Abstract
In this study, we compare the performance of five chatbots using large language models (LLMs) in handling web development tasks. Three human testers asked each chatbot nine predefined questions related to creating a simple website with a dynamic form and database integration. The questions covered tasks such as generating a web document structure, designing a layout, creating a form, and implementing database queries. The chatbots’ outputs were ranked based on accuracy, completeness, creativity, and security. The experiment reveals that conversational chatbots are adept at managing complex tasks, while programming assistants require more precisely formulated tasks or the ability to generate new responses to address irrelevant outputs. The findings suggest that conversational chatbots are more capable of handling a broader range of web development tasks with minimal supervision, whereas programming assistants need more precise task definitions to achieve comparable results. This study contributes to understanding the strengths and limitations of various LLM-based chatbots in practical coding scenarios, offering insights for their application in web development.
1. Introduction
Thanks to developments in natural language processing (NLP) and artificial intelligence (AI), chatbots are becoming more and more common in a variety of entities [1]. More specifically, chatbots that utilize large language models (LLMs) have been shown to be exceptionally skilled at recognizing and creating content that is human-like [2]. These models—including Copilot, GPT-3.5 from OpenAI, and others—are trained on enormous volumes of data, which allows them to accomplish a variety of tasks, like writing essays, answering questions, or creating code [3].
Chatbots have become useful in the field of web development [4]. These AI technologies are widely used by developers to obtain code snippets, debug issues, and simplify development processes. Chatbots that are based on LLMs can help with creating HTML structures, creating CSS, writing JavaScript, and connecting backend features with databases like MySQL and PHP. The need to assess these chatbots’ ability to handle difficult programming needs grows with the complexity of web development activities.
Although LLM-based chatbots show potential, their efficiency in real-world coding jobs has to be methodically verified. Reliable tools that not only produce precise code but also comprehend the jobs’ context, guarantee security, and preserve usability have become vital for developers. Recent research [5,6,7] has investigated these chatbots’ overall performance; however, little is known about how well they work in particular, multi-step web development scenarios. This assessment is necessary for developers to select the best chatbot for their purposes and identify areas where these AI tools may be enhanced.
1.1. Research Question
This study aims to address the following research question: “How do different chatbots using large language models compare in generating code for building a simple HTML website with PHP form and MySQL database integration?”.
1.2. Objectives
The specific objectives of this study are as follows:
- Comparing Accuracy: assess the correctness and precision of the code generated by each chatbot.
- Evaluating Usability: determine the user-friendliness and ease of understanding the outputs provided by the chatbots.
- Examining Creativity: evaluate the ability of chatbots to incorporate creative elements in the design and functionality of the web components.
- Integrating Databases: analyze the chatbots’ capability to integrate with databases, ensuring they can effectively connect, query, and manipulate data within a database system.
- Understanding Context: assess the chatbots’ proficiency in understanding and utilizing previous conversational context to generate relevant and coherent responses, enhancing the continuity and relevance of the interaction.
By achieving these objectives, this study aims to provide an evaluation of LLM-based chatbots in the context of web development, guiding developers in selecting the most effective tools for their coding tasks and highlighting potential improvements for chatbot developers.
2. Related Work
Chatbots, especially those powered by large language models (LLMs), are being actively experimented with in various fields [8,9,10]. These experiments aim to improve areas like customer service, content generation, and even coding and web development. LLMs have demonstrated the ability to understand and generate human-like text, including programming languages [11].
To ensure LLMs meet the desired performance standards in such applications, a multitude of benchmarking tools have emerged to rigorously assess their capabilities across diverse dimensions. These tools often focus on specific capabilities, such as language understanding, reasoning, code generation, or multilingual abilities. For instance, MMLU [12] evaluates general language understanding, while WinoGrande [13] assesses common sense reasoning. HumanEval [14] benchmarks code generation, and MGSM [15] evaluates multilingual capabilities. These tools typically employ a variety of evaluation methods, including automatic metrics and human evaluation. Automatic metrics assess quantitative aspects like fluency and coherence, while human evaluation provides qualitative insights into factors such as factuality, relevance, and overall quality.
A series of recent studies have examined the performance, usability, and limitations of LLMs, particularly in the context of code generation. These studies explore various aspects, including user experiences, benchmarking against different metrics, and the effectiveness of LLMs in real-world coding scenarios.
A qualitative study [16] examined early adopters’ perceptions of ChatGPT for code generation, focusing on user experiences, prompt engineering, trust, and its impact on software development. The researchers gathered and analyzed user comments from Hacker News to understand the challenges and preferences related to the tool. The findings revealed important areas for improvement, such as enhancing prompt engineering techniques and building greater user trust. These insights suggest directions for future research, particularly in refining code generation tools to better meet user needs.
In another study [17], researchers evaluated the usability of Copilot with 24 participants. Despite Copilot’s high performance on benchmark tests, the study found that it did not significantly improve participants’ task completion time or success rates. Participants favored Copilot for providing a good starting point for coding tasks. The study suggests enhancements for understanding and validating generated code, exploring multiple solutions, and aiding task decomposition, indicating room for improvement in real-world application.
In a comparative analysis [18], the correctness, efficiency, and maintainability of AI- and human-generated program code were assessed using metrics such as time and space complexity, runtime, memory usage, and maintainability index. Among the generative AIs evaluated, GitHub Copilot (Codex) achieved the highest success rate, solving 50% of the problems, while ChatGPT (GPT-3.5) was notable for solving the only hard problem, despite its lower overall correctness rate.
A pilot study [19] explored the use of ChatGPT for generating secure web application code, focusing on mitigating four common vulnerabilities: SQL Injection, Cross-Site Scripting, CRLF Injection, and Exposure of Sensitive Information. The study found that ChatGPT does not inherently address these vulnerabilities but proposed a prompt pattern that can guide the model to generate more secure code by mitigating potential risks.
In a comprehensive evaluation [20] of ChatGPT’s capability to generate Java Web application code, using a user-login program as a case study, the results show that the generated code meets expected requirements, exhibiting high readability, quality, and functionality. While ChatGPT offers an efficient solution compared to manual coding, its performance diminishes with limited input information, suggesting its potential as a valuable tool for developers in software development.
Creating a website from scratch requires knowledge of HTML coding. The authors of [21] propose an AI-based system that can automatically generate websites according to user specifications. The system works by gathering user input regarding the website’s topic and desired features. Then, it leverages this information to generate the necessary HTML code and images to construct the website.
In a comparative study of code generation tools, Yetiştiren et al. [22] evaluated GitHub Copilot, Amazon CodeWhisperer, and ChatGPT using metrics such as correctness, validity, reliability, security, and maintainability. They found that ChatGPT had the highest success rate, especially when clear problem descriptions were provided. The study highlights the rapid improvements in GitHub Copilot and Amazon CodeWhisperer and underscores the importance of precise input for optimal tool performance.
Recent work by Su et al. [23] evaluates the Python code generation capabilities of various large language models (LLMs), including ChatGPT, Claude, Spark, and Bing AI. Their experimental analysis demonstrates that search-based models like Bing AI outperform pre-trained models in generating code. They found that while these LLMs possess strong natural language understanding, errors in code suggestions are more often due to code generation issues rather than comprehension problems. The study suggests that enhancing code generation techniques, particularly through search-based approaches, could improve the accuracy and efficiency of code produced by LLMs.
Despite the availability of numerous benchmarking tools, there is currently a gap in assessing the specific capabilities of LLMs for web development tasks. Our research aims to address this gap by expanding the current diverse dimensions of benchmarking to focus explicitly on the unique requirements of web development.
