
Intelligent Computation Offloading Based on Digital Twin-Enabled 6G Industrial IoT

Abstract
1. Introduction
- We propose an integrated digital twin and IIoT architecture to model the network systems and all physical devices in the IIoT. The architecture enables more efficient and optimized network operation.
- We explore the impact of the heterogeneity of physical devices and the execution time of different tasks on offloading decisions. A solution based on deep deterministic policy gradient (DDPG) is employed to realize effective computation offloading. The solution focuses more on policy exploration than traditional algorithms to improve the adaptability of offloading algorithms and reduce the communication cost.
- We have conducted extensive experiments on the proposed learning algorithm. The results show that by considering various delay constraints, more tasks can be better executed, and unnecessary contention and the wasted resources phenomenon can be greatly reduced.
2. Related Work
2.1. DT-Enabled Computation Offloading with Cloud
2.2. DT-Enabled Computation Offloading with Edge
2.3. Edge Computation Offloading Supported by AI
3. System Model
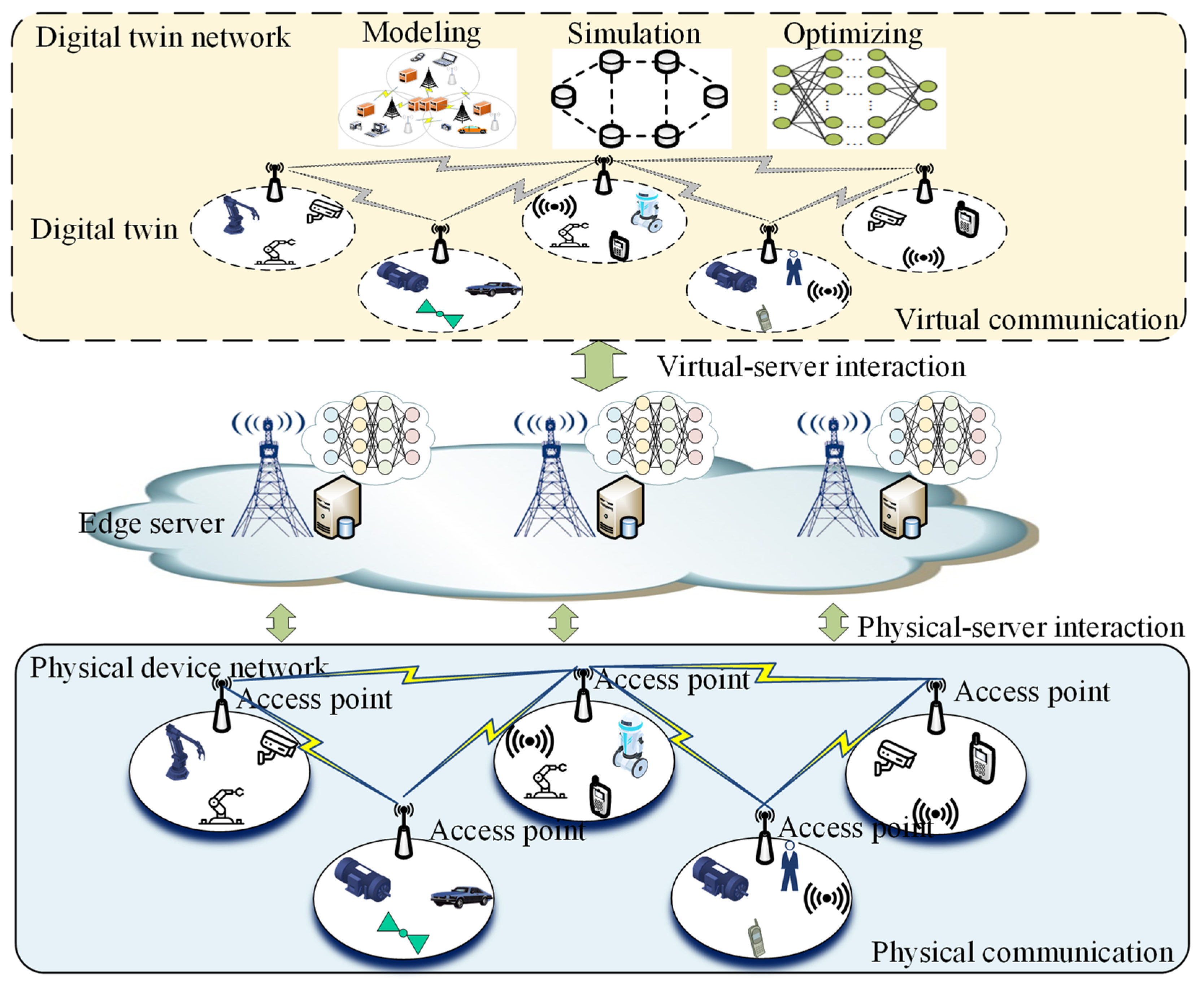
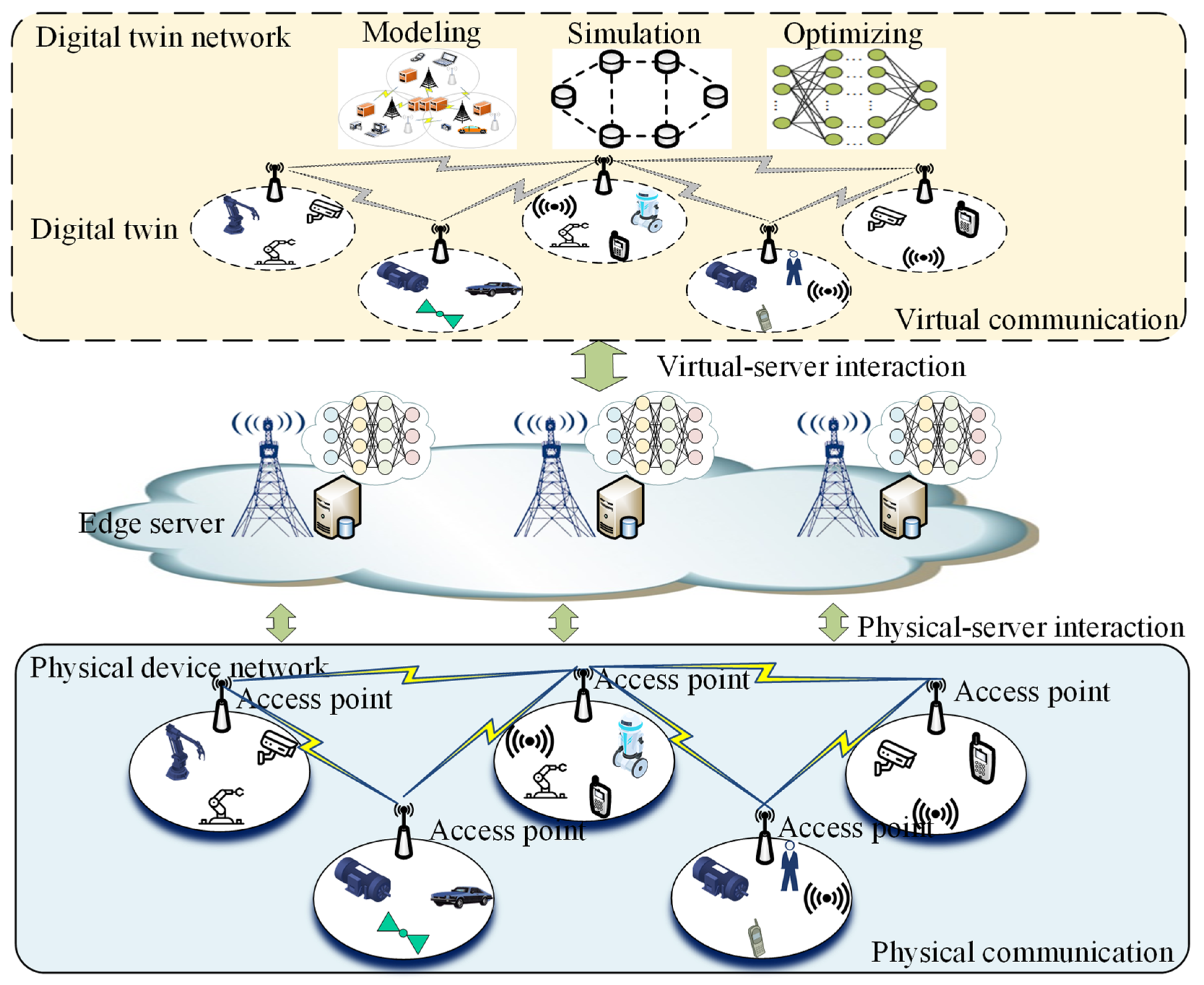
3.1. DT-Enabled Network Model
- The bottom physical device network includes client devices in the IIoT, such as smart machines, sensors, vehicles, and IIoT devices. It also contains devices such as switches, access points, and databases that assist communication between devices. Sensors collect data from the industrial field environment and connect to the nearest AP according to the network topology. Cells led by AP are scattered throughout the whole work region, operated for monitoring and control among the machines and the robots.
- The edge server element acts as a bridge between the network of physical devices and the digital twin. Digital twin networks are built and maintained with the help of edge servers. They are also the key to achieving virtual–physical interactions. The edge server element connects the network service application and the physical device network through standardized interfaces, completes the real-time information collection and control of the physical network, and provides timely diagnosis and analysis. We can complete the digital modeling of the factory communication environment before the transmission of data, and then simulate the transmission in the virtual digital space to evaluate the frequency allocation and channel tolerance. We can also import additional traffic data to evaluate whether the transmission scheme can meet the requirements of the service.
- The digital twin network can predict the optimal transmission channel through continuous acquisition and intelligent analysis of field data. A digital twin system can be roughly divided into three modules according to the functions it can achieve.
3.2. Computation Offloading Model
- Queuing delay, which is the waiting time in the output port queue due to the accumulation of packets generated by different applications to the same output port.
- Transmission delay, which is the time consumed to put the packet on the wireless link and send it from the source to the destination.
