
Advancing Arabic Word Embeddings: A Multi-Corpora Approach with Optimized Hyperparameters and Custom Evaluation

Abstract
1. Introduction
- The creation of comprehensive Arabic embedding models: We developed 108 Arabic word embedding models using advanced techniques such as Word2Vec and FastText, optimizing the hyperparameters to produce high-quality embeddings specifically suited for the unique linguistic structures of Arabic.
- Rich language representation: By training the models on three diverse Arabic corpora—news articles, books, and Wikipedia—we capture the linguistic variety and morphological richness of Arabic, supporting robust, context-aware embeddings.
- The development of Arabic-specific evaluation metrics: We adapted an Arabic benchmark from Google’s Analogy Test to accurately assess semantic relationships within Arabic, ensuring the embeddings reflect true language understanding.
2. Research Background
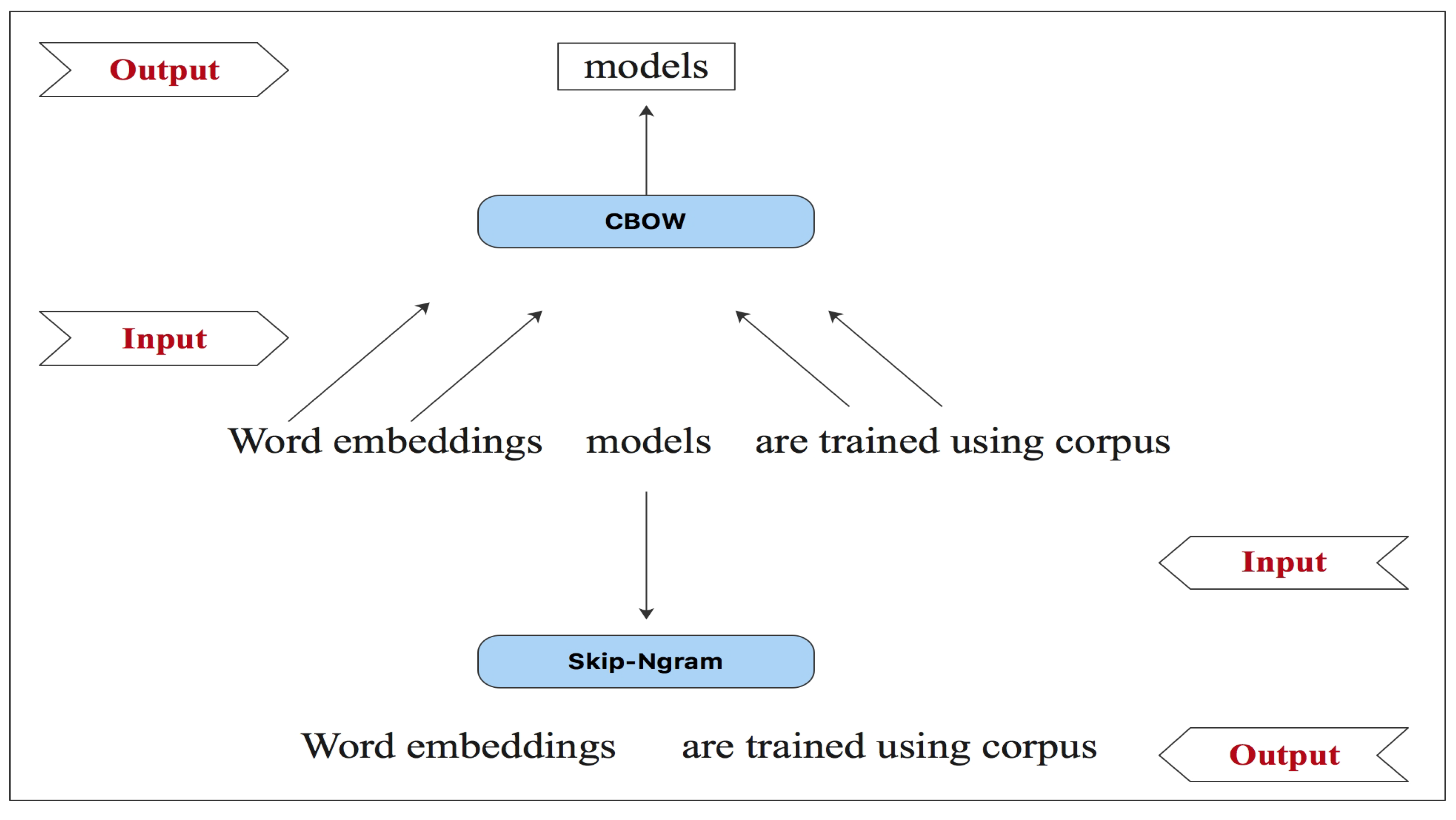
- Word2vec. This was introduced by Mikolov et al. [3]. The main idea behind Word2Vec is to pretrain a single projection matrix that incorporates the embedding dimensions and the vocabulary. The embedding is structured by maximizing the likelihood of word prediction given their context. Word2Vec can be constructed using either the skip-gram or continuous bag of words (CBOW) methods [12]. In skip-gram, the model predicts the surrounding context words based on the input word. On the other hand, CBOW uses the words surrounding the target word to predict it (see Figure 1). Both methods employ the Softmax function to assign probabilities to each word in the vocabulary as the output layer. Hierarchical Softmax is employed to reduce the search time for output nodes. This is achieved by representing the vocabulary as a Huffman binary tree [13], enabling faster search by focusing on only half of the vocabulary.Figure 1. Illustration of the skip-gram and continuous bag-of-word (CBOW) models.
