

An Algorithm for Finding Optimal k-Core in Attribute Networks

Abstract
1. Introduction
- Propose the idea of an attribute-optimal k-core. Since it is possible to miss the optimal solution by determining k through empirical analysis or manual selection, this article searches for the optimal k-core on an attribute graph as the target community to find the optimal solution to the problem.
- Propose the advanced query algorithm. Extract primary keys from commonly used attribute scoring functions to adapt to various scoring needs. Taking advantage of the nested nature of k-core, design bidirectional reachable tree nodes, improve the naming and storage methods of tree nodes, quickly locate tree nodes, and achieve reuse of the calculation process.
- We conducted numerous experiments on multiple ground-truth datasets. The experimental results on these datasets show that the Advanced algorithm can effectively avoid the scoring function falling into local optima. Its main time consumption is in forest creation, and the actual query time is improved by two orders of magnitude compared to BaseLine.
2. Related Work
3. Proposed Approach
3.1. Problem Formulation
- : the vertex set of subgraph ;
- : the number of vertices in , i.e., ;
- : the attribute set of vertex ;
- : the set of vertices in subgraph containing the attribute ;
3.2. Algorithms for Finding the Optimal k-Core
3.2.1. BaseLine Algorithm
- Step 1: Perform core decomposition on attribute graph to obtain the core numbers of all vertices.
- Step 2: For any , select all vertices with to construct all connected subgraphs as the candidate set.
