
Transformer–BiLSTM Fusion Neural Network for Short-Term PV Output Prediction Based on NRBO Algorithm and VMD



Abstract
1. Introduction
2. Principle of VMD
2.1. Construction of the Variational Constrained Model
2.2. Constrained Model Solving
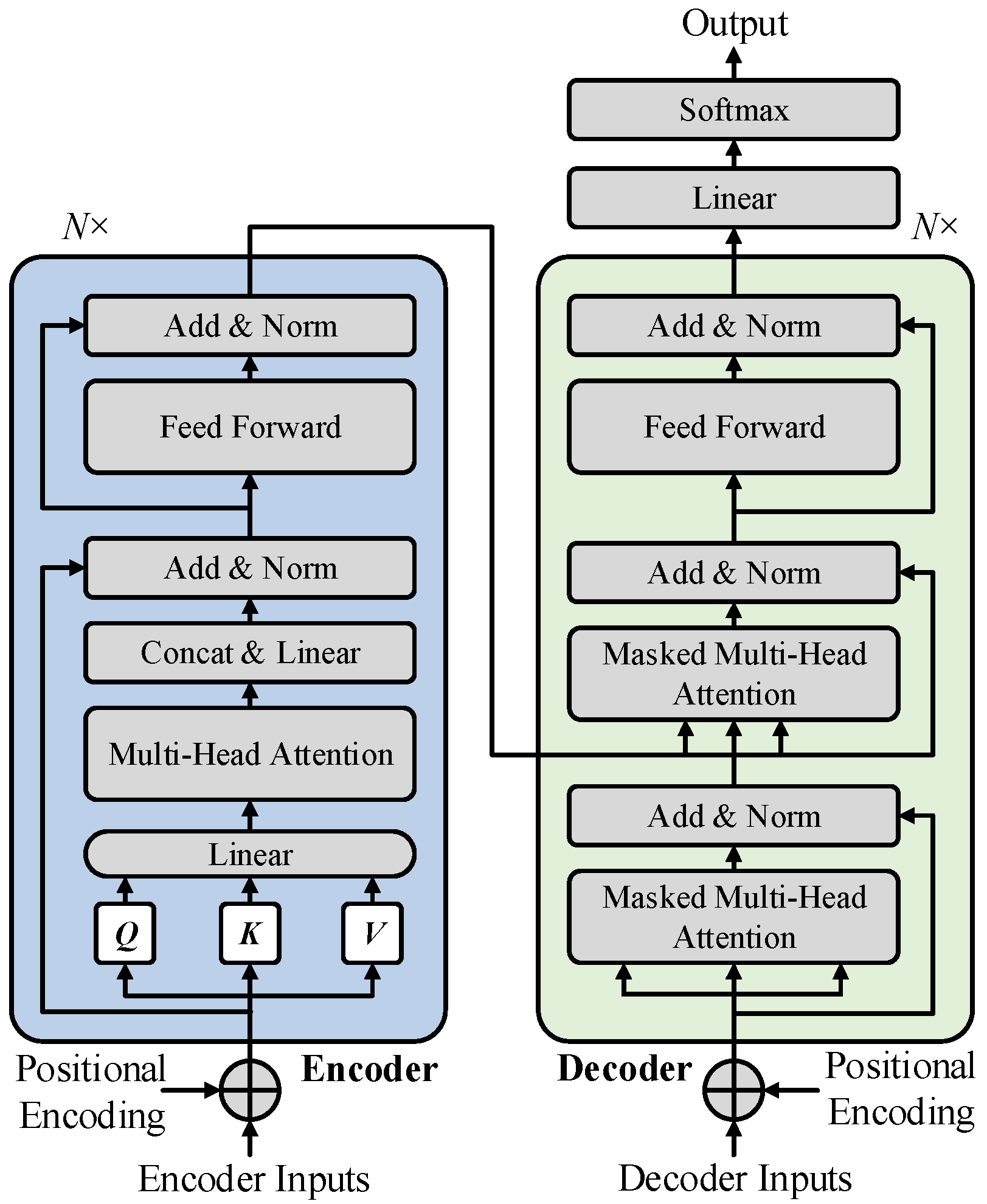
3. Transformer Encoder-Based BiLSTM Network Model
