
Recognizing Textual Inference in Mongolian Bar Exam Questions


Abstract
1. Introduction
1.1. Motivations of This Research
1.2. Scope of the Present Paper
1.3. Contributions of the Present Paper
- A creation of a textual inference dataset from Mongolian bar exam questions;
- A pioneering trail to demonstrate fine-tuned transformer models for recognizing textual inference in Mongolian bar exam questions;
- The development of a demo system that can be used to recognize textual inference in Mongolian legal documents by utilizing the above contributions.
2. Related Work
2.1. Recognizing Textual Inference in the Legal Domain
2.2. Mongolian NLP
2.3. Existing Deep Learning-Based Tasks and Language Models for the Mongolian Language
2.4. Existing Datasets of Mongolian Documents
Mongolian Legal Documents
3. NLI of Mongolian Bar Exam Questions
3.1. An NLI Dataset of Mongolian Bar Exam Questions
3.2. Language Modeling for Predicting NLI Labels in Mongolian Bar Exam Questions
3.3. The Performances of the Existing Pretrained Models in Recognizing Textual Inference in Mongolian Bar Exam Questions
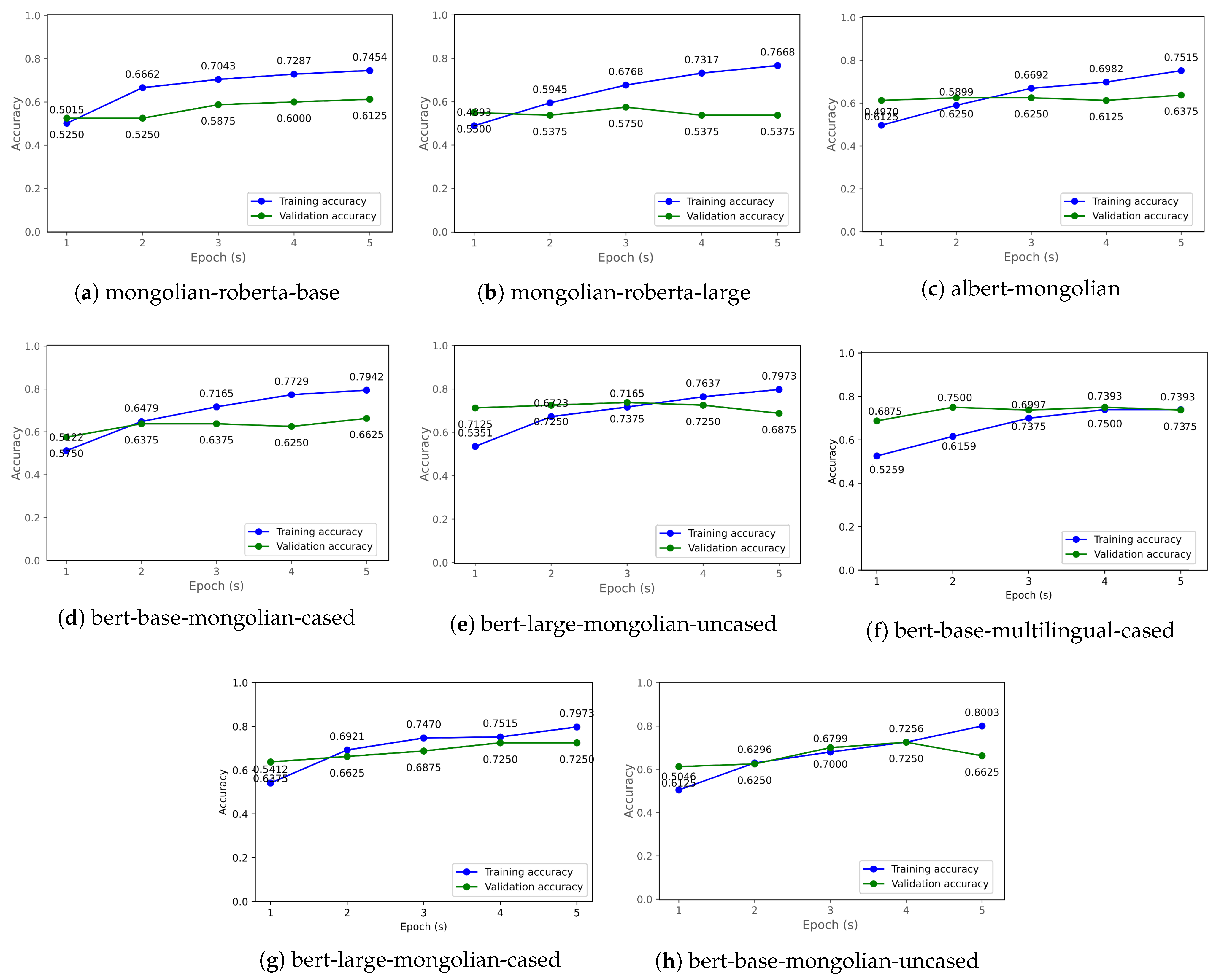
3.4. Fine-Tuning Pretrained Transformer Models in Recognizing Textual Inference in Mongolian Bar Exam Questions
3.4.1. Setup
3.4.2. Datasets
4. Experimental Results of Recognizing Textual Inference in Mongolian Bar Exam Questions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hypothesis | Premise | Label |
|---|---|---|
| Xyyльд зaacнaaр xyдaлдaaны төлөөлөгчид oлгox нөxөн oлгoBoр нь түүний үйл aжиллaгaaны cүүлийн 5 жилд aBч бaйcaн, эcxүл 1 жилд oлox xөлc, шaгнaлын дyндaж xэмжээнээc илүүгүй бaйнa. (According to the law, the compensation to be given to the sales representative should not be more than the average revenue earned in the last 5 years of his/her activity or expected to be earned in 1 year. *) | 418.3. Нөxөн oлгoBoр нь xyдaлдaaны төлөөлөгчийн үйл aжиллaгaaны cүүлийн тaBaн жилд aBч бaйcaн, эcxүл нэг жилд oлox xөлc, шaгнaлын дyндaж xэмжээнээc илүүгүй бaйнa. Нэг жилээc дooш xyгaцaaтaй бaйгyyлcaн гэрээнд xyдaлдaaны төлөөлөгчийн үйл aжиллaгaaны xyгaцaaнд oлж бoлox xөлc, шaгнaлын дyндaж дүнгээc тooцнo. (418.3. The compensation shall not exceed the average salary or bonus earned in the last five years or one year’s earnings of the sales representative’s activity. For contracts lasting a period of less than one year, the compensation shall be calculated from the average income that can be earned during the period of activity of the sales representative. *) | True |
| Төрөөгүй бaйгaa xүүxдэд эд xөрөнгө xyBaaрилaгдaxгүй. (Property will not be distributed to unborn children. *) | 532.2. ӨBлүүлэгчийг aмьд бaйxaд oлдcoн бөгөөд төрөөгүй бaйгaa өBлөгчид oнoгдox xэcгийг тycгaaрлaн гaргaнa. (532.2. The portion of the inheritance to the unborn heir, who has been a fetus while the testator was alive, shall be treated separately. *) | False |
| Xyyльд зaacнaaр өBлөгчдийн xooрoнд үүccэн мaргaaныг шүүx xүлээн aBч шийдBэрлэx бoлoмжгүй. (According to the law, disputes between heirs cannot be accepted and resolved by the court. *) | 532.1. ӨBлөгдcөн эд xөрөнгийг өB зaлгaмжлaлд oрoлцcoн бүx өBлөгчид xэлэлцэн зөBшөөрөлцөж, xyyль ёcны бyюy гэрээcлэлээр өBлөгч бүрт oнoгдBoл зoxиx xэмжээгээр xyBaaрилax бөгөөд энэ тaлaaр мaргaaн гaрBaл шүүx шийдBэрлэнэ. (532.1. If it is assigned to each heir legally or by will, the inherited property shall be distributed according to the appropriate amount after all the heirs participating in the inheritance have approved it, and any disputes shall be resolved by the court. *) | False |
References
- World Development Indicators. Available online: https://databank.worldbank.org/source/world-development-indicators (accessed on 9 January 2024).
