
Multi-Identity Recognition of Darknet Vendors Based on Metric Learning



Abstract
1. Introduction
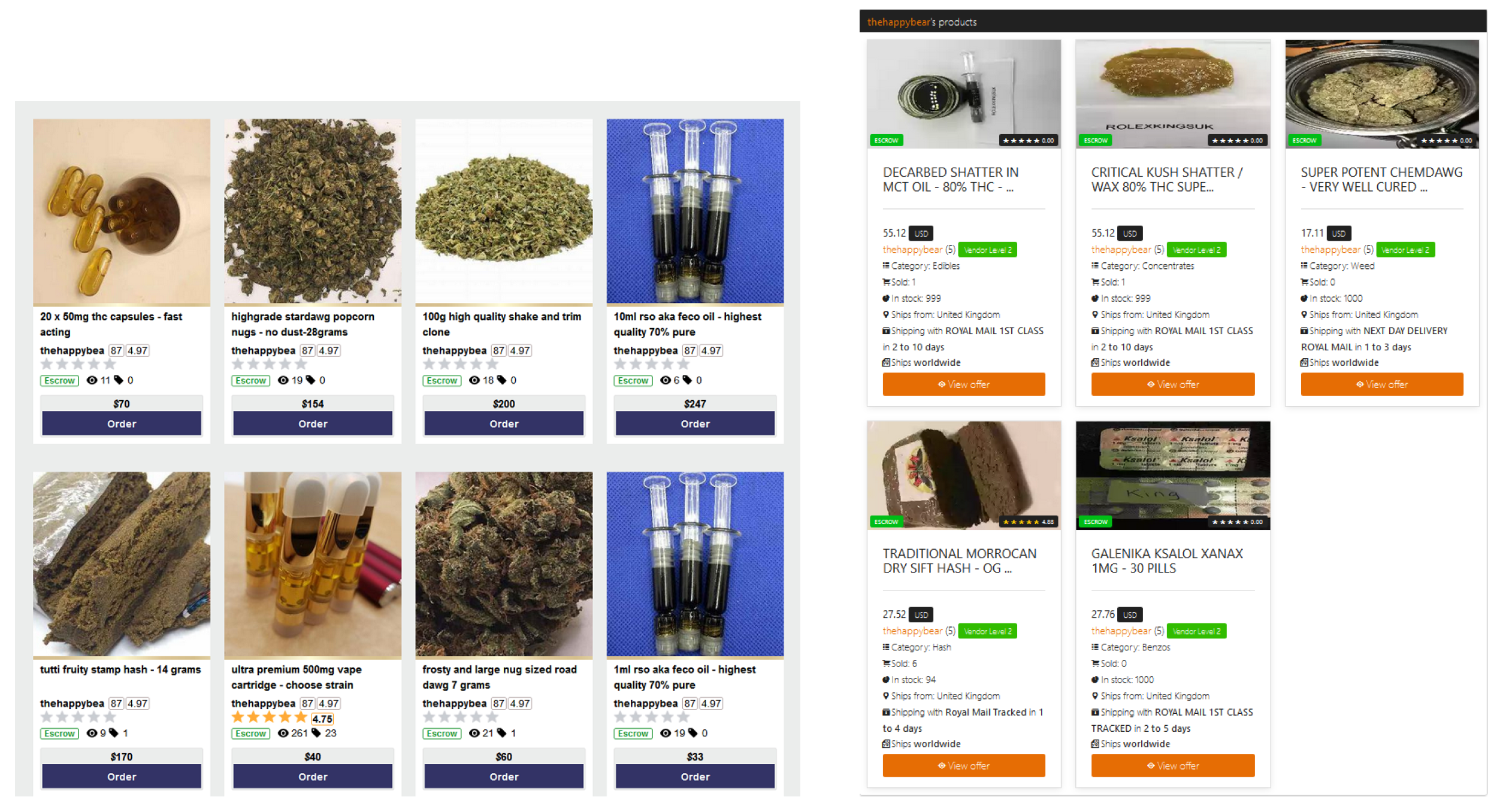
- We collected product data from 21 currently active English dark web marketplaces through a web crawler system and propose a multi-dimensional feature extraction method based on product titles, descriptions, and images, which can comprehensively represent dark web marketplace products.
- We combined pseudo-labeling technology with manual labeling to improve the accuracy of data labeling.
