
Intelligent Recognition of Road Internal Void Using Ground-Penetrating Radar

Abstract
1. Introduction
2. Materials and Methods
2.1. Data Acquisition
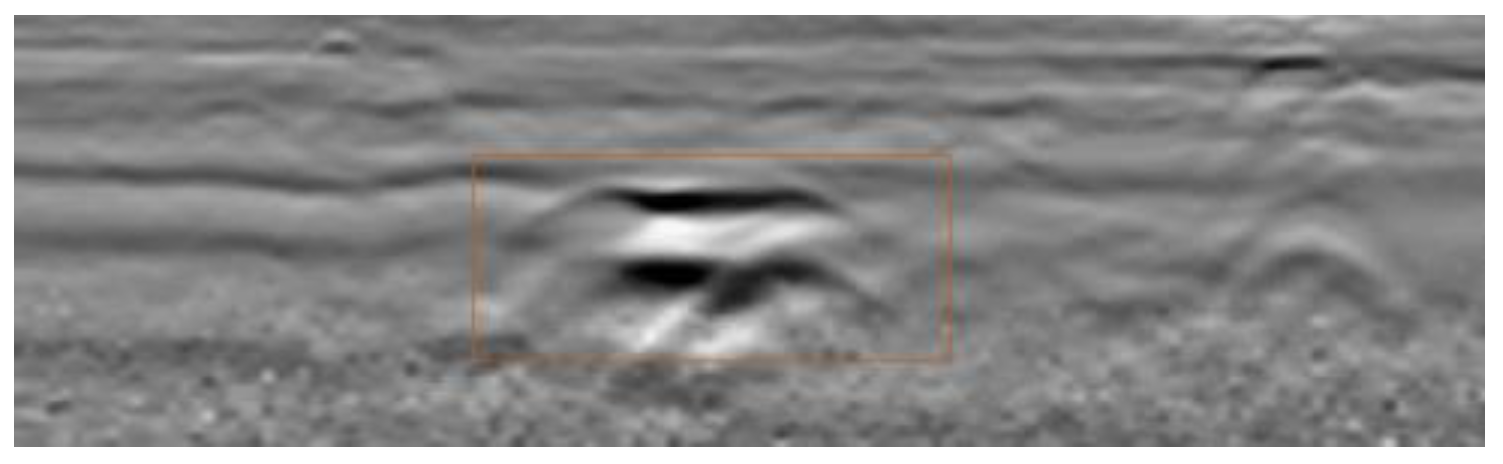
2.2. Echo Characteristics of Internal Voids in Roads
2.3. Image Quality Evaluation Metrics
- (1)
- PSNR
- (2)
- SSIM
- (3)
- LPIPS
- (4)
- NIQE
3. Results
3.1. Research on Preprocessing Techniques for Internal Void Images in Road
3.1.1. Image Size Optimization
3.1.2. Image Quality Degradation and Enhancement
3.2. Research on a Road Internal Void Image Enhancement Method Based on Improved Unet Model
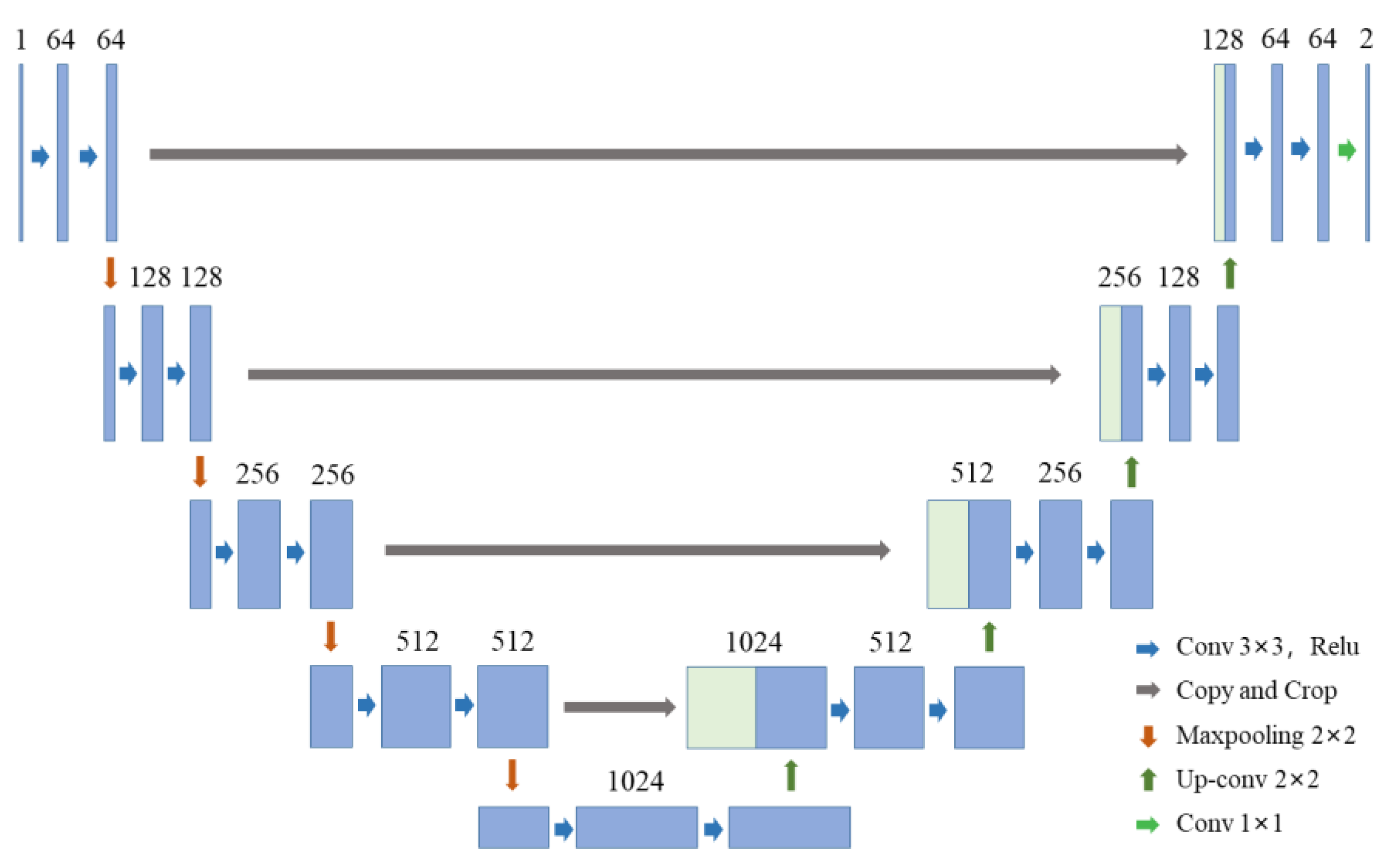
3.2.1. Unet Neural Network Model
3.2.2. MHSA Module and MHCA Module
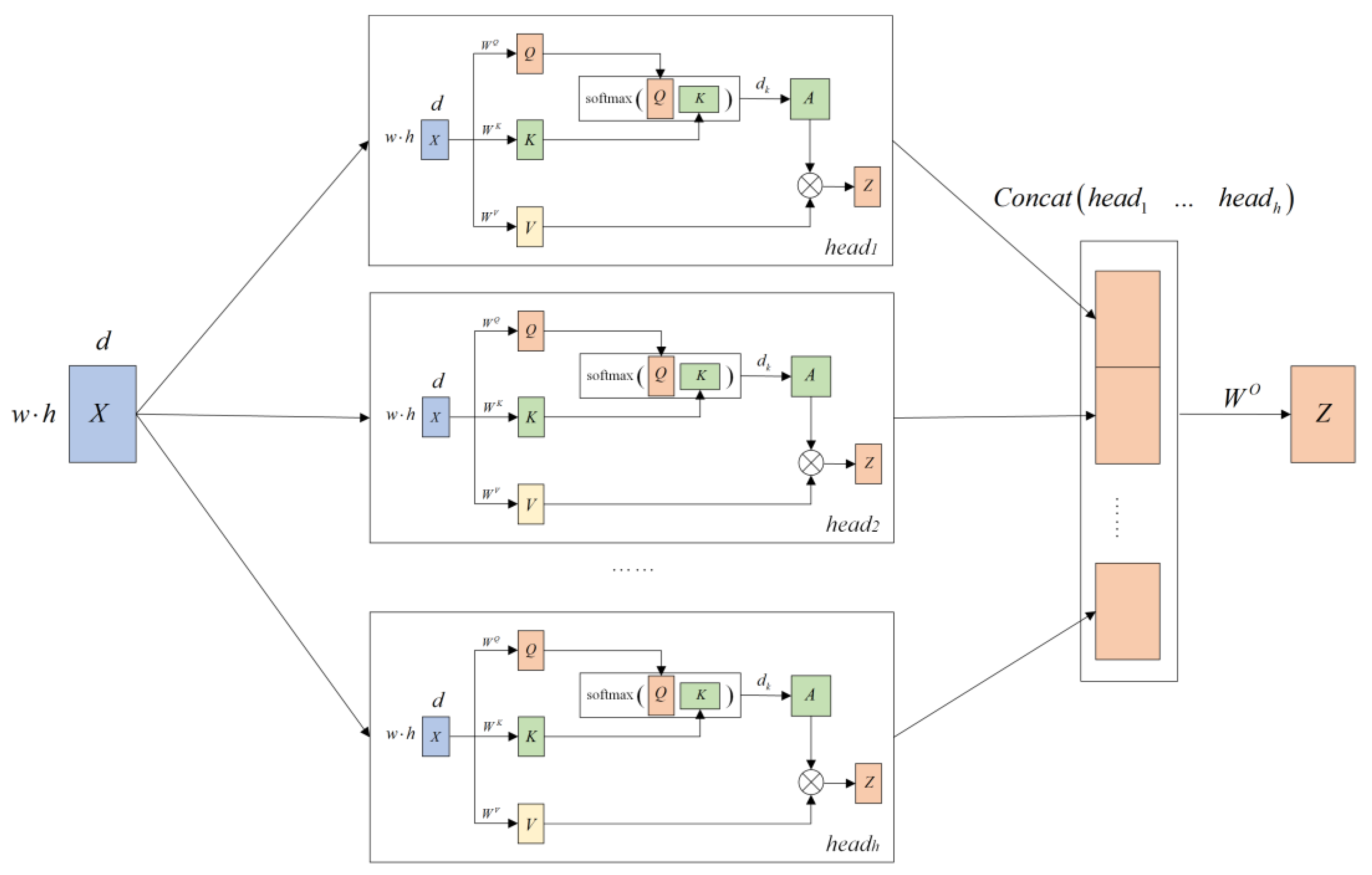
- (1) MHSA Module
- (2) Self-Attention Mechanism (SAM)
- (3) MHSA mechanism
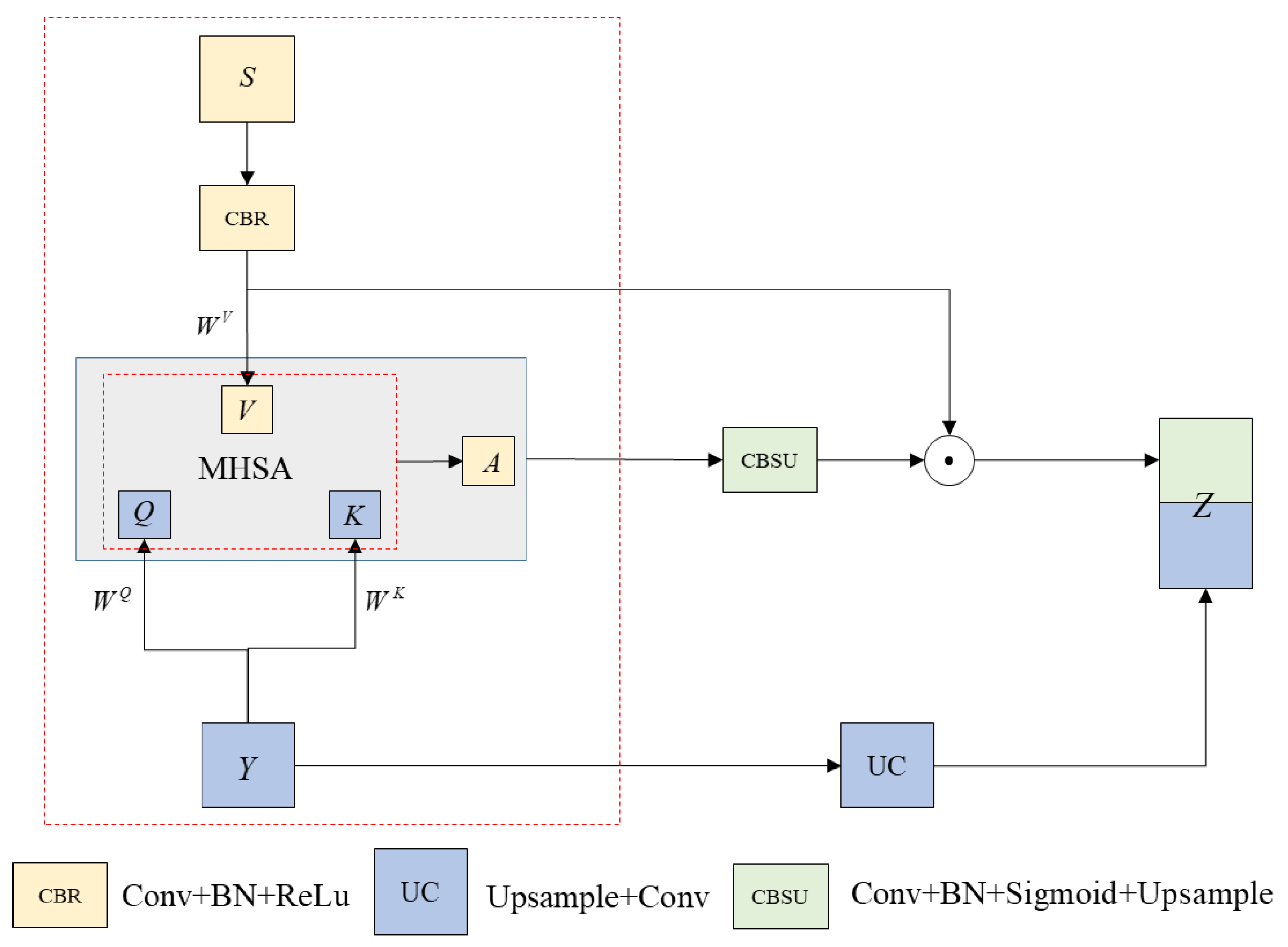
- (4) MHCA Module
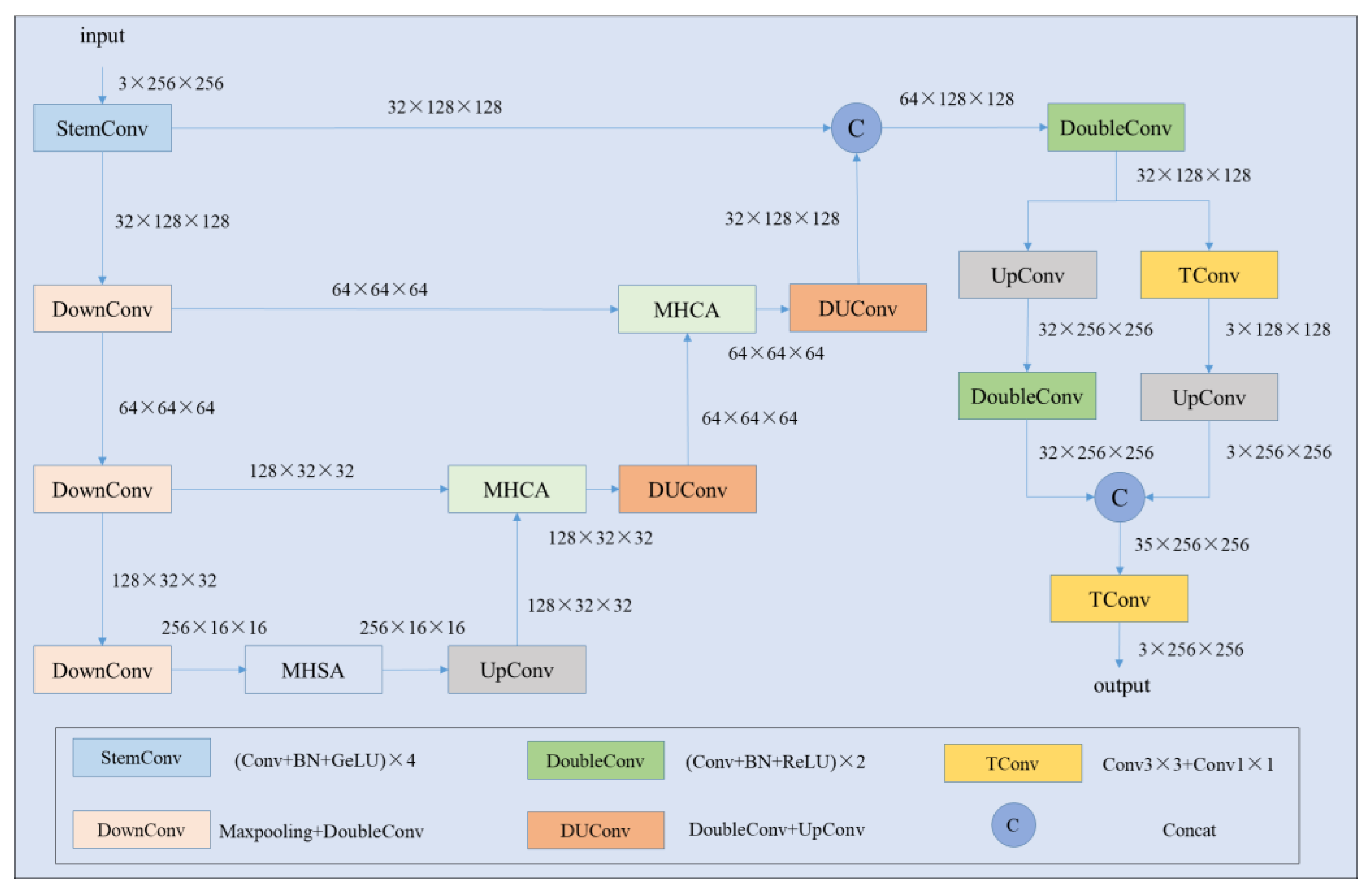
3.2.3. Image Enhancement Model Design Based on an Improved Unet Model—MHUnet
3.2.4. Analysis of Image Enhancement Effects Based on the MHUnet Model
3.3. Comparative Analysis of Void Intelligent Recognition Performance
3.4. Engineering Validation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Z.; Sun, T.; Huang, T.; Liu, G.; Tao, Y.; Wang, G.; Wang, L. Forward Modeling and Model Test of Ground—Penetrating Radar toward Typical Asphalt Pavement Distresses. Adv. Civ. Eng. 2023, 2023, 2227326. [Google Scholar] [CrossRef]
- Primusz, P.; Abdelsamei, E.; Mahmoud, A.; Sipos, G.; Fi, I.; Herceg, A.; Tóth, C. Assessment of In Situ Compactness and Air Void Content of New Asphalt Layers Using Ground-Penetrating Radar Measurements. Appl. Sci. 2024, 14, 614. [Google Scholar] [CrossRef]
- Xiong, X.; Meng, A.; Lu, J.; Tan, Y.; Chen, B.; Tang, J.; Zhang, C.; Xiao, S.; Hu, J. Automatic detection and location of pavement internal distresses from ground penetrating radar images based on deep learning. Constr. Build. Mater. 2024, 411, 134483. [Google Scholar] [CrossRef]
- Leng, Z.; Al-Qadi, I.L.; Shangguan, P.; Son, S. Field application of ground-penetrating radar for measurement of asphalt mixture density: Case study of Illinois route 72 overlay. Transp. Res. Rec. 2012, 2304, 133–141. [Google Scholar] [CrossRef]
