
MSP U-Net: Crack Segmentation for Low-Resolution Images Based on Multi-Scale Parallel Attention U-Net


Abstract
1. Introduction
2. Related Work
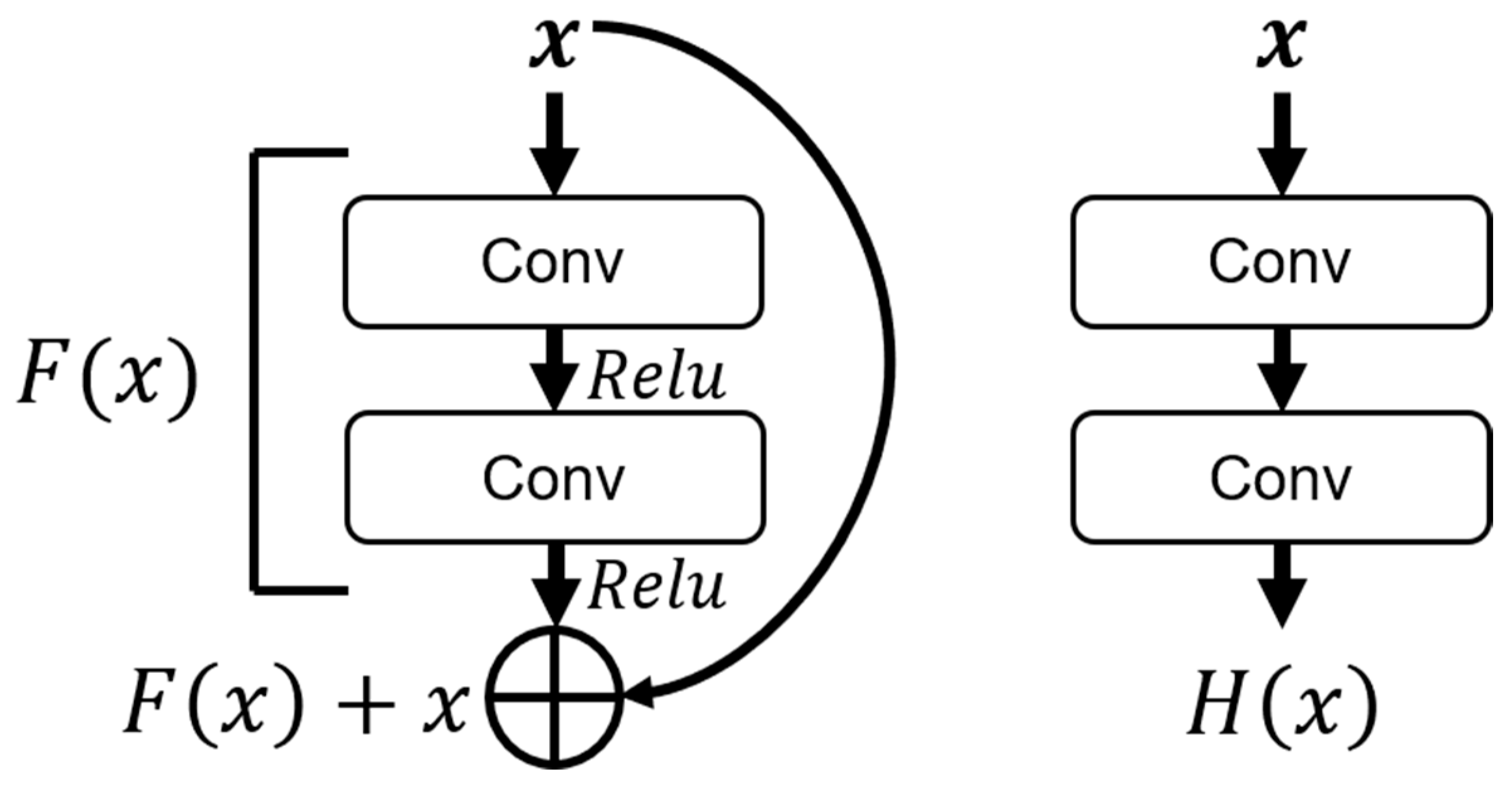
2.1. Residual Block
2.2. Attention Network
3. Proposed Method
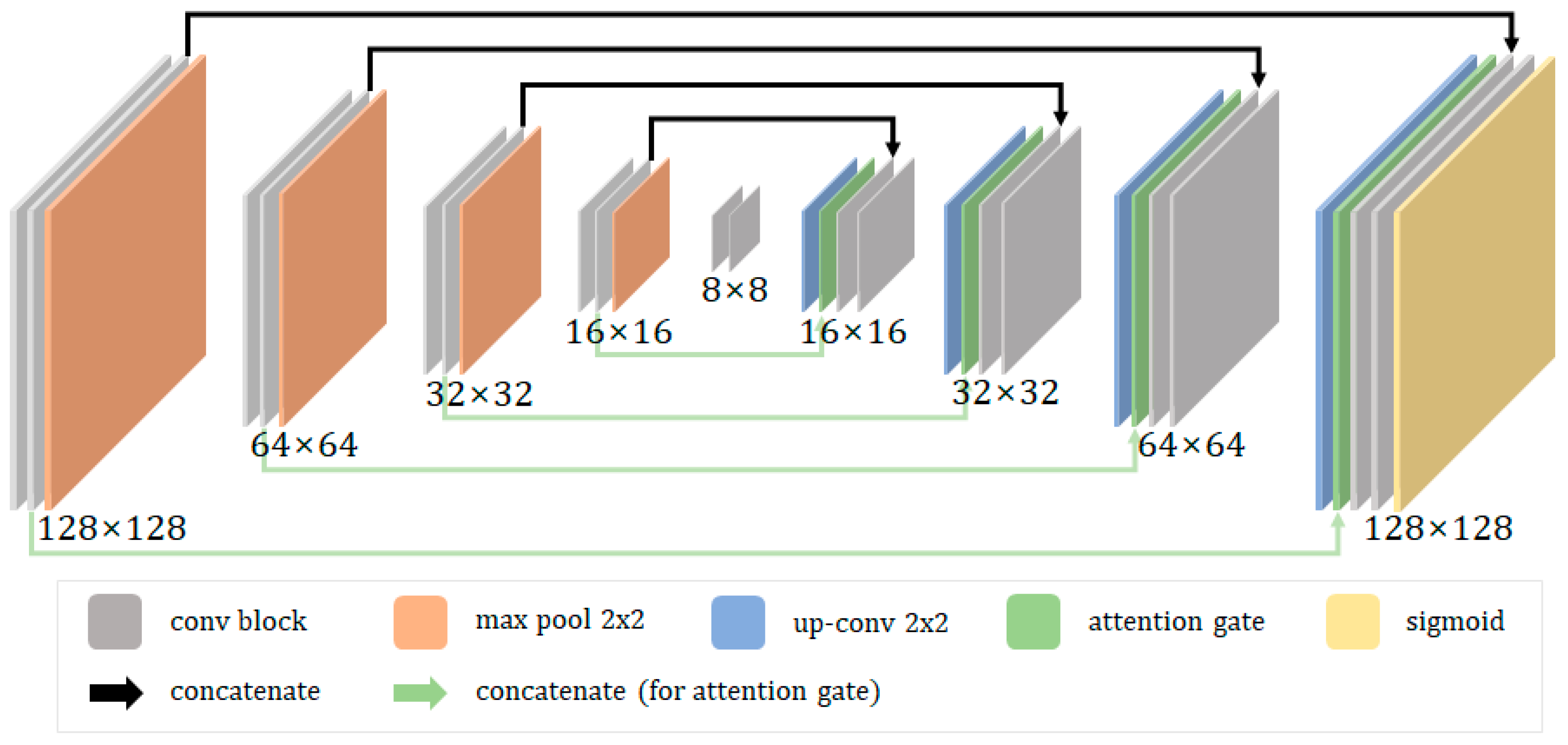
3.1. Proposed Architecture
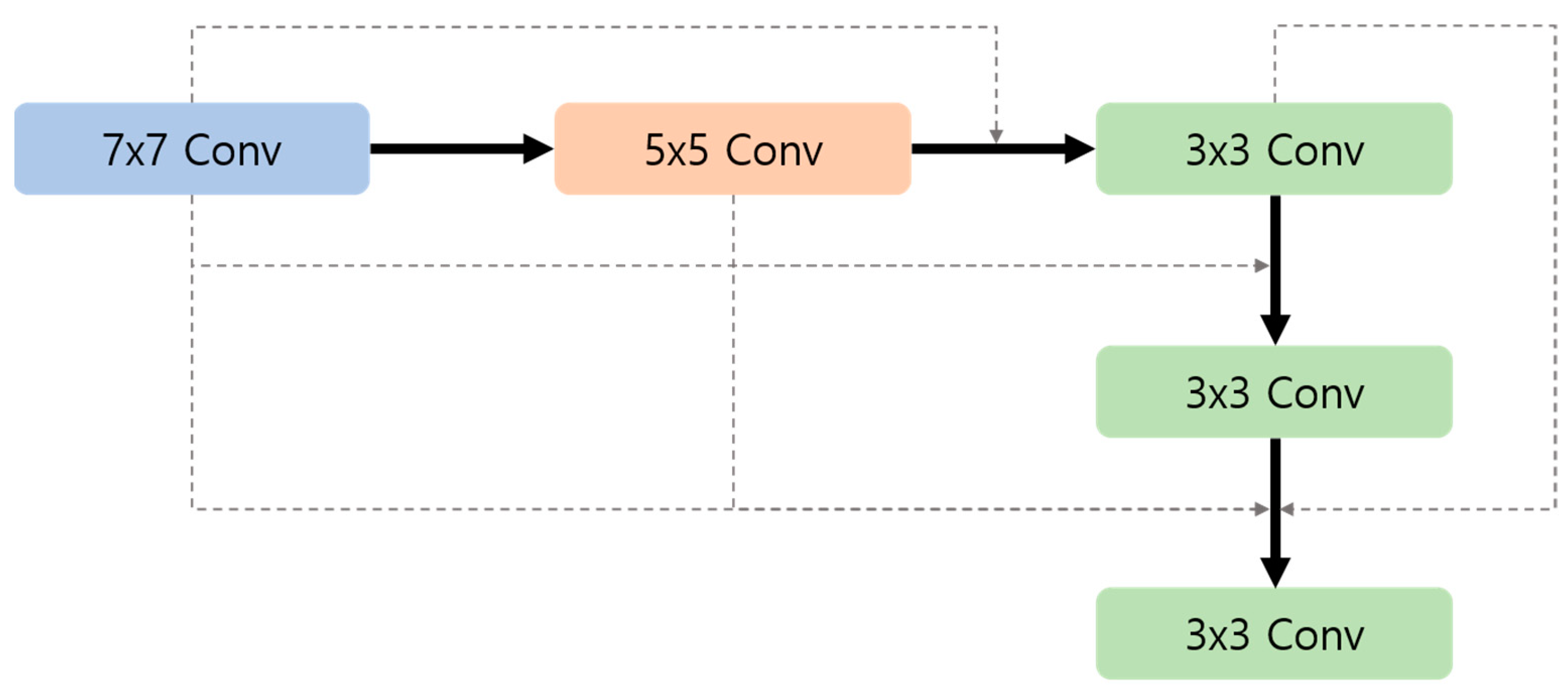
3.2. Attention Gate, Bigger Receptive Field Block
3.3. Loss Function
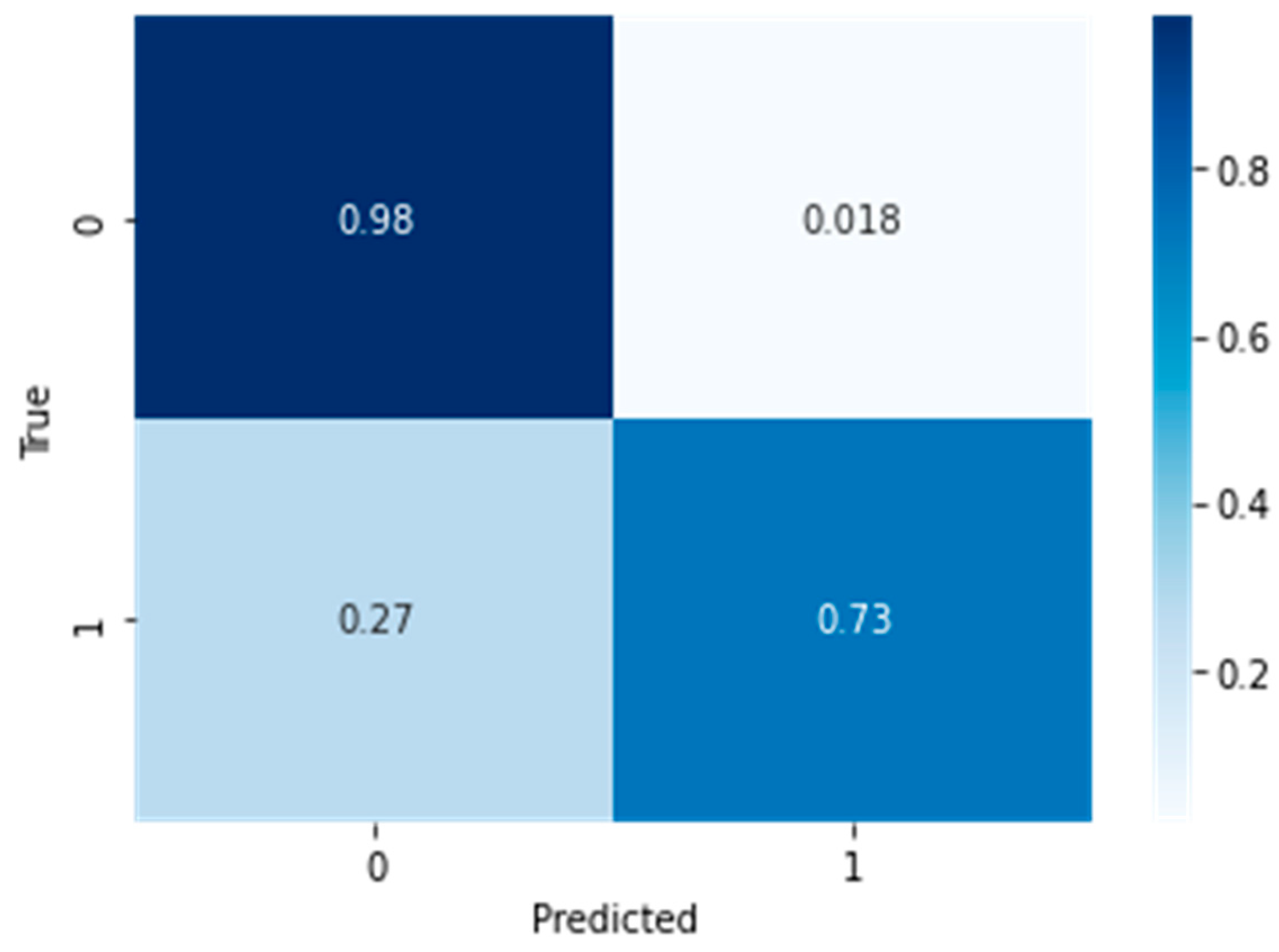
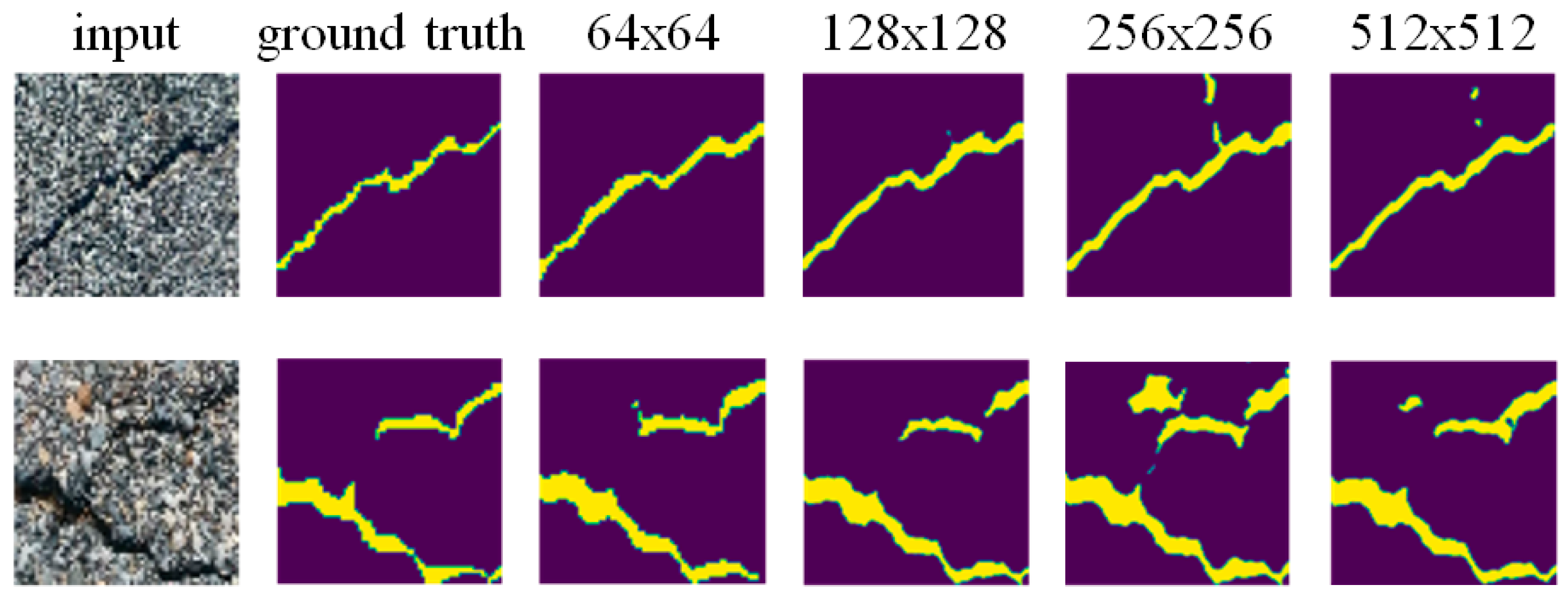
4. Analysis of Experimental Result
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tighe, S.; Li, N.Y.; Falls, L.C.; Haas, R. Incorporating road safety into pavement management. Transp. Res. Rec. 2000, 1699, 1–10. [Google Scholar] [CrossRef]
- Tang, F.; Ma, T.; Guan, Y.; Zhang, Z. Quantitative analysis and visual presentation of segregation in asphalt mixture based on image processing and BIM. Autom. Constr. 2021, 121, 103461. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Lau, S.L.H.; Chong, E.K.P.; Yang, X.; Wang, X. Automated pavement crack segmentation using u-net-based convolutional neural network. IEEE Access 2020, 8, 114892–114899. