

Advancements in Technologies and Methodologies of Machine Learning in Landslide Susceptibility Research: Current Trends and Future Directions


 ,
,  ,
,
Abstract
1. Introduction
2. Constructing the Evaluation Index System
2.1. Selection of Mapping Units
2.2. Selection of Evaluation Factors
2.3. Screening of Evaluation Factors
3. Methodology Research
3.1. Logistic Regression (LR)
3.2. Support Vector Machine (SVM)
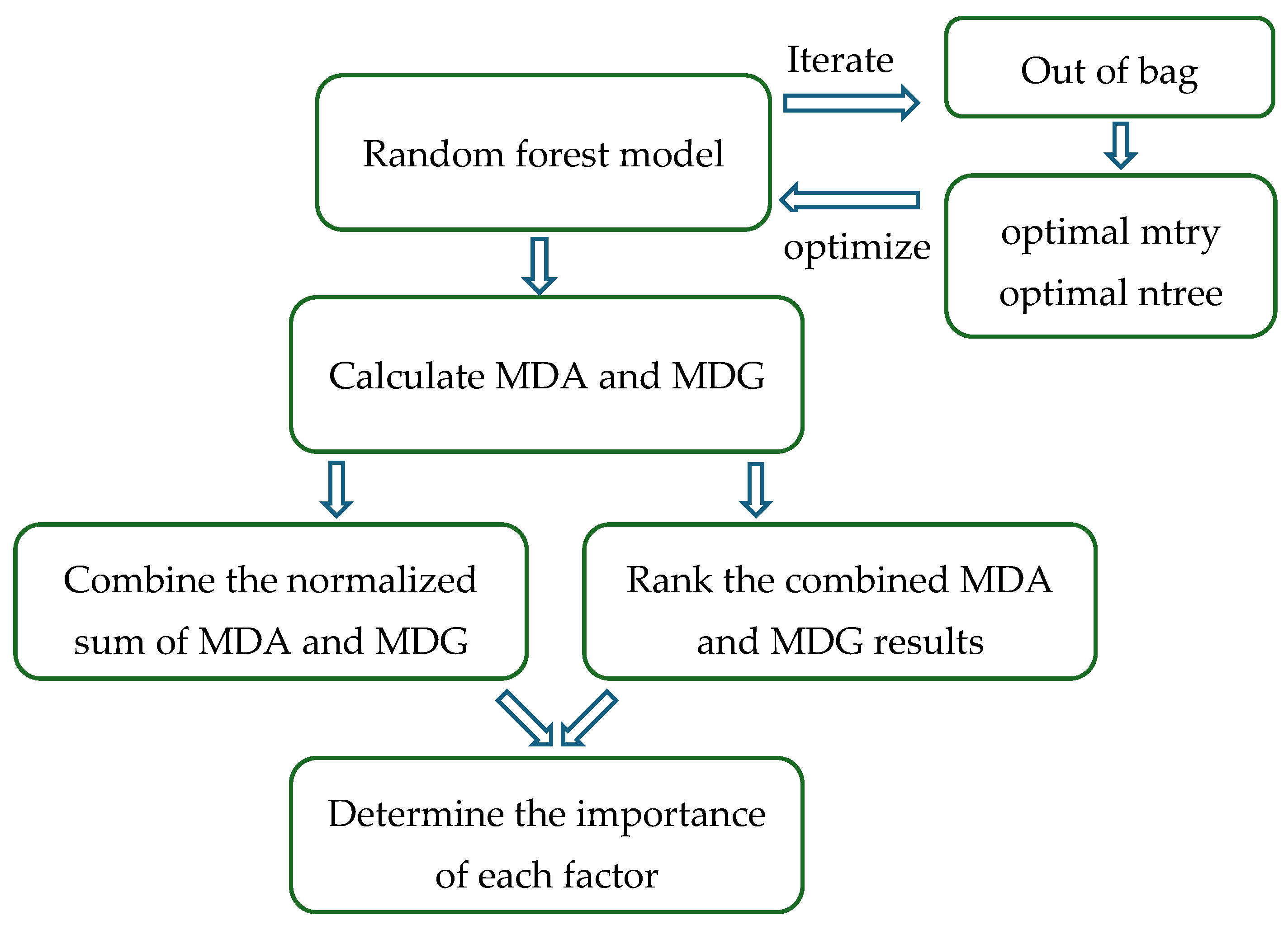
3.3. Random Forest (RF)
3.4. Artificial Neural Network (ANN)
4. Uncertainty Analysis
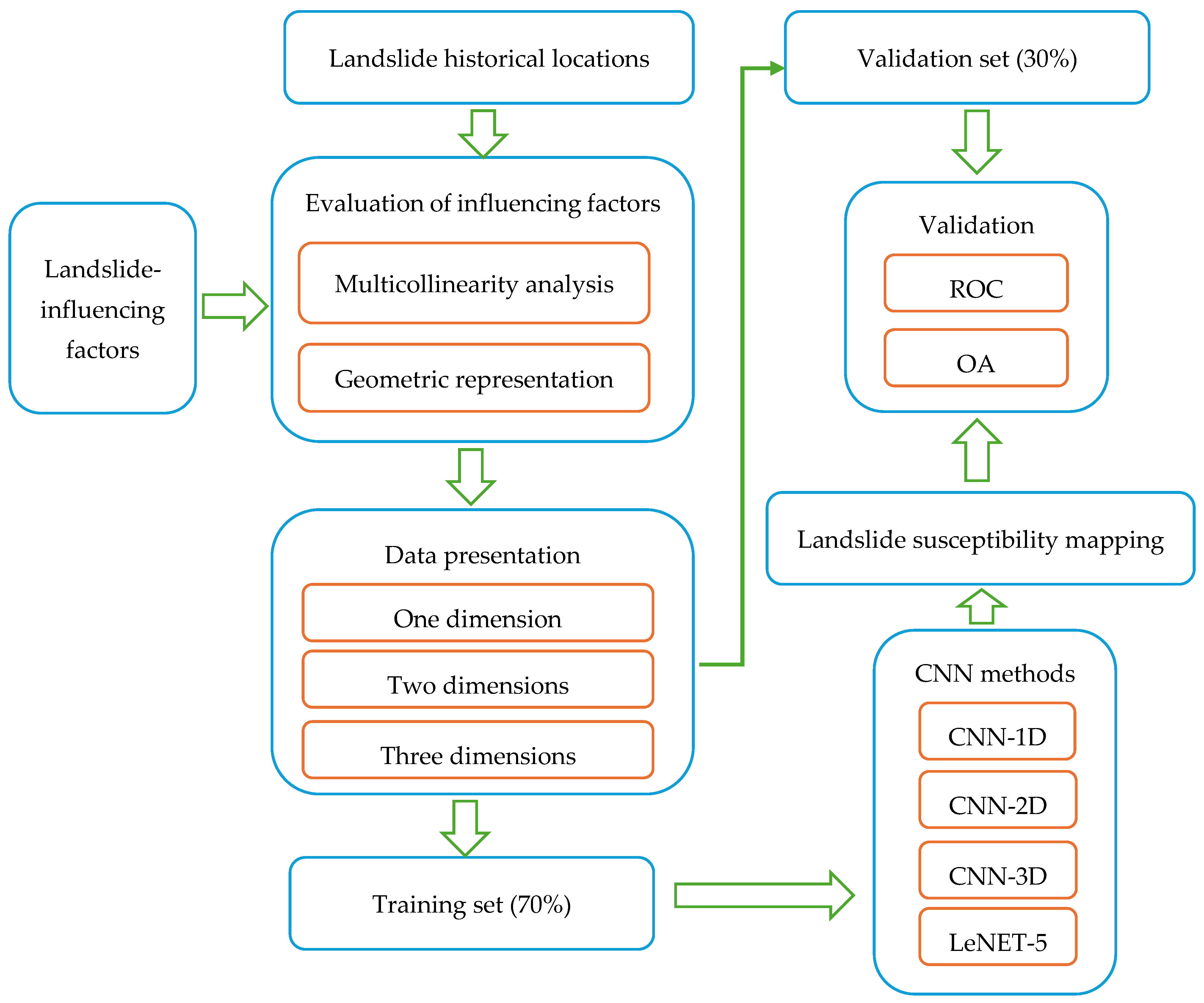
4.1. Selecting Positive and Negative Samples
4.2. Model Selection and Application
4.2.1. Traditional Machine Learning Models
4.2.2. Coupled Model
4.2.3. Deep Learning Model
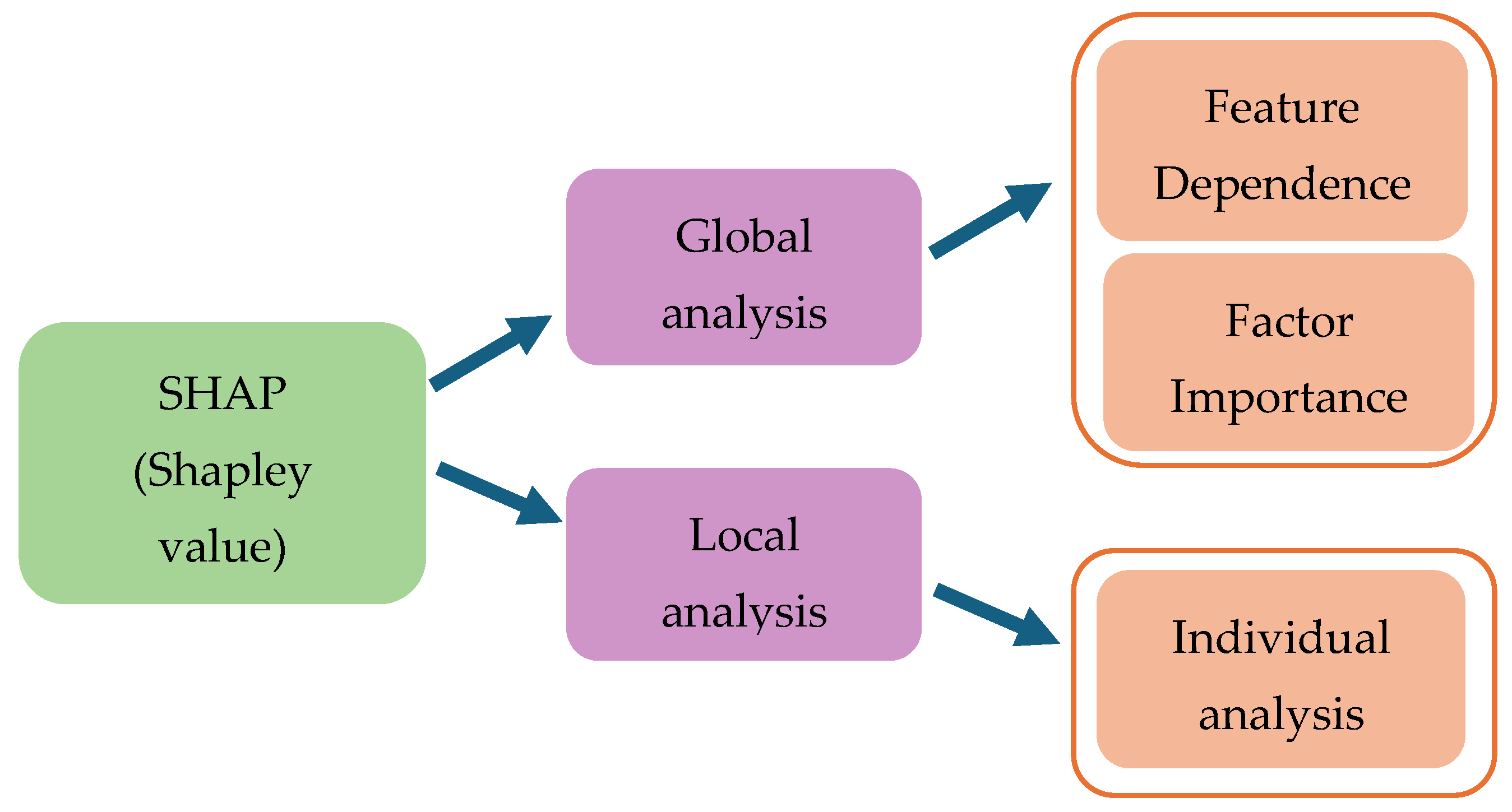
4.3. The Interpretability of “Black-Box” Models
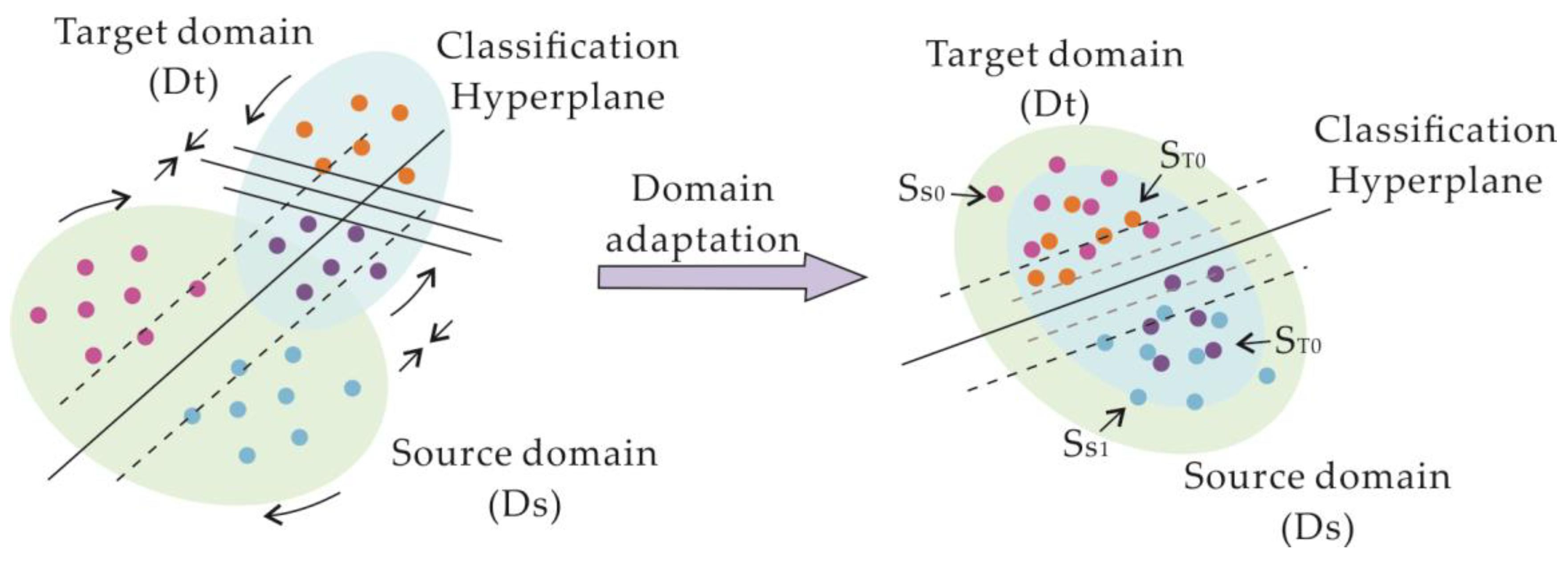
4.4. Transferability
5. Discussion and Future Opportunities
5.1. The Selection of Models
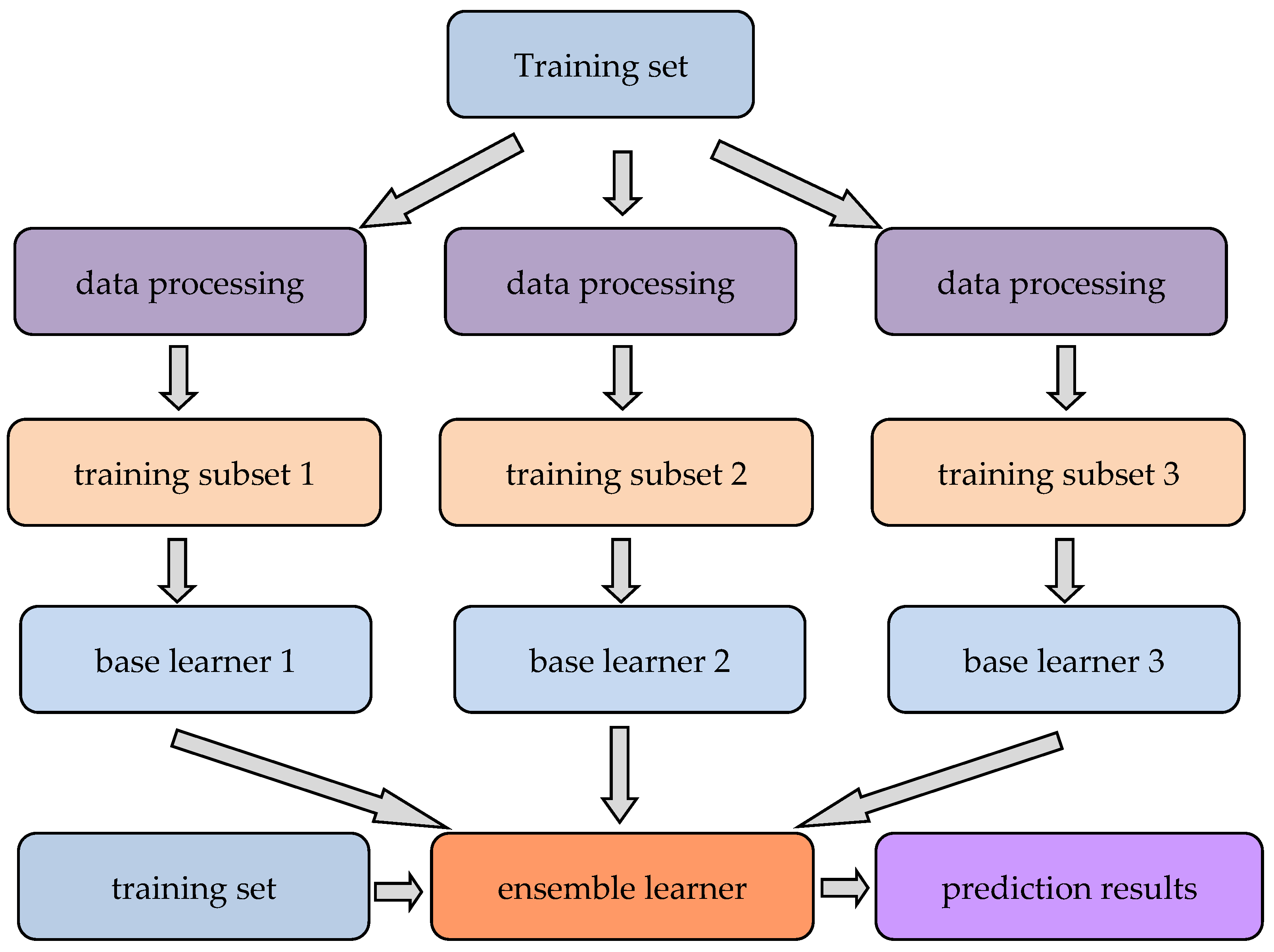
- Utilization of Coupled Models: Ensemble learning, through the integration of predictions from multiple models, has the potential to enhance overall predictive performance [108]. Section 4.2.2 details the benefits of coupled models. Figure 4 and Figure 6 illustrate two approaches to model coupling: Figure 4 shows the results of Model 1 being fed into Model 2 for further prediction, while Figure 6 depicts the evaluating factors being the input into different models, with the results of these models then being aggregated using methods such as weighted averaging or voting. Future research could delve into combining various types of machine learning models (such as decision trees, neural networks, support vector machines, etc.) to develop a more robust and reliable landslide susceptibility assessment model.