- Leng, Z. Prediction of In-Situ Asphalt Mixture Density Using Ground Penetrating Radar: Theoretical Development and Field Verification; University of Illinois at Urbana-Champaign: Champaign, IL, USA, 2011. [Google Scholar]
- Wang, W.; Xiang, W.; Li, C.; Qiu, S.; Wang, Y.; Wang, X.; Bu, S.; Bian, Q. A Case Study of Pavement Foundation Support and Drainage Evaluations of Damaged Urban Cement Concrete Roads. Appl. Sci. 2024, 14, 1791. [Google Scholar] [CrossRef]
- Xu, Y.; Shi, X.; Yao, Y. Performance Assessment of Existing Asphalt Pavement in China’s Highway Reconstruction and Expansion Project Based on Coupling Weighting Method and Cloud Model Theory. Appl. Sci. 2024, 14, 5789. [Google Scholar] [CrossRef]
- Leng, Z.; Al-Qadi, I.L. An innovative method for measuring pavement dielectric constant using the extended CMP method with two air-coupled GPR systems. NDT E Int. 2014, 66, 90–98. [Google Scholar] [CrossRef]
- Zhang, Z.; Huang, S.; Zhang, K. Accurate detection method for compaction uniformity of asphalt pavement. Constr. Build. Mater. 2017, 145, 88–97. [Google Scholar] [CrossRef]
- Tang, J.; Huang, Z.; Li, W.; Yu, H. Low compaction level detection of newly constructed asphalt pavement based on regional index. Sensors 2022, 22, 7980. [Google Scholar] [CrossRef]
- Mioduszewski, P.; Sorociak, W. Acoustic evaluation of road surfaces using different Close Proximity testing devices. Appl. Acoust. 2023, 204, 109255. [Google Scholar] [CrossRef]
- Kim, S.Y.; Kang, S.; Park, G.; Lee, D.; Lim, Y.; Lee, J.S. Detection of roadbed layers in mountainous area using down-up-crosshole penetrometer and ground penetrating radar. Measurement 2024, 224, 113889. [Google Scholar] [CrossRef]
- Kang, S.; Lee, J.S.; Park, G.; Kim, N.; Park, J. Unpaved road characterization during rainfall scenario: Electromagnetic wave and cone penetration assessment. NDT E Int. 2023, 139, 102930. [Google Scholar] [CrossRef]
- Sabery, S.M.; Bystrov, A.; Gardner, P.; Stroescu, A.; Gashinova, M. Road surface classification based on radar imaging using convolutional neural network. IEEE Sens. J. 2021, 21, 18725–18732. [Google Scholar] [CrossRef]