3. Materials and Methods
The capabilities of LLMs in assisting with coding tasks are both promising and concerning. On the one hand, these AI systems can produce useful code snippets, functions, or routines when provided with clear and detailed prompts describing the desired functionality [24]. This can potentially boost developer productivity for certain coding subtasks. However, the generated code is not always reliable or functional, as language models can also produce nonsensical, insecure, or buggy outputs [25,26,27]. The quality of the generated code heavily depends on the quality and specificity of the prompts [28,29].
While state-of-the-art language models excel at code understanding and generation tasks within limited scopes, they still struggle to independently develop complete, complex applications from scratch. Their current strengths lie more in assisting developers with specific coding challenges like implementing algorithms, refactoring code, or autocompleting partial functions [30]. When leveraging AI-generated code, developers must remain vigilant about verifying its correctness, security, and adherence to best practices [31,32,33]. There are also unresolved legal questions around the ownership and licensing of AI-generated code [34]. Overall, AI can be a useful coding aid but should be viewed as an assistive tool requiring close human supervision and scrutiny, rather than a replacement for skilled programmers [35].
Web development encompasses much more than just code generation, and while large language models are not yet capable of producing code for entire mid- or large-scale applications, they can significantly assist human programmers. The following strategies illustrate how these capabilities can be effectively organized into various categories to enhance productivity and streamline workflows.
Code Assistance and Optimization [36,37,38].
- Automated Code Creation—chatbots can efficiently generate code for various web development tasks, including the creation of well-structured HTML, CSS, JavaScript functions, and database queries, thereby conserving valuable development time.
- Code Suggestions—these tools provide context-aware code completion suggestions that align with the coding style being used, enhancing overall productivity.
- Cross-Language Code Transformation—when dealing with multiple programming languages or frameworks, chatbots can seamlessly convert code snippets from one language or framework to another, facilitating easier integration and maintenance.
- Code Clarification—chatbots aid in the comprehension of complex code by offering detailed explanations or answering specific queries related to the code.
- Code Optimization—by proposing improvements and refactorings, chatbots assist in enhancing the efficiency and readability of code with minimal effort from the developer.
- Code Evaluation—these tools can identify issues and security vulnerabilities within the code, ensuring that it remains both efficient and secure.
Bug Management and Testing [39,40]
- Bug Identification and Resolution—chatbots are capable of pinpointing and resolving bugs that may cause issues within the code, thereby streamlining the debugging process.
- Testing Assistance—chatbots provide support in writing unit tests, generating comprehensive test cases, and selecting suitable testing frameworks or libraries, thus enhancing the testing phase.
System Design and Mock Data [41]
- System Design Advice—these tools offer valuable insights and recommendations for designing systems using specific technology stacks, or they can compare different architectural designs to help select the optimal approach.
- Mock Data Creation—chatbots can quickly generate mock data for various domains and formats, facilitating development and testing processes.
Documentation and Learning [42,43,44]
- Documentation Support—chatbots assist in writing detailed comments and documentation for code, ensuring clarity and maintainability.
- Educational Support—they aid in learning new programming languages, understanding best practices, and improving website performance, serving as a valuable educational resource.
Command Line and Content [45]
- Command Line and Version Control Assistance—chatbots can assist with shell commands and version control operations using Git, simplifying these tasks.
- Content Generation—these tools can create tailored content for various purposes, addressing specific needs.
- Regular Expression Handling—chatbots understand complex regular expressions and generate new ones that match specific text patterns, simplifying tasks that involve text processing.
Despite the extensive research on LLMs and their capabilities, there are several gaps in the current literature, particularly concerning the comprehensive evaluation of these models in multi-step, practical coding scenarios relevant to web development. Most existing studies have focused on isolated tasks or simple coding challenges, without assessing the models’ ability to handle more complex, multi-step tasks that are common in real-world web development projects. For instance, generating a complete HTML structure, implementing a responsive design, creating dynamic forms, and integrating with databases are tasks that have not been extensively evaluated in a combined manner.
This study aims to fill these gaps by conducting a comprehensive evaluation of five different LLM-based chatbots on a series of interconnected web development tasks. By using predefined prompts that require the creation of a complete HTML website with PHP form and MySQL database integration, this research will achieve the following:
- Assess the ability of chatbots to handle complex, multi-step tasks in web development.
- Evaluate the user experience, including the clarity, usability, and functionality of the generated code.
- Provide comparative insights into the performance of conversational chatbots versus programming assistants.
Through this approach, the study will offer a detailed understanding of the strengths and limitations of various LLM-based chatbots, contributing valuable knowledge to the field and guiding future improvements in chatbot development for coding and web development tasks.
3.1. Testers
The experiment involved three human testers, designated as T1, T2, and T3. These testers were selected based on their varying levels of web design knowledge, ranging from junior to senior. This diversity in expertise was intended to minimize subjective evaluation and provide a broader range of perspectives on the performance of the chatbots. Each tester independently evaluated the outputs of the five chatbots to ensure an objective and fair assessment. While human evaluators inherently introduce variability due to differing expertise levels, efforts were made to standardize the testing procedure through detailed guidelines and fixed prompts.
3.2. Chatbots and Evaluation Tools
In this study, we have selected five chatbots capable of generating code, based on a ranking by Andreessen Horowitz [46] of the most popular generative AI web products, determined by monthly visits. This ranking provided insight into how consumers are utilizing these technologies. From this list, we specifically chose chatbots that met the following criteria: they are either general-purpose language models or specialized code-generating models; they have a significant user base as indicated by their ranking, ensuring their relevance and widespread adoption; they are accessible to users without prohibitive costs or restrictions, allowing for practical evaluation; and they collectively represent a variety of approaches to AI-driven code generation.
We selected five chatbots because this number strikes an optimal balance between breadth and depth in our analysis. Evaluating five distinct models allows us to cover a diverse spectrum of available technologies while keeping the scope manageable. This ensures that we can perform a thorough and detailed evaluation of each chatbot without diluting our focus. We categorized these chatbots into two distinct groups:
- General-purpose language models: these chatbots are capable of a wide range of tasks, including answering questions, generating text, programming code, and providing conversational responses.
- ChatGPT 3.5: Developed by OpenAI, ChatGPT 3.5 is a versatile AI model designed for various conversational tasks. It leverages the GPT-3.5 architecture, known for its ability to generate coherent and contextually appropriate responses across numerous topics. It is widely used for general-purpose dialogue, including generating code and assisting with programming-related queries [47].
- Copilot: Microsoft’s Copilot is a conversational AI designed to assist users by providing information, generating content, and performing web searches. It differs from ChatGPT 3.5 in that it can perform real-time web searches to provide up-to-date information. In this study, we used Microsoft’s Copilot in creative mode, which employed an adapted GPT-4 model at the time of testing (April 2024) [48].
- Gemini: This chatbot is part of Google’s AI portfolio, leveraging the latest advancements in their language model technology. Gemini is designed to assist with a broad range of tasks, from answering general questions to generating complex code snippets. It integrates Google’s extensive search and information retrieval capabilities to enhance its response accuracy and relevance [49].
- 2.
- Code-specific language models: these chatbots are designed specifically for generating code snippets and assisting with programming tasks.
- TabNine AI: An AI-powered code completion tool that uses deep learning models to provide intelligent code suggestions. TabNine supports a wide range of programming languages and is integrated into various IDEs. It focuses on enhancing developer productivity by predicting and completing code based on the context provided by the user [50].
- Blackbox AI: A specialized code generation tool that utilizes machine learning models to assist developers in writing code. Blackbox AI is designed to understand coding patterns and provide relevant code snippets, debugging assistance, and optimization suggestions. It aims to streamline the coding process and reduce the time required to write functional code [51].