- Integration of Multi-Source Data and Interdisciplinary Collaboration: Future studies can harness diverse data sources, including satellite remote sensing data, terrain data, meteorological data, etc., and collaborate with experts in geology, geography, meteorology, and related fields. By amalgamating data and expertise from various sources, more comprehensive and precise landslide susceptibility assessment models can be developed.
- Advancement of Deep Learning Methods: With the enhancement of computing capabilities and the progression of deep learning technology, the utilization of complex models such as deep neural networks in landslide susceptibility assessment is poised for further expansion [3,144]. Future research can explore strategies to leverage deep learning methods to unearth the latent patterns and features in data, thereby enhancing the accuracy and reliability of landslide prediction. Deep learning models possess strong feature extraction capabilities, enabling them to handle multi-source data and exhibit efficient pattern recognition abilities. Therefore, future research can explore the coupling between various deep learning models as well as the coupling between traditional machine learning models and deep learning models. Such an exploration can address weaknesses in the transparency, interpretability, and susceptibility to overfitting of these models, ultimately enhancing the accuracy and reliability of landslide prediction.
5.2. The Construction of Evaluation Index Systems
5.3. The Interpretability of the Model
5.4. Transferability
- Building Cross-Regional Datasets: Creating datasets that cover multiple regions can train more generalized models, thus improving their applicability across different areas.
- Transfer Learning: Applying transfer learning techniques allows models to quickly adapt to new regions, thereby enhancing their stability and robustness.
- Ensemble Learning: Combining multiple models through ensemble learning can leverage the strengths of each model, boosting overall performance.
