



Fall Recognition Based on Time-Level Decision Fusion Classification


Abstract
1. Introduction
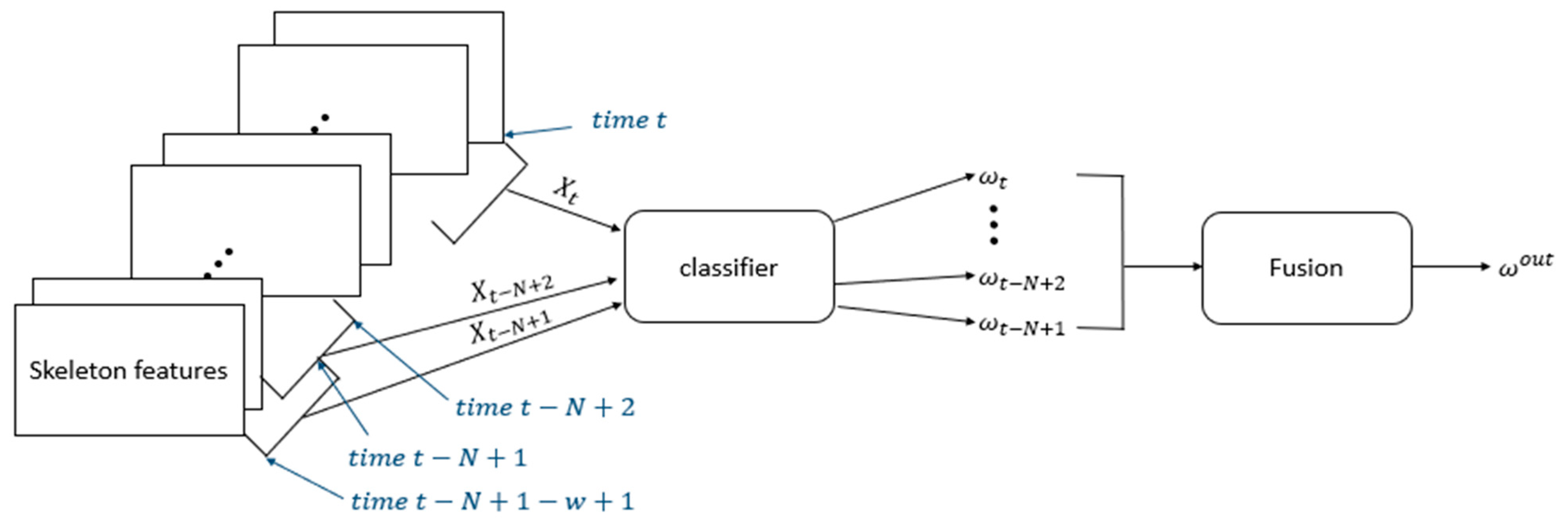
- Using a time-level ensemble, we aggregate the continuous outcomes of the modules. Thus, the system has enhanced robustness and overcomes challenges under difficult conditions. Various fusion methods, including voting-, averaging-, maximum-, and probability-based approaches, are employed.
- Our fall detection system is based on skeleton data, which means that the accuracy of person detection and pose estimation significantly influences the fall detection performance. Through comprehensive performance comparisons with several detection models and pose estimation models, we propose suitable person detection and joint point estimation algorithms for fall detection. In the experiment, YOLOv3 [28] and YOLOv7 [29] were employed to detect individuals. Moreover, AlphaPose [30], a convolutional neural network (CNN)-based approach, and ViTPose [31], which is based on a vision transformer (ViT) [32], were utilized to estimate joint points.
