
Comparison of Modern Deep Learning Models for Speaker Verification

 , , ,
, , ,  , ,
, ,
Abstract
1. Introduction
2. Related Works
3. Aim of Research
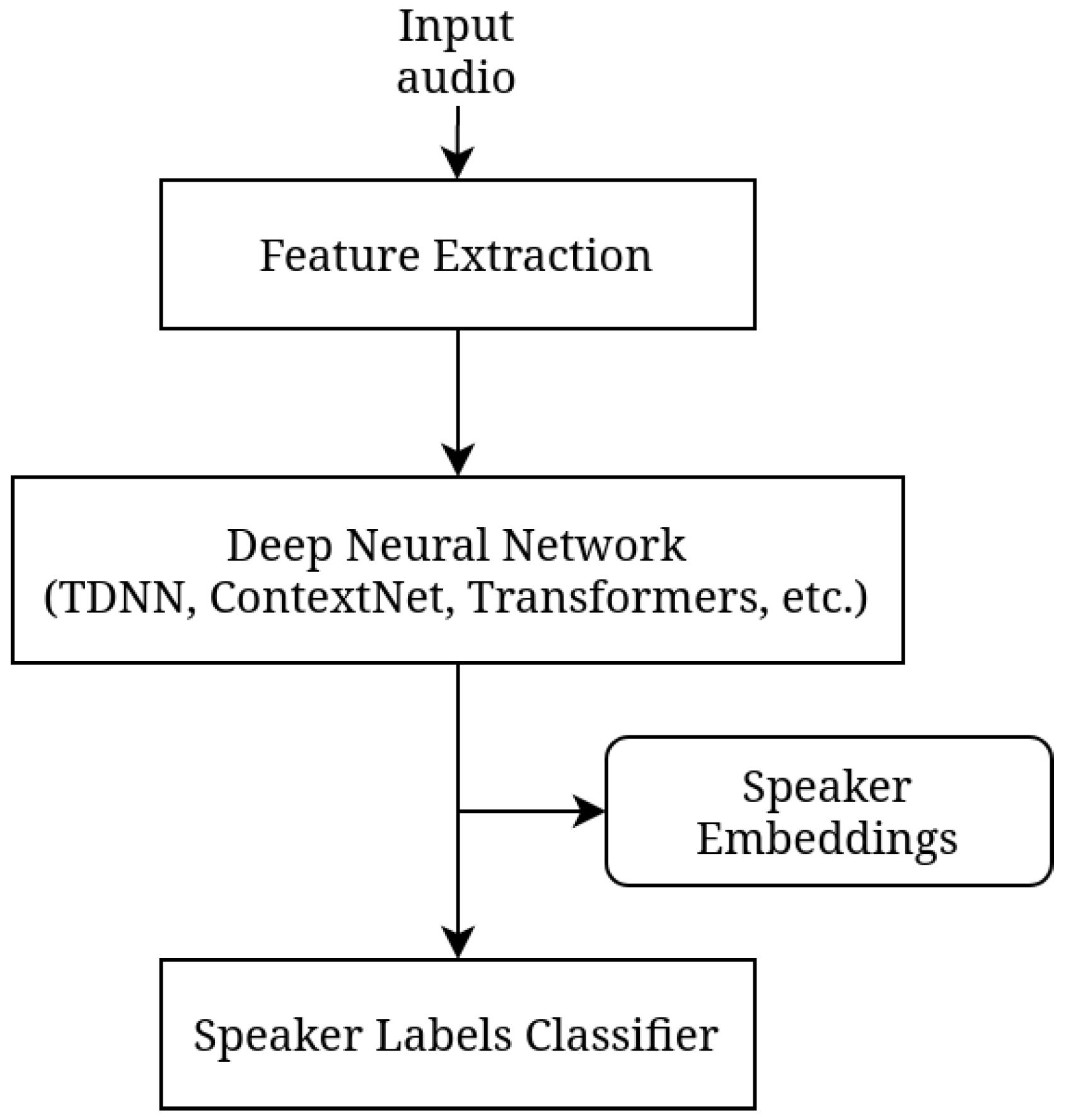
4. Models Overview
4.1. WavLM
4.2. PyAnnote
4.3. TitaNet
4.4. ECAPA
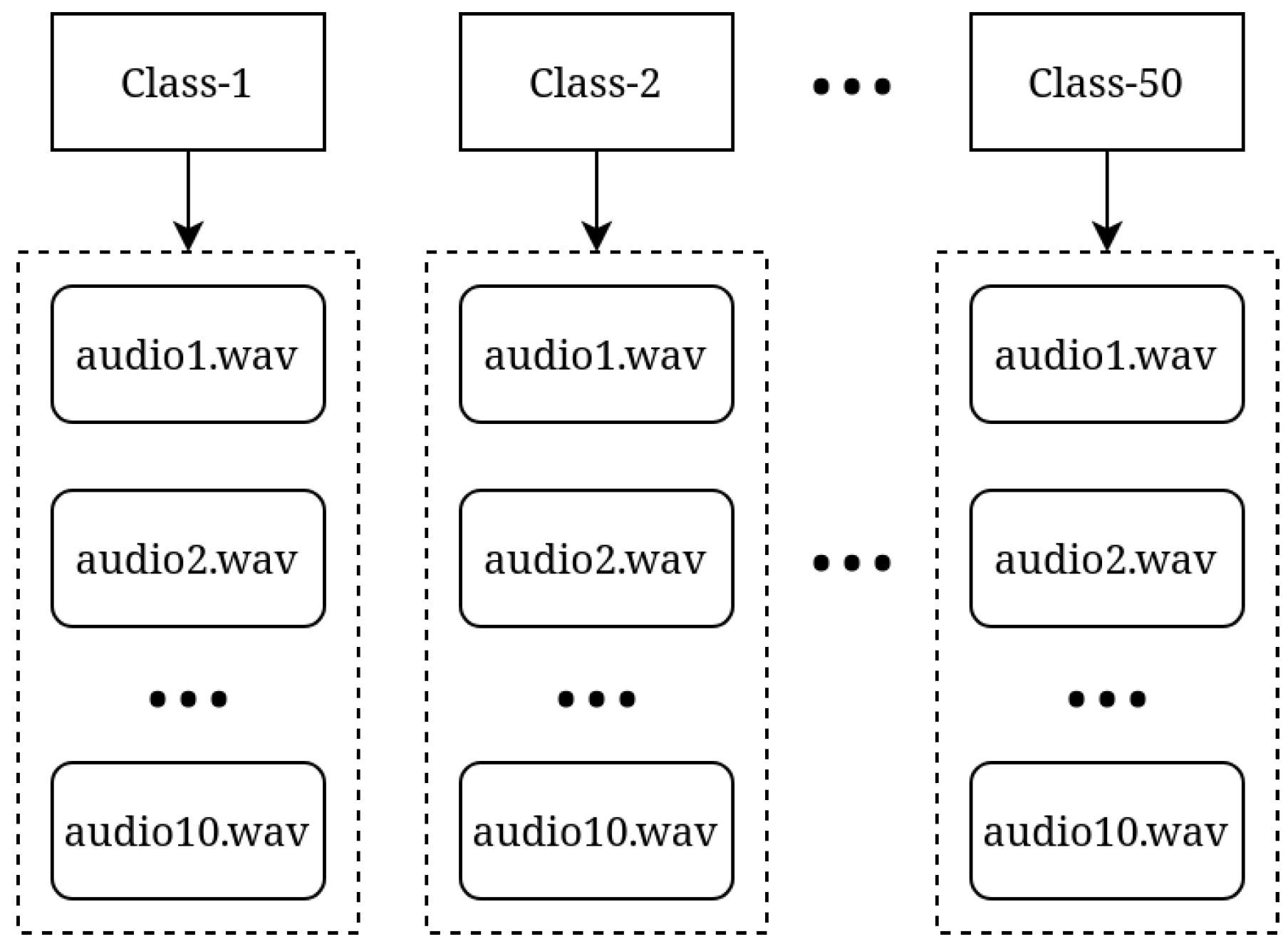
5. Experiment Setup
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bai, Z.; Zhang, X.L. Speaker recognition based on deep learning: An overview. Neural Netw. 2021, 140, 65–99. [Google Scholar] [CrossRef]
- Kabir, M.M.; Mridha, M.F.; Shin, J.; Jahan, I.; Ohi, A.Q. A survey of speaker recognition: Fundamental theories, recognition methods and opportunities. IEEE Access 2021, 9, 79236–79263. [Google Scholar] [CrossRef]
- Khoma, V.; Khoma, Y.; Brydinskyi, V.; Konovalov, A. Development of Supervised Speaker Diarization System Based on the PyAnnote Audio Processing Library. Sensors 2023, 23, 2082. [Google Scholar] [CrossRef] [PubMed]
- Dovydaitis, L.; Rasymas, T.; Rudžionis, V. Speaker authentication system based on voice biometrics and speech recognition. In Proceedings of the Business Information Systems Workshops: BIS 2016 International Workshops, Leipzig, Germany, 6–8 July 2016; Springer: Berlin/Heidelberg, Germany, 2017; pp. 79–84. [Google Scholar]
