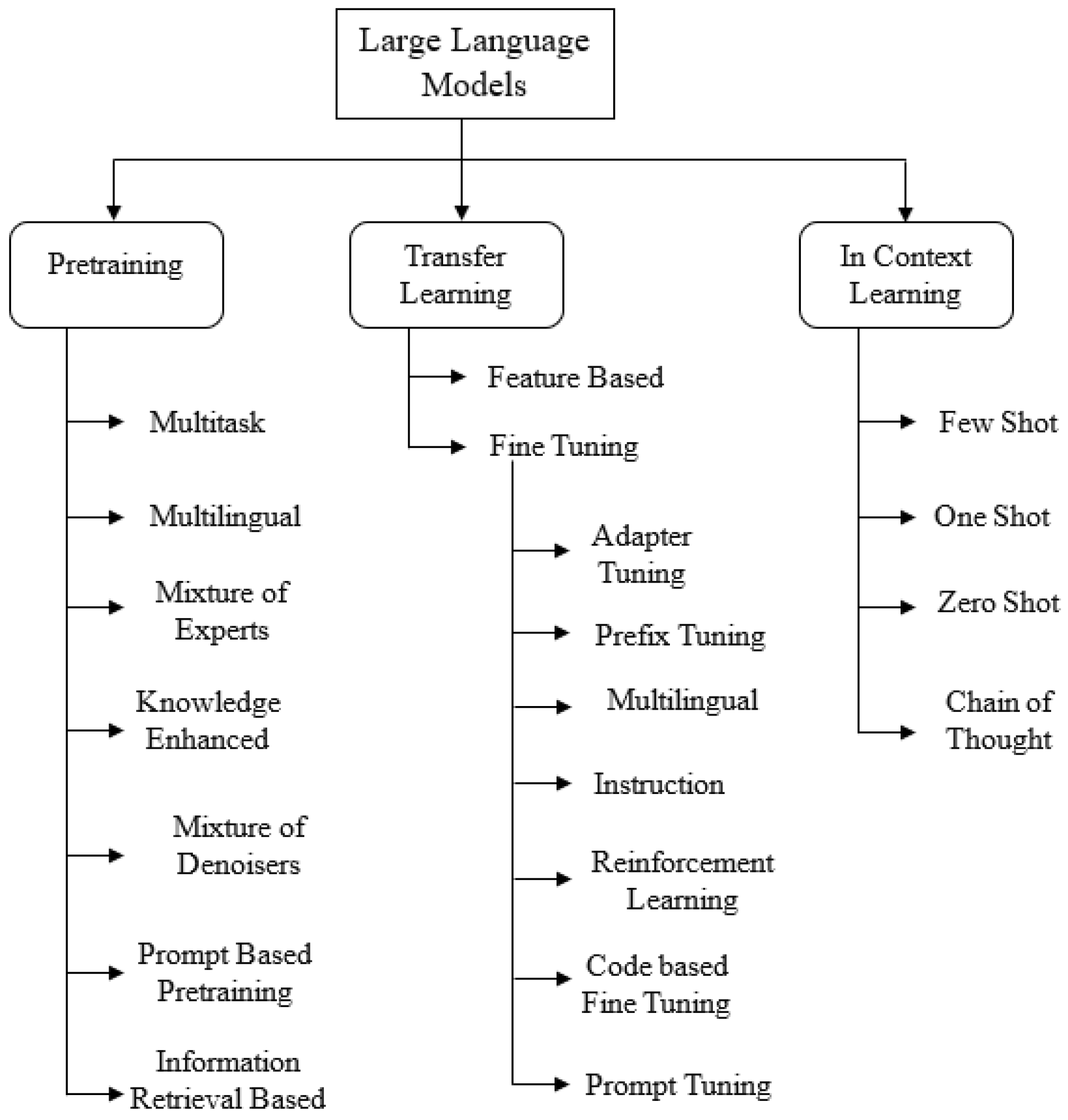
4. Pretraining—Strategies and Objectives
4.1. Objectives
4.1.1. Left-to-Right (LTR) Language Model Objective
4.1.2. Prefix Language Model Objective
4.1.3. Masked Language Model Objective
4.1.4. General Language Mode Objective
4.1.5. Span Corruption Objective
4.1.6. Deshuffle Objective
4.1.7. Next-Sentence Prediction (NSP) Objective
4.2. Learning Strategies
4.2.1. Multitask Pretraining
4.2.2. Multilingual Pretraining
4.2.3. Mixture of Experts (MoE)-Based Pretraining
4.2.4. Knowledge-Enhanced Pretraining
4.2.5. Mixture of Denoisers (MoD)-Based Pretraining
Extreme Denoising
Sequential Denoising
Regular Denoising
4.2.6. Prompt Pretraining
4.2.7. Information-Retrieval-Based Pretraining
5. Transfer Learning Strategies
5.1. Finetuning
5.2. Adapter Tuning
5.3. Gradual Unfreezing
5.4. Prefix Tuning
5.5. Prompt-Tuning
5.5.1. Prompt Engineering
5.5.2. Continuous Prompt-Tuning
5.6. Multilingual Finetuning
5.7. Reinforcement Learning from Human Feedback (RLHF) Finetuning
5.8. Instruction Tuning
5.9. Code-Based Finetuning
6. In-Context Learning
6.1. Few-Shot Learning
6.2. One-Shot Learning
6.3. Zero-Shot Learning
6.4. Chain-of-Thought Learning
7. Scalability
7.1. Model Width (Parameter Size)
7.2. Training Tokens and Data Size
7.3. Model Depth (Network Layers)
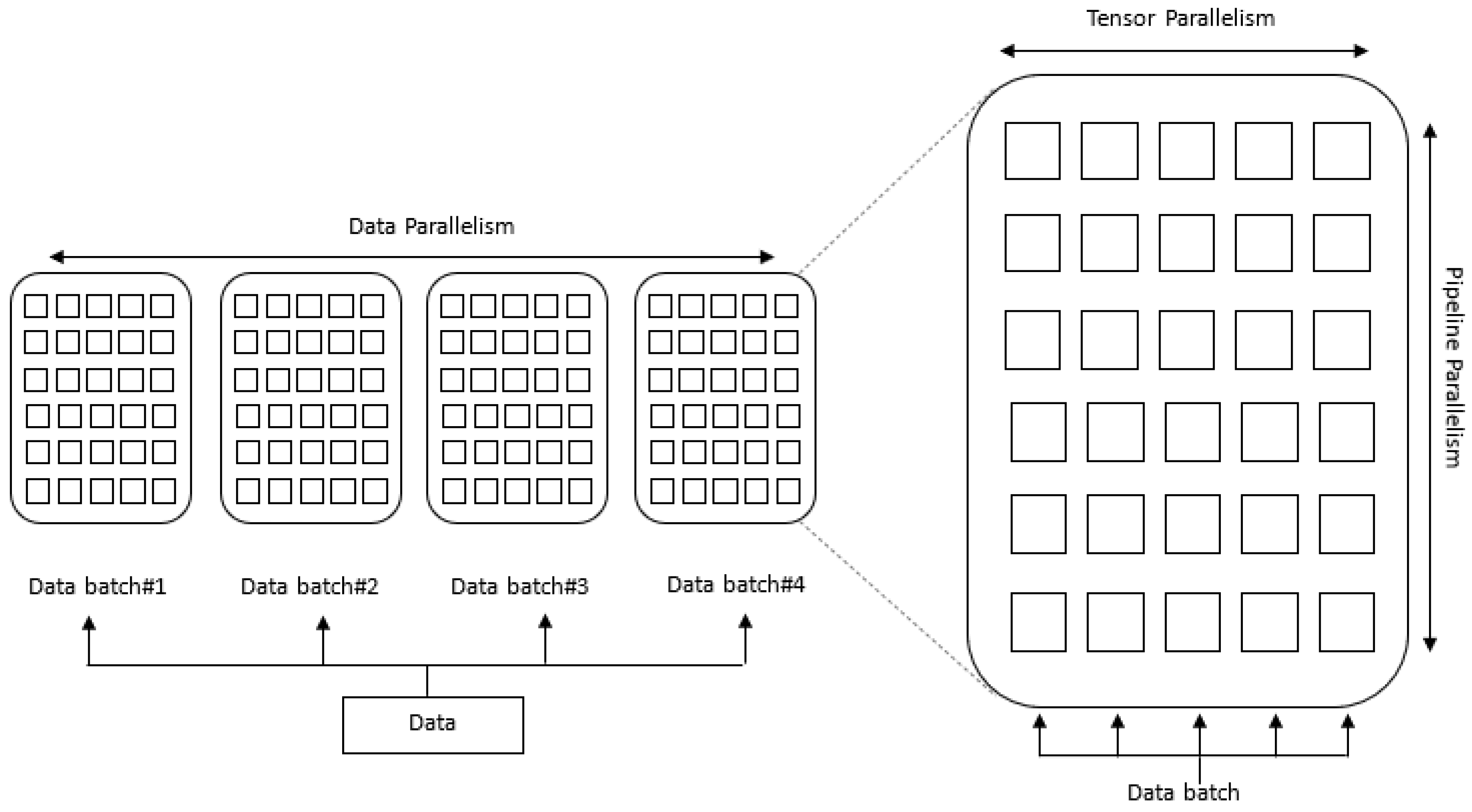
7.4. Architecture—Parallelism
7.4.1. Data Parallelism
7.4.2. Tensor Parallelism (Op-Level Model Parallelism)
7.4.3. Pipeline Parallelism
8. LLM Challenges
8.1. Toxic Content
8.2. Hallucination
- sample not one but multiple outputs and check the information consistency between them to check which statements are factual and which are hallucinated;
- validate the correctness of the model output by relying on and using external knowledge source;
- check if the generated named entities or <subject, relation, object> tuples appear in the ground truth knowledge source or not, etc.
8.3. Biases
8.4. Cost and Carbon Footprints
- Computational cost for pretraining: large language models require thousands of GPUs with several weeks of pretraining.
- Storage cost for finetuned models: a large language model usually takes hundreds of gigabytes (GBs) to store, and as many model copies as the number of downstream tasks need to be stored.
- Equipment cost for inference: it is expected to use multiple GPUs to infer a large language model.
- report energy consumed and CO2e explicitly;
- reward improvements in efficiency as well as traditional metrics at ML conferences;
- to help everyone understand its cost, include the time and number of processors used during training.
8.5. Open-Source and Low-Resource Aspects
9. Future Directions and Development Trends
9.1. Interpretability and Explainability
9.2. Fairness
9.3. Robustness and Adversarial Attacks
9.4. Multimodal LLMs
9.5. Energy Efficiency and Environmental Impact
9.6. Different Languages and Domains
9.7. Privacy-Preserving Models
9.8. Continual Learning and Adaptability
9.9. Ethical Use and Societal Impact
9.10. Real-World Applications and Human–LLM Collaboration
10. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Harris, Z.S. Distributional structure. Word 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Brown, P.F.; Cocke, J.; Della Pietra, S.A.; Della Pietra, V.J.; Jelinek, F.; Lafferty, J.; Mercer, R.L.; Roossin, P.S. A statistical approach to machine translation. Comput. Linguist. 1990, 16, 79–85. [Google Scholar]
- Salton, G.; Lesk, M.E. Computer evaluation of indexing and text processing. J. ACM (JACM) 1968, 15, 8–36. [Google Scholar] [CrossRef]
- Jones, K.S. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Salton, G.; Wong, A.; Yang, C.S. A vector space model for automatic indexing. Commun. ACM 1975, 18, 613–620. [Google Scholar] [CrossRef]
- Tang, B.; Shepherd, M.; Milios, E.; Heywood, M.I. Comparing and combining dimension reduction techniques for efficient text clustering. In Proceedings of the SIAM International Workshop on Feature Selection for Data Mining, Newport Beach, CA, USA, 21 April 2005; pp. 17–26. [Google Scholar]