Evaluation tools are essential for ensuring code accuracy in scientific studies. The W3C Nu HTML Checker was used to verify the syntax correctness of HTML and CSS, ensuring adherence to web standards. Similarly, the SQL Validator from Scaler.com was used to check SQL queries for syntax errors. These tools help maintain code quality and reliability.
3.3. Procedure
The testers followed a standardized procedure, each posing a sequence of nine specific questions (prompts) to each chatbot. These prompts were designed to simulate a multi-step web development task for a fictional engineering company. The steps involved were as follows:
- Create a basic HTML structure with a navigation menu, header, body, footer, and short content.
- Modify the basic structure to include sections describing a company specializing in machine parts (About Us, Services, Products, Contact).
- Design the appearance using CSS, focusing on responsiveness and UI design tailored to the engineering industry.
- Create an HTML form on a new subpage for adding machine products, including fields for product name, description, image, and price.
- Develop PHP code to save form data to a MySQL database table upon submission.
- Secure the PHP form against invalid data, ensuring fields are not empty and images are included.
- Create a database table for storing the form data using an SQL query.
- Modify the code snippet to display individual products in the “Products” section based on database entries.
- Implement CSS styling for the “Products” section to display products in rows of four, ensuring responsiveness and good UI design.
3.4. Data Collection
In April 2024, a chatbot evaluation was conducted using quantitative research methods [52]. Testers assessed the chatbot’s outputs against predefined criteria and recorded scores. The comprehensive testing process involved systematic interactions with the chatbot across diverse scenarios, aiming to gauge its performance thoroughly from multiple perspectives. The quantitative data enabled statistical analysis to determine the chatbot’s effectiveness. The evaluation process involved the following:
- Code Functionality Testing: The code generated by the chatbot was executed to verify its functionality. This ensured that the code was not only syntactically correct but also operational in practice [53].
- Syntax Error Detection: using online validators to check for HTML, CSS, and SQL syntax errors in the code [54,55,56].
- Usability and Appearance Assessment: The usability and visual appeal of the generated web pages were evaluated. Testers assessed factors like design responsiveness, clarity, and overall user-friendliness [57].
3.5. Evaluation Criteria
The chatbot outputs were evaluated based on the following criteria:
- HTML and CSS Syntax Rules: Evaluated using the Markup/CSS Validation Service. The number of syntax errors was scored from 1 to 5.
- Understanding of Prompts: assessed whether the chatbot fully understood and completed the prompt, scored from 1 to 5.
- Conversational Memory: evaluated the chatbot’s ability to maintain context and build on previous outputs, scored from 1 to 3.
- Original and Diverse Content: assessed the creativity and diversity of the content, including grammar and sentence composition, scored from 1 to 5.
- Appearance and User-Friendliness: evaluated the design’s responsiveness, clarity, and visual appeal, scored from 1 to 5.
