
Comparative Analysis of Chatbots Using Large Language Models for Web Development Tasks


Abstract
1. Introduction
1.1. Research Question
1.2. Objectives
- Comparing Accuracy: assess the correctness and precision of the code generated by each chatbot.
- Evaluating Usability: determine the user-friendliness and ease of understanding the outputs provided by the chatbots.
- Examining Creativity: evaluate the ability of chatbots to incorporate creative elements in the design and functionality of the web components.
- Integrating Databases: analyze the chatbots’ capability to integrate with databases, ensuring they can effectively connect, query, and manipulate data within a database system.
- Understanding Context: assess the chatbots’ proficiency in understanding and utilizing previous conversational context to generate relevant and coherent responses, enhancing the continuity and relevance of the interaction.
2. Related Work
3. Materials and Methods
- Automated Code Creation—chatbots can efficiently generate code for various web development tasks, including the creation of well-structured HTML, CSS, JavaScript functions, and database queries, thereby conserving valuable development time.
- Code Suggestions—these tools provide context-aware code completion suggestions that align with the coding style being used, enhancing overall productivity.
- Cross-Language Code Transformation—when dealing with multiple programming languages or frameworks, chatbots can seamlessly convert code snippets from one language or framework to another, facilitating easier integration and maintenance.
- Code Clarification—chatbots aid in the comprehension of complex code by offering detailed explanations or answering specific queries related to the code.
- Code Optimization—by proposing improvements and refactorings, chatbots assist in enhancing the efficiency and readability of code with minimal effort from the developer.
- Code Evaluation—these tools can identify issues and security vulnerabilities within the code, ensuring that it remains both efficient and secure.
- Bug Identification and Resolution—chatbots are capable of pinpointing and resolving bugs that may cause issues within the code, thereby streamlining the debugging process.
- Testing Assistance—chatbots provide support in writing unit tests, generating comprehensive test cases, and selecting suitable testing frameworks or libraries, thus enhancing the testing phase.
- System Design Advice—these tools offer valuable insights and recommendations for designing systems using specific technology stacks, or they can compare different architectural designs to help select the optimal approach.
- Mock Data Creation—chatbots can quickly generate mock data for various domains and formats, facilitating development and testing processes.
- Documentation Support—chatbots assist in writing detailed comments and documentation for code, ensuring clarity and maintainability.
- Educational Support—they aid in learning new programming languages, understanding best practices, and improving website performance, serving as a valuable educational resource.
- Command Line and Version Control Assistance—chatbots can assist with shell commands and version control operations using Git, simplifying these tasks.
- Content Generation—these tools can create tailored content for various purposes, addressing specific needs.
- Regular Expression Handling—chatbots understand complex regular expressions and generate new ones that match specific text patterns, simplifying tasks that involve text processing.
- Assess the ability of chatbots to handle complex, multi-step tasks in web development.
- Evaluate the user experience, including the clarity, usability, and functionality of the generated code.
- Provide comparative insights into the performance of conversational chatbots versus programming assistants.
3.1. Testers
3.2. Chatbots and Evaluation Tools
- General-purpose language models: these chatbots are capable of a wide range of tasks, including answering questions, generating text, programming code, and providing conversational responses.
- ChatGPT 3.5: Developed by OpenAI, ChatGPT 3.5 is a versatile AI model designed for various conversational tasks. It leverages the GPT-3.5 architecture, known for its ability to generate coherent and contextually appropriate responses across numerous topics. It is widely used for general-purpose dialogue, including generating code and assisting with programming-related queries [47].
- Copilot: Microsoft’s Copilot is a conversational AI designed to assist users by providing information, generating content, and performing web searches. It differs from ChatGPT 3.5 in that it can perform real-time web searches to provide up-to-date information. In this study, we used Microsoft’s Copilot in creative mode, which employed an adapted GPT-4 model at the time of testing (April 2024) [48].
- Gemini: This chatbot is part of Google’s AI portfolio, leveraging the latest advancements in their language model technology. Gemini is designed to assist with a broad range of tasks, from answering general questions to generating complex code snippets. It integrates Google’s extensive search and information retrieval capabilities to enhance its response accuracy and relevance [49].
- 2.
- Code-specific language models: these chatbots are designed specifically for generating code snippets and assisting with programming tasks.
- TabNine AI: An AI-powered code completion tool that uses deep learning models to provide intelligent code suggestions. TabNine supports a wide range of programming languages and is integrated into various IDEs. It focuses on enhancing developer productivity by predicting and completing code based on the context provided by the user [50].
- Blackbox AI: A specialized code generation tool that utilizes machine learning models to assist developers in writing code. Blackbox AI is designed to understand coding patterns and provide relevant code snippets, debugging assistance, and optimization suggestions. It aims to streamline the coding process and reduce the time required to write functional code [51].
3.3. Procedure
- Create a basic HTML structure with a navigation menu, header, body, footer, and short content.
- Modify the basic structure to include sections describing a company specializing in machine parts (About Us, Services, Products, Contact).
- Design the appearance using CSS, focusing on responsiveness and UI design tailored to the engineering industry.
- Create an HTML form on a new subpage for adding machine products, including fields for product name, description, image, and price.
- Develop PHP code to save form data to a MySQL database table upon submission.
- Secure the PHP form against invalid data, ensuring fields are not empty and images are included.
- Create a database table for storing the form data using an SQL query.
- Modify the code snippet to display individual products in the “Products” section based on database entries.
