
Enhanced Intrusion Detection with LSTM-Based Model, Feature Selection, and SMOTE for Imbalanced Data

Abstract
1. Introduction
Existing IoT Security Solutions and Their Limitations
- LSTM-Based Deep Learning: By incorporating long short-term memory (LSTM) networks into our intrusion detection system (IDS), we introduce a novel approach to IoT security. LSTM’s ability to model sequential data enables our system to capture and recognize evolving cyber threats, thus enhancing the adaptability and responsiveness of our IDS.
- SMOTE for Data Imbalance: Addressing the inherent data imbalance in IoT security datasets is a critical challenge. Through the synthetic minority over-sampling technique (SMOTE), our research takes a proactive stance, enabling our IDS to learn from underrepresented threat instances. This approach strengthens the overall robustness of our system.
- Random Forest Classifier–RFE for Feature Selection: Feature selection plays a pivotal role in optimizing the performance of an IDS. Our use of the random forest with recursive feature elimination (RFE) ensures that our system operates with a streamlined and relevant set of features, reducing computational overhead while preserving detection accuracy.
2. Literature Review
- Significance of the Proposed Methodology:
- Advancements Over Published Literature:
- Real-World Relevance:
2.1. AI-Based Intrusion Detection in IoT
2.2. Addressing Data Imbalance with SMOTE
2.3. Optimizing Feature Selection with Random Forest