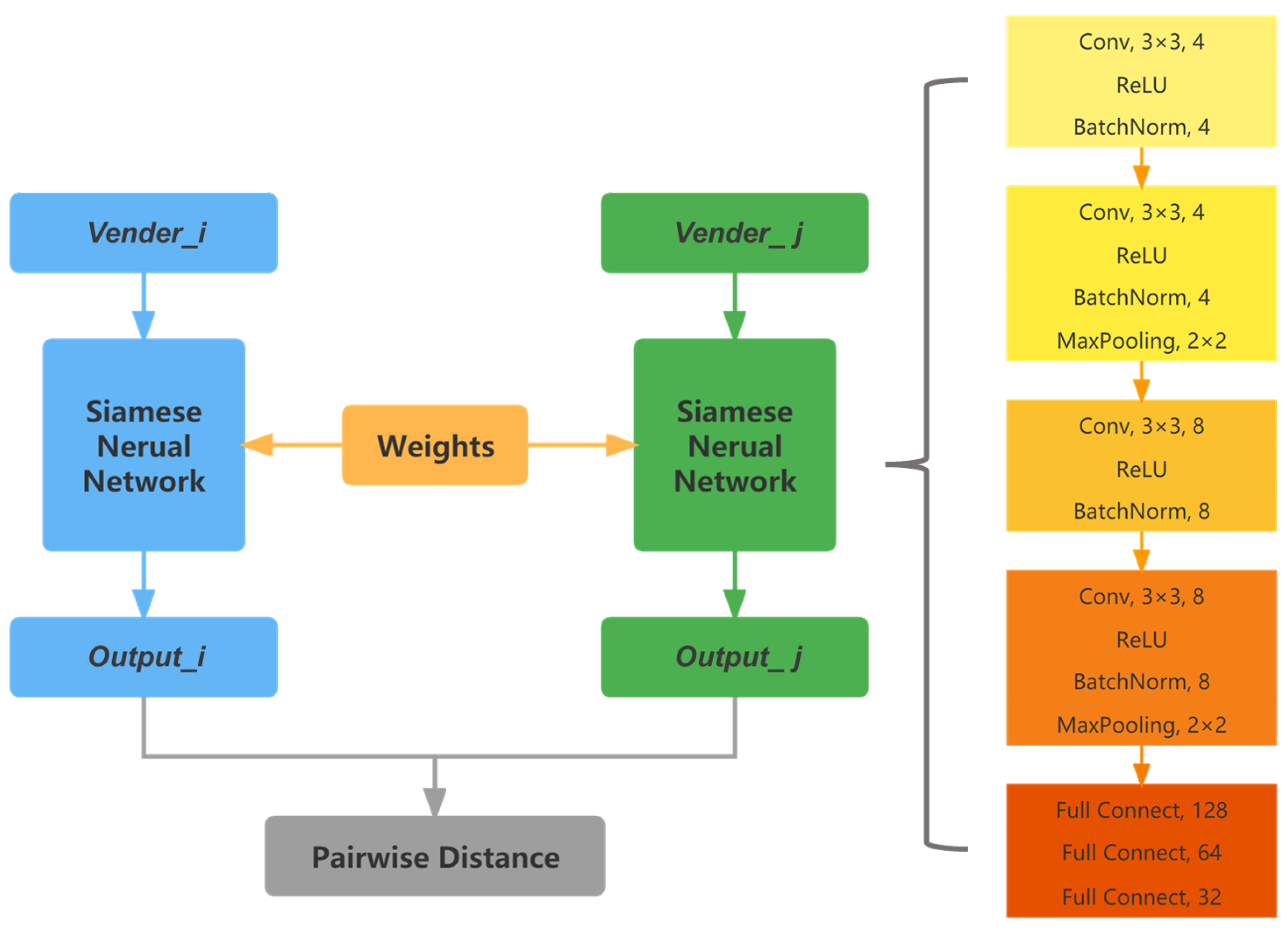
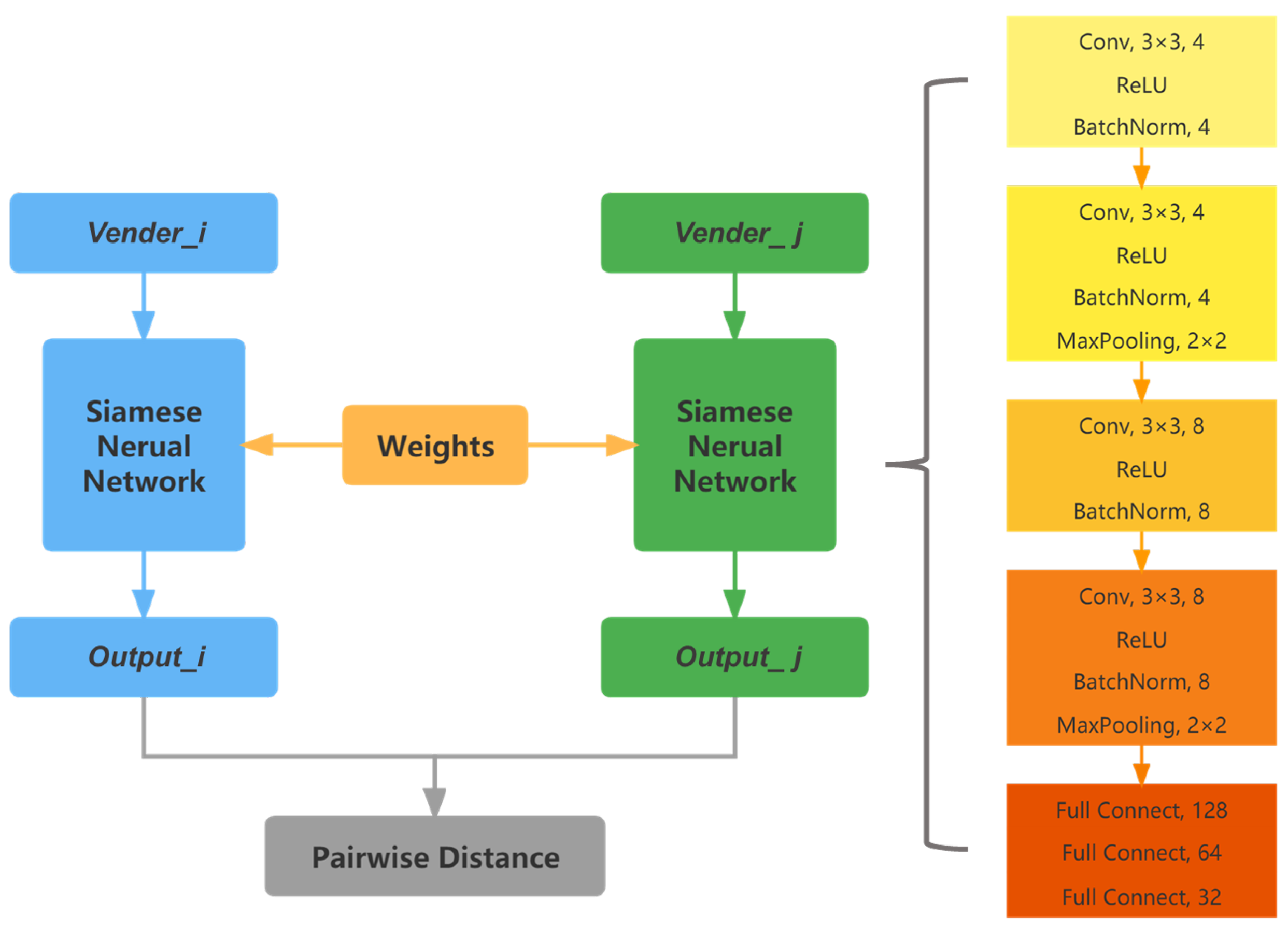
- We propose to use a Siamese neural network with metric learning to learn the similarity between vendors and achieve the identification of vendors’ multiple identities.
