

Real-Time Semantic Segmentation of 3D LiDAR Point Clouds for Aircraft Engine Detection in Autonomous Jetbridge Operations



Abstract
1. Introduction
2. Related Works
2.1. PointSeg: Real-Time Semantic Segmentation Based on 3D LiDAR Point Clouds
2.2. Semantic Segmentation of 3D Point Clouds Based on High-Precision Range Search Network
2.3. Learning Semantic Segmentation of Large-Scale Point Clouds with Random Sampling
2.4. AM-SegNet for Additive Manufacturing In Situ X-Ray Image Segmentation and Feature Quantification
3. Proposed Method
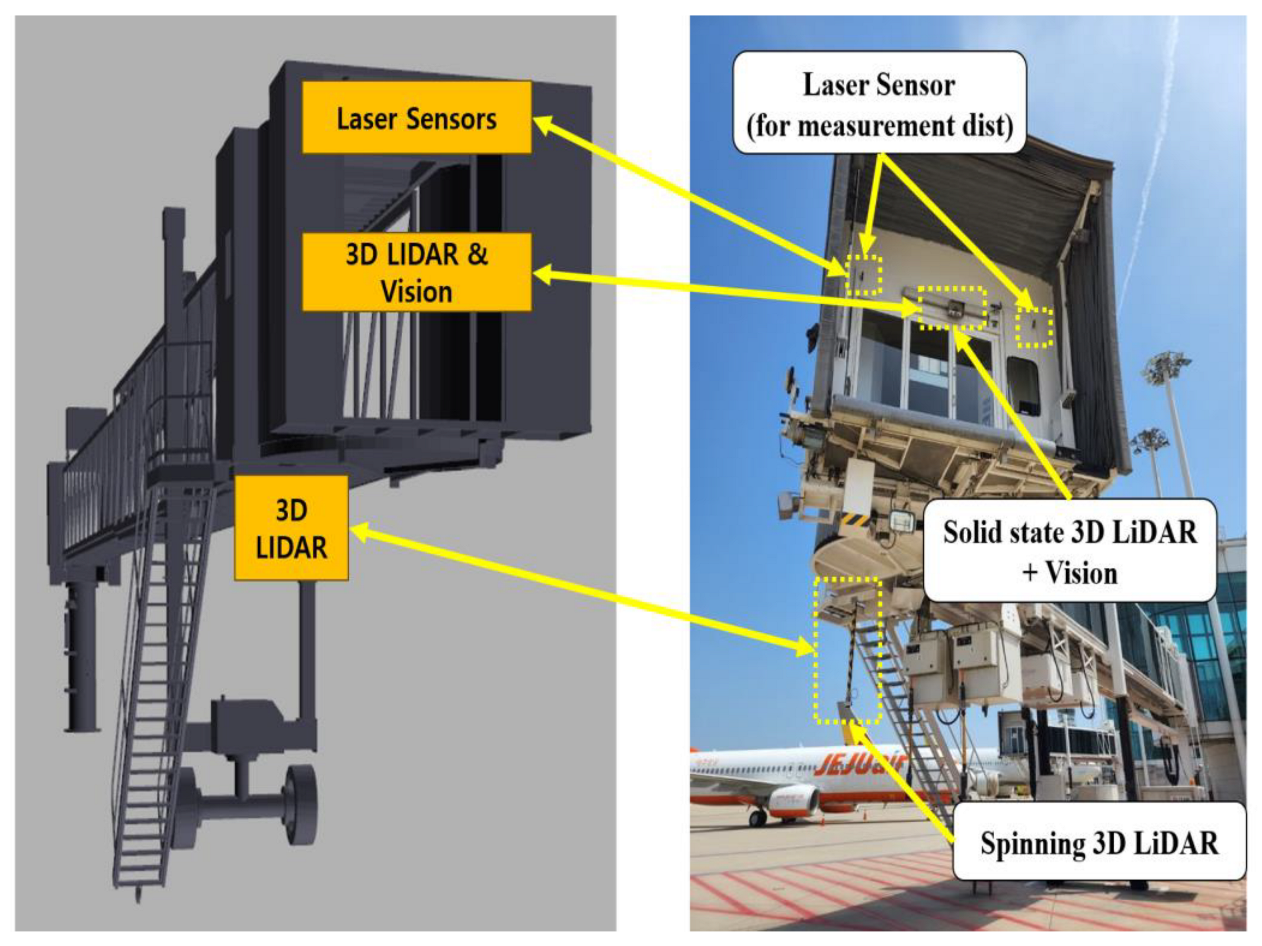
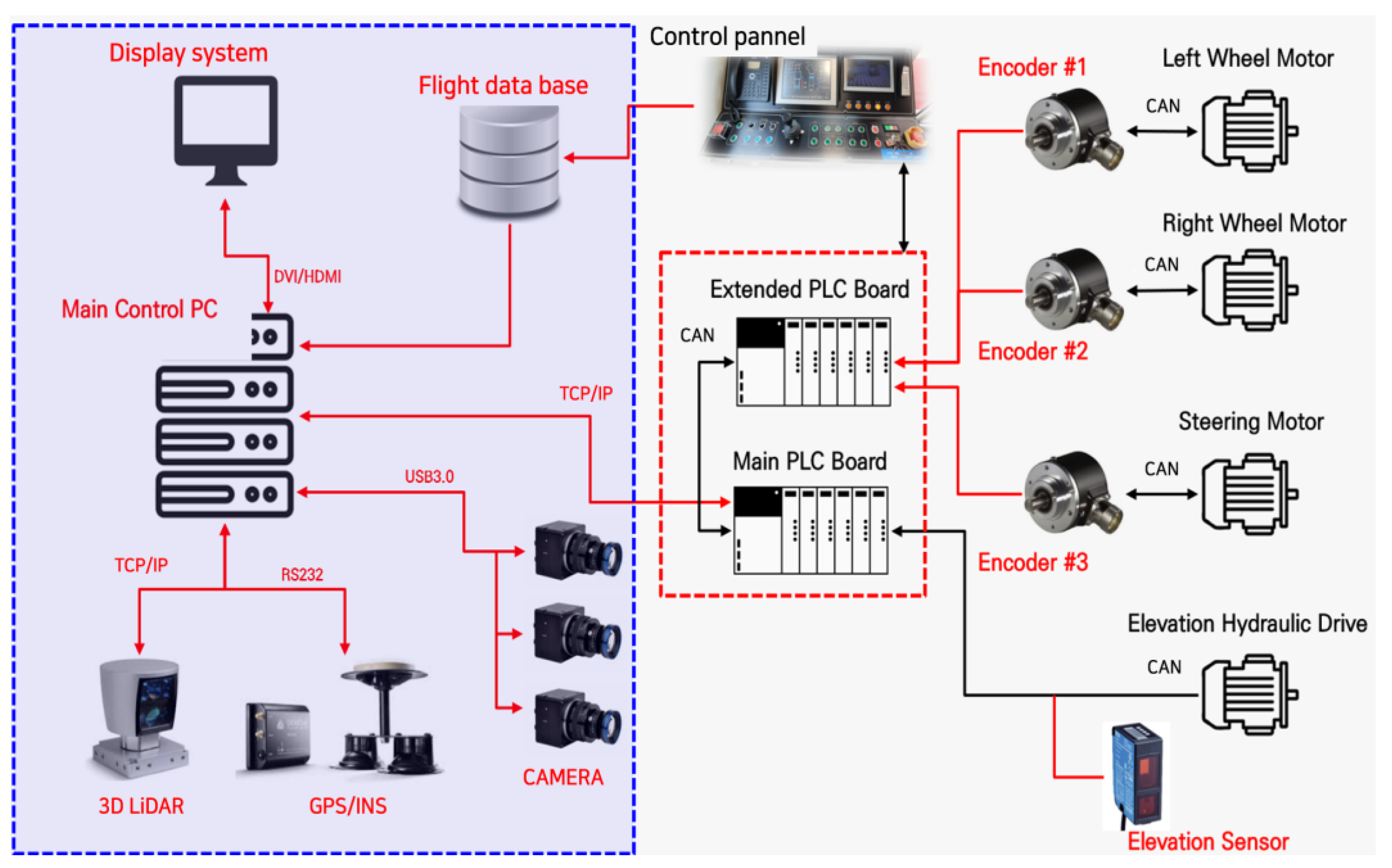
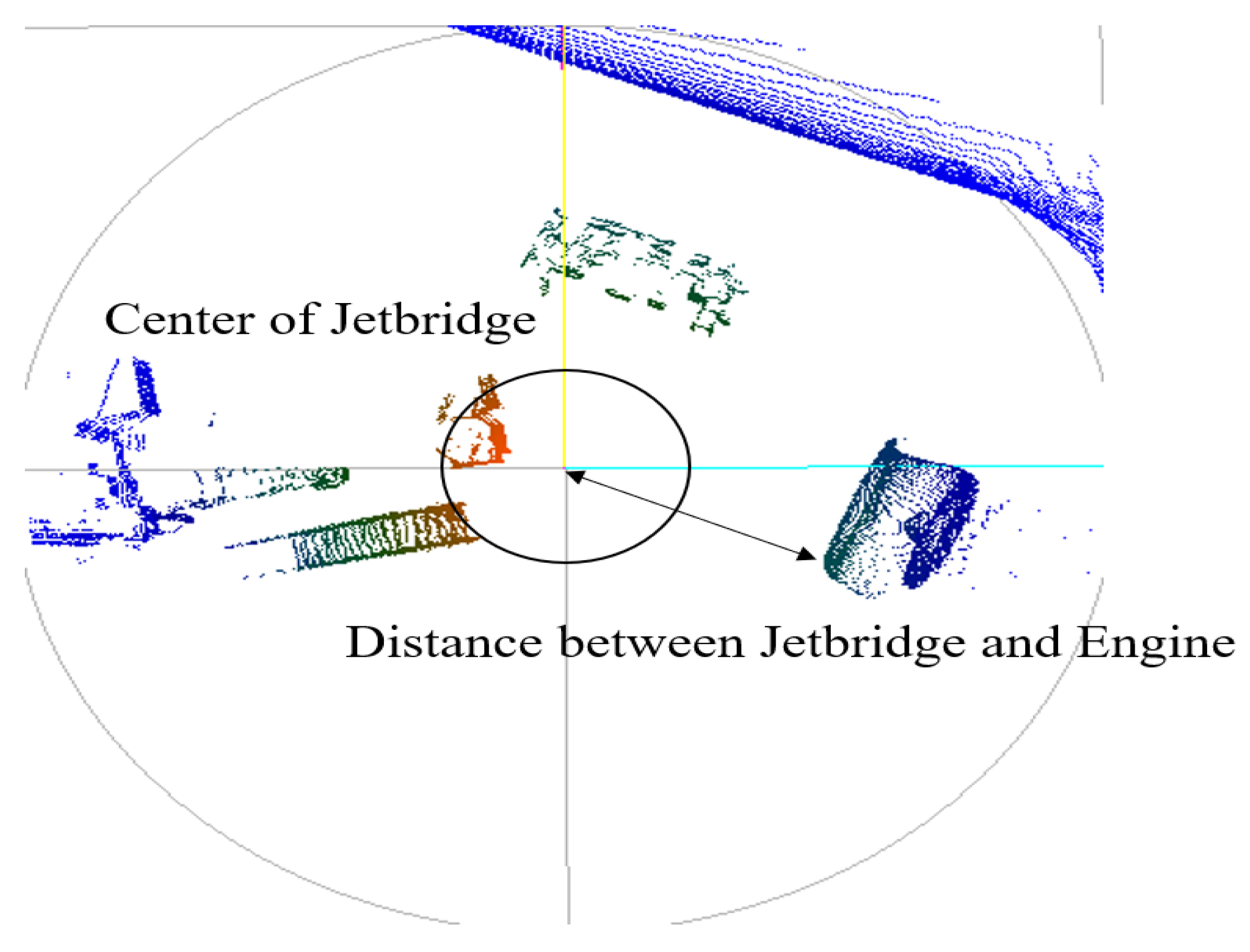
3.1. System Configuration
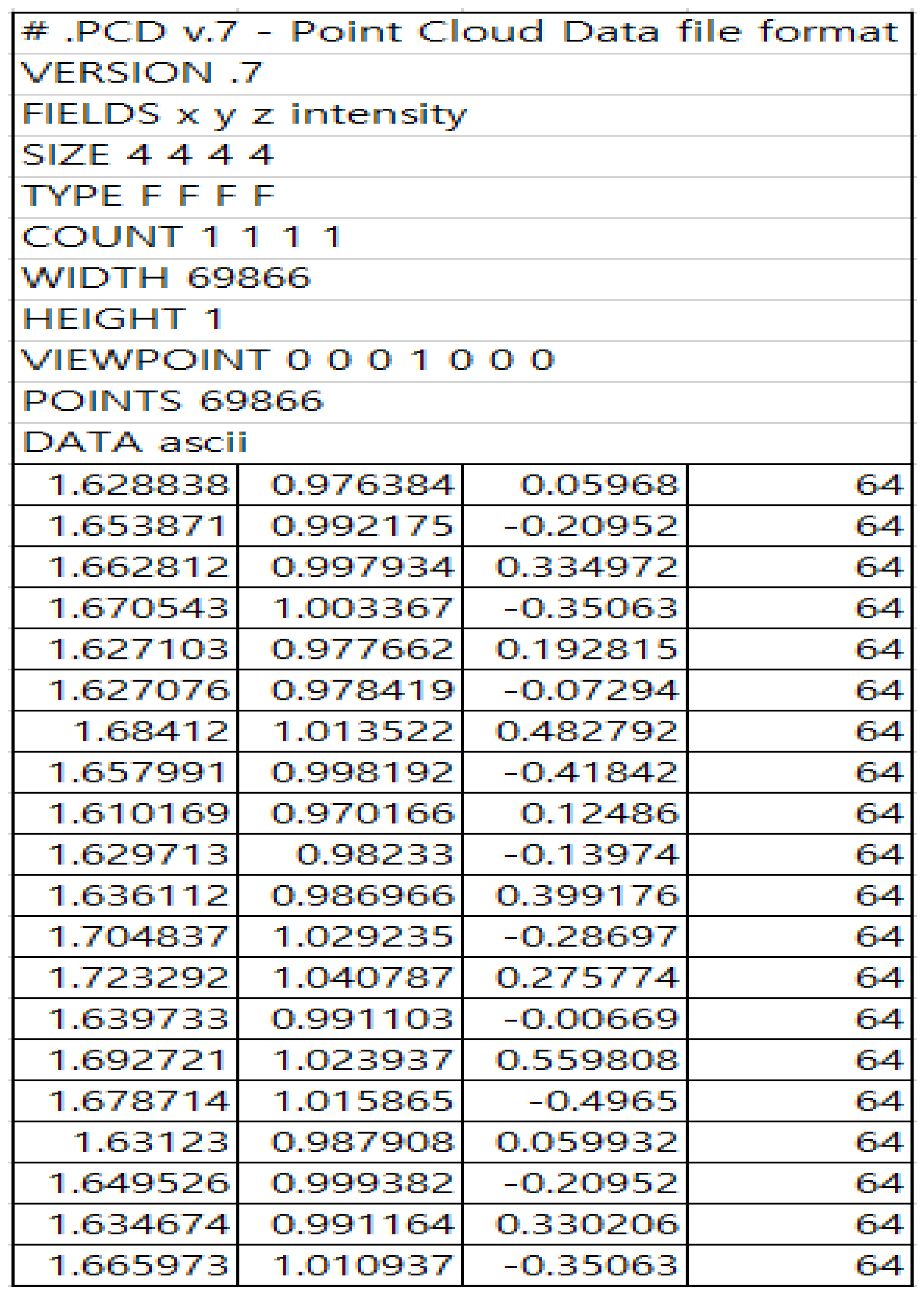
3.2. Data Analysis
- Random sampling: Select a random subset of samples from the data set.
