
Automating an Encoder–Decoder Incorporated Ensemble Model: Semantic Segmentation Workflow on Low-Contrast Underwater Images


Abstract
1. Introduction
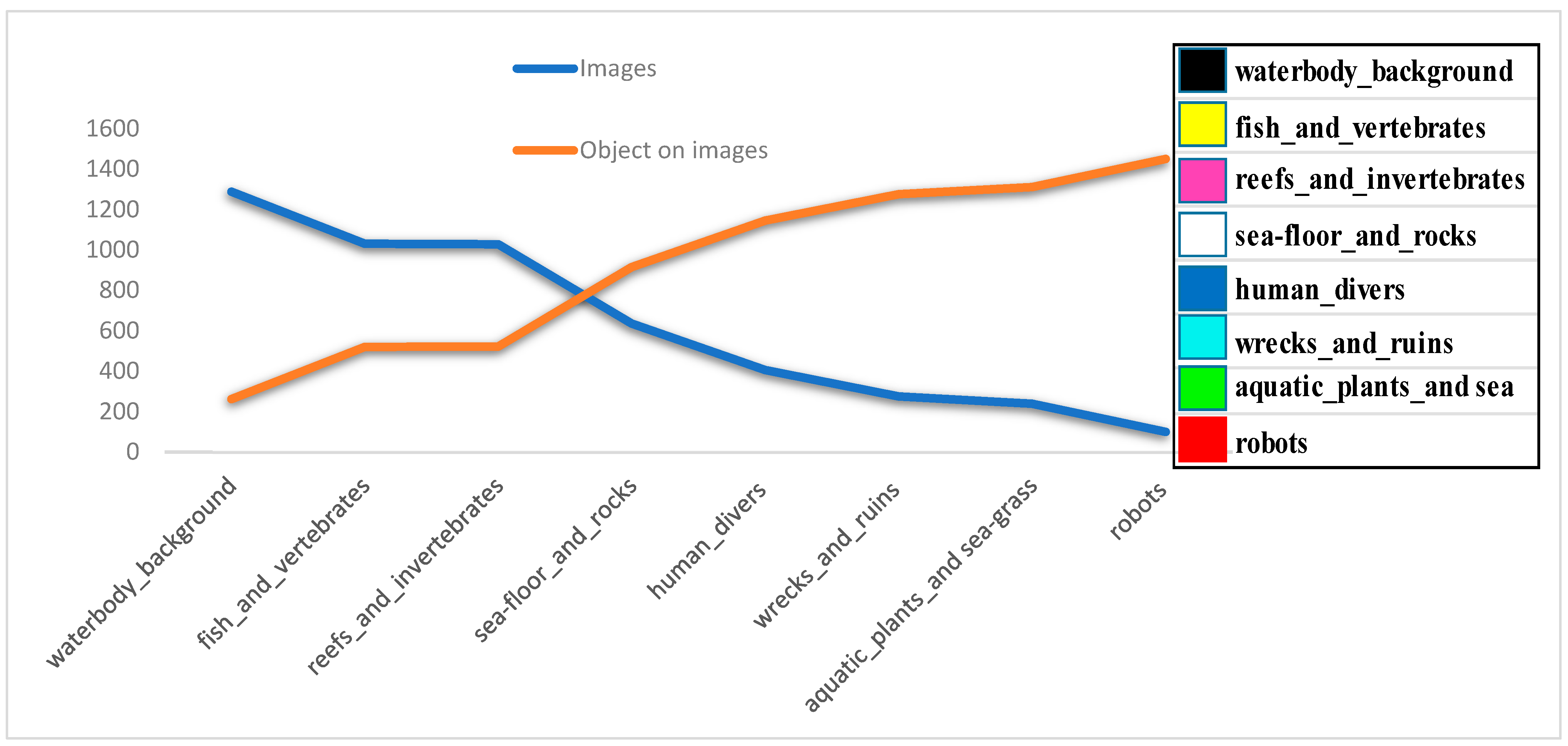
- Working on images taken underwater brings the problem of a low-contrast image quality. The images in the SUIM dataset have different sizes of resolution. Considering the computational cost and to obtain a standard suitable for all networks, all the RGB images and annotations were cropped as 256 × 256 × 3 patches. Afterwards, patches that do not contain any class information were detected and eliminated from both the annotation semantic context and the corresponding image path list. The process of cropping images into pieces helps to see and understand the broad connections between objects in the image. Moreover, focusing only on class objects without any loss of pixels is still sufficient for whole-scene segmentation, especially for such a low-contrast image dataset.