- Functioning of PHP Form and Database Linking: checked if the PHP form correctly connected to the database and displayed data on the page, scored from 1 to 5.
- SQL Query Correctness: assessed using the SQL Validator, scored from 1 to 3.
Each criterion had specific guidelines to ensure consistency across evaluators. For example, for the “HTML and CSS Syntax Rules”, a score of 1 was given when the output contained more than 10 syntax errors, while a score of 5 represented flawless execution with no errors. The decision to use different scoring scales was based on the complexity of the criteria. For example, subjective measures like usability and creativity require broader scales (1–5) to capture subtle differences, while binary or objective measures like SQL query correctness were better suited to a 1–3 scale.
The seven evaluation criteria were selected by the authors of the study to provide a comprehensive assessment of common challenges in web development [58]. These criteria collectively address the essential technical, functional, and user-centric challenges. The selection is rooted in the need to evaluate both the front-end and back-end components, as well as the overall user experience and content quality.
The final assessment was determined by a weighted average of the scores for each criterion. Weights were assigned to each criterion based on their importance in web development, aligning with industry best practices [59]. The highest weight, 30%, was given to Functioning of PHP Form and Database Linking, as these are crucial for dynamic web applications and essential for security and user experience. Significant weights of 20% were allocated to both Original and Diverse Content and Appearance and User-Friendliness. While technical functionality is vital, unique content and a user-friendly interface greatly enhance user engagement and satisfaction. Criteria like HTML and CSS Syntax Rules and Understanding of Prompts received 10% each. Proper syntax ensures code efficiency and compatibility, and understanding prompts reflects the ability to meet client requirements accurately. Lesser weights of 5% were assigned to Conversational Memory and SQL Query Correctness. Though important, they were considered less critical within the overall scope, with SQL correctness partly encompassed by the higher-weighted PHP and database functionality.
By assigning weights this way, the evaluation prioritizes both technical functionality and user-centric aspects, ensuring a comprehensive and objective assessment that mirrors real-world web development priorities.
4. Results
4.1. Quantitative Results
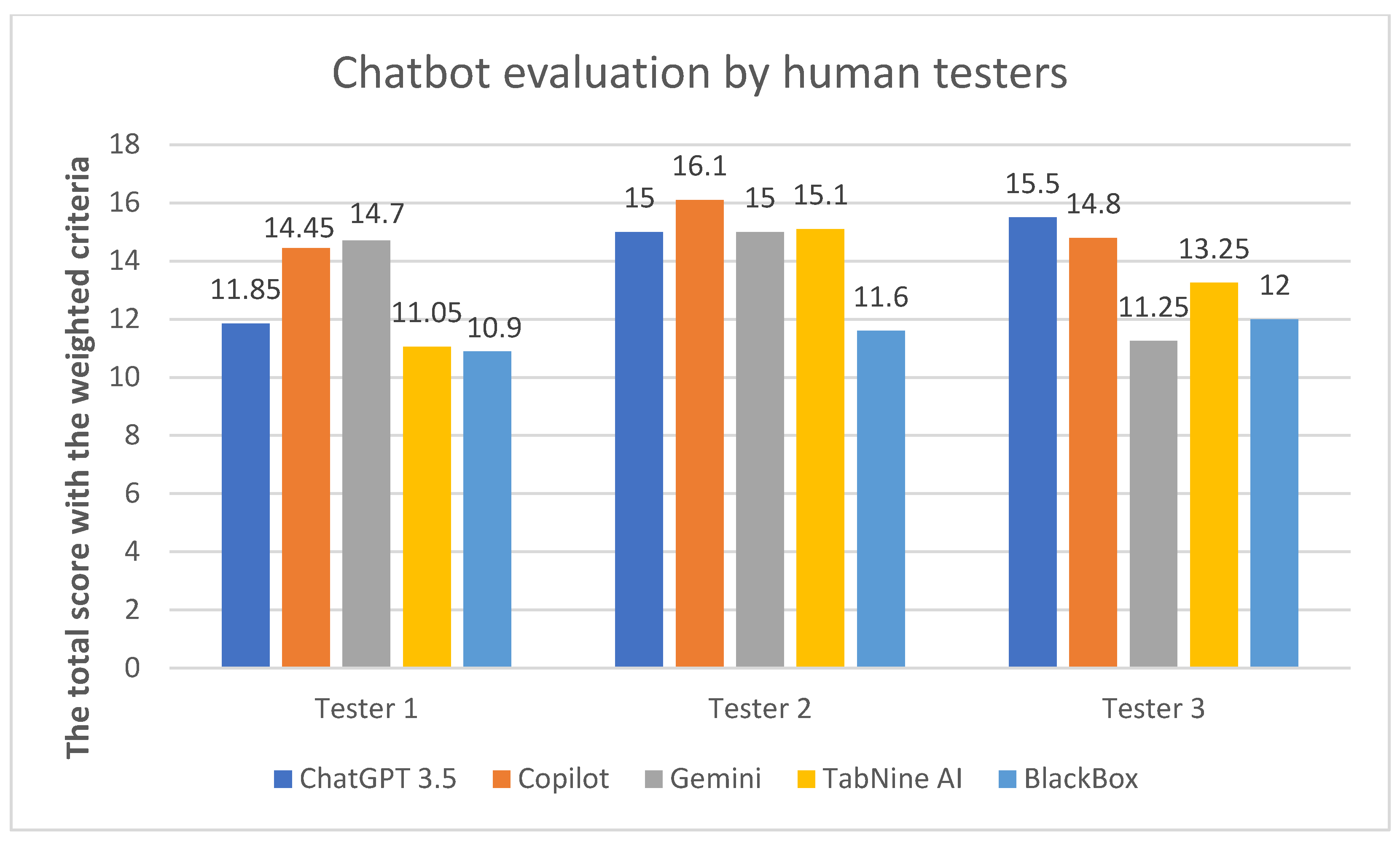
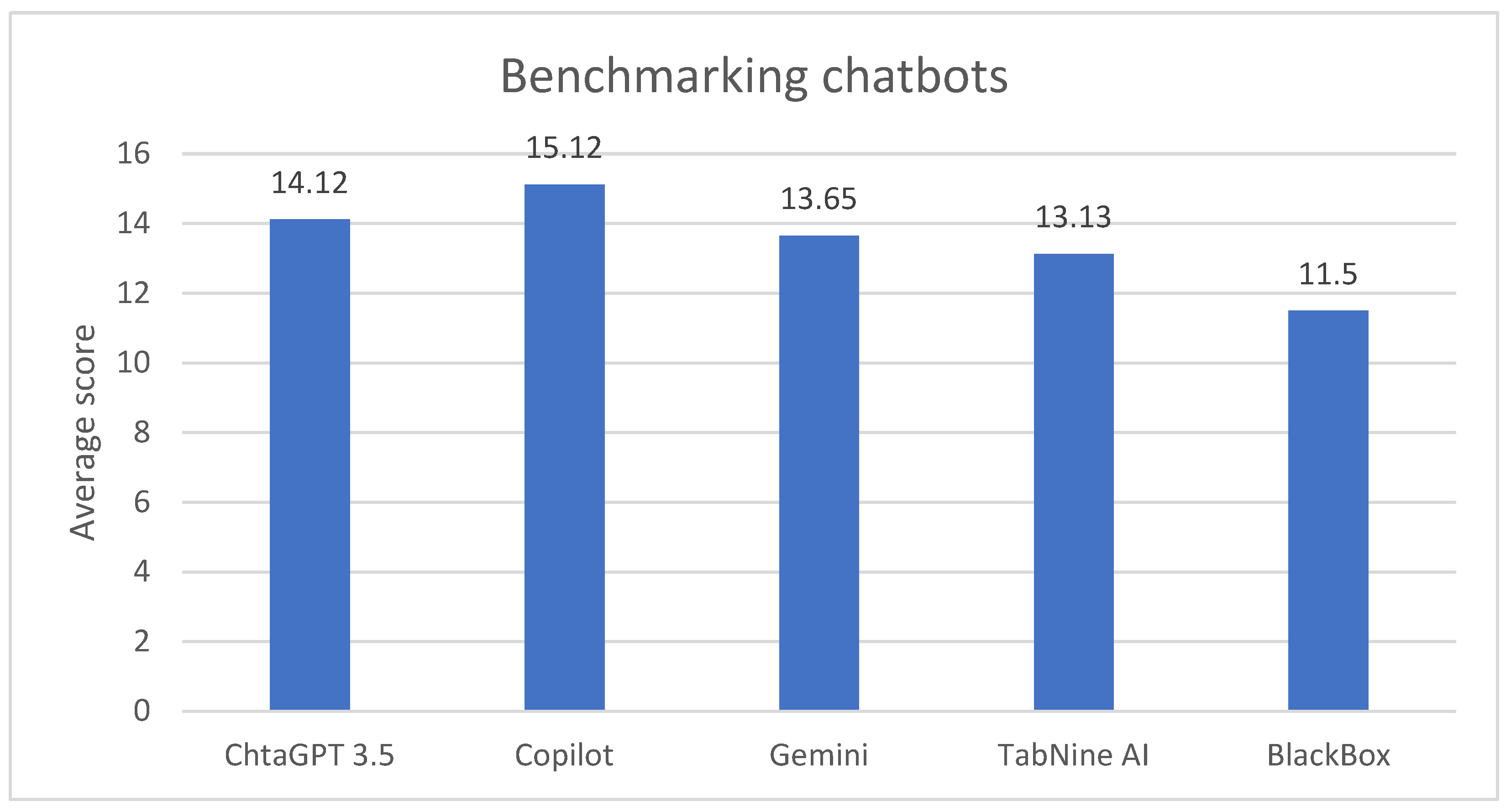
The rankings of the chatbots were determined based on their performance across various tasks, with points awarded in specific categories. The scores from three testers (T1, T2, T3) were weighted according to the importance of each criterion. The results are summarized in Table 1 and Table 2,while Figure 1 and Figure 2 offer a visual representation.

Table 1.
A summary of the scores awarded by all testers for each chatbot, according to the examined criteria.
Table 2.
A summary of the scores with applied weighted criteria.
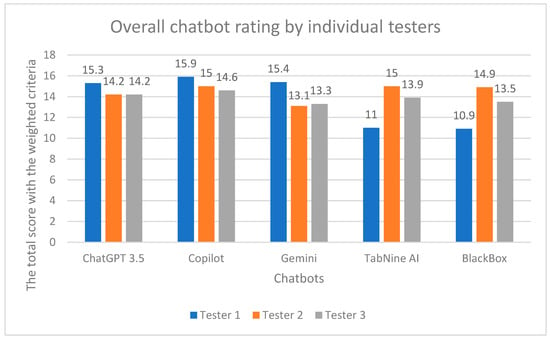
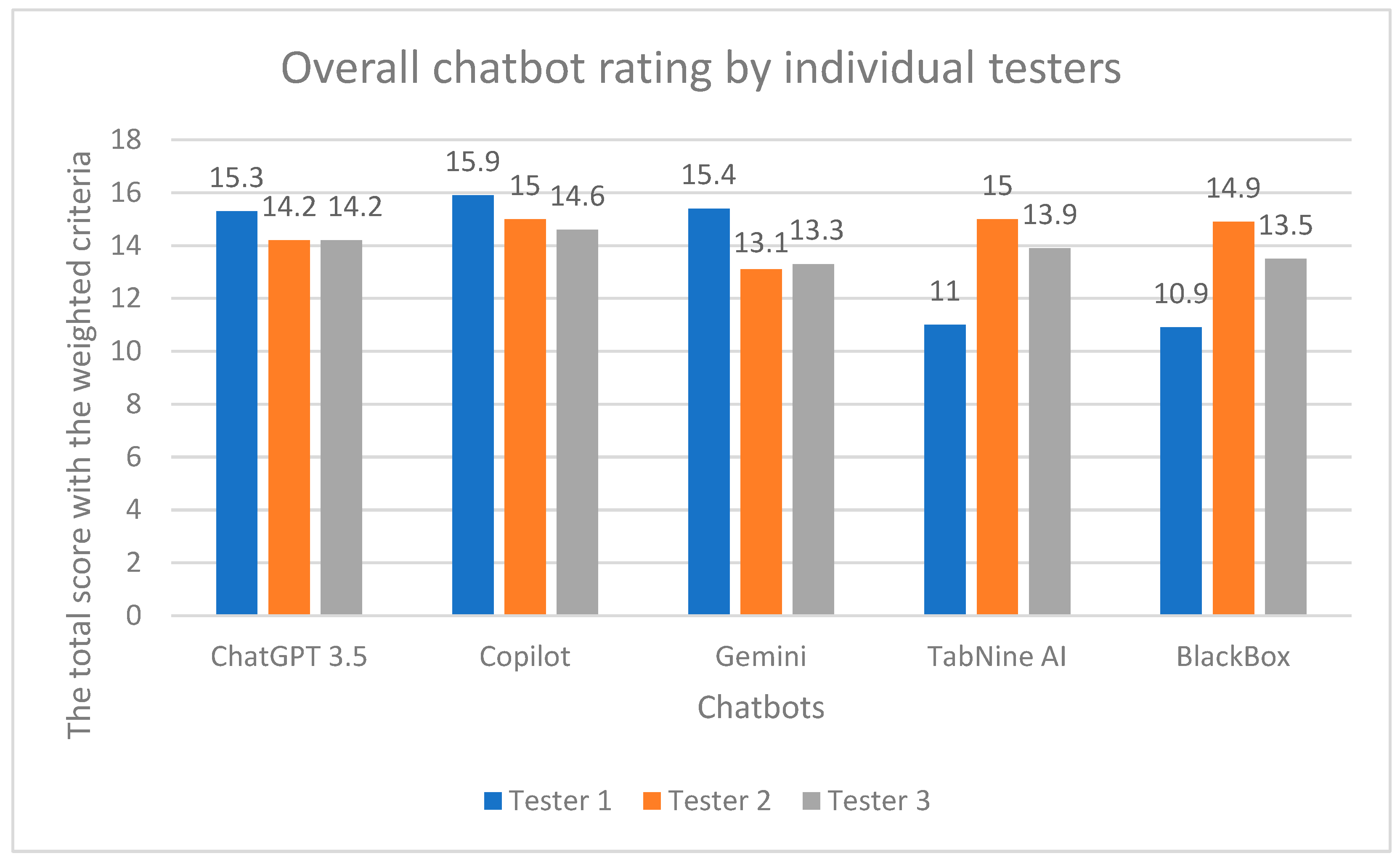
Figure 1.