- Factor Importance Analysis: Analyzing the importance of various factors in the models can help identify and understand the key elements affecting landslides in different regions, thus improving model applicability.
- Model Interpretability Research: Enhancing model interpretability helps in understanding the decision-making processes and making necessary adjustments when applying models to new regions.
6. Conclusions
- (1)
- Model Selection and Future Directions: There is currently no consensus on the most effective machine learning model for landslide susceptibility assessment. Selecting the right model is essential for improving prediction accuracy and efficiency. Future research should focus on combining models, integrating multi-source data, fostering interdisciplinary collaboration, and developing advanced deep learning techniques.
- (2)
- Indicator System and Sample Selection: An effective indicator system is vital for accurate landslide risk assessment and management. The choice of mapping units should align with research objectives, using grid units for high spatial resolution and GIS data, and slope units for terrain continuity. Challenges include the complexity of multiple factors and data uncertainties. Establishing standards for selecting positive and negative samples is crucial. Positive samples should be derived from historical landslide data, while there is a need for standardized methods to select negative samples, especially in low-susceptibility areas. Future work should focus on developing standards and ensuring a diverse sample distribution to enhance model accuracy and applicability.
- (3)
- Interpretability of Models: The black-box nature of machine learning models hampers non-experts’ understanding of their decision-making processes, making interpretability a significant challenge. Future research should aim at creating interpretable models, improving feature importance analysis, and estimating uncertainty to build trust in the assessment results.