- Hyvärinen, A.; Oja, E. Independent component analysis: Algorithms and applications. Neural Netw. 2000, 13, 411–430. [Google Scholar] [CrossRef]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, Montreal, QC, Canada, 8–13 December 2014; pp. 1188–1196. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Vilnis, L.; McCallum, A. Word representations via gaussian embedding. arXiv 2014, arXiv:1412.6623. [Google Scholar]
- Athiwaratkun, B.; Wilson, A.G. Multimodal word distributions. arXiv 2017, arXiv:1704.08424. [Google Scholar]
- Melamud, O.; Goldberger, J.; Dagan, I. context2vec: Learning generic context embedding with bidirectional lstm. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; pp. 51–61. [Google Scholar]
- McCann, B.; Bradbury, J.; Xiong, C.; Socher, R. Learned in translation: Contextualized word vectors. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 2227–2237. [Google Scholar]
- Howard, J.; Ruder, S. Universal language model fine-tuning for text classification. arXiv 2018, arXiv:1801.06146. [Google Scholar]
- Dong, L.; Yang, N.; Wang, W.; Wei, F.; Liu, X.; Wang, Y.; Gao, J.; Zhou, M.; Hon, H.W. Unified language model pre-training for natural language understanding and generation. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Scao, T.L.; Fan, A.; Akiki, C.; Pavlick, E.; Ilić, S.; Hesslow, D.; Castagné, R.; Luccioni, A.S.; Yvon, F.; Gallé, M.; et al. Bloom: A 176b-parameter open-access multilingual language model. arXiv 2022, arXiv:2211.05100. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 1 February 2024).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown., T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Guu, K.; Lee, K.; Tung, Z.; Pasupat, P.; Chang, M. Retrieval augmented language model pre-training. In Proceedings of the International Conference on Machine Learning, Online, 9–11 September 2020; pp. 3929–3938. [Google Scholar]
- Lieber, O.; Sharir, O.; Lenz, B.; Shoham, Y. Jurassic-1: Technical details and evaluation. White Pap. AI21 Labs 2021, 1, 9. [Google Scholar]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A massively multilingual pre-trained text-to-text transformer. arXiv 2020, arXiv:2010.11934. [Google Scholar]
- Zeng, W.; Ren, X.; Su, T.; Wang, H.; Liao, Y.; Wang, Z.; Jiang, X.; Yang, Z.; Wang, K.; Zhang, X.; et al. Pangu-α: Large-scale autoregressive pretrained Chinese language models with auto-parallel computation. arXiv 2021, arXiv:2104.12369. [Google Scholar]
- Zhang, Z.; Gu, Y.; Han, X.; Chen, S.; Xiao, C.; Sun, Z.; Yao, Y.; Qi, F.; Guan, J.; Ke, P.; et al. Cpm-2: Large-scale cost-effective pre-trained language models. AI Open 2021, 2, 216–224. [Google Scholar] [CrossRef]
- Wu, S.; Zhao, X.; Yu, T.; Zhang, R.; Shen, C.; Liu, H.; Li, F.; Zhu, H.; Luo, J.; Xu, L.; et al. Yuan 1.0: Large-scale pre-trained language model in zero-shot and few-shot learning. arXiv 2021, arXiv:2110.04725. [Google Scholar]
- Kim, B.; Kim, H.; Lee, S.W.; Lee, G.; Kwak, D.; Jeon, D.H.; Park, S.; Kim, S.; Kim, S.; Seo, D.; et al. What changes can large-scale language models bring? intensive study on hyperclova: Billions-scale korean generative pretrained transformers. arXiv 2021, arXiv:2109.04650. [Google Scholar]
- Du, N.; Huang, Y.; Dai, A.M.; Tong, S.; Lepikhin, D.; Xu, Y.; Krikun, M.; Zhou, Y.; Yu, A.W.; Firat, O.; et al. Glam: Efficient scaling of language models with mixture-of-experts. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 5547–5569. [Google Scholar]
- Sun, Y.; Wang, S.; Feng, S.; Ding, S.; Pang, C.; Shang, J.; Liu, J.; Chen, X.; Zhao, Y.; Lu, Y.; et al. Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation. arXiv 2021, arXiv:2107.02137. [Google Scholar]
- Rae, J.W.; Borgeaud, S.; Cai, T.; Millican, K.; Hoffmann, J.; Song, F.; Aslanides, J.; Henderson, S.; Ring, R.; Young, S.; et al. Scaling language models: Methods, analysis & insights from training gopher. arXiv 2021, arXiv:2112.11446. [Google Scholar]
- Hoffmann, J.; Borgeaud, S.; Mensch, A.; Buchatskaya, E.; Cai, T.; Rutherford, E.; Casas, D.D.L.; Hendricks, L.A.; Welbl, J.; Clark, A.; et al. Training compute-optimal large language models. arXiv 2022, arXiv:2203.15556. [Google Scholar]