- Benedetto, A.; Tosti, F.; Ciampoli, L.B.; D’amico, F. An overview of ground-penetrating radar signal processing techniques for road inspections. Signal Process. 2017, 132, 201–209. [Google Scholar] [CrossRef]
- Benedetto, A.; Benedetto, F.; De Blasiis, M.R.; Giunta, G. Reliability of signal processing technique for pavement damages detection and classification using ground penetrating radar. IEEE Sens. J. 2005, 5, 471–480. [Google Scholar] [CrossRef]
- Leucci, G. Ground penetrating radar: The electromagnetic signal attenuation and maximum penetration depth. Sch. Res. Exch. 2008, 2008, 926091. [Google Scholar] [CrossRef]
- Potin, D.; Duflos, E.; Vanheeghe, P. Landmines ground-penetrating radar signal enhancement by digital filtering. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2393–2406. [Google Scholar] [CrossRef]
- Li, R.; Zhang, H.; Chen, Z.; Yu, N.; Kong, W.; Li, T.; Wang, E.; Wu, X.; Liu, Y. Denoising method of ground-penetrating radar signal based on independent component analysis with multifractal spectrum. Measurement 2022, 192, 110886. [Google Scholar] [CrossRef]
- Xue, W.; Zhu, J.; Rong, X.; Huang, Y.; Yang, Y.; Yu, Y. The analysis of ground penetrating radar signal based on generalized S transform with parameters optimization. J. Appl. Geophys. 2017, 140, 75–83. [Google Scholar] [CrossRef]
- Li, F.; Yang, F.; Qiao, X.; Xing, W.; Zhou, C.; Xing, H. 3D ground penetrating radar cavity identification algorithm for urban roads using transfer learning. Meas. Sci. Technol. 2023, 34, 055106. [Google Scholar] [CrossRef]
- Li, F.; Yang, F.; Xie, Y.; Qiao, X.; Du, C.; Li, C.; Ru, Q.; Zhang, F.; Gu, X.; Yong, Z. Research on 3D ground penetrating radar deep underground cavity identification algorithm in urban roads using multi-dimensional time-frequency features. NDT E Int. 2024, 143, 103060. [Google Scholar] [CrossRef]
- Kang, M.S.; Kim, N.; Lee, J.J.; An, Y.K. Deep learning-based automated underground cavity detection using three-dimensional ground penetrating radar. Struct. Health Monit. 2020, 19, 173–185. [Google Scholar] [CrossRef]
- Xiong, X.; Tan, Y.; Hu, J.; Hong, X.; Tang, J. Evaluation of Asphalt Pavement Internal Distresses Using Three-Dimensional Ground-Penetrating Radar. Int. J. Pavement Res. Technol. 2024, 1–12. [Google Scholar] [CrossRef]