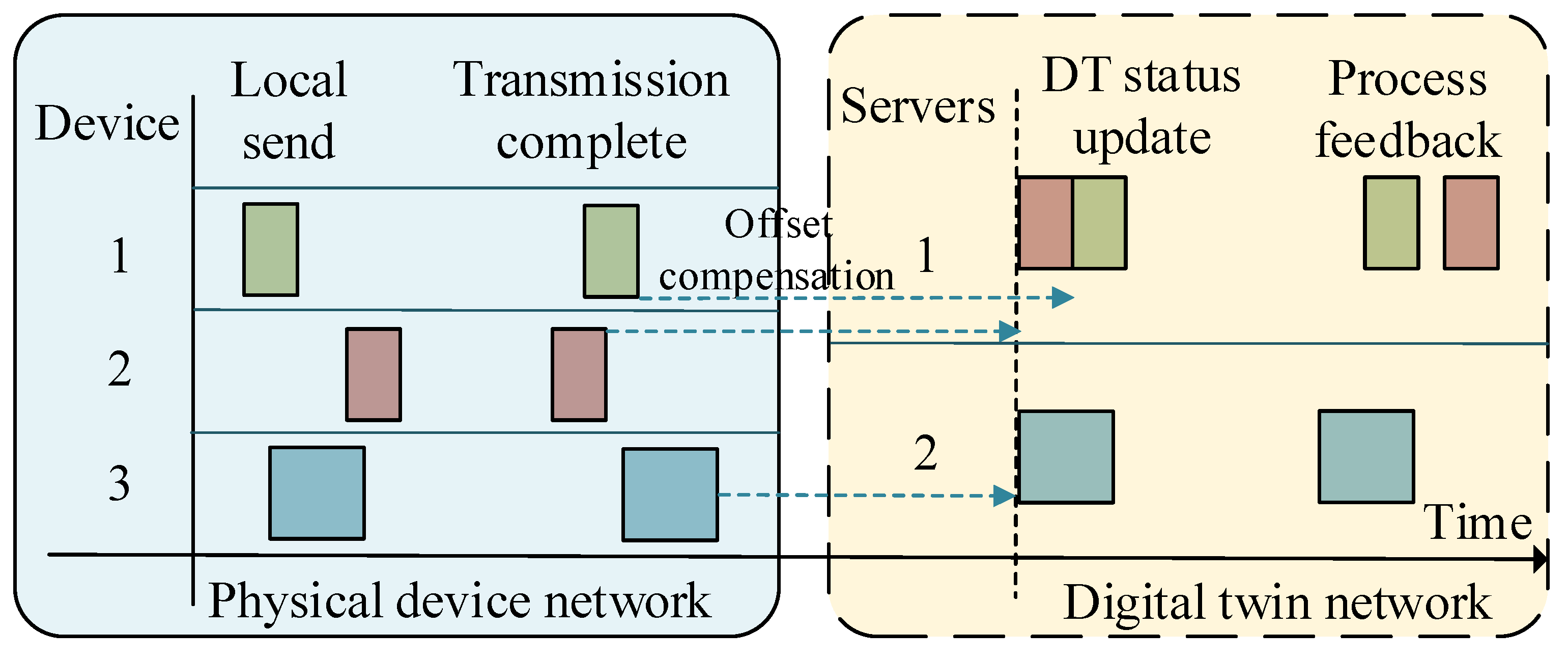
- Update delay, which refers to the delay caused by synchronizing heterogeneous physical devices when updating the global DT model.
- Processing delay, which is the time consumption associated with completing a computation task and can be measured in terms of the number of CPU cycles.
3.3. Problem Formulation
4. DRL-Driven Offloading Scheme Based on DT
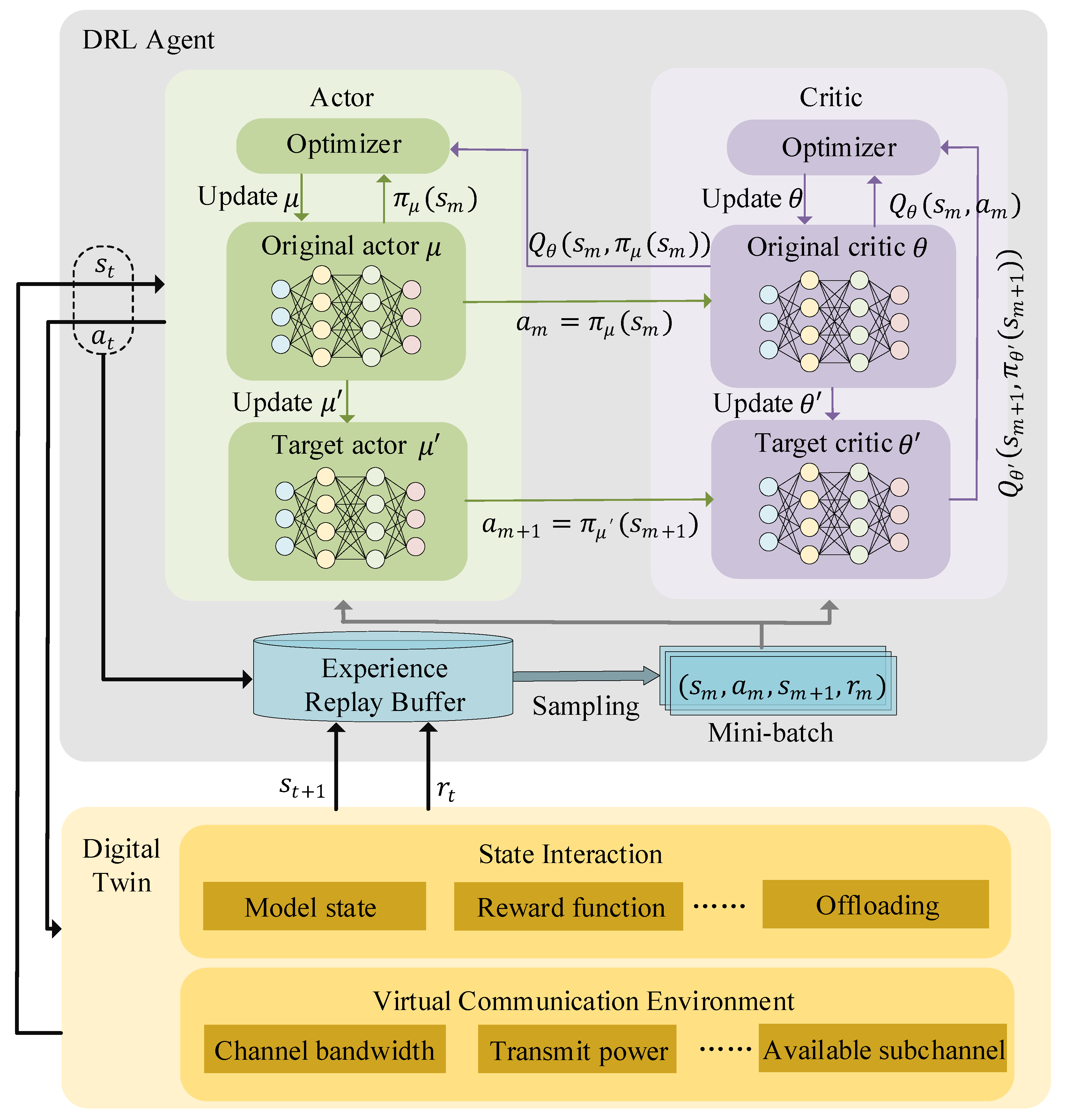
4.1. Digital Twin Simulated MDP
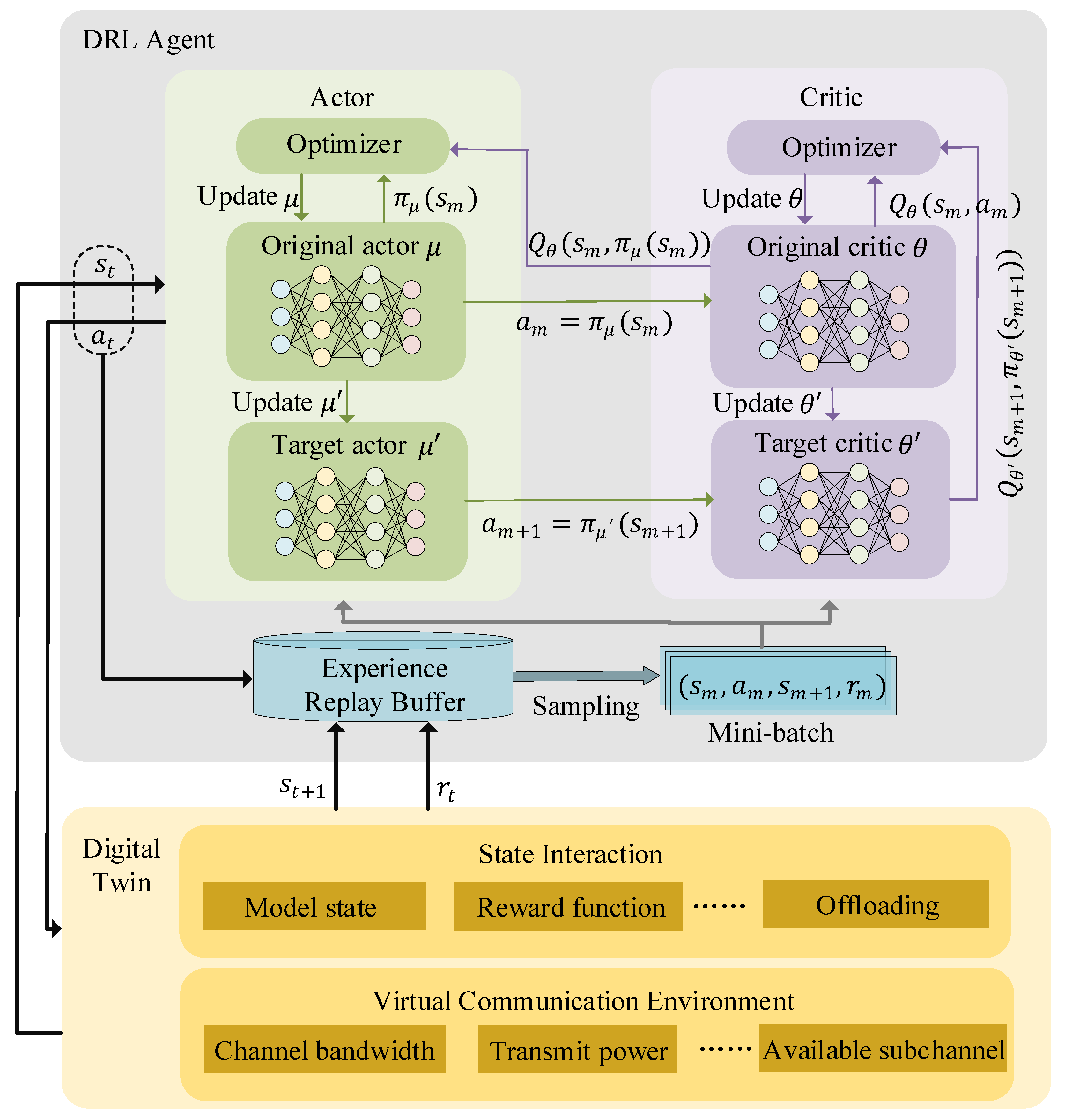
4.2. Solution Based on DDPG
| Algorithm 1: DRL-driven computation offloading algorithm with DT-enabled architecture |
| Input: The original Actor parameter . The target Actor parameter. The original Critic parameter. The target Critic parameter. Discount factor. Soft update step factor. Mini-batch size M. Output: Computation offloading scheme and network resource allocation. |
| 1. Initialize Actor networks and Critic networks. 2. for epi = 1 to thresholdE do 3. Digital twin observes its DTn. 4. Normalize the state and receive the initial state S1. 5. for to do 6. Choose and execute action at and map it onto DTn. 7. Calculate reward rt and receive next station. 8. if the experience replay buffer is not full then 9. Store transition in the buffer. 10. else 11. Randomly replace a tuple in the buffer. 12. Sample a minibatch of M transition . 13. for m=1 to M do 14. Calculate the target value based on . 15. Update the Original Critic network by . 16. Update the Original Actor network by . 17. end for 18. end if 19. Soft update the Target Actor network by . 20. Soft update the Target Critic network by . 21. end for 22. end for |
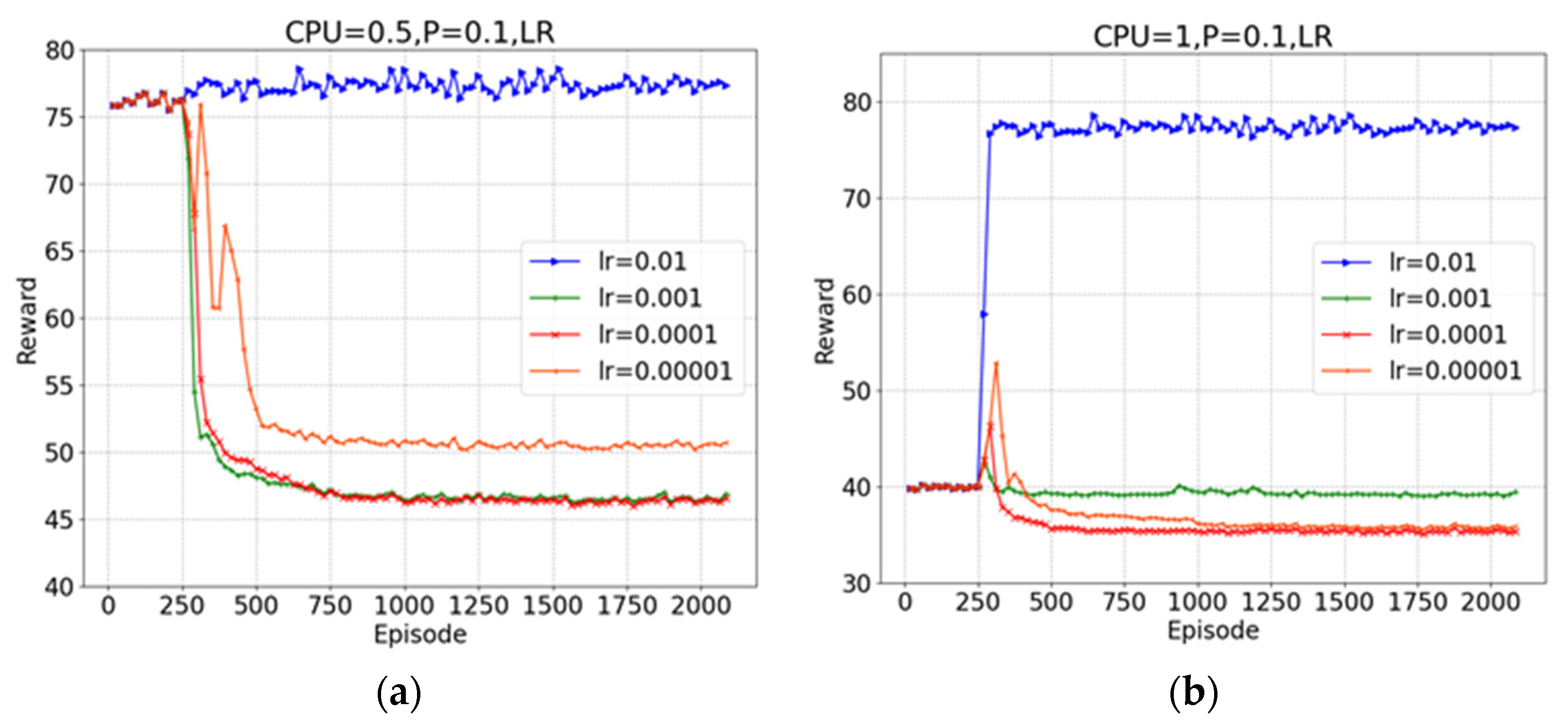
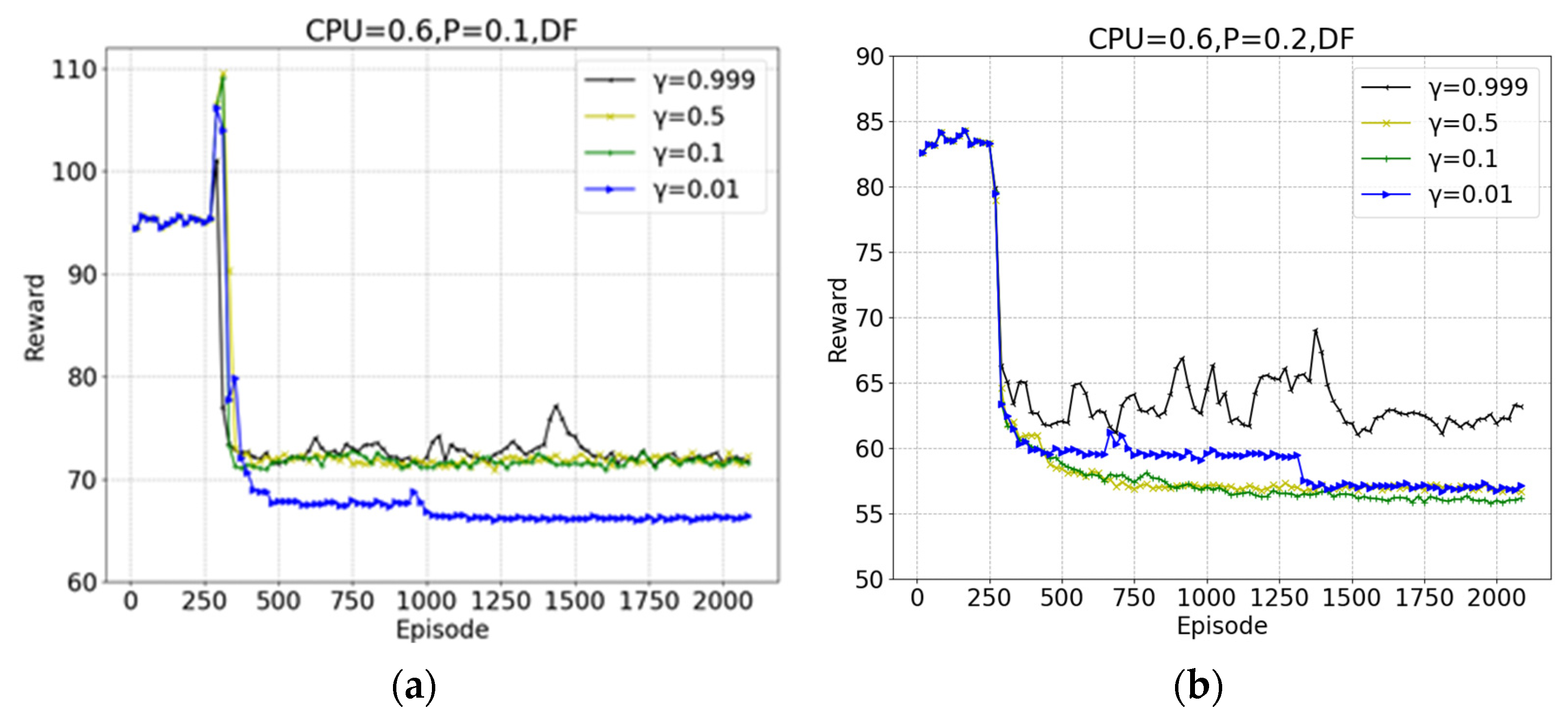
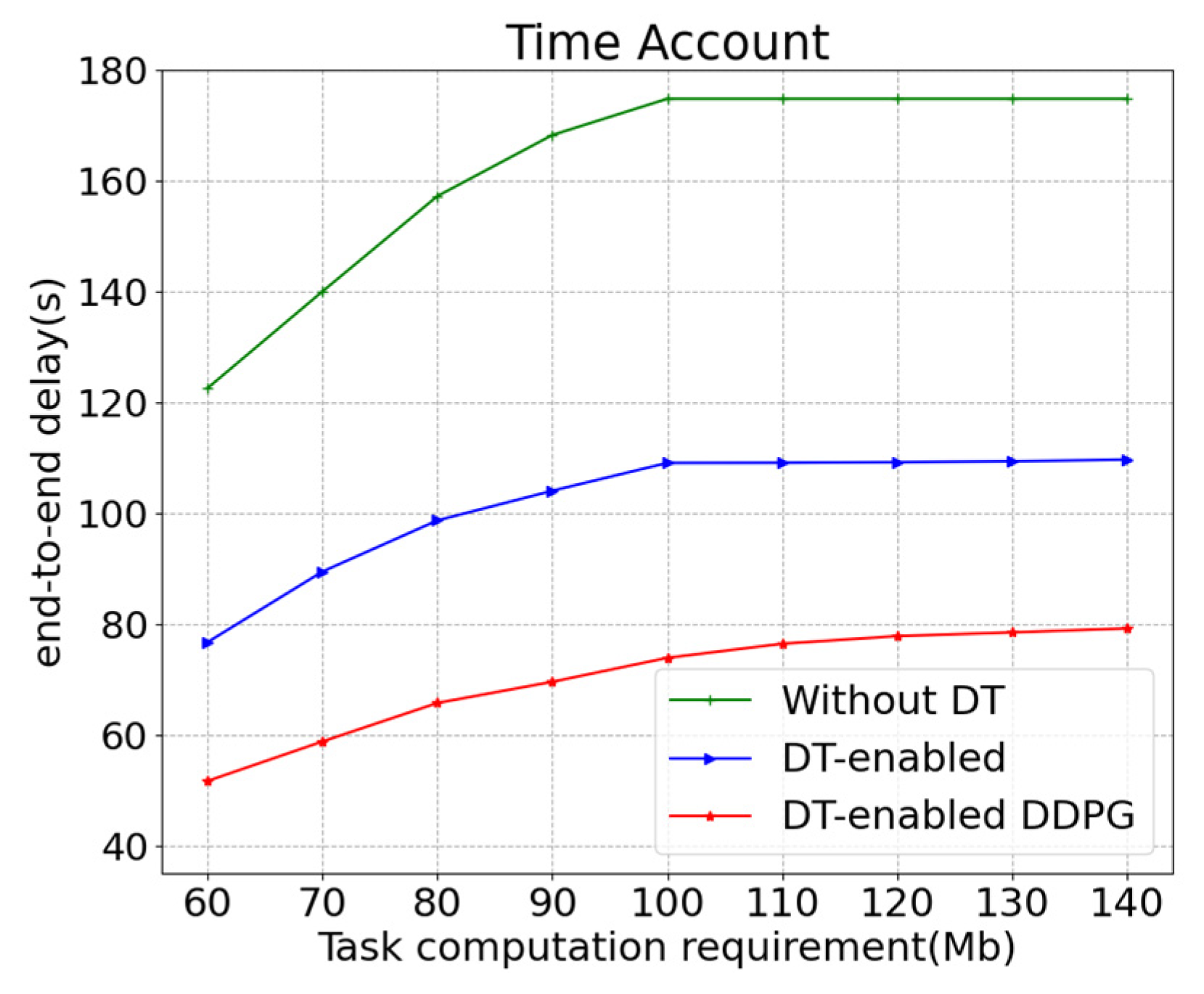
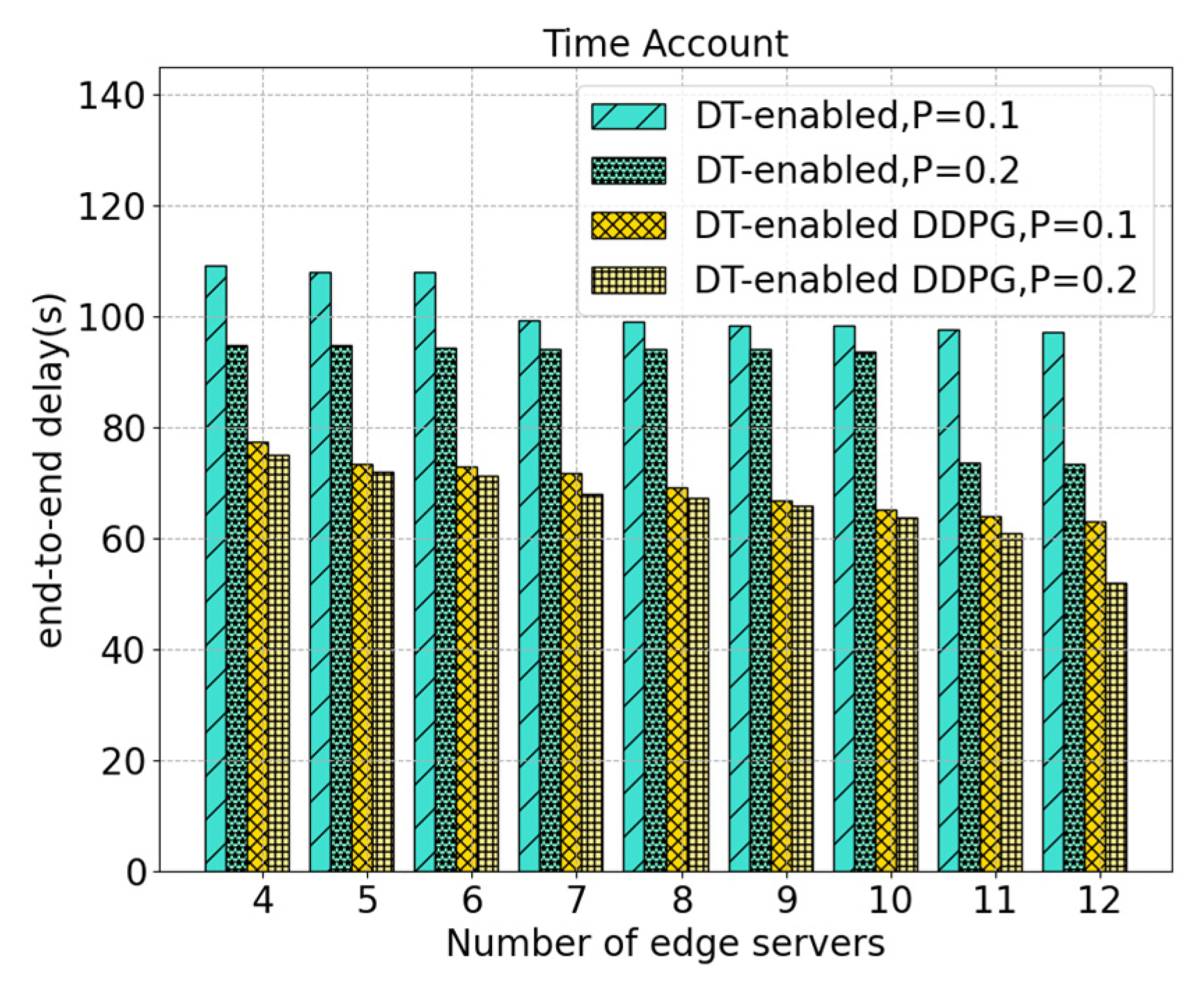
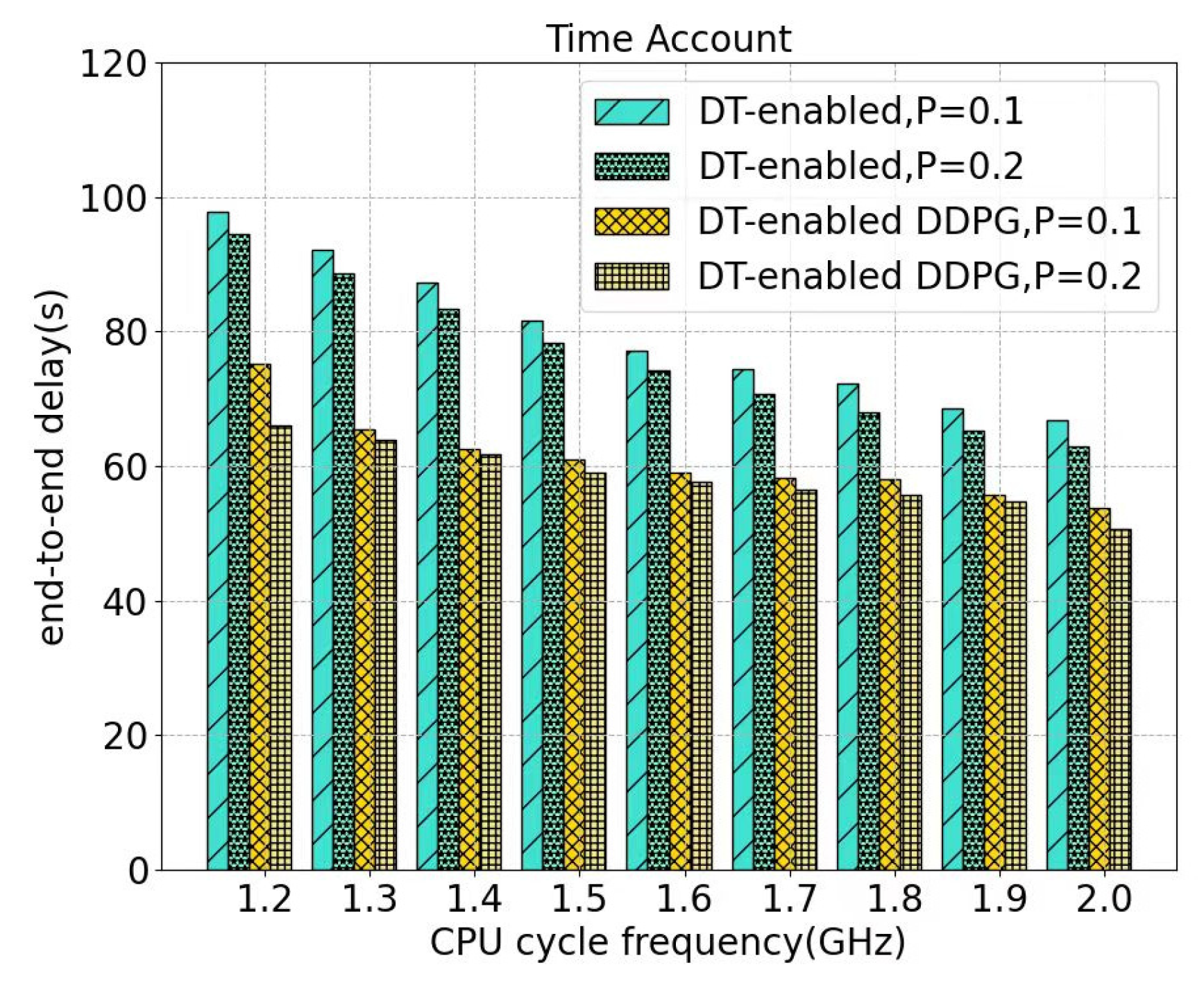
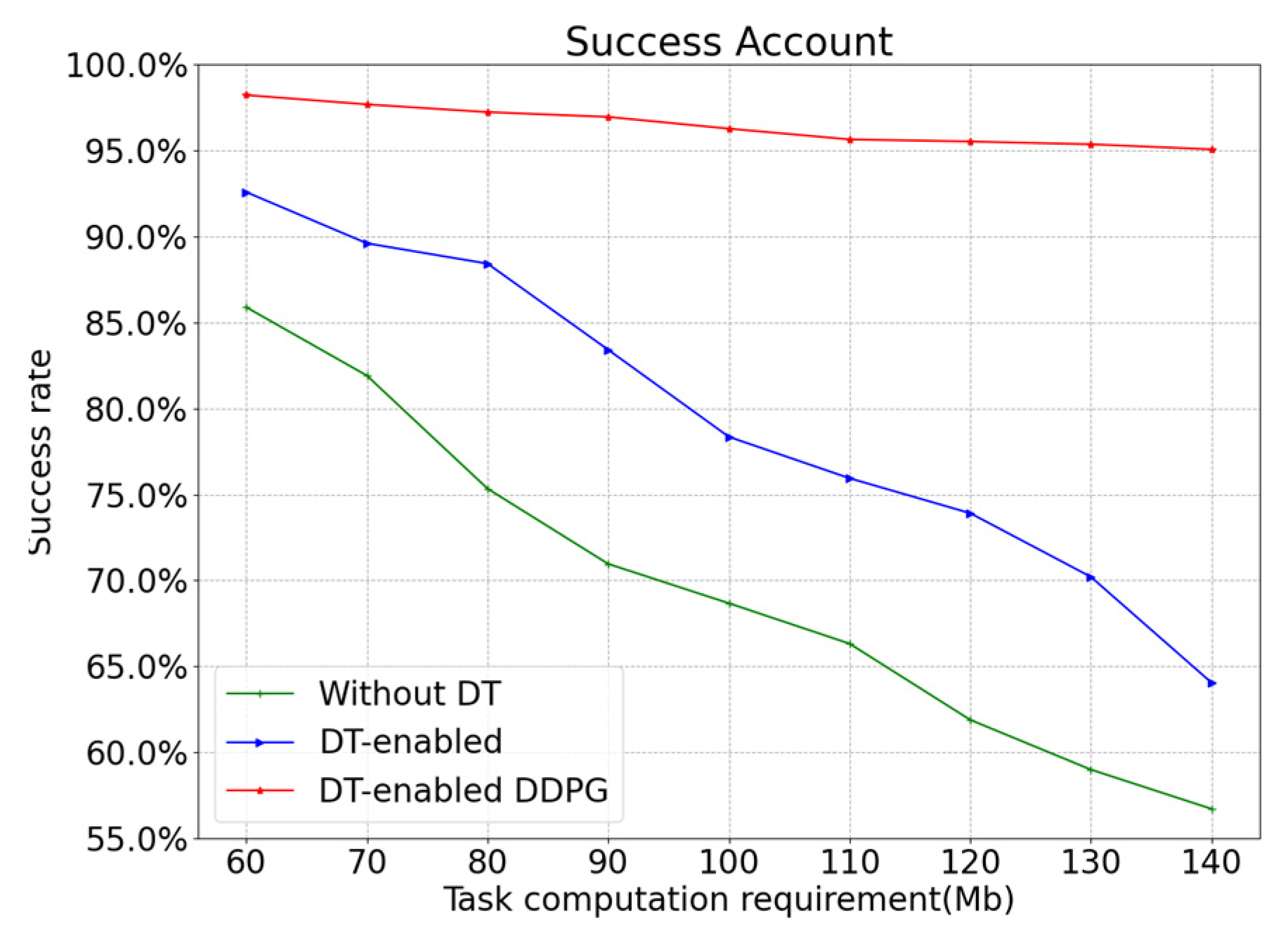
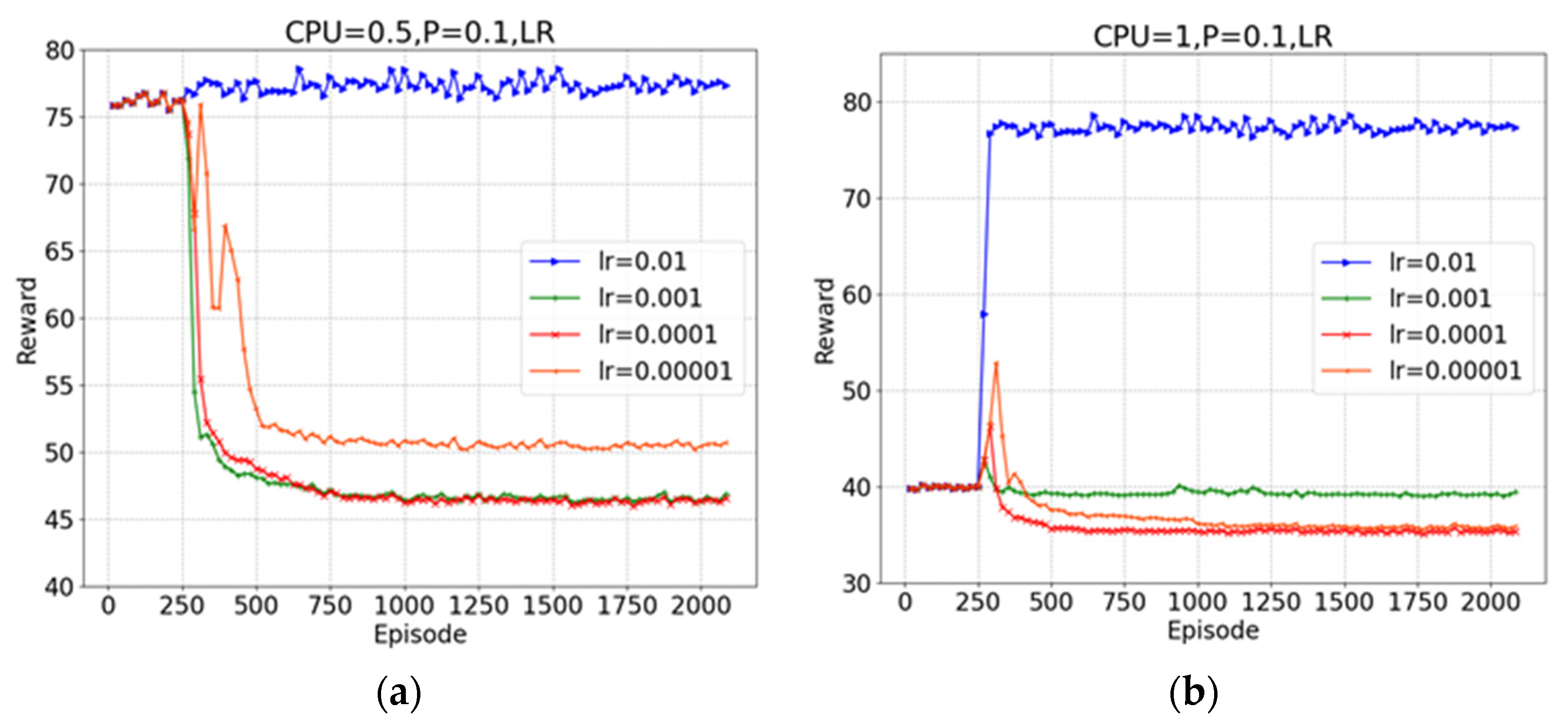
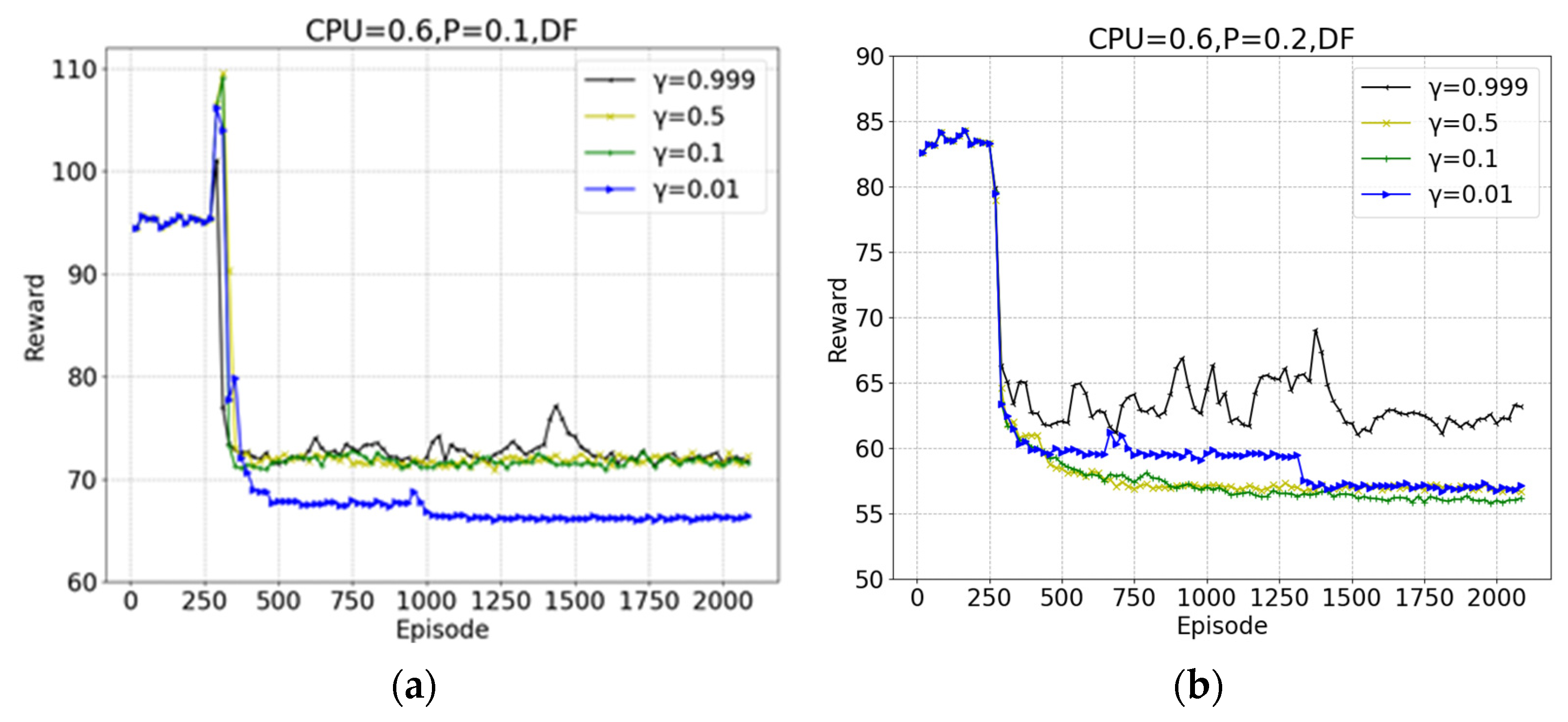
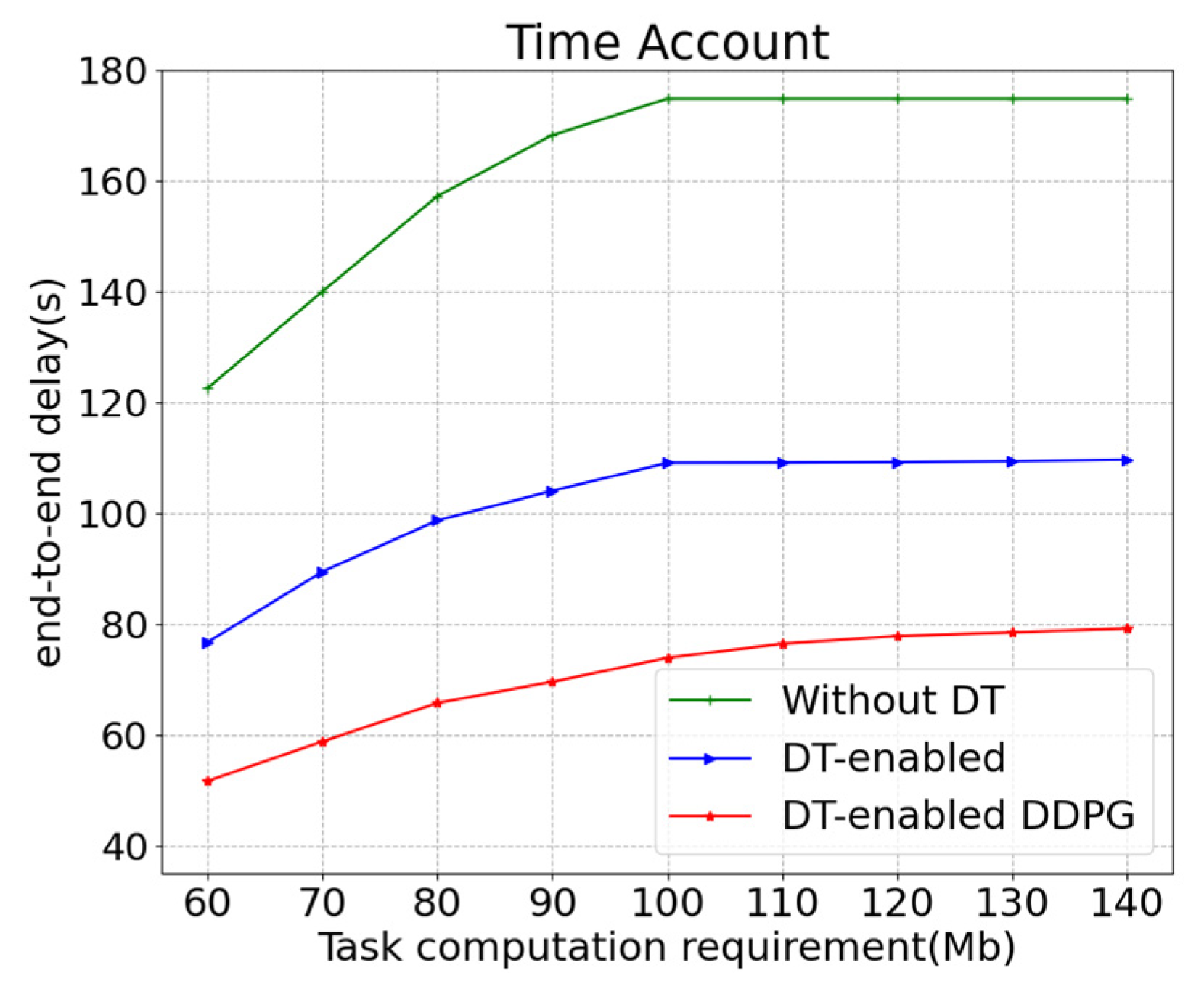