- Hansen, J.H.; Hasan, T. Speaker recognition by machines and humans: A tutorial review. IEEE Signal Process. Mag. 2015, 32, 74–99. [Google Scholar] [CrossRef]
- Jahangir, R.; Teh, Y.W.; Nweke, H.F.; Mujtaba, G.; Al-Garadi, M.A.; Ali, I. Speaker identification through artificial intelligence techniques: A comprehensive review and research challenges. Expert Syst. Appl. 2021, 171, 114591. [Google Scholar] [CrossRef]
- Alaliyat, S.; Waaler, F.F.; Dyvik, K.; Oucheikh, R.; Hameed, I. Speaker Verification Using Machine Learning for Door Access Control Systems. In Proceedings of the International Conference on Artificial Intelligence and Computer Vision, Settat, Morocco, 28–30 June 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 689–700. [Google Scholar]
- Wells, J.H.; Williams, L.R. Embeddings and Extensions in Analysis; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 84. [Google Scholar]
- Tsoi, P.K.; Fung, P. A Novel Technique for Frame Selection for GMM-based text-independent Speaker Recognition. In Proceedings of the ICSLP 2000, Beijing, China, 16–20 October 2000. [Google Scholar]
- Bhattacharya, G.; Alam, M.J.; Kenny, P. Deep Speaker Embeddings for Short-Duration Speaker Verification. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 1517–1521. [Google Scholar]
- Mohammed, T.S.; Aljebory, K.M.; Rasheed, M.A.A.; Al-Ani, M.S.; Sagheer, A.M. Analysis of Methods and Techniques Used for Speaker Identification, Recognition, and Verification: A Study on Quarter-Century Research Outcomes. Iraqi J. Sci. 2021, 62, 3256–3281. [Google Scholar] [CrossRef]
- Univaso, P. Forensic speaker identification: A tutorial. IEEE Lat. Am. Trans. 2017, 15, 1754–1770. [Google Scholar] [CrossRef]
- Echihabi, K.; Zoumpatianos, K.; Palpanas, T. Scalable machine learning on high-dimensional vectors: From data seriesto deep network embeddings. In Proceedings of the 10th International Conference on Web Intelligence, Mining and Semantics, Biarritz, France, 30 June–3 July 2020; pp. 1–6. [Google Scholar]
- Jurafsky, D.; Martin, J.H.; Kehler, A.; Vander Linden, K.; Ward, N. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition; Prentice Hall: Hoboken, NJ, USA, 2000. [Google Scholar]
- Brydinskyi, V. Dataset of 500 Short Speech Utterances of 50 Ukrainian Politicians. 2023. Available online: https://github.com/vbrydik/speaker-verification-test (accessed on 30 January 2024).