- Implement CSS styling for the “Products” section to display products in rows of four, ensuring responsiveness and good UI design.
3.4. Data Collection
- Code Functionality Testing: The code generated by the chatbot was executed to verify its functionality. This ensured that the code was not only syntactically correct but also operational in practice [53].
- Usability and Appearance Assessment: The usability and visual appeal of the generated web pages were evaluated. Testers assessed factors like design responsiveness, clarity, and overall user-friendliness [57].
3.5. Evaluation Criteria
- HTML and CSS Syntax Rules: Evaluated using the Markup/CSS Validation Service. The number of syntax errors was scored from 1 to 5.
- Understanding of Prompts: assessed whether the chatbot fully understood and completed the prompt, scored from 1 to 5.
- Conversational Memory: evaluated the chatbot’s ability to maintain context and build on previous outputs, scored from 1 to 3.
- Original and Diverse Content: assessed the creativity and diversity of the content, including grammar and sentence composition, scored from 1 to 5.
- Appearance and User-Friendliness: evaluated the design’s responsiveness, clarity, and visual appeal, scored from 1 to 5.
- Functioning of PHP Form and Database Linking: checked if the PHP form correctly connected to the database and displayed data on the page, scored from 1 to 5.
- SQL Query Correctness: assessed using the SQL Validator, scored from 1 to 3.
4. Results
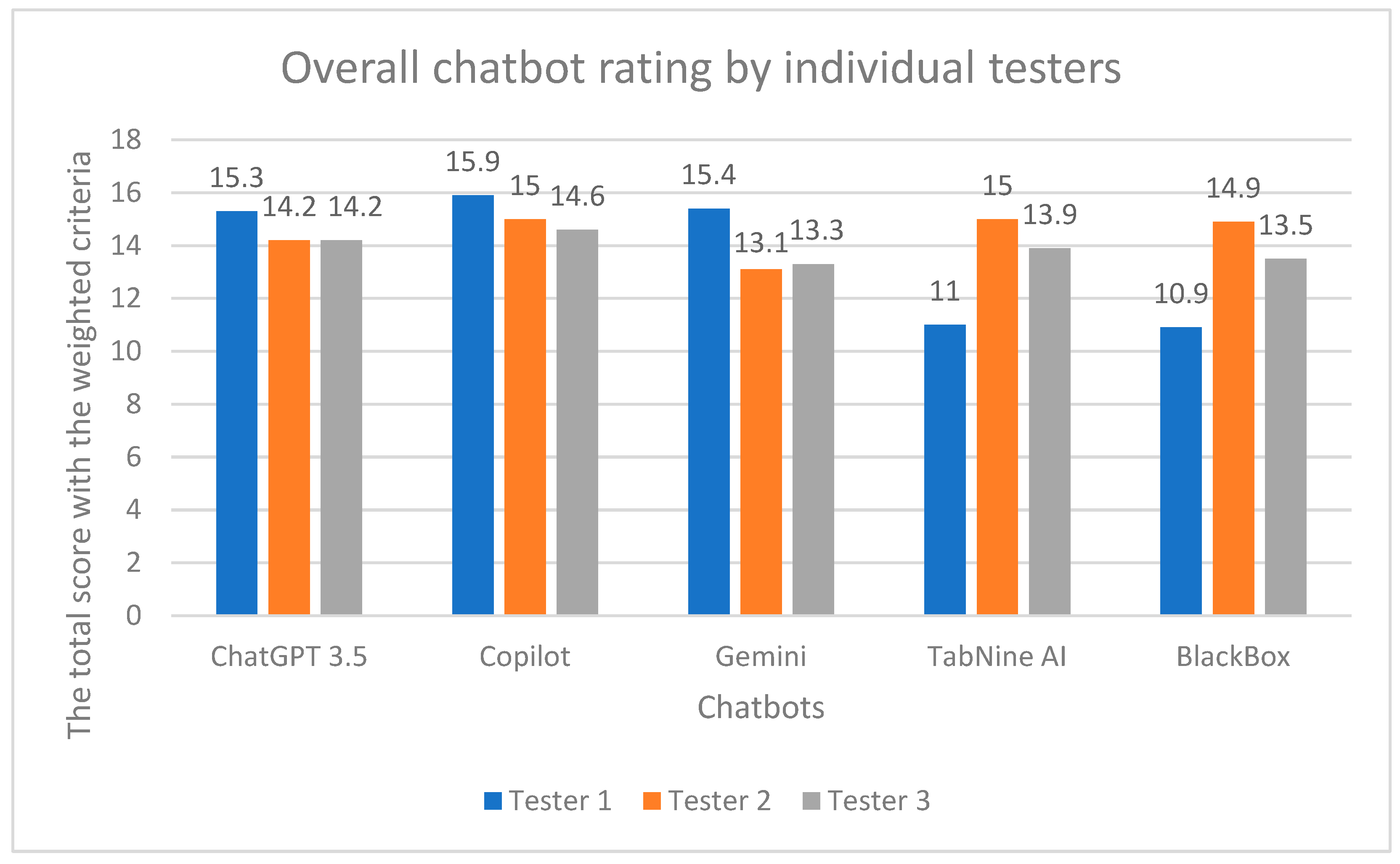
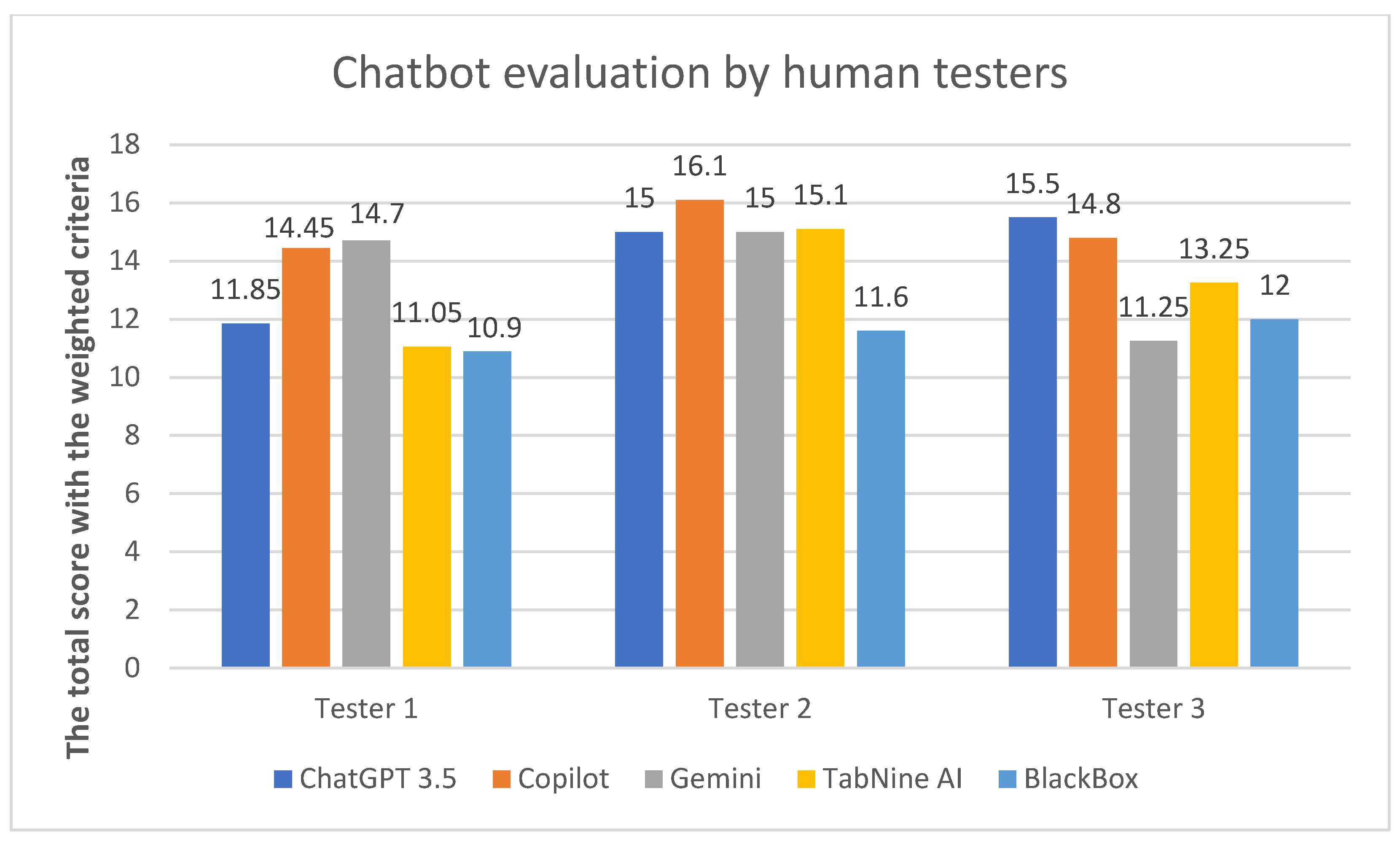
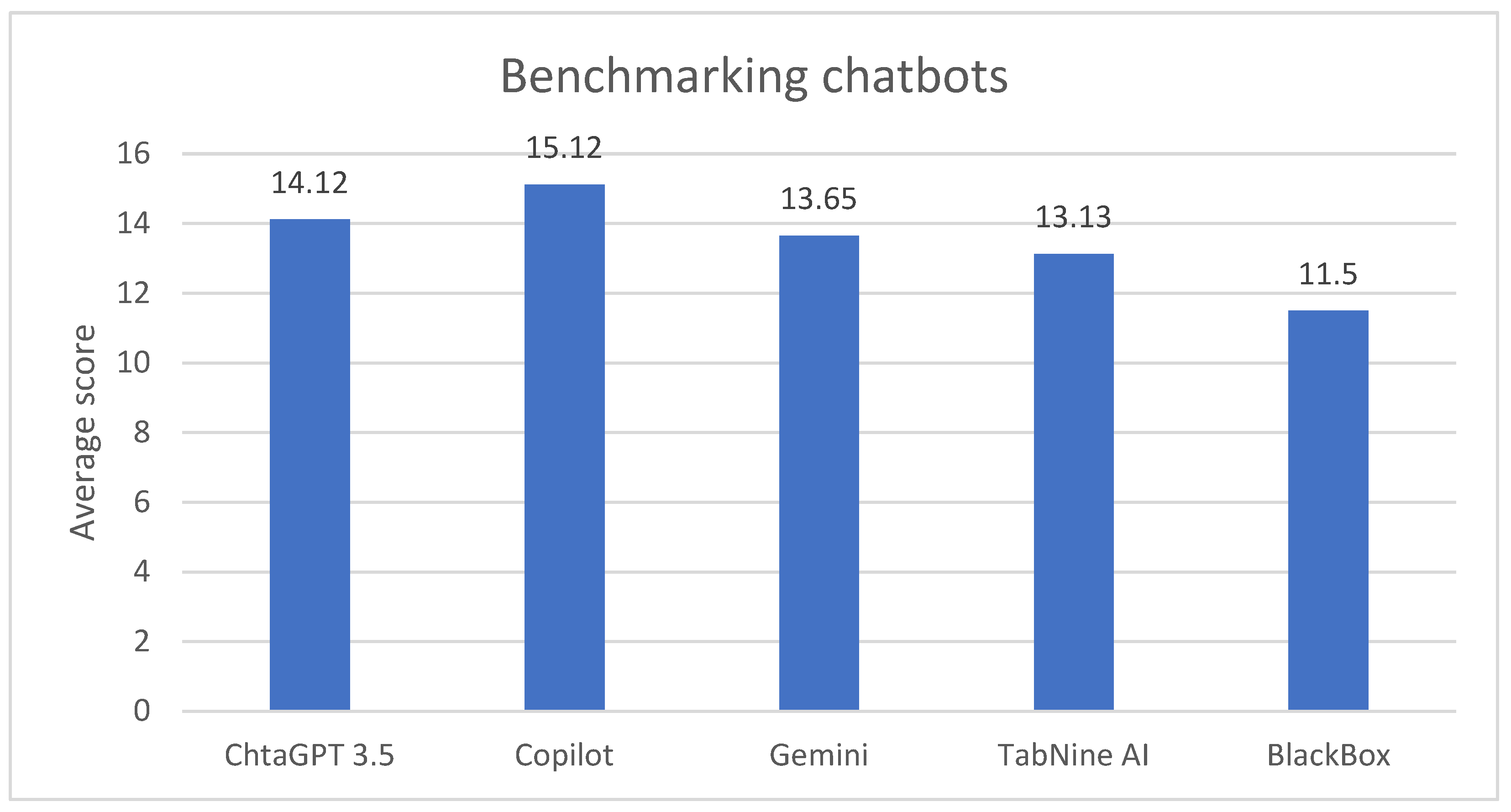
4.1. Quantitative Results
4.2. Qualitative Feedback
- ChatGPT 3.5: Highlighted for its diverse and original content and solid HTML/CSS structure. It faced challenges in maintaining conversational memory.
- Copilot: Praised for its flawless HTML and CSS syntax, excellent appearance, and user-friendliness. However, it received lower scores for original and varied content.
- Gemini: noted for creative content but occasionally faltered in syntax and structural aspects.
- TabNine AI: commended for structural correctness but criticized for issues with appearance and user-friendliness.
- BlackBox: struggled with PHP forms and had notable syntax errors, leading to the lowest overall score.
Comparison
- HTML and CSS Syntax Rules: Copilot and ChatGPT 3.5 excelled, consistently achieving high scores across all testers. BlackBox had the most difficulty, with frequent errors noted by evaluators.
- Understanding of Prompts: all chatbots showed strong performance, but ChatGPT 3.5 and Copilot stood out for their ability to understand and execute tasks as expected.
- Conversational Memory: Copilot was the most successful in maintaining context across tasks, while BlackBox showed significant gaps, leading to lower scores in this category.
- Original and Diverse Content: ChatGPT 3.5 led in this area, followed closely by Gemini. Copilot and TabNine AI showed room for improvement.
- Appearance and User-Friendliness: Copilot outperformed others, creating visually appealing and user-friendly outputs. Other chatbots, including TabNine AI, had issues with responsiveness and design.
- Functioning of PHP Form and Database Linking: Copilot excelled, producing fully functional PHP forms that integrated with databases effectively. BlackBox failed to meet requirements consistently.
- SQL Query Correctness: all chatbots met the criteria and received full points for creating correct SQL queries.