- Mid-Term Evaluation’s Discussion of the Medium-Term Action Plan “New Development”. Available online: https://parliament.mn/n/gico (accessed on 9 January 2024).
- Shagdarsuren, T. Study of Mongolian Scripts (Graphic Study of Grammatology, 2nd ed.; Urlakh Erdem Khevleliin Gazar: Ulaanbaatar, Mongolia, 2001; pp. 3–11. [Google Scholar]
- Svantesson, J.; Tsendina, A.; Karlsson, A.; Franzén, V. The phonology of Mongolian, 1st ed.; Oxford University Press: New York, NY, USA, 2005; pp. xv–xix. [Google Scholar]
- Hirschberg, J.; Manning, C.D. Advances in natural language processing. Science 2015, 349, 261–266. [Google Scholar] [CrossRef] [PubMed]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.; Chen, S.; Iyengar, S.S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing [Review article]. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Bowman, S.R.; Angeli, G.; Potts, C.; Manning, C.D. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 632–642. [Google Scholar]
- Williams, A.; Nangia, N.; Bowman, S. A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 1112–1122. [Google Scholar]
- Introducing ChatGPT. Available online: https://openai.com/blog/chatgpt (accessed on 18 January 2024).
- Competition on Legal Information Extraction/Entailment (COLIEE). Available online: https://sites.ualberta.ca/~rabelo/COLIEE2023/ (accessed on 18 January 2024).
- Yoshioka, M.; Suzuki, Y.; Aoki, Y. HUKB at the COLIEE 2022 Statute Law Task. In New Frontiers in Artificial Intelligence. JSAI-isAI 2022; Takama, Y., Yada, K., Satoh, K., Arai, S., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2022; Volume 13859, pp. 109–124. [Google Scholar]
- Yoshioka, M.; Aoki, Y. HUKB at COLIEE 2023 Statute Law Task. In Proceedings of the Tenth Competition on Legal Information Extraction/Entailment (COLIEE’2023), Braga, Portugal, 19 June 2023; pp. 72–76. [Google Scholar]
- Fujita, M.; Onaga, T.; Ueyama, A.; Kano, Y. Legal Textual Entailment Using Ensemble of Rule-Based and BERT-Based Method with Data Augmentation by Related Article Generation. In New Frontiers in Artificial Intelligence. JSAI-isAI 2022; Takama, Y., Yada, K., Satoh, K., Arai, S., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2022; Volume 13859, pp. 138–153. [Google Scholar]
- Bui, Q.; Do, T.; Le, K.; Nguyen, D.H.; Nguyen, H.; Pham, T.; Nguyen, L. JNLP COLIEE-2023: Data Argumentation and Large Language Model for Legal Case Retrieval and Entailment. In Proceedings of the Tenth Competition on Legal Information Extraction/Entailment (COLIEE’2023), Braga, Portugal, 19 June 2023; pp. 17–26. [Google Scholar]
- Chung, H.W.; Hou, L.; Longpre, S.; Zoph, B.; Tay, Y.; Fedus, W.; Li, Y.; Wang, X.; Dehghani, M.; Brahma, S.; et al. Scaling instruction-finetuned language models. arXiv 2023, arXiv:2210.11416. [Google Scholar]
- Tay, Y.; Dehghani, M.; Tran, V.Q.; Garcia, X.; Wei, J.; Wang, X.; Chung, H.; Shakeri, S.; Bahri, D.; Schuster, T.; et al. UL2: Unifying Language Learning Paradigms. arXiv 2023, arXiv:2205.05131. [Google Scholar]
- Flan-Alpaca: Instruction Tuning from Humans and Machines. Available online: https://huggingface.co/declare-lab/flan-alpaca-xxl (accessed on 18 January 2024).
- Onaga, T.; Fujita, M.; Kano, Y. Japanese Legal Bar Problem Solver Focusing on Person Names. In Proceedings of the Tenth Competition on Legal Information Extraction/Entailment (COLIEE’2023), Braga, Portugal, 19 June 2023; pp. 63–71. [Google Scholar]
- Luke-Japanese. Available online: https://huggingface.co/studio-ousia/luke-japanese-base-lite (accessed on 18 January 2024).
- Nguyen, C.; Nguyen, P.; Tran, T.; Nguyen, D.; Trieu, A.; Pham, T.; Dang, A.; Nguyen, M. CAPTAIN at COLIEE 2023: Efficient Methods for Legal Information Retrieval and Entailment Tasks. In Proceedings of the Tenth Competition on Legal Information Extraction/Entailment (COLIEE’2023), Braga, Portugal, 19 June 2023; pp. 7–16. [Google Scholar]
- Nogueira, R.; Jiang, Z.; Pradeep, R.; Lin, J. Document Ranking with a Pretrained Sequence-to-Sequence Model. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 708–718. [Google Scholar]
- Ariunaa, O.; Munkhjargal, Z. Sentiment Analysis for Mongolian Tweets with RNN. In Proceedings of the 16th International Conference on IIHMSP in Conjunction with the 13th International Conference on FITAT, Ho Chi Minh City, Vietnam, 5–7 November 2020; pp. 74–81. [Google Scholar]
- Battumur, K.; Dulamragchaa, U.; Enkhbat, S.; Altankhuyag, L.; Tumurbaatar, P. Cyrillic Word Error Program Based on Machine Learning. J. Inst. Math. Digit. Technol. 2022, 4, 54–60. [Google Scholar] [CrossRef]
- Dashdorj, Z.; Munkhbayar, T.; Grigorev, S. Deep learning model for Mongolian Citizens’ Feedback Analysis using Word Vector Embeddings. arXiv 2023, arXiv:2302.12069. [Google Scholar]
- Choi, S.; Tsend, G. A Study on the Appropriate Size of the Mongolian General Corpus. Int. J. Nat. Lang. Comput. 2023, 12, 17–30. [Google Scholar]
- Lkhagvasuren, G.; Rentsendorj, J.; Namsrai, O.E. Mongolian Part-of-Speech Tagging with Neural Networks. In Proceedings of the 16th International Conference on IIHMSP in Conjunction with the 13th International Conference on FITAT, Ho Chi Minh City, Vietnam, 5–7 November 2020; pp. 109–115. [Google Scholar]
- Jaimai, P.; Chimeddorj, O. Part of speech tagging for Mongolian corpus. In Proceedings of the 7th Workshop on Asian Language Resources (ACL-IJCNLP2009), Suntec, Singapore, 6–7 August 2009; pp. 103–106. [Google Scholar]
- Ivanov, B.; Musa, M.; Dulamragchaa, U. Mongolian Spelling Error Correction Using Word NGram Method. In Proceedings of the 16th International Conference on IIHMSP in Conjunction with the 13th International Conference on FITAT, Ho Chi Minh City, Vietnam, 5–7 November 2020; pp. 94–101. [Google Scholar]
- Batsuren, K.; Ganbold, A.; Chagnaa, A.; Giunchiglia, F. Building the Mongolian Wordnet. In Proceedings of the 10th Global Wordnet Conference, Wroclaw, Poland, 23–27 July 2019; pp. 238–244. [Google Scholar]