- Step 3: Filter out the subgraphs uncovering the query node set from the candidate set, and obtain the feasible solution set.
- Step 4: Calculate attribute scores for all feasible solution , and return the subgraph with the best score as the optimal solution.
3.2.2. Advanced Algorithm
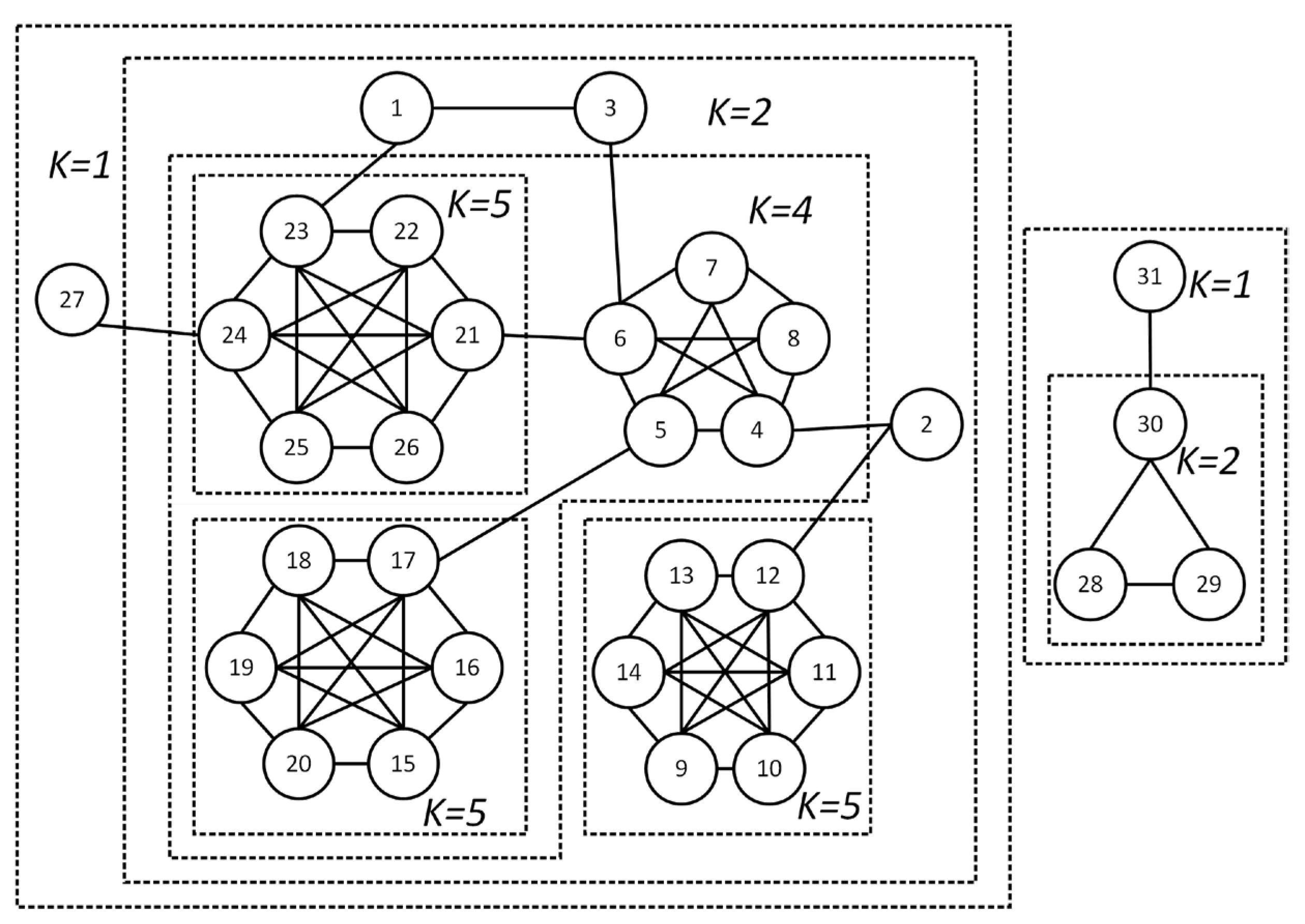
- Stage 1: Utilize the nested nature of to construct a hierarchical attribute k-core forest and sort the tree nodes.
- Stage 2: Locate the query vertex set to the relevant tree nodes, construct an initial feasible solution, and then gradually spread to the marginal tree nodes to find the optimal attribute .
- 1.
- Constructing the attribute k-core forest
- If of the connected k-shell set in equals , then add to .
- For tree nodes in the same , sort them by tree number first. Then, for nodes belonging to the same tree, sort them by the minimum rank of vertices in the vertexSet.
| Algorithm 1 Building forest |
| Input: A graph Output: the hierarchical forest 1: , 2: compute of each vertex in by core decomposition; 3: construct connected from ; 4: for in : 5: , ; 6: create root tree node and update ; 7: ; 8: update tree indicator ; 9: return . Procedure : 1: select vertices with as candidate children vertex set; 2: if candidate children vertex set is not empty: 3: obtain connected subgraphs composed of candidate vertex sets as ; 4: for each graph in : 5: ; 6: select in this graph as ; 7: create and update ; 8: update ; 9: ; 10: create attribute reverse index for ; 11: end |
- 2.
