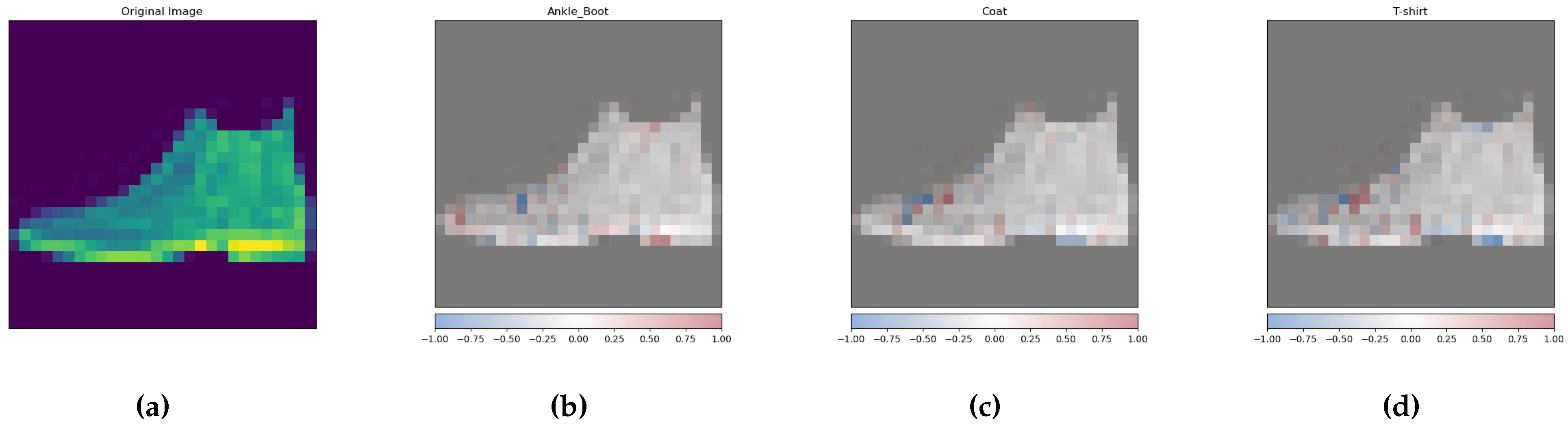
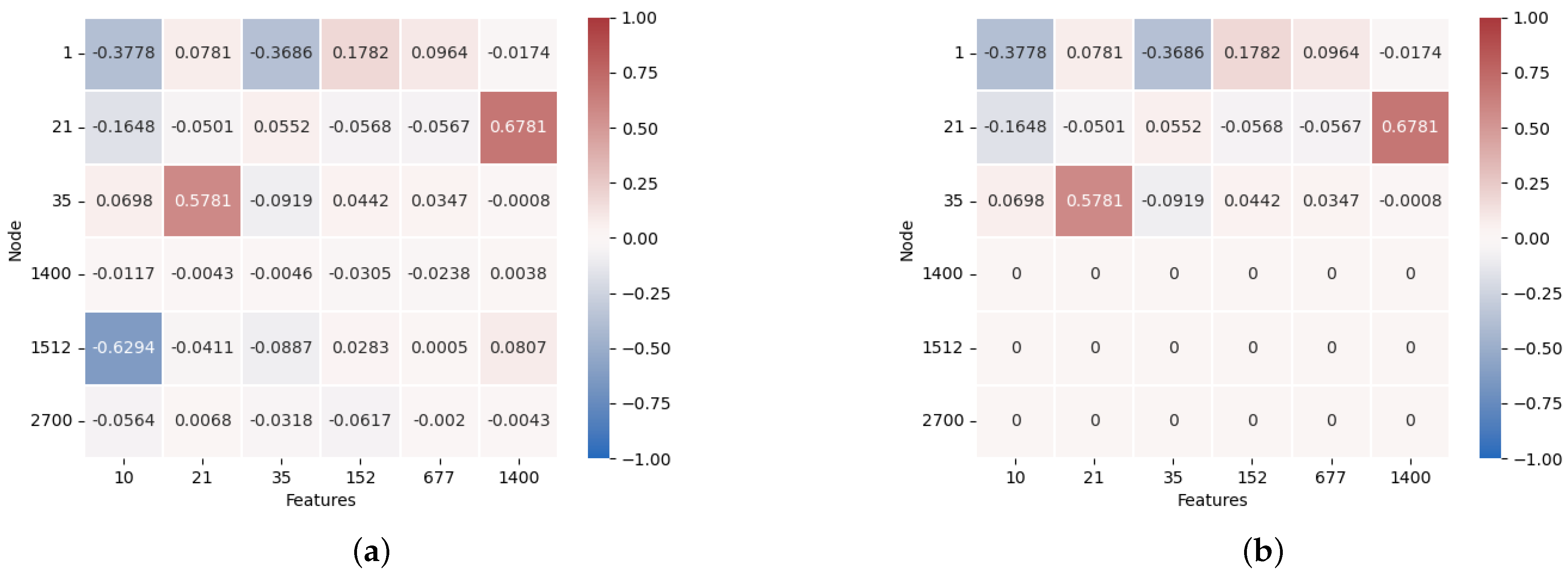
From the perspective of each numerical feature of the sample input into the deep learning model, the operations of the numerical features are defined in the real number field. This makes it impossible to separate them from the numbers in subsequent calculations of the deep learning model. We propose the orthogonal neural network (ONN) model as an extension of the deep learning model. This ONN model modulates numerical features of the sample onto orthogonal bases and extends the calculation rules corresponding to the deep learning model in the space constructed by the orthogonal bases. Then, the ONN model analyzes the weights corresponding to the input numerical features by demodulating values on the orthogonal bases. The model establishes a relationship between input features and results, quantifying this relationship in the form of weights.