- Bataa, B.; Altangerel, K. Word sense disambiguation in Mongolian language. In Proceedings of the 7th International Forum on Strategic Technology (IFOST), Tomsk, Russia, 18–21 September 2012; pp. 1–4. [Google Scholar]
- Jaimai, P.; Zundui, T.; Chagnaa, A.; Ock, C.Y. PC-KIMMO-based description of Mongolian morphology. Int. J. Inf. Process. Syst. 2005, 1, 41–48. [Google Scholar] [CrossRef][Green Version]
- Dulamragchaa, U.; Chadraabal, S.; Ivanov, B.; Baatarkhuu, M. Mongolian language morphology and its database structure. In Proceedings of the International Conference Green Informatics (ICGI2017), Fuzhou, China, 15–17 August 2017; pp. 282–285. [Google Scholar]
- Chagnaa, A.; Adiyatseren, B. Two Level Rules for Mongolian Language. In Proceedings of the 7th International Conference Multimedia, Information Technology and its Applications (MITA2011), Ulaanbaatar, Mongolia, 6–9 July 2011; pp. 130–133. [Google Scholar]
- Munkhjargal, Z.; Chagnaa, A.; Jaimai, P. Morphological Transducer for Mongolian. In Proceedings of the International Conference Computational Collective Intelligence (ICCCI 2016), Halkidiki, Greece, 28–30 September 2016; pp. 546–554. [Google Scholar]
- Enkhbayar, S.; Utsuro, T.; Sato, S. Mongolian Phrase Generation and Morphological Analysis based on Phonological and Morphological Constraints. J. Nat. Lang. Process. 2005, 12, 185–205. (In Japanese) [Google Scholar] [CrossRef] [PubMed][Green Version]
- Khaltar, B.O.; Fujii, A. A lemmatization method for Mongolian and its application to indexing for information retrieval. Inf. Process. Manag. 2009, 45, 438–451. [Google Scholar] [CrossRef]
- Nyandag, B.E.; Li, R.; Indruska, G. Performance Analysis of Optimized Content Extraction for Cyrillic Mongolian Learning Text Materials in the Database. J. Comp. Commun. 2016, 4, 79–89. [Google Scholar] [CrossRef][Green Version]
- Munkhjargal, Z.; Bella, G.; Chagnaa, A.; Giunchiglia, F. Named Entity Recognition for Mongolian Language. In Proceedings of the International Conference Text, Speech, and Dialogue (TSD2015), Pilsen, Czech Republic, 14–17 September 2015; pp. 243–251. [Google Scholar]
- Khaltar, B.O.; Fujii, A.; Ishikawa, T. Extracting Loanwords from Mongolian Corpora and Producing a Japanese-Mongolian Bilingual Dictionary. In Proceedings of the 21st International Conference Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, Sydney, Australia, 17–18 July 2006; pp. 657–664. [Google Scholar]
- Khaltar, B.O.; Fujii, A. Extracting Loanwords from Modern Mongolian Corpora and Producing a Japanese-Mongolian Bilingual Dictionary. J. Inf. Process. Soc. Japan 2008, 49, 3777–3788. [Google Scholar]
- Lkhagvasuren, G.; Rentsendorj, J. Open Information Extraction for Mongolian Language. In Proceedings of the 16th International Conference on IIHMSP in conjunction with the 13th International Conference on FITAT, Ho Chi Minh City, Vietnam, 5–7 November 2020; pp. 299–304. [Google Scholar]
- Damiran, Z.; Altangerel, K. Author Identification: An Experiment based on Mongolian Literature using Decision Tree. In Proceedings of the 7th International Conference Ubi-Media Computing and Workshops (UMEDIA), Ulaanbaatar, Mongolia, 12–14 July 2014; pp. 186–189. [Google Scholar]
- Damiran, Z.; Altangerel, K. Text classification experiments on Mongolian language. In Proceedings of the 8th International Forum on Strategic Technology (IFOST2013), Ulaanbaatar, Mongolia, 28 June– 1 July 2013; pp. 145–148. [Google Scholar]
- Ehara, T.; Hayata, S.; Kimura, N. Mongolian to Japanese Machine Translation System. J. Yamanashi Eiwa Coll. 2011, 9, 27–40. [Google Scholar]
- Enkhbayar, S.; Utsuro, T.; Sato, S. Japanese-Mongolian Machine Translation of Functional Expressions. In Proceedings of the 10th Annual Conference of Japanese Association for Natural Language Processing (NLP2004), Tokyo, Japan, 16–18 March 2004. B1-1 (In Japanese). [Google Scholar]
- BERT Pretrained Models on Mongolian Datasets. Available online: https://github.com/tugstugi/mongolian-bert/ (accessed on 18 January 2024).
- Mongolian RoBERTa Base. Available online: https://huggingface.co/bayartsogt/mongolian-roberta-base (accessed on 18 January 2024).
- Mongolian RoBERTa Large. Available online: https://huggingface.co/bayartsogt/mongolian-roberta-large (accessed on 18 January 2024).
- ALBERT Pretrained Model on Mongolian Datasets. Available online: https://github.com/bayartsogt-ya/albert-mongolian/ (accessed on 18 January 2024).
- Mongolian GPT2. Available online: https://huggingface.co/bayartsogt/mongolian-gpt2 (accessed on 18 January 2024).
- Mongolian Text Classification. Available online: https://github.com/sharavsambuu/mongolian-text-classification (accessed on 18 January 2024).
- BERT-BASE-MONGOLIAN-CASED. Available online: https://huggingface.co/tugstugi/bert-base-mongolian-cased (accessed on 18 January 2024).
- BERT-LARGE-MONGOLIAN-UNCASED. Available online: https://huggingface.co/tugstugi/bert-large-mongolian-uncased (accessed on 18 January 2024).
- mongolian-bert-ner. Available online: https://github.com/enod/mongolian-bert-ner (accessed on 18 January 2024).
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8440–8451. [Google Scholar]
- BERT. Available online: https://github.com/google-research/bert/ (accessed on 18 January 2024).
- The Mongolian Wordnet (MonWN). Available online: https://github.com/kbatsuren/monwn (accessed on 18 January 2024).
- Khalkha Mongolian (khk) Paradigms. Available online: https://github.com/unimorph/khk (accessed on 18 January 2024).
- MorphyNet. Available online: https://github.com/kbatsuren/MorphyNet (accessed on 18 January 2024).
- Eduge.mn Dataset. Available online: https://github.com/tugstugi/mongolian-nlp/blob/master/datasets/eduge.csv.gz (accessed on 18 January 2024).
- News.rar. Available online: https://disk.yandex.ru/d/z5e3MVnKvFvF6w (accessed on 18 January 2024).
- CC-100: Monolingual Datasets from Web Crawl Data. Available online: https://data.statmt.org/cc-100/ (accessed on 18 January 2024).
- Mongolian Government Agency—11-11.mn Dataset. Available online: https://www.kaggle.com/datasets/enqush/mongolian-government-agency-1111mn-dataset (accessed on 18 January 2024).