- Node localization and extended query
| Algorithm 2 LCA algorithm |
| Input: the hierarchical forest , the query vertex set Output: the lowest common ancestor 1: , , 2: for in : 3: locate according ; 4: perform a binary search the tree node , where ; 5: add to ; 6: update ; 7: end for 8: if the tree indicator are different: 9: return # the query nodes do not belong to the same tree and have no common ancestor. 10: else: 11: compute the lowest common ancestor for and as ; 12: end if |
| Algorithm 3 Expanding query algorithm |
| Input: the hierarchical fores , the query attribute set , the attribute score function and Output: the optimal attribute k-core 1: , , , 2: initialize , by traversing the subtree rooted in ; 3: compute with and ; 4: ; 5: ; 6: while exists: 7: ; 8: if has more than a child tree node: 9: for each in but not the : 10: traverse the subtree rooted on in pre-order, and iteratively update primary keys ; 11: compute of ; 12: if is better than : 13: update , ; 14: ; 15: return |
4. Experiments and Results
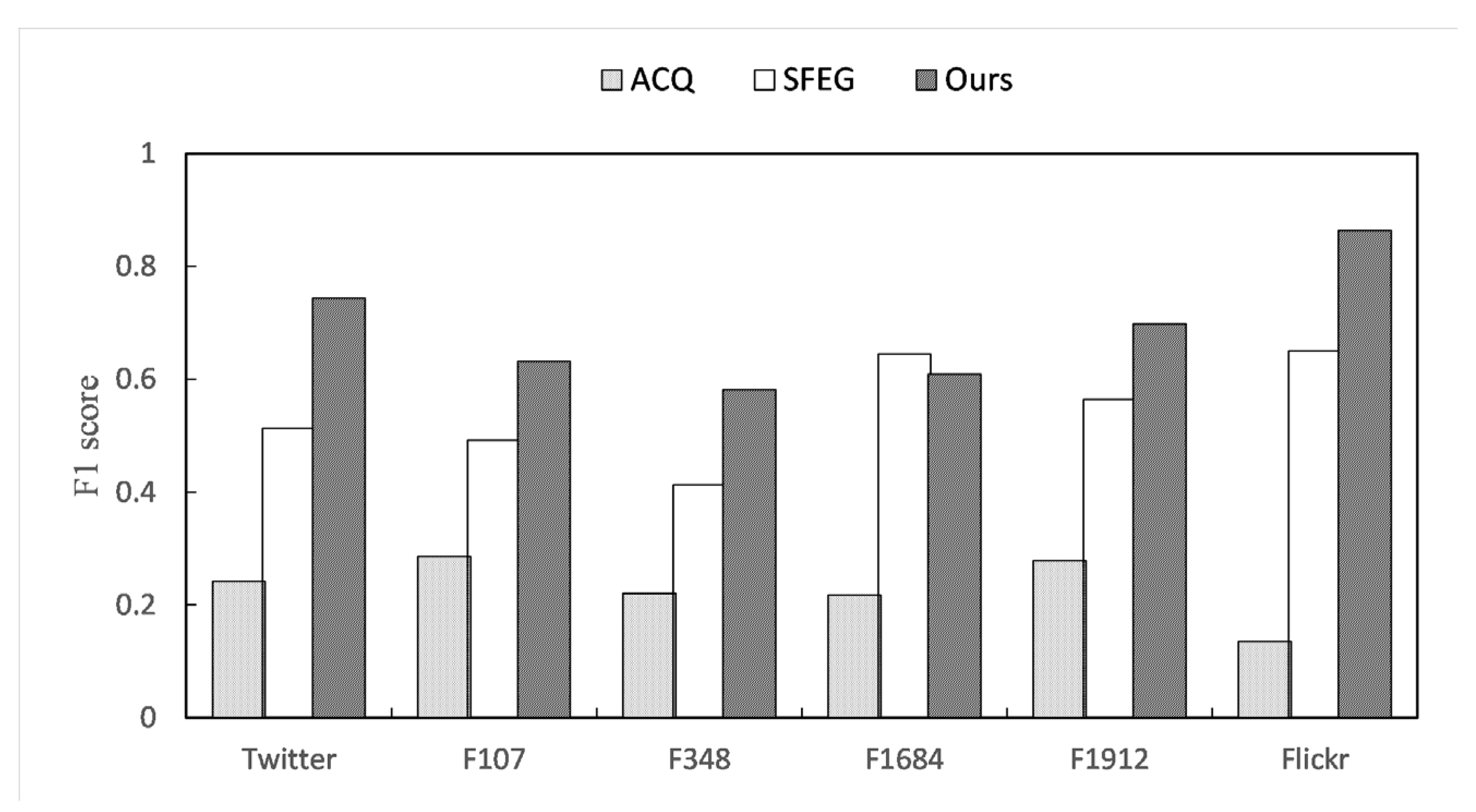
4.1. Evaluating the Effectiveness of Algorithms
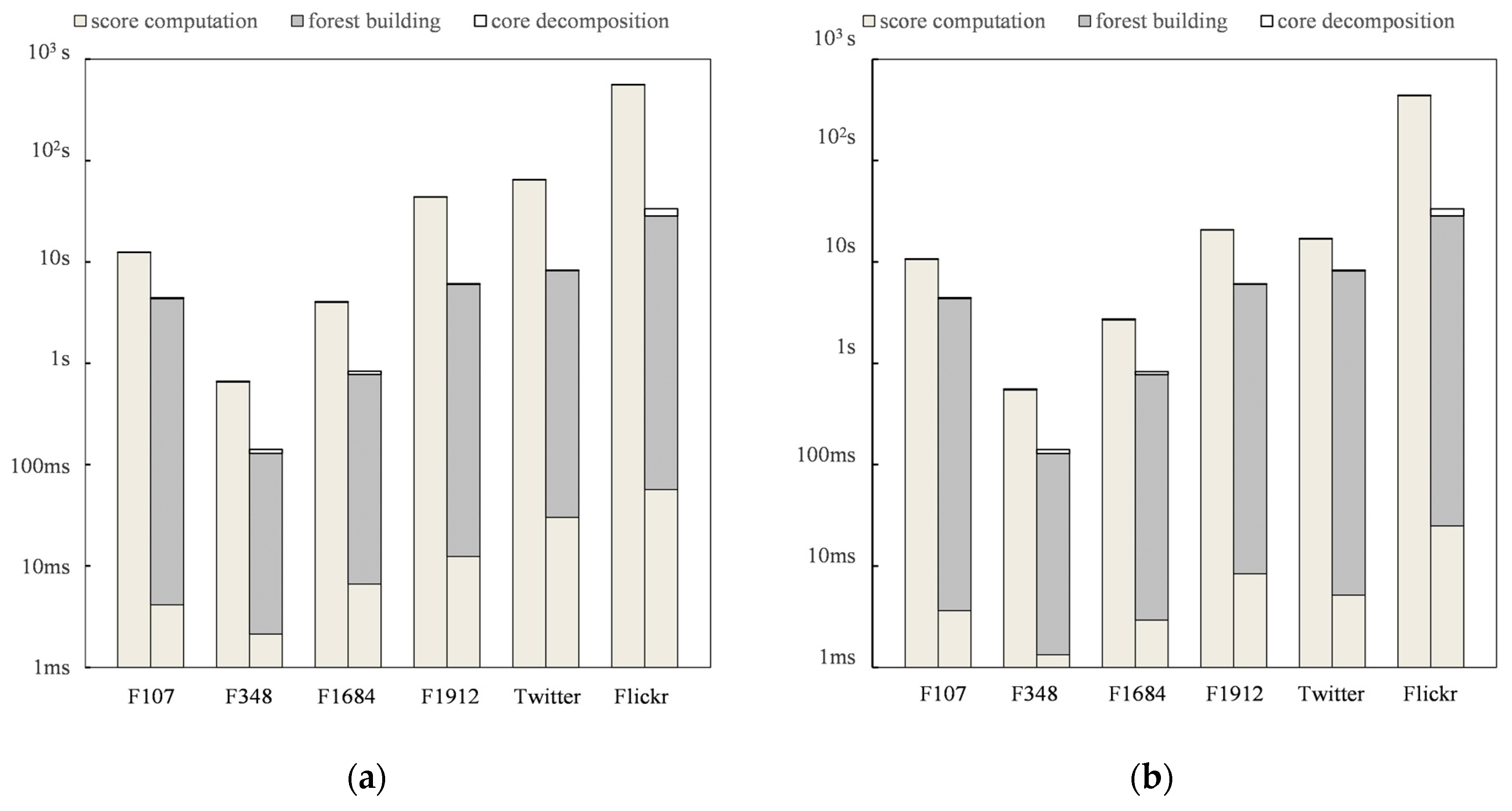
4.2. Evaluating the Performance of Algorithms
4.3. Estimating the Quality of Communities
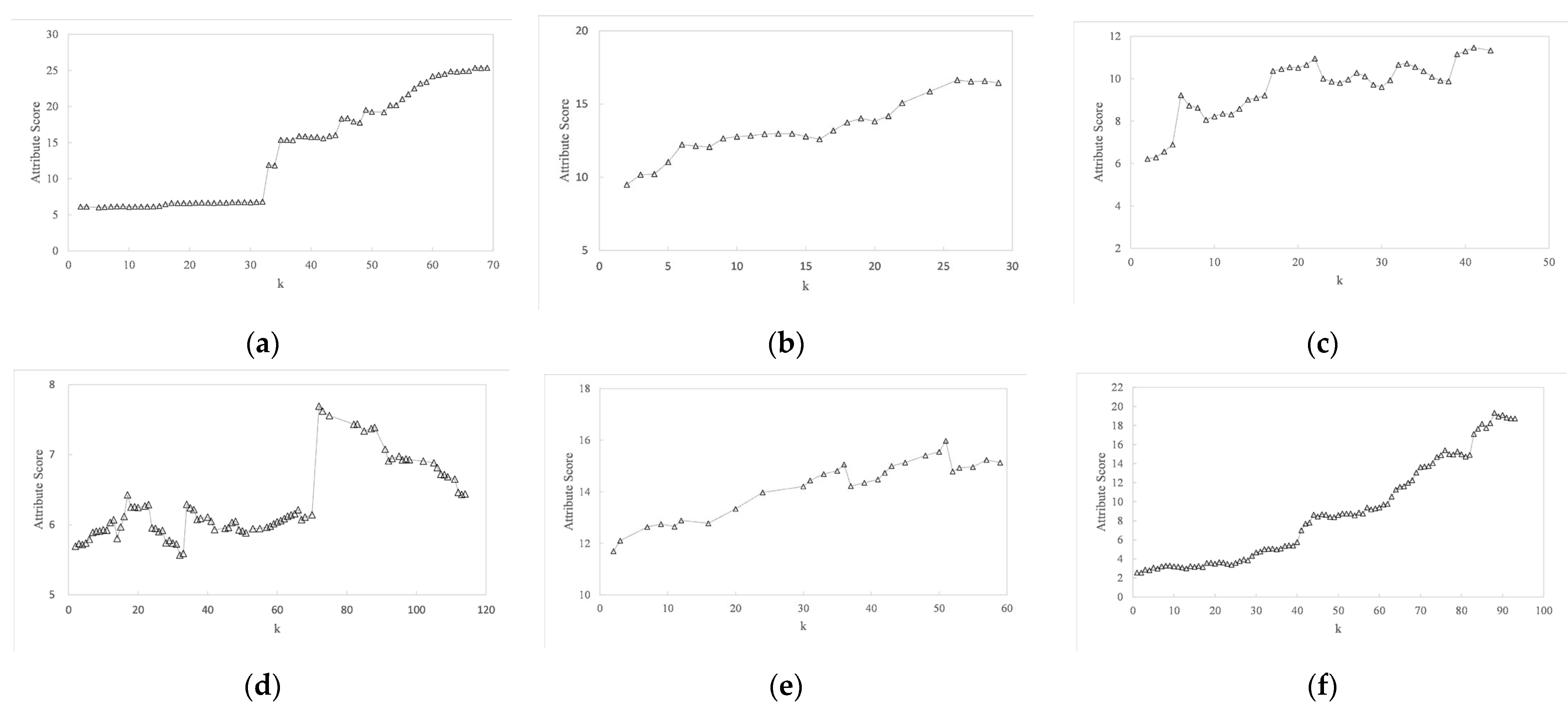
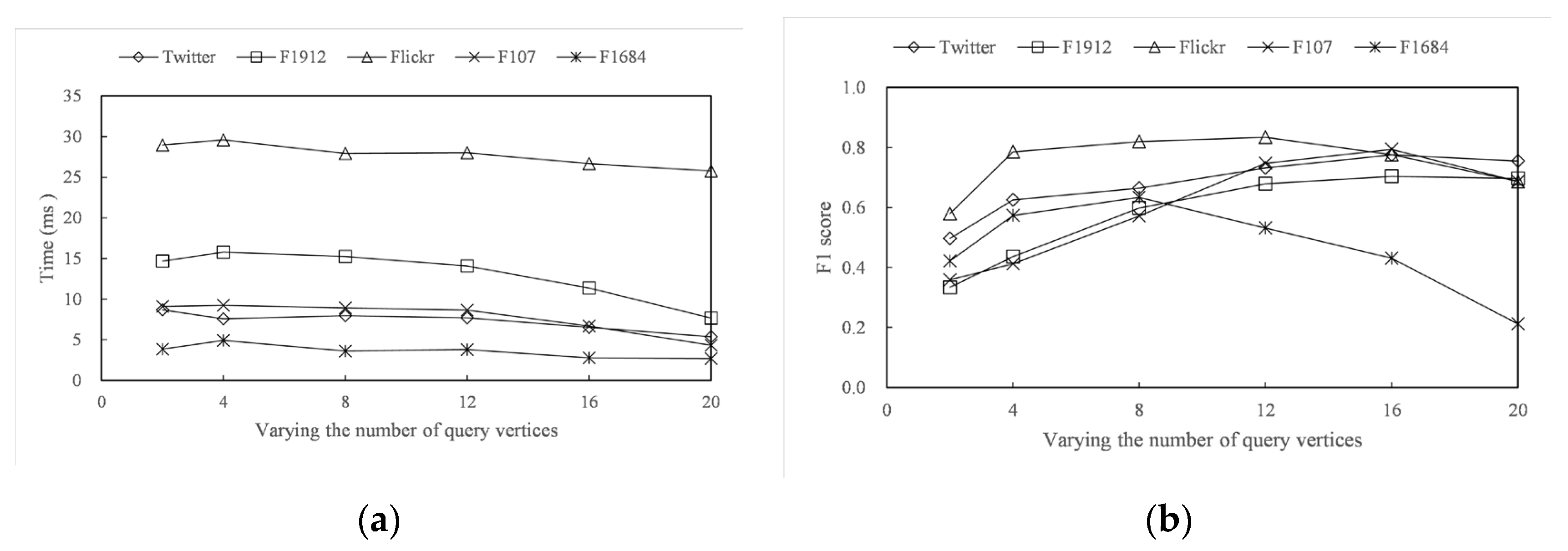
4.4. Parameter Sensitivity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, C.; Tang, Y.; Xiao, Z.; Li, T. Influential scholar recommendation model in academic social network. J. Comput. Appl. 2020, 40, 6. [Google Scholar]