2.1. Modulation and Demodulation on Orthogonal Bases
To simplify the description of the problem, we introduce here for discussion a function set composed of sine functions on
in Equation (2). The “
n” in Equation (2) is the number of input features.
The sine functions in this function set are orthogonally, as in Equation (3).
For a “modulation” process, modulating
to a sine wave of frequency
n can be expressed as Equation (4).
The amplitude modulation of the sine wave with a value
causes the value
to be loaded onto the sine wave, which is the amplitude information after modulation. “Demodulation” is the inverse process of “modulation”. For a “demodulation” process, demodulating
from a sine wave of frequency
n can be expressed as (5).
Here, modulation and demodulation are entirely defined by computation to separately modulate all values at the input of a deep learning model to different frequencies so that these values can exist independently during the computation. Such a process is implemented in a communication system using a circuit whose corresponding mathematical description differs from this one. However, the computational result is the same; here, it is fully implemented by computation.
For a value , given as input to the deep learning model, the operations involved are mainly multiplication and addition, i.e., linear operations. In standard models, the computational units that generate nonlinearity are mainly the activation function and maximum pooling, which are characterized by selection of the linear computation results in other links. Although understood as nonlinear in terms of computational properties, the output of their operations is still the result of linear computation of the values of model input. The values input to the deep learning model are denoted as , for each computational session, the values in the result can be expressed as , is the weight corresponding to , and if the computational result does not contain the input .
Therefore, by assigning a frequency to each value input in the deep learning model and modulating it according to specific rules, the values generated by each computational link in the deep learning model become a linear superposition of a set of sine functions, which can be expressed as
. When it is necessary to extract an
of interest, “demodulation” can be computationally implemented, such as in Equation (6).
The conclusion from calculating the orthogonality of sinusoidal functions is that the summation is nonzero only when , which means that can be demodulated only by using . Through the above modulation and demodulation computation process, each input value to the deep learning model is actually assigned a “frequency” label, which can be used to extract the value corresponding to the initial input value at any time during model operation, and this label has a clear physical meaning and is easy to compute.
2.2. Operational Rules of ONN Model
Application of frequency modulation to the values input into the deep learning model is equivalent to converting the input values into a function, so it is necessary to extend the computational rules of the deep learning model such that it can satisfy both the operation of the function and the computational logic in being consistent with the original numerical computation. In the following discussion, extension of the operation rules is defined for each calculation unit.
First, we discuss the case of a single neuron, which consists of an affine function and an activation function. For
n numeric features,
, the weights corresponding to the features are
, and
b is the bias and can be defaulted. Thus, the affine function is
. Then, over the activation function, it constitutes a single neuron, which can be expressed as (7). As explained at the beginning of the article, the activation function is limited to the ReLU function.
We perform frequency modulation for the numerical elements in
. For the sake of discussion, the frequency corresponding to each element is the subscript of that element.
, and the frequency assigned for the bias
b assignment is
such that the affine function becomes
. It can be seen that after modulation of the numerical elements, the calculation of the affine function changes from a numerical value to a function containing a variable
t, which is only useful in the demodulation session and, therefore, is not additionally written. Since the calculation result of the affine function changes from a numerical value to a function, it is necessary to extend the definition of the operation rules for the activation function, which is in Equation (8).
The judgment condition is the same as the original activation function. Due to the premise of frequency modulation, we can obtain
a by demodulating the values in
by Equation (9).