- Li, Y.; Choi, D.; Chung, J.; Kushman, N.; Schrittwieser, J.; Leblond, R.; Eccles, T.; Keeling, J.; Gimeno, F.; Dal Lago, A.; et al. Competition-level code generation with alphacode. Science 2022, 378, 1092–1097. [Google Scholar] [CrossRef]
- Nijkamp, E.; Pang, B.; Hayashi, H.; Tu, L.; Wang, H.; Zhou, Y.; Savarese, S.; Xiong, C. Codegen: An open large language model for code with multi-turn program synthesis. arXiv 2022, arXiv:2203.13474. [Google Scholar]
- Zheng, Q.; Xia, X.; Zou, X.; Dong, Y.; Wang, S.; Xue, Y.; Wang, Z.; Shen, L.; Wang, A.; Li, Y.; et al. Codegeex: A pre-trained model for code generation with multilingual evaluations on humaneval-x. arXiv 2023, arXiv:2303.17568. [Google Scholar]
- Wei, J.; Bosma, M.; Zhao, V.Y.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned language models are zero-shot learners. arXiv 2021, arXiv:2109.01652. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Thoppilan, R.; De Freitas, D.; Hall, J.; Shazeer, N.; Kulshreshtha, A.; Cheng, H.T.; Jin, A.; Bos, T.; Baker, L.; Du, Y.; et al. Lamda: Language models for dialog applications. arXiv 2022, arXiv:2201.08239. [Google Scholar]
- Sanh, V.; Webson, A.; Raffel, C.; Bach, S.H.; Sutawika, L.; Alyafeai, Z.; Chaffin, A.; Stiegler, A.; Scao, T.L.; Raja, A.; et al. Multitask prompted training enables zero-shot task generalization. arXiv 2021, arXiv:2110.08207. [Google Scholar]
- Black, S.; Biderman, S.; Hallahan, E.; Anthony, Q.; Gao, L.; Golding, L.; He, H.; Leahy, C.; McDonell, K.; Phang, J.; et al. Gpt-neox-20b: An open-source autoregressive language model. arXiv 2022, arXiv:2204.06745. [Google Scholar]
- Zhang, S.; Roller, S.; Goyal, N.; Artetxe, M.; Chen, M.; Chen, S.; Dewan, C.; Diab, M.; Li, X.; Lin, X.V.; et al. Opt: Open pre-trained transformer language models. arXiv 2022, arXiv:2205.01068. [Google Scholar]
- Lewkowycz, A.; Andreassen, A.; Dohan, D.; Dyer, E.; Michalewski, H.; Ramasesh, V.; Slone, A.; Anil, C.; Schlag, I.; Gutman-Solo, T.; et al. Solving quantitative reasoning problems with language models. Adv. Neural Inf. Process. Syst. 2022, 35, 3843–3857. [Google Scholar]
- Soltan, S.; Ananthakrishnan, S.; FitzGerald, J.; Gupta, R.; Hamza, W.; Khan, H.; Peris, C.; Rawls, S.; Rosenbaum, A.; Rumshisky, A.; et al. Alexatm 20b: Few-shot learning using a large-scale multilingual seq2seq model. arXiv 2022, arXiv:2208.01448. [Google Scholar]
- Zeng, A.; Liu, X.; Du, Z.; Wang, Z.; Lai, H.; Ding, M.; Yang, Z.; Xu, Y.; Zheng, W.; Xia, X.; et al. Glm-130b: An open bilingual pre-trained model. arXiv 2022, arXiv:2210.02414. [Google Scholar]
- Lin, X.V.; Mihaylov, T.; Artetxe, M.; Wang, T.; Chen, S.; Simig, D.; Ott, M.; Goyal, N.; Bhosale, S.; Du, J.; et al. Few-shot Learning with Multilingual Generative Language Models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 9019–9052. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. Palm: Scaling language modeling with pathways. arXiv 2022, arXiv:2204.02311. [Google Scholar]
- Taylor, R.; Kardas, M.; Cucurull, G.; Scialom, T.; Hartshorn, A.; Saravia, E.; Poulton, A.; Kerkez, V.; Stojnic, R. Galactica: A large language model for science. arXiv 2022, arXiv:2211.09085. [Google Scholar]
- Chen, X.; Wang, X.; Changpinyo, S.; Piergiovanni, A.J.; Padlewski, P.; Salz, D.; Goodman, S.; Grycner, A.; Mustafa, B.; Beyer, L.; et al. Pali: A jointly-scaled multilingual language-image model. arXiv 2022, arXiv:2209.06794. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Tay, Y.; Dehghani, M.; Tran, V.Q.; Garcia, X.; Wei, J.; Wang, X.; Chung, H.W.; Bahri, D.; Schuster, T.; Zheng, S.; et al. Ul2: Unifying language learning paradigms. In Proceedings of the Eleventh International Conference on Learning Representations, Virtual Event, 25–29 April 2022. [Google Scholar]
- Biderman, S.; Schoelkopf, H.; Anthony, Q.G.; Bradley, H.; O’Brien, K.; Hallahan, E.; Khan, M.A.; Purohit, S.; Prashanth, U.S.; Raff, E.; et al. Pythia: A suite for analyzing large language models across training and scaling. In Proceedings of the International Conference on Machine Learning, Nashville, TN, USA, 10–12 July 2023; pp. 2397–2430. [Google Scholar]
- Su, H.; Zhou, X.; Yu, H.; Chen, Y.; Zhu, Z.; Yu, Y.; Zhou, J. Welm: A well-read pre-trained language model for chinese. arXiv 2022, arXiv:2209.10372. [Google Scholar]