- Sozio, M.; Gionis, A. The community-search problem and how to plan a successful cocktail party. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25–28 July 2010; pp. 939–948. [Google Scholar]
- Leskovec, J.; Mcauley, J. Learning to discover social circles in ego networks. Adv. Neural Inf. Process. Syst. 2012, 25, 539–547. [Google Scholar]
- Palla, G.; Derényi, I.; Farkas, I.; Vicsek, T. Uncovering the overlapping community structure of complex networks in nature and society. Nature 2005, 435, 814–818. [Google Scholar] [CrossRef] [PubMed]
- Cui, W.; Xiao, Y.; Wang, H.; Lu, Y.; Wang, W. Online search of overlapping communities. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; pp. 277–288. [Google Scholar]
- Zhu, Q.; Hu, H.; Xu, C.; Xu, J.; Lee, W.C. Geo-social group queries with minimum acquaintance constraints. VLDB J. 2017, 26, 709–727. [Google Scholar] [CrossRef]
- Xie, X.; Song, M.; Liu, C.; Zhang, J.; Li, J. Effective influential community search on attributed graph. Neurocomputing 2021, 444, 111–125. [Google Scholar] [CrossRef]
- Sun, H.; Huang, R.; Jia, X.; He, L.; Sun, M.; Wang, P.; Sun, Z.; Huang, J. Community search for multiple nodes on attribute graphs. Knowl.-Based Syst. 2020, 193, 105393. [Google Scholar] [CrossRef]
- Lin, P.; Yu, S.; Zhou, X.; Peng, P.; Li, K.; Liao, X. Community search over large semantic-based attribute graphs. World Wide Web 2022, 25, 927–948. [Google Scholar] [CrossRef]