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural Language Processing: State of the Art, Current Trends and Challenges. Multimed. Tools Appl. 2023, 82, 3713–3744. [Google Scholar] [CrossRef] [PubMed]
- Ray, P.P. ChatGPT: A Comprehensive Review on Background, Applications, Key Challenges, Bias, Ethics, Limitations and Future Scope. Internet Things Cyber Phys. Syst. 2023, 3, 121–154. [Google Scholar] [CrossRef]
- Mohammad, A.F.; Clark, B.; Hegde, R. Large Language Model (LLM) & GPT, A Monolithic Study in Generative AI. In Proceedings of the 2023 Congress in Computer Science, Computer Engineering, and Applied Computing, CSCE 2023, Las Vegas, NV, USA, 24–27 July 2023; pp. 383–388. [Google Scholar] [CrossRef]
- Liang, Y.-C.; Ma, S.-P.; Lin, C.-Y. Chatbotification for Web Information Systems: A Pattern-Based Approach. In Proceedings of the 2024 IEEE 48th Annual Computers, Software, and Applications Conference (COMPSAC), Osaka, Japan, 2–4 July 2024; pp. 2290–2295. [Google Scholar] [CrossRef]
- Ross, S.I.; Martinez, F.; Houde, S.; Muller, M.; Weisz, J.D. The Programmer’s Assistant: Conversational Interaction with a Large Language Model for Software Development. In Proceedings of the International Conference on Intelligent User Interfaces, Sydney, Australia, 27–31 March 2023; pp. 491–514. [Google Scholar] [CrossRef]
- Belzner, L.; Gabor, T.; Wirsing, M. Large Language Model Assisted Software Engineering: Prospects, Challenges, and a Case Study. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2024; Volume 14380, pp. 355–374. [Google Scholar] [CrossRef]
- Finnie-Ansley, J.; Denny, P.; Becker, B.A.; Luxton-Reilly, A.; Prather, J. The Robots Are Coming: Exploring the Implications of OpenAI Codex on Introductory Programming. ACM Int. Conf. Proc. Ser. 2022, 22, 10–19. [Google Scholar] [CrossRef]
- Liu, L.; Duffy, V.G. Exploring the Future Development of Artificial Intelligence (AI) Applications in Chatbots: A Bibliometric Analysis. Int. J. Soc. Robot 2023, 15, 703–716. [Google Scholar] [CrossRef]
- Xue, J.; Zhang, B.; Zhao, Y.; Zhang, Q.; Zheng, C.; Jiang, J.; Li, H.; Liu, N.; Li, Z.; Fu, W.; et al. Evaluation of the Current State of Chatbots for Digital Health: Scoping Review. J. Med. Internet Res. 2023, 25, e47217. [Google Scholar] [CrossRef]
- Bellini, F.; Dima, A.M.; Braccini, A.M.; Agrifoglio, R.; Bălan, C. Chatbots and Voice Assistants: Digital Transformers of the Company–Customer Interface—A Systematic Review of the Business Research Literature. J. Theor. Appl. Electron. Commer. Res. 2023, 18, 995–1019. [Google Scholar] [CrossRef]
- Raiaan, M.A.K.; Mukta, M.S.H.; Fatema, K.; Fahad, N.M.; Sakib, S.; Mim, M.M.J.; Ahmad, J.; Ali, M.E.; Azam, S. A Review on Large Language Models: Architectures, Applications, Taxonomies, Open Issues and Challenges. IEEE Access 2024, 12, 26839–26874. [Google Scholar] [CrossRef]
- Hendrycks, D.; Burns, C.; Basart, S.; Zou, A.; Mazeika, M.; Song, D.; Steinhardt, J. Measuring Massive Multitask Language Understanding. In Proceedings of the ICLR 2021—9th International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Sakaguchi, K.; Bras, R.L.; Bhagavatula, C.; Choi, Y. WinoGrande. Commun. ACM 2021, 64, 99–106. [Google Scholar] [CrossRef]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pinto, H.P.O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating Large Language Models Trained on Code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Shi, F.; Suzgun, M.; Freitag, M.; Wang, X.; Srivats, S.; Vosoughi, S.; Chung, H.W.; Tay, Y.; Ruder, S.; Zhou, D.; et al. Language Models Are Multilingual Chain-of-Thought Reasoners. In Proceedings of the 11th International Conference on Learning Representations (ICLR 2023), Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Scoccia, G.L. Exploring Early Adopters’ Perceptions of ChatGPT as a Code Generation Tool. In Proceedings of the 2023 38th IEEE/ACM International Conference on Automated Software Engineering Workshops, ASEW 2023, Luxembourg, 11–15 September 2023; pp. 88–93. [Google Scholar] [CrossRef]
- Vaithilingam, P.; Zhang, T.; Glassman, E.L. Expectation vs. Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models. In Proceedings of the Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 28 April 2022. [Google Scholar] [CrossRef]
- Idrisov, B.; Schlippe, T. Program Code Generation with Generative AIs. Algorithms 2024, 17, 62. [Google Scholar] [CrossRef]
- Jamdade, M.; Liu, Y. A Pilot Study on Secure Code Generation with ChatGPT for Web Applications. In Proceedings of the 2024 ACM Southeast Conference, ACMSE 2024, Marietta, GA, USA, 18–20 April 2024; pp. 229–234. [Google Scholar] [CrossRef]
- Guo, M. Java Web Programming with ChatGPT. In Proceedings of the 2024 5th International Conference on Mechatronics Technology and Intelligent Manufacturing, ICMTIM 2024, Nanjing, China, 26–28 April 2024; pp. 834–838. [Google Scholar] [CrossRef]
- Yang, Z.; Xu, T. Revolutionizing Personalized Web Presence: AI-Powered Automated Website Generation for Streamlined Individual Expression and Accessibility. CS IT Conf. Proc. 2023, 13, 11–19. [Google Scholar] [CrossRef]
- Yetiştiren, B.; Özsoy, I.; Ayerdem, M.; Tüzün, E. Evaluating the Code Quality of AI-Assisted Code Generation Tools: An Empirical Study on GitHub Copilot, Amazon CodeWhisperer, and ChatGPT. arXiv 2023, arXiv:2304.10778. [Google Scholar]
- Su, H.; Ai, J.; Yu, D.; Zhang, H. An Evaluation Method for Large Language Models’ Code Generation Capability. In Proceedings of the 2023 10th International Conference on Dependable Systems and Their Applications, DSA 2023, Tokyo, Japan, 10–11 August 2023; pp. 831–838. [Google Scholar] [CrossRef]
- Pinto, G.; B de Souza, C.R.; Batista Neto, J.; de Souza, A.; Gotto, T.; Monteiro, E. Lessons from Building StackSpot AI: A Contextualized AI Coding Assistant. In Proceedings of the 46th International Conference on Software Engineering: Software Engineering in Practice, Lisbon, Portugal, 14–20 April 2024; Volume 24, pp. 408–417. [Google Scholar] [CrossRef]
- Hansson, E.; Ellréus, O. Code Correctness and Quality in the Era of AI Code Generation: Examining ChatGPT and GitHub Copilot (Dissertation). Bachelor’s Thesis, Linnaeus University, Växjö, Sweden, 2023. Available online: https://urn.kb.se/resolve?urn=urn:nbn:se:lnu:diva-121545 (accessed on 25 October 2024).