![Applsci 14 11104 g001]()
- GloVe. This was introduced by Pennington et al. [14], who proposed the idea that the ratio of word–word co-occurrence probabilities can indicate the meaning of words. Word2Vec utilizes this concept and is trained using a global corpus of word occurrences to generate linear directions of meanings [9]. The primary method employed by the GloVe approach is to utilize a textual corpus to capture word occurrences. This is achieved by constructing a co-occurrence matrix based on the co-occurrence frequency of each word with other words. The approach takes into account a fixed window size context to determine the co-occurrence scores. However, the resulting matrix is symmetric, which provides less useful information about the relatedness of the words. To overcome this limitation, GloVe relies on calculating co-occurrence ratios between two words in a context. Additionally, the matrix is factorized to generate vectors, which are then used for word embedding.
- FastText. FastText is a word embedding model developed by the Facebook research team. Unlike previous models, FastText considers words as chunks of characters, allowing them to be formed by character n-grams. An n-gram is represented by a vector, and the word vector is the sum of the n-gram vectors. This unique feature enables FastText to effectively represent rare words by creating vectors for words that may not exist in the training corpus [9]. Additionally, words composed of common roots can be used to learn new vocabulary that infrequently appears in the corpus. This capability is particularly advantageous when dealing with out-of-vocabulary words, as FastText can still provide meaningful representations based on their character-level composition. Furthermore, FastText can overcome the limitation in representing slang and misspelled words [15].
3. Related Work
4. Building Arabic Word Embeddings
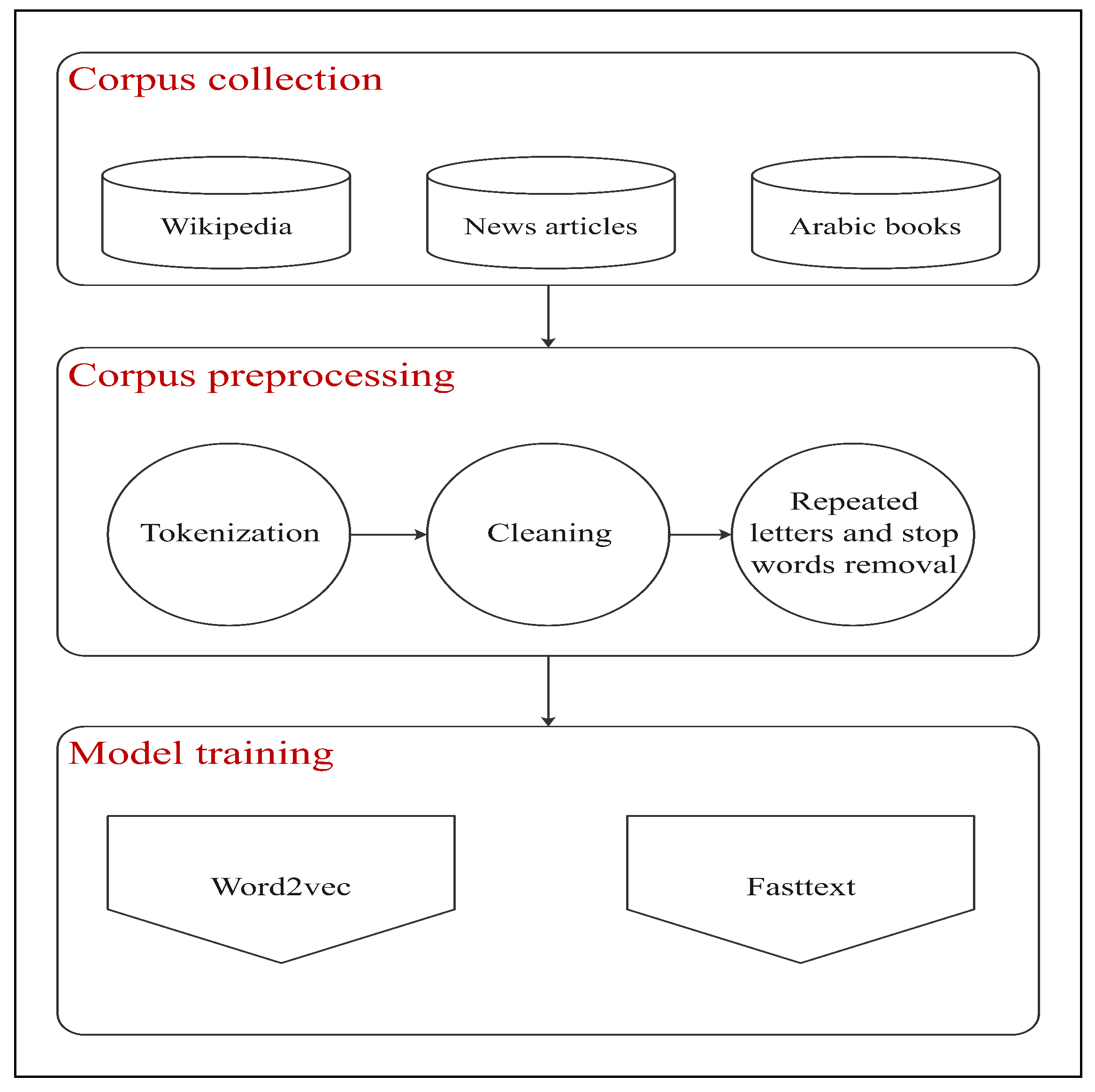
4.1. Corpus Collection
- Book corpus: Classical Arabic is one of the Arabic varieties that is commonly used in religious contexts and is distinguished by its unique and formal structure compared to modern and dialectical Arabic. Regrettably, classical Arabic, particularly ancient Arabic, has not received significant attention in the field of word embeddings. To address this gap, we constructed our first corpus by utilizing 32 well-known Arabic books. The digital versions of these books were obtained from the Almaktabah Alshamelah database (https://shamela.ws/ (accessed on 28 September 2024)). This database offers a wealth of Arabic words along with detailed descriptions. Table 2 shows the topics’ distribution in the Books corpus. Notably, one of these books, Lesan Al-arab, is considered to be the comprehensive dictionary of all Arabic dictionaries [17]. Given that these books provide various forms and descriptions for numerous Arabic words, they contribute to the morphological richness of the embedding model. Through the use of this corpus, we aim to analyze the efficacy of employing Arabic books for word embedding models and to assess their ability to capture rare and ancient Arabic words. This corpus contains approximately 11 million words.
