

InMemQK: A Product Quantization Based MatMul Module for Compute-in-Memory Attention Macro

 , ,
, ,
Abstract
1. Introduction
2. Transformer and CIM Accelerator
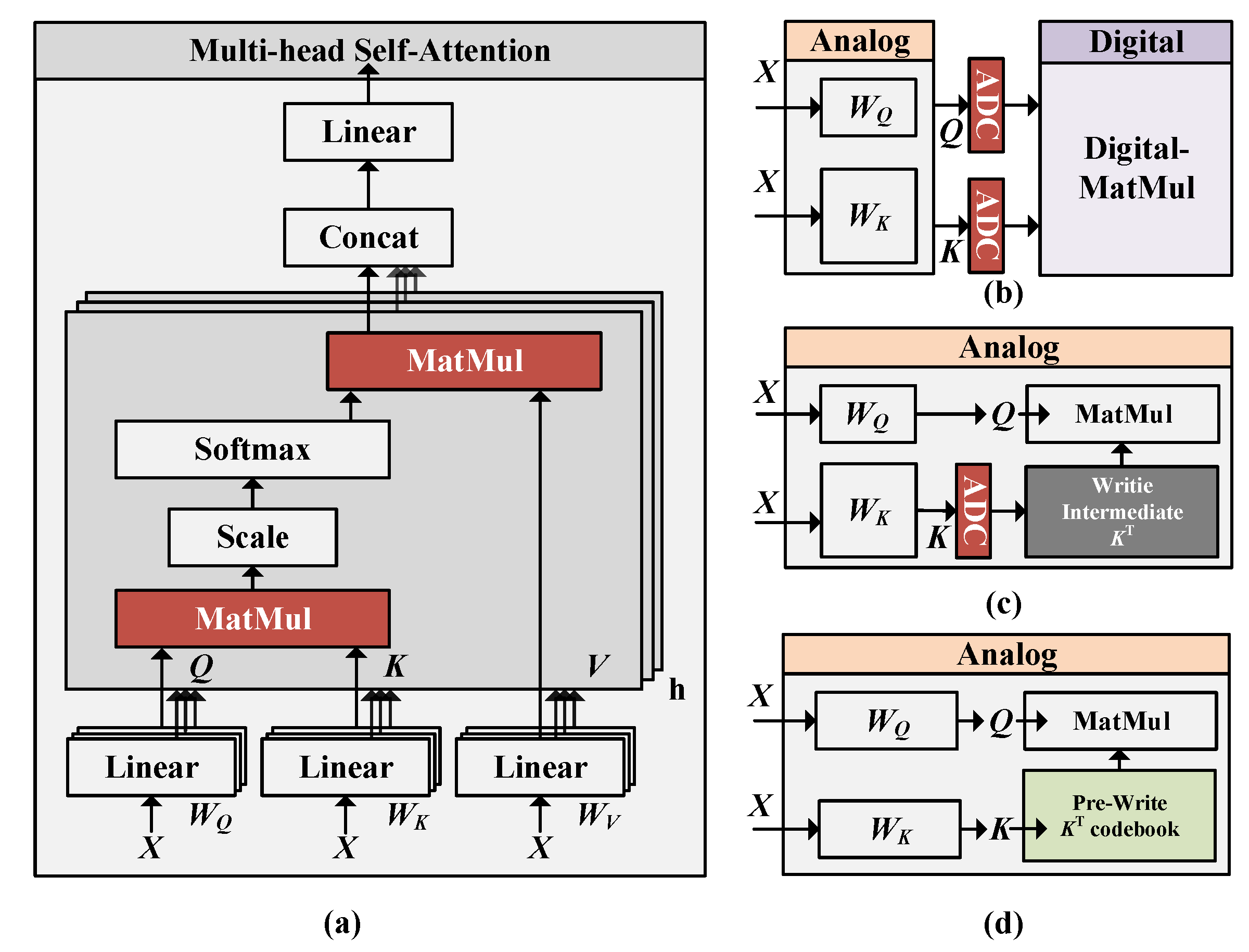
2.1. Transformer Model
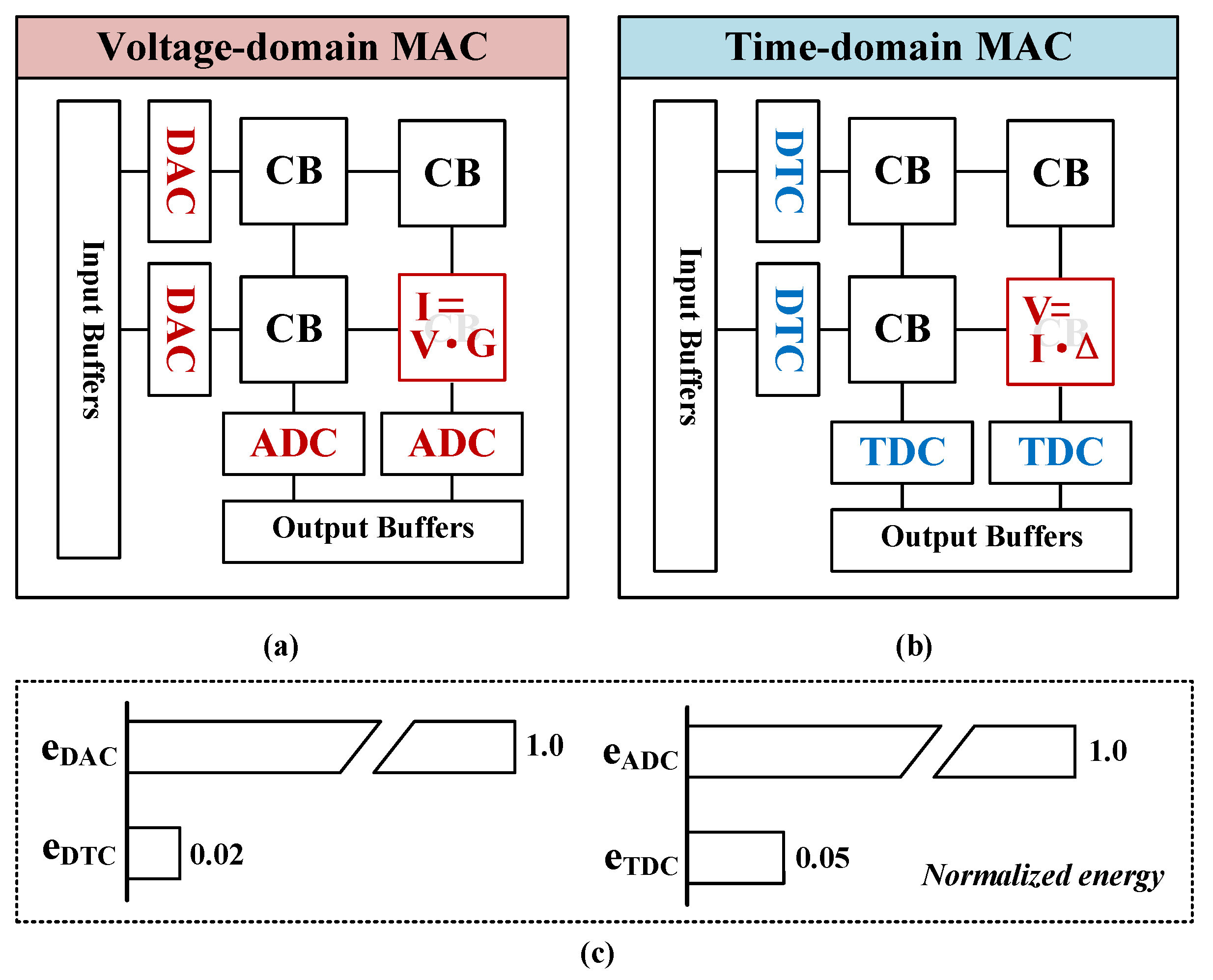
2.2. Voltage-Domain MAC and Time-Domain MAC
3. Optimized Product Quantization and InMemQK Based on Time-Domain MAC
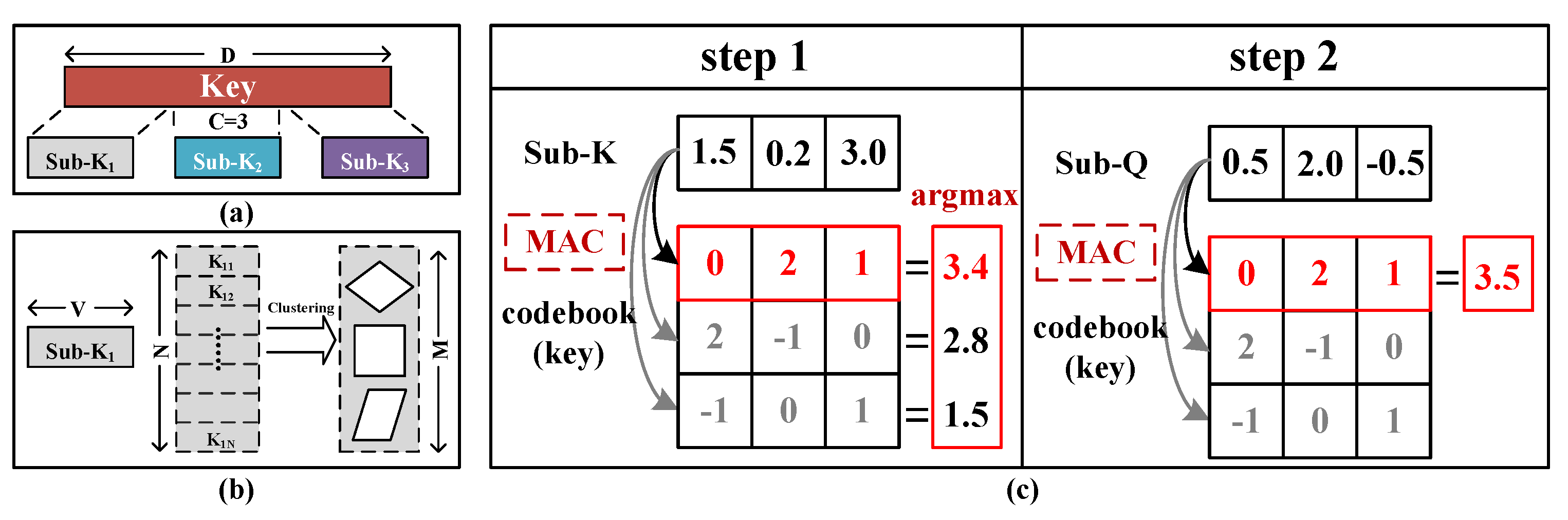
3.1. Background: Product Quantization
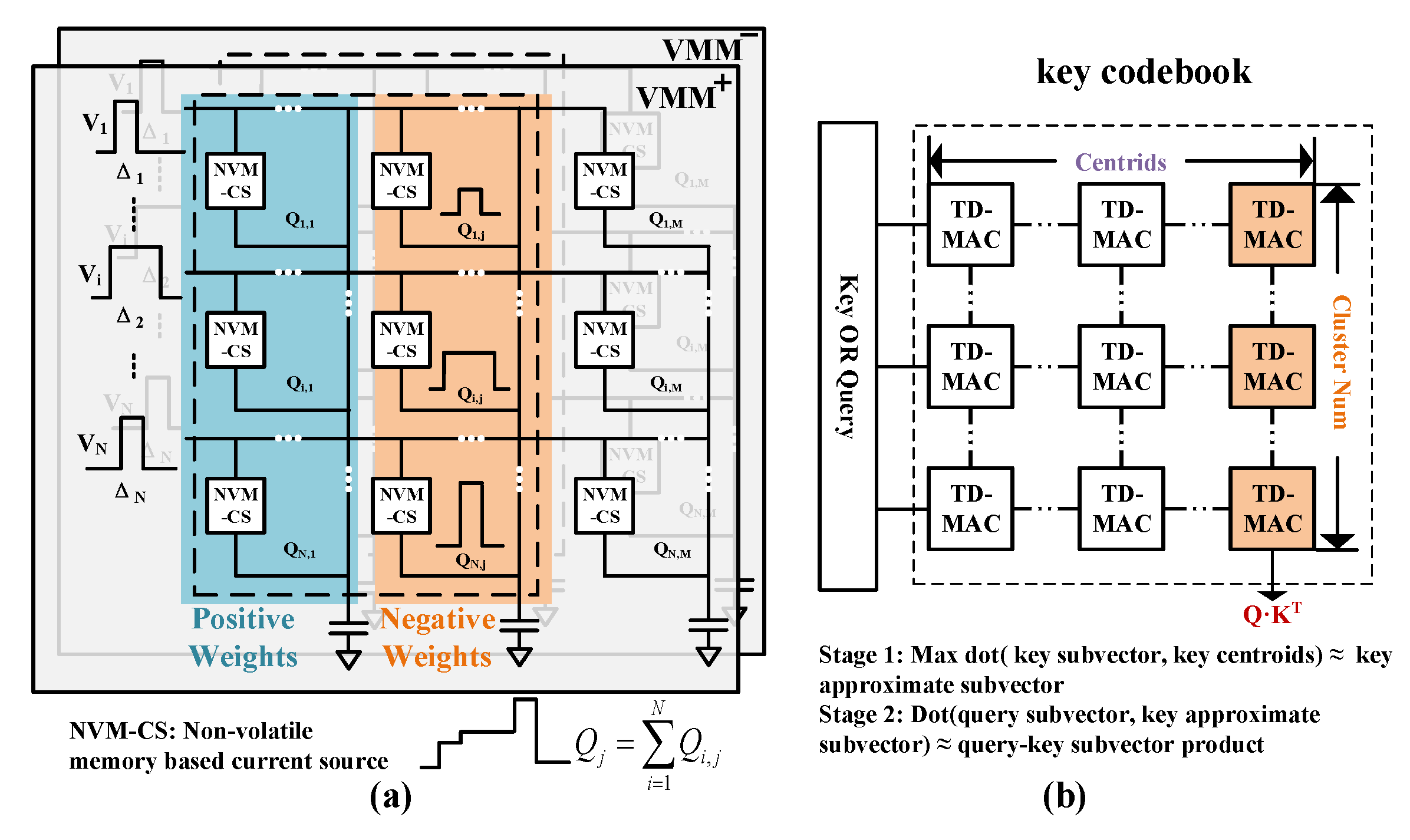
3.2. ADC-Free InMemQK Module Design
3.3. Hierarchical Feature Reconstruction and Reverse Layer-Wise Fine-Tuning
| Algorithm 1 Optimized product quantization. |
|
4. Simulation Results
4.1. Experiment Methodologies and Settings Dataset and Models
4.2. Algorithm Simulation Results
4.3. InMemQK Performance of MatMul Optimization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, T.; He, S.; Liu, J.; Sun, S.; Liu, K.; Han, Q.L.; Tang, Y. A brief overview of ChatGPT: The history, status quo and potential future development. IEEE/CAA J. Autom. Sin. 2023, 10, 1122–1136. [Google Scholar] [CrossRef]
- Lin, A.; Chen, B.; Xu, J.; Zhang, Z.; Lu, G.; Zhang, D. Ds-transunet: Dual swin transformer u-net for medical image segmentation. IEEE Trans. Instrum. Meas. 2022, 71, 1–15. [Google Scholar] [CrossRef]
- Dalmaz, O.; Yurt, M.; Çukur, T. ResViT: Residual vision transformers for multimodal medical image synthesis. IEEE Trans. Med. Imaging 2022, 41, 2598–2614. [Google Scholar] [CrossRef] [PubMed]