2. Related Work
2.1. Accelerometer-Based Methods
2.2. Radar-Based Methods
2.3. Vision-Based Methods
2.4. Multimodal-Based Methods
3. Fall Detection System
3.1. Person Detection
3.2. Skeleton-Based Feature Extraction
3.3. Classification
3.4. Time-Level Decision Fusion
3.4.1. Voting Method
3.4.2. Average Method
3.4.3. Maximum Method
3.4.4. Probabilistic Fusion Method
4. Experimental Results
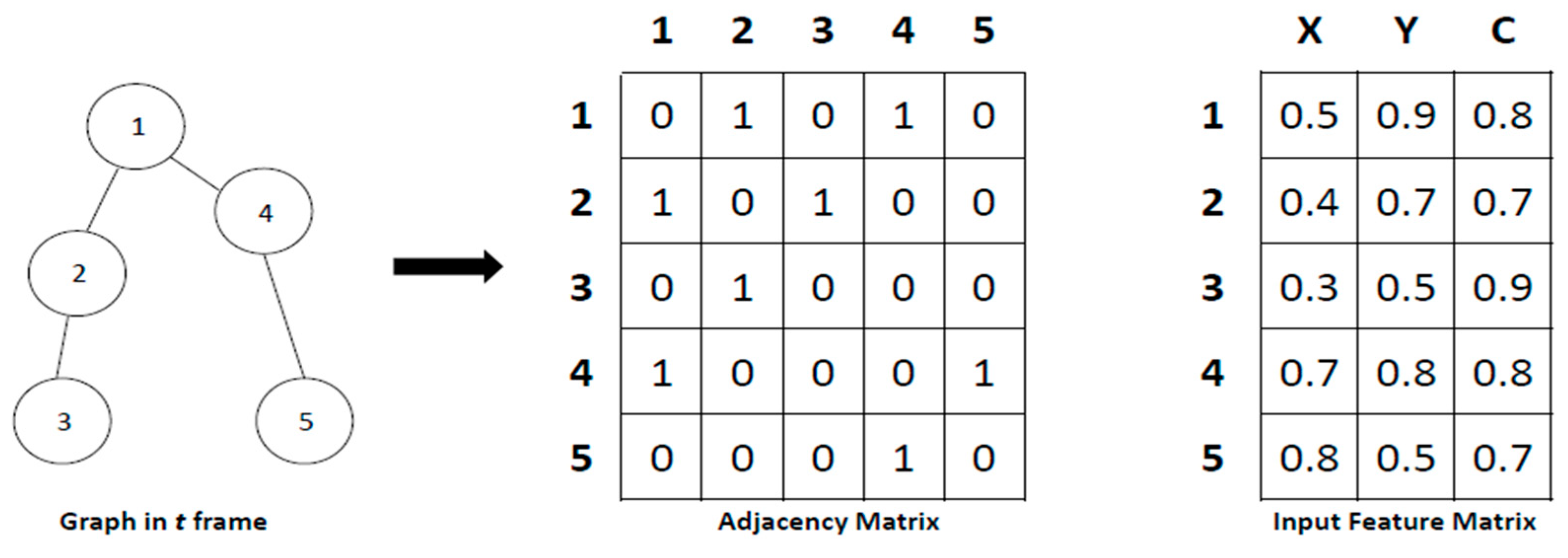
4.1. Graph Construction
4.2. Dataset and Experimental Setup
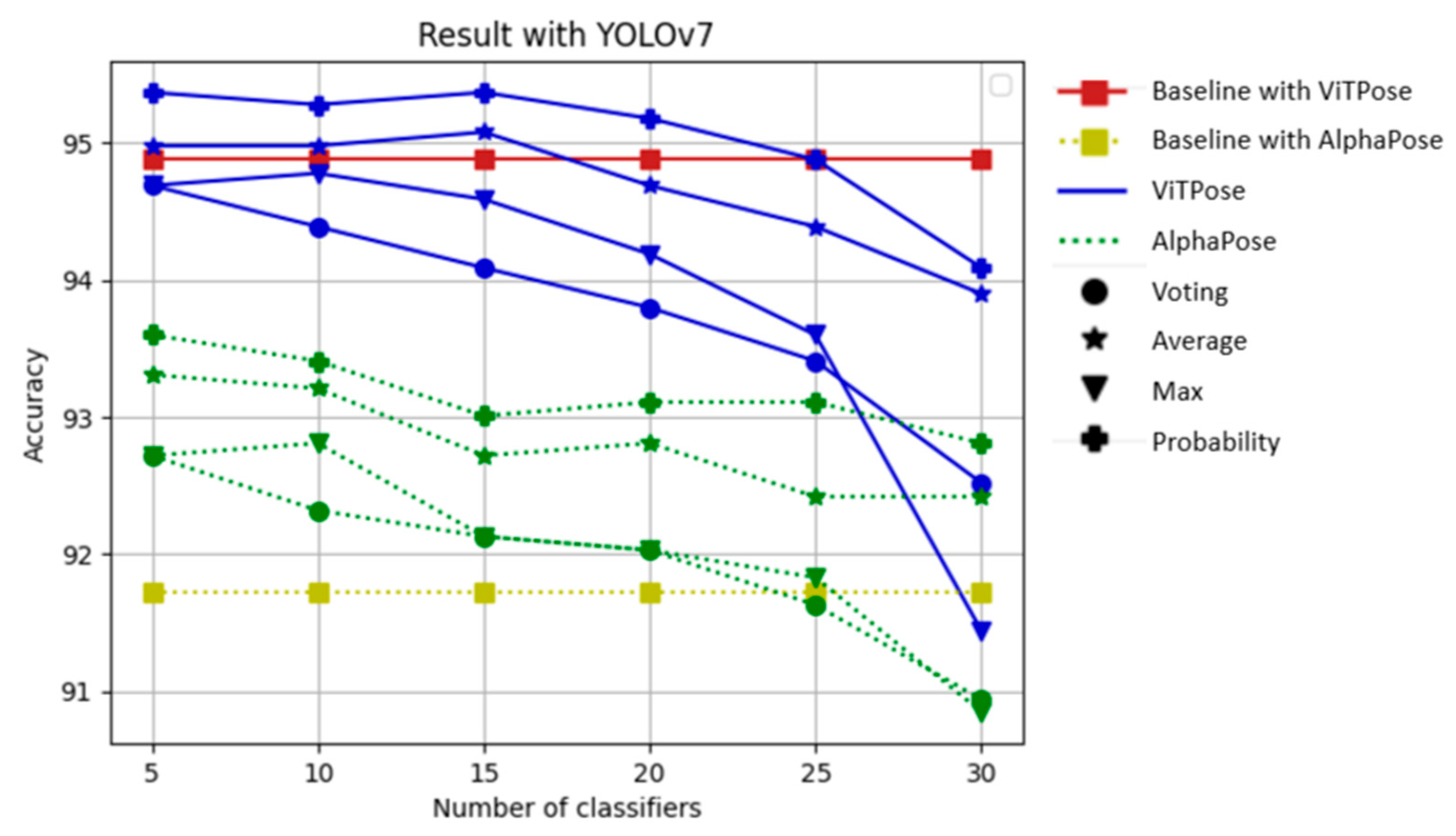
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Seydi, S.T.; Saeidi, V.; Kalantar, B.; Ueda, N.; Halin, A.A. Fire-Net: A Deep Learning Framework for Active Forest Fire Detection. J. Sens. 2022, 2022, 8044390. [Google Scholar] [CrossRef]
- Xie, Y.; Zhu, J.; Cao, Y.; Zhang, Y.; Feng, D.; Zhang, Y.; Chen, M. Efficient video fire detection exploiting motion-flicker-based dynamic features and deep static features. IEEE Access 2020, 8, 81904–81917. [Google Scholar] [CrossRef]
- Zhang, Y. Safety management of civil engineering construction based on artificial intelligence and machine vision technology. Adv. Civ. Eng. 2021, 2021, 1–14. [Google Scholar] [CrossRef]
- Degas, A.; Islam, M.R.; Hurter, C.; Barua, S.; Rahman, H.; Poudel, M.; Ruscio, D.; Ahmed, M.; Begum, S.; Rahman, M.; et al. A survey on artificial intelligence (ai) and explainable ai in air traffic management: Current trends and development with future research trajectory. Appl. Sci. 2022, 12, 1295. [Google Scholar] [CrossRef]
- Industrial Accident Analysis Booklet; Ministry of Employment and Labor of South Korea: Sejong, Republic of Korea, 2021; p. 12.