- Model estimation: Estimate a model based on the selected samples.
- Consensus set formation: Identify data points that fit the estimated model to form a consensus set.
- Model evaluation: Evaluate the size of the consensus set and select the model that includes the most data points.
- Iteration: Repeat the above process for a predefined number of iterations to find the optimal model.
- Initial data collection: Collect raw point cloud data scanned with a 3D LiDAR sensor. There data comprise points from various objects, including the ground.
- Plane model estimation: Randomly select samples from the collected point cloud and estimate a plane model. The plane model, representing the ground, is estimated using the 3D RANSAC algorithm.
- Ground point identification: Identify points that fit the estimated plane model to form a consensus set. During this process, a distance threshold is set to distinguish ground points from non-ground points.
- Ground data filtering: Filter out points that do not belong to the consensus set, thus obtaining a clean point cloud containing only ground points.
- Post-processing: Perform additional preprocessing tasks using the filtered ground data. For instance, normalize the height information for the ground or separate obstacle data on the ground.
3.3. Semantic Segmentation Based on PointNet
- Input and embedding layers: PointNet takes N points as the inputs and maps each point to a higher-dimensional space through shared multi-layer perceptrons (MLPs). This step ensures that each point is represented by a feature vector.
- Symmetric function for aggregation: To handle the unordered nature of point clouds, PointNet employs a symmetric function, specifically max pooling, to aggregate features from all points. This function ensures that the network is invariant to the permutation of input points.
- Output layers: The aggregated global feature vector is processed by further MLPs to produce the final output, which can be classification scores for object recognition or per point scores for semantic segmentation.
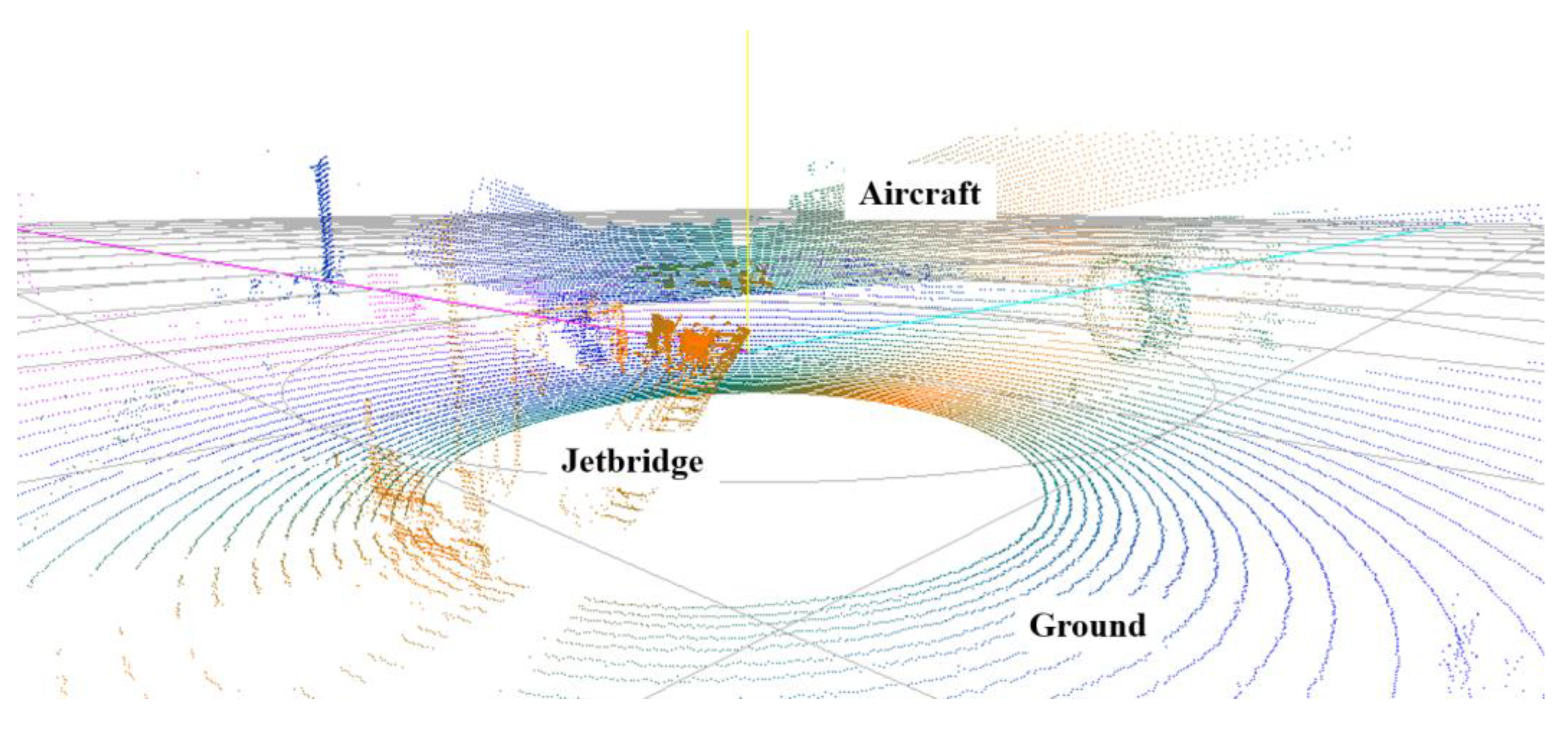