2.4. Comprehensive Evaluation of Public Datasets
- Comparison Experiment:
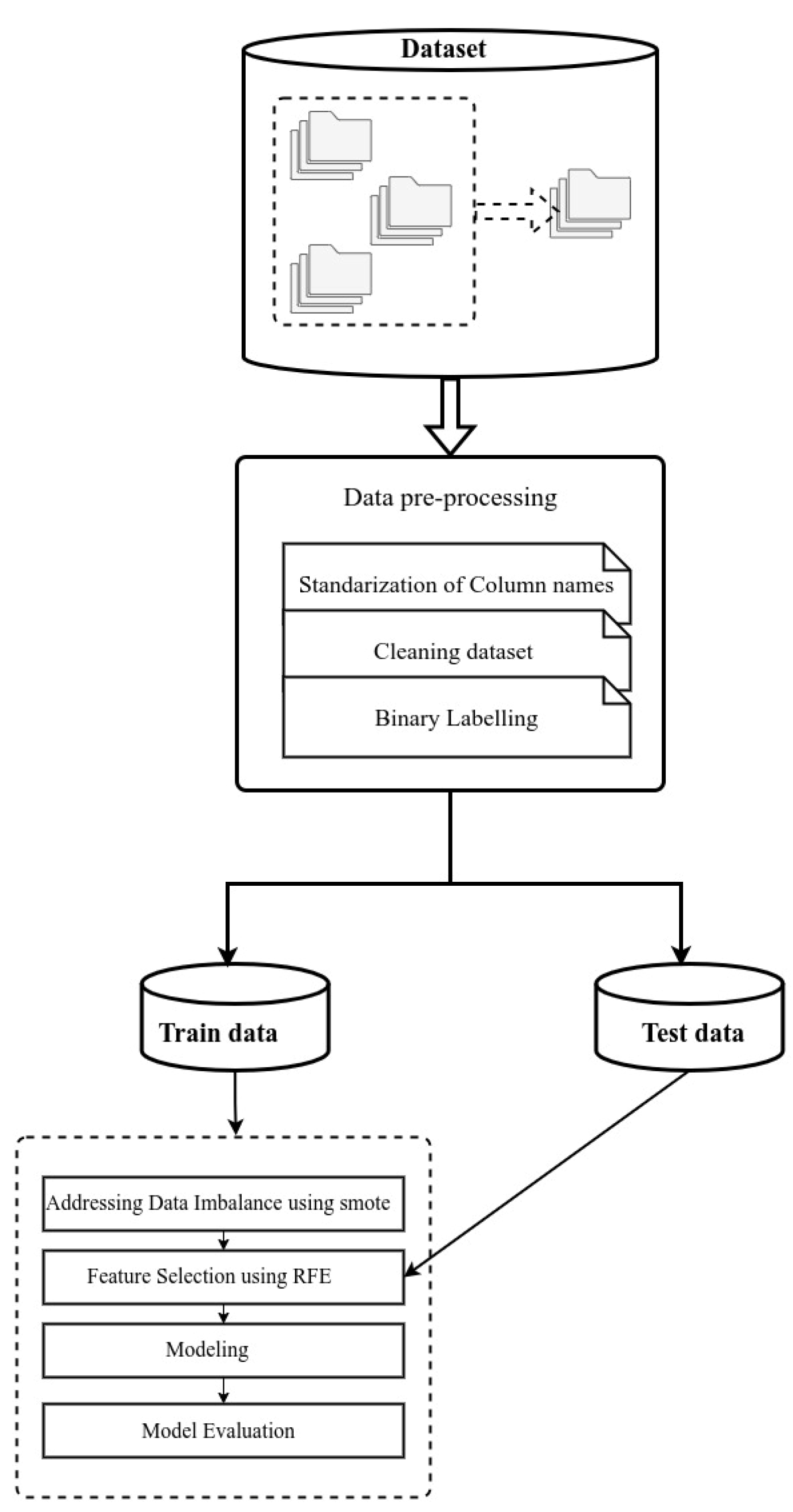
3. Methodology
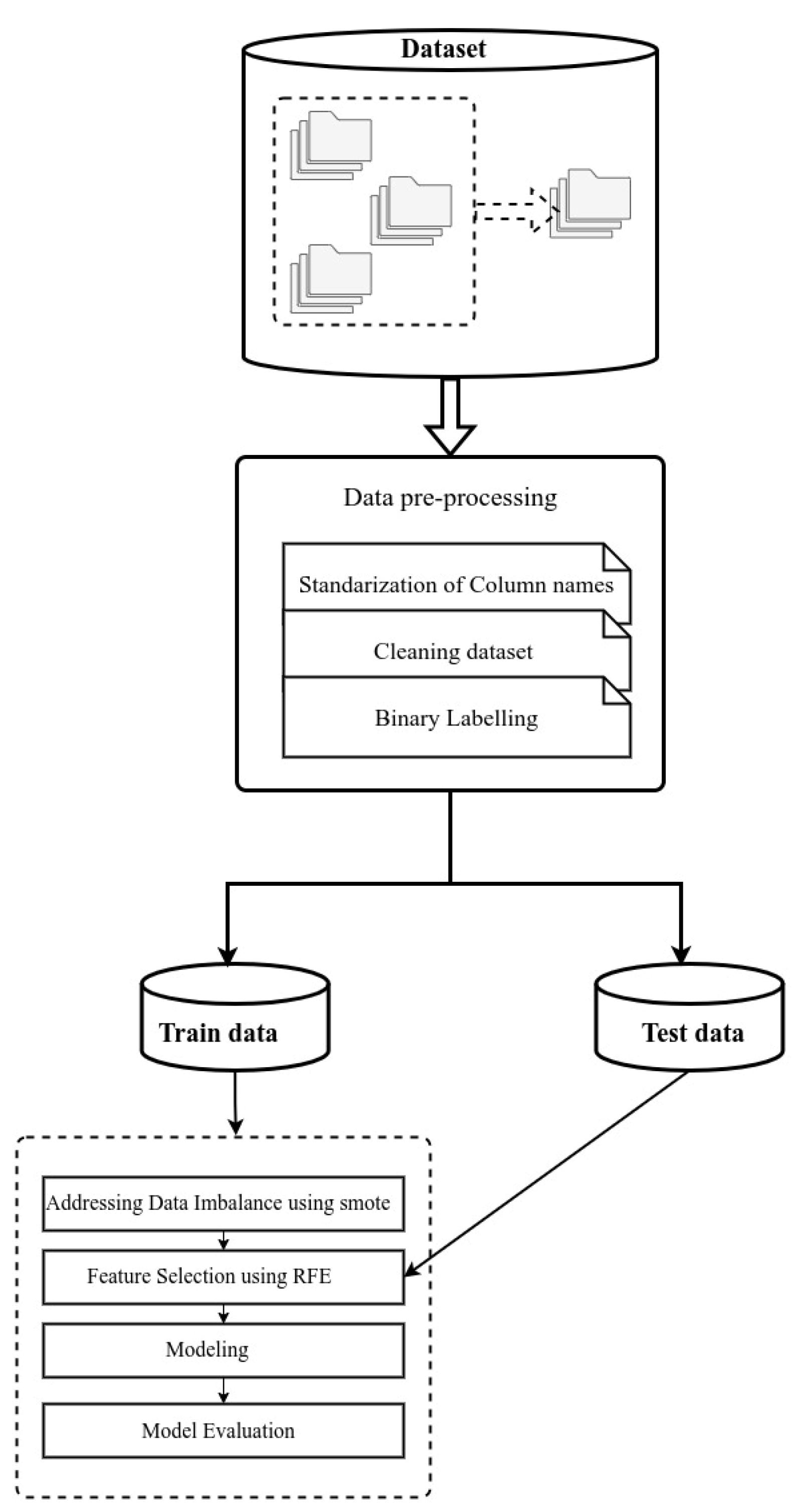
3.1. Dataset and Data Preprocessing
3.1.1. Dataset Selection
Intrusion Detection Evaluation Dataset (CIC-IDS2017)
NSL-KDD
The UNSW-NB15 Dataset
3.1.2. Data Preprocessing
Binary Labeling
Addressing Data Imbalance
Feature Selection
- Initialization: we start by creating a random forest classifier model, which serves as the base estimator for the RFE algorithm.
- Recursive Elimination: The RFE algorithm recursively eliminates the least important features by retraining the model at each iteration. Features are ranked based on their contribution to the classification task, and the least significant feature is removed.
- Convergence: The recursive elimination process continues until the desired number of features is reached. In our case, we select the top 20 features with the highest importance scores.
- Enhanced Model Efficiency: with a reduced feature set, the IDS can process data more efficiently and expedite the intrusion detection process.
- Improved Model Interpretability: the selected features provide a concise representation of relevant information, facilitating easier interpretation of the IDS’s decision-making process.
- Optimized Performance: by focusing on the most informative attributes, the IDS can achieve higher accuracy in distinguishing between normal network traffic and potential cyber threats.