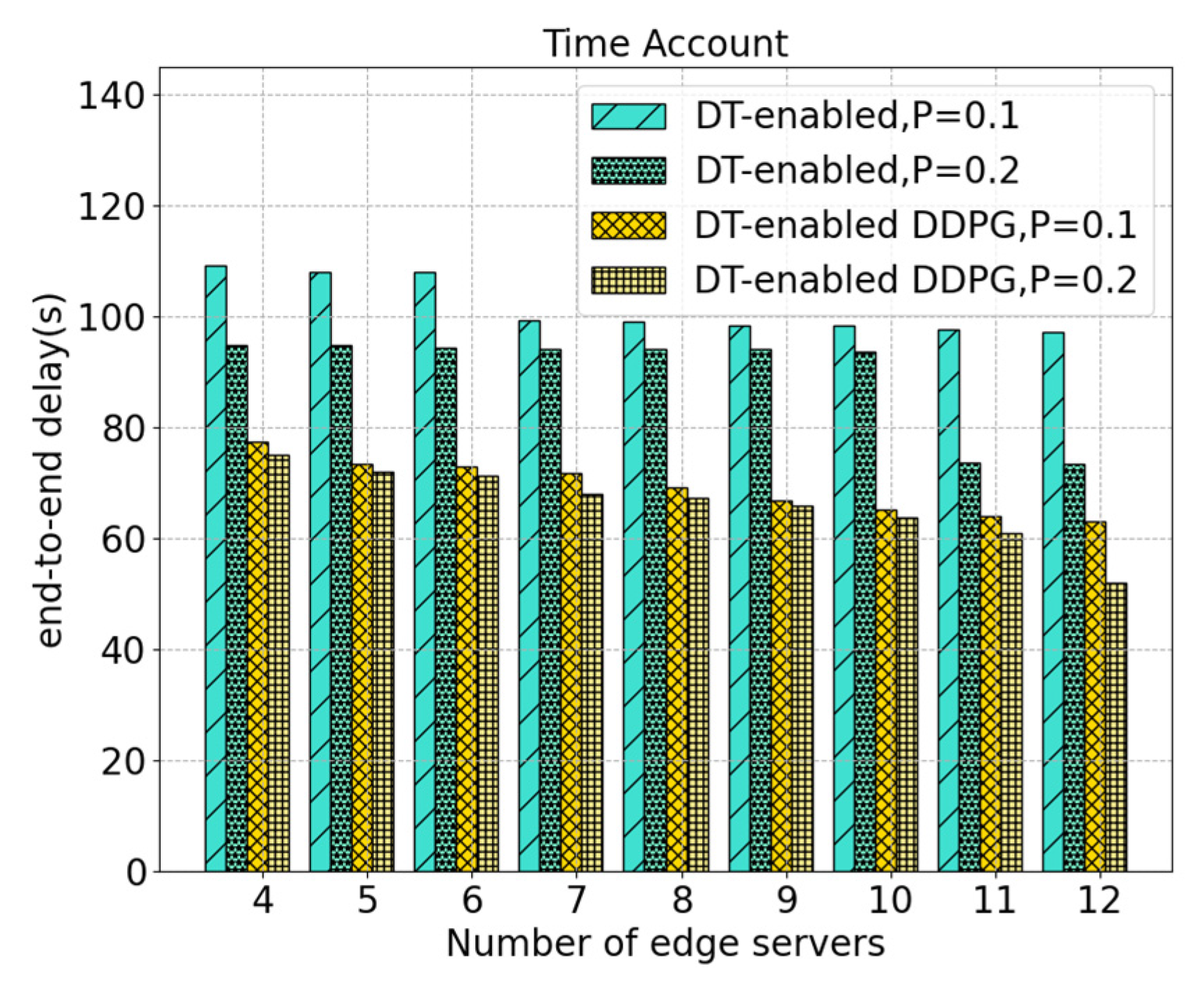
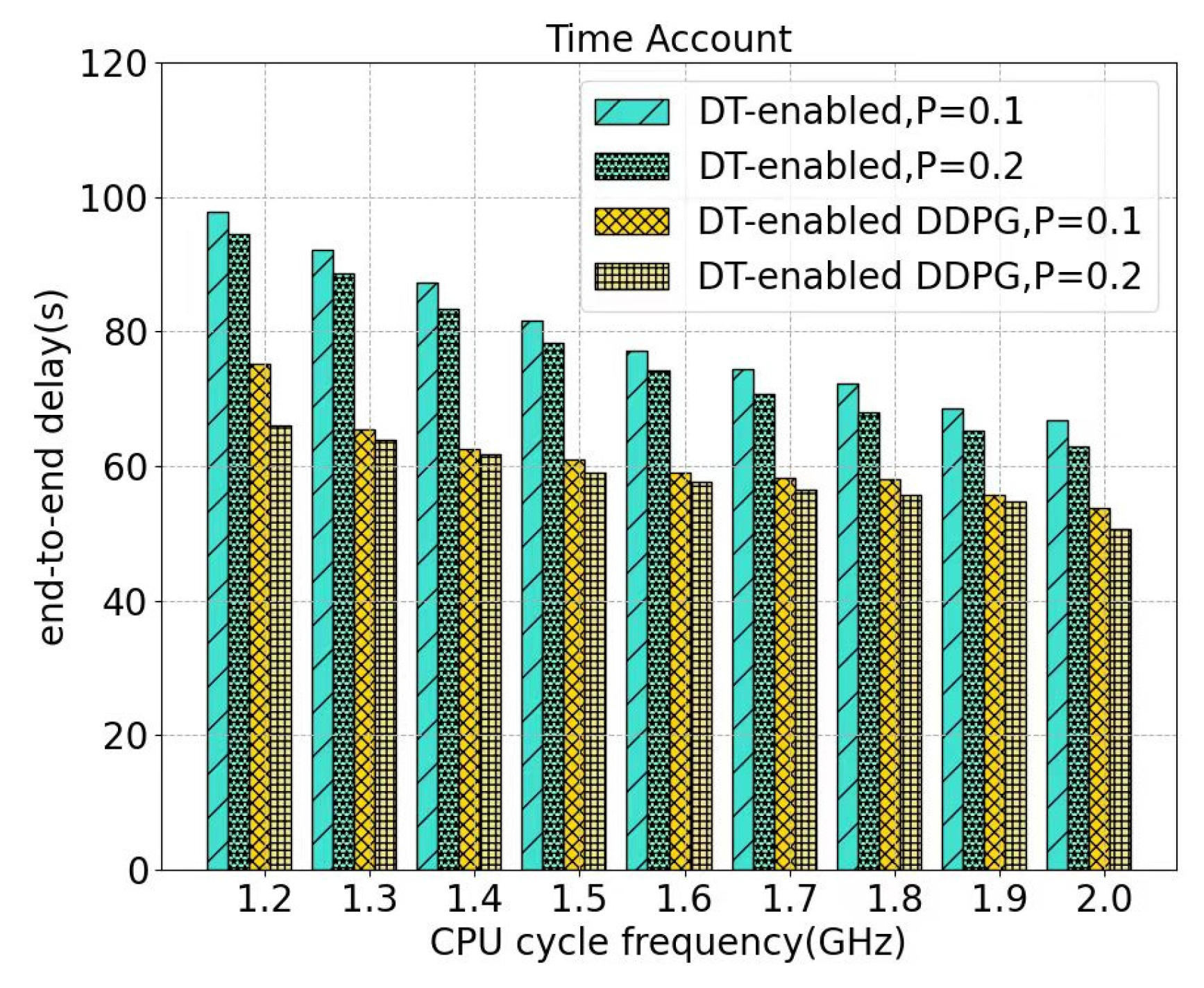
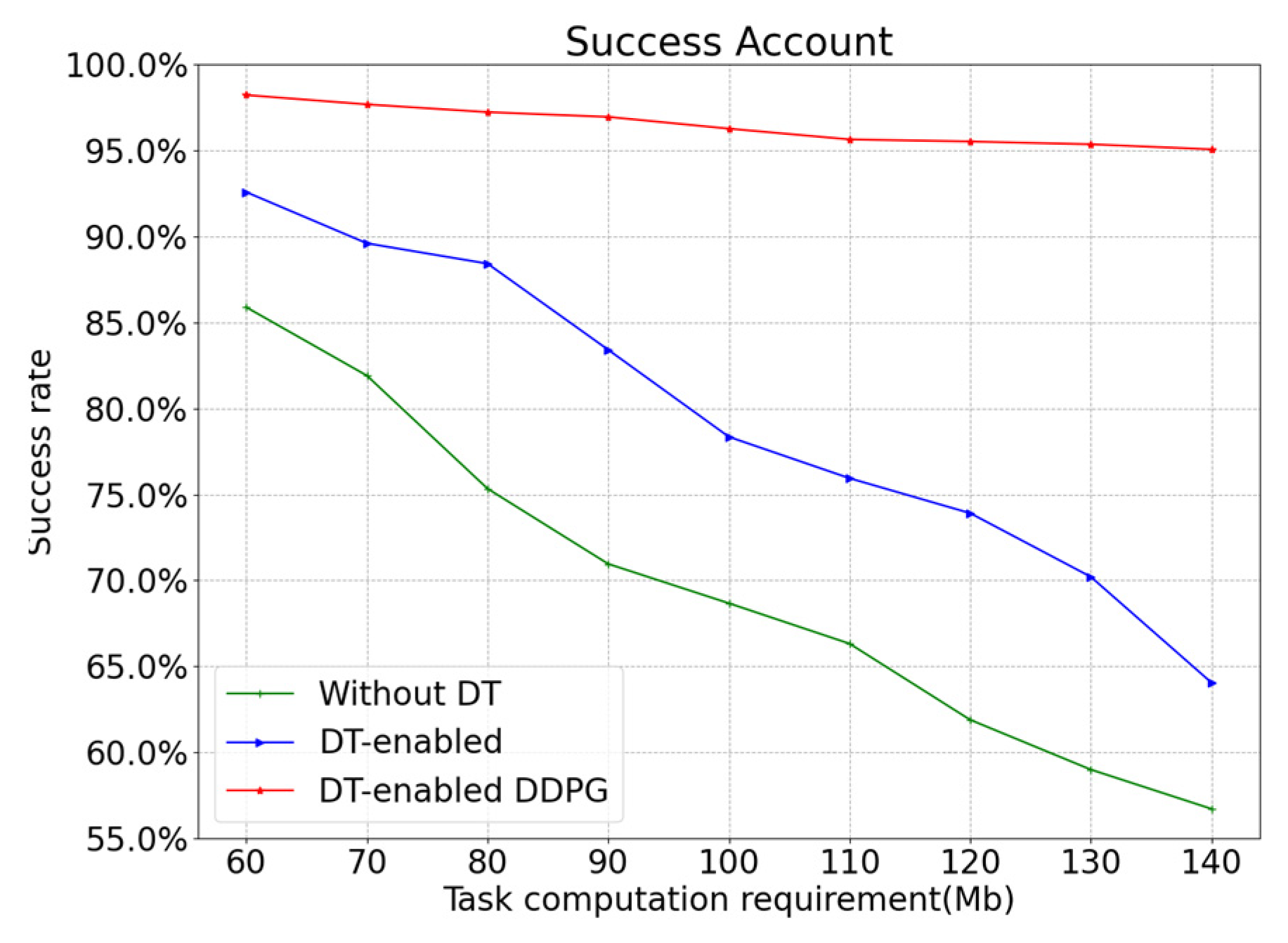
5. Experiments and Discussion
- (1)
- Local processing scheme: all computing tasks are performed by local devices, and DT is not enabled. The simulation scenario is a normal 6G IIoT network.
- (2)
- Nearest edge server selection scheme: in a DT-enabled network architecture, the nearest edge server is selected to offload the computation tasks.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wei, J.; Bin, H.; Mohammad, A.H.; Hans, D.S. The road towards 6G: A comprehensive survey. IEEE Open J. Commun. Soc. 2021, 2, 334–366. [Google Scholar]
- Aqeel, T.J.; Rihab, M.; Lamia, C. A comprehensive survey on 6G and beyond: Enabling technologies, opportunities of machine learning and challenges. Comput. Netw. 2023, 237, 110085. [Google Scholar]
- Xiaoheng, D.; Leilei, W.; Jinsong, G.; Ping, J.; Xuechen, C.; Feng, Z.; Shaohua, W. A review of 6G autonomous intelligent transportation systems: Mechanisms, applications and challenges. J. Syst. Architech. 2023, 142, 102929. [Google Scholar]
- Di, Z.; Min, S.; Jiandong, L.; Zhu, H. Aerospace integrated networks innovation for empowering 6G: A survey and future challenges. IEEE Commun. Surv. Tutor. 2023, 25, 975–1019. [Google Scholar]
- Jerry, C.W.L.; Gautam, S.; Yuyu, Z.; Youcef, D.; Moayad, A. Privacy preserving multiobjective sanitization model in 6G IoT environments. IEEE Internet Things 2021, 8, 5340–5349. [Google Scholar]
- Bomin, M.; Jiajia, L.; Yingying, W.; Nei, K. Security and privacy on 6G network edge: A survey. IEEE Commun. Surv. 2023, 25, 1095–1127. [Google Scholar]
- Demos, S.; Mohsen, K.; Tim, W.C.B.; Rahim, T. Terahertz channel propagation phenomena, measurement techniques and modeling for 6G wireless communication applications: A survey, open challenges and future research directions. IEEE Commun. Surv. Tutor. 2022, 24, 1957–1996. [Google Scholar]
