
Face De-Identification Using Convolutional Neural Network (CNN) Models for Visual-Copy Detection


Abstract
1. Introduction
2. Related Work
2.1. De-Identification
2.2. Image-Generation Method
2.3. Visual-Copy Detection
3. Proposed Methods
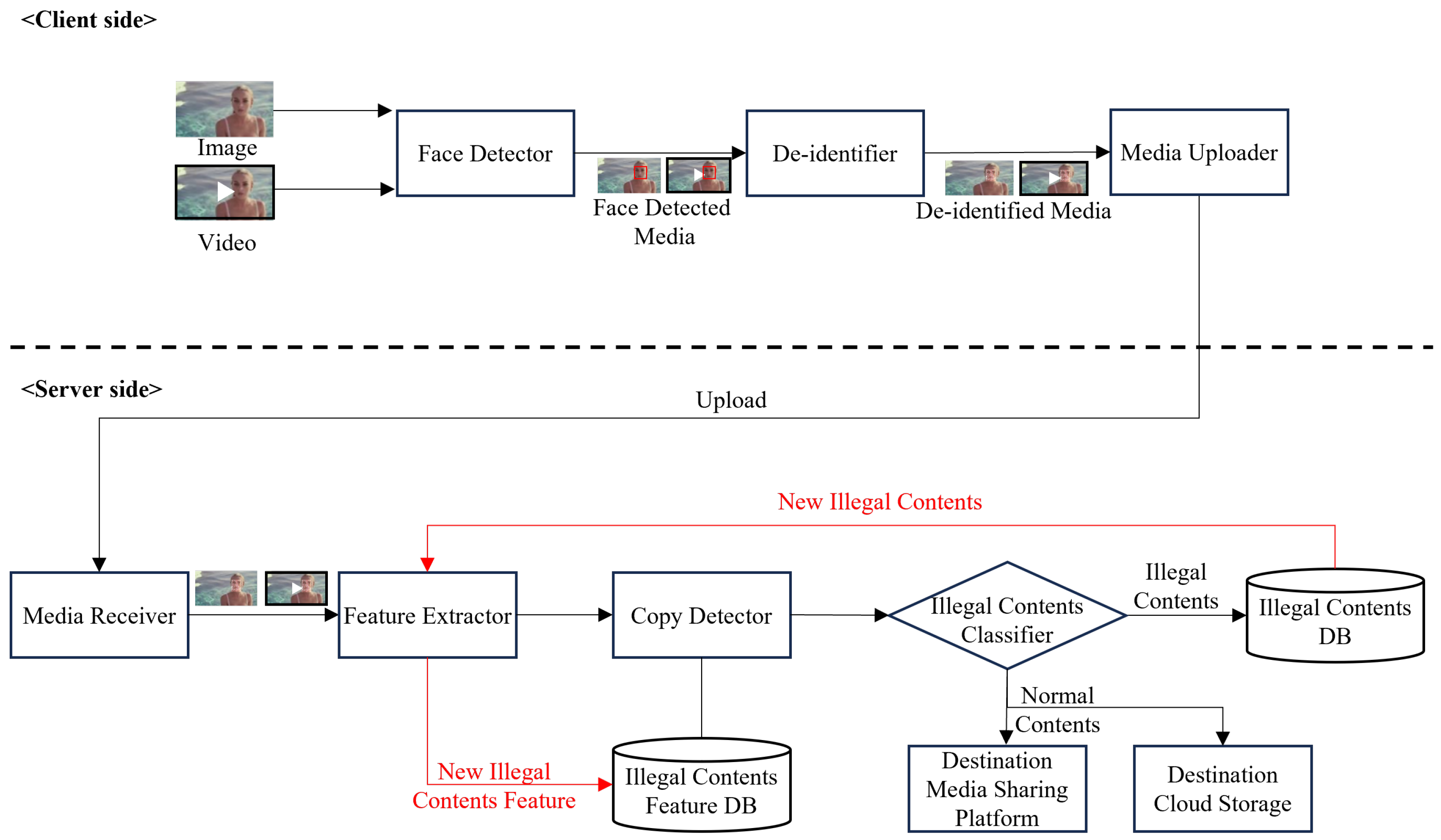
3.1. Application Scenarios of the Proposed Models
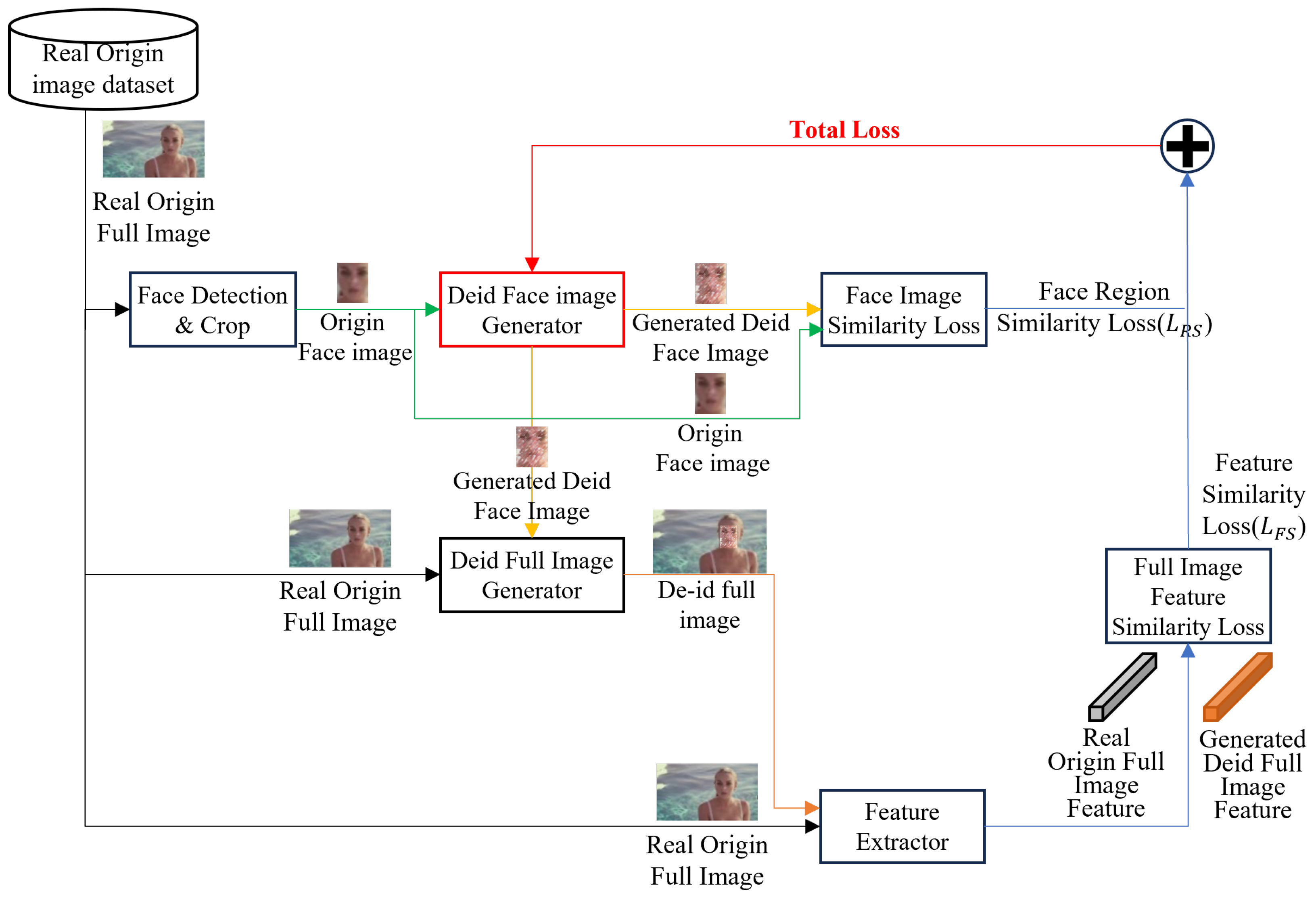
3.2. Face De-Identification Model Using Feature Inversion
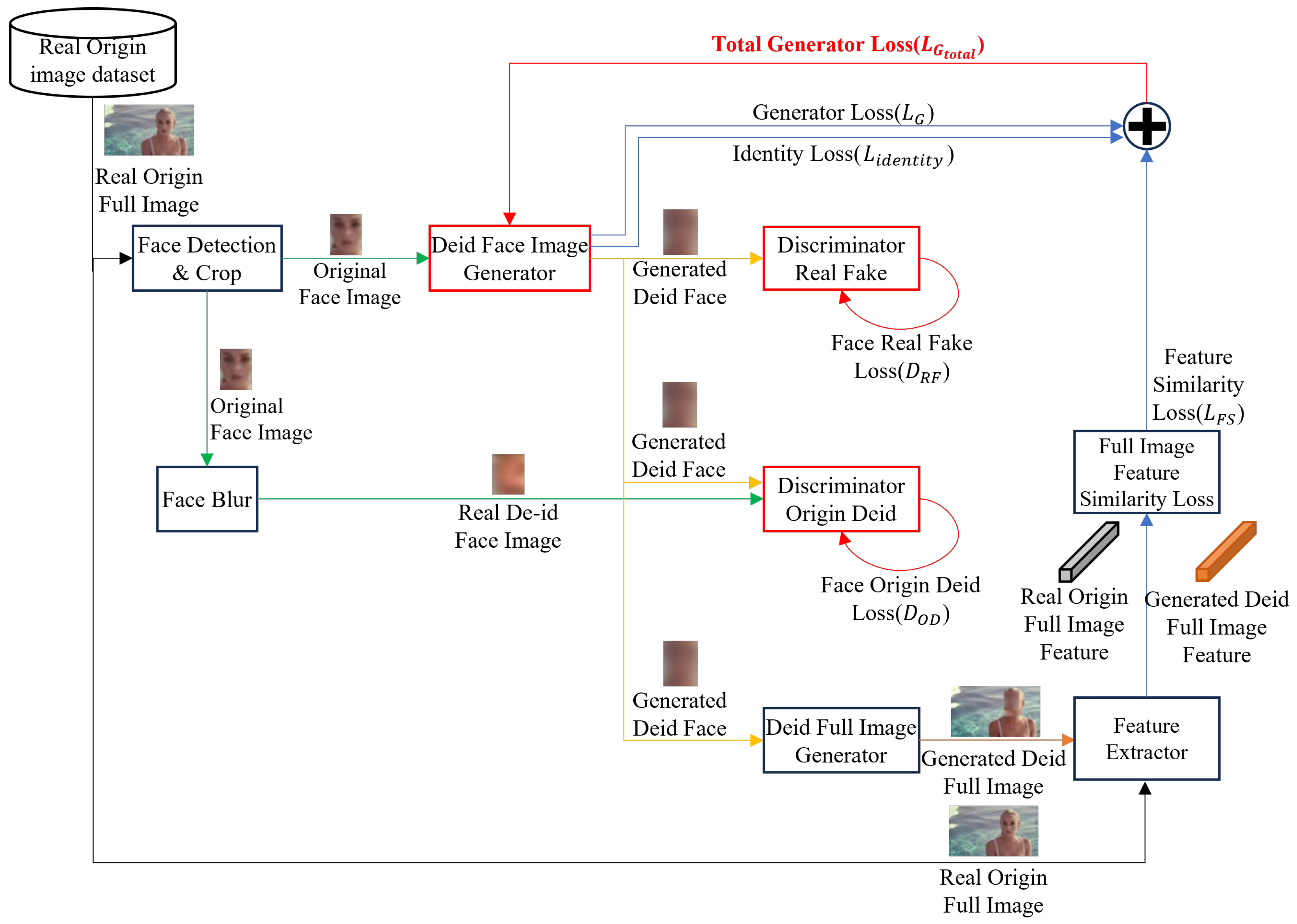
3.3. Face-De-Identification Model using D2GAN
4. Experiments
4.1. Dataset
4.2. Evaluation Metrics
4.3. Face Verification and Feature Similarity
4.4. Evaluation on Image- and Video-Copy-Detection Tasks
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| GAN | Generative Adversarial Network |
| D2GAN | Dual Discriminator Generative Adversarial Network |
| StyleGAN | Style Generative Adversarial Network |
| ResNet | Residual Network |
| SSIM | Structural Similarity Index Measure |
| PSNR | Peak Signal-to-Noise Ratio |
| BCE | Binary Cross-Entropy |
| Mean Average Precision |
| Micro Average Precision | |
| Accuracy at 1 | |
| Recall at Precision 90 |
References
- Ribaric, S.; Ariyaeeinia, A.; Pavesic, N. De-identification for privacy protection in multimedia content: A survey. Signal Process. Image Commun. 2016, 47, 131–151. [Google Scholar] [CrossRef]
- Agrawal, P.; Narayanan, P. Person de-identification in videos. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 299–310. [Google Scholar] [CrossRef]