- Du, Z.; Qian, Y.; Liu, X.; Ding, M.; Qiu, J.; Yang, Z.; Tang, J. Glm: General language model pretraining with autoregressive blank infilling. arXiv 2021, arXiv:2103.10360. [Google Scholar]
- Tay, Y.; Dehghani, M.; Rao, J.; Fedus, W.; Abnar, S.; Chung, H.W.; Narang, S.; Yogatama, D.; Vaswani, A.; Metzler, D. Scale efficiently: Insights from pre-training and fine-tuning transformers. arXiv 2021, arXiv:2109.10686. [Google Scholar]
- Artetxe, M.; Bhosale, S.; Goyal, N.; Mihaylov, T.; Ott, M.; Shleifer, S.; Lin, X.V.; Du, J.; Iyer, S.; Pasunuru, R.; et al. Efficient large scale language modeling with mixtures of experts. arXiv 2021, arXiv:2112.10684. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised cross-lingual representation learning at scale. arXiv 2019, arXiv:1911.02116. [Google Scholar]
- Shazeer, N.; Mirhoseini, A.; Maziarz, K.; Davis, A.; Le, Q.; Hinton, G.; Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv 2017, arXiv:1701.06538. [Google Scholar]
- Zoph, B.; Bello, I.; Kumar, S.; Du, N.; Huang, Y.; Dean, J.; Shazeer, N.; Fedus, W. St-moe: Designing stable and transferable sparse expert models. arXiv 2022, arXiv:2202.08906. [Google Scholar]
- Lepikhin, D.; Lee, H.; Xu, Y.; Chen, D.; Firat, O.; Huang, Y.; Krikun, M.; Shazeer, N.; Chen, Z. GShard: Scaling giant models with conditional computation and automatic sharding. arXiv 2020, arXiv:2006.16668. [Google Scholar]
- Fedus, W.; Zoph, B.; Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. J. Mach. Learn. Res. 2022, 23, 5232–5270. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced language representation with informative entities. arXiv 2019, arXiv:1905.07129. [Google Scholar]
- Peters, M.E.; Neumann, M.; Logan, R.L., IV; Schwartz, R.; Joshi, V.; Singh, S.; Smith, N.A. Knowledge enhanced contextual word representations. arXiv 2019, arXiv:1909.04164. [Google Scholar]
- Zhou, W.; Lee, D.H.; Selvam, R.K.; Lee, S.; Lin, B.Y.; Ren, X. Pre-training text-to-text transformers for concept-centric common sense. arXiv 2020, arXiv:2011.07956. [Google Scholar]
- Xiong, W.; Du, J.; Wang, W.Y.; Stoyanov, V. Pretrained encyclopedia: Weakly supervised knowledge-pretrained language model. arXiv 2019, arXiv:1912.09637. [Google Scholar]
- Wang, X.; Gao, T.; Zhu, Z.; Zhang, Z.; Liu, Z.; Li, J.; Tang, J. KEPLER: A unified model for knowledge embedding and pre-trained language representation. Trans. Assoc. Comput. Linguist. 2021, 9, 176–194. [Google Scholar] [CrossRef]
- Sun, T.; Shao, Y.; Qiu, X.; Guo, Q.; Hu, Y.; Huang, X.; Zhang, Z. Colake: Contextualized language and knowledge embedding. arXiv 2020, arXiv:2010.00309. [Google Scholar]
- Wang, R.; Tang, D.; Duan, N.; Wei, Z.; Huang, X.; Cao, G.; Jiang, D.; Zhou, M. K-adapter: Infusing knowledge into pre-trained models with adapters. arXiv 2020, arXiv:2002.01808. [Google Scholar]
- Tay, Y.; Wei, J.; Chung, H.W.; Tran, V.Q.; So, D.R.; Shakeri, S.; Garcia, X.; Zheng, H.S.; Rao, J.; Chowdhery, A.; et al. Transcending scaling laws with 0.1% extra compute. arXiv 2022, arXiv:2210.11399. [Google Scholar]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-efficient transfer learning for NLP. In Proceedings of the International Conference on Machine Learning, Vancouver, BC, Canada, 13 December 2019; pp. 2790–2799. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-tuning: Optimizing continuous prompts for generation. arXiv 2021, arXiv:2101.00190. [Google Scholar]
- Liu, X.; Zheng, Y.; Du, Z.; Ding, M.; Qian, Y.; Yang, Z.; Tang, J. GPT understands, too. AI Open 2023, in press. [Google Scholar] [CrossRef]
- Lester, B.; Al-Rfou, R.; Constant, N. The power of scale for parameter-efficient prompt tuning. arXiv 2021, arXiv:2104.08691. [Google Scholar]
- Muennighoff, N.; Wang, T.; Sutawika, L.; Roberts, A.; Biderman, S.; Scao, T.L.; Bari, M.S.; Shen, S.; Yong, Z.X.; Schoelkopf, H.; et al. Crosslingual generalization through multitask finetuning. arXiv 2022, arXiv:2211.01786. [Google Scholar]
- Ziegler, D.M.; Stiennon, N.; Wu, J.; Brown, T.B.; Radford, A.; Amodei, D.; Christiano, P.; Irving, G. Fine-tuning language models from human preferences. arXiv 2019, arXiv:1909.08593. [Google Scholar]