Aggregate chatbot scores from individual testers.
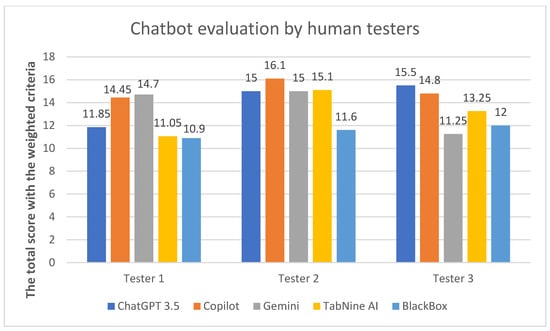
Figure 2.
The graph shows the average score of each chatbot given by human testers.
4.2. Qualitative Feedback
The testers provided qualitative feedback on the strengths and weaknesses of each chatbot:
- ChatGPT 3.5: Highlighted for its diverse and original content and solid HTML/CSS structure. It faced challenges in maintaining conversational memory.
- Copilot: Praised for its flawless HTML and CSS syntax, excellent appearance, and user-friendliness. However, it received lower scores for original and varied content.
- Gemini: noted for creative content but occasionally faltered in syntax and structural aspects.
- TabNine AI: commended for structural correctness but criticized for issues with appearance and user-friendliness.
- BlackBox: struggled with PHP forms and had notable syntax errors, leading to the lowest overall score.
Comparison
The performance of the chatbots varied significantly across different tasks:
- HTML and CSS Syntax Rules: Copilot and ChatGPT 3.5 excelled, consistently achieving high scores across all testers. BlackBox had the most difficulty, with frequent errors noted by evaluators.
- Understanding of Prompts: all chatbots showed strong performance, but ChatGPT 3.5 and Copilot stood out for their ability to understand and execute tasks as expected.
- Conversational Memory: Copilot was the most successful in maintaining context across tasks, while BlackBox showed significant gaps, leading to lower scores in this category.
- Original and Diverse Content: ChatGPT 3.5 led in this area, followed closely by Gemini. Copilot and TabNine AI showed room for improvement.
- Appearance and User-Friendliness: Copilot outperformed others, creating visually appealing and user-friendly outputs. Other chatbots, including TabNine AI, had issues with responsiveness and design.
- Functioning of PHP Form and Database Linking: Copilot excelled, producing fully functional PHP forms that integrated with databases effectively. BlackBox failed to meet requirements consistently.
- SQL Query Correctness: all chatbots met the criteria and received full points for creating correct SQL queries.
The observed difference in performance between simpler and more complex tasks can be attributed to the inherent nature of language models. Simpler tasks typically require fewer steps, lower contextual depth, and involve more straightforward prompts, which makes it easier for the models to generate accurate and effective responses. In contrast, complex tasks demand more nuanced understanding, contextual continuity, and intricate code generation. These requirements increase the likelihood of errors, as the model needs to maintain the contextual flow across multiple steps and generate more comprehensive outputs.
The distinction between conversational and programming-specific chatbots is key to understanding their practical applications. Conversational chatbots like ChatGPT and Copilot excel in understanding prompts in a broader context and generating diverse responses, which makes them highly effective in situations requiring more open-ended problem-solving or creative tasks. Conversely, programming-specific chatbots like TabNine AI are designed to assist with precise code generation, focusing on efficiency and adherence to syntax rules. They are better suited for integration within development environments and generate code with fewer errors, particularly when the prompt is explicitly detailed. A hybrid approach may serve as the ideal solution, combining the strengths of both model types to improve developer productivity across a wider variety of use cases.
In summary, Copilot was the best-performing chatbot due to its strong technical execution and user-friendly designs, despite needing improvement in content originality (Figure 3). ChatGPT 3.5 was a close second, notable for its creativity and overall solid performance. Gemini, while strong in content, had occasional technical issues. TabNine AI showed competence in structural tasks but lacked in design and user experience. BlackBox’s performance was hindered by technical errors, particularly in PHP form functionality.
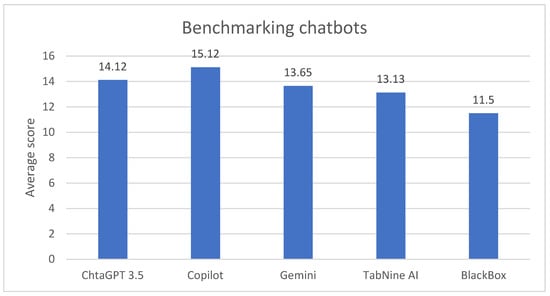
Figure 3.
The bar chart depicts the average evaluation scores of five chatbots as assessed by three human testers.
5. Discussion
Benchmarking and evaluating large language models is crucial, but existing methods have limitations. Traditional fixed benchmarks are limited in scope due to costly human annotations and risk overfitting. Using LLMs as evaluators provides human-like assessments but may suffer from biases and unreliability in certain domains. Human evaluation is considered the gold standard but is time-consuming and labor-intensive for large test sets, while small sets introduce sampling bias. Some platforms like Chatbot Arena [60] or Dynabench [61] facilitate human evaluation through crowdsourcing, but the process remains manual and costly. Another issue is the breakneck pace at which LLMs are improving, with major upgrades happening within just months. This makes it extremely difficult to establish stable benchmarks before they become outdated by the next generation of more powerful models.
Adding to the complexity is the uneven global availability of LLM chatbots due to factors like regulatory differences, linguistic barriers, and infrastructure constraints across countries. Some markets have greater access than others, limiting the representativeness of any benchmarks [62,63].