- Xue, W.; Li, T.; Peng, J.; Liu, L.; Zhang, J. Road underground defect detection in ground penetrating radar images based on an improved YOLOv5s model. J. Appl. Geophys. 2024, 229, 105491. [Google Scholar] [CrossRef]
- Zhu, J.; Zhao, D.; Luo, X. Evaluating the optimised YOLO-based defect detection method for subsurface diagnosis with ground penetrating radar. Road Mater. Pavement Des. 2024, 25, 186–203. [Google Scholar] [CrossRef]
- Zhang, B.; Cheng, H.; Zhong, Y.; Chi, J.; Shen, G.; Yang, Z.; Li, X.; Xu, S. Real-Time Detection of Voids in Asphalt Pavement Based on Swin-Transformer-Improved YOLOv5. IEEE Trans. Intell. Transp. Syst. 2023, 25, 2615–2626. [Google Scholar] [CrossRef]
- Kan, Q.; Liu, X.; Meng, A.; Yu, L. Identification of internal voids in pavement based on improved knowledge distillation technology. Case Stud. Constr. Mater. 2024, 21, e03555. [Google Scholar] [CrossRef]
- Khudoyarov, S.; Kim, N.; Lee, J.J. Three-dimensional convolutional neural network–based underground object classification using three-dimensional ground penetrating radar data. Struct. Health Monit. 2020, 19, 1884–1893. [Google Scholar] [CrossRef]
- Lu, K.; Huang, X.; Xia, R.; Zhang, P.; Shen, J. Cross attention is all you need: Relational remote sensing change detection with transformer. GISci. Remote Sens. 2024, 61, 2380126. [Google Scholar] [CrossRef]
- Sameera, P.; Deshpande, A.A. Disease detection and classification in pomegranate fruit using hybrid convolutional neural network with honey badger optimization algorithm. Int. J. Food Prop. 2024, 27, 815–837. [Google Scholar]
- Jiang, S.; Mei, Y.; Wang, P.; Liu, Q. Exposure difference network for low-light image enhancement. Pattern Recognit. 2024, 156, 110796. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, L.; Zhu, J.; Xue, Y. DEANet: Decomposition enhancement and adjustment network for low-light image enhancement. Tsinghua Sci. Technol. 2023, 28, 743–753. [Google Scholar] [CrossRef]
- Saleem, A.; Paheding, S.; Rawashdeh, N.; Awad, A.; Kaur, N. A non-reference evaluation of underwater image enhancement methods using a new underwater image dataset. IEEE Access 2023, 11, 10412–10428. [Google Scholar] [CrossRef]