- Watan corpus: To build a topically rich medium corpus, we used the Arabic corpus Watan-2004 [18]. This corpus contains 20,000 Arabic news articles covering a wide range of topics such as culture, religion, economy, local news, international news, and sports, all provided in HTML format; additional information about the corpus can be found in [18]. Table 3 shows the topics’ distribution in the Watan corpus. This corpus contains approximately 6 million words.
- Wiki corpus: Wikipedia (https://www.wikipedia.org/ (accessed on 28 September 2024)) provides a plethora of articles on various topics in multiple languages. Therefore, we have selected Wikipedia as the source of the large corpus. We collected recent articles from 2023 using the Wikiextractor tool from [19] to gather articles from Wikimedia, a website that archives articles in different languages (https://dumps.wikimedia.org/ (accessed on 28 September 2024)). The collected files comprise recent Arabic articles, totaling around 2 million articles across different topics. This corpus contains approximately 111 million words.
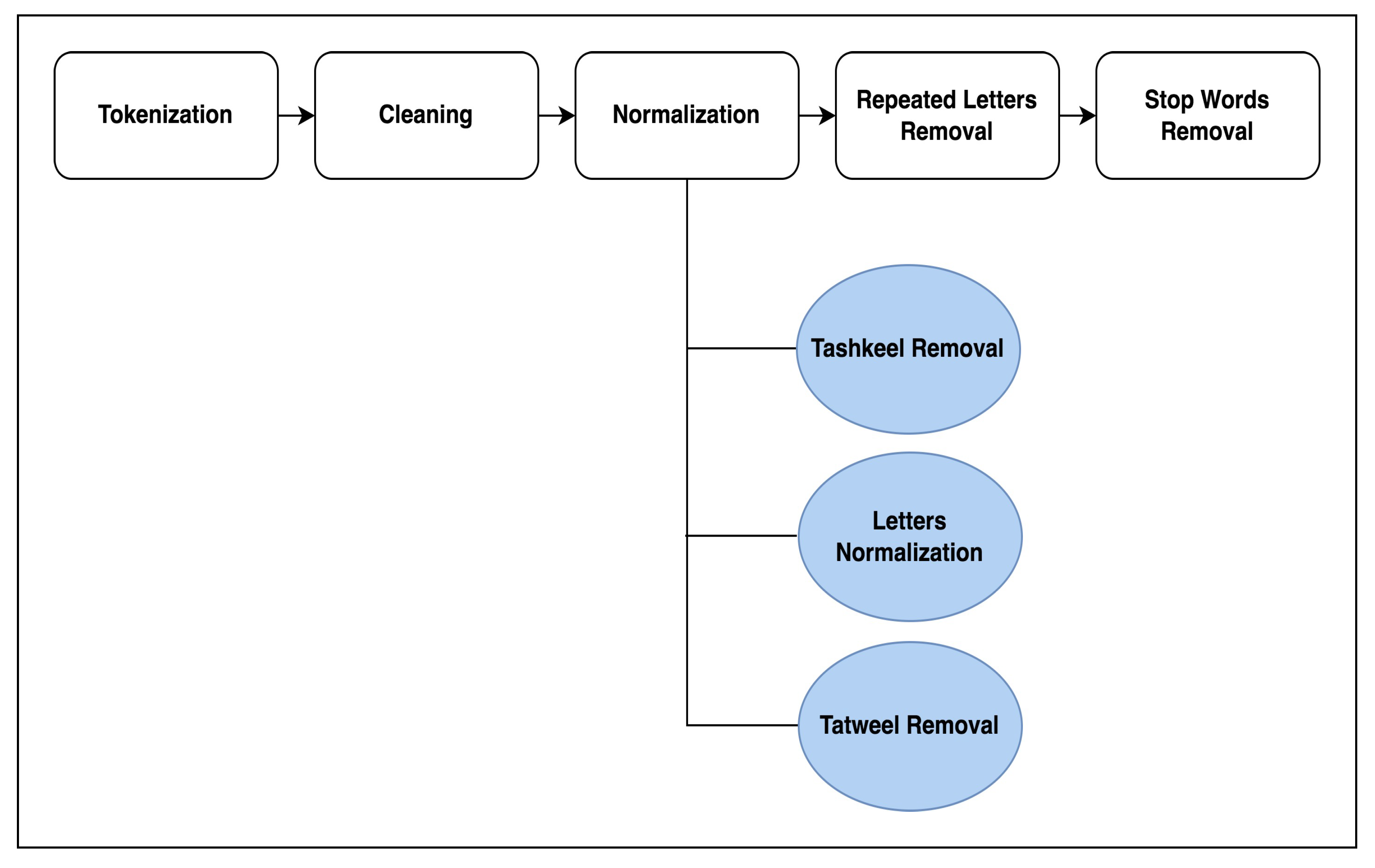
4.2. Corpus Preprocessing
- Tokenization: Since the text is considered as a single input block for the preprocessing program, we utilized tokenization as the first step. Tokenization breaks the text into individual tokens (words), allowing for easier processing. To accomplish this, we employed the (tokenize) function, which is a part of the pyarabic (https://pypi.org/project/PyArabic/ (accessed on 28 September 2024)) library.