3.1. Feature Extraction of the Transformer Encoder
- 1
- Positional Encoding
- 2
- Self-Attention
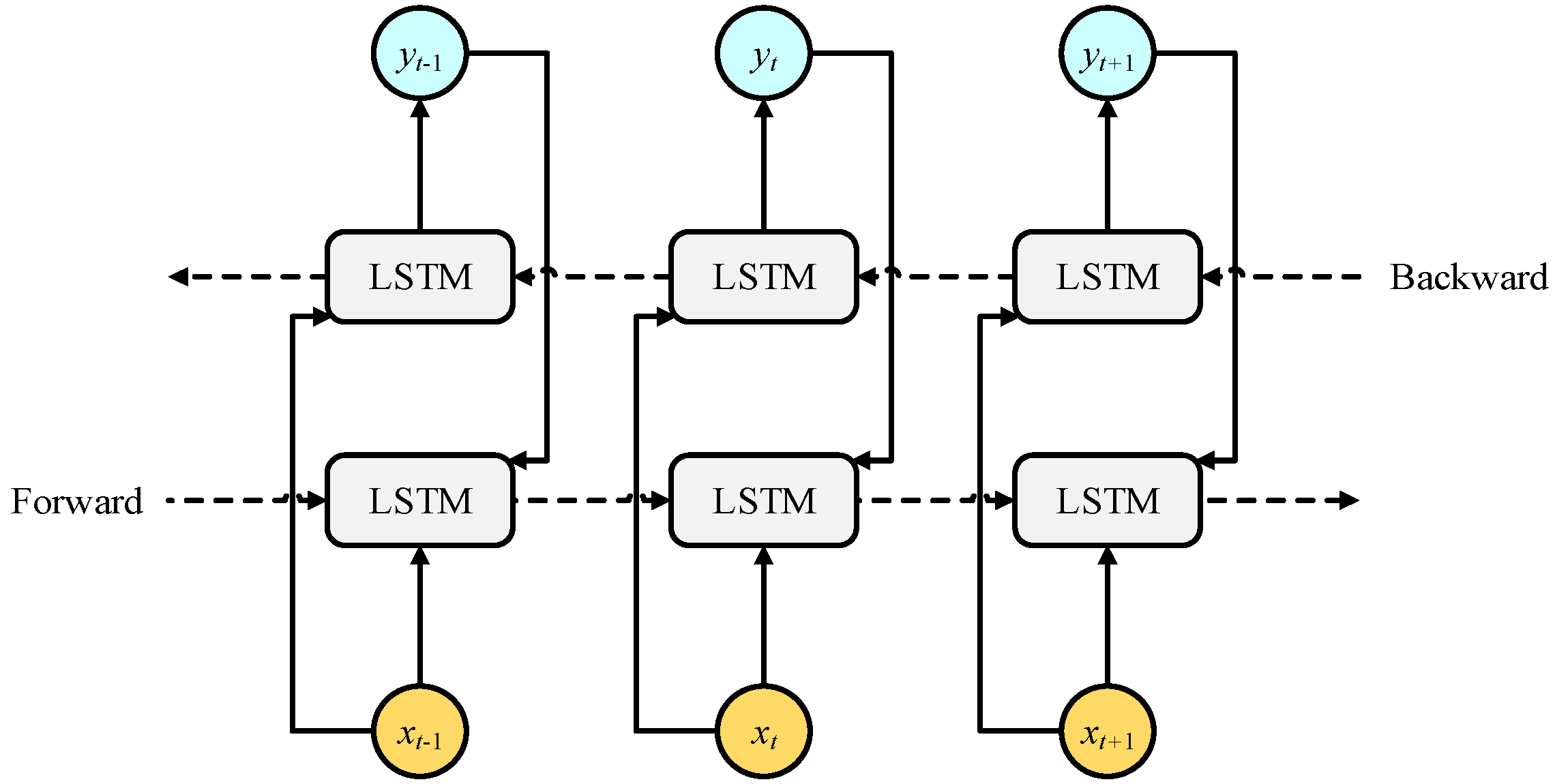
3.2. BiLSTM Network
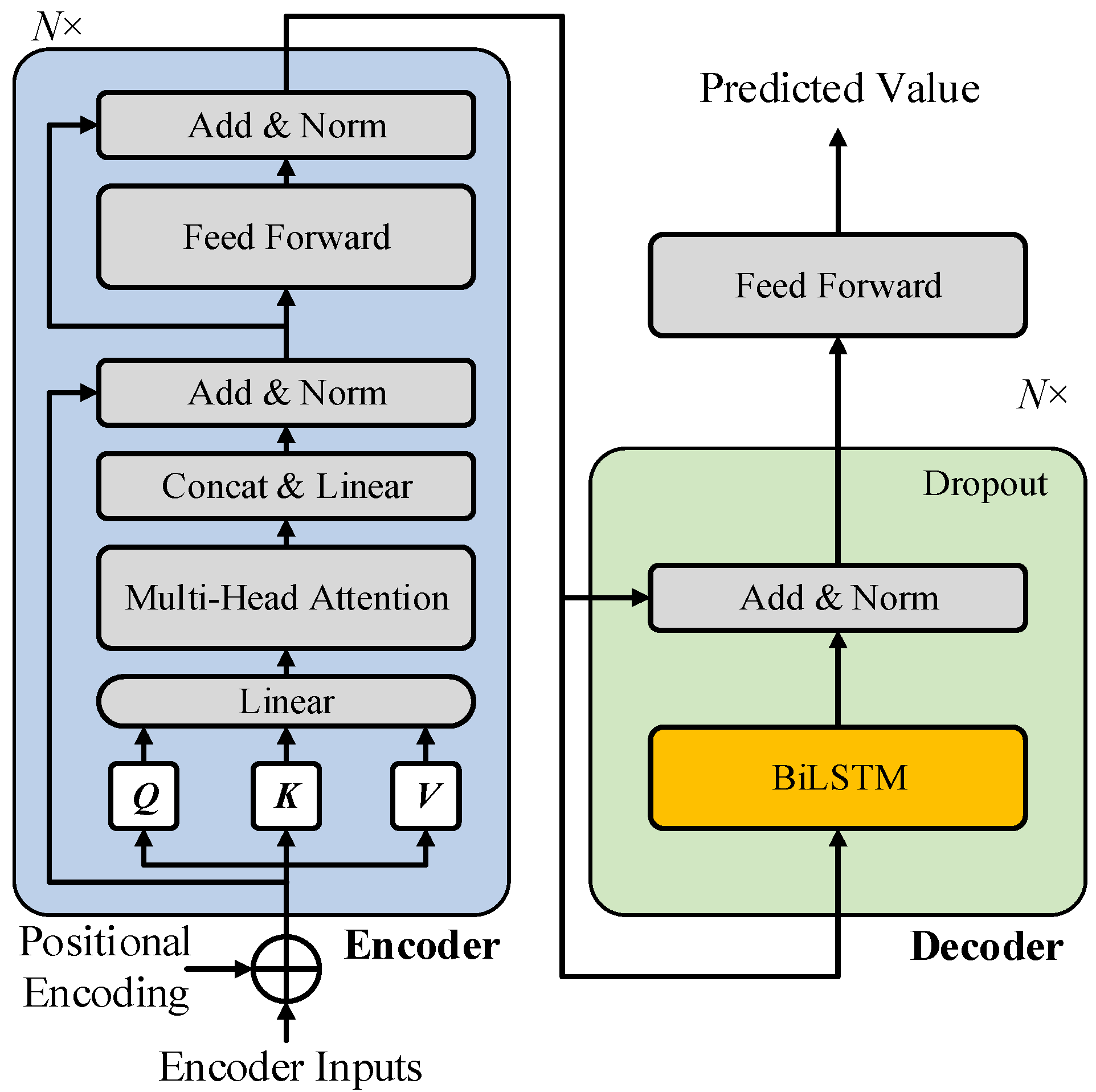
3.3. The Architecture of the Transformer–BiLSTM Model
4. NRBO Algorithm
4.1. Population Initialization
4.2. Newton–Raphson Search Rule (NRSR)