- (4)
- Portability and Adaptability: The effectiveness of landslide susceptibility models can vary due to geographical and data quality differences. Enhancing model stability and applicability through cross-regional datasets, transfer learning, and ensemble models is crucial. Addressing the challenges related to data availability and regional variations remains a priority for future research.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huang, R.; Xiang, X.; Ju, N. Assessment of China’s regional geohazards: Present situation and problems. Geol. Bull. China 2004, 23, 1078–1082. [Google Scholar]
- Zhang, H.; Yin, C.; Wang, S.; Guo, B. Landslide susceptibility mapping based on landslide classification and improved convolutional neural networks. Nat. Hazards 2023, 116, 1931–1971. [Google Scholar] [CrossRef]
- Azarafza, M.; Akgün, H.; Atkinson, P.M.; Derakhshani, R. Deep learning-based landslide susceptibility mapping. Sci. Rep. 2021, 11, 24112. [Google Scholar] [CrossRef] [PubMed]
- Bragagnolo, L.; Silva, R.V.d.; Grzybowski, J.M.V. Artificial neural network ensembles applied to the mapping of landslide susceptibility. Catena 2020, 184, 104240. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Niu, R.; Peng, L. Landslide susceptibility analysis based on deep learning. J. Geo-Inf. Sci. 2021, 23, 2244–2260. [Google Scholar]
- Li, W.; Wang, X. Application and comparison of frequency ratio and information value model for evaluating landslide susceptibility of loess gully region. J. Nat. Disasters 2020, 29, 213–220. [Google Scholar]
- Brabb, E.E. Innovative approaches to landslide hazard and risk mapping. In Proceedings of the International Landslide Symposium Proceedings, Toronto, ON, USA, 23–31 August 1985; pp. 17–22. [Google Scholar]
- Wang, J. Research on Deep Learning Methods for Identifying Potential Landslides and Assessing Susceptibility in Luding County. Ph.D. Thesis, China University of Geosciences, Wuhan, China, 2023. [Google Scholar]
- Wang, Z.; Li, D.; Wang, X. Review of researches on regional landslide susceptibility mapping model. J. Yangtze River Sci. Res. Inst. 2012, 29, 78–85+94. [Google Scholar]
- Sakulski, D.; Cosic, S.P.D.; Anna, A.F. Geo-Information Technology for Disaster Risk Assessment. Acta Geotech. Slov. 2011, 8, 64–74. [Google Scholar]
- Aditian, A.; Kubota, T.; Shinohara, Y. Comparison of GIS-based landslide susceptibility models using frequency ratio, logistic regression, and artificial neural network in a tertiary region of Ambon, Indonesia. Geomorphology 2018, 318, 101–111. [Google Scholar] [CrossRef]
- Sevgen, E.; Kocaman, S.; Nefeslioglu, H.A.; Gokceoglu, C. A novel performance assessment approach using photogrammetric techniques for landslide susceptibility mapping with logistic regression, ANN and random forest. Sensors 2019, 19, 3940. [Google Scholar] [CrossRef]
- Huang, F.; Cao, Z.; Guo, J.; Jiang, S.H.; Li, S.; Guo, Z. Comparisons of heuristic, general statistical anuniversityd machine learning models for landslide susceptibility prediction and mapping. Catena 2020, 191, 104580. [Google Scholar] [CrossRef]
- Guo, Y.; Dou, J.; Xiang, Z.; Ma, H.; Dong, A.; Luo, W. Optimized negative sampling strategies of gradient boosting decision tree and random forest for evaluating Wenchuan coseismic landslides susceptibility mapping. Bull. Geol. Sci. Technol. 2024, 43, 251–265. [Google Scholar]
- Reichenbach, P.; Rossi, M.; Malamud, B.D.; Mihir, M.; Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth Sci. Rev. 2018, 180, 60–91. [Google Scholar]
- Pacheco, Q.R.; Velastegui, M.A.; Montalván, B.N.; Morante, C.F.; Korup, O.; Daleles, R.C. Land use and land cover as a conditioning factor in landslide susceptibility: A literature review. Landslides 2023, 20, 967–982. [Google Scholar]
- Merghadi, A.; Yunus, A.P.; Dou, J.; Whiteley, J.; Thaipham, B.; Bui, D.T.; Avtar, R.; Abderrahmane, B. Machine learning methods for landslide susceptibility studies: A comparative overview of algorithm performance. Earth Sci. Rev. 2020, 207, 103225. [Google Scholar]
- Chen, Y.; Dong, J.; Guo, F.; Tong, B.; Zhou, T.; Fang, H.; Wang, L.; Zhan, Q. Review of landslide susceptibility assessment based on knowledge mapping. Stoch. Environ. Res. Risk Assess. 2022, 36, 2399–2417. [Google Scholar]
- Peng, R. Research on the Change of Landslide Susceptibility Trend in Typical Subtropical Areas of China Under Rainfall Change. Master’ Thesis, Central South University, Changsha, Cina, 2022. [Google Scholar]
- Guzzetti, F.; Carrara, A.; Cardinali, M.; Reichenbach, P. Landslide hazard evaluation: A review of current techniques and their application in a multi-scale study, Central Italy—ScienceDirect. Geomorphology 1999, 31, 181–216. [Google Scholar] [CrossRef]
- Li, J.; Zhou, C. Appropriate Grid Size for Terrain Based Landslide Risk Assessment in Lantau Island, Hong Kong. J. Remote Sens. 2003, 7, 86–92+161. [Google Scholar]
- Chang, Z.; Catani, F.; Huang, F.; Liu, G.; Meena, S.R.; Huang, J.; Zhou, C. Landslide susceptibility prediction using slope unit-based machine learning models considering the heterogeneity of conditioning factors. J. Rock Mech. Geotech. Eng. 2023, 15, 1127–1143. [Google Scholar] [CrossRef]
- Alvioli, M.; Marchesini, I.; Reichenbach, P.; Rossi, M.; Ardizzone, F.; Fiorucci, F.; Guzzetti, F. Automatic delineation of geomorphological slope units with r.slopeunits v1.0 and their optimization for landslide susceptibility modeling. Geosci. Model Dev. 2017, 9, 3975–3991. [Google Scholar] [CrossRef]
- Huang, F.; Tao, S.; Chang, Z.; Huang, J.; Fan, X.; Jiang, S.; Li, W. Efficient and automatic extraction of slope units based on multi-scale segmentation method for landslide assessments. Landslides 2021, 18, 3715–3731. [Google Scholar] [CrossRef]
- Mergili, M.; Marchesini, I.; Alvioli, M.; Metz, M.; Schneider-Muntau, B.; Rossi, M.; Guzzetti, F. A strategy for GIS-based 3-D slope stability modelling over large areas. Geosci. Model Dev. 2015, 7, 2969–2982. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, H.; Wen, H.; Sun, D. Landslide susceptibility mapping based on logistic regression in wushan county. J. Chongqing Norm. Univ. (Nat. Sci.) 2021, 38, 48–56. [Google Scholar]
- Nhu, V.-H.; Shirzadi, A.; Shahabi, H.; Singh, S.K.; Al-Ansari, N.; Clague, J.J.; Jaafari, A.; Chen, W.; Miraki, S.; Dou, J.; et al. Shallow landslide susceptibility mapping: A comparison between logistic model tree, logistic regression, naïve bayes tree, artificial neural network, and support vector machine algorithms. Int. J. Environ. Res. Public Health 2020, 17, 2749. [Google Scholar] [CrossRef] [PubMed]
- Rossi, M.; Guzzetti, F.; Reichenbach, P.; Mondini, A.C.; Peruccacci, S. Optimal landslide susceptibility zonation based on multiple forecasts. Geomorphology 2010, 114, 129–142. [Google Scholar] [CrossRef]
- Yao, X.; Tham, L.; Dai, F. Landslide susceptibility mapping based on support vector machine: A case study on natural slopes of Hong Kong, China. Geomorphology 2008, 101, 572–582. [Google Scholar] [CrossRef]
- Zhou, X.; Wen, H.; Zhang, Y.; Xu, J.; Zhang, W. Landslide susceptibility mapping using hybrid random forest with GeoDetector and RFE for factor optimization. Geosci. Front. 2021, 12, 101211. [Google Scholar] [CrossRef]
- Hao, G. Landslide Susceptibility Assessment based on Random Forest Model in Shangnan County. Master’s Thesis, Xi’an University of Science and Technology, Xi’an, China, 2019. [Google Scholar]
- Chen, Z. Study on Geological Hazard Susceptibility Assessment Model Based on Integrated Machine Learning and its Application. Master’s Thesis, Lanzhou University of Technology, Lanzhou, China, 2023. [Google Scholar]