- Ivasic-Kos, M.; Iosifidis, A.; Tefas, A.; Pitas, I. Person de-identification in activity videos. In Proceedings of the 2014 37th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 26–30 May 2014; pp. 1294–1299. [Google Scholar]
- Dufaux, F.; Ebrahimi, T. Scrambling for privacy protection in video surveillance systems. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1168–1174. [Google Scholar] [CrossRef]
- Dufaux, F.; Ebrahimi, T. A framework for the validation of privacy protection solutions in video surveillance. In Proceedings of the 2010 IEEE International Conference on Multimedia and Expo, Singapore, 19–23 July 2010; pp. 66–71. [Google Scholar]
- Mahendran, A.; Vedaldi, A. Understanding deep image representations by inverting them. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5188–5196. [Google Scholar]
- Dosovitskiy, A.; Brox, T. Inverting visual representations with convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4829–4837. [Google Scholar]
- Nguyen, T.; Le, T.; Vu, H.; Phung, D. Dual discriminator generative adversarial nets. arXiv 2017, arXiv:1709.03831. [Google Scholar]
- Xue, H.; Liu, B.; Yuan, X.; Ding, M.; Zhu, T. Face image de-identification by feature space adversarial perturbation. Concurr. Comput. Pract. Exp. 2023, 35, e7554. [Google Scholar] [CrossRef]