- Xiaofei, W.; Yiwen, H.; Victor, C.M.L.; Dusit, N.; Xueqiang, Y.; Xu, C. Convergence of edge computing and deep learning: A comprehensive survey. IEEE Commun. Surv. Tutor. 2020, 22, 869–904. [Google Scholar]
- Houming, Q.; Kun, Z.; Nguyen, C.L.; Changyan, Y.; Dusit, N.; Dong, I.K. Applications of auction and mechanism design in edge computing: A survey. IEEE T. Cogn. Commun. 2022, 8, 1034–1058. [Google Scholar]
- Yuyi, M.; Changsheng, Y.; Jun, Z.; Kaibin, H.; Khaled, B.L. A survey on mobile edge computing: The communication perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar]
- Binayak, K.; Widhi, Y.; Ying, D.L.; Asad, A. A survey on offloading in federated cloud-edge-fog systems with traditional optimization and machine learning. arXiv 2022, arXiv:2202.10628. [Google Scholar]
- Quyuan, L.; Shihong, H.; Changle, L.; Guanghui, L.; Weisong, S. Resource scheduling in edge computing: A survey. IEEE Commun. Surv. Tutor. 2021, 23, 2131–2165. [Google Scholar]
- Yao, C.; Yi, Z.; Hao, L.; Tse, Y.C.; Guan, H.C.; Huan, T.C.; Yan, J.W.; Hung, Y.W.; Chun, T.C. Management and orchestration of edge computing for IoT: A comprehensive survey. IEEE Internet Things 2023, 10, 14307–14331. [Google Scholar]
- Yiwen, W.; Ke, Z.; Yan, Z. Digital twin networks: A survey. IEEE Internet Things 2021, 8, 13789–13804. [Google Scholar]
- Fengxiao, T.; Xuehan, C.; Tiago, K.R.; Ming, Z.; Nei, K. Survey on digital twin edge networks (DITEN) toward 6G. IEEE Open J. Commun. Soc. 2022, 3, 1360–1381. [Google Scholar]
- Stefan, M.; Mahnoor, Y.; Dang, V.H.; William, D.; Praveer, T.; Mohsin, R.; Mehmet, K.; Balbir, B.; Dattaprasad, S.; Raja, V.P.; et al. Digital twins: A survey on enabling technologies, challenges, trends and future prospects. IEEE Commun. Surv. Tutor. 2022, 24, 2255–2291. [Google Scholar]
- Yuntao, W.; Zhou, S.; Shaolong, G.; Minghui, D.; Tom, H.L.; Yiliang, L. A survey on digital twins: Architecture, enabling technologies, security and privacy, and future prospects. IEEE Internet Things 2023, 10, 14965–14987. [Google Scholar]