4.3. Trap Avoidance Operator (TAO)
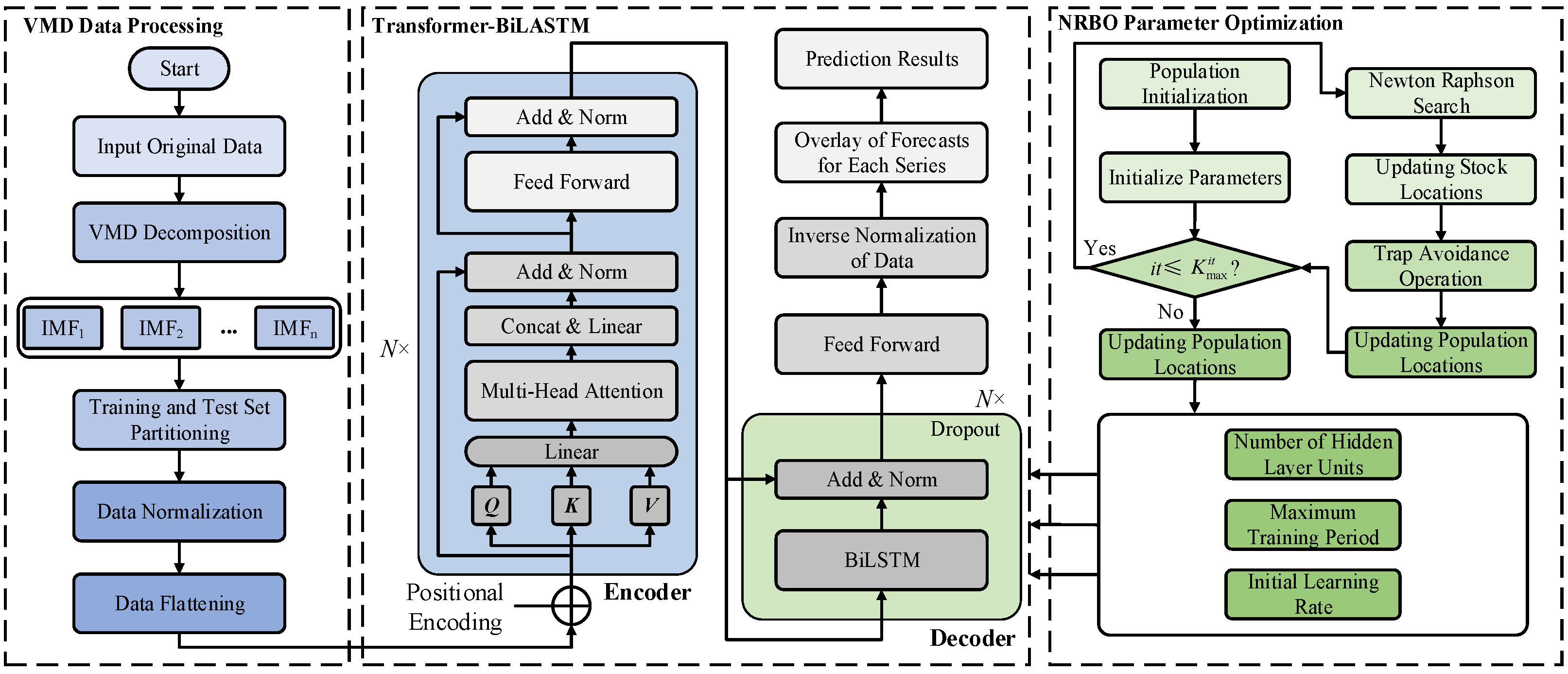
5. VMD-NRBO-Transformer-BiLSTM Hybrid Prediction Model
5.1. Optimization of Model Parameters
5.2. Overall Framework
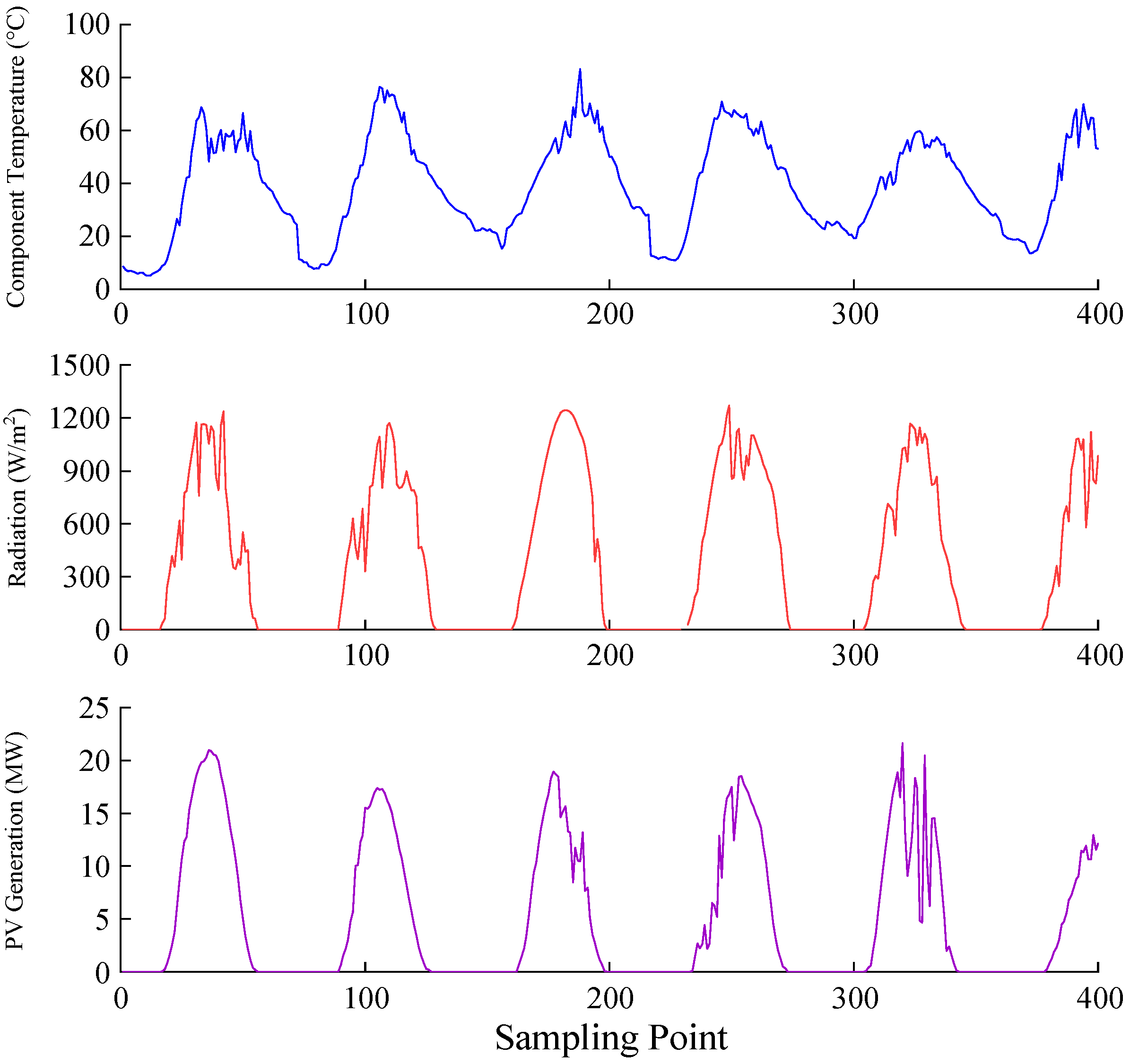
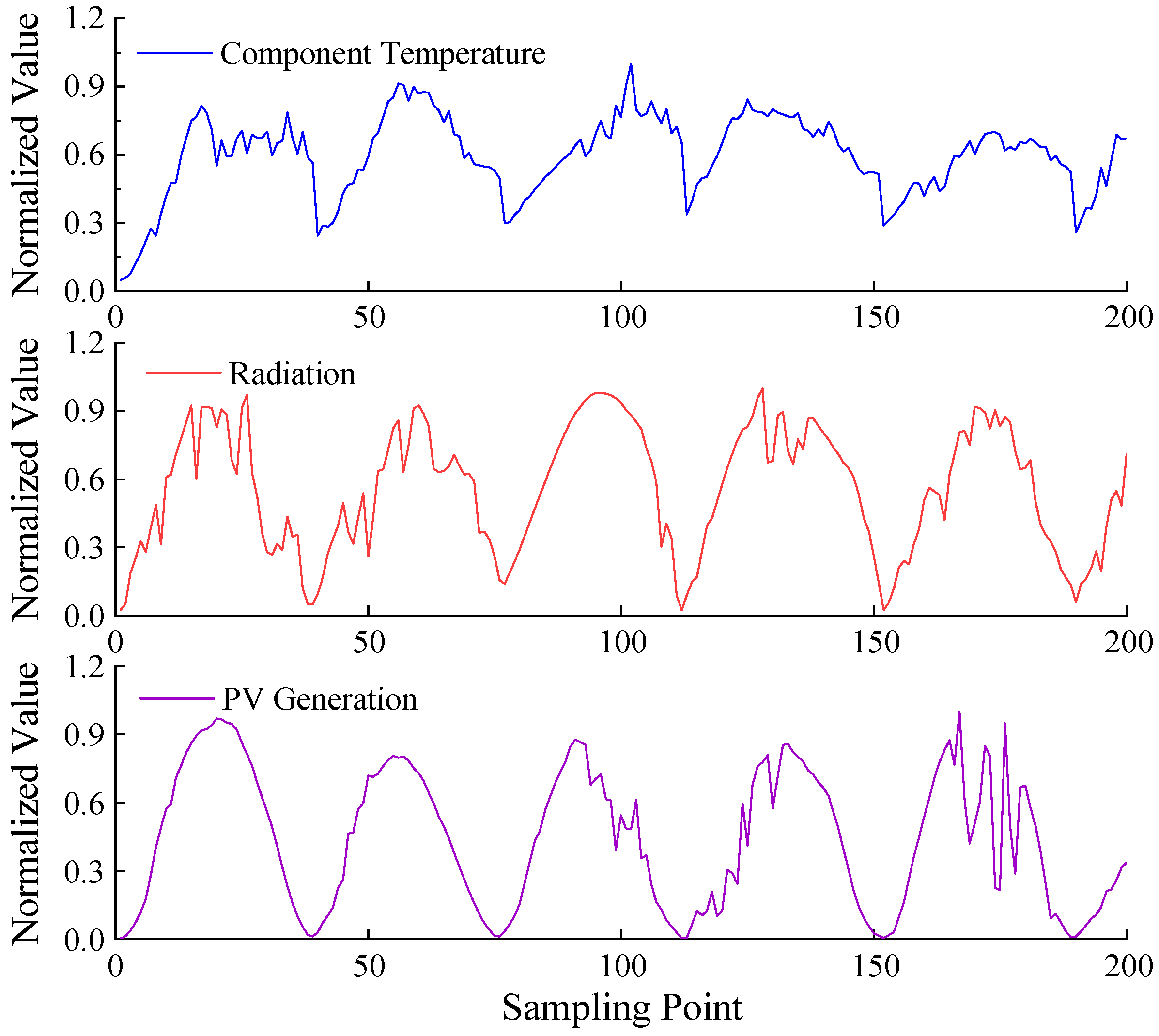
6. Example Analysis
6.1. Parameter Settings
6.2. Model Evaluation Metrics