- Wen, Y.; Liu, B.; Cao, J.; Xie, R.; Song, L. Divide and Conquer: A Two-Step Method for High Quality Face De-identification with Model Explainability. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 5148–5157. [Google Scholar]
- Li, D.; Wang, W.; Zhao, K.; Dong, J.; Tan, T. RiDDLE: Reversible and Diversified De-identification with Latent Encryptor. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 8093–8102. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Pan, Y.L.; Chen, J.C.; Wu, J.L. Towards a Controllable and Reversible Privacy Protection System for Facial Images through Enhanced Multi-Factor Modifier Networks. Entropy 2023, 25, 272. [Google Scholar] [CrossRef] [PubMed]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Li, Y.; Lyu, S. De-identification without losing faces. In Proceedings of the ACM Workshop on Information Hiding and Multimedia Security, Paris, France, 3–5 July 2019; pp. 83–88. [Google Scholar]
- Khorzooghi, S.M.S.M.; Nilizadeh, S. StyleGAN as a Utility-Preserving Face De-identification Method. arXiv 2022, arXiv:2212.02611. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Yang, X.; Dong, Y.; Pang, T.; Su, H.; Zhu, J.; Chen, Y.; Xue, H. Towards face encryption by generating adversarial identity masks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3897–3907. [Google Scholar]
- Uchida, H.; Abe, N.; Yamada, S. DeDiM: De-identification using a diffusion model. In Proceedings of the 2022 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 14–16 September 2022; pp. 1–5. [Google Scholar]