- Seidman, S.B. Network structure and minimum degree. Soc. Netw. 1983, 5, 269–287. [Google Scholar] [CrossRef]
- Batagelj, V.; Zaversnik, M. An o (m) algorithm for cores decomposition of networks. arXiv 2003, arXiv:cs/0310049. [Google Scholar]
- Liu, B.; Zhang, F. Incremental algorithms of the core maintenance problem on edge-weighted graphs. IEEE Access 2020, 8, 63872–63884. [Google Scholar] [CrossRef]
- Chowdhary, A.A.; Liu, C.; Chen, L.; Zhou, R.; Yang, Y. Finding attribute diversified community over large attributed networks. World Wide Web 2022, 25, 569–607. [Google Scholar] [CrossRef]
- Ghosh, B.; Ali, M.E.; Choudhury, F.M.; Apon, S.H.; Sellis, T.; Li, J. The flexible socio spatial group queries. Proc. VLDB Endow. 2018, 12, 99–111. [Google Scholar] [CrossRef]
- Islam, M.S.; Ali, M.E.; Kang, Y.B.; Sellis, T.; Choudhury, F.M.; Roy, S. Keyword aware influential community search in large attributed graphs. Inf. Syst. 2022, 104, 101914. [Google Scholar] [CrossRef]
- Fang, Y.; Cheng, C.K.; Luo, S.; Hu, J. Effective community search for large attributed graphs. Proc. VLDB Endow. 2016, 9, 1233–1244. [Google Scholar] [CrossRef]
- Zhang, Z.; Huang, X.; Xu, J.; Choi, B.; Shang, Z. Keyword-centric community search. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 422–433. [Google Scholar]