2. Related Works
2.1. Multi-Identity Recognition
2.2. Features of Classification
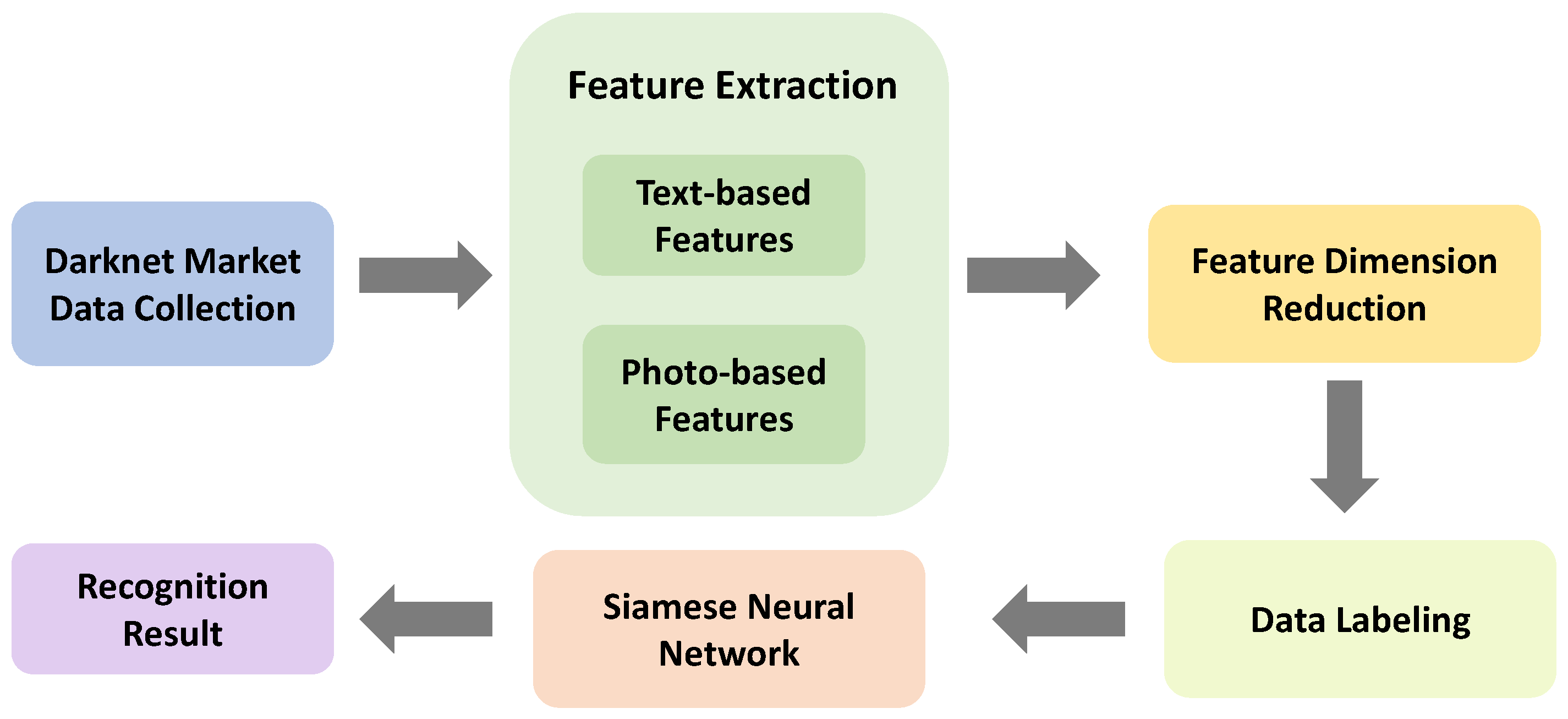
3. Research Design
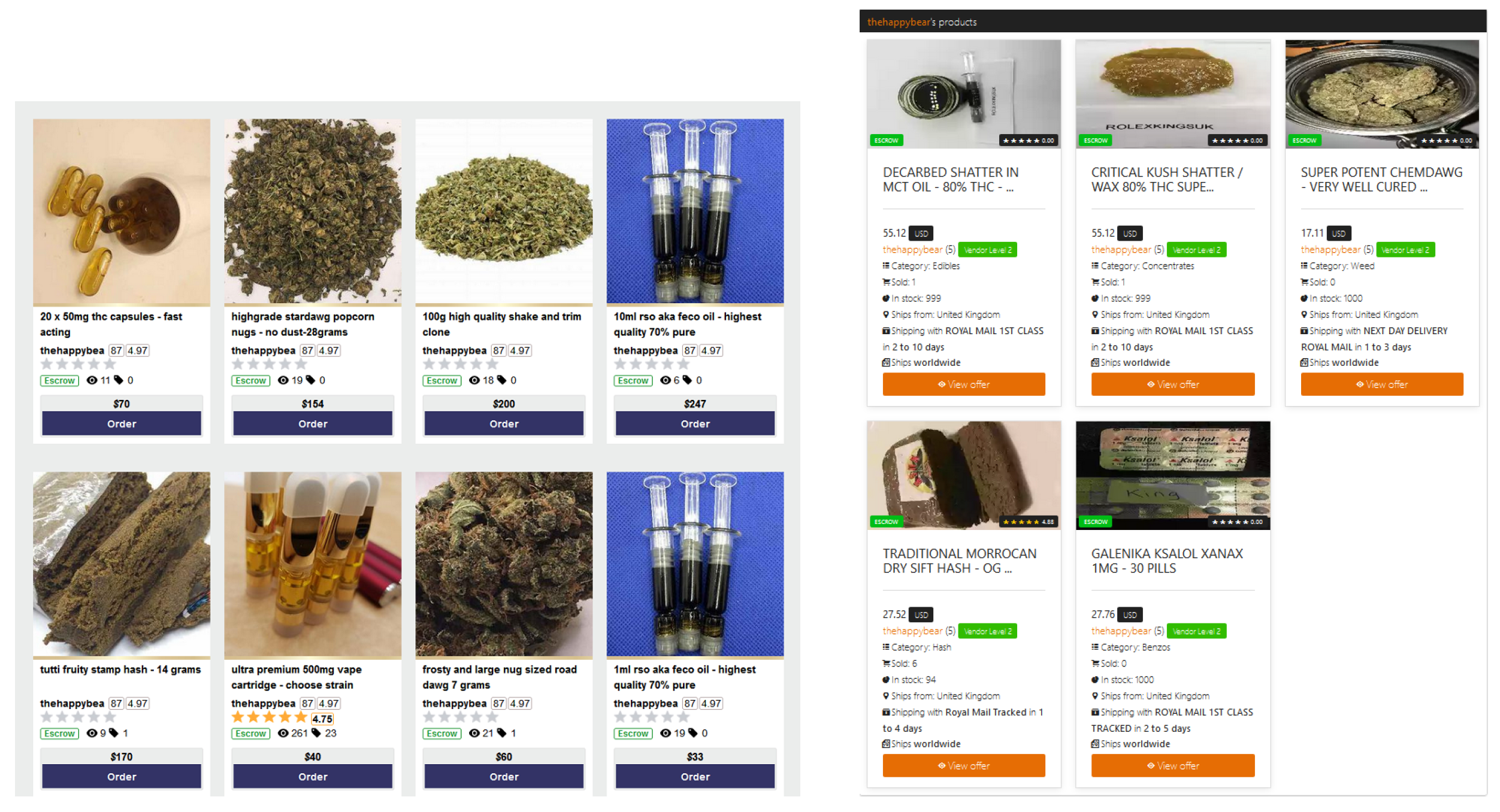
3.1. The Dataset
- There were duplicate items in the same market, which referred to items with the same name, description, vendor name, and category. These items increased the training time of the model but did not help the model converge. Additionally, some market item names could end in “Clone”, and these items also needed to be deduplicated.