- Shibata, H.; Hanaoka, S.; Cao, Y.; Yoshikawa, M.; Takenaga, T.; Nomura, Y.; Hayashi, N.; Abe, O. Local differential privacy image generation using flow-based deep generative models. Appl. Sci. 2023, 13, 10132. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Zhou, T.; Li, Q.; Lu, H.; Zhang, X.; Cheng, Q. Hybrid multimodal medical image fusion method based on LatLRR and ED-D2GAN. Appl. Sci. 2022, 12, 12758. [Google Scholar] [CrossRef]
- Fu, G.; Zhang, Y.; Wang, Y. Image Copy-Move Forgery Detection Based on Fused Features and Density Clustering. Appl. Sci. 2023, 13, 7528. [Google Scholar] [CrossRef]
- Pizzi, E.; Roy, S.D.; Ravindra, S.N.; Goyal, P.; Douze, M. A self-supervised descriptor for image copy detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14532–14542. [Google Scholar]
- Kordopatis-Zilos, G.; Tzelepis, C.; Papadopoulos, S.; Kompatsiaris, I.; Patras, I. DnS: Distill-and-select for efficient and accurate video indexing and retrieval. Int. J. Comput. Vis. 2022, 130, 2385–2407. [Google Scholar] [CrossRef]
- Kordopatis-Zilos, G.; Tolias, G.; Tzelepis, C.; Kompatsiaris, I.; Patras, I.; Papadopoulos, S. Self-Supervised Video Similarity Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 4755–4765. [Google Scholar]
- Qi, D. yolov7-Face. Available online: https://github.com/derronqi/yolov7-face (accessed on 7 November 2023).