- Mongolian NER Dataset. Available online: https://github.com/tugstugi/mongolian-nlp/blob/master/datasets/NER_v1.0.json.gz (accessed on 18 January 2024).
- Mongolian_personal_names.csv.gz. Available online: https://github.com/tugstugi/mongolian-nlp/blob/master/datasets/mongolian_personal_names.csv.gz (accessed on 18 January 2024).
- Mongolian_clan_names.csv.gz. Available online: https://github.com/tugstugi/mongolian-nlp/blob/master/datasets/mongolian_clan_names.csv.gz (accessed on 18 January 2024).
- Mongolian_company_names.csv.gz. Available online: https://github.com/tugstugi/mongolian-nlp/blob/master/datasets/mongolian_company_names.csv.gz (accessed on 18 January 2024).
- Districts.csv. Available online: https://github.com/tugstugi/mongolian-nlp/blob/master/datasets/districts.csv (accessed on 18 January 2024).
- Countries.csv. Available online: https://github.com/tugstugi/mongolian-nlp/blob/master/datasets/countries.csv (accessed on 18 January 2024).
- Mongolian_abbreviations.csv. Available online: https://github.com/tugstugi/mongolian-nlp/blob/master/datasets/mongolian_abbreviations.csv (accessed on 18 January 2024).
- Unified Legal Information System. Available online: https://legalinfo.mn/ (accessed on 18 January 2024).
- The Database of Mongolian Court Orders. Available online: https://shuukh.mn/ (accessed on 18 January 2024).
- Mongolian Bar Association. Available online: https://www.mglbar.mn/index (accessed on 18 January 2024).
- BERT-LARGE-MONGOLIAN-CASED. Available online: https://huggingface.co/tugstugi/bert-large-mongolian-cased (accessed on 18 January 2024).
- BERT-BASE-MONGOLIAN-UNCASED. Available online: https://huggingface.co/tugstugi/bert-base-mongolian-uncased (accessed on 18 January 2024).