- Hansong, X.; Jun, W.; Qianqian, P.; Xinping, G.; Mohsen, G. A survey on digital twin for industrial internet of things: Applications, technologies and tools. IEEE Commun. Surv. Tutor. 2023, 25, 2569–2598. [Google Scholar]
- Julia, R.; Cristian, M.; Manuel, D. Opentwins: An open-source framework for the development of next-gen compositional digital twins. Comput. Ind. 2023, 152, 104007. [Google Scholar]
- Md, M.H.S.; Sajal, K.D.; Safwat, M.C. Design, development, and optimization of a conceptual framework of digital twin electric grid using systems engineering approach. Electr. Pow. Syst. Res. 2023, 226, 109958. [Google Scholar]
- Van-Dinh, N.; Saeed, R.K.; Vishal, S.; Octavia, A.D. URLLC edge networks with joint optimal user association, task offloading and resource allocation: A digital twin approach. IEEE Trans. Commun. 2022, 70, 7669–7682. [Google Scholar]
- Bin, T.; Lihua, A.; Min, W.; Jiaxi, W. Toward a task offloading framework based on cyber digital twins in mobile edge computing. IEEE Wirel. Commun. 2023, 30, 157–162. [Google Scholar]
- Long, C.; Shaojie, Z.; Yalan, W.; Hong-Ning, D.; Jigang, W. Resource and fairness-aware digital twin service caching and request routing with edge collaboration. IEEE Wirel. Commun. Lett. 2023, 12, 1881–1885. [Google Scholar]
- Yunlong, L.; Sabita, M.; Yan, Z. Adaptive edge association for wireless digital twin networks in 6G. IEEE Internet Things 2021, 8, 16219–16230. [Google Scholar]
- Lindong, Z.; Shouxiang, N.; Dan, W.; Liang, Z. Cloud-edge-client collaborative learning in digital twin empowered mobile networks. IEEE J. Sel. Areas Commun. 2023, 41, 3491–3503. [Google Scholar]
- Haijun, L.; Zhenyu, Z.; Nian, L.; Yan, Z.; Guangyuan, X.; Zhenti, W.; Shahid, M. Cloud-edge-device collaborative reliable and communication-efficient digital twin for low-carbon electrical equipment management. IEEE Trans. Ind. Inform. 2023, 19, 1715–1724. [Google Scholar]