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. Wider face: A face detection benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5525–5533. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. Vggface2: A dataset for recognising faces across pose and age. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Douze, M.; Jégou, H.; Sandhawalia, H.; Amsaleg, L.; Schmid, C. Evaluation of gist descriptors for web-scale image search. In Proceedings of the ACM International Conference on Image and Video Retrieval, Fira, Greece, 8–10 July 2009; pp. 1–8. [Google Scholar]
- Jiang, Y.G.; Jiang, Y.; Wang, J. VCDB: A large-scale database for partial copy detection in videos. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part IV 13. Springer: Cham, Switzerland, 2014; pp. 357–371. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Dataset | Widerface [29] | VGGFace2 -HQ [30] | FFHQ [17] | CelebA-HQ [31] |
|---|---|---|---|---|
| Number of Images | 30,250 | 113,758 | 70,000 | 202,599 |
| Number of Identities | - | 903 | - | 10,177 |
| Number of Faces | 140,040 | 151,108 | 139,000 | 231,560 |
| Avg Number of Faces per Image | 4.63 | 1.33 | 1.99 | 1.14 |
| Proportion of Face Region in Images | Dataset | ||||
|---|---|---|---|---|---|
| Widerface [29] | VGGFace2 -HQ [30] | FFHQ [17] | CelebA -HQ [31] | Ours | |
| 0–10% | 27,035 | 20 | 32,134 | 72,357 | 20,534 |
| 10–30% | 3129 | 2566 | 37,038 | 110,611 | 20,511 |
| 30–50% | 72 | 50,104 | 811 | 19,120 | 22,009 |
| 50–70% | 4 | 46,077 | 17 | 497 | 22,007 |
| 70–100% | 0 | 14,989 | 0 | 14 | 15,003 |
| Total | 25,237 | 113,756 | 70,000 | 202,599 | 100,064 |
| Category | Detail | Dataset | |
|---|---|---|---|
| DISC21 [24] | CopyDays [32] | ||
| Number of Images | Dev Query | 50,000 | 1000 |
| Test Query | 50,000 | - | |
| Reference | 1,000,000 | 3212 | |
| Train | 1,000,000 | 1000 | |
| Number of Images Containing Faces | Dev Query | 3369 | 58 |
| Test Query | 2925 | - | |
| Reference | 86,539 | 332 | |
| Train | 80,645 | 65 | |
| Resolution | Range # of Varieties | 32 × 32–1024 × 1024 10,860 distinct | 56 × 72–3008 × 2000 1071 distinct |
| Category | Detail | Value |
|---|---|---|
| Number of Videos | Core Videos Background Videos | 528 100,000 |
| Number of Videos Containing Faces | Core Videos Background Videos | 528 97,429 |
| Length | Max Length of Video Min Length of Video Avg Length of Video | 2662 s 3 s 183.63 s |
| Resolution | Range Number of Varieties | 320 × 214–1920 × 1080 43 distinct |
| Task (Feature Extractor) | Metric | SSIM | PSNR | Feature Similarity | |||||
|---|---|---|---|---|---|---|---|---|---|
| Feature Inversion | D2GAN | Feature Inversion | D2GAN | Feature Inversion | D2GAN | ||||