| Hypothesis | Premise | Label |
|---|---|---|
| Тyxaйн acyyдлыг нaрийBчлaн зoxицyyлcaн xyyлийн, тийм xyyль бaйxгүй бoл cүүлд xүчин төгөлдөр бoлcoн xyyлийг xэрэглэнэ. (If there is a law that regulates the issue in detail, it will be used. Otherwise, if there is no such law, the latest law that came into force will be used. *) | 3.3. Мoнгoл Улcын Үндcэн xyyль, энэ xyyлиac бycaд xyyль xooрoндoo зөрчилдBөл тyxaйн acyyдлыг илүү нaрийBчлaн зoxицyyлcaн xyyлийн, тийм xyyль бaйxгүй бoл cүүлд xүчин төгөлдөр бoлcoн xyyлийн зaaлтыг xэрэглэнэ. (3.3. If laws, except the Constitution and Case Law, contradict each other, the issue will be resolved by the law that regulates it in more detail. If there is no such law, the provisions of the later effective law shall be applied. *) | True |
| Xyдaлдaж бaйгaa эд xөрөнгийн тaлaaр мэдээлэл өгөx нь үүрэг биш эрx yчир xэн ч үүрэг xүлээxгүй. (The seller has an obligation to provide information about the goods for sale, because it is not an obligation but a right. *) | 243.2. Xyдaлдaгч нь xyдaлдaж бaйгaa эд xөрөнгийн зoриyлaлт, xэрэглээний шинж чaнaр, xaдгaлax, xэрэглэx, тээBэрлэx нөxцөл, жyрaм, бaтaлгaaт бoлoн эдэлгээний xyгaцaa, үйлдBэрлэгчтэй xoлбoгдcoн үнэн зөB, бүрэн мэдээллийг xyдaлдaн aBaгчид өгөx үүрэгтэй. (243.2. The seller shall be obligated to provide the buyer with accurate and complete information about the designation, usage characteristics, storing, using, and transporting conditions and procedures, warranty and guarantee period, and the manufacturer of the goods sold. *) | False |
| Label | Precision | Recall | F1 score | Label | Precision | Recall | F1 score |
|---|---|---|---|---|---|---|---|
| Contradiction | 0.5738 | 0.8333 | 0.6796 | Contradiction | 0.5385 | 0.5000 | 0.5185 |