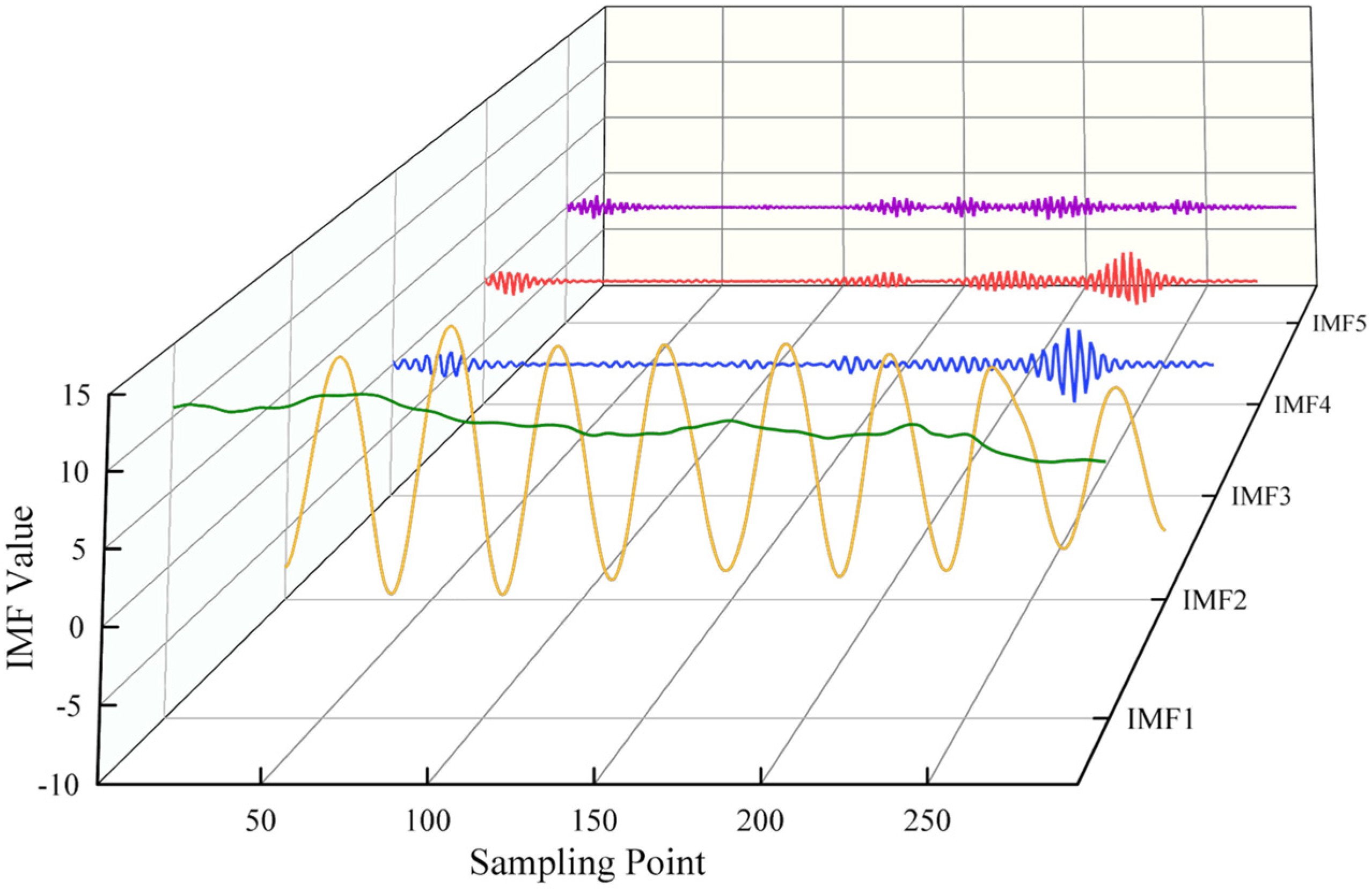
6.3. Decomposition of Original Data
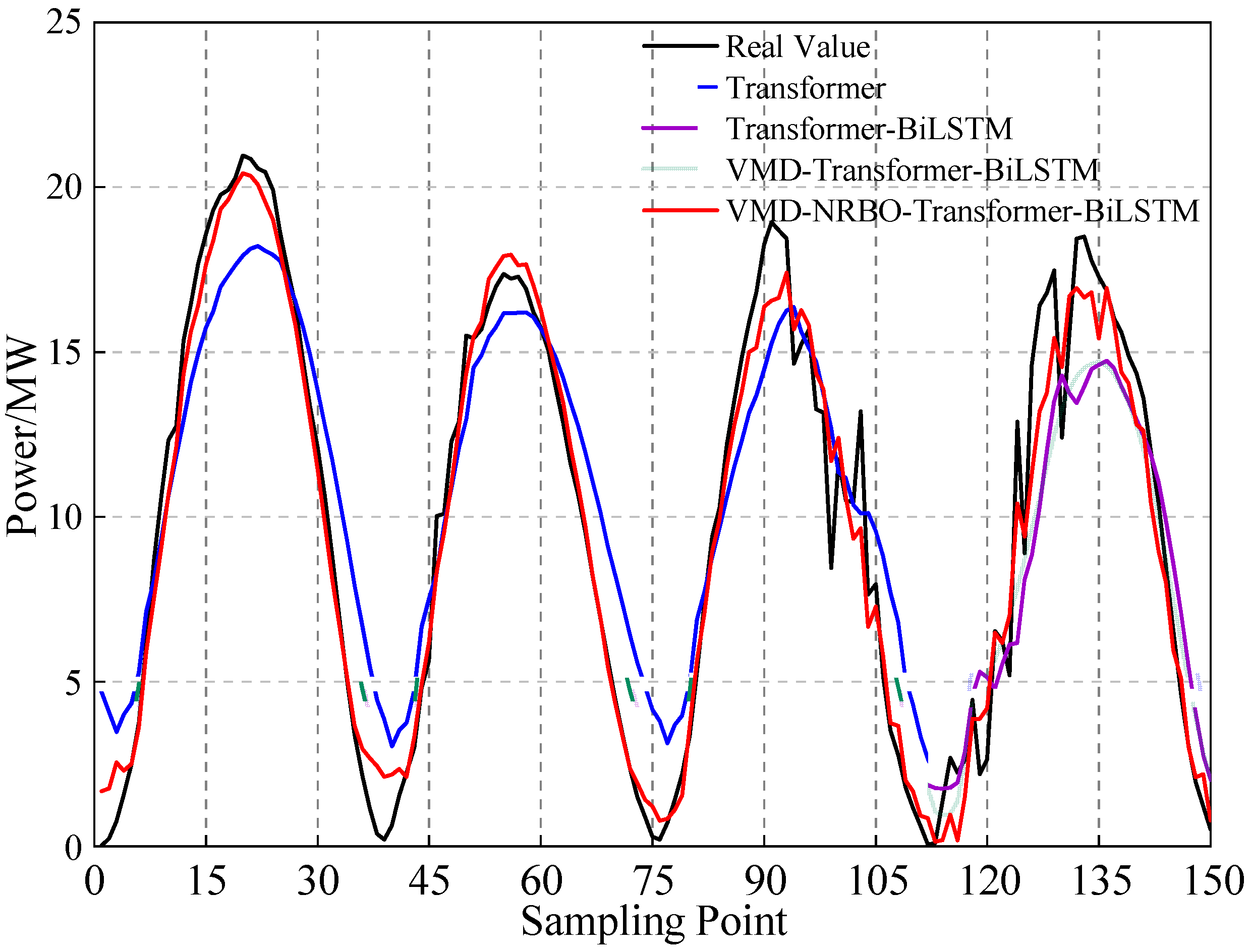
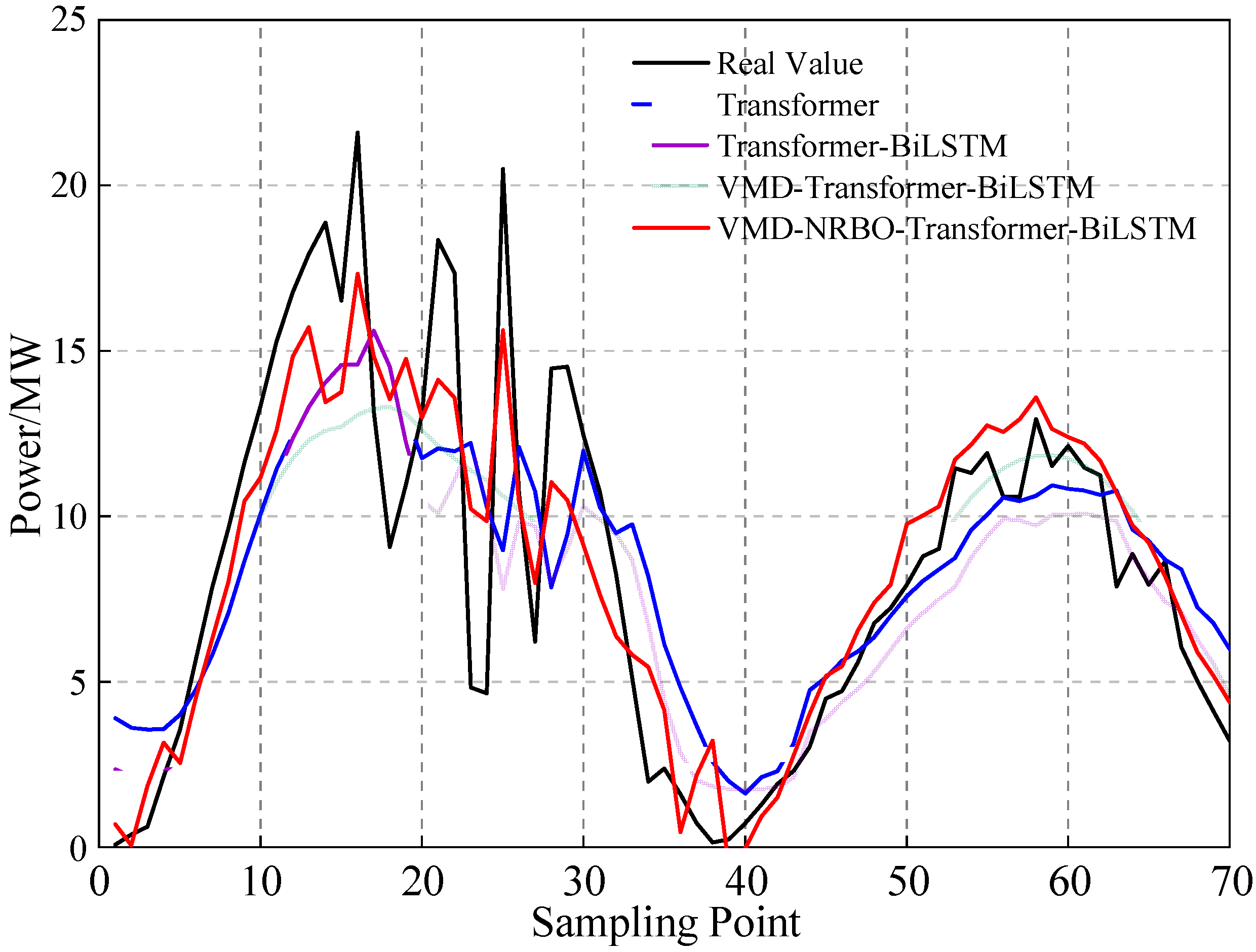
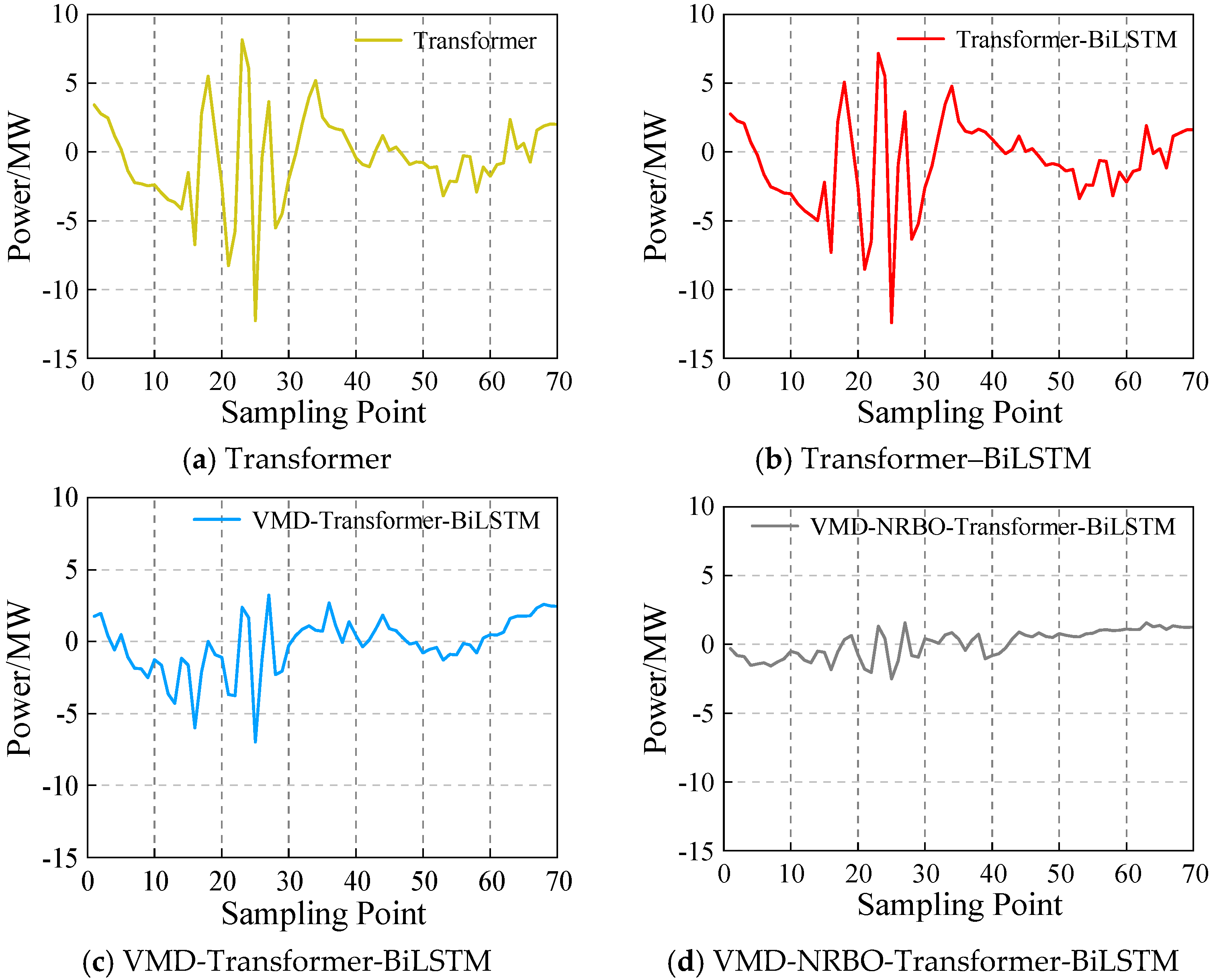
6.4. Comparison and Analysis of Prediction Results
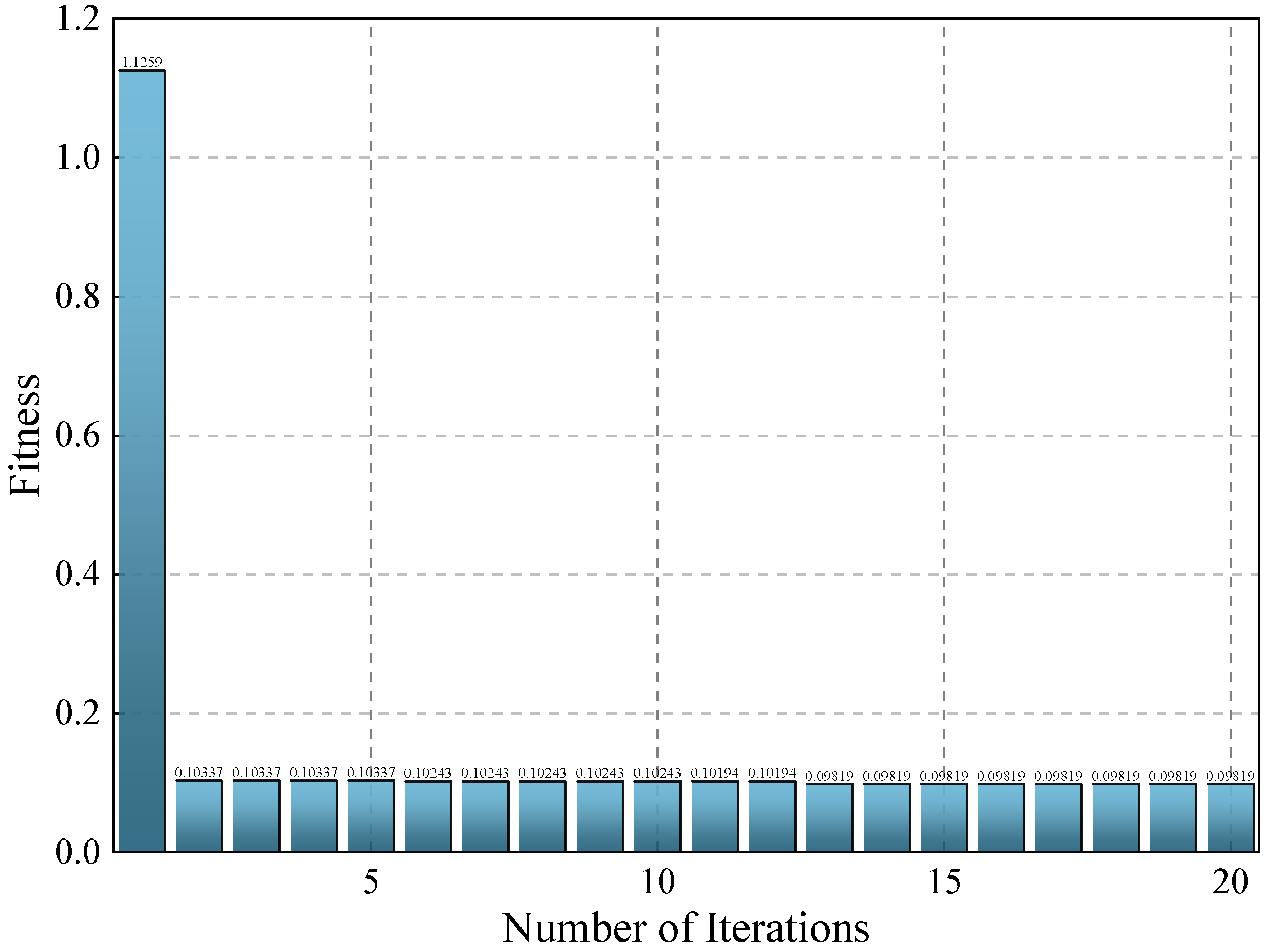
6.4.1. Iterations of the NRBO Algorithm