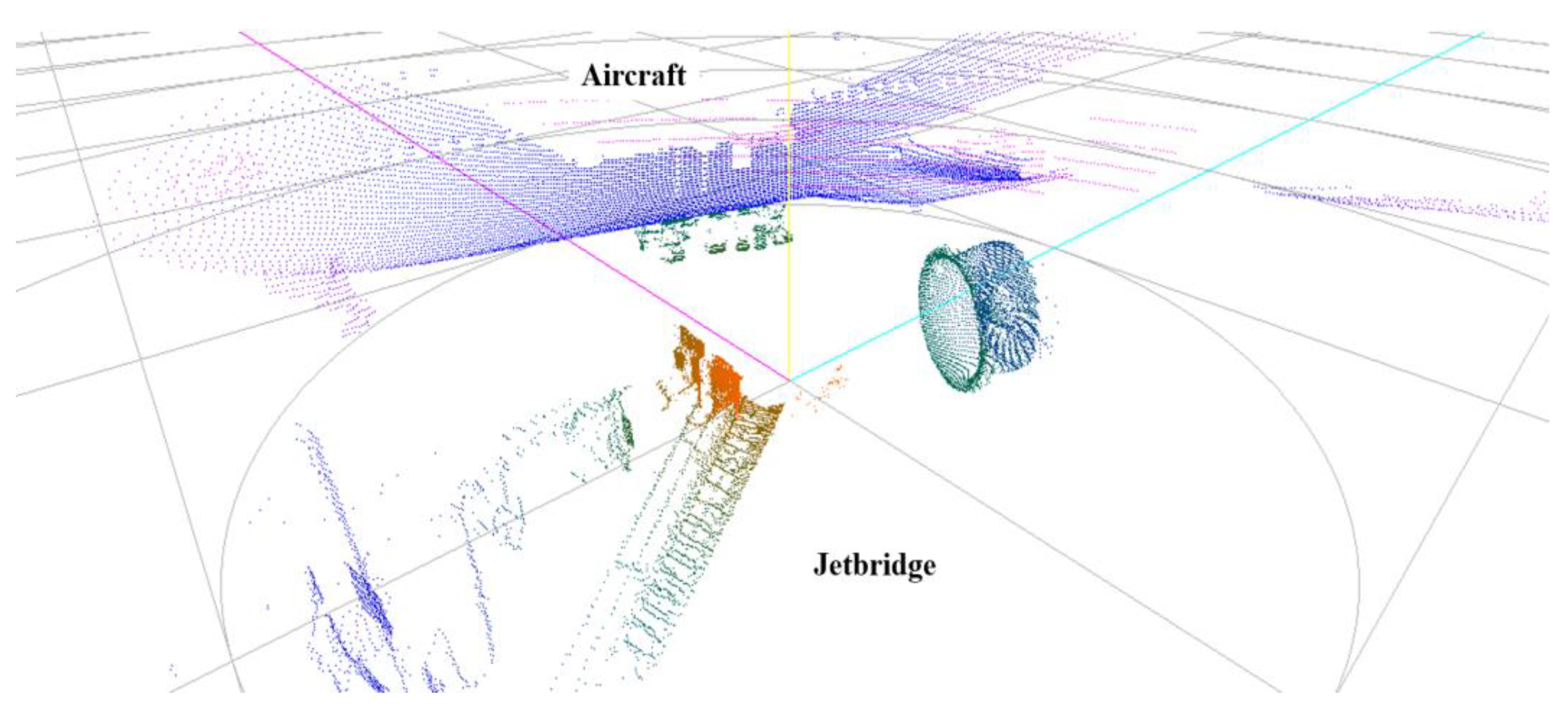
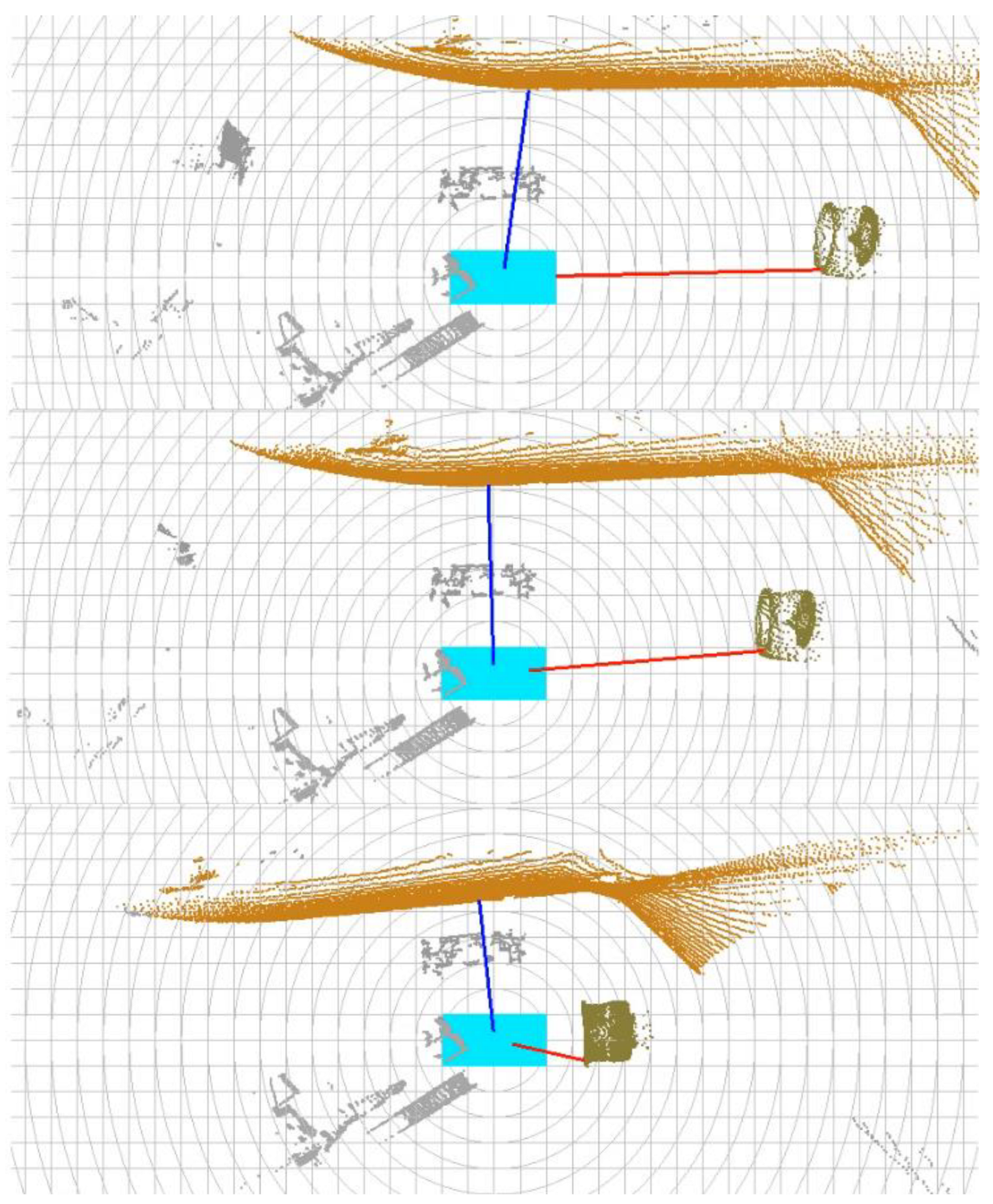
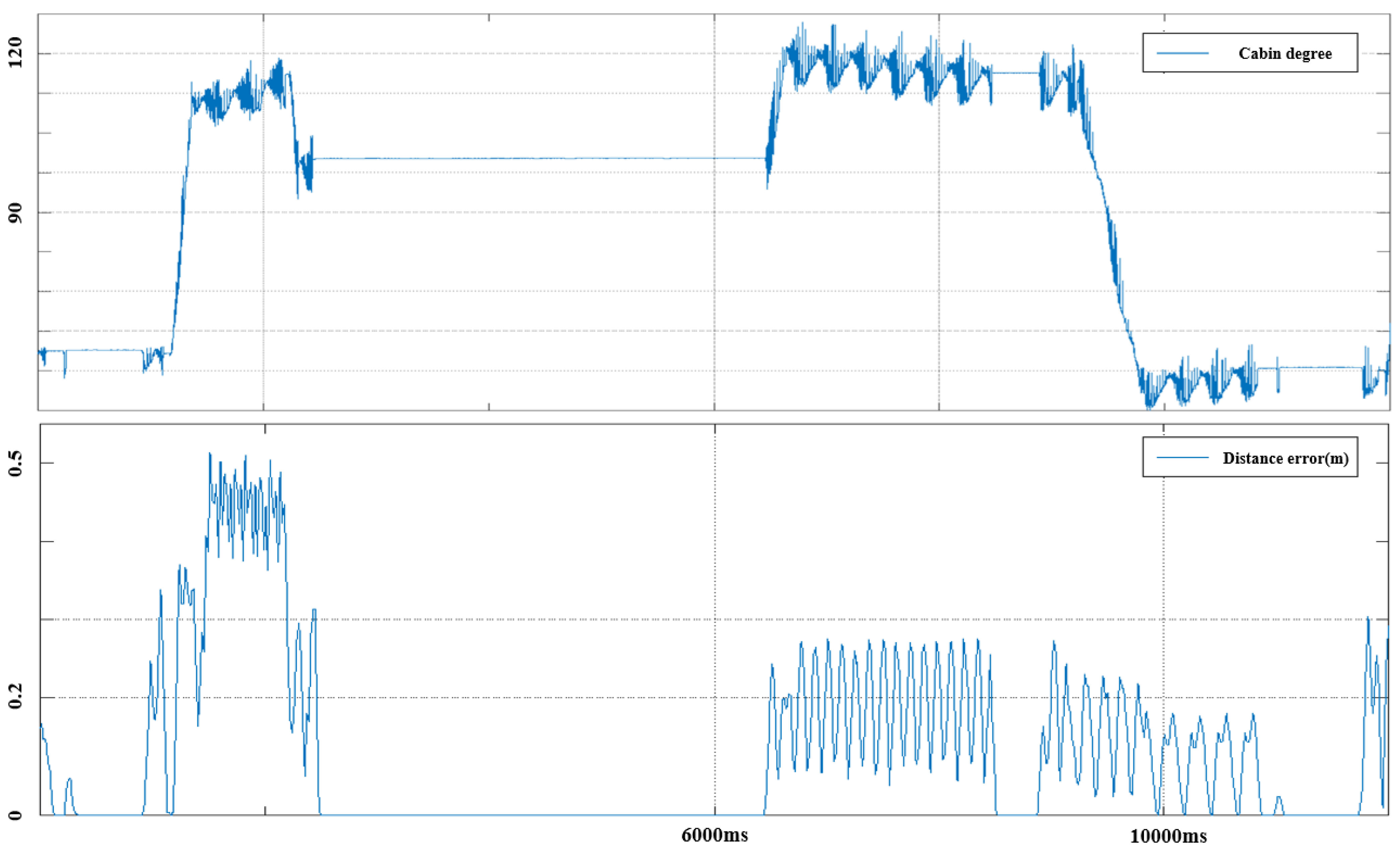
4. Experiments and Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fentaye, A.D.; Zaccaria, V.; Kyprianidis, K. Aircraft engine performance monitoring and diagnostics based on deep convolutional neural networks. Machines 2021, 9, 337. [Google Scholar] [CrossRef]
- Lee, J.-H.; Weon, I.-S.; Lee, S.-G. Digital Twin Simulation for Automated Aerobridge Docking System. In Proceedings of the International Conference on Intelligent Autonomous Systems, Zagreb, Croatia, 13–16 June 2023; Springer Nature: Berlin, Germany, 2023; pp. 361–374. [Google Scholar]
- Wu, Y.; Wang, Y.; Zhang, S.; Ogai, H. Deep 3D object detection networks using LiDAR data: A review. IEEE Sens. J. 2020, 21, 1152–1171. [Google Scholar] [CrossRef]
- Wang, Q.; Tan, Y.; Mei, Z. Computational methods of acquisition and processing of 3D point cloud data for construction applications. Arch. Comput. Methods Eng. 2020, 27, 479–499. [Google Scholar] [CrossRef]
- Haznedar, B.; Bayraktar, R.; Ozturk, A.E.; Arayici, Y. Implementing PointNet for point cloud segmentation in the heritage context. Herit. Sci. 2023, 11, 2. [Google Scholar] [CrossRef]
- Soilán, M.; Nóvoa, A.; Sánchez-Rodríguez, A.; Riveiro, B.; Arias, P. Semantic segmentation of point clouds with pointnet and kpconv architectures applied to railway tunnels. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, V-2-2020, 281–288. [Google Scholar] [CrossRef]
- He, Q.; Peng, J.; Jiang, Z.; Hu, X.; Zhang, J.; Nie, Q.; Wang, Y.; Wang, C. PointSeg: A Training-Free Paradigm for 3D Scene Segmentation via Foundation Models. arXiv 2024, arXiv:2403.06403. [Google Scholar]
- Alnaggar, Y.A.; Afifi, M.; Amer, K.; ElHelw, M. Multi projection fusion for real-time semantic segmentation of 3d lidar point clouds. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2021; pp. 1800–1809. [Google Scholar]
- Wang, Y.; Shi, T.; Yun, P.; Tai, L.; Liu, M. Pointseg: Real-Time semantic segmentation based on 3d lidar point cloud. arXiv 2018, arXiv:1807.06288. [Google Scholar]