- Teeneti, C.R.; Truscott, T.T.; Beal, D.N.; Pantic, Z. Review of wireless charging systems for autonomous underwater vehicles. IEEE J. Ocean. Eng. 2019, 46, 68–87. [Google Scholar] [CrossRef]
- Dao, T.; Fu, D.; Ermon, S.; Rudra, A.; Ré, C. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. Adv. Neural Inf. Process. Syst. 2022, 35, 16344–16359. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Hamdioui, S.; Pouyan, P.; Li, H.; Wang, Y.; Raychowdhur, A.; Yoon, I. Test and reliability of emerging non-volatile memories. In Proceedings of the 2017 IEEE 26th Asian Test Symposium (ATS), Taipei, Taiwan, 27–30 November 2017. [Google Scholar]
- Xia, L.; Gu, P.; Boxun, L.; Tang, T.; Yin, X.; Huangfu, W.; Yu, S.; Cao, Y.; Wang, Y.; Yang, H. Technological exploration of RRAM crossbar array for matrix-vector multiplication. J. Comput. Sci. Technol. 2016, 31, 3–19. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Kombrink, S.; Mikolov, T.; Karafiát, M.; Burget, L. Recurrent neural network based language model. In Proceedings of the 12th Annual Conference of the International Speech Communication Association INTERSPEECH 2011, Florence, Italy, 27–31 August 2011; Volume 2. [Google Scholar]
- Li, Y.; Ma, H.; Wang, L.; Mao, S.; Wang, G. Optimized content caching and user association for edge computing in densely deployed heterogeneous networks. IEEE Trans. Mob. Comput. 2020, 21, 2130–2142. [Google Scholar] [CrossRef]
- Jhang, C.J.; Xue, C.X.; Hung, J.M.; Chang, F.C.; Chang, M.F. Challenges and trends of SRAM-based computing-in-memory for AI edge devices. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 1773–1786. [Google Scholar] [CrossRef]