- Prakash, A.; Bhandari, A.K. Cuckoo search constrained gamma masking for MRI image contrast enhancement. Multimed. Tools Appl. 2023, 82, 40129–40148. [Google Scholar] [CrossRef]
- Wu, G.X.; Liu, Y. Image Enhancement Algorithm for Ground Penetrating Radar Based on Nonlinear Technology. J. Phys. Conf. Ser. IOP Publ. 2024, 2887, 012045. [Google Scholar]
- Liu, Z.; Gu, X.Y.; Li, J.; Dong, Q.; Jiang, J. Deep learning-enhanced numerical simulation of ground penetrating radar and image detection of road cracks. Chin. J. Geophys. 2024, 67, 2455–2471. [Google Scholar]
- Lan, T.; Luo, X.; Yang, X.; Gong, J.; Li, X.; Qu, X. A Constrained Diffusion Model for Deep GPR Image Enhancement. IEEE Geosci. Remote Sens. Lett. 2024, 21, 3003505. [Google Scholar] [CrossRef]
- Sara, U.; Akter, M.; Uddin, M.S. Image quality assessment through FSIM, SSIM, MSE and PSNR—A comparative study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef]
- Qu, Q.; Liang, H.; Chen, X.; Chung, Y.Y.; Shen, Y. NeRF-NQA: No-Reference Quality Assessment for Scenes Generated by NeRF and Neural View Synthesis Methods. IEEE Trans. Vis. Comput. Graph. 2024, 30, 2129–2139. [Google Scholar] [CrossRef] [PubMed]
- Krithika Alias AnbuDevi, M.; Suganthi, K. Review of semantic segmentation of medical images using modified architectures of UNET. Diagnostics 2022, 12, 3064. [Google Scholar] [CrossRef] [PubMed]
- Tan, H.; Liu, X.; Yin, B.; Li, X. MHSA-Net: Multihead self-attention network for occluded person re-identification. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 8210–8224. [Google Scholar] [CrossRef] [PubMed]
- Wen, Z.; Lin, W.; Wang, T.; Xu, G. Distract your attention: Multi-head cross attention network for facial expression recognition. Biomimetics 2023, 8, 199. [Google Scholar] [CrossRef] [PubMed]
- Chheda, R.R.; Priyadarshi, K.; Muragodmath, S.M.; Dehalvi, F.; Kulkarni, U.; Chikkamath, S. EnhanceNet: A Deep Neural Network for Low-Light Image Enhancement with Image Restoration. In International Conference on Recent Trends in Machine Learning, IOT, Smart Cities & Applications; Springer Nature: Singapore, 2023; pp. 283–300. [Google Scholar]