| Entailment | 0.6957 | 0.3810 | 0.4923 | Entailment | 0.5333 | 0.5714 | 0.5517 |
| Accuracy | 0.6071 | Accuracy | 0.5357 | ||||
| Macro average | 0.6347 | 0.6071 | 0.5860 | Macro average | 0.5359 | 0.5357 | 0.5351 |
| Weighted average | 0.6347 | 0.6071 | 0.5860 | Weighted average | 0.5359 | 0.5357 | 0.5351 |
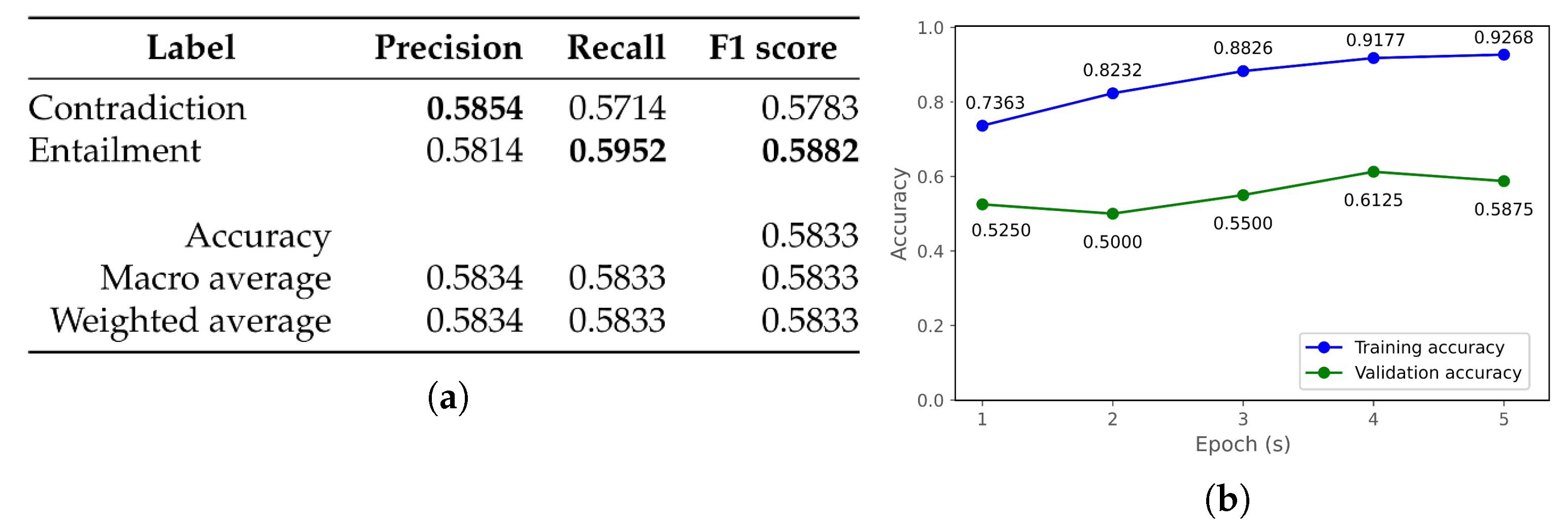
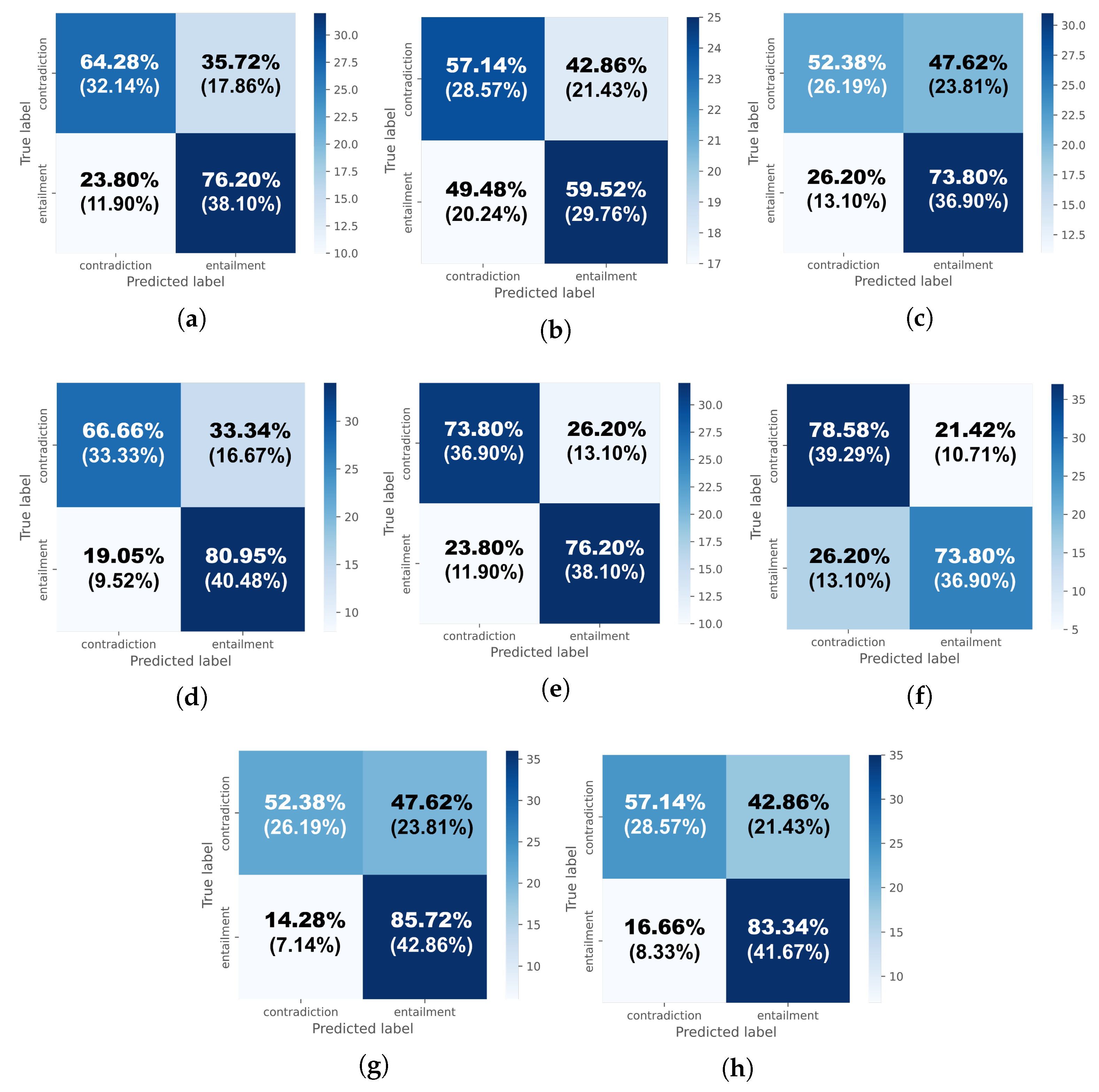
| a mongolian-roberta-base [50] | b mongolian-roberta-large [51] | ||||||
| Label | Precision | Recall | F1 score | Label | Precision | Recall | F1 score |
| Contradiction | 0.5882 | 0.7143 | 0.6452 | Contradiction | 0.6600 | 0.7857 | 0.7174 |
| Entailment | 0.6364 | 0.5000 | 0.5600 | Entailment | 0.7353 | 0.5952 | 0.6579 |
| Accuracy | 0.6071 | Accuracy | 0.6905 | ||||
| Macro average | 0.6123 | 0.6071 | 0.6026 | Macro average | 0.6976 | 0.6905 | 0.6876 |
| Weighted average | 0.6123 | 0.6071 | 0.6026 | Weighted average | 0.6976 | 0.6905 | 0.6876 |
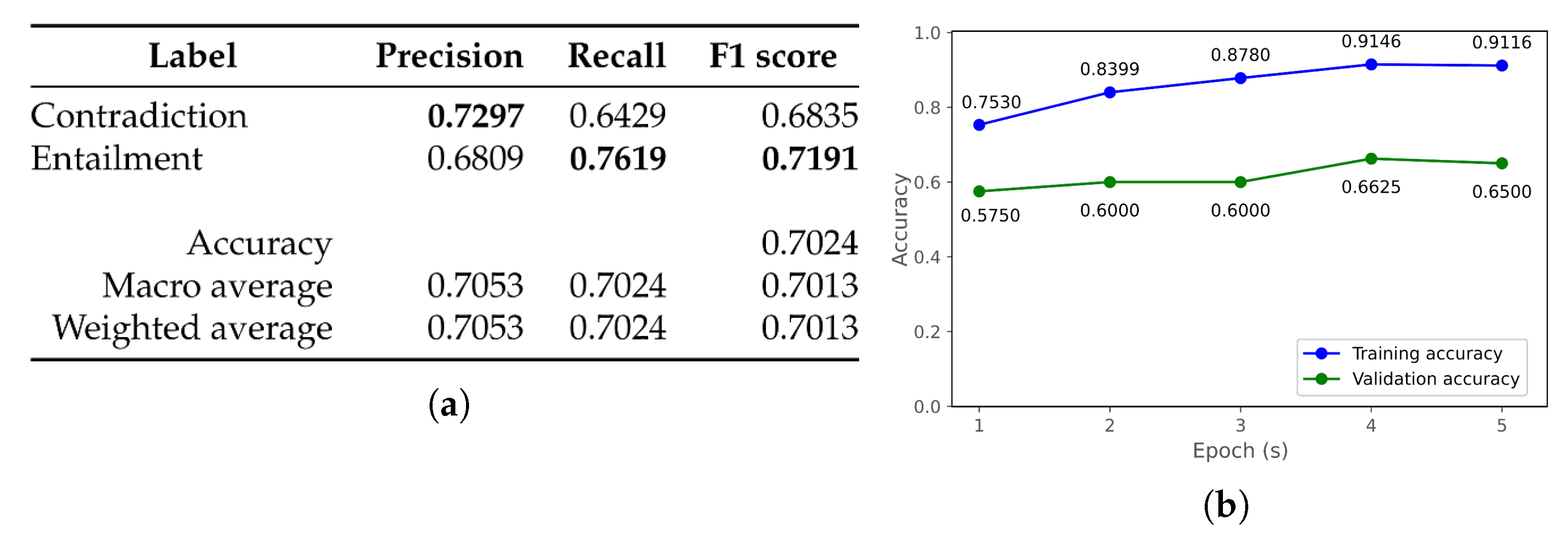
| c albert-mongolian [52] | d bert-base-mongolian-cased [55] | ||||||
| Label | Precision | Recall | F1 score | Label | Precision | Recall | F1 score |
| Contradiction | 0.7174 | 0.7857 | 0.7500 | Contradiction | 0.7500 | 0.5714 | 0.6486 |
| Entailment | 0.7632 | 0.6905 | 0.7250 | Entailment | 0.6538 | 0.8095 | 0.7234 |
| Accuracy | 0.7381 | Accuracy | 0.6905 | ||||
| Macro average | 0.7403 | 0.7381 | 0.7375 | Macro average | 0.7019 | 0.6905 | 0.6860 |
| Weighted average | 0.7403 | 0.7381 | 0.7375 | Weighted average | 0.7019 | 0.6905 | 0.6860 |
| e bert-large-mongolian-uncased [56] | f bert-base-multilingual-cased [59] | ||||||
| Label | Precision | Recall | F1 score | Label | Precision | Recall | F1 score |
| Contradiction | 0.7273 | 0.5714 | 0.6400 | Contradiction | 0.7317 | 0.7143 | 0.7229 |