- The shipping origin of each market was not uniform. For example, some products had the United States as the shipping origin, and some markets were set to USA, US, U.S.A, United States, etc. These shipping origins were standardized to USA.
- The categories were not uniform. For example, cannabis drugs were defined as cannabis in some markets and hashish in others.
3.2. Feature Extraction
3.2.1. Text-Based Features
BERT [13]
Doc2Vec [20]
Writing-StyleFeatures
3.2.2. Photo-Based Features
3.2.3. Feature Dimension Reduction
3.3. Metric Learning
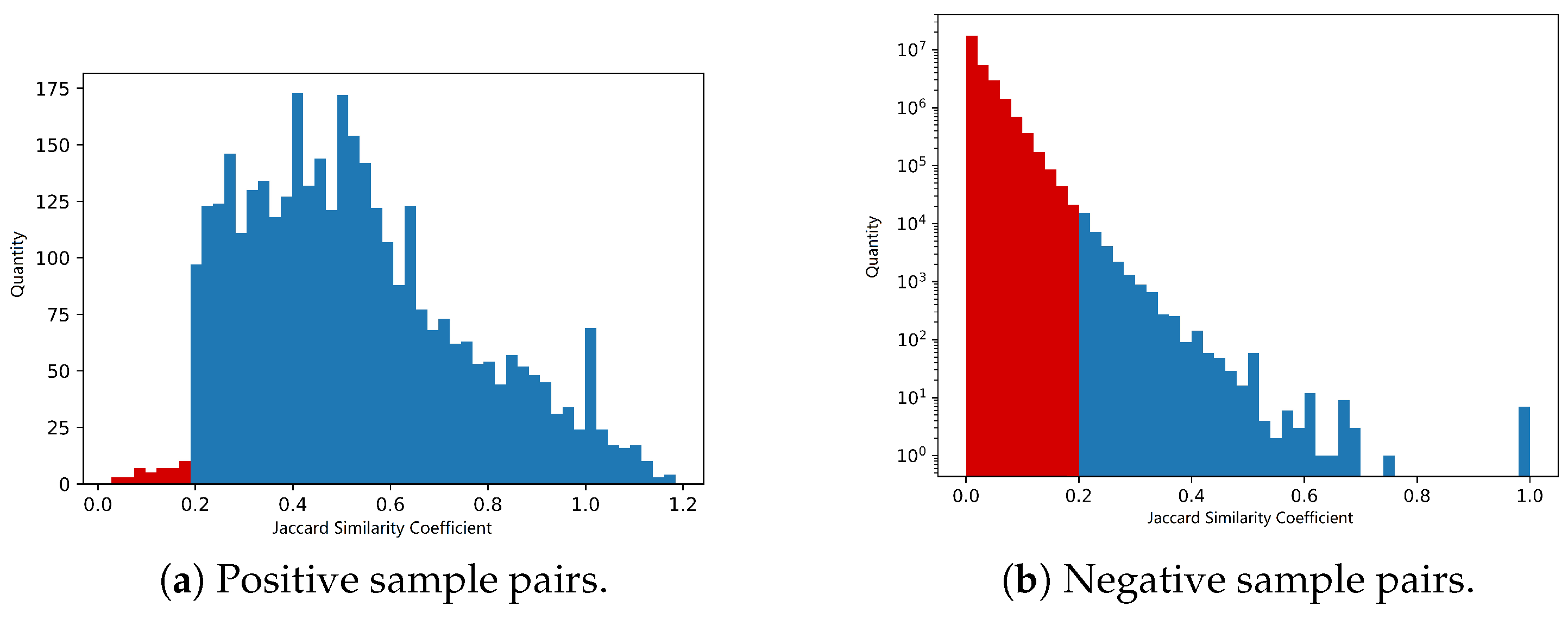
3.3.1. Data Labeling
| Algorithm 1 Pseudo-labeling algorithm. |