- Taeb, M.; Chi, H.; Bernadin, S. Assessing the Effectiveness and Security Implications of AI Code Generators. J. Colloq. Inf. Syst. Secur. Educ. 2024, 11, 6. [Google Scholar] [CrossRef]
- Wong, M.F.; Guo, S.; Hang, C.N.; Ho, S.W.; Tan, C.W. Natural Language Generation and Understanding of Big Code for AI-Assisted Programming: A Review. Entropy 2023, 25, 888. [Google Scholar] [CrossRef]
- Zamfirescu-Pereira, J.D.; Wong, R.Y.; Hartmann, B.; Yang, Q. Why Johnny Can’t Prompt: How Non-AI Experts Try (and Fail) to Design LLM Prompts. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI’23), Hamburg, Germany, 23–28 April 2023; Association for Computing Machinery: New York, NY, USA, 2023; p. 437. [Google Scholar] [CrossRef]
- Liu, M.; Wang, J.; Lin, T.; Ma, Q.; Fang, Z.; Wu, Y. An Empirical Study of the Code Generation of Safety-Critical Software Using LLMs. Appl. Sci. 2024, 14, 1046. [Google Scholar] [CrossRef]
- Sadik, A.R.; Ceravola, A.; Joublin, F.; Patra, J. Analysis of ChatGPT on Source Code. arXiv 2023, arXiv:2306.00597. [Google Scholar]
- Improta, C. Poisoning Programs by Un-Repairing Code: Security Concerns of AI-Generated Code. In Proceedings of the 2023 IEEE 34th International Symposium on Software Reliability Engineering Workshop, ISSREW 2023, Florence, Italy, 9–12 October 2023; pp. 128–131. [Google Scholar] [CrossRef]
- Le, K.T.; Andrzejak, A.; Tuyen Le, K. Rethinking AI Code Generation: A One-Shot Correction Approach Based on User Feedback. Autom. Softw. Eng. 2023, 31, 60. [Google Scholar] [CrossRef]
- Mohamed, N. Current Trends in AI and ML for Cybersecurity: A State-of-the-Art Survey. Cogent Eng. 2023, 10, 2272358. [Google Scholar] [CrossRef]
- Lucchi, N. ChatGPT: A Case Study on Copyright Challenges for Generative Artificial Intelligence Systems. Eur. J. Risk Regul. 2023, 1–23. [Google Scholar] [CrossRef]
- Kuhail, M.A.; Mathew, S.S.; Khalil, A.; Berengueres, J.; Shah, S.J.H. “Will I Be Replaced?” Assessing ChatGPT’s Effect on Software Development and Programmer Perceptions of AI Tools. Sci. Comput. Program 2024, 235, 103111. [Google Scholar] [CrossRef]
- Yeo, S.; Ma, Y.S.; Kim, S.C.; Jun, H.; Kim, T. Framework for Evaluating Code Generation Ability of Large Language Models. ETRI J. 2024, 46, 106–117. [Google Scholar] [CrossRef]
- Sharma, T.; Kechagia, M.; Georgiou, S.; Tiwari, R.; Vats, I.; Moazen, H.; Sarro, F. A Survey on Machine Learning Techniques Applied to Source Code. J. Syst. Softw. 2024, 209, 111934. [Google Scholar] [CrossRef]
- Liu, J.; Xia, C.S.; Wang, Y.; Zhang, L. Is your code generated by ChatGPT really correct? rigorous evaluation of large language models for code generation. In Proceedings of the 37th International Conference on Neural Information Processing Systems (NIPS’23), New Orleans, LA, USA, 10–16 December 2023; Curran Associates Inc.: Red Hook, NY, USA, 2024; pp. 21558–21572. Available online: https://dl.acm.org/doi/10.5555/3666122.3667065 (accessed on 25 October 2024).