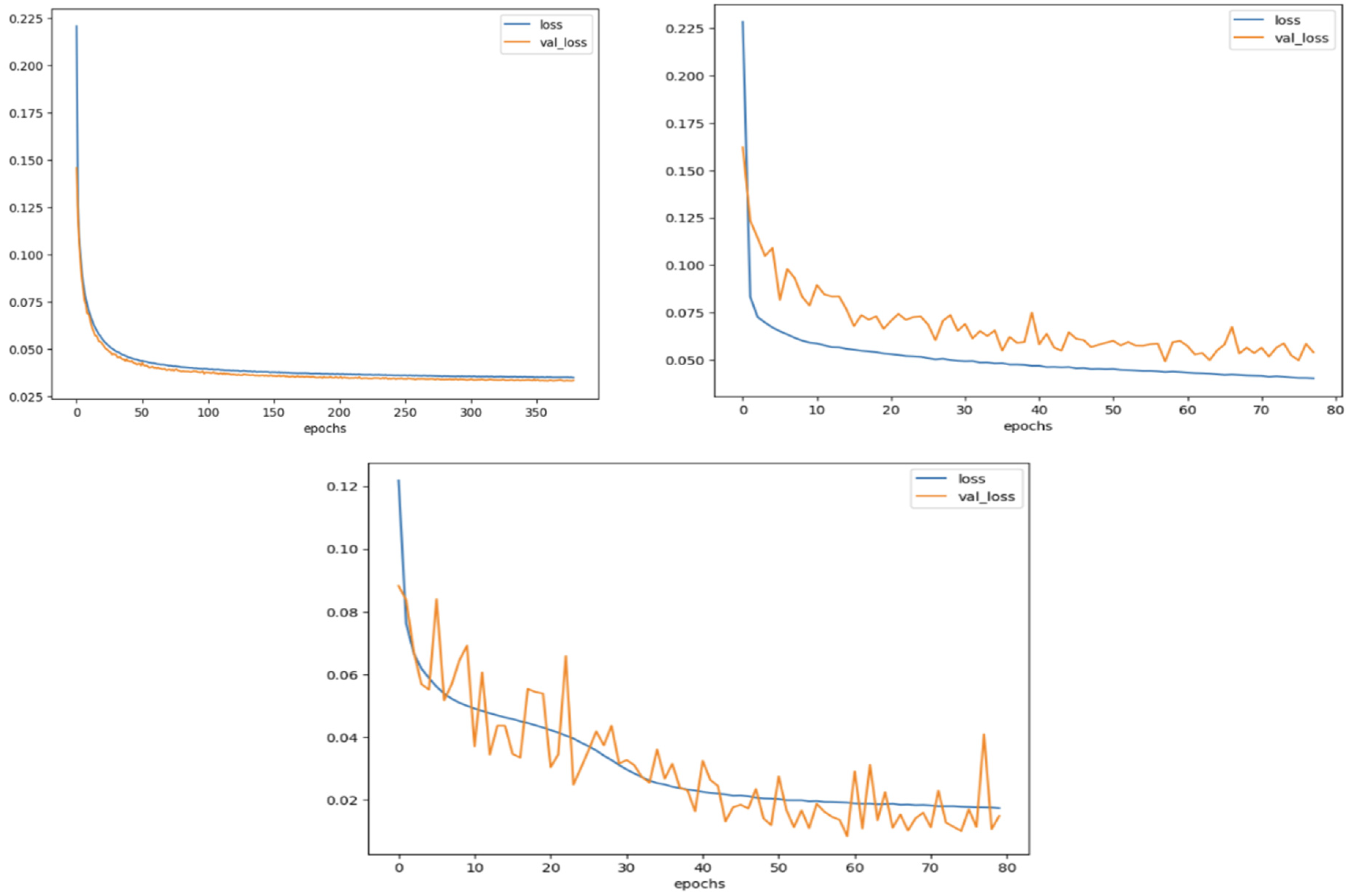
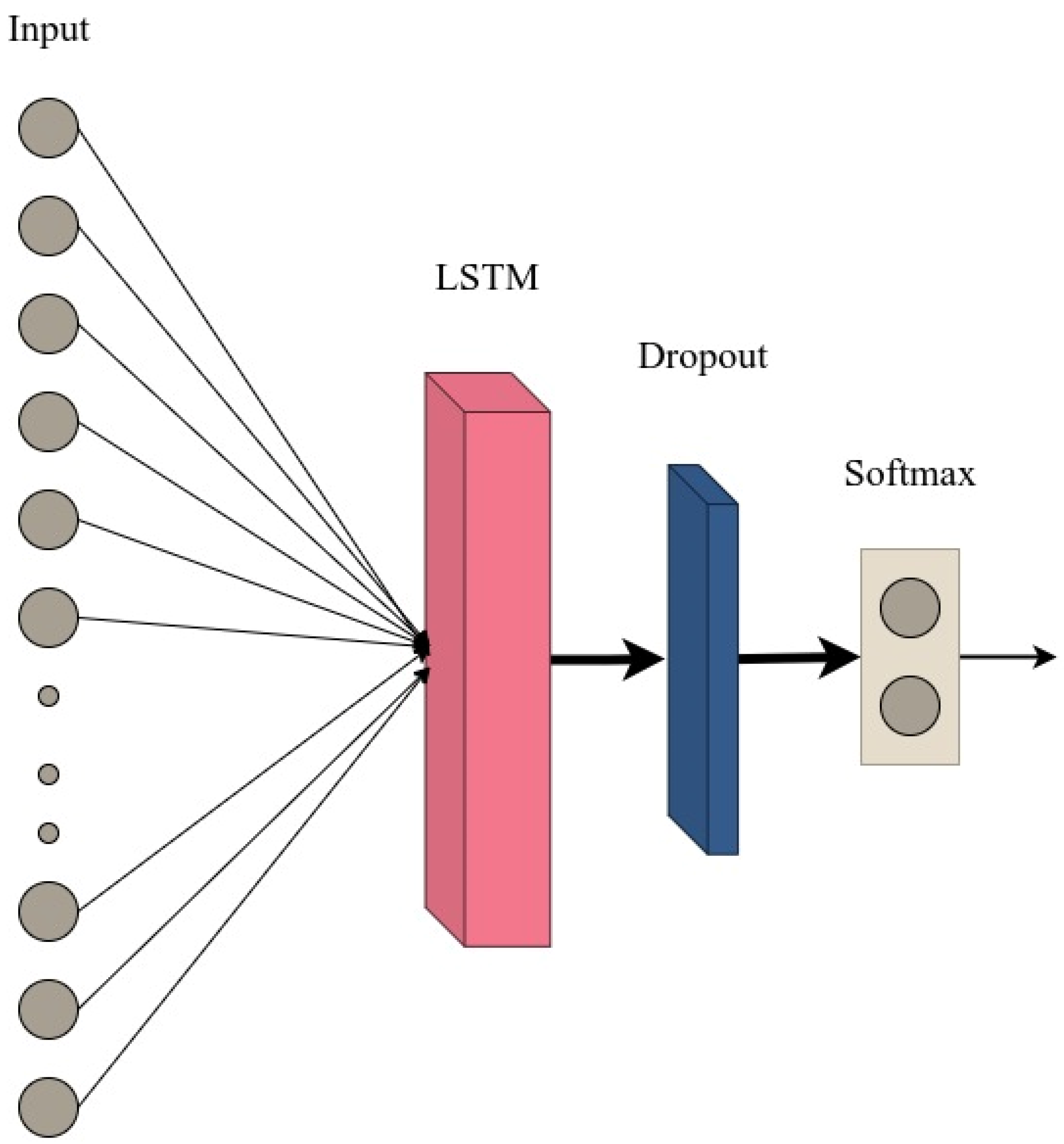
3.2. Model Architecture
3.2.1. Long Short-Term Memory (LSTM)
- Cell State (C_t): Serving as the memory component, the cell state enables the LSTM to retain essential information over time. It selectively regulates the information to be stored or discarded through specialized gates, allowing the network to learn long-term dependencies from the data.