- Wu, J.; Ouyang, L.; Ziegler, D.M.; Stiennon, N.; Lowe, R.; Leike, J.; Christiano, P. Recursively summarizing books with human feedback. arXiv 2021, arXiv:2109.10862. [Google Scholar]
- Stiennon, N.; Ouyang, L.; Wu, J.; Ziegler, D.; Lowe, R.; Voss, C.; Radford, A.; Amodei, D.; Christiano, P.F. Learning to summarize with human feedback. Adv. Neural Inf. Process. Syst. 2020, 33, 3008–3021. [Google Scholar]
- Wang, Y.; Mishra, S.; Alipoormolabashi, P.; Kordi, Y.; Mirzaei, A.; Arunkumar, A.; Ashok, A.; Dhanasekaran, A.S.; Naik, A.; Stap, D.; et al. Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks. arXiv 2022, arXiv:2204.07705. [Google Scholar]
- Iyer, S.; Lin, X.V.; Pasunuru, R.; Mihaylov, T.; Simig, D.; Yu, P.; Shuster, K.; Wang, T.; Liu, Q.; Koura, P.S.; et al. Opt-iml: Scaling language model instruction meta learning through the lens of generalization. arXiv 2022, arXiv:2212.12017. [Google Scholar]
- Chung, H.W.; Hou, L.; Longpre, S.; Zoph, B.; Tay, Y.; Fedus, W.; Li, E.; Wang, X.; Dehghani, M.; Brahma, S.; et al. Scaling instruction-finetuned language models. arXiv 2022, arXiv:2210.11416. [Google Scholar]
- Wang, Y.; Kordi, Y.; Mishra, S.; Liu, A.; Smith, N.A.; Khashabi, D.; Hajishirzi, H. Self-instruct: Aligning language model with self generated instructions. arXiv 2022, arXiv:2212.10560. [Google Scholar]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pinto, H.P.D.O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating large language models trained on code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Zhao, Z.; Wallace, E.; Feng, S.; Klein, D.; Singh, S. Calibrate before use: Improving few-shot performance of language models. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 12697–12706. [Google Scholar]
- Liu, J.; Shen, D.; Zhang, Y.; Dolan, B.; Carin, L.; Chen, W. What Makes Good In-Context Examples for GPT-3? arXiv 2021, arXiv:2101.06804. [Google Scholar]
- Mosbach, M.; Pimentel, T.; Ravfogel, S.; Klakow, D.; Elazar, Y. Few-shot Fine-tuning vs. In-context Learning: A Fair Comparison and Evaluation. arXiv 2023, arXiv:2305.16938. [Google Scholar]
- Wang, T.; Roberts, A.; Hesslow, D.; Le Scao, T.; Chung, H.W.; Beltagy, I.; Launay, J.; Raffel, C. What language model architecture and pretraining objective works best for zero-shot generalization? In Proceedings of the International Conference on Machine Learning, PMLR, Online, 28–30 March 2022; pp. 22964–22984. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Wang, X.; Wei, J.; Schuurmans, D.; Le, Q.; Chi, E.; Narang, S.; Chowdhery, A.; Zhou, D. Self-consistency improves chain of thought reasoning in language models. arXiv 2022, arXiv:2203.11171. [Google Scholar]
- Wei, J.; Tay, Y.; Bommasani, R.; Raffel, C.; Zoph, B.; Borgeaud, S.; Yogatama, D.; Bosma, M.; Zhou, D.; Metzler, D.; et al. Emergent abilities of large language models. arXiv 2022, arXiv:2206.07682. [Google Scholar]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling laws for neural language models. arXiv 2020, arXiv:2001.08361. [Google Scholar]
- Levine, Y.; Wies, N.; Sharir, O.; Bata, H.; Shashua, A. Limits to depth efficiencies of self-attention. Adv. Neural Inf. Process. Syst. 2020, 33, 22640–22651. [Google Scholar]
- Gehman, S.; Gururangan, S.; Sap, M.; Choi, Y.; Smith, N.A. Realtoxicityprompts: Evaluating neural toxic degeneration in language models. arXiv 2020, arXiv:2009.11462. [Google Scholar]
- Ung, M.; Xu, J.; Boureau, Y.L. Saferdialogues: Taking feedback gracefully after conversational safety failures. arXiv 2021, arXiv:2110.07518. [Google Scholar]
- Dinan, E.; Abercrombie, G.; Bergman, A.S.; Spruit, S.; Hovy, D.; Boureau, Y.L.; Rieser, V. Anticipating safety issues in e2e conversational ai: Framework and tooling. arXiv 2021, arXiv:2107.03451. [Google Scholar]
- Lin, S.; Hilton, J.; Evans, O. Truthfulqa: Measuring how models mimic human falsehoods. arXiv 2021, arXiv:2109.07958. [Google Scholar]
- Rudinger, R.; Naradowsky, J.; Leonard, B.; Van Durme, B. Gender bias in coreference resolution. arXiv 2018, arXiv:1804.09301. [Google Scholar]