- Cleaning: Then, we cleaned the text to remove any unwanted data. This includes removing digits, non-Arabic text, punctuation marks, emojis, and symbols.
- Normalization: Arabic is a highly complex language due to its richness, which includes representing the same word in various formats. To enhance the robustness of our models, we implemented several normalization steps to prevent word redundancy.
- –
- Tashkeel Removal: One of the unique features of Arabic is its use of specific marks for each letter in words. These marks represent the required sound for each letter in the word. Their existence affects the representation of the word, as changing one mark can lead the model to perceive the word as a new one. From the model’s perspective, every unique input is treated as individual input. To prevent the model from establishing different vectors for each marked version of the word, we removed any tashkeel marks. To perform this, we used the (strip_tashkeel) function from the (pyarabic) library.
- –
- Letters Normalization: We conducted letter normalization to standardize the format of certain Arabic letters. This step is crucial in ensuring that the model treats each letter consistently, preventing redundancy and improving overall performance.
- –
- Tatweel Removal: Some Arabic writers use (Tatweel) to add a touch of elegance to the text by incorporating extra dashes within the words. We removed it from the text by utilizing the (strip_tatweel) function from the (pyarabic) library.
- Repeated Letters Removal: One of the challenges that affects our training is the presence of unintentionally repeated letters within the same word. To address this issue, we implemented a step to remove repeated letters within the same word.
- Stop Words Removal: In the context of the Arabic language, stop words are words that are frequently used but do not carry significant meaning. By removing these stop words, we can reduce the size of the corpus and focus on more meaningful words. We started by adopting the Arabic stop words list provided by NLTK (https://www.nltk.org/ (accessed on 28 September 2024)), which contains 754 words. However, we noticed that stop words in Arabic can appear in various forms, such as different tenses, formats, or with the conjunction letter attached directly to them. To address this, we expanded the NLTK Arabic stop words list by adding a conjunction