- Input Gate (i_t): The input gate controls the flow of new information into the cell state. It decides which values from the current input and the previous hidden state should be incorporated into the cell state.
- Forget Gate (f_t): The forget gate determines which information from the cell state should be forgotten. It allows the LSTM to selectively discard irrelevant or outdated information from previous time steps.
- Output Gate (o_t): The output gate governs the filtering of the cell state’s information to compute the current hidden state. It regulates the information to be propagated to the next time step.
- Input Gate (i_t):
- Forget Gate (f_t):
- Output Gate (o_t):
- Cell State Update:
- Hidden State (h_t):
3.2.2. Model Architecture
4. Performance Evaluation and Comparison
4.1. Evaluation Metrics
4.1.1. Accuracy
4.1.2. Precision
4.1.3. Recall (Sensitivity or True Positive Rate)
4.1.4. F1-Score
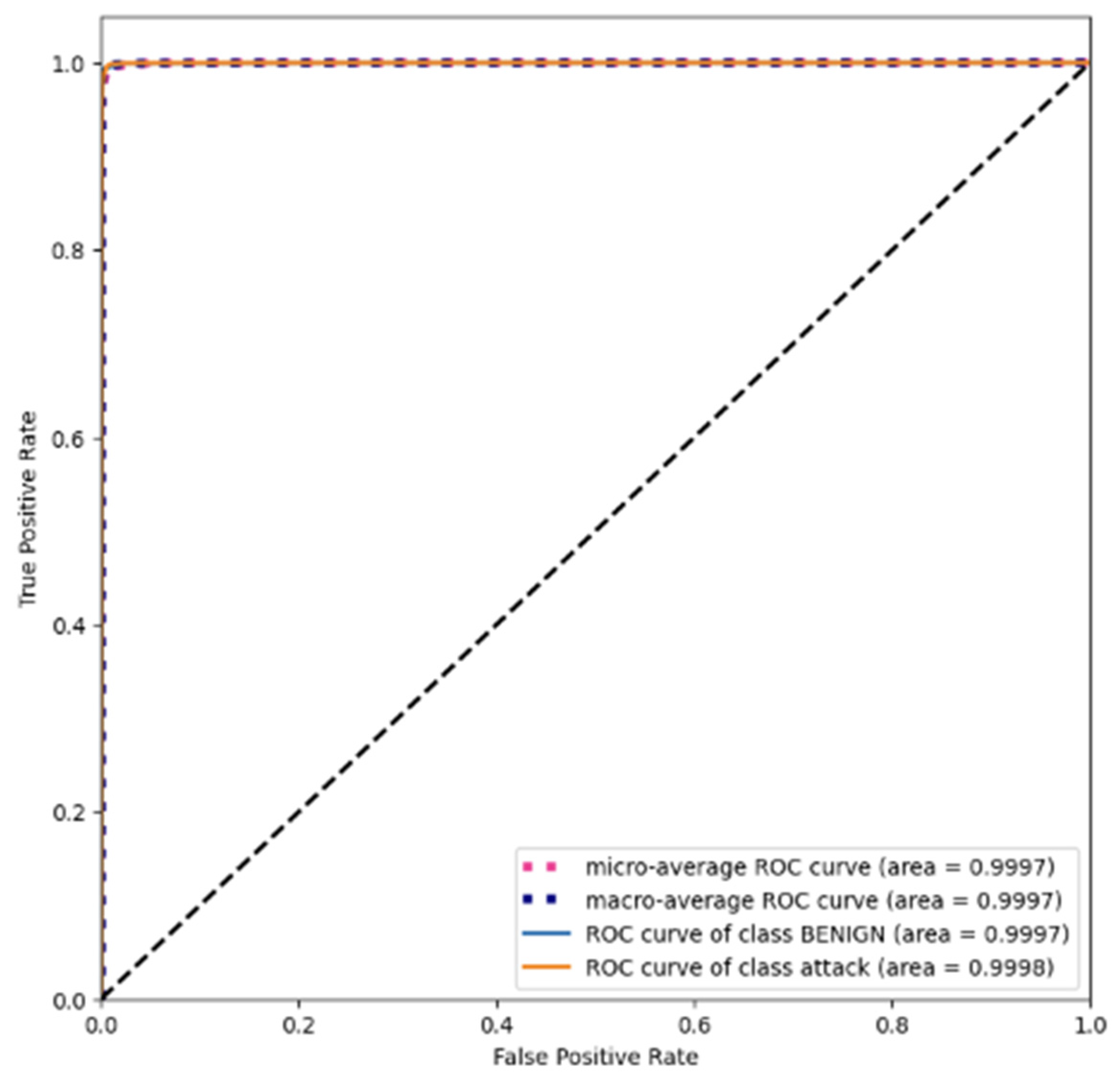
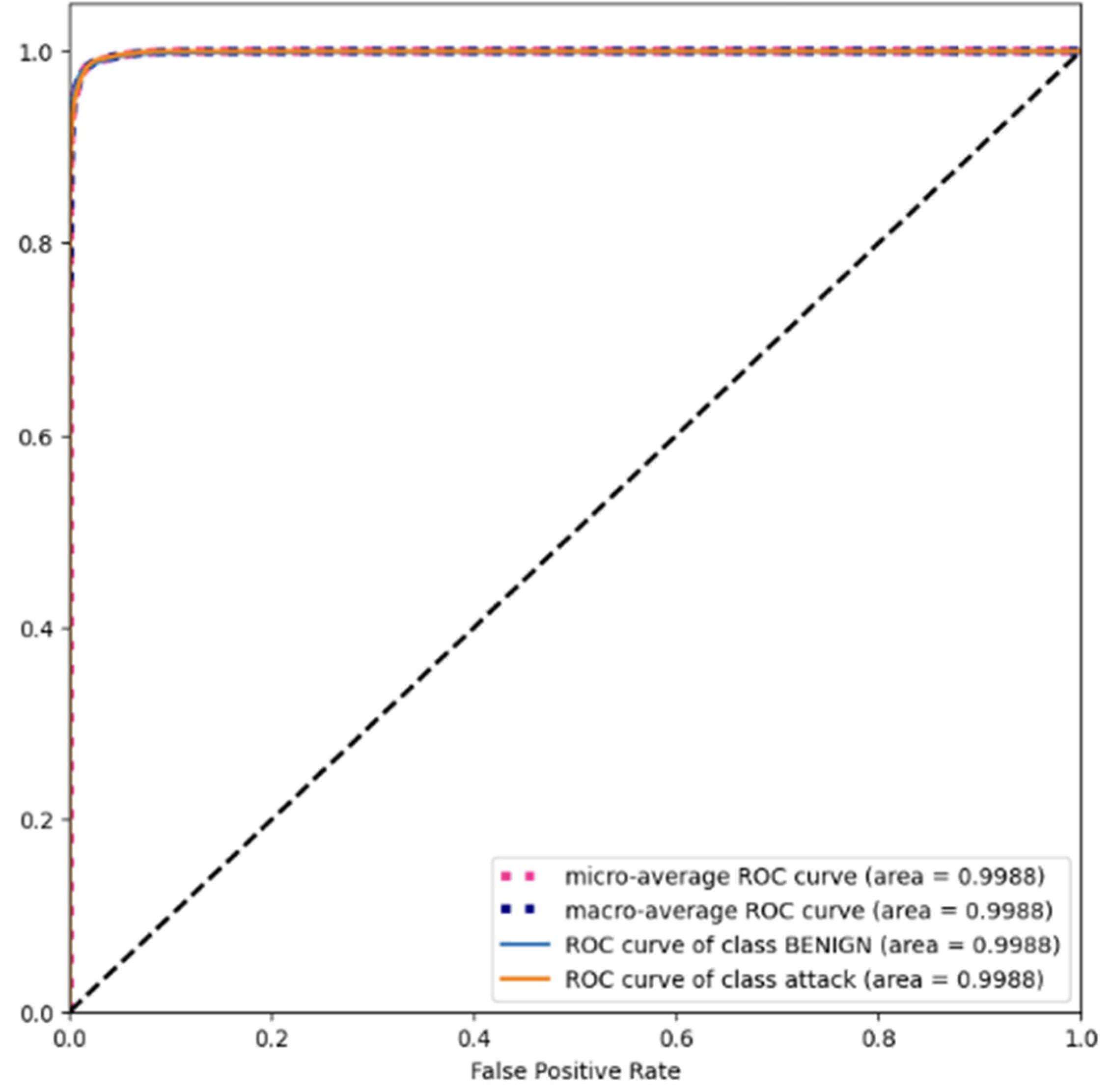
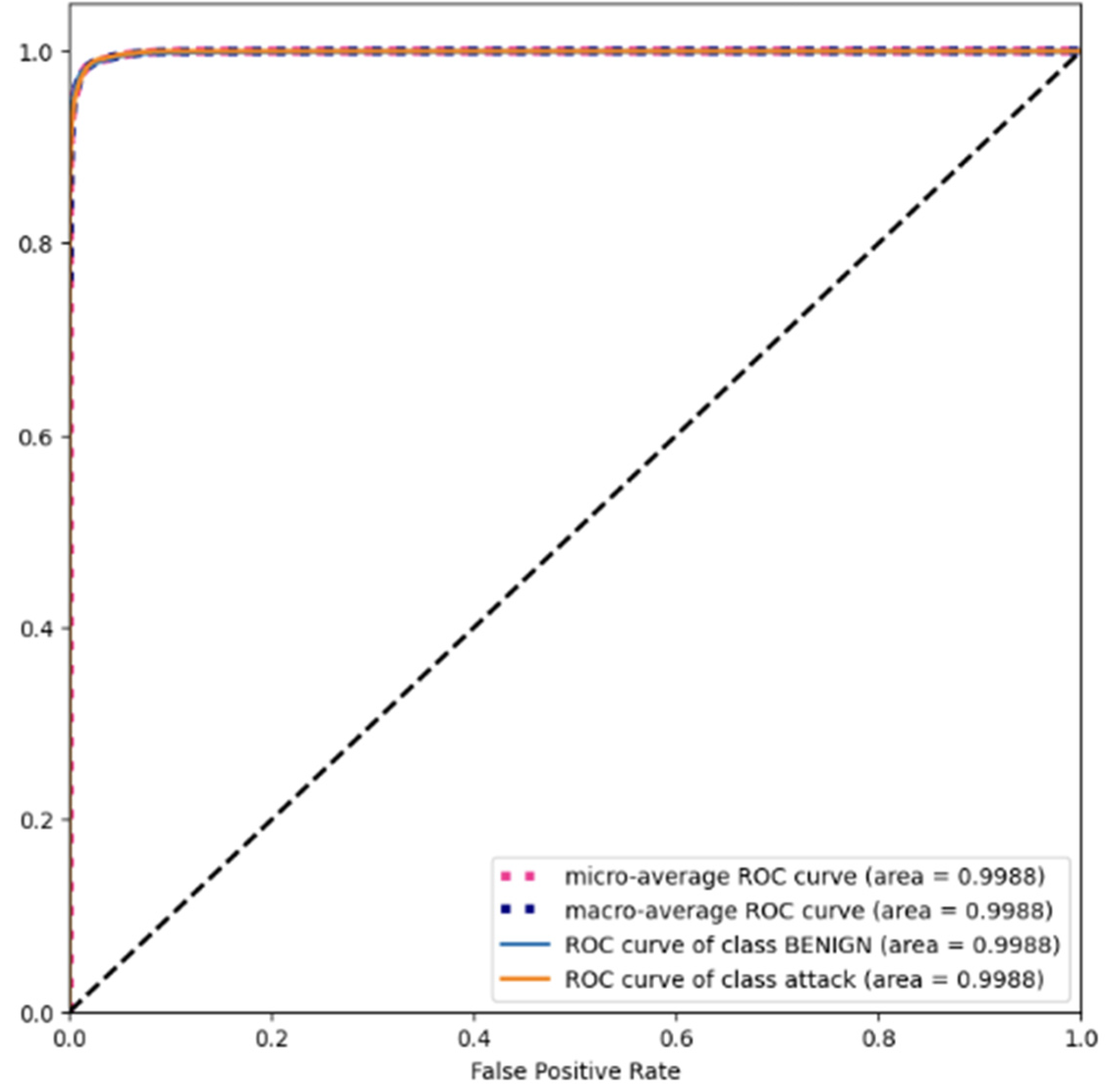
4.1.5. Area under the Receiver Operating Characteristic Curve (AUC-ROC)