- Nangia, N.; Vania, C.; Bhalerao, R.; Bowman, S.R. CrowS-pairs: A challenge dataset for measuring social biases in masked language models. arXiv 2020, arXiv:2010.00133. [Google Scholar]
- Nadeem, M.; Bethke, A.; Reddy, S. StereoSet: Measuring stereotypical bias in pretrained language models. arXiv 2020, arXiv:2004.09456. [Google Scholar]
- Patterson, D.; Gonzalez, J.; Le, Q.; Liang, C.; Munguia, L.M.; Rothchild, D.; So, D.; Texier, M.; Dean, J. Carbon emissions and large neural network training. arXiv 2021, arXiv:2104.10350. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Param Size | Layers | d-Model | Attention Heads | Hardware |
|---|---|---|---|---|---|
| Transformer-base [24] | - | 6 E, 6 D | 512 | 8 | 8 NVIDIA P100 GPUs |
| Transformer-big [24] | - | 12 E, 12 D | 1024 | 16 | 8 NVIDIA P100 GPUs |
| BERT-base [26] | 110 M | 12 E | 768 | 12 | 4 Cloud TPUs |
| BERT-large [26] | 340 M | 24 E | 1024 | 16 | 16 Cloud TPUs (64 TPU chips) |
| GPT-1 [27] | 117 M | 12 D | 768 | 12 | - |
| GPT-2 [28] | 117 M to 1.5 B | 24 D to 48 D | 1600 | 48 | - |
| GPT-3 [29] | 175 B | 96 | 12,288 | 96 | V 100 GPUs (285 K CPU cores, 10 K GPUs) |
| T5 [25] | 220 M–11 B | (12 E, 12 D) | - | - | 1024 TPU v3 |
| REALM [30] | 330 M | - | - | - | 64 Google Cloud TPUs, 12 GB GPU |
| Jurassic-1 [31] | 178 B | 76 | 13,824 | 96 | |
| mT5 [32] | 13 B | - | - | - | - |
| Pangu-Alpha [33] | 207 B | 64 | 16,384 | 128 | 2048 Ascend 910 AI processors |
| CPM-2 [34] | 198 B | 24 | 4096 | 64 | - |
| Yuan 1.0 [35] | 245 B | - | - | - | - |
| HyperClova [36] | 82B | 64 | 10,240 | 80 | 128 DGX servers with 1024 A100 GPUs |
| GLaM [37] | 1.2 T (96.6) | 64 MoE | 8192 | 128 | 1024 Cloud TPU-V4 chips (Single System) |
| ERNIE 3.0 [38] | 10 B | 48, 12 | 4096, 768 | 64, 12 | 384 NVDIA v100 GPU cards |
| Gopher [39] | 280 B | 80 | 16,384 | 128 | 4 DCN-connected TPU v3 Pods (each with 1024 TPU v3 chips) |
| Chinchilla [40] | 70 B | 80 | 8192 | 64 | - |
| AlphaCode [41] | 41.1 B | 8 E, 56 D | 6144 | 48, 16 | - |
| CodeGEN [42] | 16.1 B | 34 | 256 | 24 | - |
| CodeGeeX [43] | 13 B | 39 | 5120 | 40 | 1536 Ascend 910 AI Processors |
| FLAN [44] | 137 B | - | - | - | TPUv3 with 128 cores |
| InstructGPT [45] | 175 B | 96 | 12,288 | 96 | V 100 GPUs |
| LaMDA [46] | 137 B | 64 | 8192 | 128 | 1024 TPU-v3 chips |
| T0 [47] | 11 B | 12 | - | - | - |
| GPT NeoX 20B [48] | 20 B | 44 | 6144 | 64 | 12 AS-4124GO-NART servers (each with 8 NVIDIA A100-SXM4-40GB GPUs) |
| OPT [49] | 175B | 96 | 12,288 | 96 | 992 80GB A100 GPUs |
| MINERVA [50] | 540.35 B | 118 | 18,432 | 48 | - |
| AlexaTM 20B [51] | 20 B (19.75 B) | 46 E, 32 D | 4096 | 32 | 128 A100 GPUs |
| GLM-130 B [52] | 130 B | 70 | 12,288 | 96 | 96 NVIDIA DGX-A100 (8×40 G) |
| XGLM [53] | 7.5 B | 32 | 4096 | ||
| PaLM [54] | 540.35 B | 118 | 18,432 | 48 | 6144 TPU v4 chips (2 Pods) |
| Galactica [55] | 120 B | 96 | 10,240 | 80 | 128 NVIDIA A100 80 GB nodes |
| Pali [56] | 16.9 ( 17) B | - | - | - | - |
| LLaMA [57] | 65B | 80 | 8192 | 64 | 2048 A100 GPU (80 GB RAM) |
| UL2 [58] | 20 B | 32 E, 32 D | 4096 | 16 | 64 to 128 TPUv4 chips |
| Pythia [59] | 12 B | 36 | 5120 | 40 | - |
| WeLM [60] | 10 B | 32 | 5120 | 40 | 128 A100-SXM4-40 GB GPUs |
| BLOOM [22] | 176 B | 70 | 14,336 | 112 | 48 nodes having 8 NVIDIA A100 80GB GPUs (384 GPUs) |
| GLM [61] | 515 M | 30 | 1152 | 18 | 64 V100 GPUs |
| GPT-J | 6 B | 28 | 4096 | 16 | TPU v3-256 pod |
| YaLM | 100 B | 800 A100 | |||
| Alpaca | 7 B | 8 80 GB A100s | |||
| Falcon | 40 B | - | - | - | - |
| (Xmer) XXXL [62] | 30 B | 28 | 1280 | 256 | 64 TPU-v3 chips |
| [63] | 1.1 T | 32 | 4096 | 512 (experts) | |
| XLM-R [64] | 550 M | 24 | 1024 | 16 |
| Model | Architecture | Objectives | Pretraining Dataset | Tokens, Corpus Size |
|---|---|---|---|---|
| Transformer-base [24] | encoder–decoder | |||
| Transformer-big [24] | encoder–decoder | MLM, NSP | WMT 2014 | - |
| BERT-base [26] | Encoder-only | |||
| BERT-large [26] | Encoder-only | MLM, NSP | BooksCorpus, English Wikipedia | 137 B, - |
| GPT-1 [27] | Decoder-only | Causal/LTR-LM | BooksCorpus, 1B Word Benchmark | - |
| GPT-2 [28] | Decoder-only | Causal/LTR-LM | Reddit, WebText | -, 40 GB |