- As a workflow strategy to evaluate training schemes, different variations of encoder–decoder dense frame fusions were used and the generalization ability of the models was increased. Dice loss and Focal loss were used in the models to address parts such as feature class imbalance and insufficient segmentation, and with this method, predictions for all objects were generalized.
- Finally, instead of evaluating the success of these two models separately, a general performance success was achieved with an ensemble model. The ensemble model combines the model performances of independent models by considering their superior inference accuracy on a per-class basis separately and improves the model performances by emphasizing the better one on a per-class basis. This situation makes the ensemble model feasible for real-time underwater applications especially under offline circumstances. In this study, the ensemble model was constituted from the fusion of the models Res34+Unet and VGG19+FPN which obtained the best mIoU results.
2. Related Work
3. Materials and Methods
3.1. Data Description
3.2. Patch Generation
3.3. Encoder–Decoder Architectures
3.3.1. Encoder Architectures
3.3.2. Decoder Architectures
3.4. Weighted-Based Model-Optimization Algorithm
| Algorithm 1 Weighted-based model-optimization algorithm |
| 1. Input Data: test images D = {(x1, x2, …, xm)}, i = 1,2, …,m and Ypred- Predictions of each base model 2. Initialization Set parameters for a dataset: Cnum-Class number of the dataset, Range_ofWeights = (0,1) Wofmodel = [w1/10., w2/10., …wk/10.], where a weight array for each base model, k corresponds to the finalist model number 3. Prediction Search for the best combination for Wofmodel that gives maximum IoU for each wi in Range_ofweights Compute the mean IoU values for each class: Wts_IoU = meanIoU(Cnum) Sum the predictions of all objects on the specified axis and find the maximum predictions Wts_Ensemble= tensordot(Ypred, Wofmodel)max Measure the metrics (AUC, IoU), and store them in the wts_ensemble_IoU wts_ensemble_IoU = GenerateMetrics(D, Wts_Ensemble) return wts_ensemble_IoUresults |
4. Experiments and Analysis
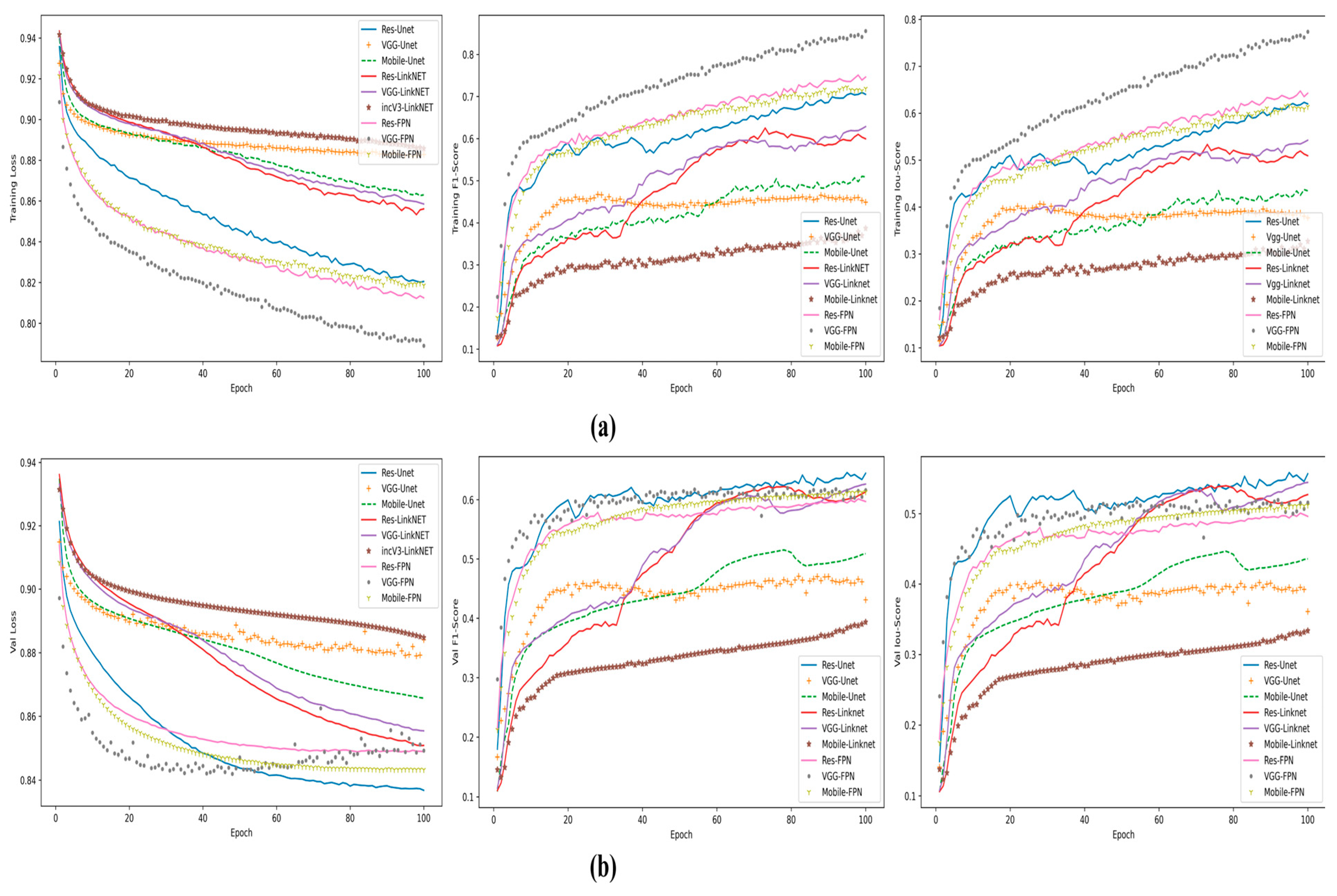
4.1. Evaluation Metrics
4.2. Dice Loss and Focal Loss Functions
5. Results
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Van Rijthoven, M.; Balkenhol, M.; Siliņa, K.; Van Der Laak, J.; Ciompi, F. HookNet: Multi-resolution convolutional neural networks for semantic segmentation in histopathology whole-slide images. Med. Image Anal. 2021, 68, 101890. [Google Scholar] [CrossRef] [PubMed]