- Shany, T.; Redmond, S.J.; Narayanan, M.R.; Lovell, N.H. Sensors-based wearable systems for monitoring of human movement and falls. IEEE Sens. J. 2011, 12, 658–670. [Google Scholar] [CrossRef]
- Lindemann, U.; Hock, A.; Stuber, M.; Keck, W.; Becker, C. Evaluation of a fall detector based on accelerometers: A pilot study. Med. Biol. Eng. Comput. 2005, 43, 548–551. [Google Scholar] [CrossRef]
- Gibson, R.M.; Amira, A.; Ramzan, N.; Casaseca-de-la-Higuera, P.; Pervez, Z. Multiple comparator classifier framework for accelerometer-based fall detection and diagnostic. Appl. Soft Comput. 2016, 39, 94–103. [Google Scholar] [CrossRef]
- Jeong, S.S.; Kim, N.H.; Yu, Y.S. Fall Detection System Based on Simple Threshold Method and Long Short-Term Memory: Comparison with Hidden Markov Model and Extraction of Optimal Parameters. Appl. Sci. 2022, 12, 11031. [Google Scholar] [CrossRef]
- Cippitelli, E.; Fioranelli, F.; Gambi, E.; Spinsante, S. Radar and RGB-depth sensors for fall detection: A review. IEEE Sens. J. 2017, 17, 3585–3604. [Google Scholar] [CrossRef]
- Garripoli, C.; Mercuri, M.; Karsmakers, P.; Soh, P.J.; Crupi, G.; Vandenbosch, G.A.; Pace, C.; Leroux, P.; Schreurs, D. Embedded DSP-based telehealth radar system for remote in-door fall detection. IEEE J. Biomed. Health Inform. 2014, 19, 92–101. [Google Scholar] [CrossRef]
- Wang, B.; Guo, Y. Soft fall detection using frequency modulated continuous wave radar and regional power burst curve. In Proceedings of the 2022 Asia-Pacific Microwave Conference (APMC), Yokohama, Japan, 29 November–2 December 2022; pp. 240–242. [Google Scholar]
- Takabatake, W.; Yamamoto, K.; Toyoda, K.; Ohtsuki, T.; Shibata, Y.; Nagate, A. FMCW radar-based anomaly detection in toilet by supervised machine learning classifier. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Cippitelli, E.; Gasparrini, S.; Gambi, E.; Spinsante, S. A human activity recognition system using skeleton data from RGBD sensors. Comput. Intell. Neurosci. 2016, 2016, 4351435. [Google Scholar] [CrossRef]
- Panahi, L.; Ghods, V. Human fall detection using machine vision techniques on RGB–D images. Biomed. Signal Process. Control 2018, 44, 146–153. [Google Scholar] [CrossRef]
- Keskes, O.; Noumeir, R. Vision-based fall detection using st-gcn. IEEE Access 2021, 9, 28224–28236. [Google Scholar] [CrossRef]
- Lie, W.N.; Le, A.T.; Lin, G.H. Human fall-down event detection based on 2D skeletons and deep learning approach. In Proceedings of the 2018 International Workshop on Advanced Image Technology (IWAIT), Chiang Mai, Thailand, 7–9 January 2018; pp. 1–4. [Google Scholar]
- Ramirez, H.; Velastin, S.A.; Meza, I.; Fabregas, E.; Makris, D.; Farias, G. Fall detection and activity recognition using human skeleton features. IEEE Access 2021, 9, 33532–33542. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.H.; Lee, H. Fall down detection using vision transformer and graph convolutional network. J. Korean Soc. Railw. 2023, 26, 251–259. [Google Scholar] [CrossRef]
- Galvão, Y.M.; Portela, L.; Ferreira, J.; Barros, P.; Fagundes, O.A.D.A.; Fernandes, B.J. A framework for anomaly identification applied on fall detection. IEEE Access 2021, 9, 77264–77274. [Google Scholar] [CrossRef]
- Alanazi, T.; Muhammad, G. Human fall detection using 3D multi-stream convolutional neural networks with fusion. Diagnostics 2022, 12, 3060. [Google Scholar] [CrossRef]
- Alanazi, T.; Babutain, K.; Muhammad, G. A Robust and Automated Vision-Based Human Fall Detection System Using 3D Multi-Stream CNNs with an Image Fusion Technique. Appl. Sci. 2023, 13, 6916. [Google Scholar] [CrossRef]