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Nguyen, N.T.H.; Tran, Q.L.; Do, H.N.; Choi, H.J. Pavement crack detection using convolutional neural network. In Proceedings of the 9th International Symposium on Information and Communication Technology, Da Nang, Vietnam, 6–7 December 2018; pp. 251–256. [Google Scholar]
- Yu, G.; Li, W.; Chen, X.; Zhang, Y. RUC-Net: A residual-unet-based convolutional neural network for pixel-level pavement crack segmentation. Sensors 2022, 23, 53. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Su, C. Convolutional neural network-based pavement crack segmentation using pyramid attention network. IEEE Access 2020, 8, 206548–206558. [Google Scholar] [CrossRef]
- Di Benedetto, A.; Fiani, M.; Gujski, L.M. U-Net-based CNN architecture for road crack segmentation. Infrastructures 2023, 8, 90. [Google Scholar] [CrossRef]
- Choi, W.; Cha, Y.-J. SDDNet: Real-time crack segmentation. IEEE Trans. Ind. Electron. 2019, 67, 8016–8025. [Google Scholar] [CrossRef]
- Kang, D.H.; Cha, Y.-J. Efficient attention-based deep encoder and decoder for automatic crack segmentation. Struct. Health Monit. 2022, 21, 2190–2205. [Google Scholar] [CrossRef] [PubMed]
- Chun, C.; Ryu, S.-K. Road surface damage detection using fully convolutional neural networks and semi-supervised learning. Sensors 2019, 19, 5501. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Lin, F.; Zhang, C.; Yang, Y.; Wang, X. Crack semantic segmentation using the U-Net with full attention strategy. arXiv 2021, arXiv:2104.14586. [Google Scholar]
- Wang, W.; Su, C. Automatic concrete crack segmentation model based on transformer. Autom. Constr. 2022, 139, 104275. [Google Scholar] [CrossRef]
- Sun, X.; Zhang, J.; Yan, X.; Zhang, H. DMA-Net: DeepLab with multi-scale attention for pavement crack segmentation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18392–18403. [Google Scholar] [CrossRef]
- Tao, H.; Li, Q.; Zhou, W.; Li, H. A convolutional-transformer network for crack segmentation with boundary awareness. In Proceedings of the IEEE International Conference on Image Processing, Kuala Lumpur, Malaysia, 8–11 October 2023; pp. 86–90. [Google Scholar]