- Schutera, M.; Rettenberger, L.; Pylatiuk, C.; Reischl, M. Methods for the frugal labeler: Multi-class semantic segmentation on heterogeneous labels. PLoS ONE 2022, 17, e0263656. [Google Scholar] [CrossRef] [PubMed]
- Yi, D.; Ahmedov, H.B.; Jiang, S.; Li, Y.; Flinn, S.J.; Fernandes, P.G. Coordinate-Aware Mask R-CNN with Group Normalization: A underwater marine animal instance segmentation framework. Neurocomputing 2024, 583, 127488. [Google Scholar] [CrossRef]
- Ulutas, G.; Ustubioglu, B. Underwater image enhancement using contrast limited adaptive histogram equalization and layered difference representation. Multimed. Tools Appl. 2021, 80, 15067–15091. [Google Scholar] [CrossRef]
- Md Jahidul, I.; Chelsey, E.; Yuyang, X.; Peigen, L.; Muntaqim, M.; Christopher, M.; Sadman Sakib, E.; Junaed, S. Semantic Segmentation of Underwater Imagery: Dataset and Benchmark. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020. [Google Scholar]
- He, W.; Wang, J.A.; Wang, L.; Pan, R.; Gao, W. A semantic segmentation algorithm for fashion images based on modified mask RCNN. Multimed. Tools Appl. 2023, 82, 28427–28444. [Google Scholar] [CrossRef]
- Lai, L.; Chen, J.; Zhang, C.; Zhang, Z.; Lin, G.; Wu, Q. Tackling background ambiguities in multi-class few-shot point cloud semantic segmentation. Knowl. Based Syst. 2022, 253, 109508. [Google Scholar] [CrossRef]
- Pranto, T.H.; Noman, A.A.; Noor, A.; Deepty, U.H.; Rahman, R.M. Effect of label noise on multi-class semantic segmentation: A case study on Bangladesh marine region. Appl. Artif. Intell. 2022, 36, 2039348. [Google Scholar] [CrossRef]
- Bajcsy, P.; Feldman, S.; Majurski, M.; Snyder, K.; Brady, M. Approaches to training multiclass semantic image segmentation of damage in concrete. J. Microsc. 2020, 279, 98–113. [Google Scholar] [CrossRef]
- Yadavendra, S.; Chand, S. Semantic segmentation and detection of satellite objects using U-Net model of deep learning. Multimed. Tools Appl. 2022, 81, 44291–44310. [Google Scholar] [CrossRef]
- Duan, C.; Belgiu, M.; Stein, A. Efficient Cloud Removal Network for Satellite Images Using SAR-optical Image Fusion. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Nunes, A.; Matos, A. Improving Semantic Segmentation Performance in Underwater Images. J. Mar. Sci. Eng. 2023, 11, 2268. [Google Scholar] [CrossRef]
- Samudrala, S.; Mohan, C.K. Semantic segmentation of breast cancer images using DenseNet with proposed PSPNet. Multimed. Tools Appl. 2024, 83, 46037–46063. [Google Scholar] [CrossRef]
- George, G.; Anusuya, S. Enhancing Underwater Image Segmentation: A Semantic Approach to Segment Objects in Challenging Aquatic Environment. Procedia Comput. Sci. 2024, 235, 361–371. [Google Scholar] [CrossRef]