- Lara, O.D.; Pérez, A.J.; Labrador, M.A.; Posada, J.D. Centinela: A human activity recognition system based on acceleration and vital sign data. Pervasive Mob. Comput. 2012, 8, 717–729. [Google Scholar] [CrossRef]
- Li, H.; Shrestha, A.; Heidari, H.; Le Kernec, J.; Fioranelli, F. Bi-LSTM network for multimodal continuous human activity recognition and fall detection. IEEE Sens. J. 2019, 20, 1191–1201. [Google Scholar] [CrossRef]
- Chahyati, D.; Hawari, R. Fall detection on multimodal dataset using convolutional neural network and long short term memory. In Proceedings of the 2020 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Depok, Indonesia, 17–18 October 2020; pp. 371–376. [Google Scholar]
- Wang, X.; Penta, R.; Sehgal, B.; Chen-Song, D. Human fall detection-multimodality approach. arXiv 2023, arXiv:2302.00224. [Google Scholar]
- Martínez-Villaseñor, L.; Ponce, H.; Brieva, J.; Moya-Albor, E.; Núñez-Martínez, J.; Peñafort-Asturiano, C. UP-fall detection dataset: A multimodal approach. Sensors 2019, 19, 1988. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2334–2343. [Google Scholar]
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. Vitpose: Simple vision transformer baselines for human pose estimation. Adv. Neural Inf. Process. Syst. 2022, 35, 38571–38584. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 21–26 June 2016; pp. 779–788. [Google Scholar]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing System, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 24–27 June 2018; pp. 7132–7141. [Google Scholar]
- Yao, L.; Miller, J. Tiny imagenet classification with convolutional neural networks. CS 231n 2015, 2, 8. [Google Scholar]
- Lee, H.; Hong, S.; Kim, E. Neural network ensemble with probabilistic fusion and its application to gait recognition. Neurocomputing 2009, 72, 1557–1564. [Google Scholar] [CrossRef]
- Thrun, S.; Burgard, W.; Fox, D. Probabilistic Robotics; MIT Press: Cambridge, MA, USA, 2005; p. 28. [Google Scholar]
- Human-Falling-Detect-Tracks. Available online: https://github.com/GajuuzZ/Human-Falling-Detect-Tracks (accessed on 1 December 2023).
- Yadav, S.K.; Luthra, A.; Tiwari, K.; Pandey, H.M.; Akbar, S.A. ARFDNet: An efficient activity recognition & fall detection system using latent feature pooling. Knowl. Based Syst. 2022, 239, 107948. [Google Scholar]
- Raza, A.; Yousaf, M.H.; Velastin, S.A.; Viriri, S. Human fall detection from sequences of skeleton features using vision transformer. In Proceedings of the 18th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Lisbon, Porutugal, 8–10 February 2023; pp. 591–598. [Google Scholar]
- Kwolek, B.; Kepski, M. Human fall detection on embedded platform using depth maps and wireless accelerometer. Comput. Methods Programs Biomed. 2014, 117, 489–501. [Google Scholar] [CrossRef]
- Alzahrani, M.S.; Jarraya, S.K.; Salamah, M.A.; Ben-Abdallah, H. FallFree: Multiple fall scenario dataset of cane users for monitoring applications using kinect. In Proceedings of the International Conference on Signal-Image Technology & Internet-Based Systems, Jaipur, India, 4–7 December 2017; pp. 327–333. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Pros | Cons |
|---|---|---|
| Accelerometer | Sensor sensitivity | Limitation in catching the global movements of the body caused by the number of attached sensors. Devices have to be worn. |
| Radar | Low-light condition performance Privacy friendliness | Limitation in recognizing different postures. Difficulty in distinguishing between the fall of objects and humans. |
| Vision | Capture of global body posture is possible No requirements are imposed on users | Vulnerability in low-light conditions. |