- Dong, Z.; Mao, Q.; Wang, Y.; Chen, B.; Tang, L. Patch-based weakly supervised semantic segmentation network for crack detection. Constr. Build. Mater. 2020, 258, 120291. [Google Scholar] [CrossRef]
- Moon, J.-H.; Lee, S.-H.; Kim, J.-H.; Kim, J.-T. PCTC-Net: A Crack Segmentation Network with Parallel Dual Encoder Network Fusing Pre-Conv-Based Transformers and Convolutional Neural Networks. Sensors 2024, 24, 1467. [Google Scholar] [CrossRef] [PubMed]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Katsamenis, I.; Protopapadakis, E.; Doulamis, A.; Doulamis, N. A Few-Shot Attention Recurrent Residual U-Net for Crack Segmentation. In Proceedings of the International Symposium on Visual Computing, Lake Tahoe, NV, USA, 16–18 October 2023; Springer: Cham, Switzerland, 2023; pp. 199–209. [Google Scholar]
- Kim, J. Crack Segmentation for Low Resolution Image Based on Attention U-Net. Master’s Thesis, Chosun University, Gwangju, Republic of Korea, 2024. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CPU | Memory | GPU |
|---|---|---|
| AMD EPYC 2713 | 512 GB | RTX A6000 |
| OS | Python | Tensorflow |
| Ubuntu 20.04 | 3.8 | 2.5.0 |