- Kiesler, N.; Lohr, D.; Keuning, H. Exploring the Potential of Large Language Models to Generate Formative Programming Feedback. In Proceedings of the Frontiers in Education Conference, FIE, College Station, TX, USA, 18–21 October 2023. [Google Scholar] [CrossRef]
- Santos, R.; Santos, I.; Magalhaes, C.; De Souza Santos, R. Are We Testing or Being Tested? Exploring the Practical Applications of Large Language Models in Software Testing. In Proceedings of the 2024 IEEE Conference on Software Testing, Verification and Validation, ICST 2024, Toronto, ON, Canada, 27–31 May 2024; pp. 353–360. [Google Scholar] [CrossRef]
- Lu, Q.; Zhu, L.; Xu, X.; Liu, Y.; Xing, Z.; Whittle, J. A Taxonomy of Foundation Model Based Systems through the Lens of Software Architecture. In Proceedings of the 2024 IEEE/ACM 3rd International Conference on AI Engineering—Software Engineering for AI, CAIN 2024, Lisbon, Portugal, 14–15 April 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Cowan, B.; Watanobe, Y.; Shirafuji, A. Enhancing Programming Learning with LLMs: Prompt Engineering and Flipped Interaction. In Proceedings of the ACM International Conference Proceeding Series, Aizu-Wakamatsu City, Japan, 29 October 2023; pp. 10–16. [Google Scholar] [CrossRef]
- Sarsa, S.; Denny, P.; Hellas, A.; Leinonen, J. Automatic Generation of Programming Exercises and Code Explanations Using Large Language Models. In Proceedings of the ICER 2022: ACM Conference on International Computing Education Research, Lugano, Switzerland, 7–11 August 2022; Volume 1, pp. 27–43. [Google Scholar] [CrossRef]
- Leinonen, J.; Hellas, A.; Sarsa, S.; Reeves, B.; Denny, P.; Prather, J.; Becker, B.A. Using Large Language Models to Enhance Programming Error Messages. In Proceedings of the SIGCSE 2023: The 54th ACM Technical Symposium on Computer Science Education, Toronto, ON, Canada, 16–18 March 2023; Volume 1, pp. 563–569. [Google Scholar]
- Jiang, E.; Toh, E.; Molina, A.; Olson, K.; Kayacik, C.; Donsbach, A.; Cai, C.J.; Terry, M. Discovering the Syntax and Strategies of Natural Language Programming with Generative Language Models. In Proceedings of the Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022; p. 19. [Google Scholar]
- Moore, O. The Top 100 Gen AI Consumer Apps|Andreessen Horowitz. Available online: https://a16z.com/100-gen-ai-apps/ (accessed on 14 June 2024).
- OpenAI ChatGPT. Available online: https://chatgpt.com/ (accessed on 22 October 2024).
- Microsoft Copilot. Available online: https://copilot.microsoft.com/ (accessed on 22 October 2024).
- Google Gemini. Available online: https://gemini.google.com/ (accessed on 22 October 2024).
- Tabnine Tabnine AI. Available online: https://www.tabnine.com/ (accessed on 22 October 2024).
- Cours Connecte Blackbox AI. Available online: https://www.blackbox.ai/ (accessed on 22 October 2024).
- Pandian, C.R.; SK, M.K. Simple Statistical Methods for Software Engineering: Data and Patterns; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- McConnell, S. Code Complete: A Practical Handbook of Software Construction, 2nd ed.; Microsoft Press: Redmond, WA, USA, 2004; ISBN 978-0735619678. [Google Scholar]
- SQL Validator and Query Fixer. Available online: https://www.sqlvalidator.com/ (accessed on 22 October 2024).
- W3C CSS Validation Service. Available online: https://jigsaw.w3.org/css-validator/ (accessed on 22 October 2024).
- W3C Markup Validation Service. Available online: https://validator.w3.org/ (accessed on 22 October 2024).
- Pengnate, S.; Sarathy, R. Visual Appeal of Websites: The Durability of Initial Impressions. In Proceedings of the Annual Hawaii International Conference on System Sciences, Wailea, HI, USA, 7–10 January 2013; pp. 480–489. [Google Scholar] [CrossRef]
- Barua, A.; Thomas, S.W.; Hassan, A.E. What Are Developers Talking about? An Analysis of Topics and Trends in Stack Overflow. Empir. Softw. Eng. 2014, 19, 619–654. [Google Scholar]
- Maleki, N.G.; Ramsin, R. Agile Web Development Methodologies: A Survey and Evaluation. Stud. Comput. Intell. 2018, 722, 1–25. [Google Scholar] [CrossRef]
- Zheng, L.; Chiang, W.-L.; Sheng, Y.; Zhuang, S.; Wu, Z.; Zhuang, Y.; Lin, Z.; Li, Z.; Li, D.; Xing, E.P.; et al. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. Adv. Neural Inf. Process. Syst. 2023, 36, 46595–46623. [Google Scholar]
- Kiela, D.; Bartolo, M.; Nie, Y.; Kaushik, D.; Geiger, A.; Wu, Z.; Vidgen, B.; Prasad, G.; Singh, A.; Ringshia, P.; et al. Dynabench: Rethinking Benchmarking in NLP. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 4110–4124. [Google Scholar] [CrossRef]
- Fabiano, N. AI Act and Large Language Models (LLMs): When Critical Issues and Privacy Impact Require Human and Ethical Oversight. arXiv 2024, arXiv:2404.00600. [Google Scholar]
- Mökander, J.; Schuett, J.; Kirk, H.R.; Floridi, L. Auditing Large Language Models: A Three-Layered Approach. AI Ethics 2023, 1, 1–31. [Google Scholar] [CrossRef]
- Ding, D.; Mallick, A.; Wang, C.; Sim, R.; Mukherjee, S.; Ruhle, V.; Lakshmanan, L.V.S.; Awadallah, A.H. Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing. arXiv 2024, arXiv:2404.14618. [Google Scholar]
- Chen, L.; Zaharia, M.; Zou, J. Less is More: Using Multiple LLMs for Applications with Lower Costs. Workshop on Efficient Systems for Foundation Models @ ICML2023. 2023. Available online: https://openreview.net/pdf?id=TkXjqcwQ4s (accessed on 25 October 2024).