- Zhe, J.; Sheng, W.; Chunxiao, J. Cooperative multi-agent deep reinforcement learning for computation offloading in digital twin satellite edge networks. IEEE J. Sel. Areas Commun. 2023, 41, 3414–3429. [Google Scholar]
- Siguang, C.; Jiamin, C.; Yifeng, M.; Qian, W.; Chuanxin, Z. Deep reinforcement learning-based cloud-edge collaborative mobile computation offloading in industrial networks. IEEE Trans. Signal Inf. Process. Netw. 2022, 8, 364–375. [Google Scholar]
- Nikos, A.M.; Vasilis, K.P.; Panagiotis, D.D.; Trung, Q.D.; George, K.K. Digital twin-aided orchestration of mobile edge computing with grant-free access. IEEE Open J. Commun. Soc. 2023, 4, 841–853. [Google Scholar]
- Kai, P.; Hualong, H.; Muhammad, B.; Xiaolong, X. Distributed incentives for intelligent offloading and resource allocation in digital twin driven smart industry. IEEE Trans. Ind. Inform. 2023, 19, 3133–3143. [Google Scholar]
- Dang, V.H.; Van-Dinh, N.; Saeed, R.K.; George, K.K.; Trung, Q.D. Distributed communication and computation resource management for digital twin-aided edge computing with short-packet communications. IEEE J. Sel. Areas Commun. 2023, 41, 3008–3021. [Google Scholar]
- Bowen, W.; Yanjing, S.; Haejoon, J.; Long, D.N.; Nguyen-Son, V.; Trung, Q.D. Digital twin-enabled computation offloading in UAV-assisted MEC emergency networks. IEEE Wirel. Commun. Lett. 2023, 12, 1588–1592. [Google Scholar]
- Long, Z.; Han, W.; Hongmei, X.; Hongliang, Z.; Qilie, L.; Dusit, N.; Zhu, H. Digital twin-assisted edge computation offloading in industrial internet of things with NOMA. IEEE Trans. Veh. Technol. 2023, 72, 11935–11950. [Google Scholar]
- Lingxiao, C.; Qiangqiang, G.; Kai, J.; Liang, Z. A3C-based and dependency-aware computation offloading and service caching in digital twin edge networks. IEEE Access 2023, 11, 57564–57573. [Google Scholar]
- Xiaolong, X.; Zhongjian, L.; Muhammad, B.; Vimal, S.; Houbing, S. Computation offloading and service caching for intelligent transportation systems with digital twin. IEEE Trans. Intell. Transp. Syst. 2022, 23, 20757–20772. [Google Scholar]