- Liu, Q.; Zhu, Y.; Zhao, M.; Huang, X.; Xu, J.; Gao, Y. VAC, vertex-centric attributed community search. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 937–948. [Google Scholar]
- Huang, X.; Lakshmanan, L.V.S. Attribute truss community search. arXiv 2016, arXiv:1609.00090. [Google Scholar]
- Wang, C.; Wang, H.; Chen, H.; Li, D. Attributed community search based on effective scoring function and elastic greedy method. Inf. Sci. 2021, 562, 78–93. [Google Scholar] [CrossRef]
- Luo, J.; Cao, X.; Xie, X.; Qu, Q.; Xu, Z.; Jensen, C.S. Efficient attribute-constrained co-located community search. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1201–1212. [Google Scholar]
- Chu, D.; Zhang, F.; Lin, X.; Zhang, W.; Zhang, Y.; Xia, Y.; Zhang, C. Finding the best k in core decomposition, A time and space optimal solution. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 685–696. [Google Scholar]
- Guo, T.; Cao, X.; Cong, G. Efficient algorithms for answering the m-closest keywords query. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Victoria, Australia, 31 May–4 June 2015; pp. 405–418. [Google Scholar]
- Wang, K.; Wang, S.; Cao, X.; Qin, L. Efficient radius-bounded community search in geo-social networks. IEEE Trans. Knowl. Data Eng. 2020, 34, 4186–4200. [Google Scholar] [CrossRef]
- Luo, J.; Cao, X.; Xie, X.; Qu, Q. Best co-located community search in attributed networks. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2453–2456. [Google Scholar]