- Peng, X.; Huang, S.; Jiang, H.; Lu, A.; Yu, S. DNN+ NeuroSim V2. 0: An end-to-end benchmarking framework for compute-in-memory accelerators for on-chip training. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 40, 2306–2319. [Google Scholar] [CrossRef]
- Vaswani, A. Attention is all you need. In Proceedings of the 31st Conference on Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Li, W.; Xu, P.; Zhao, Y.; Li, H.; Xie, Y.; Lin, Y. Timely: Pushing data movements and interfaces in pim accelerators towards local and in time domain. In Proceedings of the 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 30 May–3 June 2020. [Google Scholar]
- Yang, X.; Yan, B.; Li, H.; Chen, Y. ReTransformer: ReRAM-based processing-in-memory architecture for transformer acceleration. In Proceedings of the 39th International Conference on Computer-Aided Design, Virtual, 2–5 November 2020. [Google Scholar]
- Sheu, S.-S.; Chang, M.-F.; Lin, K.-F.; Wu, C.-W.; Chen, Y.-S.; Chiu, P.-F.; Kuo, C.-C.; Yang, Y.-S.; Chiang, P.-C.; Lin, W.-P.; et al. A 4 Mb embedded SLC resistive-RAM macro with 7.2 ns read-write random-access time and 160 ns MLC-access capability. In Proceedings of the 2011 IEEE International Solid-State Circuits Conference, San Francisco, CA, USA, 20–24 February 2011. [Google Scholar]
- Chi, P.; Li, S.; Xu, C.; Zhang, T.; Zhao, J.; Liu, Y.; Wang, Y.; Xie, Y. Prime: A novel processing-in-memory architecture for neural network computation in reram-based main memory. ACM SIGARCH Comput. Archit. News 2016, 44, 27–39. [Google Scholar] [CrossRef]