| GPT-3 [29] | Decoder-only | Causal/LTR-LM | Common Crawl, WebText, English-Wikipedia, Books1, Books2 | 300 B, 570 GB |
| T5 [25] | encoder–decoder | MLM, Span Correction | C4 | (1T tokens) 34 B, 750 GB |
| REALM [30] | Retriever + Encoder | Salient Span Masking | English Wikipedia (2018) | - |
| Jurassic-1 [31] | Decoder-only | Causal/LTR-LM | Wikipedia, OWT, Books, C4, PileCC | 300 B |
| mT5 [32] | encoder–decoder | MLM, Span Correction | mC4 | - |
| Pangu-Alpha [33] | Decoder + Query Layer | LM | Public datasets (e.g., BaiDuQA, CAIL2018, Sogou-CA, etc.), Common Crawl, encyclopedia, news and e-books | 1.1 TB (80 TB raw) |
| CPM-2 [34] | encoder–decoder | MLM | encyclopedia, novels, QA, scientific literature, e-book, news, and reviews. | -, 2.3 TB Chinese data and 300 GB English Data |
| Yuan 1.0 [35] | Decoder-only | LM, PLM | Common Crawl, Public Datasets, Encyclopedia, Books | 5 TB |
| HyperClova [36] | Decoder-only | LM | Blog, Cafe, News, Comments, KiN, Modu, WikiEn, WikiJp, Others | 561 B |
| GLaM [37] | Sparse/MoE Decoder-only | LM | Web Pages, Wikipedia, Forums, Books, News, Conversations | 1.6 T tokens, |
| ERNIE 3.0 [38] | Transformer-XL structure | UKTP | plain texts and a large-scale knowledge graph | 375 billion, 4 TB |
| Gopher [39] | Decoder-only | LM | MassiveText (MassiveWeb, Books, C4, News, GitHub, Wikipedia) | 300 B |
| Chinchilla [40] | - | - | MassiveText | 1.4 T |
| AlphaCode [41] | encoder–decoder | MLM, LM | Github, CodeContests | 967 B |
| CodeGEN [42] | decoder-only | LM | THEPILE, BIGQUERY, and BIGPYTHON | 505.5 B |
| CodeGeeX [43] | decoder-only | LM | The Pile, CodeParrot Collected | 850 B |
| FLAN [44] | Decoder-only | LM | web documents, dialog data, and Wikipedia | 2.49 T tokens, |
| InstructGPT [45] | Decoder-only | LTR-LM | Common Crawl, WebText, English-Wikipedia, Books1, Books2, Prompt Dataset (SFT, RM, PPO) | 300 B, 570 GB |
| LaMDA [46] | Decoder-Only | LM | public dialog data and web text | 168 B (2.97 B documents, 1.12 B dialogs, and 13.39 B) 1.56T words, - |
| T0 [47] | encoder–decoder | MLM + LM | C4 | 1T tokens + 100 B |
| GPT NeoX 20 B [48] | Decoder-only | LM | The Pile | - 825 GB |
| OPT [49] | Decoder-only | - | BookCorpus, Stories, the Pile, and PushShift.io Reddit | 180 B tokens |
| MINERVA [50] | Decoder-only + Parallel Layers | LM | technical content dataset (containing scientific and mathematical data), questions from MIT’s OpenCourseWare, in addition to PaLM pretraining dataset | 38.5 B tokens (math content), |
| AlexaTM 20 B [51] | seq2seq (encoder–decoder) | mix of denoising and Causal language modeling (CLM) tasks | Wikipedia and mC4 datasets | 1 Trillion tokens, - |
| GLM-130 B [52] | bidirectional encoder and unidirectional decoder, | GLM, MIP (Multitask Instruction pretraining) | 400 billion tokens, | |
| XGLM [53] | decoder-only | Causal LM | CC100-XL | |
| PaLM [54] | Decoder-only + Parallel Layers | LM | Social media conversations, Filtered webpages, Wikipedia (multilingual), Books, Github, News (English) | 780 B tokens, |
| Galactica [55] | decoder-only | - | papers, code, reference material, knowledge bases, filtered CommonCrawl, prompts, GSM8k, OneSmallStep, Khan Problems, Workout, Other | 106 B |
| Pali [56] | encoder–decoder and Vision Transformers | mixture of 8 pretraining tasks | WebLI (10 B images and texts in over 100 languages), 29 billion image-OCR pairs | - |
| LLaMA [57] | transformer | LM | CommonCrawl, C4, Github, Wikipedia, Books, ArXiv, StackExchange | 1.4 T tokens, |
| UL2 [58] | Enc–Dec, decoder-Only Prefix-LM | R, S, X denoising | C4 | 32 B tokens, |
| Pythia [59] | decoder-only | LM | the Pile | 300 B tokens - |
| WeLM [60] | - | - | Common Crawl, news, books, forums, academic writings. | - |
| BLOOM [22] | Causal Decoder-only | LM | ROOTS corpus (46 natural languages and 13 programming languages) | 366 B, 1.61 TB |
| GLM [61] | bidirectional encoder and unidirectional decoder | GLM | ||
| GPT-J | Mesh Transformer JAX | LM | PILE | 402 B |
| YaLM | online texts, The Pile, books, other resources (in English, Russian) | 1.7 TB | ||
| Alpaca | ||||
| Falcon | encoder-only | LM | RefinedWeb, Reddit | 1T |
| (Xmer) XXXL [62] | encoder–decoder | MLM | C4 | 1T tokens |