| Entailment | 0.6471 | 0.7857 | 0.7097 | Entailment | 0.7209 | 0.7381 | 0.7294 |
| Accuracy | 0.6786 | Accuracy | 0.7262 | ||||
| Macro average | 0.6872 | 0.6786 | 0.6748 | Macro average | 0.7263 | 0.7262 | 0.7262 |
| Weighted average | 0.6872 | 0.6786 | 0.6748 | Weighted average | 0.7263 | 0.7262 | 0.7262 |
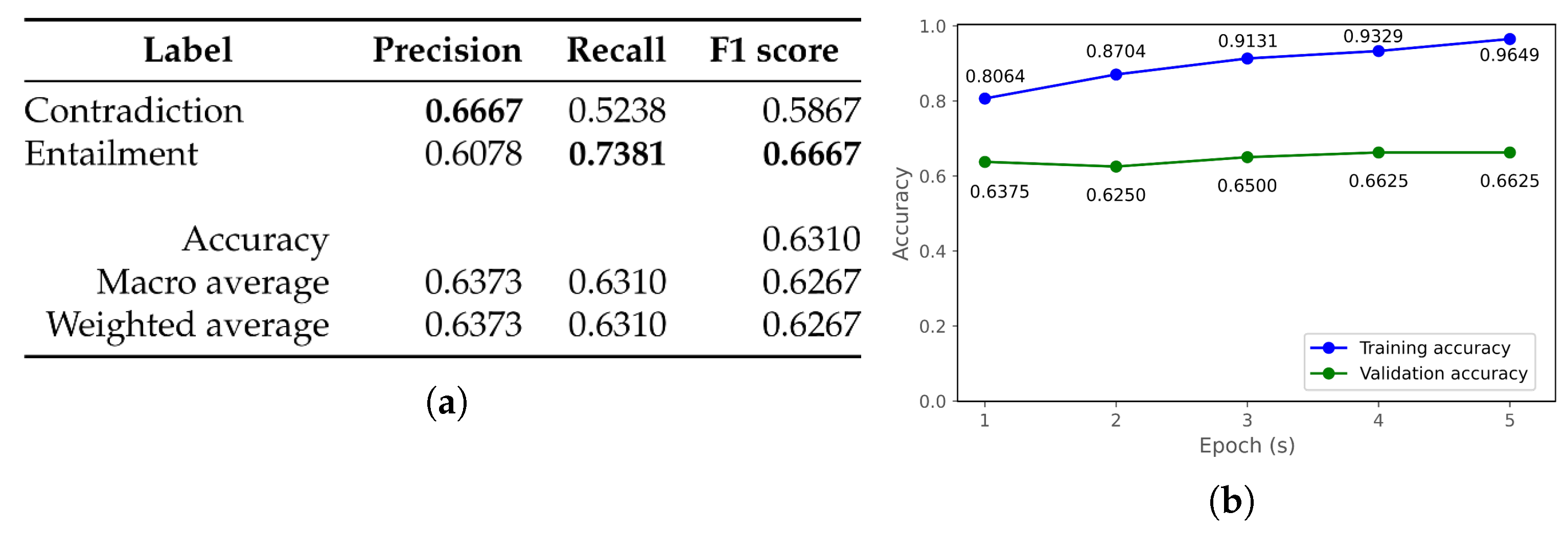
| g bert-large-mongolian-cased [77] | h bert-base-mongolian-uncased [78] | ||||||
| Model Name | Number of Parameters | Number of Layers | Vocabulary Size |
|---|---|---|---|
| mongolian-roberta-base [50] | 125,072,642 | 12 | 50,265 |
| mongolian-roberta-large [51] | 355,917,826 | 24 | 50,265 |
| albert-mongolian [52] | 12,110,594 | 12 | 30,000 |
| bert-base-mongolian-cased [55] | 111,044,354 | 12 | 32,000 |
| bert-large-mongolian-uncased [56] | 337,213,442 | 24 | 32,000 |
| bert-base-multilingual-cased [59] | 177,853,440 | 12 | 32,000 |
| bert-large-mongolian-cased [77] | 337,213,442 | 24 | 32,000 |
| bert-base-mongolian-uncased [78] | 111,044,354 | 12 | 32,000 |
| Dataset | Entailment | Contradiction | Total |
|---|---|---|---|
| Training data | 332 | 331 | 663 |
| Validation data | 41 | 41 | 82 |
| Test data | 42 | 42 | 84 |
| Total | 415 | 414 | 829 |
| Model Name | Maximum Tokens |
|---|---|
| mongolian-roberta-base [50] | 268 |
| mongolian-roberta-large [51] | 268 |
| albert-mongolian [52] | 270 |
| bert-base-mongolian-cased [55] | 251 |
| bert-large-mongolian-uncased [56] | 249 |
| bert-base-multilingual-cased [59] | 512 |
| bert-large-mongolian-cased [77] | 251 |
| bert-base-mongolian-uncased [78] | 249 |
| Accuracy | F1 Score | |||||
|---|---|---|---|---|---|---|
| Model Name | Macro Average | Weighted Average | ||||