- Shafiee, A.; Nag, A.; Muralimanohar, N.; Balasubramonian, R.; Strachan, J.P.; Hu, M.; Williams, R.S.; Srikumar, V. ISAAC: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars. ACM SIGARCH Comput. Archit. News 2016, 44, 14–26. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Y.; Luo, Y.; Liu, X.; Wang, Y.; Gao, F.; Xu, J.; Hu, E.; Samanta, S.; Wang, X.; et al. Realization of artificial neuron using MXene bi-directional threshold switching memristors. IEEE Electron Device Lett. 2019, 40, 1686–1689. [Google Scholar] [CrossRef]
- Yue, Z.; Wang, J.; Lian, C.; Bai, Y.; Wang, G.; Zhang, Z.; Zheng, Z.; Chen, L.; Zhang, K.; Sirakoulis, G.; et al. Time-domain computing in memory using spintronics for energy-efficient convolutional neural network. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 1193–1205. [Google Scholar]
- Freye, F.; Lou, J.; Bengel, C.; Menzel, S.; Wiefels, S.; Gemmeke, T. Memristive devices for time domain compute-in-memory. IEEE J. Explor.-Solid-State Comput. Devices Circuits 2022, 8, 119–127. [Google Scholar] [CrossRef]
- Herve, J.; Douze, M.; Schmid, C. Product quantization for nearest neighbor search. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 117–128. [Google Scholar]
- Mohammad, B.; Mahmoodi, M.R.; Strukov, D.B. Energy-efficient time-domain vector-by-matrix multiplier for neurocomputing and beyond. IEEE Trans. Circuits Syst. II Express Briefs 2019, 66, 512–1516. [Google Scholar]