Input: ▹ Vendor features, n is the number of vendors, d is the number of feature dimensions; ▹ Vendor sample pairs, p is the number of sample pairs; ▹ Vendor sample pairs’ label; C ▹ Number of epochs Output ▹ New vendor sample pairs’ label;
|
3.3.2. Model Architecture
4. Evaluation
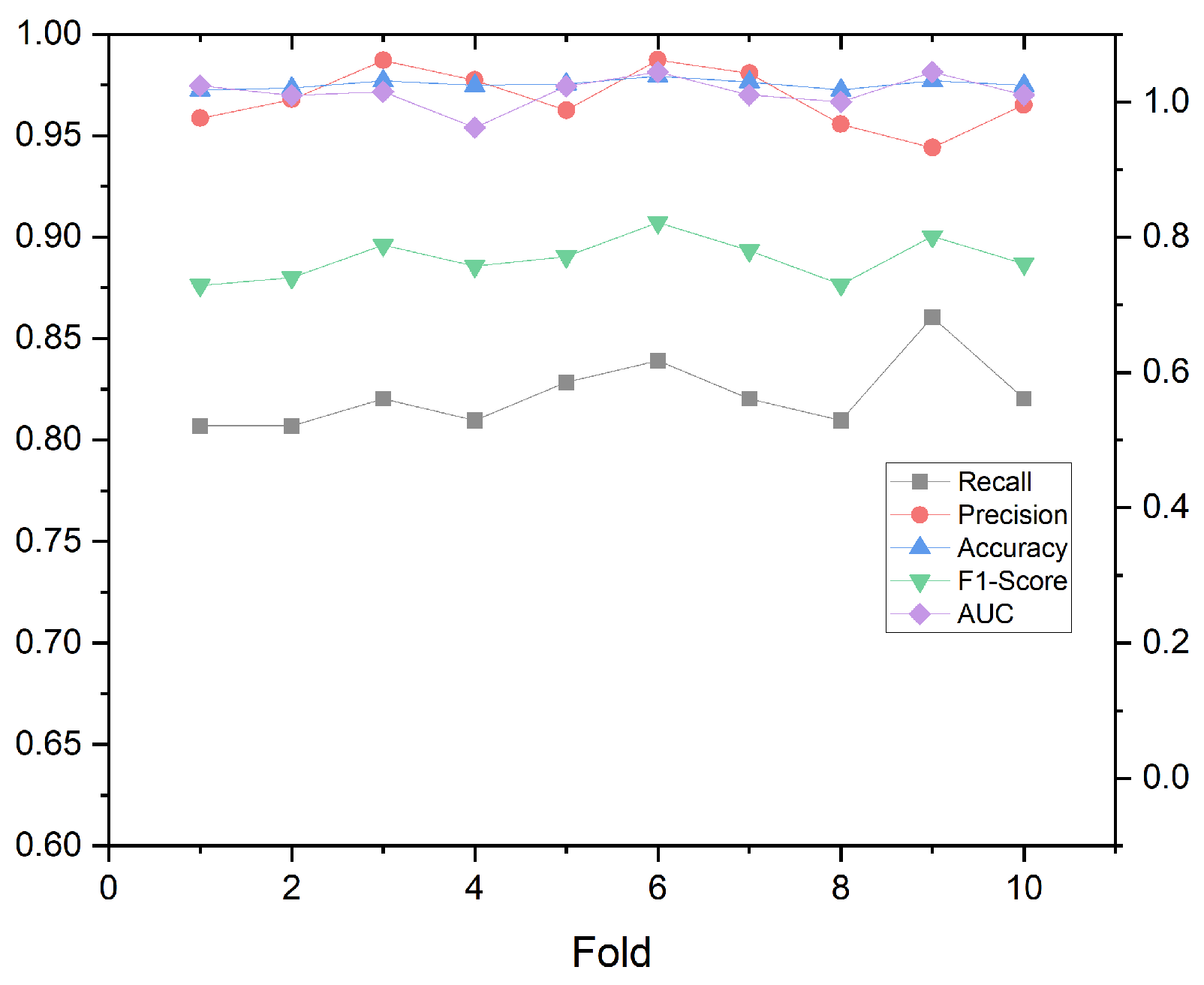
- We employed a tenfold cross-validation to more comprehensively evaluate the model’s performance and reduce errors caused by sample set partitioning. In other words, the sample set was divided into ten parts, and ten models were trained with a training-to-test ratio of 9:1 to obtain ten evaluation results.