| Multimodal | Enhancement in performance through the utilization of abundant information | Decreased inference time due to processing of various sensor values. |
| Author | Pros | Cons | Dataset |
|---|---|---|---|
| Panahi, L., 2018 [15] | Fit a person’s silhouette on the ellipses and observe the changes in the ellipses and detect fall. In general, the extraction accuracy of silhouette is higher than skeleton coordinate prediction accuracy, so the performance degradation due to the silhouette step is less. | It is difficult to detect detailed body movements because the method creates an ellipse by fitting silhouettes and observes changes in the ellipse to detect falls. | UR-Fall |
| Lie, W. N., 2018 [17] | It is possible to extract the temporal characteristics of the skeleton sequence because the predicted skeleton is used as an input for the LSTM | There is less temporal information using only 8 frames of input. And it is difficult to convey the relationship between the joints because the skeleton coordinate value itself is used as the input. | Private dataset |
| Keskes, O., 2021 [16] | This study uses 3D skeleton sequences as inputs and classifies them using ST-GCN models, so all spatial–temporal information can be considered. | Since 3D skeleton predictions are less accurate than 2D skeleton predictions, incorrect 3D coordinate predictions are likely to occur in a real-world environment. This may result in performance degradation. | TST v2 Fallfree dataset |
| Ramirez, H., 2021 [18] | The authors present a comparison of various ML models as classifiers. | Because it detects falling in frame, input data do not contain temporal information. | HAR-UP UR-FALL |
| Galvão, Y. M., 2021 [20] | The authors trained an encoder–decoder model using action features extracted from the pre-trained ST-GCN. By using only data on activities of daily living (ADL) as the dataset for training the encoder–decoder model, it can address the scarcity of fall data. | It is trained on ADL data, not fall data, and if the likelihood of an action as an ADL is below a certain level, it is classified as a fall. So there is a possibility of classifying actions as falls that are neither falls nor ADL. | PRECIS HAR, HAR-UP UR-Fall |
| Kim, J., 2023 [19] | Using the ST-GCN model as a classifier, spatial–temporal information can be considered. | Person detection that precedes the extraction of skeleton data does not work well. | HAR-UP |
| Alanazi, T., 2023 [22] | The proposed image fusion method converts multiple frames into a richly informative image to detect falls. | Since it is based on segmentation, a person’s clothes and belongings can be reflected in the silhouette and post-processing is required for incorrect segmentation | Le2i fall detection dataset |
| Model | Data Type | Parameters | Input | Output |
|---|---|---|---|---|
| YOLOV3 | RGB image | 8,669,876 | (640, 480) | (1, 7) |
| YOLOV7 | RGB image | 36,905,341 | (640, 480) | (1, 7) |
| AlphaPose | RGB image | 40,577,745 | (256, 192) | (3, 13) |
| ViTPose | RGB image | 89,994,513 | (256, 192) | (3, 13) |
| ST-GCN | Skeleton data | 6,144,323 | (3, 13, 30) | (1, 2) |
| Type | Main Specification |
|---|---|
| OS | Ubuntu 20.04LTS |
| GPU | NVIDIA GeForce RTX 3090 |
| CPU | Intel Core i9 13900KF |
| RAM | DDR5, 64GB |
| Fusion Method | Optimal Number of Classifiers | Model | Data Label | Precision (%) | Recall (%) | Accuracy (%) |
|---|---|---|---|---|---|---|
| Baseline | - | ViTPose | Fall | 97.49 | 91.57 | 94.59 |
| Normal | 91.99 | 97.63 | ||||
| AlphaPose | Fall | 93.65 | 89.61 | 91.73 | ||
| Normal | 89.96 | 93.87 | ||||
| Probability | 10 | ViTPose | Fall | 97.90 | 91.37 | 94.69 |