- Tang, X.; Wang, Y.; Cao, T.; Zhang, L.L.; Chen, Q.; Cai, D.; Liu, Y.; Yang, M. Lut-nn: Empower efficient neural network inference with centroid learning and table lookup. In Proceedings of the 29th Annual International Conference on Mobile Computing and Networking, Madrid, Spain, 2–6 October 2023. [Google Scholar]
- Wilder, B.; Ewing, E.; Dilkina, B.; Tambe, M. End to end learning and optimization on graphs. Adv. Neural Inf. Process. Syst. 2019, 32, 2620. [Google Scholar]
- Zhou, H.; Qixuan, Z.; Luo, T.; Zhang, Y.; Xu, Z.Q. Towards understanding the condensation of neural networks at initial training. Adv. Neural Inf. Process. Syst. 2022, 35, 2184–2196. [Google Scholar]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A survey of the usages of deep learning for natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 604–624. [Google Scholar] [CrossRef]
- Devlin, J. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Lan, Z. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Liu, Y. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Wang, A. GLUE: A multi-task benchmark and analysis platform for natural language understanding. arxiv 2018, arXiv:1804.07461. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Virtual, 16–20 November 2020. [Google Scholar]
- Yi, W.; Mo, K.; Wang, W.; Zhou, Y.; Zeng, Y.; Yuan, Z.; Cheng, B.; Pan, B. RDCIM: RISC-V Supported Full-Digital Computing-in-Memory Processor with High Energy Efficiency and Low Area Overhead. IEEE Trans. Circuits Syst. I Regul. Pap. 2024, 71, 1719–1732. [Google Scholar] [CrossRef]