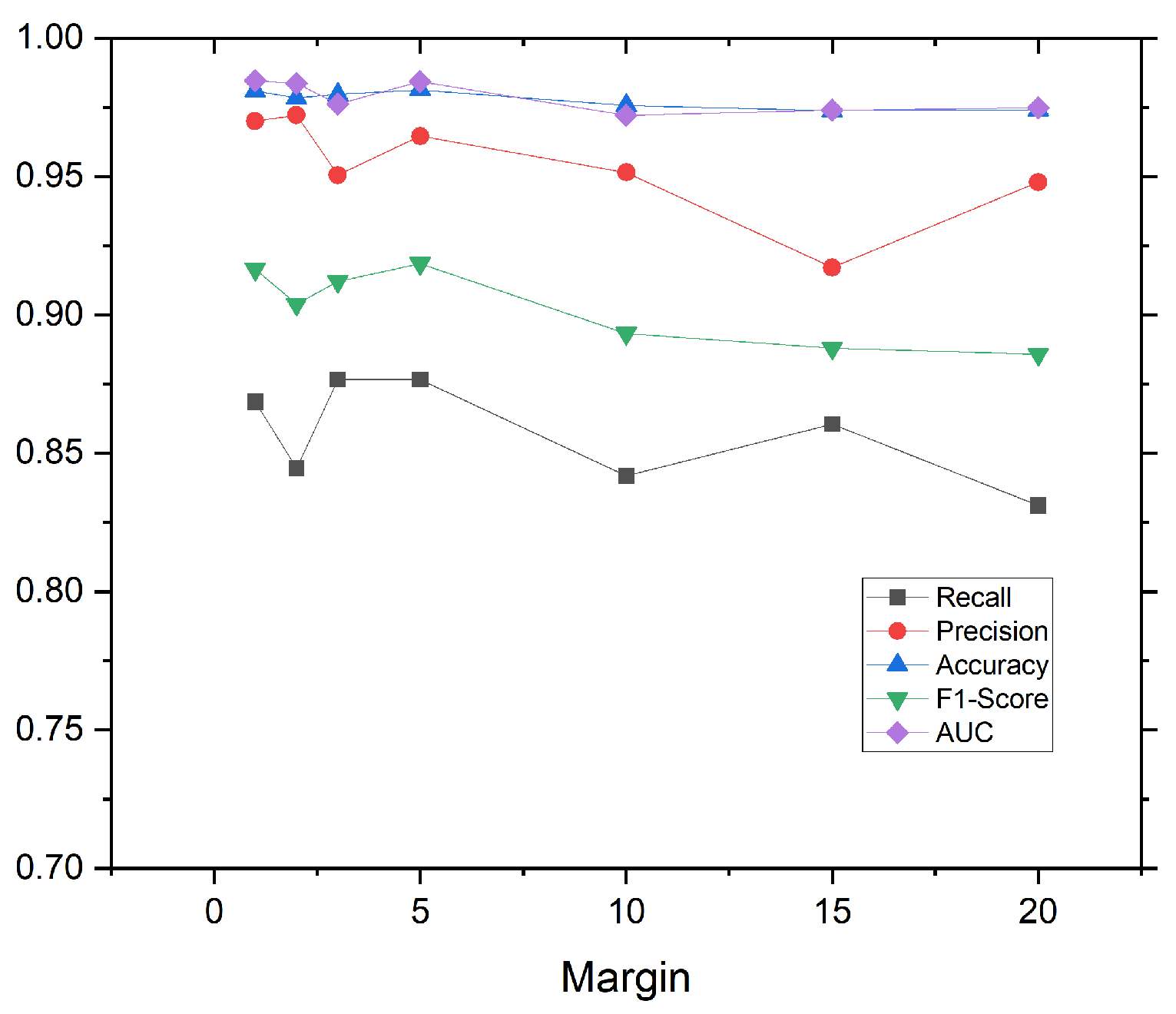
- The parameter in Equation (1) determined how far the negative sample pairs were pulled apart from each other, and different were chosen to verify their effect on the model’s effectiveness.
- Kumar et al. [17] proposed the eDarkFind model for identifying multiple identities of darknet vendors. The specific method involved using cosine similarity to determine whether two vendor accounts were controlled by the same real vendor. Our experiment compared the performance of our method with the eDarkFind model on the dataset collected in this study.
4.1. Tenfold Cross-Validation Result
4.2. Impact of
4.3. Compare with eDarkFind Model
- It only focuses on vendors selling drugs and only uses data from three markets, so it performs well on the original dataset;
- It relies entirely on feature calculation, and once the number of vendors increases, the distinguishability of the features may not be clear.