- Li, C.; Yang, B. Underwater Image Enhancement Based on the Fusion of PUIENet and NAFNet. In Proceedings of the Advances in Computer Graphics: 40th Computer Graphics International Conference, CGI 2023, Shanghai, China, 28 August–1 September 2023; Springer Nature: Cham, Switzerland, 2023; pp. 335–347. [Google Scholar]
- Wang, C.; Liu, K.; Shi, J.; Yuan, H.; Wang, W. An Image Enhancement Method for Domestic High-Resolution Remote Sensing Satellite. In Proceedings of the 2023 6th International Conference on Big Data Technologies, Qingdao, China, 22–24 September 2023; pp. 340–345. [Google Scholar]
- Sun, Y.; Sun, J.; Sun, F.; Wang, F.; Li, H. Low-light image enhancement using transformer with color fusion and channel attention. J. Supercomput. 2024, 80, 18365–18391. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, K.; Shen, T.; Luo, W.; Stenger, B.; Lu, T. Ultra-high-definition low-light image en-hancement: A benchmark and transformer-based method. Proc. AAAI Conf. Artif. Intell. 2023, 37, 2654–2662. [Google Scholar]
- Hu, X.; Wang, J.; Xu, S. Lightweight and Fast Low-Light Image Enhancement Method Based on PoolFormer. IEICE Trans. Inf. Syst. 2024, 107, 157–160. [Google Scholar] [CrossRef]
- Warren, C.; Giannopoulos, A.; Giannakis, I. gprMax: Open source software to simulate electromagnetic wave propagation for Ground Penetrating Radar. Comput. Phys. Commun. 2016, 209, 163–170. [Google Scholar] [CrossRef]
- Niu, F.; Huang, Y.; He, P.; Su, W.; Jiao, C.; Ren, L. Intelligent recognition of ground penetrating radar images in urban road detection: A deep learning approach. J. Civ. Struct. Health Monit. 2024, 14, 1917–1933. [Google Scholar] [CrossRef]
- Todkar, S.S.; Le Bastard, C.; Baltazart, V.; Ihamouten, A.; Dérobort, X. Comparative study of classification algorithms to detect interlayer debondings within pavement structures from step-frequency radar data. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 6820–6823. [Google Scholar]
- Sezgin, M.; Yoldemir, B.; Özkan, E.; Nazlı, H. Identification of buried objects based on peak scatter modelling of GPR A-scan signals. In Proceedings of the Detection and Sensing of Mines, Explosive Objects, and Obscured Targets XXIV, Baltimore, MD, USA, 15–17 April 2019; Volume 11012, pp. 39–48. [Google Scholar]