| Input Image Size | Precision | Recall | F-1 Score | mIoU |
|---|---|---|---|---|
| 64 × 64 | 0.7092 | 0.6832 | 0.6959 | 0.7495 |
| 128 × 128 | 0.7561 | 0.7315 | 0.7436 | 0.7752 |
| 256 × 256 | 0.7352 | 0.6926 | 0.7133 | 0.7170 |
| 512 × 512 | 0.7310 | 0.6883 | 0.7090 | 0.5962 |
| Method | Precision | Recall | F-1 Score | mIoU |
|---|---|---|---|---|
| U-Net By Lau [7] | 0.7426 | 0.7285 | 0.7327 | 0.5782 |
| U-Net By Nguyen [9] | 0.6954 | 0.6744 | 0.6895 | 0.5261 |
| U-Net By Yu [10] | 0.6988 | 0.7619 | 0.7290 | 0.5736 |
| U-Net By A Di [12] | 0.8534 | 0.6813 | 0.7327 | 0.6248 |
| FCN-8s [25] | 0.7031 | 0.6172 | 0.6574 | 0.6898 |
| U-Net [26] | 0.7207 | 0.6401 | 0.6779 | 0.6852 |
| Attention U-Net By [27] | - | - | 0.7706 | 0.6311 |
| Ours | 0.7561 | 0.7315 | 0.7436 | 0.7752 |
| Method | Precision | Recall | F-1 Score | mIoU |
|---|---|---|---|---|
| Without BRFB (Attention U-Net) | 0.7195 | 0.7033 | 0.7113 | 0.7183 |
| With BRFB | 0.7561 | 0.7315 | 0.7436 | 0.7752 |
| Batch Size | Precision | Recall | F-1 Score | mIoU |
|---|---|---|---|---|
| 4 | 0.6884 | 0.6746 | 0.6814 | 0.7398 |
| 8 | 0.7218 | 0.6448 | 0.6811 | 0.7404 |