- Maharana, A.; Lee, D.-H.; Tulyakov, S.; Bansal, M.; Barbieri, F.; Fang, Y. Evaluating Very Long-Term Conversational Memory of LLM Agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 11–16 August 2024; Volume 1, pp. 13851–13870. [Google Scholar] [CrossRef]
- McDonald, D.; Papadopoulos, R.; Benningfield, L. Reducing LLM Hallucination Using Knowledge Distillation: A Case Study with Mistral Large and MMLU Benchmark. TechRxiv 2024. [Google Scholar] [CrossRef]
- Duan, H.; Yang, Y.; Tam, K.Y. Do LLMs Know about Hallucination? An Empirical Investigation of LLM’s Hidden States. arXiv 2024, arXiv:2402.09733. [Google Scholar]
- Haugsbaken, H.; Hagelia, M. A New AI Literacy For The Algorithmic Age: Prompt Engineering Or Eductional Promptization? In Proceedings of the 2024 4th International Conference on Applied Artificial Intelligence, ICAPAI 2024, Halden, Norway, 16 April 2024. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| ChatGPT 3.5 | Copilot (Creative Mode) | Gemini (Concept 1) | TabNine AI (Protected) | BlackBox | Maximum | Weighted Criteria | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Criteria | T1 | T2 | T3 | T1 | T2 | T3 | T1 | T2 | T3 | T1 | T2 | T3 | T1 | T2 | T3 | ||
| HTML and CSS Syntax Rules | 29 | 30 | 30 | 30 | 30 | 30 | 29 | 25 | 26 | 30 | 26 | 27 | 24 | 26 | 27 | 30 | 10% |
| Understanding of Prompts | 41 | 45 | 45 | 42 | 45 | 45 | 43 | 45 | 41 | 37 | 43 | 45 | 40 | 42 | 44 | 45 | 10% |
| Conversational Memory | 20 | 21 | 21 | 20 | 21 | 21 | 21 | 21 | 18 | 18 | 21 | 20 | 17 | 19 | 17 | 21 | 5% |
| Original and Diverse Content | 5 | 5 | 4 | 4 | 4 | 4 | 5 | 5 | 3 | 5 | 4 | 4 | 5 | 4 | 4 | 5 | 20% |
| Appearance and User-Friendliness | 9 | 13 | 12 | 13 | 15 | 13 | 13 | 11 | 7 | 7 | 13 | 10 | 8 | 10 | 8 | 15 | 20% |
| Functioning of PHP Form and Database Linking | 3 | 9 | 12 | 9 | 12 | 9 | 9 | 12 | 5 | 3 | 12 | 7 | 3 | 3 | 5 | 12 | 30% |
| SQL Query Correctness | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 5% |
| ChatGPT 3.5 | Copilot (Creative Mode) | Gemini (Concept 1) | TabNine AI (Protected) | BlackBox | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Criteria | T1 | T2 | T3 | T1 | T2 | T3 | T1 | T2 | T3 | T1 | T2 | T3 | T1 | T2 | T3 |
| HTML and CSS Syntax Rules | 2.9 | 3 | 3 | 3 | 3 | 3 | 2.9 | 2.5 | 2.6 | 3 | 2.6 | 2.7 | 2.4 | 2.6 | 2.7 |
| Understanding of Prompts | 4.1 | 4.5 | 4.5 | 4.2 | 4.5 | 4.5 | 4.3 | 4.5 | 4.1 | 3.7 | 4.3 | 4.5 | 4 | 4.2 | 4.4 |
| Conversational Memory | 1 | 1.05 | 1.05 | 1 | 1.05 | 1.05 | 1.05 | 1.05 | 0.9 | 0.9 | 1.05 | 1 | 0.85 | 0.95 | 0.85 |
| Original and Diverse Content | 1 | 1 | 0.8 | 0.8 | 0.8 | 0.8 | 1 | 1 | 0.6 | 1 | 0.8 | 0.8 | 1 | 0.8 | 0.8 |
| Appearance and User-Friendliness | 1.8 | 2.6 | 2.4 | 2.6 | 3 | 2.6 | 2.6 | 2.2 | 1.4 | 1.4 | 2.6 | 2 | 1.6 | 2 | 1.6 |
| Functioning of PHP Form and Database Linking | 0.9 | 2.7 | 3.6 | 2.7 | 3.6 | 2.7 | 2.7 | 3.6 | 1.5 | 0.9 | 3.6 | 2.1 | 0.9 | 0.9 | 1.5 |
| SQL Query Correctness | 0.15 | 0.15 | 0.15 | 0.15 | 0.15 | 0.15 | 0.15 | 0.15 | 0.15 | 0.15 | 0.15 | 0.15 | 0.15 | 0.15 | 0.15 |
| The total score with the weighted criteria | 11.85 | 15 | 15.5 | 14.45 | 16.1 | 14.8 | 14.7 | 15 | 11.25 | 11.05 | 15.1 | 13.25 | 10.9 | 11.6 | 12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Smutny, P.; Bojko, M. Comparative Analysis of Chatbots Using Large Language Models for Web Development Tasks. Appl. Sci. 2024, 14, 10048. https://doi.org/10.3390/app142110048
Smutny P, Bojko M. Comparative Analysis of Chatbots Using Large Language Models for Web Development Tasks. Applied Sciences. 2024; 14(21):10048. https://doi.org/10.3390/app142110048
Chicago/Turabian StyleSmutny, Pavel, and Michal Bojko. 2024. "Comparative Analysis of Chatbots Using Large Language Models for Web Development Tasks" Applied Sciences 14, no. 21: 10048. https://doi.org/10.3390/app142110048
APA StyleSmutny, P., & Bojko, M. (2024). Comparative Analysis of Chatbots Using Large Language Models for Web Development Tasks. Applied Sciences, 14(21), 10048. https://doi.org/10.3390/app142110048