letter to each word and applied normalization to words that can come in different formats. Additionally, we added present and future verb formats to the stop words list. The resulting stop words list contains around 936 words.
4.3. Model Training
5. Model Evaluation
5.1. Analogy Test
5.2. Sentiment Analysis
5.3. Similarity Score
6. Results and Discussion
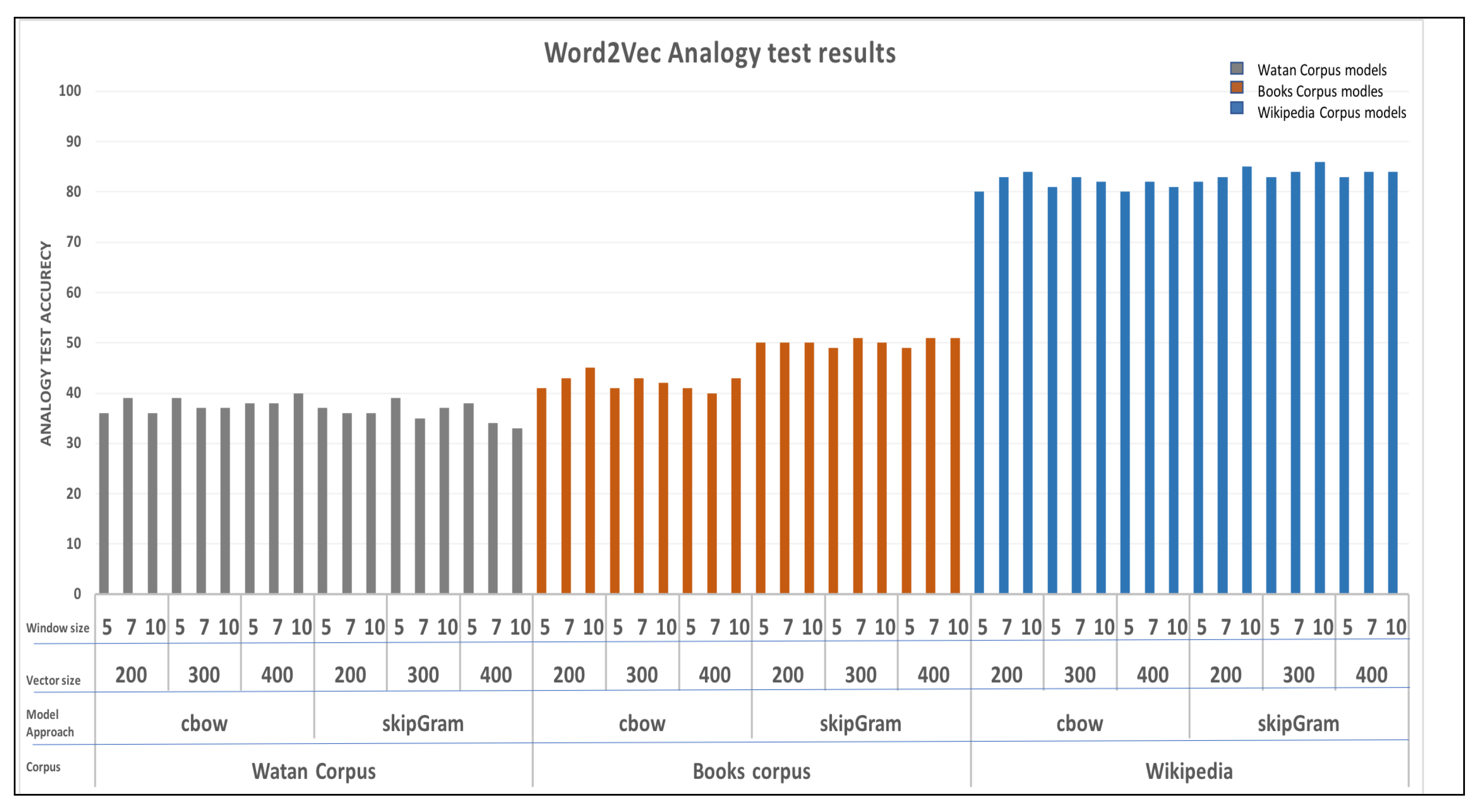
6.1. Analogy Test
6.1.1. Word2vec Models
6.1.2. FastText Models
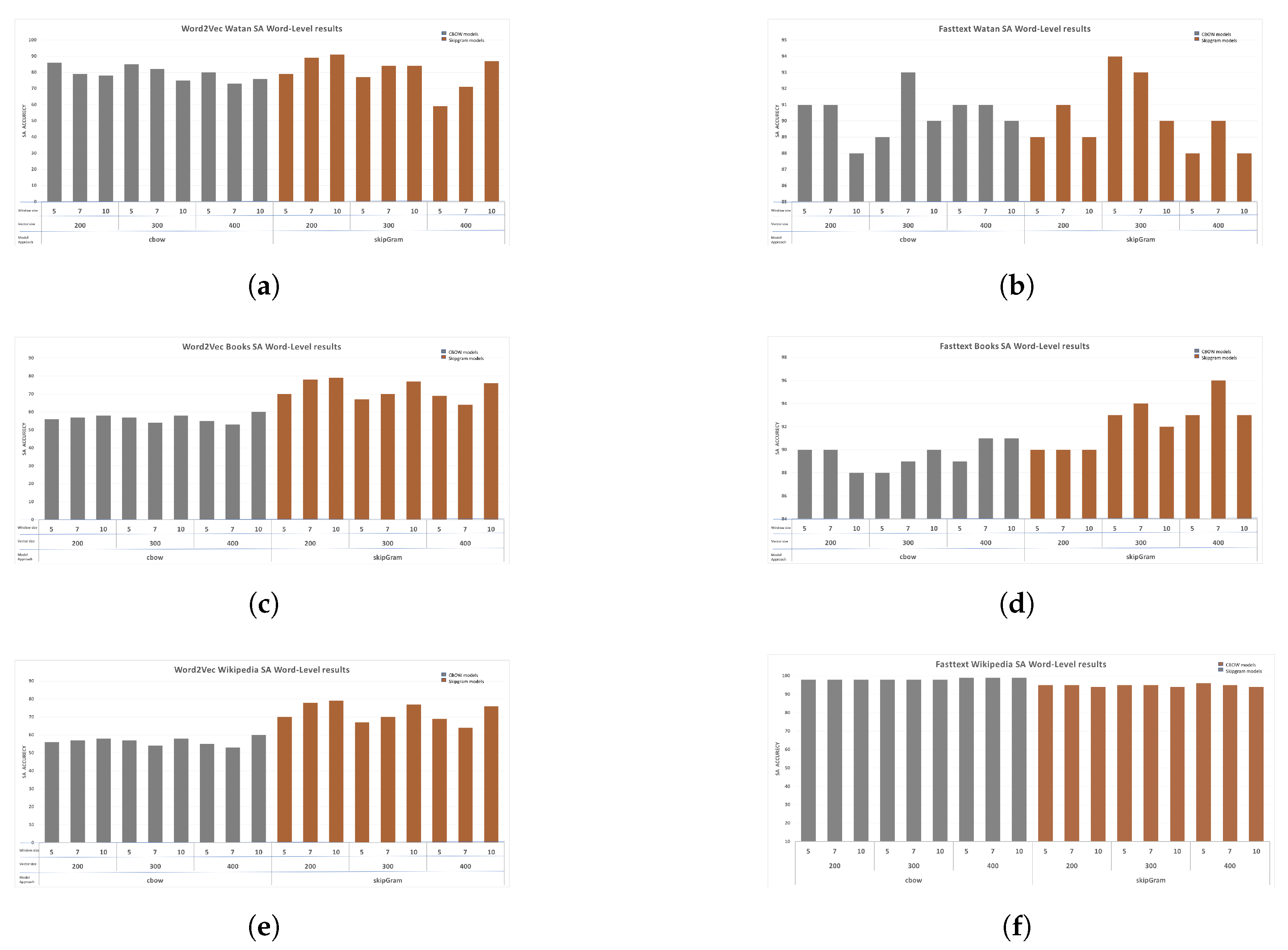
6.2. Sentiment Analysis
6.2.1. Word2vec Models
6.2.2. FastText Models
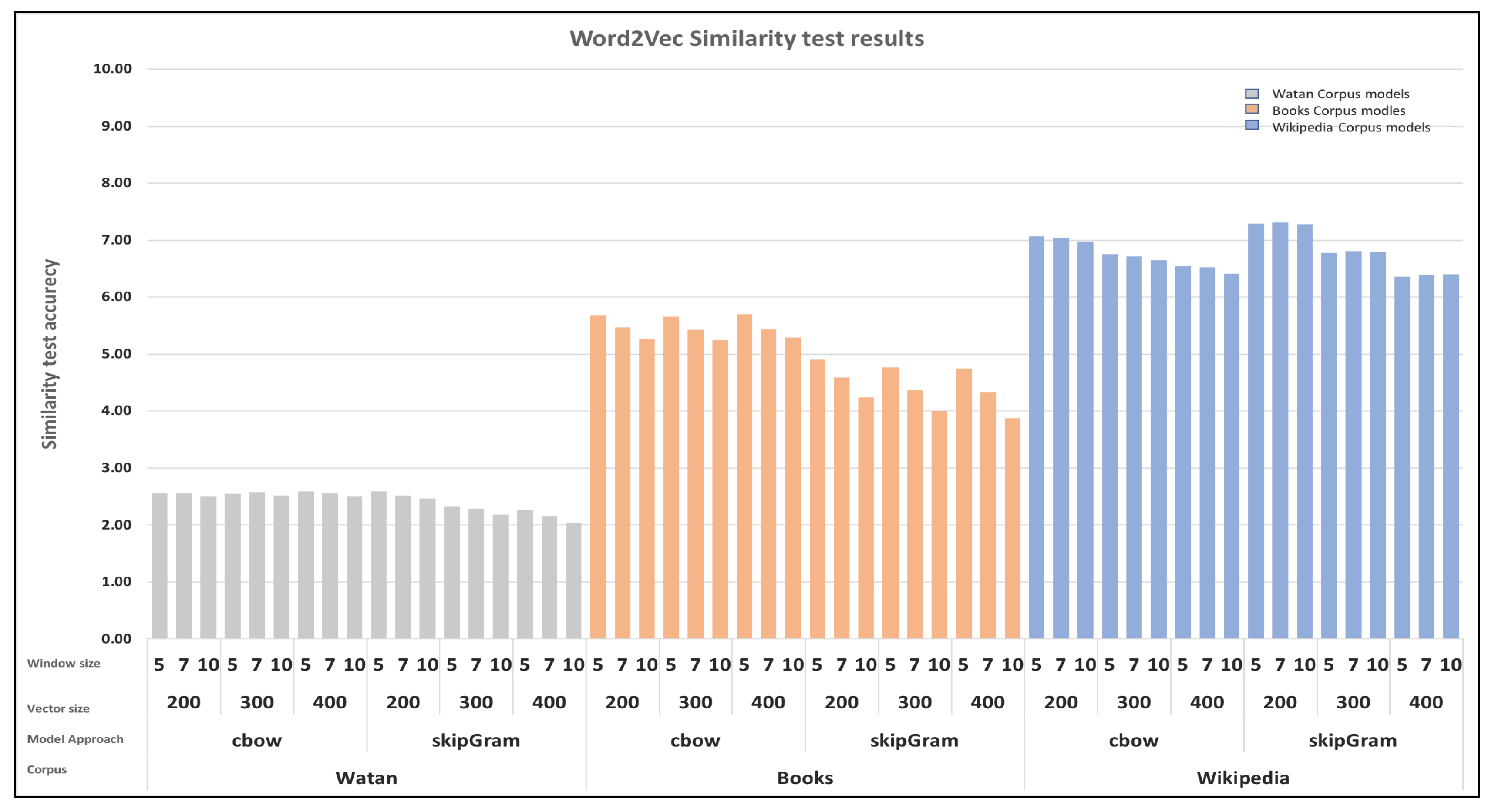
6.3. Similarity Score
7. Conclusions
- In the analogy test, it has been shown that employing a large vocabulary size had a positive influence on the results. Additionally, the FastText models with skip-gram approaches proved to be effective in solving analogy test questions.
- For sentiment analysis, we discovered that vocabulary size played a crucial role. Furthermore, for the FastText models, applying CBOW architecture led to improved accuracy, whereas for Word2Vec, applying skip-gram architecture enhanced accuracy. Moreover, smaller window size has a positive effect on accuracy.