- Du, P.; Liao, L.; Yang, X. Intelligent recognition of defects in railway subgrade. J. China Railw. Soc. 2010, 32, 142–146. [Google Scholar]
- Xu, J.; Zhang, J.; Sun, W. Recognition of the typical distress in concrete pavement based on GPR and 1D-CNN. Remote Sens. 2021, 13, 2375. [Google Scholar] [CrossRef]
- Xu, Z.; Dai, Z.; Sun, Z.; Li, W.; Dong, S. Pavement Image Enhancement in Pixel-Wise Based on Multi-Level Semantic Information. IEEE Trans. Intell. Transp. Syst. 2023, 24, 15077–15091. [Google Scholar] [CrossRef]
- Arezoumand, S.; Mahmoudzadeh, A.; Golroo, A.; Mojaradi, B. Automatic pavement rutting measurement by fusing a high speed-shot camera and a linear laser. Constr. Build. Mater. 2021, 283, 122668. [Google Scholar] [CrossRef]
- Ren, Z.; Tian, X.; Qin, G.; Zhou, D. Lightweight recognition method of infrared sensor image based on deep learning method. In Proceedings of the 2024 8th International Conference on Control Engineering and Artificial Intelligence, Shanghai, China, 26–28 January 2024; pp. 273–277. [Google Scholar]
- Ullah, F.; Ansari, S.U.; Hanif, M.; Ayari, M.A.; Chowdhury, M.E.H.; Khandakar, A.A.; Khan, M.S. Brain MR image enhancement for tumor segmentation using 3D U-Net. Sensors 2021, 21, 7528. [Google Scholar] [CrossRef]
- Zhao, M.; Yang, R.; Hu, M.; Liu, B. Deep learning-based technique for remote sensing image enhancement using multiscale feature fusion. Sensors 2024, 24, 673. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Hua, Z.; Li, J.; Fan, L. Dual UNet low-light image enhancement network based on attention mechanism. Multimed. Tools Appl. 2023, 82, 24707–24742. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, B.; Zhao, T. Convolutional multi-head self-attention on memory for aspect sentiment classification. IEEE/CAA J. Autom. Sin. 2020, 7, 1038–1044. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Z.; Zhou, L.; Yuan, X.; Shangguan, Z.; Hu, X.; Hu, B. A facial depression recognition method based on hybrid multi-head cross attention network. Front. Neurosci. 2023, 17, 1188434. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Type | PSNR (dB) | SSIM | LPIPS | NIQE |
|---|---|---|---|---|
| Not enhanced | 28.21 | 0.9137 | 0.0253 | 12.1723 |