6.4.2. Comparison of Training and Test Results
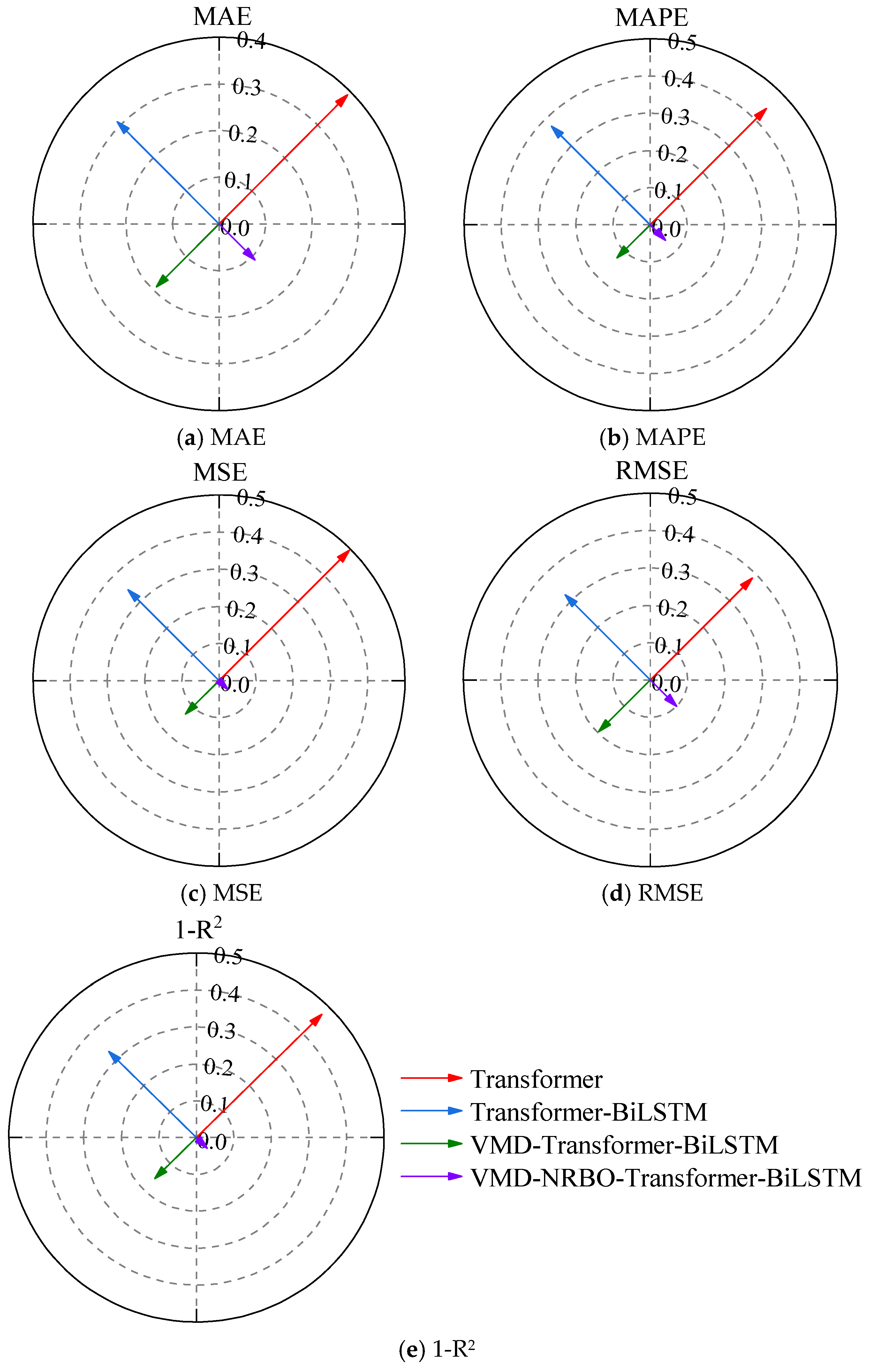
6.4.3. Comparison of Evaluation Metrics
7. Conclusions
- The VMD method effectively mitigates the challenge of feature extraction caused by the volatility of photovoltaic output data. By removing high-frequency components from each decomposed mode and reconstructing the data using the remaining components, the resulting waveform becomes smoother while preserving key information. This process effectively filters out noise, thereby reducing its interference with the model’s predictions.
- Building on the Transformer encoder–decoder architecture, BiLSTM is employed to replace the attention layer in the original Transformer decoder, while residual connections are introduced to process the input sequence data. This approach preserves the encoder’s information, enhances the model’s capacity to capture and process relevant features, and effectively addresses the challenge of long-term dependencies in sequence data.