| Normal | 91.85 | 98.02 | ||||
| AlphaPose | Fall | 93.94 | 91.18 | 92.62 | ||
| Normal | 91.36 | 94.07 | ||||
| Average | 5 | ViTPose | Fall | 97.26 | 90.59 | 94.00 |
| Normal | 91.13 | 97.43 | ||||
| AlphaPose | Fall | 93.87 | 90.00 | 92.03 | ||
| Normal | 90.32 | 94.07 | ||||
| Max | 5 | ViTPose | Fall | 97.46 | 90.39 | 94.00 |
| Normal | 90.98 | 97.63 | ||||
| AlphaPose | Fall | 93.78 | 88.63 | 91.34 | ||
| Normal | 89.14 | 94.07 | ||||
| Voting | 5 | ViTPose | Fall | 98.28 | 89.80 | 94.09 |
| Normal | 90.55 | 98.42 | ||||
| AlphaPose | Fall | 93.78 | 88.63 | 91.34 | ||
| Normal | 89.14 | 94.07 |
| Fusion Method | Optimal Number of Classifiers | Model | Data Label | Precision (%) | Recall (%) | Accuracy (%) |
|---|---|---|---|---|---|---|
| Baseline | - | ViTPose | Fall | 96.73 | 92.94 | 94.88 |
| Normal | 93.16 | 96.84 | ||||
| AlphaPose | Fall | 93.65 | 89.61 | 91.73 | ||
| Normal | 89.96 | 93.87 | ||||
| Probability | 5 | ViTPose | Fall | 97.15 | 93.53 | 95.37 |
| Normal | 93.71 | 97.23 | ||||
| AlphaPose | Fall | 95.69 | 91.37 | 93.60 | ||
| Normal | 91.68 | 95.85 | ||||
| Average | 15 | ViTPose | Fall | 91.96 | 98.12 | 95.08 |
| Normal | 98.22 | 92.38 | ||||
| AlphaPose | Fall | 88.82 | 96.38 | 92.72 | ||
| Normal | 96.64 | 89.56 | ||||
| Max | 10 | ViTPose | Fall | 91.76 | 97.70 | 94.78 |
| Normal | 97.83 | 92.18 | ||||
| AlphaPose | Fall | 89.22 | 96.19 | 92.81 | ||
| Normal | 96.44 | 89.87 | ||||
| Voting | 5 | ViTPose | Fall | 97.70 | 91.57 | 94.69 |
| Normal | 92.01 | 97.83 | ||||
| AlphaPose | Fall | 95.61 | 89.61 | 92.72 | ||
| Normal | 90.15 | 95.85 |
| Model | Action | Predicted Value | Fall | Normal | Recall (%) | |
|---|---|---|---|---|---|---|
| Actual Value | ||||||
| ViTPose | 1 | Fall | 98 | 4 | 96.08 | |
| AlphaPose | 101 | 1 | 99.02 | |||
| ViTPose | 2 | Fall | 88 | 14 | 86.27 | |
| AlphaPose | 81 | 21 | 79.41 | |||
| ViTPose | 3 | Fall | 96 | 6 | 94.12 | |
| AlphaPose | 93 | 9 | 91.18 | |||
| ViTPose | 4 | Fall | 96 | 6 | 94.12 | |
| AlphaPose | 92 | 10 | 90.20 | |||
| ViTPose | 5 | Fall | 99 | 3 | 97.06 | |
| AlphaPose | 99 | 3 | 97.06 | |||
| ViTPose | 7 | Normal (Standing) | 0 | 102 | 100 | |
| AlphaPose | 0 | 102 | 100 | |||
| ViTPose | 8 | Normal (Sitting) | 0 | 102 | 100 | |
| AlphaPose | 0 | 102 | 100 | |||
| ViTPose | 9 | Normal (Picking up) | 4 | 98 | 96.08 | |
| AlphaPose | 5 | 97 | 95.10 | |||
| ViTPose | 10 | Normal (Jumping) | 0 | 102 | 100 | |
| AlphaPose | 0 | 102 | 100 | |||
| ViTPose | 11 | Normal (Lying down) | 10 | 88 | 89.80 | |
| AlphaPose | 16 | 82 | 83.67 | |||
| Author | Classifier | Accuracy (%) |
|---|---|---|
| Martínez-Villaseñor, L., 2019 [27] | CNN | 95.10 |
| Ramirez, H., 2021 [18] | RF | 99.34 |
| Galvão, Y. M., 2021 [20] | Encoder–decoder | 98.62 |
| Yadav, S. K., 2022 [42] | ARFDNet | 96.70 |
| Raza, A., 2023 [43] | ViT | 97.36 |
| Proposed method | ST-GCN with probabilistic fusion | 99.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Kim, B.; Lee, H. Fall Recognition Based on Time-Level Decision Fusion Classification. Appl. Sci. 2024, 14, 709. https://doi.org/10.3390/app14020709
Kim J, Kim B, Lee H. Fall Recognition Based on Time-Level Decision Fusion Classification. Applied Sciences. 2024; 14(2):709. https://doi.org/10.3390/app14020709
Chicago/Turabian StyleKim, Juyoung, Beomseong Kim, and Heesung Lee. 2024. "Fall Recognition Based on Time-Level Decision Fusion Classification" Applied Sciences 14, no. 2: 709. https://doi.org/10.3390/app14020709
APA StyleKim, J., Kim, B., & Lee, H. (2024). Fall Recognition Based on Time-Level Decision Fusion Classification. Applied Sciences, 14(2), 709. https://doi.org/10.3390/app14020709