There is also a lack of standardization in the pricing and usage models offered by commercial chatbot providers. Subscription, pay-per-use, freemium, and enterprise plans make it challenging to directly compare cost-effectiveness across different real-world applications [64,65].
While the focus of this study was on generating basic elements such as HTML and PHP forms, it is important to consider the chatbots’ ability to handle larger, more complex projects. Such projects often require maintaining state across multiple interactions and managing dependencies between different files and technologies. General-purpose language models possess conversational memory capabilities that allow them to maintain context over multiple interactions, which can be beneficial in managing stateful applications [66]. However, complex dependency management across multiple files and technologies—such as coordinating frontend, backend, and database interactions—remains a significant challenge. Current chatbots may struggle without specific prompts and user intervention, as they are optimized for simpler tasks. Programming-specific models are more focused on code accuracy and syntax adherence and also face challenges in handling multi-component projects that require seamless integration between technologies.
A critical area requiring improvement is enhancing the factual accuracy and reliability of chatbot outputs. Integrating automated fact-checking capabilities could reduce issues like hallucinations, but implementing robust self-verification remains an open technical hurdle [67,68].
Furthermore, despite their fluency, modern chatbots can struggle with precisely comprehending natural language prompts and maintaining consistency across long conversations. Better prompt engineering techniques are needed to optimize chatbot performance and response quality [69].
Finally, while foundational LLMs trained on broad data are impressively capable, domain-specific customization through techniques like fine-tuning can unlock significant additional performance gains. However, accounting for such specialized customizations in benchmarking presents its own difficulties.
6. Conclusions
This study set out to determine the capabilities of LLM-based chatbots in generating code for web development tasks. The results demonstrate that these chatbots are quite proficient in handling complex, multi-step tasks such as creating HTML structures, designing CSS layouts, implementing PHP forms, and integrating with MySQL databases. While there is still room for improvement, the overall performance of the evaluated chatbots suggests that they can be valuable assistive tools for web developers, potentially boosting productivity and streamlining certain coding processes.
A key objective was to explore the differences between conversational chatbots and programming assistants in this context. The findings reveal distinct strengths and weaknesses. Conversational models like ChatGPT and Copilot excelled in understanding prompts, generating diverse and user-friendly content, and delivering visually appealing designs. However, programming assistants like TabNine AI and BlackBox demonstrated stronger adherence to syntax rules and structural requirements. Interestingly, the study suggests that the ideal approach may be to integrate the output from conversational chatbots into integrated development environments (IDEs) using plugins, combining the strengths of both types of models for a seamless web development experience.
One of the challenges addressed in this research was the lack of a standardized method for evaluating and selecting the most appropriate LLM chatbot for web development tasks. While no easy solution currently exists, this study provides a useful guideline for testing and comparing different chatbots across various criteria, such as accuracy, usability, creativity, and database integration. By following a structured evaluation process similar to the one outlined in this study, web developers can make informed decisions when choosing the most suitable chatbot assistant for their specific needs and project requirements.
Beyond the academic scope, the implications of this research extend to applied web development practices. The findings suggest that integrating conversational chatbots within existing IDEs can significantly enhance productivity, allowing developers to focus on refining complex backend logic while benefiting from the chatbots’ proficiency in generating clean, well-structured HTML and CSS. Furthermore, the study highlights that conversational chatbots can reduce development time in rapid prototyping phases and improve code creativity, while code-specific tools like BlackBox offer valuable support in repetitive coding tasks with an emphasis on correctness and security. This comparative analysis provides a roadmap for improving LLM-based coding tools, both in academic research and practical software development, and positions these tools as key enablers of the future of AI-assisted development.
Despite the valuable insights gained from evaluating the chatbots on specific web development tasks, we acknowledge that the scope of tasks tested in this study was relatively small. Our focus was on seven common challenges in web development, which, while representative of certain aspects of the field, do not encompass the full spectrum of complexities and scenarios that developers encounter in real-world projects. This limitation may affect the generalizability of our findings to other programming tasks or domains. Future research should consider expanding the range of tasks to include more diverse and complex challenges, such as advanced backend development, security implementations, and performance optimization.
Author Contributions
The authors confirm contributions to the paper as follows: Study conception and design: P.S. and M.B.; Data collection, analysis and interpretation of results, P.S. and M.B.; Original draft manuscript preparation, P.S.; Writing, review, and editing, P.S. and M.B. All authors have read and agreed to the published version of the manuscript.
Funding
This article was co-funded by the European Union under the REFRESH—Research Excellence For REgion Sustainability and High-Tech Industries—project number CZ.10.03.01/00/22_003/0000048 via the Operational Programme Just Transition and the project SP2024/038 Applied Research in the Area of Control, Measurement and Diagnostic Systems supported by the Ministry of Education, Youth and Sports, the Czech Republic.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural Language Processing: State of the Art, Current Trends and Challenges. Multimed. Tools Appl. 2023, 82, 3713–3744. [Google Scholar] [CrossRef] [PubMed]
- Ray, P.P. ChatGPT: A Comprehensive Review on Background, Applications, Key Challenges, Bias, Ethics, Limitations and Future Scope. Internet Things Cyber Phys. Syst. 2023, 3, 121–154. [Google Scholar] [CrossRef]
- Mohammad, A.F.; Clark, B.; Hegde, R. Large Language Model (LLM) & GPT, A Monolithic Study in Generative AI. In Proceedings of the 2023 Congress in Computer Science, Computer Engineering, and Applied Computing, CSCE 2023, Las Vegas, NV, USA, 24–27 July 2023; pp. 383–388. [Google Scholar] [CrossRef]
- Liang, Y.-C.; Ma, S.-P.; Lin, C.-Y. Chatbotification for Web Information Systems: A Pattern-Based Approach. In Proceedings of the 2024 IEEE 48th Annual Computers, Software, and Applications Conference (COMPSAC), Osaka, Japan, 2–4 July 2024; pp. 2290–2295. [Google Scholar] [CrossRef]
- Ross, S.I.; Martinez, F.; Houde, S.; Muller, M.; Weisz, J.D. The Programmer’s Assistant: Conversational Interaction with a Large Language Model for Software Development. In Proceedings of the International Conference on Intelligent User Interfaces, Sydney, Australia, 27–31 March 2023; pp. 491–514. [Google Scholar] [CrossRef]