- Finally, in the similarity score test, the FastText models delivered the highest scores. Smaller window sizes and smaller vector sizes positively impacted the results.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lai, S.; Liu, K.; He, S.; Zhao, J. How to Generate a Good Word Embedding? IEEE Intell. Syst. 2017, 31, 5–14. [Google Scholar] [CrossRef]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning Word Vectors for Sentiment Analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 142–150. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. Proc. Workshop ICLR 2013, 2013. [Google Scholar]
- Salama, R.A.; Youssef, A.; Fahmy, A. Morphological Word Embedding for Arabic. Procedia Comput. Sci. 2018, 142, 83–93. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Douze, M.; Jégou, H.; Mikolov, T. FastText.zip: Compressing text classification models. arXiv 2016, arXiv:1612.03651. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Grave, E.; Bojanowski, P.; Gupta, P.; Joulin, A.; Mikolov, T. Learning Word Vectors for 157 Languages. arXiv 2018, arXiv:1802.06893. [Google Scholar]
- Azroumahli, C.; El Younoussi, Y.; Achbal, F. An Overview of a Distributional Word Representation for an Arabic Named Entity Recognition System. In Proceedings of the Ninth International Conference on Soft Computing and Pattern Recognition (SoCPaR 2017), Marrakech, Morocco, 11–13 December 2017; pp. 130–140. [Google Scholar] [CrossRef]
- Azroumahli, C.; Rybinski, M.; Younoussi, Y.; Montes, J. Comparative study of Arabic Word Embeddings: Evaluation and Application. Int. J. Comput. Inf. Syst. Ind. Manag. Appl. 2020, 12, 349–362. [Google Scholar]
- Yagi, S.; Elnagar, A.; Fareh, S. A benchmark for evaluating Arabic word embedding models. Nat. Lang. Eng. 2022, 9, 978–1003. [Google Scholar]
- Soliman, A.B.; Eissa, K.; El-Beltagy, S.R. AraVec: A set of Arabic Word Embedding Models for use in Arabic NLP. Procedia Comput. Sci. 2017, 117, 256–265. [Google Scholar] [CrossRef]
- Mikolov, T.; Grave, E.; Bojanowski, P.; Puhrsch, C.; Joulin, A. Advances in Pre-Training Distributed Word Representations. arXiv 2017, arXiv:1712.09405. [Google Scholar]
- Naili, M.; Chaibi, A.H.; Ben Ghezala, H.H. Comparative study of word embedding methods in topic segmentation. Procedia Comput. Sci. 2017, 112, 340–349. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Athiwaratkun, B.; Wilson, A.G.; Anandkumar, A. Probabilistic FastText for Multi-Sense Word Embeddings. arXiv 2018, arXiv:1806.02901. [Google Scholar]
- Oueslati, O.; Cambria, E.; HajHmida, M.B.; Ounelli, H. A review of sentiment analysis research in Arabic language. Future Gener. Comput. Syst. 2020, 112, 408–430. [Google Scholar] [CrossRef]
- Kayraldeen, A. Ketab Alaalam. 1926. Available online: https://www.kutubltd.com/book_year/1926/ (accessed on 28 September 2024).
- Abbas, M. Watan 2004 Corpus. 2004. Available online: https://metatext.io/datasets/watan-2004-corpus (accessed on 28 September 2024).
- Attardi, G. WikiExtractor. 2015. Available online: https://github.com/attardi/wikiextractor (accessed on 28 September 2024).
- Chen, Z.; He, Z.; Liu, X.; Bian, J. Evaluating semantic relations in neural word embeddings with biomedical and general domain knowledge bases. BMC Med. Inform. Decis. Mak. 2018, 18, 65. [Google Scholar] [CrossRef]
- Zahran, M.A.; Magooda, A.; Mahgoub, A.Y.; Raafat, H.; Rashwan, M.; Atyia, A. Word Representations in Vector Space and their Applications for Arabic. In Proceedings of the Computational Linguistics and Intelligent Text Processing; Gelbukh, A., Ed.; Springer: New York, NY, USA, 2015; pp. 430–443. [Google Scholar]
- Dahou, A.; Xiong, S.; Zhou, J.; Haddoud, M.H.; Duan, P. Word Embeddings and Convolutional Neural Network for Arabic Sentiment Classification. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2418–2427. [Google Scholar]
- Gladkova, A.; Drozd, A.; Matsuoka, S. Analogy-based detection of morphological and semantic relations with word embeddings: What works and what doesn’t. In Proceedings of the NAACL Student Research Workshop, San Diego, CA, USA, 13–15 June 2016; pp. 8–15. [Google Scholar] [CrossRef]
- Khusainova, A.; Khan, A.; Rivera, A.R. SART - Similarity, Analogies, and Relatedness for Tatar Language: New Benchmark Datasets for Word Embeddings Evaluation. In Proceedings of the Computational Linguistics and Intelligent Text Processing; Gelbukh, A., Ed.; Springer: New York, NY, USA, 2023; pp. 380–390. [Google Scholar]