- Hsu, H.-H.; Wen, T.-H.; Khwa, W.-S.; Huang, W.-H.; Ke, Z.-E.; Chin, Y.-H.; Wen, H.-J.; Chang, Y.-C.; Hsu, W.-T.; Lele, A.S.; et al. A 22 nm Floating-Point ReRAM Compute-in-Memory Macro Using Residue-Shared ADC for AI Edge Device. IEEE J.-Solid-State Circuits 2024. [Google Scholar] [CrossRef]
- Hung, J.-M.; Wen, T.-H.; Huang, Y.-H.; Huang, S.-P.; Chang, F.-C.; Su, C.-I.; Khwa, W.-S.; Lo, C.-C.; Liu, R.-S.; Hsieh, C.-C.; et al. 8-b precision 8-Mb ReRAM compute-in-memory macro using direct-current-free time-domain readout scheme for AI edge devices. IEEE J. Solid-State Circuits 2022, 58, 303–315. [Google Scholar] [CrossRef]
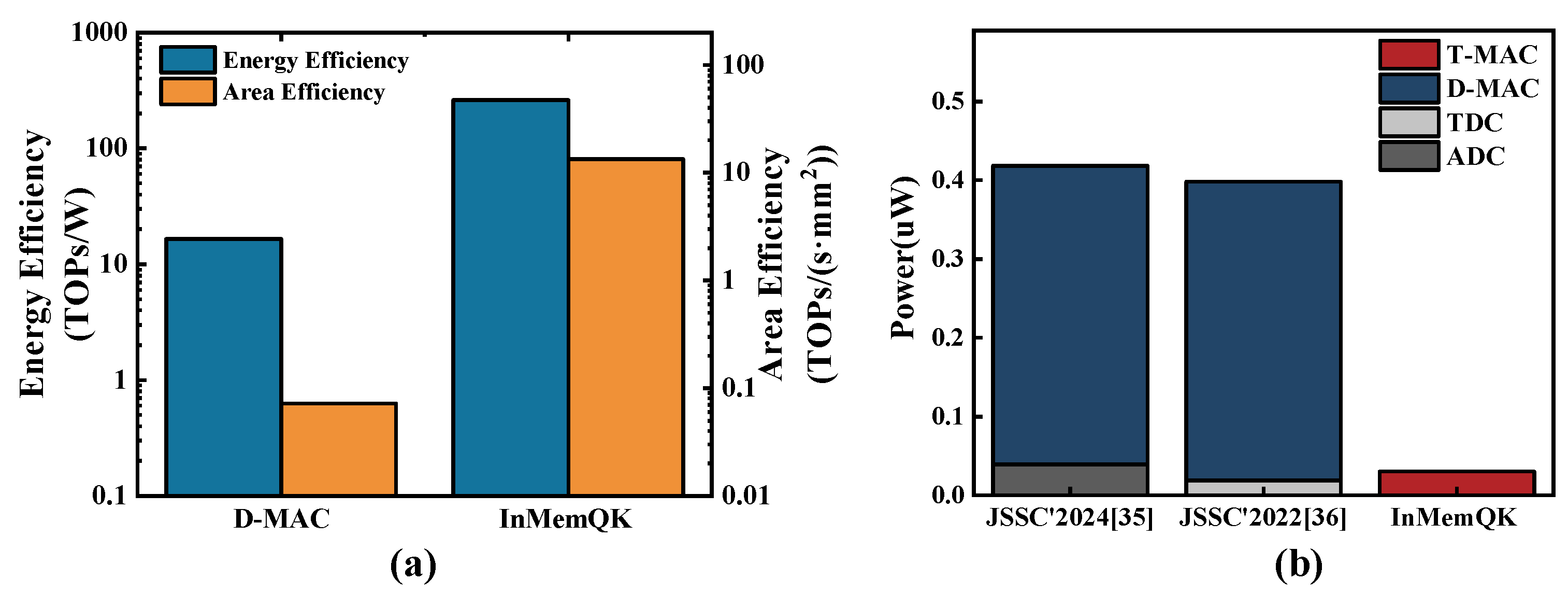

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | STSB | COLA | SST2 | MRPC | RTE | MNLI | QNLI | QQP | |
|---|---|---|---|---|---|---|---|---|---|
| BERT | Baseline | 0.88 | 0.57 | 0.933 | 0.84 | 0.693 | 0.835 | 0.897 | 0.912 |
| L2 | 0.665 | 0.07 | 0.79 | 0.31 | 0.472 | 0.497 | 0.542 | 0.688 | |
| HFR | 0.819 | 0.389 | 0.836 | 0.715 | 0.631 | 0.615 | 0.754 | 0.759 | |
| HFR * | 0.817 | 0.417 | 0.84 | 0.693 | 0.519 | 0.615 | 0.744 | 0.755 | |
| RL-FT | 0.868 | 0.433 | 0.87 | 0.819 | 0.642 | 0.757 | 0.832 | 0.884 | |
| ALBERT | Baseline | 0.904 | 0.576 | 0.865 | 0.845 | 0.667 | 0.842 | 0.89 | 0.901 |
| L2 | 0.131 | 0.012 | 0.844 | 0.665 | 0.472 | 0.326 | 0.51 | 0.719 | |
| HFR | 0.814 | 0.384 | 0.877 | 0.754 | 0.592 | 0.501 | 0.64 | 0.828 | |
| HFR * | 0.807 | 0.356 | 0.858 | 0.752 | 0.61 | 0.502 | 0.66 | 0.825 | |