| 16 | 0.7561 | 0.7315 | 0.7436 | 0.7752 |
| 32 | 0.7128 | 0.7087 | 0.7107 | 0.7585 |
| 64 | 0.7199 | 0.6472 | 0.6816 | 0.7406 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.-H.; Noh, J.-H.; Jang, J.-Y.; Yang, H.-D. MSP U-Net: Crack Segmentation for Low-Resolution Images Based on Multi-Scale Parallel Attention U-Net. Appl. Sci. 2024, 14, 11541. https://doi.org/10.3390/app142411541
Kim J-H, Noh J-H, Jang J-Y, Yang H-D. MSP U-Net: Crack Segmentation for Low-Resolution Images Based on Multi-Scale Parallel Attention U-Net. Applied Sciences. 2024; 14(24):11541. https://doi.org/10.3390/app142411541
Chicago/Turabian StyleKim, Joon-Hyeok, Ju-Hyeon Noh, Jun-Young Jang, and Hee-Deok Yang. 2024. "MSP U-Net: Crack Segmentation for Low-Resolution Images Based on Multi-Scale Parallel Attention U-Net" Applied Sciences 14, no. 24: 11541. https://doi.org/10.3390/app142411541
APA StyleKim, J.-H., Noh, J.-H., Jang, J.-Y., & Yang, H.-D. (2024). MSP U-Net: Crack Segmentation for Low-Resolution Images Based on Multi-Scale Parallel Attention U-Net. Applied Sciences, 14(24), 11541. https://doi.org/10.3390/app142411541