5. Case Study
5.1. Drug Trafficking Group
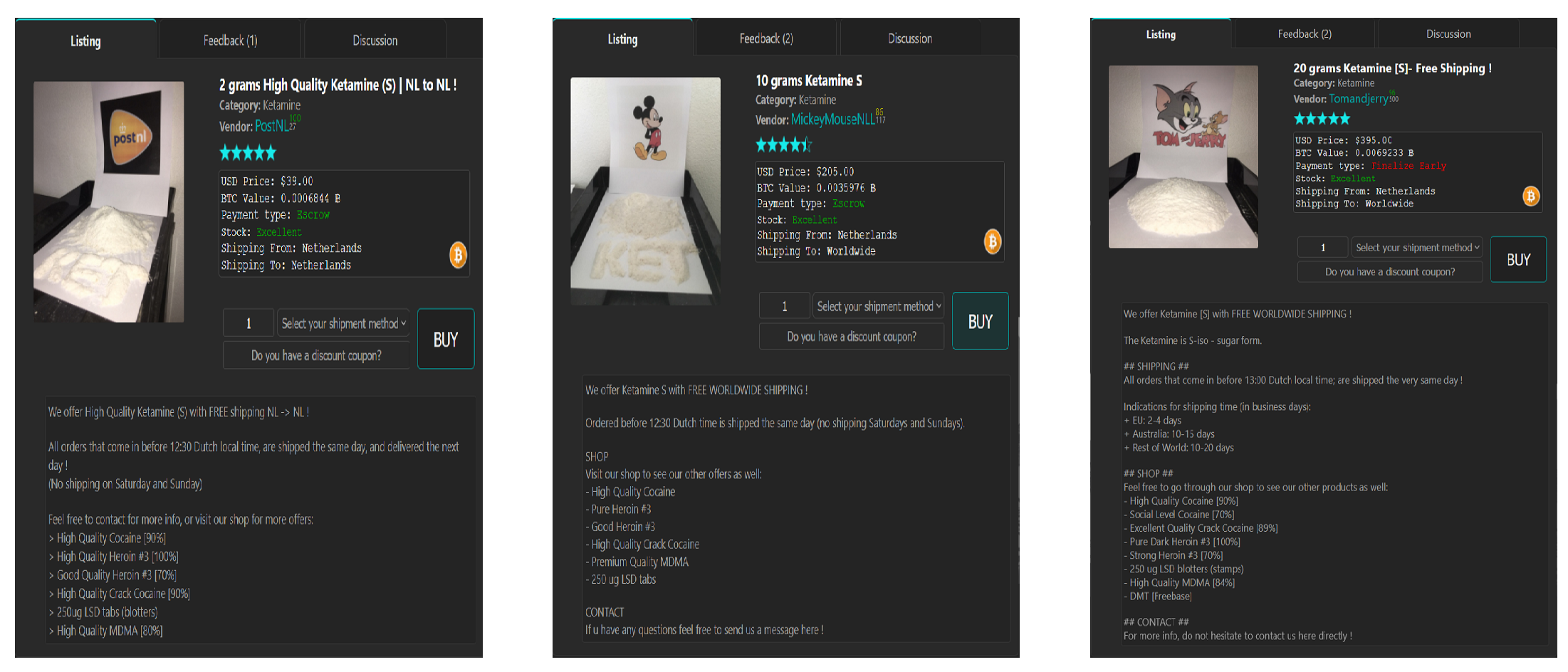
5.2. Same Username for Different Vendors
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chaum, D.L. Untraceable electronic mail, return addresses, and digital pseudonyms. Commun. ACM 1981, 24, 84–90. [Google Scholar] [CrossRef]
- Reed, M.G.; Syverson, P.F.; Goldschlag, D.M. Anonymous connections and onion routing. IEEE J. Sel. Areas Commun. 1998, 16, 482–494. [Google Scholar] [CrossRef]
- Astolfi, F.; Kroese, J.; Van Oorschot, J. I2p—The Invisible Internet Project; Leiden University Web Technology Report; Leiden University: Leiden, The Netherlands, 2015. [Google Scholar]
- Clarke, I.; Sandberg, O.; Wiley, B.; Hong, T.W. Freenet: A distributed anonymous information storage and retrieval system. In Proceedings of the Designing Privacy Enhancing Technologies, Berkeley, CA, USA, 25–26 July 2000; Springer: Berlin/Heidelberg, Germany, 2001; pp. 46–66. [Google Scholar]
- The 2021 Crypto Crime Report; Chainalysis: New York, NY, USA, 2021; pp. 44–45.
- Georgoulias, D.; Pedersen, J.M.; Falch, M.; Vasilomanolakis, E. Botnet business models, takedown attempts, and the darkweb market: A survey. ACM Comput. Surv. 2023, 55, 1–39. [Google Scholar] [CrossRef]
- Maneriker, P.; He, Y.; Parthasarathy, S. SYSML: StYlometry with Structure and Multitask Learning: Implications for Darknet Forum Migrant Analysis. In Proceedings of the Empirical Methods in Natural Language Processing, Online, 7–11 November 2021. [Google Scholar]
- Waldner, O. Illuminating Dark Paths: Identifying Patterns of Darknet Drug Vendor Migration. Independent Thesis, Malmö University, Malmö, Sweden, 2022. [Google Scholar]
- Branwen, G.; Christin, N.; Décary-Hétu, D.; Andersen, R.M.; StExo; Presidente, E.; Anonymous; Lau, D.; Sohhlz, D.K.; Cakic, V.; et al. Dark Net Market Archives, 2011–2015. 2015. Available online: https://www.gwern.net/DNM-archives (accessed on 5 December 2022).