| RL-FT | 0.848 | 0.446 | 0.0.832 | 0.812 | 0.654 | 0.732 | 0.855 | 0.871 | |
| RoBERTa | Baseline | 0.903 | 0.603 | 0.928 | 0.887 | 0.667 | 0.866 | 0.9 | 0.909 |
| L2 | 0.211 | 0.166 | 0.676 | 0.696 | 0.498 | 0.452 | 0.564 | 0.631 | |
| HFR | 0.566 | 0.328 | 0.877 | 0.757 | 0.595 | 0.626 | 0.721 | 0.766 | |
| HFR * | 0.567 | 0.311 | 0.876 | 0.718 | 0.566 | 0.624 | 0.744 | 0.755 | |
| RL-FT | 0.855 | 0.459 | 0.893 | 0.801 | 0.631 | 0.795 | 0.848 | 0.858 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, P.; Chen, Y.; Yu, J.; Yue, H.; Jiang, Z.; Xiao, Y.; Xiao, W.; Lu, H.; Chen, G. InMemQK: A Product Quantization Based MatMul Module for Compute-in-Memory Attention Macro. Appl. Sci. 2024, 14, 11198. https://doi.org/10.3390/app142311198
Feng P, Chen Y, Yu J, Yue H, Jiang Z, Xiao Y, Xiao W, Lu H, Chen G. InMemQK: A Product Quantization Based MatMul Module for Compute-in-Memory Attention Macro. Applied Sciences. 2024; 14(23):11198. https://doi.org/10.3390/app142311198
Chicago/Turabian StyleFeng, Pengcheng, Yihao Chen, Jinke Yu, Hao Yue, Zhelong Jiang, Yi Xiao, Wan’ang Xiao, Huaxiang Lu, and Gang Chen. 2024. "InMemQK: A Product Quantization Based MatMul Module for Compute-in-Memory Attention Macro" Applied Sciences 14, no. 23: 11198. https://doi.org/10.3390/app142311198
APA StyleFeng, P., Chen, Y., Yu, J., Yue, H., Jiang, Z., Xiao, Y., Xiao, W., Lu, H., & Chen, G. (2024). InMemQK: A Product Quantization Based MatMul Module for Compute-in-Memory Attention Macro. Applied Sciences, 14(23), 11198. https://doi.org/10.3390/app142311198