- Chen, B.; Wang, Y.; Huang, X.; Huang, J. Spatial Prediction of Landslide Susceptibility in Mountainous and Hilly Counties Based on the Coupling Model of Information Value-Random Forest. Jiangxi Sci. 2022, 40, 914–919+964. [Google Scholar]
- Dahal, R.K.; Hasegawa, S.; Nonomura, A.; Yamanaka, M.; Masuda, T.; Nishino, K. GIS-based weights-of-evidence modelling of rainfall-induced landslides in small catchments for landslide susceptibility mapping. Environ. Geol. 2008, 54, 311–324. [Google Scholar] [CrossRef]
- Clemence, G.; Jose, Z. Landslide susceptibility assessment and validation in the framework of municipal planning in Portugal: The case of Loures Municipality. Environ. Manag. 2012, 50, 721–735. [Google Scholar]
- Zhan, H. Research on Susceptibility Assessment Method of Collapse Landslides Based on Machine Learning: A Case Study of Baiyun District, Guangzhou City. Master’s Thesis, Guangzhou University, Guangzhou, China, 2023. [Google Scholar]
- Chen, D.; Sun, D.; Wen, H.; Gu, Q. A study on landslide susceptibility of LightGBM-SHAP based on different factor screening methods. J. Beijing Norm. Univ. (Nat. Sci.) 2024, 60, 148–158. [Google Scholar]
- Sun, D.; Chen, D.; Mi, C.; Chen, X.; Mi, S.; Li, X. Evaluation of landslide susceptibility in the gentle hill-valley areas based on the interpretable random forest-recursive feature elimination model. J. Geomech. 2023, 29, 202–219. [Google Scholar]
- Zhang, K. Landslide Susceptibility Assessment Based on Optimal Computing Cell and Ulti-Model Coupling. Master’s Thesis, Lanzhou University, Lanzhou, China, 2023. [Google Scholar]
- Chang, K.T.; Merghadi, A.; Yunus, A.P.; Pham, B.T.; Dou, J. Evaluating scale effects of topographic variables in landslide susceptibility models using GIS-based machine learning techniques. Sci. Rep. 2019, 9, 12296. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Meng, Z.; Zhu, L.; Hu, D.; He, H. Optimizing the Sample Selection of Machine Learning Models for Landslide Susceptibility Prediction Using Information Value Models in the Dabie Mountain Area of Anhui, China. Sustainability 2023, 15, 1971. [Google Scholar] [CrossRef]
- Nguyen, M.D.; Pham, B.T.; Tuyen, T.T.; Hai Yen, H.P.; Prakash, I.; Vu, T.T.; Chapi, K.; Shirzadi, A.; Shahabi, H.; Dou, J. Development of an artificial intelligence approach for prediction of consolidation coefficient of soft soil: A sensitivity analysis. Open Constr. Build. Technol. J. 2019, 13, 178–188. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shirzadi, A.; Shahabi, H.; Geertsema, M.; Omidvar, E.; Clague, J.J.; Thai Pham, B.; Dou, J.; Talebpour Asl, D.; Bin Ahmad, B. New ensemble models for shallow landslide susceptibility modeling in a semi-arid watershed. Forests 2019, 10, 743. [Google Scholar] [CrossRef]
- Khosravi, K.; Shahabi, H.; Pham, B.T.; Adamowski, J.; Shirzadi, A.; Pradhan, B.; Dou, J.; Ly, H.B.; Gróf, G.; Ho, H.L.; et al. A comparative assessment of flood susceptibility modeling using multi-criteria decision-making analysis and machine learning methods. J. Hydrol. 2019, 573, 311–323. [Google Scholar] [CrossRef]
- Peng, L.; Sun, Y.; Zhan, Z.; Shi, W.; Zhang, M. FR-weighted GeoDetector for landslide susceptibility and driving factors analysis. Geomat. Nat. Hazards Risk 2023, 14, 2205001. [Google Scholar] [CrossRef]
- Chen, W.; Han, H.; Huang, B.; Huang, Q.; Fu, X. A data-driven approach for landslide susceptibility mapping: A case study of Shennongjia Forestry District, China. Geomat. Nat. Hazards Risk 2018, 9, 720–736. [Google Scholar] [CrossRef]
- Kayastha, P.; Dhital, M.R.; De, S.F. Application of the analytical hierarchy process (AHP) for landslide susceptibility mapping: A case study from the Tinau watershed, west Nepal. Comput. Geosci. 2013, 52, 398–408. [Google Scholar] [CrossRef]
- Li, Y.; Chen, J.; Zhou, F.; Li, Z.; Mehmood, Q. Stability evaluation and potential damage of a giant paleo-landslide deposit at the East Himalayan Tectonic Junction on the Southeastern margin of the Qinghai–Tibet Plateau. Nat. Hazards 2022, 111, 2117–2140. [Google Scholar]
- Migoń, P.; Jancewicz, K.; Różycka, M.; Duszyński, F.; Kasprzak, M. Large-scale slope remodelling by landslides–Geomorphic diversity and geological controls, Kamienne Mts., Central Europe. Geomorphology 2017, 289, 134–151. [Google Scholar] [CrossRef]
- Chen, W.; Pourghasemi, H.R.; Naghibi, S.A. A comparative study of landslide susceptibility maps produced using support vector machine with different kernel functions and entropy data mining models in China. Bull. Eng. Geol. Environ. 2018, 77, 647–664. [Google Scholar]
- Chen, Z.; Liang, S.; Ke, Y.; Yang, Z.; Zhao, H. Landslide susceptibility assessment using evidential belief function, certainty factor and frequency ratio model at Baxie River basin, NW China. Geocarto Int. 2019, 34, 348–367. [Google Scholar] [CrossRef]
- Liu, R.; Yang, X.; Xu, C.; Wei, L.; Zeng, X. Comparative study of convolutional neural network and conventional machine learning methods for landslide susceptibility mapping. Remote Sens. 2022, 14, 321. [Google Scholar] [CrossRef]
- Tang, R.; Yan, E.; Wen, T.; Yin, X.; Tang, W. Comparison of logistic regression, information value, and comprehensive evaluating model for landslide susceptibility mapping. Sustainability 2021, 13, 3803. [Google Scholar] [CrossRef]
- Torizin, J. Elimination of informational redundancy in the weight of evidence method: An application to landslide susceptibility assessment. Stoch. Environ. Res. Risk Assess. 2016, 30, 635–651. [Google Scholar] [CrossRef]
- Huang, W. Landslide Susceptibility Assessment in Large Range Based on Deep Learning: A Case Study of the Qinghai-Tibet Plateau Transportation Corridor. Master’s Thesis, Chang’an University, Xi’an, China, 2023. [Google Scholar]
- Guo, Z.; Shi, Y.; Huang, F.; Fan, X.; Huang, J. Landslide susceptibility zonation method based on C5. 0 decision tree and K-means cluster algorithms to improve the efficiency of risk management. Geosci. Front. 2021, 12, 101249. [Google Scholar] [CrossRef]
- Qi, T.; Zhao, Y.; Meng, X.; Shi, W.; Qing, F.; Chen, G.; Zhang, Y.; Yue, D.; Guo, F. Distribution modeling and factor correlation analysis of landslides in the large fault zone of the western Qinling Mountains: A machine learning algorithm. Remote Sens. 2021, 13, 4990. [Google Scholar] [CrossRef]
- Tonini, M.; Pecoraro, G.; Romailler, K.; Calvello, M. Spatio-temporal cluster analysis of recent Italian landslides. Georisk Assess. Manag. Risk Eng. Syst. Geohazards 2022, 16, 536–554. [Google Scholar] [CrossRef]
- Zhang, Y.; Tang, J.; Liao, R.; Zhang, M.; Zhang, Y.; Wang, X.; Su, Z. Application of an enhanced BP neural network model with water cycle algorithm on landslide prediction. Stoch. Environ. Res. Risk Assess. 2021, 35, 1273–1291. [Google Scholar] [CrossRef]
- Chen, W.; Pourghasemi, H.R.; Kornejady, A.; Zhang, N. Landslide spatial modeling: Introducing new ensembles of ANN, MaxEnt, and SVM machine learning techniques. Geofis. Int. 2017, 305, 314–327. [Google Scholar] [CrossRef]
- He, Q.; Wang, M.; Liu, K. Rapidly assessing earthquake-induced landslide susceptibility on a global scale using random forest—ScienceDirect. Geomorphology 2021, 391, 107889. [Google Scholar] [CrossRef]
- Chowdhury, M.S.; Rahaman, M.N.; Sheikh, M.S.; Sayeid, M.A.; Mahmud, K.H.; Hafsa, B. GIS-based landslide susceptibility mapping using logistic regression, random forest and decision and regression tree models in Chattogram District, Bangladesh. Heliyon 2024, 10, e23424. [Google Scholar] [CrossRef] [PubMed]