- Kumar, S.; Sur, A.; Baruah, R.D. DatUS: Data-driven Unsupervised Semantic Segmentation with Pre-trained Self-supervised Vision Transformer. IEEE Trans. Cogn. Dev. Syst. 2024, 16, 1775–1788. [Google Scholar] [CrossRef]
- Chicchon, M.; Bedon, H.; Del-Blanco, C.R.; Sipiran, I. Semantic segmentation of fish and underwater environments using deep convolutional neural networks and learned active contours. IEEE Access 2023, 11, 33652–33665. [Google Scholar] [CrossRef]
- Priyanka, N.; Lal, S.; Nalini, S.; Reddy, J.; Dell’Acqua, F. DIResUNet: Architecture for multiclass semantic segmentation of high resolution remote sensing imagery data. Appl. Intell. 2022, 52, 15462–15482. [Google Scholar] [CrossRef]
- Pergeorelis, M.; Bazik, M.; Saponaro, P.; Kim, J.; Kambhamettu, C. Synthetic data for semantic segmentation in underwater imagery. In Proceedings of the OCEANS 2022, Hampton Roads, VA, USA, 17–20 October 2022; pp. 1–6. [Google Scholar]
- Kabir, I.; Shaurya, S.; Maigur, V.; Thakurdesai, N.; Latnekar, M.; Raunak, M.; Reza, M.A. Few-Shot Segmentation and Semantic Segmentation for Underwater Imagery. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; pp. 11451–11457. [Google Scholar]
- Yu, L.; Fan, G. DrsNet: Dual-resolution semantic segmentation with rare class-oriented superpixel prior. Multimed. Tools Appl. 2021, 80, 1687–1706. [Google Scholar] [CrossRef]
- Liu, X.; Deng, Z.; Yang, Y. Recent progress in semantic image segmentation. Artif. Intell. Rev. 2019, 52, 1089–1106. [Google Scholar] [CrossRef]
- He, Z.; Cao, L.; Luo, J.; Xu, X.; Tang, J.; Xu, J.; Chen, Z. UISS-Net: Underwater Image Semantic Segmentation Network for improving boundary segmentation accuracy of underwater images. Aquac. Int. 2024, 32, 5625–5638. [Google Scholar] [CrossRef]
- Thisanke, H.; Deshan, C.; Chamith, K.; Seneviratne, S.; Vidanaarachchi, R.; Herath, D. Semantic segmentation using Vision Transformers: A survey. Eng. Appl. Artif. Intell. 2023, 126, 106669. [Google Scholar] [CrossRef]
- Pavithra, S. An efficient approach to detect and segment underwater images using Swin Transformer. Results Eng. 2024, 23, 102460. [Google Scholar]
- Lin, A.; Chen, B.; Xu, J.; Zhang, Z.; Lu, G.; Zhang, D. Ds-transunet: Dual swin transformer u-net for medical image segmentation. IEEE Trans. Instrum. Meas. 2022, 71, 1–15. [Google Scholar] [CrossRef]
- Sun YBi, F.; Gao, Y.; Chen, L.; Feng, S. A multi-attention UNet for semantic segmentation in remote sensing images. Symmetry 2022, 14, 906. [Google Scholar] [CrossRef]