- Elrazzaz, M.; Elbassuoni, S.; Shaban, K.; Helwe, C. Methodical Evaluation of Arabic Word Embeddings. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 454–458. [Google Scholar] [CrossRef]
- Abdul-Mageed, M.; Elbassuoni, S.; Doughman, J.; Elmadany, A.; Nagoudi, E.M.B.; Zoughby, Y.; Shaher, A.; Gaba, I.; Helal, A.; El-Razzaz, M. DiaLex: A Benchmark for Evaluating Multidialectal Arabic Word Embeddings. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine (Virtual), 19 April 2021; pp. 11–20. [Google Scholar]
- Brahimi, B.; Touahria, M.; Tari, A. Improving sentiment analysis in Arabic: A combined approach. J. King Saud Univ.-Comput. Inf. Sci. 2019, 33, 1242–1250. [Google Scholar] [CrossRef]
- Ibrahim, H.S.; Abdou, S.M.; Gheith, M. Sentiment Analysis For Modern Standard Arabic And Colloquial. arXiv 2015, arXiv:1505.03105. [Google Scholar] [CrossRef]
- Iqbal, F.; Hashmi, J.M.; Fung, B.C.M.; Batool, R.; Khattak, A.M.; Aleem, S.; Hung, P.C.K. A Hybrid Framework for Sentiment Analysis Using Genetic Algorithm Based Feature Reduction. IEEE Access 2019, 7, 14637–14652. [Google Scholar] [CrossRef]
- Nassif, A.B.; Elnagar, A.; Shahin, I.; Henno, S. Deep learning for Arabic subjective sentiment analysis: Challenges and research opportunities. Appl. Soft Comput. 2021, 98, 106836. [Google Scholar] [CrossRef]
- Terad, M. Almojam Almofasal; Dar Alkotob Alarabiah. 2011. Available online: https://books.google.co.kr/books/about/%D8%A7%D9%84%D9%85%D8%B9%D8%AC%D9%85_%D8%A7%D9%84%D9%85%D9%81%D8%B5%D9%84_%D9%81%D9%8A_%D8%A7%D9%84%D9%85%D8%AA.html?id=6eVhDwAAQBAJ&redir_esc=y (accessed on 28 September 2024).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Multiple Vector Size | Multiple Window Size | Arabic Analogy | Models Availability | Corpus Availability | Books Corpus |
|---|---|---|---|---|---|---|
| AraVec [11] | ✓ | |||||
| Azroumahli et al. [9] | ✓ | ✓ | ||||
| Our paper | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Category | Number of Books |
|---|---|
| Dictionaries | 8 |
| Linguistics | 9 |
| Gramertic | 15 |
| Topic | Number of Articles |
|---|---|
| Culture | 2782 |
| Religion | 3860 |
| Economy | 3468 |
| Local news | 3596 |
| Internation news | 2035 |
| Sports | 4550 |
| Corpus | Source | Number of Words | Number of Vocabulary |
|---|---|---|---|
| Watan | Watan newspaper | 6 M | 35,211 |
| Book | 32 Arabic books | 11 M | 181,432 |
| Wiki | Wikipedia | 111 M | 445,977 |
| Architecture | Model | Best Score |
|---|---|---|
| Word2vec | Watan Corpus-CBOW | 40 |
| Watan Corpus-Skip-gram | 39 | |
| Books Corpus-CBOW | 45 | |
| Books Corpus-Skip-gram | 51 | |
| Wiki Corpus-CBOW | 84 | |
| Wiki Corpus-Skip-gram | 86 | |
| FastText | Watan Corpus - BOW | 34 |
| Watan Corpus - Skip-gram | 40 | |
| Books Corpus - BOW | 45 | |
| Books Corpus - Skip-gram | 49 | |
| Wiki Corpus - BOW | 80 | |
| Wiki Corpus - Skip-gram | 90 |
| Model | Score |
|---|---|
| Azroumahli et al. [9] | 60% |
| Aravec [11] | 79% |
| Our model-FastText approach | 90% |
| Our model-Word2Vec approach | 86% |
| Model | Best Scores |
|---|---|
| Word2vec-Watan Corpus | 91 |
| Word2vec-Book Corpus | 79 |
| Word2vec-Wiki | 85 |
| FastText-Watan Corpus | 94 |
| FastText-Book Corpus | 96 |
| FastText-Wiki | 99 |
| Model | Score |
|---|---|
| Aravec [11] | 90% |
| Our model-FastText approach | 99% |
| Our model-Word2Vec approach | 91% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Allahim, A.; Cherif, A. Advancing Arabic Word Embeddings: A Multi-Corpora Approach with Optimized Hyperparameters and Custom Evaluation. Appl. Sci. 2024, 14, 11104. https://doi.org/10.3390/app142311104
Allahim A, Cherif A. Advancing Arabic Word Embeddings: A Multi-Corpora Approach with Optimized Hyperparameters and Custom Evaluation. Applied Sciences. 2024; 14(23):11104. https://doi.org/10.3390/app142311104
Chicago/Turabian StyleAllahim, Azzah, and Asma Cherif. 2024. "Advancing Arabic Word Embeddings: A Multi-Corpora Approach with Optimized Hyperparameters and Custom Evaluation" Applied Sciences 14, no. 23: 11104. https://doi.org/10.3390/app142311104
APA StyleAllahim, A., & Cherif, A. (2024). Advancing Arabic Word Embeddings: A Multi-Corpora Approach with Optimized Hyperparameters and Custom Evaluation. Applied Sciences, 14(23), 11104. https://doi.org/10.3390/app142311104