- Meng, Q.; Smith, S.A.; Rodgers, J. Geospatial Analysis and Mapping of Regional Landslide Susceptibility: A Case Study of Eastern Tennessee, USA. GeoHazards 2024, 5, 364–373. [Google Scholar] [CrossRef]
- Hu, X. Research on the Susceptibility and Risk Assessment of Geological Hazards in Changchun Based on GIS and Stacking Model. Master’s Thesis, Jilin University, Changchun, China, 2020. [Google Scholar]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin, Germany, 2000; pp. 267–290. [Google Scholar]
- Dai, F.; Yao, X.; Tan, G. Landslide susceptibility mapping using support vector machines. Earth Sci. Front. 2007, 14, 153–159. [Google Scholar]
- Yu, C.; Chen, J. Landslide Susceptibility Mapping Using the Slope Unit for Southeastern Helong City, Jilin Province, China: A Comparison of ANN and SVM. Symmetry 2020, 12, 1047. [Google Scholar] [CrossRef]
- Huang, F.; Yin, K.; Jiang, S.; Huang, J.; Cao, Z. Landslide susceptibility assessment based on clustering analysis and support vector machine. Chin. J. Rock Mech. Eng. 2018, 37, 156–167. [Google Scholar]
- Pradhan, B. A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput. Geosci. 2013, 51, 350–365. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach Learn 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Zhou, C.; Fang, X.; Wu, X.; Wang, Y. Risk assessment of mountain torrents based on three machine learning algorithms. J. Geo-Inf. Sci. 2019, 21, 1679–1688. [Google Scholar]
- Liu, Y.; Di, B.; Zhan, Y.A.; Stamatopoulos, C. Debris Flows Susceptibility Assessment in Wenchuan Earthquake Areas Based on Random Forest Algorithm Model. Mt. Res. 2018, 36, 765–773. [Google Scholar]
- Zhang, S.; Wu, G. Debris flow susceptibility and its reliability based on random forest and gis. Earth Sci. 2019, 44, 3115–3134. [Google Scholar]
- Wu, X.; Lai, C.; Chen, X.; Ren, X. A landslide hazard assessment based on random forest weight: A case study in the Dongjiang River Basin. J. Nat. Disasters 2017, 26, 119–129. [Google Scholar]
- Deng, Y. Flood Susceptibility Assessment in Mainland China Based on Machine Learning. Master’s Thesis, Lanzhou University, Lanzhou, China, 2023. [Google Scholar]
- Taalab, K.; Cheng, T.; Zhang, Y. Mapping landslide susceptibility and types using Random Forest. Big Earth Data 2018, 2, 159–178. [Google Scholar] [CrossRef]
- Wu, X.; Song, Y.; Chen, W.; Kang, G.; Qu, R.; Wang, Z.; Wang, J.; Lv, P.; Chen, H. Analysis of Geological Hazard Susceptibility of Landslides in Muli County Based on Random Forest Algorithm. Sustainability 2023, 15, 4328. [Google Scholar] [CrossRef]
- Lin, R.; Liu, J.; Xu, S.; Liu, M.; Zhang, M.; Liang, E. Evaluation method of landslide susceptibility based on random forest weighted information. Sci. Surv. Mapp. 2020, 45, 131–138. [Google Scholar]
- He, L.; Wu, X.; He, Z.; Xue, D.; Luo, F.; Bai, W.; Kang, G.; Chen, X.; Zhang, Y. Susceptibility Assessment of Landslides in the Loess Plateau Based on Machine Learning Models: A Case Study of Xining City. Sustainability 2023, 15, 14761. [Google Scholar] [CrossRef]
- Selamat, S.N.; Majid, N.A.; Taha, M.R.; Osman, A. Landslide Susceptibility Model Using Artificial Neural Network (ANN) Approach in Langat River Basin, Selangor, Malaysia. Land 2022, 11, 833. [Google Scholar] [CrossRef]
- Dou, J.; Xiang, Z.; Xu, Q.; Zheng, P.; Wang, X.; Su, A.; Liu, J.; Luo, W. Application and Development Trend of Machine Learning in Landslide Intelligent Disaster Prevention and Mitigation. Earth Sci. 2023, 48, 1657–1674. [Google Scholar]
- Ji, S.; Yu, D.; Shen, C.; Li, W.; Xu, Q. Landslide detection from an open satellite imagery and digital elevation model dataset using attention boosted convolutional neural networks. Landslides 2020, 17, 1337–1352. [Google Scholar] [CrossRef]
- Xu, Q.; Guo, C.; Dong, X. Application status and prospect of aerial remote sensing technology for geohazards. Acta Geod. Cartogr. Sin. 2022, 51, 2020–2033. [Google Scholar]
- Feng, J.; Zhou, A.; Yu, J.; Tang, X.; Zheng, J.; Chen, X.; You, S. A Comparative Study on Plum-Rain-Triggered Landslide Susceptibility Assessment Models in West Zheiiang Province. Earth Sci. Rev. 2016, 41, 403–415. [Google Scholar]
- Sun, C.; Ma, R.; Shang, H.; Xie, W.; Li, Y.; Liu, Y.; Wang, B.; Wang, S. Landslide susceptibility assessment in Xining based on landslide classification. Hydrogeol. Eng. Geol. 2020, 47, 173–181. [Google Scholar]
- Xiong, J.; Sun, M.; Zhang, H.; Cheng, W.; Yang, Y.; Sun, M.; Cao, Y.; Wang, J. Application of the Levenburg–Marquardt back propagation neural network approach for landslide risk assessments. Nat. Hazards Earth Syst. Sci. 2019, 19, 629–653. [Google Scholar] [CrossRef]
- Gao, H.; Fam, P.S.; Tay, L.T.; Low, H.C. Three oversampling methods applied in a comparative landslide spatial research in Penang Island, Malaysia. SN Appl. Sci. 2020, 2, 1512. [Google Scholar] [CrossRef]
- Shao, X.; Ma, S.; Xu, C.; Zhou, Q. Effects of sampling intensity and non-slide/slide sample ratio on the occurrence probability of coseismic landslides. Geomorphology 2020, 363, 107222. [Google Scholar] [CrossRef]
- Chang, Z.; Du, Z.; Zhang, F.; Huang, F.; Chen, J.; Li, W.; Guo, Z. Landslide susceptibility prediction based on remote sensing images and GIS: Comparisons of supervised and unsupervised machine learning models. Remote Sens. 2020, 12, 502. [Google Scholar] [CrossRef]
- Sifa, S.F.; Mahmud, T.; Tarin, M.A.; Haque, D.M.E. Event-based landslide susceptibility mapping using weights of evidence (WoE) and modified frequency ratio (MFR) model: A case study of Rangamati district in Bangladesh. Geol. Ecol. Landsc. 2020, 4, 222–235. [Google Scholar] [CrossRef]
- Mahmuda, K.; Shakhawat, H.A.T.M.; Md, S.H.; Md, M.; Zia, A.; Rubayet, R.K. Landslide Susceptibility Mapping Using Weighted-Overlay Approach in Rangamati, Bangladesh. Earth Syst. Environ. 2022, 7, 223–235. [Google Scholar]
- Wang, Y.; Fang, Z.; Hong, H. Comparison of convolutional neural networks for landslide susceptibility mapping in Yanshan County, China. Sci. Total Environ. 2019, 666, 975–993. [Google Scholar] [CrossRef] [PubMed]
- Xing, Y.; Huang, S.; Yue, J.; Chen, Y.; Xie, W.; Wang, P.; Xiang, Y.; Peng, Y. Patterns of influence of different landslide boundaries and their spatial shapes on the uncertainty of landslide susceptibility prediction. Nat. Hazards 2023, 118, 709–727. [Google Scholar] [CrossRef]
- Zhu, A.X.; Miao, Y.; Yang, L.; Bai, S.; Liu, J.; Hong, H. Comparison of the presence-only method and presence-absence method in landslide susceptibility mapping. Catena 2018, 171, 222–233. [Google Scholar] [CrossRef]
- Kalantar, B.; Pradhan, B.; Naghibi, S.A.; Motevalli, A.; Mansor, S. Assessment of the effects of training data selection on the landslide susceptibility mapping: A comparison between support vector machine (SVM), logistic regression (LR) and artificial neural networks (ANN). Geomat. Nat. Hazards Risk 2018, 9, 49–69. [Google Scholar] [CrossRef]
- Choi, J.; Oh, H.J.; Lee, H.J.; Lee, C.; Lee, S. Combining landslide susceptibility maps obtained from frequency ratio, logistic regression, and artificial neural network models using ASTER images and GIS. Eng. Geol. 2012, 124, 12–23. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Sahin, E.K.; Colkesen, I. Landslide susceptibility mapping using GIS-based multi-criteria decision analysis, support vector machines, and logistic regression. Landslides 2014, 11, 425–439. [Google Scholar] [CrossRef]
- Zhou, X. Recognition and Dynamic Susceptibility Assessment of Landslides Based on Multi-Source Data. Ph.D. Thesis, East China Institute of Technology, Nanchang, China, 2022. [Google Scholar]