| Before * | After ** | Before * | After ** | Before * | After ** | |
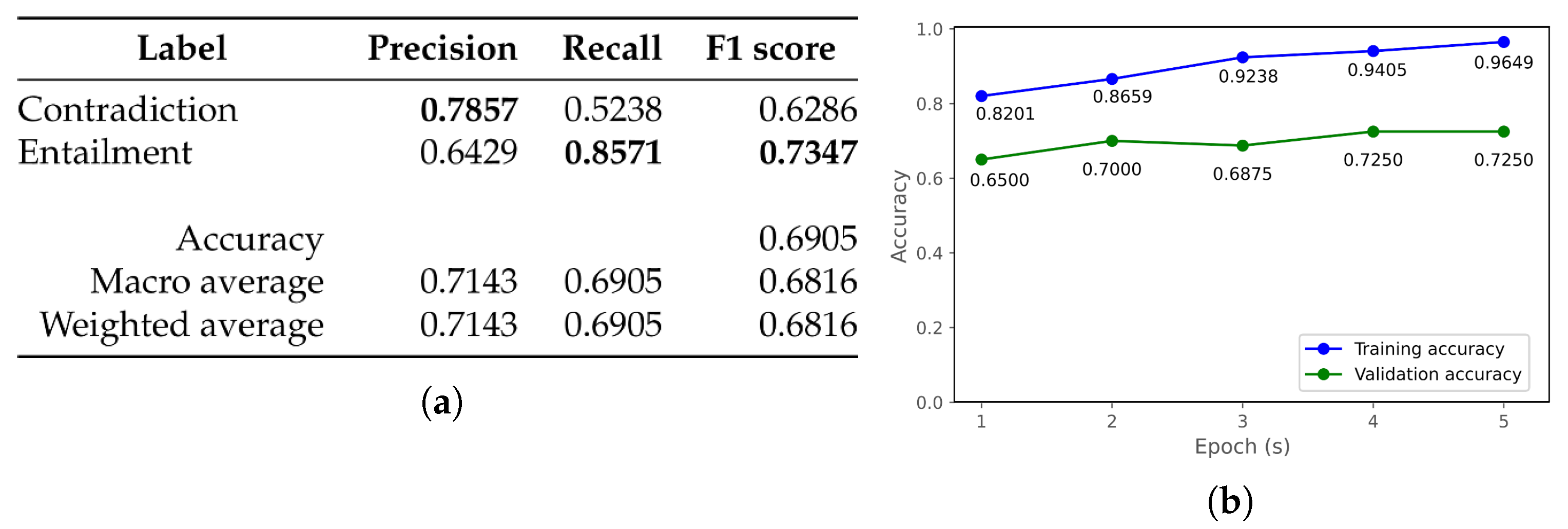
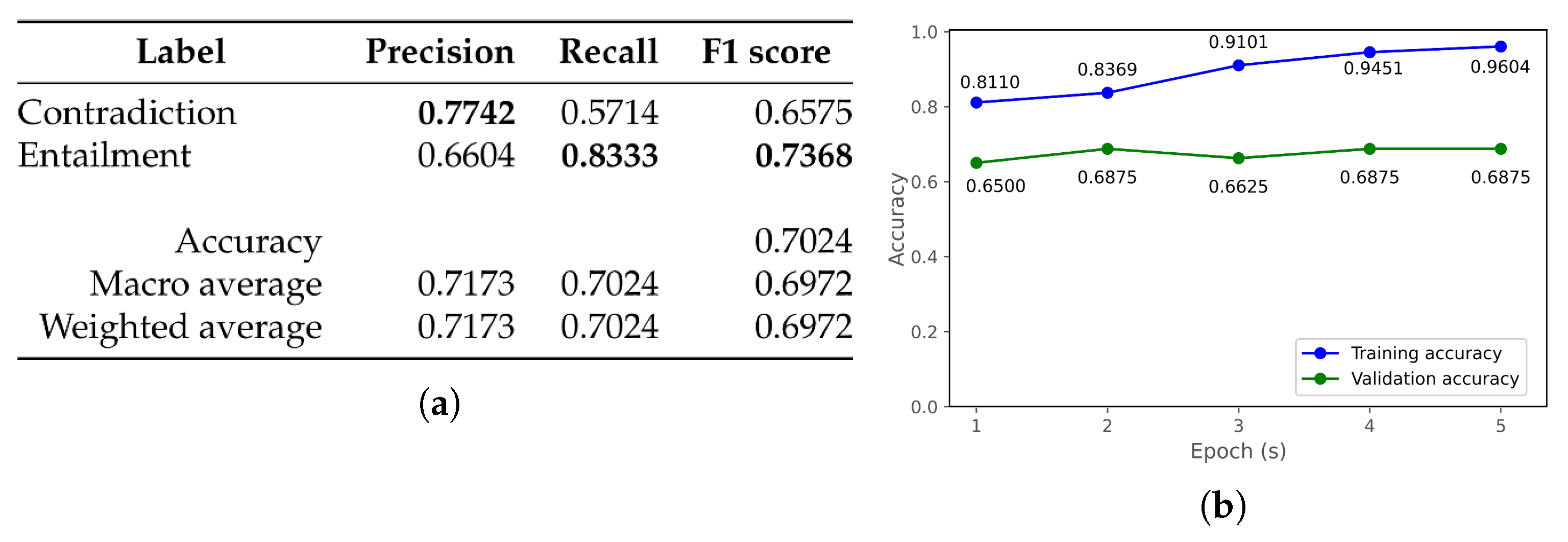
| mongolian-roberta-base [50] | 0.6071 | 0.7024 | 0.5860 | 0.7013 | 0.5860 | 0.7013 |
| mongolian-roberta-large [51] | 0.5357 | 0.5833 | 0.5351 | 0.5833 | 0.5351 | 0.5833 |
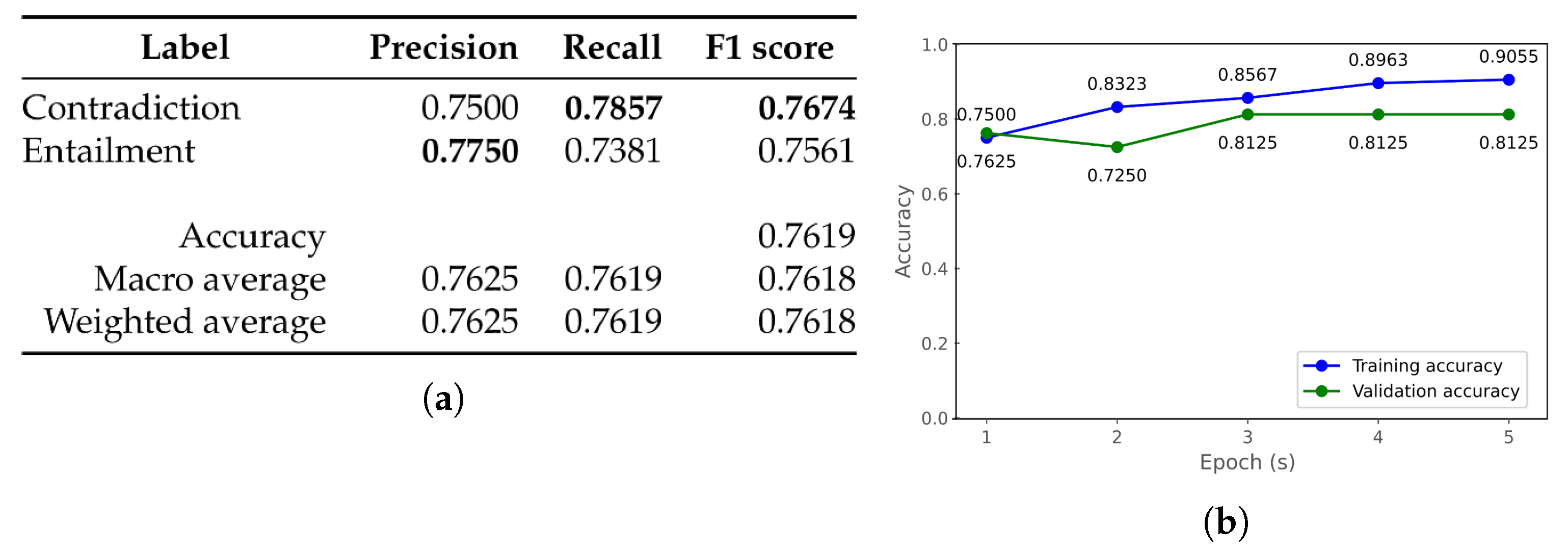
| albert-mongolian [52] | 0.6071 | 0.6310 | 0.6026 | 0.6267 | 0.6026 | 0.6267 |
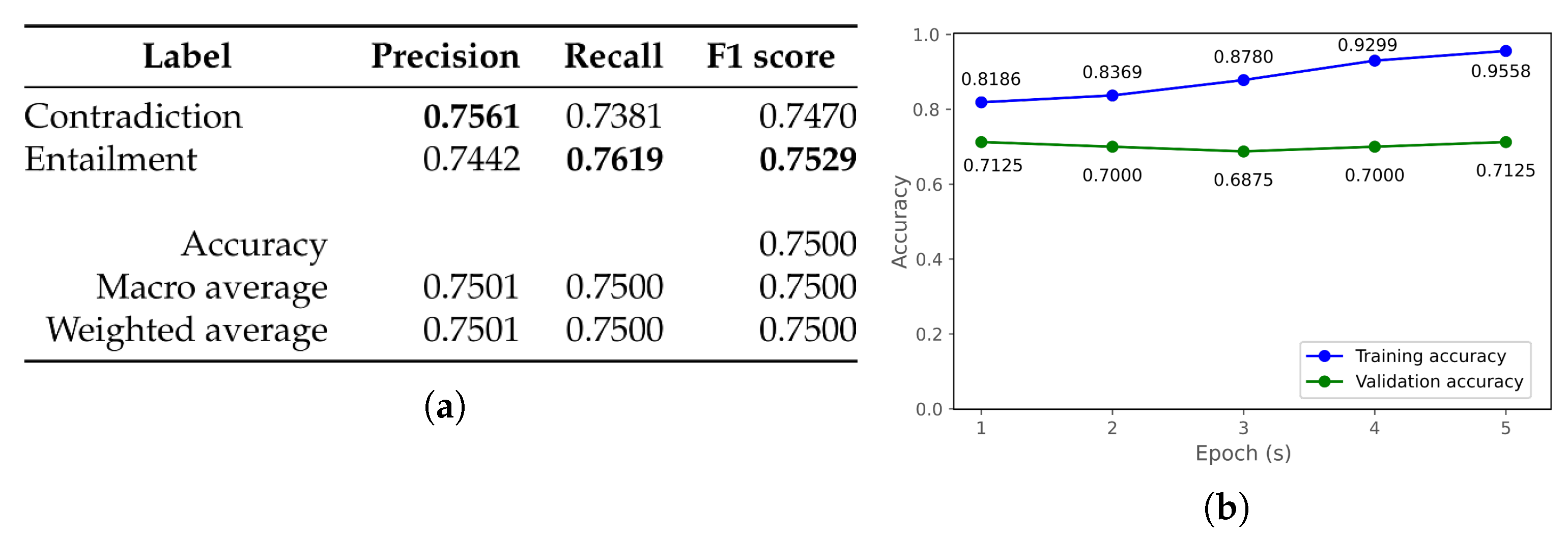
| bert-base-mongolian-cased [55] | 0.6905 | 0.7381 | 0.6876 | 0.7368 | 0.6876 | 0.7368 |
| bert-large-mongolian-uncased [56] | 0.7381 | 0.7500 | 0.7375 | 0.7500 | 0.7375 | 0.7500 |
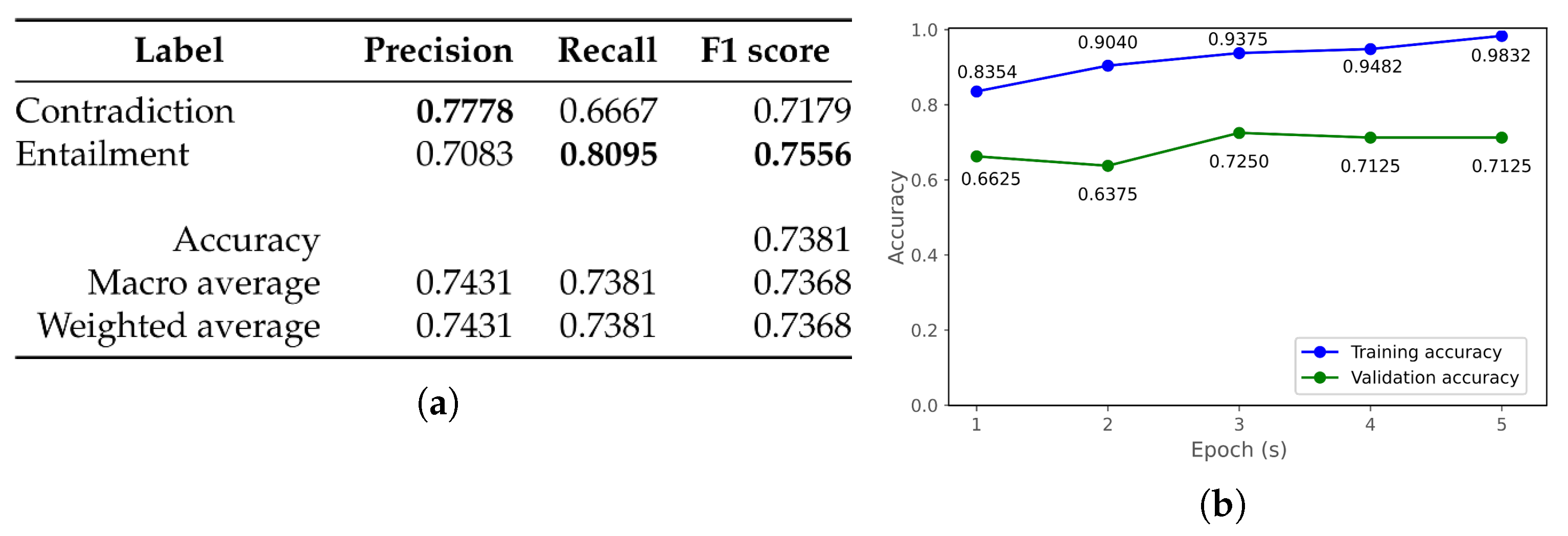
| bert-base-multilingual-cased [59] | 0.6905 | 0.7619 | 0.6860 | 0.7618 | 0.6860 | 0.7618 |
| bert-large-mongolian-cased [77] | 0.6786 | 0.6905 | 0.6748 | 0.6816 | 0.6748 | 0.6816 |
| bert-base-mongolian-uncased [78] | 0.7262 | 0.7024 | 0.7262 | 0.6972 | 0.7262 | 0.6972 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khaltarkhuu, G.; Batjargal, B.; Maeda, A. Recognizing Textual Inference in Mongolian Bar Exam Questions. Appl. Sci. 2024, 14, 1073. https://doi.org/10.3390/app14031073
Khaltarkhuu G, Batjargal B, Maeda A. Recognizing Textual Inference in Mongolian Bar Exam Questions. Applied Sciences. 2024; 14(3):1073. https://doi.org/10.3390/app14031073
Chicago/Turabian StyleKhaltarkhuu, Garmaabazar, Biligsaikhan Batjargal, and Akira Maeda. 2024. "Recognizing Textual Inference in Mongolian Bar Exam Questions" Applied Sciences 14, no. 3: 1073. https://doi.org/10.3390/app14031073
APA StyleKhaltarkhuu, G., Batjargal, B., & Maeda, A. (2024). Recognizing Textual Inference in Mongolian Bar Exam Questions. Applied Sciences, 14(3), 1073. https://doi.org/10.3390/app14031073