- Li, J.; Huang, X.; Zhan, J. High-precision motion detection and tracking based on point cloud registration and radius search. IEEE Trans. Intell. Transp. Syst. 2023, 24, 6322–6335. [Google Scholar] [CrossRef]
- Chen, J.; Kakillioglu, B.; Velipasalar, S. Background-Aware 3-D point cloud segmentation with dynamic point feature aggregation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5703112. [Google Scholar] [CrossRef]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Learning semantic segmentation of large-Scale point clouds with random sampling. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8338–8354. [Google Scholar] [CrossRef]
- Mattheuwsen, L.; Bassier, M.; Vergauwen, M. Storm Drain Detection and Localisation on Mobile LIDAR Data Using a Pre-Trained Randla-Net Semantic Segmentation Network. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, 43, 237–244. [Google Scholar] [CrossRef]
- Huq, Y.B.; XieL, R.S.; GuoY, W.Z.; TrigoniN, M.A. RandLA-Net: Efficient semantic segmentation of large scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117. [Google Scholar]
- Li, W.; Lambert-Garcia, R.; Getley, A.C.M.; Kim, K.; Bhagavath, S.; Majkut, M.; Rack, A.; Lee, P.D.; Leung, C.L.V. AM-SegNet for additive manufacturing in situ X-ray image segmentation and feature quantification. Virtual Phys. Prototyp. 2024, 19, e2325572. [Google Scholar] [CrossRef]
- Weon, I.; Lee, S.-G. Multi-Sensor Fusion and YOLOv5 Model for Automated Detection of Aircraft Cabin Door. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 239–250. [Google Scholar] [CrossRef]
- Mishra, S.; Pandey, G.; Saripalli, S. Extrinsic Calibration of a 3D-LIDAR and a Camera. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; IEEE: New York, NY, USA, 2020; pp. 1765–1770. [Google Scholar]
- Weon, I.; Park, B.; Kim, H.-J.; Park, J.-H. Development of Autonomous Driving for Passenger Boarding Bridge (PBB) Through Aircraft Door Detection Based on YOLO Object Detection Algorithm. In Proceedings of the International Conference on Intelligent Autonomous Systems, Suwon, Republic of Korea, 4–7 July 2023; Springer Nature: Berlin, Germany, 2023; pp. 191–198. [Google Scholar]