Here, we can figuratively understand the extended definition of the activation function as a switch function, and the affine function calculates as a signal. When , the switch opens the signal through; when , the switch closes the signal blocking. There are differences in the definition of the activation function for the judgment condition when . In the original activation function, the condition can be included in either the greater- or less-than conditions. In the extended definition of the activation function, the condition can only be included in the less-than condition because consistency with the original definition must be guaranteed in the numerical computation logic of the extended definition. In the original definition of the condition , the activation function outputs . In the extended definition, if the equal condition is included in the greater-than condition, the activation function outputs , which is inconsistent with the computational logic of the original activation function.
When the neuron is not in the input layer, each output of the previous layer is a linear combination of sine functions, which can be expressed as , and the modulated is not essentially different, but is a linear combination of sine functions, so it still satisfies the above discussion of affine functions and activation functions. The output of each computational unit is a linear combination of sine functions.
With the above discussion on the extension of the activation function operation rules, we initially show the extension method. In order to further provide a normatively rigorous mathematical representation of the arithmetic process, we define a function set
F.
The function set
F consists of linear combinations of sine functions with integer frequencies, where
F satisfies
,
,
. Thus, the function set
F is complete. For the convenience of discussion, we define a size measure for
. Here,
represents the linear superposition of a set of sine functions, corresponding to the deep learning computation, where the information modulated on the corresponding sine functions needs to be demodulated and summed. Combining the definition of the function set
F, we define the sum of the coefficients of the sine functions
for
in Equation (11).
Here, we further provide a more normative definition of the ReLU activation function in Equation (12). The
and
in the previous discussion belong to the function set
F.
For a single-layer neural network containing
n neurons, the input layer contains
m features. The calculation rule is output
, where
is a function matrix denoting the input layer of the neural network,
is a numerical matrix denoting the parameters of that layer of the neural network,
is a function matrix denoting the output layer of the neural network, which is in Equation (13).
Due to
,
, obviously
. For the calculation rules of multilayer neural networks, one layer contains
n neurons. The output of the previous layer has
m neurons, so the input of the layer is the output of the previous layer as
and
is the parameter matrix of the neural network of the current layer. The output is
, and
is consistent with the above. Multilayer neural networks [
16] can be constructed according to such rules.
Multilayer neurons are logically composed as a linear computational combination of multiple neurons. It should be emphasized here that their composition is characterized as a linear combination but, as a whole, does not satisfy the property of linearity. Since the activation function in a single neuron is nonlinear, the condition of linearity is not satisfied. Therefore, the combination of linear superposition of neurons also does not satisfy the conditions for linearity, but its calculation results in a linear combination of the input features. This phenomenon occurs because the ReLU function is a piecewise linear function and can therefore guarantee the properties of partial linear calculation under piecewise conditions.
In typical deep learning models, multiple layers of neurons are generally used as fully connected layers in combination with other calculation units to build models capable of achieving complex learning functions. In convolutional neural networks [
17], the basic calculation units are convolution, activation function, pooling, and multilayer neurons. Next, we discuss the convolutional neural network used in computer vision as an example.
Convolution is one of the operations for extracting features in a convolutional neural network. For a two-dimensional numerical matrix
, the convolution kernel is
, with
k being an odd number, and the convolution is computed as
, which is in Equation (14), where
.
Expansion of the convolution operation involves transforming the input numerical matrix , replaced by the function matrix , then the output function matrix . The calculation formula is still written as . From the previous discussion, the formula is obviously compatible with two operations.
The graph neural network [
18,
19,
20] is a model recently proposed in deep learning that is mainly composed of graph convolutions. For a graph with
M nodes, each containing
N features, the structural information of the graph is the adjacency matrix
, and the feature information is the matrix
. Each graph convolution layer comprises a fully connected layer of
K neurons with a parameter matrix of
. The graph convolution layer is defined as
, where the Laplace matrix
is calculated from the adjacency matrix
A and the output
. When multiple graph convolution layers are combined, the matrix
Y output from the previous layer is used as the feature matrix
X as input for this layer.
The extension of the operational rules mainly involves converting the numerical matrix
, which represents the characteristic information, into a function matrix
. Since the activation functions have been discussed, the main discussion here is on the function matrix
left multiplication numerical matrix
, which is in Equation (15), and the function matrix
right multiplication parameter matrix
, which is in Equation (16). Here, the matrix multiplication rules correspond to the original model for the inner product multiplication operation of the matrix.
Obviously, , and the extended graph convolution layer is , where is a function matrix. The operation here also satisfies the associative law, which is .
2.3. Further Optimization for Orthogonal Bases
In the previous discussion, inspired by the frequency division multiplexing technology in communication technology, we introduced the concepts of “frequency”, “modulation”, and “demodulation” and extended the operation rules of the deep learning model. This discussion revolves around the physical meaning of sine function and frequency. From a mathematical point of view, the sine function is introduced to form a function set and the elements in this function set are orthogonal to each other on the interval . The sine function on the interval is taken as a set of orthogonal bases to form a space and further extend the corresponding definition of the operation rules of the deep learning model on this space.