- The NRBO algorithm overcomes the challenges associated with manually selecting hyperparameters for the network model, as well as the limitations of empirical selection methods in specific prediction scenarios. As a result, the model’s prediction accuracy is significantly enhanced. The MAE, MAPE, MSE, and RMSE are reduced by 42.38%, 53.40%, 73.94%, and 48.94%, respectively, while the R2 score increases by 15.18%.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, H.; Shi, Y.; Guo, L.; Qiao, L. China’s energy reform in the new era: Process, achievements and prospects. J. Manag. World 2022, 38, 6–24. [Google Scholar]
- Zhu, Q.; Li, J.; Qiao, J.; Shi, M.; Wang, C. Application and prospect of artificial intelligence technology in renewable energy forecasting. Proc. CSEE 2023, 43, 3027–3047. [Google Scholar]
- Hu, Z.; Gao, Y.; Ji, S.; Mae, M.; Imaizumi, T. Improved multistep ahead photovoltaic power prediction model based on LSTM and self-attention with weather forecast data. Appl. Energy 2024, 359, 122709. [Google Scholar] [CrossRef]
- Yu, Z. Transformer-Based Photovoltaic Power Generation Prediction Method for Long Sequences. Nanchang University, Nanchang, China, 2024. [Google Scholar]
- Chen, Y.; Ma, X.; Cheng, K.; Bao, T.; Chen, Y.; Zhou, C. Ultra-short-term power forecast of new energy based on meteorological feature selection and SVM model parameter optimization. Acta Energiae Solaris Sin. 2023, 44, 568–576. [Google Scholar]
- Zhong, A.; Wu, Z.; Xie, Z.; Mao, Y.; Yang, L. Research on short-term power prediction of photovoltaic power generation based on ACO-BP neural network. Electron. Des. Eng. 2024, 32, 82–86. [Google Scholar]
- Zhang, B.; Wang, X.; Zhou, W.; Chen, Z.; Wang, J. Photovoltaic power generation prediction based on machine learning taking Jinhua City as an example. Technol. Mark. 2022, 29, 17–22. [Google Scholar]
- López Santos, M.; García-Santiago, X.; Echevarría Camarero, F.; Blázquez Gil, G.; Carrasco Ortega, P. Application of temporal fusion transformer for day-ahead PV power forecasting. Energies 2022, 15, 5232. [Google Scholar] [CrossRef]
- Zhu, H.; Sun, Y.; Zhou, H.; Guan, Y.; Wang, N.; Ma, W. Intelligent clustering-based interval forecasting method for photovoltaic power generation using CNN-LSTM neural network. AIP Adv. 2024, 14, 065329. [Google Scholar] [CrossRef]
- Cao, Y.; Liu, G.; Luo, D.; Bavirisetti, D.P.; Xiao, G. Multi-timescale photovoltaic power forecasting using an improved Stacking ensemble algorithm based LSTM-Informer model. Energy 2023, 283, 128669. [Google Scholar] [CrossRef]
- Zhang, C.; Peng, T.; Nazir, M.S. A novel integrated photovoltaic power forecasting model based on variational mode decompo-sition and CNN-BiGRU considering meteorological variables. Electr. Power Syst. Res. 2022, 213, 108796. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational Mode Decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Yanovsky, I.; Dragomiretskiy, K. Variational destriping in remote sensing imagery: Total variation with L1 fidelity. Remote Sens. 2018, 10, 300. [Google Scholar] [CrossRef]
- Ma, K.; Nie, X.; Yang, J.; Zha, L.; Li, G.; Li, H. A power load forecasting method in port based on VMD-ICSS-hybrid neural network. Appl. Energy 2025, 377, 124246. [Google Scholar] [CrossRef]
- Wang, F.; Wang, S.; Zhang, L. Ultra short term power prediction of photovoltaic power generation based on VMD-LSTM and error compensation. Acta Energiae Solaris Sin. 2022, 43, 96–103. [Google Scholar]
- Yu, Y.; Shekhar, A.; Chandra Mouli, G.R.; Bauer, P. Comparative impact of three practical electric vehicle charging scheduling schemes on low voltage distribution grids. Energies 2022, 15, 8722. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar]
- Li, J.; Du, J.; Zhu, Y.; Guo, Y. Survey of Transformer-based object detection algorithms. Comput. Eng. Appl. 2023, 59, 48–64. [Google Scholar]
- Zhang, X. Semantic Relation Extraction Method Based on Bidirectional Encoder Representations from Transformers. Henan University, Kaifeng, China, 2021. [Google Scholar]
- Lu, W.; Li, J.; Wang, J.; Qin, L. A CNN-BiLSTM-AM method for stock price prediction. Neural Comput. Appl. 2021, 33, 4741–4753. [Google Scholar]
- Ren, J.; Wei, H.; Zou, Z.; Hou, T.; Yuan, Y.; Shen, J.; Wang, X. Ultra-short-term power load forecasting based on CNN-BiLSTM-Attention. Power Syst. Prot. Control 2022, 50, 108–116. [Google Scholar]
- Qin, Q.; Lai, X.; Zou, J. Direct multistep wind speed forecasting using LSTM neural network combining EEMD and fuzzy entropy. Appl. Sci. 2019, 9, 126. [Google Scholar] [CrossRef]
- Liu, T.; Liu, S.; Heng, J.; Gao, Y. A new hybrid approach for wind speed forecasting applying support vector machine with ensemble empirical mode decomposition and cuckoo search algorithm. Appl. Sci. 2018, 8, 1754. [Google Scholar] [CrossRef]
- Li, Y.; Shi, G.; Liao, Y.; Li, J.; Chen, X.; Huang, W. Research on monthly runoff prediction based on NRBO-SVM model. Water Power 2024, 1–7. Available online: https://link.cnki.net/urlid/11.1845.TV.20240808.1430.007 (accessed on 4 December 2024).
- Weerakoon, S.; Fernando, T. A variant of Newton’s method with accelerated third-order convergence. Appl. Math. Lett. 2000, 13, 87–93. [Google Scholar] [CrossRef]
- Argyros, I.K.; Magreñán, Á.A. Iterative Methods and Their Dynamics with Applications: A Contemporary Study; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Ahmadianfar, I.; Bozorg-Haddad, O.; Chu, X. Gradient-based optimizer: A new metaheuristic optimization algorithm. Inf. Sci. 2020, 540, 131–159. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Population Size | 3 |
| 20 | |
| Optimization Lower Bound lb | [50, 50, 0.001] |
| Optimization Upper Bound | [300, 300, 0.01] |
| Number of Attention Heads | 4 |
| Dropout | 0.2 |
| Number of Hidden Layer Units | 204 |
| Epoch | 300 |
| Initial Learning Rate | 0.0087 |
| Regularization Coefficient | 0.001 |
| Model | MAE | MAPE | MSE | RMSE | R2 |
|---|---|---|---|---|---|
| Transformer | 3.160 | 1.503 | 15.471 | 3.933 | 0.486 |
| Transformer–BiLSTM | 2.501 | 1.276 | 10.793 | 3.285 | 0.641 |
| VMD-Transformer-BiLSTM | 1.536 | 0.427 | 3.960 | 1.990 | 0.830 |
| VMD-NRBO-Transformer-BiLSTM | 0.885 | 0.199 | 1.032 | 1.016 | 0.956 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, X.; Wang, R.; Yang, Y.; Wang, J. Transformer–BiLSTM Fusion Neural Network for Short-Term PV Output Prediction Based on NRBO Algorithm and VMD. Appl. Sci. 2024, 14, 11991. https://doi.org/10.3390/app142411991
Fan X, Wang R, Yang Y, Wang J. Transformer–BiLSTM Fusion Neural Network for Short-Term PV Output Prediction Based on NRBO Algorithm and VMD. Applied Sciences. 2024; 14(24):11991. https://doi.org/10.3390/app142411991
Chicago/Turabian StyleFan, Xiaowei, Ruimiao Wang, Yi Yang, and Jingang Wang. 2024. "Transformer–BiLSTM Fusion Neural Network for Short-Term PV Output Prediction Based on NRBO Algorithm and VMD" Applied Sciences 14, no. 24: 11991. https://doi.org/10.3390/app142411991
APA StyleFan, X., Wang, R., Yang, Y., & Wang, J. (2024). Transformer–BiLSTM Fusion Neural Network for Short-Term PV Output Prediction Based on NRBO Algorithm and VMD. Applied Sciences, 14(24), 11991. https://doi.org/10.3390/app142411991