- Weon, I.-S.; Lee, S.-G.; Ryu, J.-K. Object Recognition based interpolation with 3d lidar and vision for autonomous driving of an intelligent vehicle. IEEE Access 2020, 8, 65599–65608. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.; Choi, B. Real-Time 3D Object Detection using LiDAR and Camera Sensor Fusion. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Li, Z.; Shan, J. Ransac-based multi primitive building reconstruction from 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2022, 185, 247–260. [Google Scholar] [CrossRef]
- Wang, B.; Lan, J.; Gao, J. LiDAR filtering in 3D object detection based on improved RANSAC. Remote Sens. 2022, 14, 2110. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, X.; Liu, K.; Zhang, Z. A PointNet-Based CFAR Detection Method for Radar Target Detection in Sea Clutter. IEEE Geosci. Remote Sens. Lett. 2024, 21, 3502305. [Google Scholar] [CrossRef]
- Kumar, A.; Ray, N.; Panda, R.; Patra, P.K.; Das, M. A Deep3D: Comprehensive Approaches for 3D Object Analysis and Feature Extraction Using PointNet. In Proceedings of the 2024 1st International Conference on Cognitive, Green and Ubiquitous Computing (IC-CGU), Bhubaneswar, India, 1–2 March 2024; IEEE: New York, NY, USA, 2024; pp. 1–6. [Google Scholar]
- Liu, H.; Tian, S. Deep 3D point cloud classification and segmentation network based on GateNet. Vis. Comput. 2024, 40, 971–981. [Google Scholar] [CrossRef]
- Wang, G.; Wang, L.; Wu, S.; Zu, S.; Song, B. Semantic Segmentation of Transmission Corridor 3D Point Clouds Based on CA-PointNet++. Electronics 2023, 12, 2829. [Google Scholar] [CrossRef]
- Zhao, K.; Lu, H.; Li, Y. PointNetX: Part Segmentation Based on PointNet Promotion. In Proceedings of the International Conference on Cognitive Computation and Systems, Beijing, China, 17–18 December 2022; Springer Nature: Singapore, 2022; pp. 65–76. [Google Scholar]
- Wu, W.; Qi, Z.; Li, F. Pointconv: Deep convolutional networks on 3d point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9621–9630. [Google Scholar]