| [63] | decoder-only (MoE) | LM | BookCorpus, English Wikipedia, CC-News, OpenWebText, CC-Stories, CC100 | 300 B |
| XLM-R [64] | encoder-only | Multilingual MLM | CommonCrawl (CC-100) | 2.5 TB |
| Model | PT, FT Batch-Size | Context Size | PT, FT Epochs | Activation, Optimizer | Finetuning Methods |
|---|---|---|---|---|---|
| Transformer-base [24] | - | - | 100,000 | ||
| Transformer-big [24] | - | - | 300,000 | -, Adam | Feature-based |
| BERT-base [26] | 256, 32 | 128, 512 | 40, 4 | ||
| BERT-large [26] | 256, 32 | 128, 512 | 40, 4 | GELU, Adam | FT |
| GPT-1 [27] | 64 | 512 | 100 | GELU, Adam | FT, zero-shot |
| GPT-2 [28] | 512 | 1024 | - | GELU, Adam | zero-shot |
| GPT-3 [29] | 3.2M | 2048 | - | - | few-shot, one-shot, zero-shot |
| T5 [25] | 128, 128 | 512 | , steps | RELU, AdaFactor | FT |
| REALM [30] | 512, 1 | - | 200 k steps, 2 epochs | - | - |
| Jurassic-1 [31] | 3.2 M tokens | 2048 | - | - | few-shot, zero-shot |
| mT5 [32] | - | - | - | GeGLU, | FT, zero-shot |
| Pangu-Alpha [33] | - | 1024 | 130 K 260 K | GeLU | few-shot, one-shot, zero-shot |
| CPM-2 [34] | - | - | - | - | FT, PT |
| Yuan 1.0 [35] | - | - | - | - | few-shot, zero-shot |
| HyperClova [36] | 1024,- | - | - | -, AdamW | few-shot, zero-shot, PT |
| GLaM [37] | - | 1024 | - | -, Adafactor | zero-, one-, and few-shot |
| ERNIE 3.0 [38] | 6144 | 512 | - | GeLU, Adam | FT, zero- and few-shot |
| Gopher [39] | - | 2048 | - | Adam | FT, few-shot, zero-shot |
| Chinchilla [40] | - | - | - | AdamW | FT, zero-shot |
| AlphaCode [41] | 2048 | - | 205 K | - | finetuning |
| CodeGEN [42] | 2 M | 2048 | - | - | zero-shot |
| CodeGeeX [43] | 3072 | - | - | FastGELU, Adam | finetuning |
| FLAN [44] | -, 8192 | 1024 | 30 K | -, Adafactor | Instruction Tuning, zero-shot |
| InstructGPT [45] | 3.2 M | 2048 | - | - | RLHF |
| LaMDA [46] | - | - | - | gated-GELU, | FT |
| T0 [47] | - | - | - | RELU, AdaFactor | FT, zero-shot |
| GPT NeoX 20B [48] | 3.15 M tokens | 2048 | 150 K steps | -, AdamW with ZeRO | few-shot |
| OPT [49] | 2 M tokens | 2048 | - | ReLU, AdamW | few-shot, zero-shot |
| MINERVA [50] | - | 1024 | 399 K | SwiGLU, Adafactor | few-shot, chain-of-thought context |
| AlexaTM 20 B [51] | 2 million tokens | - | - | Adam | Finetuning, few-shot, one-shot, zero-shot |
| GLM-130 B [52] | 4224 | 2048 | - | GeGLU, | zero-shot, few (5) shots |
| XGLM [53] | |||||
| PaLM [54] | 512, 1024, 2048 (1, 2, 4 M tokens), - | 2048 | 1 (255 k steps) | SwiGLU, Adafactor | few-shot, chain-of-thought, finetuning |
| Galactica [55] | 2 M | 2048 | 4 epochs | GeLU | zero-shot |
| Pali [56] | - | - | - | ||
| LLaMA [57] | 4 M tokens | - | - | SwiGLU, AdamW | zero-shot, few-shot, Instruction Tuning |
| UL2 [58] | 128 | 512 | 500 K steps | SwiGLU, Adafactor | in-context learning, zero-shot, one-shot, finetuning, instruction tuning |
| Pythia [59] | 1024 | 2048 | 1.5 Epochs | Adam | zero-shot |
| WeLM [60] | 2048 | 2048 | - | - | zero-shot, few-shot |
| BLOOM [22] | 20,482,048 | 2048 | - | GELU, - | zero-shot, few-shot, multitask-prompted (fine)-tuning |
| GLM [61] | 1024 | 200 K Steps | FT | ||
| GPT-J | 2048 | 383,500 steps | - | FT | |
| YaLM | |||||
| Alpaca | - | - | FT, IT (instruction Tuning) | ||
| Falcon | - | 2048 | - | - | - |
| (Xmer) XXXL [62] | FT | ||||
| [63] | 2048 | FT, zero-shot, few-shot |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Patil, R.; Gudivada, V. A Review of Current Trends, Techniques, and Challenges in Large Language Models (LLMs). Appl. Sci. 2024, 14, 2074. https://doi.org/10.3390/app14052074
Patil R, Gudivada V. A Review of Current Trends, Techniques, and Challenges in Large Language Models (LLMs). Applied Sciences. 2024; 14(5):2074. https://doi.org/10.3390/app14052074
Chicago/Turabian StylePatil, Rajvardhan, and Venkat Gudivada. 2024. "A Review of Current Trends, Techniques, and Challenges in Large Language Models (LLMs)" Applied Sciences 14, no. 5: 2074. https://doi.org/10.3390/app14052074
APA StylePatil, R., & Gudivada, V. (2024). A Review of Current Trends, Techniques, and Challenges in Large Language Models (LLMs). Applied Sciences, 14(5), 2074. https://doi.org/10.3390/app14052074