- Liu, L.L.; Li, Z.Y.; Xiao, T.; Yang, C. A frequency ratio–based sampling strategy for landslide susceptibility assessment. Bull. Eng. Geol. Environ. 2022, 81, 360. [Google Scholar] [CrossRef]
- Deng, N.; Shi, H.; Wen, Q.; Li, Y.; Cao, X. Collapse Susceptibility Evaluation of Random Forest Model Supported by Information Value Model. Sci. Technol. Eng. 2021, 21, 2210–2217. [Google Scholar]
- Chen, F.; Cai, C.; Li, X.; Sun, T.; Qian, K. Evaluation of landslide susceptibility based on information volume and neural network model. Chin. J. Rock Mech. Eng. 2020, 39, 2859–2870. [Google Scholar]
- Rabby, Y.W.; Li, Y.; Hilafu, H. An objective absence data sampling method for landslide susceptibility mapping. Sci. Rep. 2023, 13, 1740. [Google Scholar] [CrossRef]
- Li, M.; Wang, H.; Chen, J.; Zheng, K. Assessing landslide susceptibility based on the random forest model and multi-source heterogeneous data. Ecol. Indic. 2024, 158, 111600. [Google Scholar]
- Zhao, P.; Masoumi, Z.; Kalantari, M.; Aflaki, M.; Mansourian, A. A GIS-based landslide susceptibility mapping and variable importance analysis using artificial intelligent training-based methods. Remote Sens. 2022, 14, 211. [Google Scholar] [CrossRef]
- Wang, Y.; Feng, L.; Li, S.; Ren, F.; Du, Q. A hybrid model considering spatial heterogeneity for landslide susceptibility mapping in Zhejiang Province, China. Catena 2020, 188, 104425. [Google Scholar] [CrossRef]
- Achour, Y.; Pourghasemi, H.R. How do machine learning techniques help in increasing accuracy of landslide susceptibility maps? Geosci. Front. 2020, 11, 871–883. [Google Scholar] [CrossRef]
- Ado, M.; Amitab, K.; Maji, A.K.; Jasińska, E.; Gono, R.; Leonowicz, Z.; Jasiński, M. Landslide susceptibility mapping using machine learning: A literature survey. Remote Sens. 2022, 14, 3029. [Google Scholar] [CrossRef]
- Yuan, X.; Liu, C.; Nie, R.; Yang, Z.; Li, W.; Dai, X.; Cheng, J.; Zhang, J.; Ma, L.; Fu, X.; et al. A Comparative Analysis of Certainty Factor-Based Machine Learning Methods for Collapse and Landslide Susceptibility Mapping in Wenchuan County, China. Remote Sens. 2022, 14, 3259. [Google Scholar] [CrossRef]
- Li, Y.; Mei, H.; Ren, X.; Hu, X.; Li, M. Geological Disaster Susceptibility Evaluation Based on Certainty Factor and Support Vector Machine. J. Geo-Inf. Sci. 2018, 20, 1699–1709. [Google Scholar]
- Luo, L.; Pei, X.; Huang, R.; Pei, Z.; Zhu, L. Landslide susceptibility assessment in jiuzhaigou scenic area with gis based on certainty factor and logistic regression model. J. Eng. Geol. 2021, 29, 526–535. [Google Scholar]
- Sun, D.; Shi, S.; Wen, H.; Xu, J.; Zhou, X.; Wu, J. A hybrid optimization method of factor screening predicated on GeoDetector and Random Forest for Landslide Susceptibility Mapping. Geomorphology 2021, 379, 107623. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, W.; Zhang, Z.; Xu, Q.; Li, W. Risk factor detection and landslide susceptibility mapping using Geo-Detector and Random Forest Models: The 2018 Hokkaido eastern Iburi earthquake. Remote Sens. 2021, 13, 1157. [Google Scholar] [CrossRef]
- Kavoura, K.; Sabatakakis, N. Investigating landslide susceptibility procedures in Greece. Landslides 2019, 17, 127–145. [Google Scholar] [CrossRef]
- Zheng, Y.; Chen, J.; Wang, C.; Cheng, T. Application of certainty factor and random forests model in landslide susceptibility evaluation in Mangshi City, Yunnan Province. Bull. Geol. Sci. Technol. 2020, 39, 131–144. [Google Scholar]
- Cui, Y.; Deng, N.; Cao, X.; Ding, Y.; Xing, C. Geological Disaster Risk Assessment Based on Ensemble Learning Algorithm. Water Power 2020, 46, 36–41. [Google Scholar]
- Fang, Z.; Wang, Y.; Peng, L.; Hong, H. A comparative study of heterogeneous ensemble-learning techniques for landslide susceptibility mapping. Int. J. Geogr. Inf. Sci. 2021, 35, 321–347. [Google Scholar] [CrossRef]
- Shi, Q.; Li, Y.; Pei, L.; Han, X. Research and Implementation of Text Resource Classification Method of Thematic Database Based on Blending Ensemble Learning. Inf. Stud. Theory Appl. 2022, 45, 169–175. [Google Scholar]
- Bui, D.T.; Ho, T.C.; Pradhan, B.; Pham, B.T.; Nhu, V.H.; Revhaug, I. GIS-based modeling of rainfall-induced landslides using data mining-based functional trees classifier with AdaBoost, Bagging, and MultiBoost ensemble frameworks. Environ. Earth Sci. 2016, 75, 1101. [Google Scholar]
- Jiang, B.; Li, X.; Luo, H.; Song, Y. A comparative analysis of heterogeneous ensemble learning methods for landslide susceptibility assessment. China Civ. Eng. J. 2023, 56, 170–179. [Google Scholar]
- Dou, J.; Yunus, A.P.; Merghadi, A.; Shirzadi, A.; Nguyen, H.; Hussain, Y.; Avtar, R.; Chen, Y.; Pham, B.T.; Yamagishi, H. Different sampling strategies for predicting landslide susceptibilities are deemed less consequential with deep learning. Sci. Total Environ. 2020, 720, 137320. [Google Scholar] [CrossRef]
- Prakash, N.; Manconi, A.; Loew, S. Mapping landslides on EO data: Performance of deep learning models vs. traditional machine learning models. Remote Sens. 2020, 12, 346. [Google Scholar] [CrossRef]
- Ullah, K.; Wang, Y.; Fang, Z.; Wang, L.; Rahman, M. Multi-hazard susceptibility mapping based on Convolutional Neural Networks. Geosci. Front. 2022, 13, 101425. [Google Scholar] [CrossRef]
- Ruggieri, S.; Cardellicchio, A.; Leggieri, V.; Uva, G. Machine-learning based vulnerability analysis of existing buildings. Autom. Constr. 2021, 132, 103936. [Google Scholar] [CrossRef]
- Cardellicchio, A.; Ruggieri, S.; Nettis, A.; Renò, V.; Uva, G. Physical interpretation of machine learning-based recognition of defects for the risk management of existing bridge heritage. Eng. Fail. Anal. 2023, 149, 107237. [Google Scholar] [CrossRef]
- Habumugisha, J.M.; Chen, N.; Rahman, M.; Islam, M.M.; Ahmad, H.; Elbeltagi, A.; Sharma, G.; Liza, S.N.; Dewan, A. Landslide susceptibility mapping with deep learning algorithms. Sustainability 2022, 14, 1734. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, L.; Luo, H.; He, J.; Cheung, R.W.M. AI-powered landslide susceptibility assessment in Hong Kong. Eng. Geol. 2021, 288, 106103. [Google Scholar] [CrossRef]
- Wang, M. Study on the Evaluation Methodology of Landslide Susceptibility Based on Multi-Scale Analysis. Master’s Thesis, Southwest University of Science and Technology, Mianyang, China, 2023. [Google Scholar]
- Caruana, R.; Lou, Y.; Gehrke, J.; Koch, P.; Sturm, M.; Elhadad, N. Intelligible Models for HealthCare: Predicting Pneumonia Risk and Hospital 30-day Readmission. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015. [Google Scholar]
- Zhang, J.; Ma, X.; Zhang, J.; Sun, D.; Zhou, X.; Mi, C.; Wen, H. Insights into geospatial heterogeneity of landslide susceptibility based on the SHAP-XGBoost model. J. Environ. Manag. 2023, 332, 117357. [Google Scholar] [CrossRef]
- Sebastian, L.; Stephan, W.; Alexander, B.; Grégoire, M.; Wojciech, S.; Klaus-Robert, M. Unmasking Clever Hans predictors and assessing what machines really learn. Nat. Commun. 2019, 10, 1096. [Google Scholar]
- Dong, A.; Dou, J.; Fu, Y.; Zhang, R.; Xing, K. Unraveling the Evolution of Landslide Susceptibility: A Systematic Review of 30-Years of Strategic Themes and Trends. Geocarto Int. 2023, 38, 2256308. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems 30, Proceedings of the NIPS 2017, Long Beach, CA, USA, 4–9 December 2017; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Mangalathu, S.; Hwang, S.H.; Jeon, J.S. Failure mode and effects analysis of RC members based on machine-learning-based SHapley Additive exPlanations (SHAP) approach. Eng. Struct. 2020, 219, 110927. [Google Scholar] [CrossRef]