- Rajamani, K.T.; Rani, P.; Siebert, H.; ElagiriRamalingam, R.; Heinrich, M.P. Attention-augmented U-Net (AA-U-Net) for semantic segmentation. Signal Image Video Process. 2023, 17, 981–989. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Chiu, Y.C.; Tsai, C.Y.; Ruan, M.D.; Shen, G.Y.; Lee, T.T. Mobilenet-SSDv2: An improved object detection model for embedded systems. In Proceedings of the 2020 International Conference on System Science and Engineering (ICSSE), Kagawa, Japan, 31 August–3 September 2020; pp. 1–5. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting The encoder Representations for Efficient Semantic Segmentation. In Proceedings of the IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017. [Google Scholar]
- Jin, L.; Liu, G. An approach on image processing of deep learning based on improved SSD. Symmetry 2021, 13, 495. [Google Scholar] [CrossRef]
- Zhao, R.; Buyue, Q.; Xianli, Z.; Yang, L.; Rong, W.; Yang, L.; Yinggang, P. Rethinking dice loss for medical image segmentation. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 20 November 2020; pp. 851–860. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2020, arXiv:1412.6980. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | Validation | |||||
|---|---|---|---|---|---|---|
| Model | Loss | F1-Score | mIoU |  Loss Loss |  F1-Score F1-Score |  mIoU mIoU |
| Res34+Unet | 0.851 | 0.515 | 0.601 | 0.852 | 0.510 | 0.592 |
| VGG19+FPN | 0.818 | 0.630 | 0.723 | 0.849 | 0.491 | 0.590 |
| Mobilenet V2+FPN | 0.839 | 0.520 | 0.623 | 0.851 | 0.468 | 0.566 |
| Res34+FPN | 0.837 | 0.536 | 0.641 | 0.856 | 0.463 | 0.561 |
| VGG19+Linknet | 0.883 | 0.439 | 0.500 | 0.878 | 0.443 | 0.501 |
| Res34+Linknet | 0.881 | 0.409 | 0.476 | 0.876 | 0.425 | 0.488 |
| Mobilenet V2+Unet | 0.883 | 0.359 | 0.416 | 0.882 | 0.380 | 0.436 |
| VGG19+Unet | 0.889 | 0.371 | 0.433 | 0.886 | 0.375 | 0.436 |
| Mobilenet V2+Linknet | 0.897 | 0.267 | 0.310 | 0.895 | 0.283 | 0.326 |
| Model | mIoU |
|---|---|
| Res34+Unet | 0.592 |
| VGG19+FPN | 0.590 |
| Proposed Ensemble Model | 0.652 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bektaş, J. Automating an Encoder–Decoder Incorporated Ensemble Model: Semantic Segmentation Workflow on Low-Contrast Underwater Images. Appl. Sci. 2024, 14, 11964. https://doi.org/10.3390/app142411964
Bektaş J. Automating an Encoder–Decoder Incorporated Ensemble Model: Semantic Segmentation Workflow on Low-Contrast Underwater Images. Applied Sciences. 2024; 14(24):11964. https://doi.org/10.3390/app142411964
Chicago/Turabian StyleBektaş, Jale. 2024. "Automating an Encoder–Decoder Incorporated Ensemble Model: Semantic Segmentation Workflow on Low-Contrast Underwater Images" Applied Sciences 14, no. 24: 11964. https://doi.org/10.3390/app142411964
APA StyleBektaş, J. (2024). Automating an Encoder–Decoder Incorporated Ensemble Model: Semantic Segmentation Workflow on Low-Contrast Underwater Images. Applied Sciences, 14(24), 11964. https://doi.org/10.3390/app142411964