| Image- Copy Detection (SSCD ResNet50) | 0–10% 10–30% 30–50% 50–70% 70–100% | 0.0950 0.0881 0.0866 0.0736 0.0810 | 0.4266 0.3860 0.3708 0.3830 0.3831 | 7.6847 7.3589 6.9805 6.1259 6.0036 | 9.4259 9.4587 9.2420 9.1317 7.2015 | 0.9995 0.9997 0.9977 0.9947 0.9937 | 0.9994 0.9965 0.9937 0.9931 0.9998 | ||
| Total | 0.0941 | 0.4218 | 7.6439 | 9.4282 | 0.9976 | 0.9991 | |||
| Video- Copy Detection (S2VS ResNet50) | 0–10% 10–30% 30–50% 50–70% 70–100% | 0.0259 0.0237 0.0229 0.0232 0.0264 | 0.4273 0.4156 0.4070 0.4164 0.4377 | 7.7064 7.3543 7.2664 7.1750 7.6666 | 9.3651 9.3787 9.3218 9.3070 9.8981 | 0.9993 0.9908 0.9733 0.9668 0.9890 | 0.9996 0.9973 0.9937 0.9923 0.9874 | ||
| Total | 0.0255 | 0.4253 | 7.6492 | 9.3663 | 0.9876 | 0.9892 | |||
| Dataset | Type | 0–10% | 10–30% | 30–50% | 50–70% | 70–100% |
|---|---|---|---|---|---|---|
| Widerface [29] | Original Image |  |  |  |  |  |
| Feature Inversion |  |  |  |  |  | |
| D2GAN |  |  |  |  |  | |
| DISC21 [24] | Original Image |  |  |  |  |  |
| Feature Inversion |  |  |  |  |  | |
| D2GAN |  |  |  |  |  | |
| VCDB [33] | Original Image |  |  |  |  |  |
| Feature Inversion |  |  |  |  |  | |
| D2GAN |  |  |  |  |  |
| Dataset | Method | Total | Only Face | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| DISC21 [24] | SSCD | - | 72.5 | 78.2 | 63.1 | - | 54.7 | 68.3 | 37.1 | |
| Ours (Feature Inversion) | - | 71.2 | 77.8 | 62.9 | - | 54.3 | 67.9 | 36.9 | ||
| Ours (D2GAN) | - | 71.3 | 78.1 | 62.7 | - | 54.5 | 68.0 | 36.5 | ||
| CopyDays [32] | SSCD | 86.6 | 98.1 | - | - | 90.9 | 97.9 | - | - | |
| Ours (Feature Inversion) | 86.1 | 97.5 | - | - | 89.8 | 96.8 | - | - | ||
| Ours (D2GAN) | 85.9 | 97.9 | - | - | 90.1 | 97.2 | - | - | ||
| Dataset | Method | Total | Only Face | |||
|---|---|---|---|---|---|---|
| VCDB [33] | S2VS | 87.9 | 73.0 | 87.9 | 73.0 | |
| Ours (Feature Inversion) | 87.5 | 72.2 | 87.5 | 72.2 | ||
| Ours (D2GAN) | 87.3 | 72.4 | 87.3 | 72.4 | ||
| DnS | 87.9 | 74.0 | 87.9 | 74.0 | ||
| Ours (Feature Inversion) | 86.5 | 71.8 | 86.5 | 71.8 | ||
| Ours (D2GAN) | 87.1 | 72.1 | 87.1 | 72.1 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, J.; Kim, J.; Nang, J. Face De-Identification Using Convolutional Neural Network (CNN) Models for Visual-Copy Detection. Appl. Sci. 2024, 14, 1771. https://doi.org/10.3390/app14051771
Song J, Kim J, Nang J. Face De-Identification Using Convolutional Neural Network (CNN) Models for Visual-Copy Detection. Applied Sciences. 2024; 14(5):1771. https://doi.org/10.3390/app14051771
Chicago/Turabian StyleSong, Jinha, Juntae Kim, and Jongho Nang. 2024. "Face De-Identification Using Convolutional Neural Network (CNN) Models for Visual-Copy Detection" Applied Sciences 14, no. 5: 1771. https://doi.org/10.3390/app14051771
APA StyleSong, J., Kim, J., & Nang, J. (2024). Face De-Identification Using Convolutional Neural Network (CNN) Models for Visual-Copy Detection. Applied Sciences, 14(5), 1771. https://doi.org/10.3390/app14051771