- Belzner, L.; Gabor, T.; Wirsing, M. Large Language Model Assisted Software Engineering: Prospects, Challenges, and a Case Study. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2024; Volume 14380, pp. 355–374. [Google Scholar] [CrossRef]
- Finnie-Ansley, J.; Denny, P.; Becker, B.A.; Luxton-Reilly, A.; Prather, J. The Robots Are Coming: Exploring the Implications of OpenAI Codex on Introductory Programming. ACM Int. Conf. Proc. Ser. 2022, 22, 10–19. [Google Scholar] [CrossRef]
- Liu, L.; Duffy, V.G. Exploring the Future Development of Artificial Intelligence (AI) Applications in Chatbots: A Bibliometric Analysis. Int. J. Soc. Robot 2023, 15, 703–716. [Google Scholar] [CrossRef]
- Xue, J.; Zhang, B.; Zhao, Y.; Zhang, Q.; Zheng, C.; Jiang, J.; Li, H.; Liu, N.; Li, Z.; Fu, W.; et al. Evaluation of the Current State of Chatbots for Digital Health: Scoping Review. J. Med. Internet Res. 2023, 25, e47217. [Google Scholar] [CrossRef]
- Bellini, F.; Dima, A.M.; Braccini, A.M.; Agrifoglio, R.; Bălan, C. Chatbots and Voice Assistants: Digital Transformers of the Company–Customer Interface—A Systematic Review of the Business Research Literature. J. Theor. Appl. Electron. Commer. Res. 2023, 18, 995–1019. [Google Scholar] [CrossRef]
- Raiaan, M.A.K.; Mukta, M.S.H.; Fatema, K.; Fahad, N.M.; Sakib, S.; Mim, M.M.J.; Ahmad, J.; Ali, M.E.; Azam, S. A Review on Large Language Models: Architectures, Applications, Taxonomies, Open Issues and Challenges. IEEE Access 2024, 12, 26839–26874. [Google Scholar] [CrossRef]
- Hendrycks, D.; Burns, C.; Basart, S.; Zou, A.; Mazeika, M.; Song, D.; Steinhardt, J. Measuring Massive Multitask Language Understanding. In Proceedings of the ICLR 2021—9th International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Sakaguchi, K.; Bras, R.L.; Bhagavatula, C.; Choi, Y. WinoGrande. Commun. ACM 2021, 64, 99–106. [Google Scholar] [CrossRef]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pinto, H.P.O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating Large Language Models Trained on Code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Shi, F.; Suzgun, M.; Freitag, M.; Wang, X.; Srivats, S.; Vosoughi, S.; Chung, H.W.; Tay, Y.; Ruder, S.; Zhou, D.; et al. Language Models Are Multilingual Chain-of-Thought Reasoners. In Proceedings of the 11th International Conference on Learning Representations (ICLR 2023), Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Scoccia, G.L. Exploring Early Adopters’ Perceptions of ChatGPT as a Code Generation Tool. In Proceedings of the 2023 38th IEEE/ACM International Conference on Automated Software Engineering Workshops, ASEW 2023, Luxembourg, 11–15 September 2023; pp. 88–93. [Google Scholar] [CrossRef]
- Vaithilingam, P.; Zhang, T.; Glassman, E.L. Expectation vs. Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models. In Proceedings of the Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 28 April 2022. [Google Scholar] [CrossRef]
- Idrisov, B.; Schlippe, T. Program Code Generation with Generative AIs. Algorithms 2024, 17, 62. [Google Scholar] [CrossRef]
- Jamdade, M.; Liu, Y. A Pilot Study on Secure Code Generation with ChatGPT for Web Applications. In Proceedings of the 2024 ACM Southeast Conference, ACMSE 2024, Marietta, GA, USA, 18–20 April 2024; pp. 229–234. [Google Scholar] [CrossRef]
- Guo, M. Java Web Programming with ChatGPT. In Proceedings of the 2024 5th International Conference on Mechatronics Technology and Intelligent Manufacturing, ICMTIM 2024, Nanjing, China, 26–28 April 2024; pp. 834–838. [Google Scholar] [CrossRef]
- Yang, Z.; Xu, T. Revolutionizing Personalized Web Presence: AI-Powered Automated Website Generation for Streamlined Individual Expression and Accessibility. CS IT Conf. Proc. 2023, 13, 11–19. [Google Scholar] [CrossRef]
- Yetiştiren, B.; Özsoy, I.; Ayerdem, M.; Tüzün, E. Evaluating the Code Quality of AI-Assisted Code Generation Tools: An Empirical Study on GitHub Copilot, Amazon CodeWhisperer, and ChatGPT. arXiv 2023, arXiv:2304.10778. [Google Scholar]
- Su, H.; Ai, J.; Yu, D.; Zhang, H. An Evaluation Method for Large Language Models’ Code Generation Capability. In Proceedings of the 2023 10th International Conference on Dependable Systems and Their Applications, DSA 2023, Tokyo, Japan, 10–11 August 2023; pp. 831–838. [Google Scholar] [CrossRef]
- Pinto, G.; B de Souza, C.R.; Batista Neto, J.; de Souza, A.; Gotto, T.; Monteiro, E. Lessons from Building StackSpot AI: A Contextualized AI Coding Assistant. In Proceedings of the 46th International Conference on Software Engineering: Software Engineering in Practice, Lisbon, Portugal, 14–20 April 2024; Volume 24, pp. 408–417. [Google Scholar] [CrossRef]
- Hansson, E.; Ellréus, O. Code Correctness and Quality in the Era of AI Code Generation: Examining ChatGPT and GitHub Copilot (Dissertation). Bachelor’s Thesis, Linnaeus University, Växjö, Sweden, 2023. Available online: https://urn.kb.se/resolve?urn=urn:nbn:se:lnu:diva-121545 (accessed on 25 October 2024).
- Taeb, M.; Chi, H.; Bernadin, S. Assessing the Effectiveness and Security Implications of AI Code Generators. J. Colloq. Inf. Syst. Secur. Educ. 2024, 11, 6. [Google Scholar] [CrossRef]
- Wong, M.F.; Guo, S.; Hang, C.N.; Ho, S.W.; Tan, C.W. Natural Language Generation and Understanding of Big Code for AI-Assisted Programming: A Review. Entropy 2023, 25, 888. [Google Scholar] [CrossRef]
- Zamfirescu-Pereira, J.D.; Wong, R.Y.; Hartmann, B.; Yang, Q. Why Johnny Can’t Prompt: How Non-AI Experts Try (and Fail) to Design LLM Prompts. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI’23), Hamburg, Germany, 23–28 April 2023; Association for Computing Machinery: New York, NY, USA, 2023; p. 437. [Google Scholar] [CrossRef]
- Liu, M.; Wang, J.; Lin, T.; Ma, Q.; Fang, Z.; Wu, Y. An Empirical Study of the Code Generation of Safety-Critical Software Using LLMs. Appl. Sci. 2024, 14, 1046. [Google Scholar] [CrossRef]
- Sadik, A.R.; Ceravola, A.; Joublin, F.; Patra, J. Analysis of ChatGPT on Source Code. arXiv 2023, arXiv:2306.00597. [Google Scholar]
- Improta, C. Poisoning Programs by Un-Repairing Code: Security Concerns of AI-Generated Code. In Proceedings of the 2023 IEEE 34th International Symposium on Software Reliability Engineering Workshop, ISSREW 2023, Florence, Italy, 9–12 October 2023; pp. 128–131. [Google Scholar] [CrossRef]
- Le, K.T.; Andrzejak, A.; Tuyen Le, K. Rethinking AI Code Generation: A One-Shot Correction Approach Based on User Feedback. Autom. Softw. Eng. 2023, 31, 60. [Google Scholar] [CrossRef]
- Mohamed, N. Current Trends in AI and ML for Cybersecurity: A State-of-the-Art Survey. Cogent Eng. 2023, 10, 2272358. [Google Scholar] [CrossRef]
- Lucchi, N. ChatGPT: A Case Study on Copyright Challenges for Generative Artificial Intelligence Systems. Eur. J. Risk Regul. 2023, 1–23. [Google Scholar] [CrossRef]
- Kuhail, M.A.; Mathew, S.S.; Khalil, A.; Berengueres, J.; Shah, S.J.H. “Will I Be Replaced?” Assessing ChatGPT’s Effect on Software Development and Programmer Perceptions of AI Tools. Sci. Comput. Program 2024, 235, 103111. [Google Scholar] [CrossRef]
- Yeo, S.; Ma, Y.S.; Kim, S.C.; Jun, H.; Kim, T. Framework for Evaluating Code Generation Ability of Large Language Models. ETRI J. 2024, 46, 106–117. [Google Scholar] [CrossRef]
- Sharma, T.; Kechagia, M.; Georgiou, S.; Tiwari, R.; Vats, I.; Moazen, H.; Sarro, F. A Survey on Machine Learning Techniques Applied to Source Code. J. Syst. Softw. 2024, 209, 111934. [Google Scholar] [CrossRef]
- Liu, J.; Xia, C.S.; Wang, Y.; Zhang, L. Is your code generated by ChatGPT really correct? rigorous evaluation of large language models for code generation. In Proceedings of the 37th International Conference on Neural Information Processing Systems (NIPS’23), New Orleans, LA, USA, 10–16 December 2023; Curran Associates Inc.: Red Hook, NY, USA, 2024; pp. 21558–21572. Available online: https://dl.acm.org/doi/10.5555/3666122.3667065 (accessed on 25 October 2024).