- Xie, W.; Nagrani, A.; Chung, J.S.; Zisserman, A. Utterance-level aggregation for speaker recognition in the wild. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 5791–5795. [Google Scholar]
- Poddar, A.; Sahidullah, M.; Saha, G. Speaker verification with short utterances: A review of challenges, trends and opportunities. IET Biom. 2018, 7, 91–101. [Google Scholar] [CrossRef]
- Viñals, I.; Ortega, A.; Miguel, A.; Lleida, E. An analysis of the short utterance problem for speaker characterization. Appl. Sci. 2019, 9, 3697. [Google Scholar] [CrossRef]
- Wan, L.; Wang, Q.; Papir, A.; Moreno, I.L. Generalized end-to-end loss for speaker verification. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4879–4883. [Google Scholar]
- Li, J.; Yan, N.; Wang, L. FDN: Finite difference network with hierarchical convolutional features for text-independent speaker verification. arXiv 2021, arXiv:2108.07974. [Google Scholar]
- Liu, M.; Lee, K.A.; Wang, L.; Zhang, H.; Zeng, C.; Dang, J. Cross-Modal Audio-Visual Co-Learning for Text-Independent Speaker Verification. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Kim, S.H.; Nam, H.; Park, Y.H. Analysis-based Optimization of Temporal Dynamic Convolutional Neural Network for Text-Independent Speaker Verification. IEEE Access 2023, 11, 60646–60659. [Google Scholar] [CrossRef]
- Xia, W.; Huang, J.; Hansen, J.H. Cross-lingual text-independent speaker verification using unsupervised adversarial discriminative domain adaptation. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 5816–5820. [Google Scholar]
- Habib, H.; Tauseef, H.; Fahiem, M.A.; Farhan, S.; Usman, G. SpeakerNet for Cross-lingual Text-Independent Speaker Verification. Arch. Acoust. 2020, 45, 573–583. [Google Scholar]
- Bredin, H.; Yin, R.; Coria, J.M.; Gelly, G.; Korshunov, P.; Lavechin, M.; Fustes, D.; Titeux, H.; Bouaziz, W.; Gill, M.P. Pyannote.audio: Neural building blocks for speaker diarization. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7124–7128. [Google Scholar]
- Chen, S.; Wang, C.; Chen, Z.; Wu, Y.; Liu, S.; Chen, Z.; Li, J.; Kanda, N.; Yoshioka, T.; Xiao, X.; et al. WavLM: Large-scale self-supervised pre-training for full stack speech processing. IEEE J. Sel. Top. Signal Process. 2022, 16, 1505–1518. [Google Scholar] [CrossRef]
- Koluguri, N.R.; Park, T.; Ginsburg, B. TitaNet: Neural Model for speaker representation with 1D Depth-wise separable convolutions and global context. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 8102–8106. [Google Scholar]
- Desplanques, B.; Thienpondt, J.; Demuynck, K. ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in TDNN based speaker verification. arXiv 2020, arXiv:2005.07143. [Google Scholar]
- Dawalatabad, N.; Ravanelli, M.; Grondin, F.; Thienpondt, J.; Desplanques, B.; Na, H. ECAPA-TDNN embeddings for speaker diarization. arXiv 2021, arXiv:2104.01466. [Google Scholar]
- Jakubec, M.; Jarina, R.; Lieskovska, E.; Kasak, P. Deep speaker embeddings for Speaker Verification: Review and experimental comparison. Eng. Appl. Artif. Intell. 2024, 127, 107232. [Google Scholar] [CrossRef]
- Safavi, S.; Najafian, M.; Hanani, A.; Russell, M.J.; Jancovic, P. Comparison of speaker verification performance for adult and child speech. In Proceedings of the WOCCI, Singapore, 19 September 2014; pp. 27–31. [Google Scholar]
- Tobin, J.; Tomanek, K. Personalized automatic speech recognition trained on small disordered speech datasets. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 6637–6641. [Google Scholar]
- Nammous, M.K.; Saeed, K.; Kobojek, P. Using a small amount of text-independent speech data for a BiLSTM large-scale speaker identification approach. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 764–770. [Google Scholar] [CrossRef]
- Prihasto, B.; Azhar, N.F. Evaluation of recurrent neural network based on Indonesian speech synthesis for small datasets. Adv. Sci. Technol. 2021, 104, 17–25. [Google Scholar]
- Nagrani, A.; Chung, J.S.; Zisserman, A. Voxceleb: A large-scale speaker identification dataset. arXiv 2017, arXiv:1706.08612. [Google Scholar]
- Zeinali, H.; Burget, L.; Černockỳ, J.H. A multi purpose and large scale speech corpus in Persian and English for speaker and speech recognition: The DeepMine database. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 397–402. [Google Scholar]