- Jiang, M.; Wu, Y.; Zhao, T.; Zhao, Z.; Lu, C. Pointsift: A sift-Like network module for 3d point cloud semantic segmentation. arXiv 2018, arXiv:1807.00652. [Google Scholar]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16259–16268. [Google Scholar]
- Qian, G.; Li, Y.; Peng, H.; Mai, J.; Hammoud, H.A.A.K.; Elhoseiny, M.; Ghanem, B. Pointnext: Revisiting pointnet++ with improved training and scaling strategies. Adv. Neural Inf. Process. Syst. 2022, 35, 23192–23204. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Range (80%, 1024 @ 10 Hz mode) | 170 m @ > 90% detection probability, 100 klx sunlight |
| Range (10%, 1024 @ 10 Hz mode) | 90 m @ > 90% detection probability, 100 klx sunlight |
| Min~Max Range | 0.5 m~150 m |
| Vertical Resolution | 64 channels |
| Horizontal Resolution | 1024 or 2048 (configurable) |
| Rotation Rate | 10 or 20 Hz (configurable) |
| Field of View | Vertical (+22.5° to −22.5°), Horizontal 360° |
| Angular Accuracy | Vertical: ±0.01°, Horizontal: ±0.01° |
| Range Resolution | 0.1 cm |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Weon, I.; Lee, S.; Yoo, J. Real-Time Semantic Segmentation of 3D LiDAR Point Clouds for Aircraft Engine Detection in Autonomous Jetbridge Operations. Appl. Sci. 2024, 14, 9685. https://doi.org/10.3390/app14219685
Weon I, Lee S, Yoo J. Real-Time Semantic Segmentation of 3D LiDAR Point Clouds for Aircraft Engine Detection in Autonomous Jetbridge Operations. Applied Sciences. 2024; 14(21):9685. https://doi.org/10.3390/app14219685
Chicago/Turabian StyleWeon, Ihnsik, Soongeul Lee, and Juhan Yoo. 2024. "Real-Time Semantic Segmentation of 3D LiDAR Point Clouds for Aircraft Engine Detection in Autonomous Jetbridge Operations" Applied Sciences 14, no. 21: 9685. https://doi.org/10.3390/app14219685
APA StyleWeon, I., Lee, S., & Yoo, J. (2024). Real-Time Semantic Segmentation of 3D LiDAR Point Clouds for Aircraft Engine Detection in Autonomous Jetbridge Operations. Applied Sciences, 14(21), 9685. https://doi.org/10.3390/app14219685