- Zhixiu, Y.; Shichao, X.; Yun, L.; Guangfu, W. Cooperative task offloading and service caching for digital twin edge networks: A graph attention multi-agent reinforcement learning approach. IEEE J. Sel. Areas Commun. 2023, 41, 3401–3413. [Google Scholar]
- Yueyue, D.; Ke, Z.; Sabita, M.; Yan, Z. Deep reinforcement learning for stochastic computation offloading in digital twin networks. IEEE J. Sel. Areas Commun. 2021, 17, 4968–4977. [Google Scholar]
- Bin, L.; Yufeng, L.; Ling, T.; Heng, P.; Yan, Z. Digital twin assisted task offloading for aerial edge computing and networks. IEEE Trans. Veh. Technol. 2022, 71, 10863–10877. [Google Scholar]
- Yongchao, Z.; Jia, H.; Geyong, M. Digital twin-driven intelligent task offloading for collaborative mobile edge computing. IEEE J. Sel. Areas Commun. 2023, 41, 3386–3400. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Offloading Position | Algorithm | Optimization Objective |
|---|---|---|---|
| [24] | Cloud-edge-client | DRL | Minimize latency performance |
| [25] | Cloud-edge-client | FL | Minimize the system cost |
| [26] | Cloud-edge-client | -FLOW | Minimize communication cost |
| [27] | Cloud-edge | MA-DATD3 | Minimize delay and energy |
| [28] | Cloud-edge-client | DRL | Minimize execution delay |
| [29] | Edge-client | SCA | Minimize the average delay |
| [30] | Edge-client | two-stage | Maximize total profits |
| [31] | Edge | SCA | Minimize latency |
| [32] | Edge | UCB | Minimize delay |
| [33] | Edge-client | non-convex optimization | Minimize the average delay |
| [34] | Edge | A3C | Minimize system energy cost |
| [35] | Edge | MINLP | Minimize the system latency |
| [36] | Edge | GatMARL | Maximize QoS |
| [37] | Edge | AAC | Minimize long term energy |
| [38] | Edge | DDQN | Minimize energy consumption |
| [39] | Edge-client | DRL | Minimize long term income |
| Symbol | Description |
|---|---|
| , | Network topology |
| The DT model for a physical device n | |