- Aldarmaki, H.; Ullah, A.; Ram, S.; Zaki, N. Unsupervised automatic speech recognition: A review. Speech Commun. 2022, 139, 76–91. [Google Scholar] [CrossRef]
- Chi, Z.; Huang, S.; Dong, L.; Ma, S.; Zheng, B.; Singhal, S.; Bajaj, P.; Song, X.; Mao, X.L.; Huang, H.; et al. Xlm-e: Cross-lingual language model pre-training via electra. arXiv 2021, arXiv:2106.16138. [Google Scholar]
- Coria, J.M.; Bredin, H.; Ghannay, S.; Rosset, S. A comparison of metric learning loss functions for end-to-end speaker verification. In Proceedings of the International Conference on Statistical Language and Speech Processing, Cardiff, UK, 14–16 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 137–148. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-vectors: Robust dnn embeddings for speaker recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AL, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Ravanelli, M.; Bengio, Y. Speaker recognition from raw waveform with sincnet. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 1021–1028. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Kuchaiev, O.; Li, J.; Nguyen, H.; Hrinchuk, O.; Leary, R.; Ginsburg, B.; Kriman, S.; Beliaev, S.; Lavrukhin, V.; Cook, J.; et al. Nemo: A toolkit for building ai applications using neural modules. arXiv 2019, arXiv:1909.09577. [Google Scholar]
- Cheng, J.M.; Wang, H.C. A method of estimating the equal error rate for automatic speaker verification. In Proceedings of the 2004 International Symposium on Chinese Spoken Language Processing, Hong Kong, China, 15–18 December 2004; pp. 285–288. [Google Scholar]
- Kinnunen, T.; Lee, K.A.; Delgado, H.; Evans, N.; Todisco, M.; Sahidullah, M.; Yamagishi, J.; Reynolds, D.A. t-DCF: A detection cost function for the tandem assessment of spoofing countermeasures and automatic speaker verification. arXiv 2018, arXiv:1804.09618. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Embedding Method | EER (%) |
|---|---|
| i-vector | 10.73 |
| d-vector | 6.44 |
| x-vector | 3.98 |
| x-vector (E-TDNN) | 3.76 |
| x-vector (F-TDNN) | 3.53 |
| r-vector (ResNet) | 3.18 |
| r-vector (Res2Net) | 2.71 |
| Model | Speaker Embedding Dimension | Training Dataset | Architecture |
|---|---|---|---|
| PyAnnote | 512 | VoxCeleb | X-vector with SincNet |
| WavLM | 256 | LibriSpeech | Transformer |
| TitaNet | 192 | VoxCeleb, NIST SRE, Fisher, LibriSpeech | ContextNet with channel attention pooling |
| Ecapa-TDNN | 192 | VoxCeleb | Improved TDNN |
| Model | FAR (%) | FRR (%) | EER (%) | DCF | Inference Time (ms) |
|---|---|---|---|---|---|
| PyAnnote | 3.78 | 3.82 | 3.8 | 0.259 | 49.44 ± 11.97 |
| WavLM-Base-SV | 12.53 | 12.4 | 12.47 | 0.445 | 91.39 ± 12.85 |
| WavLM-Base-Plus-SV | 10.84 | 10.93 | 10.88 | 0.407 | 92.25 ± 17.01 |
| TitaNet-Large | 1.91 | 1.91 | 1.91 | 0.138 | 110.18 ± 8.59 |
| Ecapa | 1.73 | 1.68 | 1.71 | 0.139 | 69.43 ± 8.06 |
| Model | The Distance between Samples of Different Classes | The Distance between Samples of the Same Class |
|---|---|---|
| PyAnnote | 1.298 ± 0.071 | 0.941 ± 0.117 |
| WavLM-Base-SV | 0.654 ± 0.238 | 0.286 ± 0.075 |
| WavLM-Base-Plus-SV | 0.684 ± 0.254 | 0.286 ± 0.073 |
| TitaNet-Large | 1.246 ± 0.084 | 0.773 ± 0.121 |
| Ecapa | 1.293 ± 0.081 | 0.827 ± 0.119 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brydinskyi, V.; Khoma, Y.; Sabodashko, D.; Podpora, M.; Khoma, V.; Konovalov, A.; Kostiak, M. Comparison of Modern Deep Learning Models for Speaker Verification. Appl. Sci. 2024, 14, 1329. https://doi.org/10.3390/app14041329
Brydinskyi V, Khoma Y, Sabodashko D, Podpora M, Khoma V, Konovalov A, Kostiak M. Comparison of Modern Deep Learning Models for Speaker Verification. Applied Sciences. 2024; 14(4):1329. https://doi.org/10.3390/app14041329
Chicago/Turabian StyleBrydinskyi, Vitalii, Yuriy Khoma, Dmytro Sabodashko, Michal Podpora, Volodymyr Khoma, Alexander Konovalov, and Maryna Kostiak. 2024. "Comparison of Modern Deep Learning Models for Speaker Verification" Applied Sciences 14, no. 4: 1329. https://doi.org/10.3390/app14041329
APA StyleBrydinskyi, V., Khoma, Y., Sabodashko, D., Podpora, M., Khoma, V., Konovalov, A., & Kostiak, M. (2024). Comparison of Modern Deep Learning Models for Speaker Verification. Applied Sciences, 14(4), 1329. https://doi.org/10.3390/app14041329