However, what needs to be further discussed is that from the perspective of concrete calculation in the computer, the continuous function in an interval is a sampled discrete sequence on the computer. When the sampling interval is
T in the interval
, there are
sampling points, so the sequence sampled by
is
, and the sampled sequence has the same orthogonal property, which is in Equation (17).
Therefore, when performing operations on the computer, we actually use a set of orthogonal sequences after sampling the sine function, which is in Equation (18).
When n features need to be modulated, n frequencies need to be allocated and generated. In order to ensure that the sine functions of these n frequencies do not produce frequency aliasing, when the maximum frequency is n, it is necessary to satisfy the Nyquist sampling theorem when discretizing, which in this case means that a sequence of at least points is needed to represent the sine functions on the interval. In the scenario of deep learning, this n is always enormous. When allocating values of storage space for each frequency, floating point values need to be allocated to memory, which will cause considerable resource consumption. At the same time, there will also be quantization errors in the process of discrete sampling of continuous functions. After entering the deep learning algorithm, the cumulative errors resulting from these quantization errors will affect its accuracy.
Therefore, the space constructed by the sine function on the interval
as the orthogonal basis has clear physical significance, but it is challenging to realize in practical applications. Further, consider constructing a set of orthogonal bases from a mathematical perspective and the equivalent, realizing the theoretical process discussed in the previous article. The most common orthogonal basis in mathematics is the standard orthogonal basis of Euclidean space, which can be expressed as an orthogonal vector set
and (19). The “
n” is the number of input features which is consistent with Equation (2).
The use of the orthogonal basis is not only simple and elegant in form, but can also allow directly avoiding the quantization error generated by digital sampling of the sine function when the sine function is used as the orthogonal basis. The position index of the nonzero item in the base vector also completely corresponds to the base number. Using sparse data structures for storage can significantly save the storage space and improve the operation efficiency. Another point is that as a standard orthogonal basis, its modulus is 1, and the nonzero term value is also 1, which is convenient for the calculation.
Corresponding to function set
F, define vector set
E.
Evidently, E satisfies , , , with completeness. When discussing function set F, the sum function is defined for . For vector set E, the corresponding operation for . And, is exactly the sum of elements of vector . This is also the advantage of using the standard orthogonal basis of Euclidean space.
Therefore, the extended operation rules defined on the function set F discussed in the previous section can be directly replaced by the vector set E, which is equivalent. The corresponding calculation logic has been fully discussed for (10), (12)–(16), and (20), and there will be no further detailed discussion here.
2.4. Summary of the Model
In the previous discussion, the features input into the depth learning model are loaded onto different bases by introducing a set of orthogonal bases, and the orthogonal relationship between the bases is used to ensure the input features remain independent of each other. Further, according to the numerical computation relationship of each feature in the original model, the corresponding operation rules are defined in the space composed of this set of orthogonal bases, which is the extension discussed for the deep learning model. From the perspective of numerical calculation, the two are entirely consistent, but the latter can separate the features on each based on the orthogonal relationship between the bases.
Most of the computational units of the deep learning model are linear, so the computation between features and model parameters is actually a linear operation on the real number field. In the expanded deep learning model, the features exist as vectors in space, and their operation with the model parameters becomes a linear operation between the vectors in space.
Regarding the two typical nonlinear operation units, activation function and maximum pooling, the operation rules in vector set E can still be expanded and defined through the analysis of their operation logic and the use of their “partially linear” nature; that is, the vectors involved in the operation can be linearly expressed with an orthogonal basis. Therefore, we can extend the deep learning model to operate in the vector set E.
It should be emphasized again that the operation here maintains the property that the output results of the computational units can all be expressed as linear combinations of orthogonal bases, but is not a linear system and does not satisfy the definition of a linear system. On the other hand, if the system is linear, the deep learning model does not have the problem of insufficient interpretability, and the linear system can directly solve the system function using impulse response methods.
The most important feature of the discussion in this paper is the introduction of the orthogonal function set and orthogonal vector set to extend the deep learning model with operational rules and introduce the concept of modulation and demodulation, so the extended model is called
orthogonal neural network (ONN) in this paper. The process of loading features onto an orthogonal basis is expressed as orthogonal modulation of features. The definition of the model is shown in
Figure 1, which includes the modulated data, the parameters of the deep learning model, and the algorithmic rules defined in the extension in this section. Then, we can compute the analysis data of the classification results based on the orthogonal neural network model by demodulating values on the orthogonal bases. The ONN model can be applied to almost any deep learning model that uses the ReLU activation function. In the following, we detail the applications of the ONN model on two typical deep learning models: convolutional neural network and graph neural network.


{kind=link}
{kind=link}
{kind=link}
{kind=link}