- Kiesler, N.; Lohr, D.; Keuning, H. Exploring the Potential of Large Language Models to Generate Formative Programming Feedback. In Proceedings of the Frontiers in Education Conference, FIE, College Station, TX, USA, 18–21 October 2023. [Google Scholar] [CrossRef]
- Santos, R.; Santos, I.; Magalhaes, C.; De Souza Santos, R. Are We Testing or Being Tested? Exploring the Practical Applications of Large Language Models in Software Testing. In Proceedings of the 2024 IEEE Conference on Software Testing, Verification and Validation, ICST 2024, Toronto, ON, Canada, 27–31 May 2024; pp. 353–360. [Google Scholar] [CrossRef]
- Lu, Q.; Zhu, L.; Xu, X.; Liu, Y.; Xing, Z.; Whittle, J. A Taxonomy of Foundation Model Based Systems through the Lens of Software Architecture. In Proceedings of the 2024 IEEE/ACM 3rd International Conference on AI Engineering—Software Engineering for AI, CAIN 2024, Lisbon, Portugal, 14–15 April 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Cowan, B.; Watanobe, Y.; Shirafuji, A. Enhancing Programming Learning with LLMs: Prompt Engineering and Flipped Interaction. In Proceedings of the ACM International Conference Proceeding Series, Aizu-Wakamatsu City, Japan, 29 October 2023; pp. 10–16. [Google Scholar] [CrossRef]
- Sarsa, S.; Denny, P.; Hellas, A.; Leinonen, J. Automatic Generation of Programming Exercises and Code Explanations Using Large Language Models. In Proceedings of the ICER 2022: ACM Conference on International Computing Education Research, Lugano, Switzerland, 7–11 August 2022; Volume 1, pp. 27–43. [Google Scholar] [CrossRef]
- Leinonen, J.; Hellas, A.; Sarsa, S.; Reeves, B.; Denny, P.; Prather, J.; Becker, B.A. Using Large Language Models to Enhance Programming Error Messages. In Proceedings of the SIGCSE 2023: The 54th ACM Technical Symposium on Computer Science Education, Toronto, ON, Canada, 16–18 March 2023; Volume 1, pp. 563–569. [Google Scholar]
- Jiang, E.; Toh, E.; Molina, A.; Olson, K.; Kayacik, C.; Donsbach, A.; Cai, C.J.; Terry, M. Discovering the Syntax and Strategies of Natural Language Programming with Generative Language Models. In Proceedings of the Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022; p. 19. [Google Scholar]
- Moore, O. The Top 100 Gen AI Consumer Apps|Andreessen Horowitz. Available online: https://a16z.com/100-gen-ai-apps/ (accessed on 14 June 2024).
- OpenAI ChatGPT. Available online: https://chatgpt.com/ (accessed on 22 October 2024).
- Microsoft Copilot. Available online: https://copilot.microsoft.com/ (accessed on 22 October 2024).
- Google Gemini. Available online: https://gemini.google.com/ (accessed on 22 October 2024).
- Tabnine Tabnine AI. Available online: https://www.tabnine.com/ (accessed on 22 October 2024).
- Cours Connecte Blackbox AI. Available online: https://www.blackbox.ai/ (accessed on 22 October 2024).
- Pandian, C.R.; SK, M.K. Simple Statistical Methods for Software Engineering: Data and Patterns; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- McConnell, S. Code Complete: A Practical Handbook of Software Construction, 2nd ed.; Microsoft Press: Redmond, WA, USA, 2004; ISBN 978-0735619678. [Google Scholar]
- SQL Validator and Query Fixer. Available online: https://www.sqlvalidator.com/ (accessed on 22 October 2024).
- W3C CSS Validation Service. Available online: https://jigsaw.w3.org/css-validator/ (accessed on 22 October 2024).
- W3C Markup Validation Service. Available online: https://validator.w3.org/ (accessed on 22 October 2024).
- Pengnate, S.; Sarathy, R. Visual Appeal of Websites: The Durability of Initial Impressions. In Proceedings of the Annual Hawaii International Conference on System Sciences, Wailea, HI, USA, 7–10 January 2013; pp. 480–489. [Google Scholar] [CrossRef]
- Barua, A.; Thomas, S.W.; Hassan, A.E. What Are Developers Talking about? An Analysis of Topics and Trends in Stack Overflow. Empir. Softw. Eng. 2014, 19, 619–654. [Google Scholar]
- Maleki, N.G.; Ramsin, R. Agile Web Development Methodologies: A Survey and Evaluation. Stud. Comput. Intell. 2018, 722, 1–25. [Google Scholar] [CrossRef]
- Zheng, L.; Chiang, W.-L.; Sheng, Y.; Zhuang, S.; Wu, Z.; Zhuang, Y.; Lin, Z.; Li, Z.; Li, D.; Xing, E.P.; et al. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. Adv. Neural Inf. Process. Syst. 2023, 36, 46595–46623. [Google Scholar]
- Kiela, D.; Bartolo, M.; Nie, Y.; Kaushik, D.; Geiger, A.; Wu, Z.; Vidgen, B.; Prasad, G.; Singh, A.; Ringshia, P.; et al. Dynabench: Rethinking Benchmarking in NLP. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 4110–4124. [Google Scholar] [CrossRef]
- Fabiano, N. AI Act and Large Language Models (LLMs): When Critical Issues and Privacy Impact Require Human and Ethical Oversight. arXiv 2024, arXiv:2404.00600. [Google Scholar]
- Mökander, J.; Schuett, J.; Kirk, H.R.; Floridi, L. Auditing Large Language Models: A Three-Layered Approach. AI Ethics 2023, 1, 1–31. [Google Scholar] [CrossRef]
- Ding, D.; Mallick, A.; Wang, C.; Sim, R.; Mukherjee, S.; Ruhle, V.; Lakshmanan, L.V.S.; Awadallah, A.H. Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing. arXiv 2024, arXiv:2404.14618. [Google Scholar]
- Chen, L.; Zaharia, M.; Zou, J. Less is More: Using Multiple LLMs for Applications with Lower Costs. Workshop on Efficient Systems for Foundation Models @ ICML2023. 2023. Available online: https://openreview.net/pdf?id=TkXjqcwQ4s (accessed on 25 October 2024).
- Maharana, A.; Lee, D.-H.; Tulyakov, S.; Bansal, M.; Barbieri, F.; Fang, Y. Evaluating Very Long-Term Conversational Memory of LLM Agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 11–16 August 2024; Volume 1, pp. 13851–13870. [Google Scholar] [CrossRef]
- McDonald, D.; Papadopoulos, R.; Benningfield, L. Reducing LLM Hallucination Using Knowledge Distillation: A Case Study with Mistral Large and MMLU Benchmark. TechRxiv 2024. [Google Scholar] [CrossRef]
- Duan, H.; Yang, Y.; Tam, K.Y. Do LLMs Know about Hallucination? An Empirical Investigation of LLM’s Hidden States. arXiv 2024, arXiv:2402.09733. [Google Scholar]
- Haugsbaken, H.; Hagelia, M. A New AI Literacy For The Algorithmic Age: Prompt Engineering Or Eductional Promptization? In Proceedings of the 2024 4th International Conference on Applied Artificial Intelligence, ICAPAI 2024, Halden, Norway, 16 April 2024. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).