| Unet | 30.12 | 0.9309 | 0.0211 | 10.8357 |
| NAFNet | 32.38 | 0.9488 | 0.0197 | 10.2675 |
| Uformer | 34.06 | 0.9364 | 0.0145 | 9.3738 |
| Enhanced by MHUnet | 34.65 | 0.9695 | 0.0165 | 9.6543 |
| Image Type | Precision | Recall | ||||
|---|---|---|---|---|---|---|
| AV (%) | SD (%) | t-Value | AV (%) | SD (%) | t-Value | |
| Original image | 86.55 | 0.553 | 10.43 | 80.31 | 0.512 | 16.86 |
| MHUnet Enhancement | 87.94 | 0.601 | 81.99 | 0.486 | ||
| Image Type | F1(%) | mAP(%) | ||||
| AV(%) | SD(%) | t-Value | AV(%) | SD(%) | t-Value | |
| Original image | 83.31 | 0.526 | 17.24 | 86.74 | 0.412 | 13.79 |
| MHUnet Enhancement | 84.86 | 0.415 | 87.62 | 0.387 | ||
| Model Type | Image Type | Precision (%) | Recall (%) | F1 (%) | mAP (%) |
|---|---|---|---|---|---|
| YOLOv7 | Original image | 85.61 | 78.43 | 81.68 | 85.85 |
| MHUnet Enhancement | 86.99 | 79.75 | 82.63 | 86.73 | |
| YOLOv8 | Original image | 86.55 | 80.31 | 83.31 | 86.74 |
| MHUnet Enhancement | 87.94 | 81.99 | 84.86 | 87.62 | |
| YOLOv9 | Original image | 86.28 | 80.54 | 83.38 | 85.99 |
| MHUnet Enhancement | 87.38 | 81.84 | 84.95 | 87.35 | |
| Faster-rcnn | Original image | 88.61 | 81.57 | 84.69 | 87.85 |
| MHUnet Enhancement | 90.38 | 83.31 | 86.15 | 88.42 |
| Type | Number of Voids | Accuracy (%) |
|---|---|---|
| Model detection | 10 | 90 |
| Accurate verification | 9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kan, Q.; Liu, X.; Meng, A.; Yu, L. Intelligent Recognition of Road Internal Void Using Ground-Penetrating Radar. Appl. Sci. 2024, 14, 11848. https://doi.org/10.3390/app142411848
Kan Q, Liu X, Meng A, Yu L. Intelligent Recognition of Road Internal Void Using Ground-Penetrating Radar. Applied Sciences. 2024; 14(24):11848. https://doi.org/10.3390/app142411848
Chicago/Turabian StyleKan, Qian, Xing Liu, Anxin Meng, and Li Yu. 2024. "Intelligent Recognition of Road Internal Void Using Ground-Penetrating Radar" Applied Sciences 14, no. 24: 11848. https://doi.org/10.3390/app142411848
APA StyleKan, Q., Liu, X., Meng, A., & Yu, L. (2024). Intelligent Recognition of Road Internal Void Using Ground-Penetrating Radar. Applied Sciences, 14(24), 11848. https://doi.org/10.3390/app142411848