- Zhou, X. Study on Machine Learning Optimization Model and Interpretability of Landslide Susceptibility. Master’s Thesis, Chongqing University, Chongqing, China, 2022. [Google Scholar]
- Sun, H.; Li, W.; Gao, J. Influence of spatial heterogeneity on landslide susceptibility in the transboundary area of the Himalayas. Geomorphology 2023, 433, 108723. [Google Scholar] [CrossRef]
- Tyler, R.; Eitan, S.; Ben, M.; Tim, C. Prolonged influence of urbanization on landslide susceptibility. Landslides 2023, 20, 1433–1447. [Google Scholar]
- Hu, Q.; Zhou, Y.; Wang, S.; Wang, F.; Wang, H. Improving the accuracy of landslide detection in “off-site” area by machine learning model portability comparison: A case study of Jiuzhaigou earthquake, China. Remote Sens. 2019, 11, 2530. [Google Scholar] [CrossRef]
- Yang, Y.; Yang, J.; Xu, C.; Xu, C.; Song, C. Local-scale landslide susceptibility mapping using the B-GeoSVC model. Landslides 2019, 16, 1301–1312. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, Q.; Liu, Y. Mapping landslide susceptibility using machine learning algorithms and GIS: A case study in Shexian County, Anhui Province, China. Symmetry 2020, 12, 1954. [Google Scholar] [CrossRef]
- Rolain, S.; Alvioli, M.; Nguyen, Q.D.; Nguyen, T.L.; Jacobs, L.; Kervyn, M. Influence of landslide inventory timespan and data selection on slope unit-based susceptibility models. Nat. Hazards 2022, 118, 2227–2244. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, S.; Wang, L.; Samui, P.; Chwała, M.; He, Y. Landslide Susceptibility Research Combining Qualitative Analysis and Quantitative Evaluation: A Case Study of Yunyang County in Chongqing, China. Forests 2022, 13, 1055. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, S.; Liu, J.; Wang, Y.; Ma, X.; Jiang, T.; He, X.; Han, Z. A Combination of Deep Autoencoder and Multi-Scale Residual Network for Landslide Susceptibility Evaluation. Remote Sens. 2023, 15, 653. [Google Scholar] [CrossRef]
- Su, Y.; Chen, Y.; Lai, X.; Huang, S.; Lin, C.; Xie, X. Feature adaptation for landslide susceptibility assessment in “no sample” areas. Gondwana Res. 2024, 131, 1–17. [Google Scholar] [CrossRef]
- Huang, F.; Zhang, J.; Zhou, C.; Wang, Y.; Huang, J.; Zhu, L. A deep learning algorithm using a fully connected sparse autoencoder neural network for landslide susceptibility prediction. Landslides 2020, 17, 217–229. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Author | Method |
|---|---|---|
| 2022 | Peng [19] | raster units |
| 2003 | Li et al. [21] | raster units |
| 2023 | Chang et al. [22] | slope units + MSS |
| 2017 | Alvioli [23] | slope units + r.slopeunits |
| 2021 | Huang et al. [24] | slope units + MSS |
| 2015 | Mergili et al. [25] | slope units + r.slopeunits |
| Data Type | Evaluation Factor | Effects on Landslides |
|---|---|---|
| topography | altitude | Increasing elevation significantly impacts slope stability, leading to higher potential energy and increased landslide risk [31]. |
| slope | Steep slopes are more prone to destabilization and landslides, usually happening between 10° and 45°. | |
| exposure | Different slope orientations receive varying levels of solar radiation and weathering, affecting slope stability accordingly. | |
| terrain relief | The greater the terrain’s undulations, the more concentrated the stress is at the base and valley floor of slopes in that area. This leads to lower safety coefficients for slopes, making landslides more likely to occur [31]. | |
| surface curvature | Research shows that landslides are more likely to occur when the curvature is greater than 0, indicating a convex slope shape [31]. | |
| meteorology and hydrology | rainfall | Rainfall catalyzes the occurrence of landslide geological disasters, leading to slope instability and landslide formation [32]. |
| distance to water bodies | Increased soil moisture in areas traversed by water bodies leads to the softening of rock formations, reducing the stability of both the soil and rock. This greatly increases the likelihood of landslides. | |
| geology | distance to faults | The formation of faults disrupts the original shapes of rock and soil formations. Structural effects directly control the occurrence of geological disasters at both individual and regional levels. |
| lithology | Different types of rock and soil formations have varying degrees of influence on landslide development. They not only affect the extent of landslide development but also determine the type and scale of landslides. | |
| human activities | distance to roads | Existing research indicates that landslides are more concentrated along the sides of roads, and the density of landslide distribution decreases as the distance from the road increases [8]. |
| vegetation cover | Normalized Difference Vegetation Index (NDVI) | Vegetation cover has complex effects on slope stability. |
| Year | Author | Title |
|---|---|---|
| 2024 | Chen et al. [37] | A study on the landslide susceptibility of LightGBM-SHAP, based on different factor screening methods. |
| 2023 | Sun Deliang et al. [38] | Evaluation of landslide susceptibility in gentle hill-valley areas, based on an interpretable random forest-recursive feature elimination model |
| 2023 | Zhang Kai [39] | Landslide susceptibility assessment, based on an optimal computing cell and ulti-model coupling |
| Year | Author | Recommendation Strategy |
|---|---|---|
| 2018 | Kalantar et al. [95] | randomly generated |
| 2012 | Choi et al. [96] | zero slope |
| 2014 | Kavzoglu et al. [97] | low-slope areas |
| 2022 | Liu et al. [99] | frequency ratio method |
| 2023 | Guo et al. [14] | frequency ratio method |
| 2021 | Deng et al. [100] | information value method |
| 2020 | Chen et al. [101] | information value method |
| 2023 | Rabby et al. [102] | Mahalanobis distance method |
| Model | Accuracy | Kappa Coefficient | Specificity | Sensitivity | AUC |
|---|---|---|---|---|---|
| RF | 0.948 | 0.887 | 0.956 | 0.927 | 0.985 |
| SVM | 0.942 | 0.871 | 0.983 | 0.868 | 0.984 |
| BPNN | 0.930 | 0.846 | 0.939 | 0.907 | 0.973 |
| Stacking ensemble | 0.958 | 0.908 | 0.982 | 0.932 | 0.988 |
| Blending ensemble | 0.947 | 0.878 | 0.956 | 0.910 | 0.980 |
| Weighted average | 0.955 | 0.901 | 0.971 | 0.924 | 0.987 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Z.; Liu, G.; Song, Z.; Sun, K.; Li, M.; Chen, Y.; Zhao, X.; Zhang, W. Advancements in Technologies and Methodologies of Machine Learning in Landslide Susceptibility Research: Current Trends and Future Directions. Appl. Sci. 2024, 14, 9639. https://doi.org/10.3390/app14219639
Lu Z, Liu G, Song Z, Sun K, Li M, Chen Y, Zhao X, Zhang W. Advancements in Technologies and Methodologies of Machine Learning in Landslide Susceptibility Research: Current Trends and Future Directions. Applied Sciences. 2024; 14(21):9639. https://doi.org/10.3390/app14219639
Chicago/Turabian StyleLu, Zongyue, Genyuan Liu, Zhihong Song, Kang Sun, Ming Li, Yansi Chen, Xidong Zhao, and Wei Zhang. 2024. "Advancements in Technologies and Methodologies of Machine Learning in Landslide Susceptibility Research: Current Trends and Future Directions" Applied Sciences 14, no. 21: 9639. https://doi.org/10.3390/app14219639
APA StyleLu, Z., Liu, G., Song, Z., Sun, K., Li, M., Chen, Y., Zhao, X., & Zhang, W. (2024). Advancements in Technologies and Methodologies of Machine Learning in Landslide Susceptibility Research: Current Trends and Future Directions. Applied Sciences, 14(21), 9639. https://doi.org/10.3390/app14219639