- Suman, C.; Raj, A.; Saha, S.; Bhattacharyya, P. Authorship attribution of microtext using capsule networks. IEEE Trans. Comput. Soc. Syst. 2021, 9, 1038–1047. [Google Scholar] [CrossRef]
- Zhang, R.; Hu, Z.; Guo, H.; Mao, Y. Syntax encoding with application in authorship attribution. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2742–2753. [Google Scholar]
- Fabien, M.; Villatoro-Tello, E.; Motlicek, P.; Parida, S. BertAA: BERT fine-tuning for Authorship Attribution. In Proceedings of the 17th International Conference on Natural Language Processing (ICON), Online, 18–21 December 2020; pp. 127–137. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Wang, X.; Iwaihara, M. Integrating RoBERTa Fine-Tuning and User Writing Styles for Authorship Attribution of Short Texts. In Proceedings of the Web and Big Data: 5th International Joint Conference, APWeb-WAIM 2021, Guangzhou, China, 23–25 August 2021; Part I 5. Springer: Cham, Switzerland, 2021; pp. 413–421. [Google Scholar]
- Hung, C.Y.; Hu, Z.; Hu, Y.; Lee, R. Who Wrote it and Why? Prompting Large-Language Models for Authorship Verification. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; pp. 14078–14084. [Google Scholar]
- Tai, X.H.; Soska, K.; Christin, N. Adversarial matching of dark net market vendor accounts. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1871–1880. [Google Scholar]
- Kumar, R.; Yadav, S.; Daniulaityte, R.; Lamy, F.; Thirunarayan, K.; Lokala, U.; Sheth, A. edarkfind: Unsupervised multi-view learning for sybil account detection. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 1955–1965. [Google Scholar]
- Me, G.; Pesticcio, L.; Spagnoletti, P. Discovering hidden relations between tor marketplaces users. In Proceedings of the 2017 IEEE 15th International Conference on Dependable, Autonomic and Secure Computing, 15th Intl Conf on Pervasive Intelligence and Computing, 3rd Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech), Orlando, FL, USA, 6–10 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 494–501. [Google Scholar]
- Wang, X.; Peng, P.; Wang, C.; Wang, G. You are your photographs: Detecting multiple identities of vendors in the darknet marketplaces. In Proceedings of the 2018 on Asia Conference on Computer and Communications Security, Incheon, Republic of Korea, 4 June 2018; pp. 431–442. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; Volume 32, pp. 1188–1196. [Google Scholar]
- Covington, M.A.; McFall, J.D. Cutting the Gordian Knot: The Moving-Average Type–Token Ratio (MATTR). J. Quant. Linguist. 2010, 17, 94–100. [Google Scholar] [CrossRef]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Proceedings of the Workshop on Challenges in Representation Learning, ICML 2013, Atlanta, GA, USA, 16–21 June 2013; Volume 3, p. 896. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Dimension | Feature Name | Number of Features |
|---|---|---|
| Lexical features | Character count | 1 |
| Number and frequency of digits/whitespaces/special characters | 6 | |
| Number of letters/number and frequency of uppercase letters | 4 | |
| Number of words | 1 | |
| Average word length | 1 | |
| Lexical richness | 6 | |
| Proportion of lowercase/uppercase letters | 52 | |
| Number and frequency of punctuation marks | 2 | |
| Grammatical features | Number and frequency of function words | 2 |
| Structural features | Number of paragraphs | 1 |
| Average paragraph indent | 1 | |
| Separator between paragraphs | 1 | |
| Average number of words/sentences/characters per paragraph | 3 | |
| Total | 81 |
| Positive Sample Pairs | Negative Sample Pairs | |
|---|---|---|
| Quantity | 3728 | 26,827 |
| Precision | Recall | Accuracy | F1-Score | AUC |
|---|---|---|---|---|
| 96.868% | 82.252% | 97.535% | 0.889 | 0.971 |
| Accuracy | Precision | Recall | AUC | |
|---|---|---|---|---|
| eDarkFind | 76.789% | 43.94% | 44.53% | 0.768 |
| Siamese neural network | 97.535% | 96.877% | 82.25% | 0.971 |
| MickeymouseNL | PostNL | Tomandjerry | |
|---|---|---|---|
| Apollon | ✓ | ✓ | ✓ |
| Tor2door | ✓ | ✓ | ✓ |
| Darkfox | ✓ | ✓ | ✓ |
| Monopoly | ✓ | ✓ | ✓ |
| Cartel | ✓ | ✓ | ✓ |
| Versus | ✓ | ✓ | ✓ |
| Cypher | ✓ | ✓ | ✓ |
| Dark0de | ✓ | ✓ | ✓ |
| Vice City | ✓ | ✓ | ✓ |
| Agartha | ✓ | ||
| Incognito | ✓ | ||
| TomAndJerry | ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Hu, Y.; Xu, W.; Zou, F. Multi-Identity Recognition of Darknet Vendors Based on Metric Learning. Appl. Sci. 2024, 14, 1619. https://doi.org/10.3390/app14041619
Wang Y, Hu Y, Xu W, Zou F. Multi-Identity Recognition of Darknet Vendors Based on Metric Learning. Applied Sciences. 2024; 14(4):1619. https://doi.org/10.3390/app14041619
Chicago/Turabian StyleWang, Yilei, Yuelin Hu, Wenliang Xu, and Futai Zou. 2024. "Multi-Identity Recognition of Darknet Vendors Based on Metric Learning" Applied Sciences 14, no. 4: 1619. https://doi.org/10.3390/app14041619
APA StyleWang, Y., Hu, Y., Xu, W., & Zou, F. (2024). Multi-Identity Recognition of Darknet Vendors Based on Metric Learning. Applied Sciences, 14(4), 1619. https://doi.org/10.3390/app14041619