| DT attribute element of n to process task : DT model, QoS requirements, essential state, deviation | |
| The set of tasks | |
| Task attribute element of task : computation requirement, transmitted data size, maximum delay bound | |
| The set of nodes in the network | |
| Queue parameter | |
| Wireless communication parameters | |
| ,, | Resource upper limits for various nodes |
| Environmental bandwidth in DT model | |
| DT global clock | |
| Task arrival time | |
| Processing start time | |
| Boolean variable | |
| , | The composition of total end-to-end delay |
| MDP attribute element: state, action, transition matrix, reward, discount factor | |
| Distribution of network resources at the current time | |
| Deterministic policy | |
| , | Parameters of the Actor network |
| , | Parameters of the Critic network |
| Maximum Q-value | |
| A small step factor |
| Parameters | Value |
|---|---|
| Maximum number of edge servers | 12 |
| Number of physical devices | 40~50 |
| CPU cycle frequency of IIoT | (0, 1] GHz |
| CPU cycle frequency of edge server | (1, 2] GHz |
| Task computation requirement | [100, 200] M |
| Bandwidth | 20 MHz |
| Gaussian white noise power | mW |
| Batch size | 32 |
| Episodes | 2000 |
| Sample rate | 0.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Zuo, R. Intelligent Computation Offloading Based on Digital Twin-Enabled 6G Industrial IoT. Appl. Sci. 2024, 14, 1035. https://doi.org/10.3390/app14031035
Wu J, Zuo R. Intelligent Computation Offloading Based on Digital Twin-Enabled 6G Industrial IoT. Applied Sciences. 2024; 14(3):1035. https://doi.org/10.3390/app14031035
Chicago/Turabian StyleWu, Jingjing, and Ruiyong Zuo. 2024. "Intelligent Computation Offloading Based on Digital Twin-Enabled 6G Industrial IoT" Applied Sciences 14, no. 3: 1035. https://doi.org/10.3390/app14031035
APA StyleWu, J., & Zuo, R. (2024). Intelligent Computation Offloading Based on Digital Twin-Enabled 6G Industrial IoT. Applied Sciences, 14(3), 1035. https://doi.org/10.3390/app14031035