- Matula, D.W.; Beck, L.L. Smallest-last ordering and clustering and graph coloring algorithms. JACM 1983, 30, 417–427. [Google Scholar] [CrossRef]
- Sariyuce, A.E.; Seshadhri, C.; Pinar, A.; Catalyurek, U.V. Finding the hierarchy of dense subgraphs using nucleus decompositions. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 927–937. [Google Scholar]
- Lin, Z.; Zhang, F.; Lin, X.; Zhang, W.; Tian, Z. Hierarchical core maintenance on large dynamic graphs. Proc. VLDB Endow. 2021, 14, 757–770. [Google Scholar] [CrossRef]
- He, T.; Liu, Y.; Ko, T.H.; Chan, K.C.; Ong, Y.S. Contextual correlation preserving multiview featured graph clustering. IEEE Trans. Cybern. 2019, 50, 4318–4331. [Google Scholar] [CrossRef] [PubMed]
- He, T.; Bai, L.; Ong, Y.S. Vicinal vertex allocation for matrix factorization in networks. IEEE Trans. Cybern. 2021, 52, 8047–8060. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Topic | Participation Condition 1 | Structural Cohesiveness | Attribute Function | Target Community |
|---|---|---|---|---|---|
| [16] | ACS | k-core | YES | local | |
| [17] | ACS | k-core | YES | local | |
| [18] | ACS | k-truss | YES | local | |
| [19] | ACS | (k, d)-truss | YES | local | |
| [20] | ACS | ECOQUG | YES | local | |
| [22] | CD | - | k-core | NO | global |
| Ours | ACS | k-core | NO | global |
| Notation | Meaning |
|---|---|
| is an undirected attribute graph, including the vertex set , the edge set , and the attribute set . | |
| the attribute set of vertex . | |
| is the subgraph of , is the vertex set of . | |
| the number of vertices in . | |
| the core number of vertex . | |
| the core number set of graph . | |
| a connected graph composed of vertices with | |
| a vertex set with | |
| a tree node in attribute k-core forest | |
| a list of tree nodes that can be restored to |
| Dataset | |||||
|---|---|---|---|---|---|
| 2403 | 3715 | 9067 | 15 | 59 | |
| 4039 | 88,234 | 1283 | 9 | 115 | |
| Flickr | 7575 | 239,738 | 12,047 | 24 | 93 |
| F0 | F107 | F348 | F414 | F686 | F698 | F1684 | F1912 | F3437 | F3980 | Flickr | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 18 | 69 | 29 | 23 | 19 | 8 | 39 | 109 | 19 | 7 | 49 | 85 | |
| 16 | 63 | 24 | 18 | 7 | 6 | 37 | 70 | 16 | 5 | 38 | 73 | |
| 20 | 66 | 26 | 19 | 9 | 9 | 41 | 72 | 20 | 7 | 51 | 89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Zhong, Y. An Algorithm for Finding Optimal k-Core in Attribute Networks. Appl. Sci. 2024, 14, 1256. https://doi.org/10.3390/app14031256
Liu J, Zhong Y. An Algorithm for Finding Optimal k-Core in Attribute Networks. Applied Sciences. 2024; 14(3):1256. https://doi.org/10.3390/app14031256
Chicago/Turabian StyleLiu, Jing, and Yong Zhong. 2024. "An Algorithm for Finding Optimal k-Core in Attribute Networks" Applied Sciences 14, no. 3: 1256. https://doi.org/10.3390/app14031256
APA StyleLiu, J., & Zhong, Y. (2024). An Algorithm for Finding Optimal k-Core in Attribute Networks. Applied Sciences, 14(3), 1256. https://doi.org/10.3390/app14031256