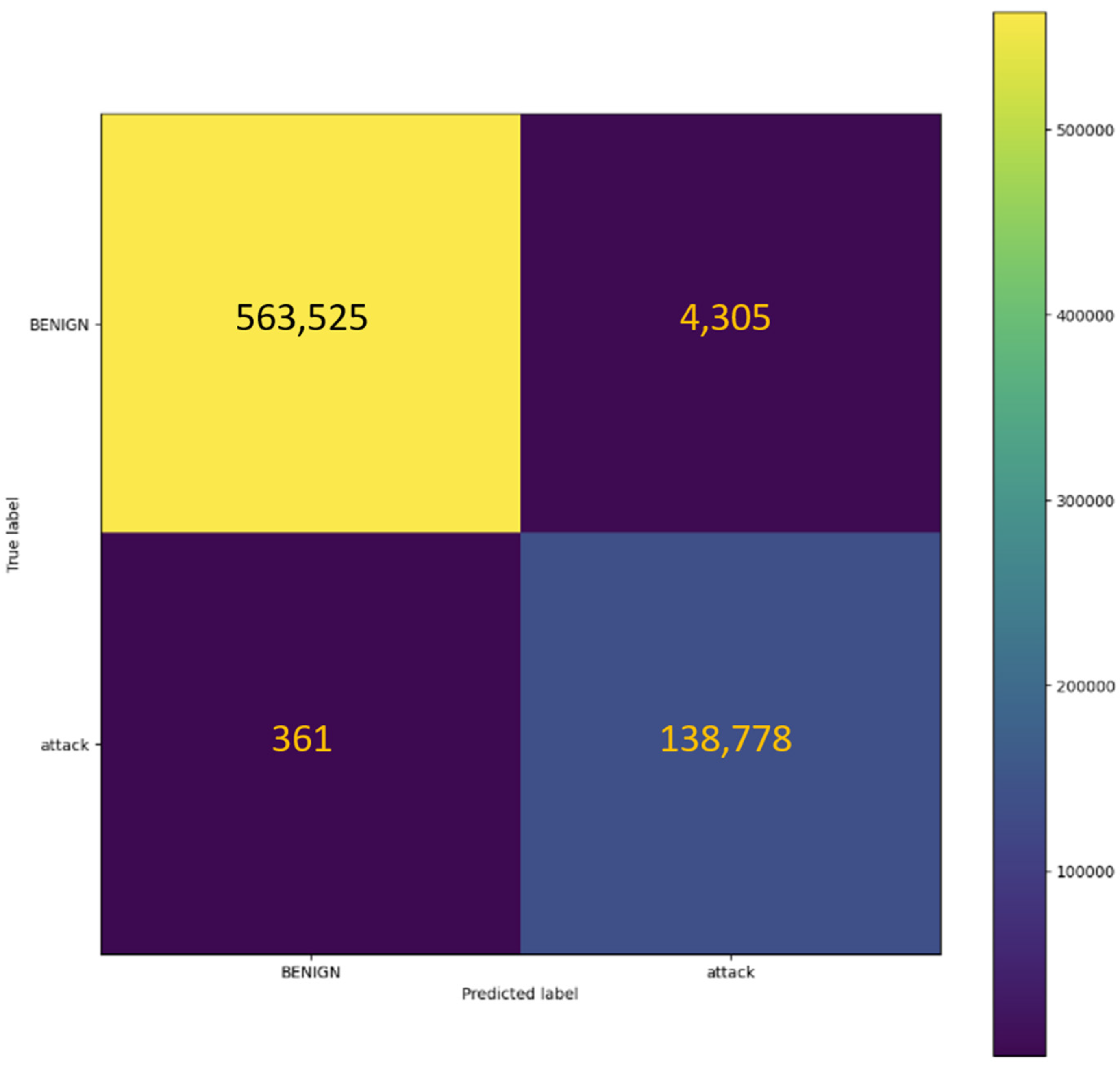
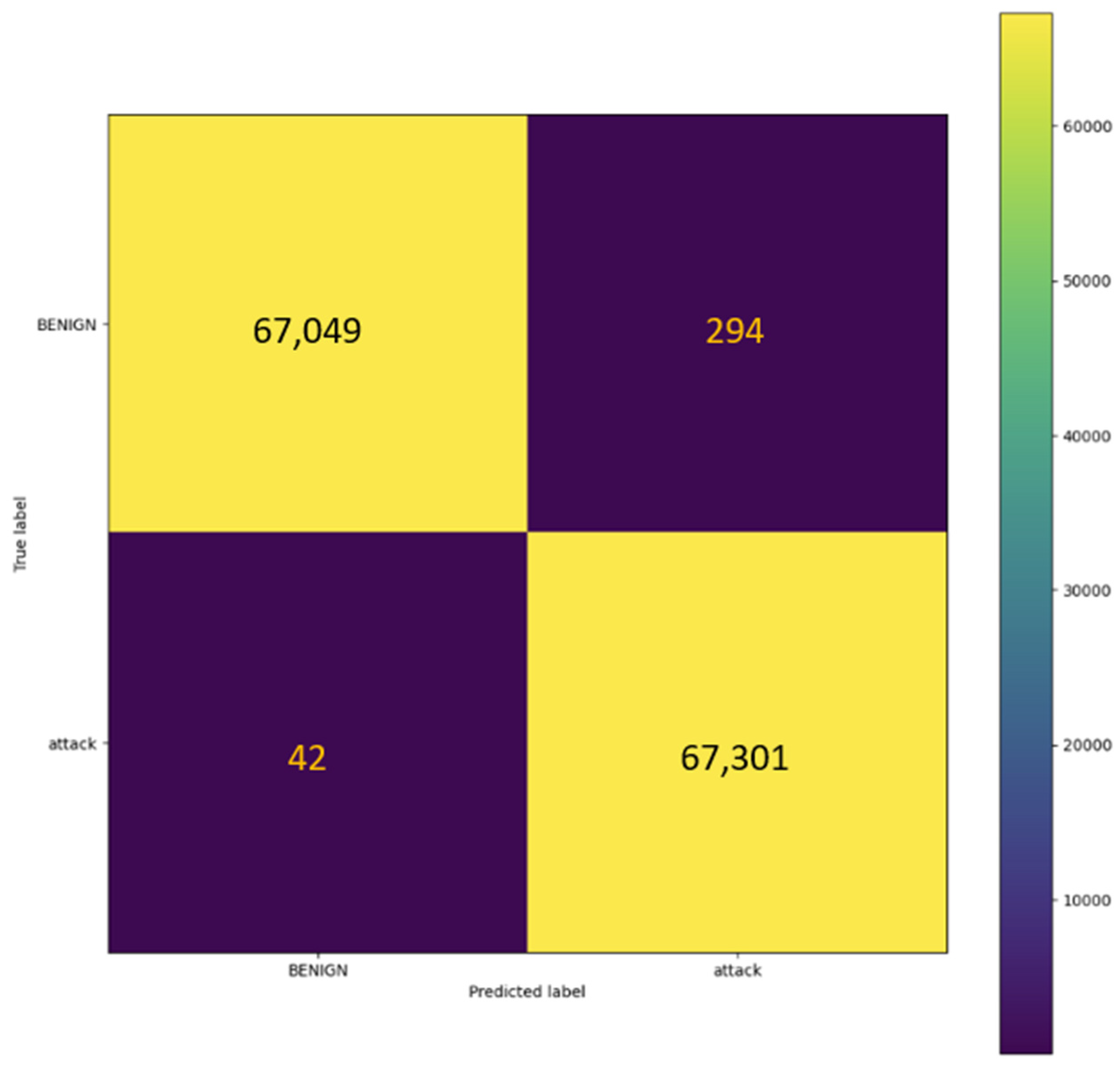
4.1.6. Confusion Matrix
4.2. Results and Comparison
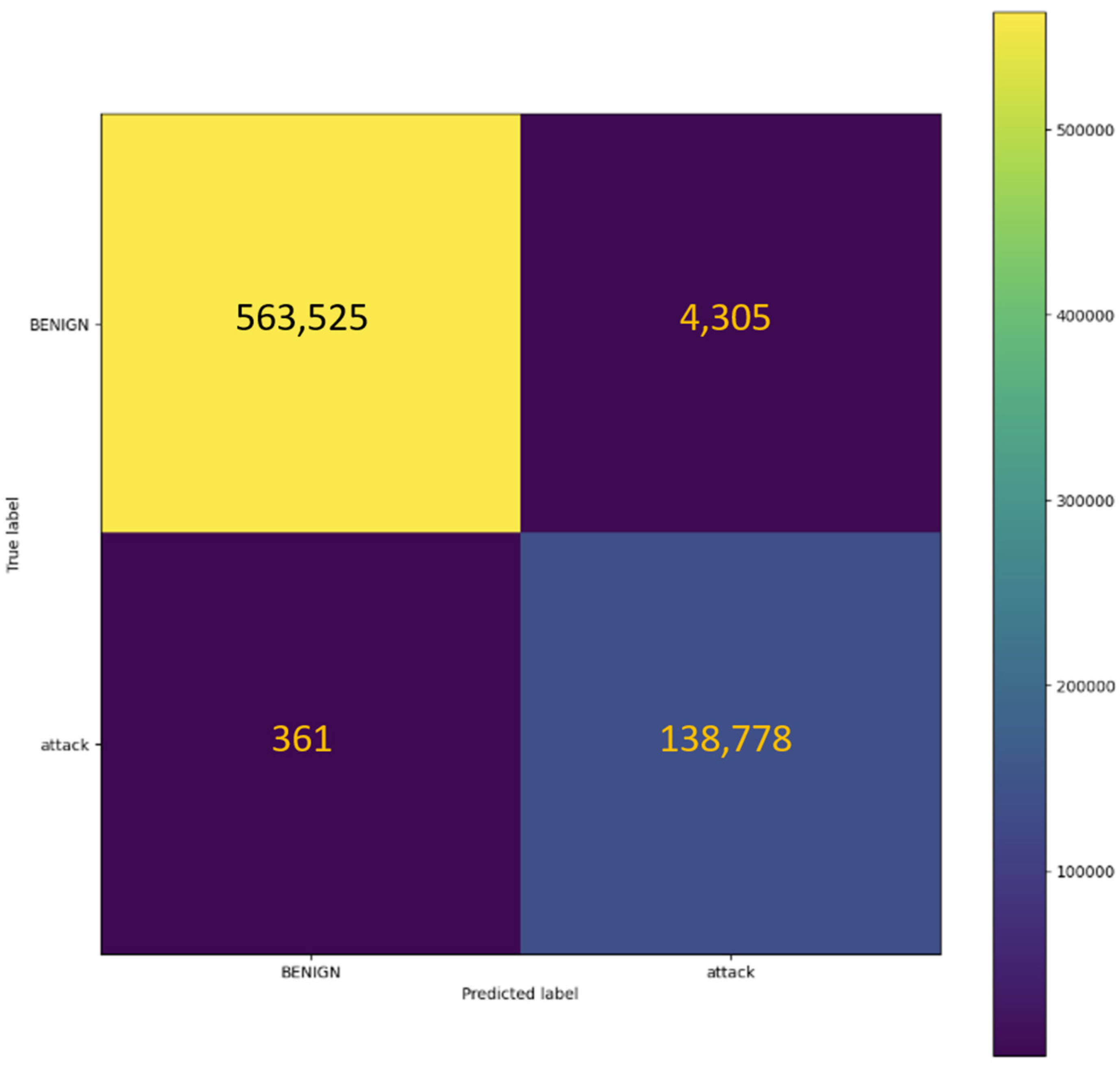
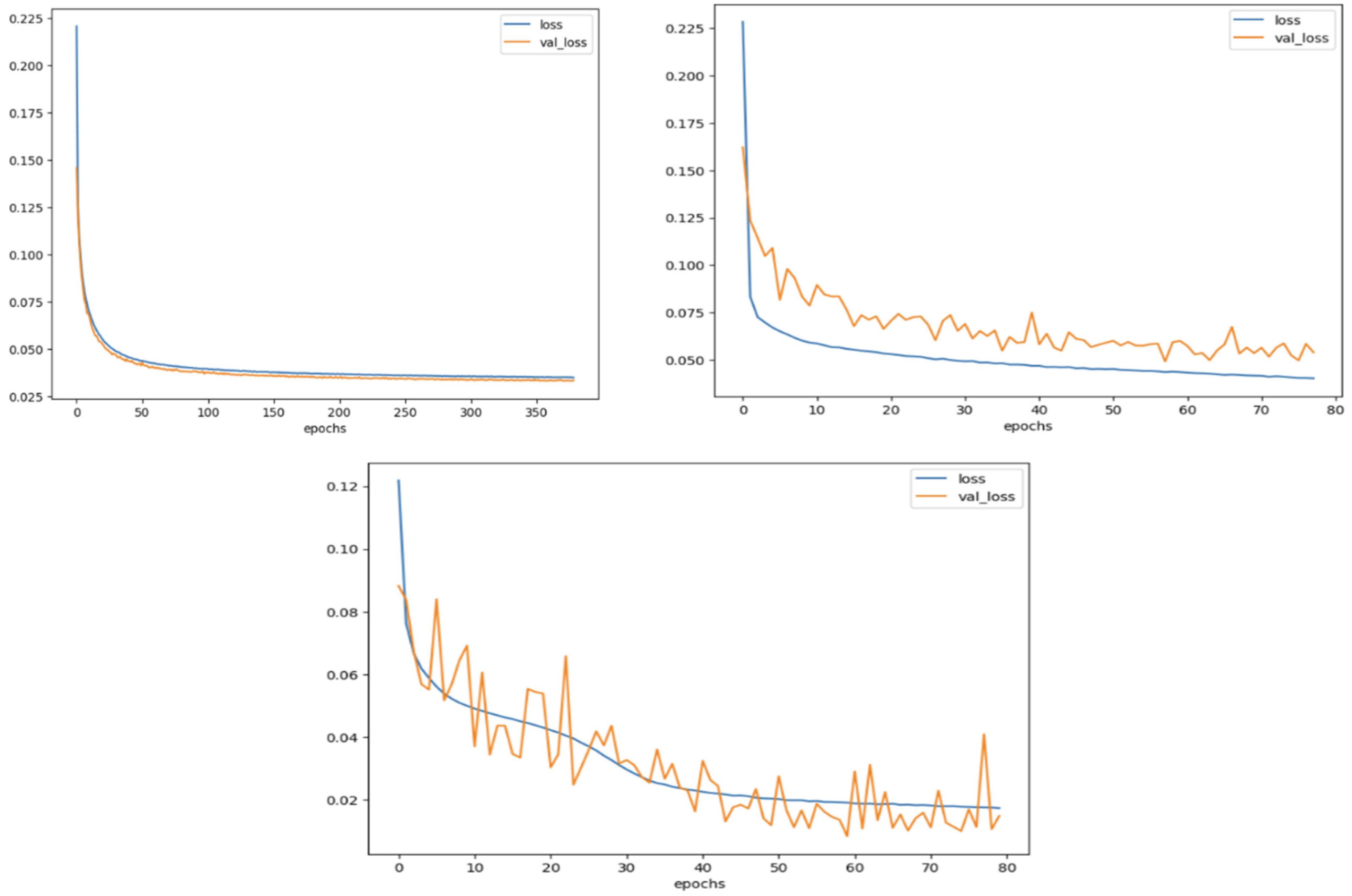
4.2.1. CICIDS2017 Dataset
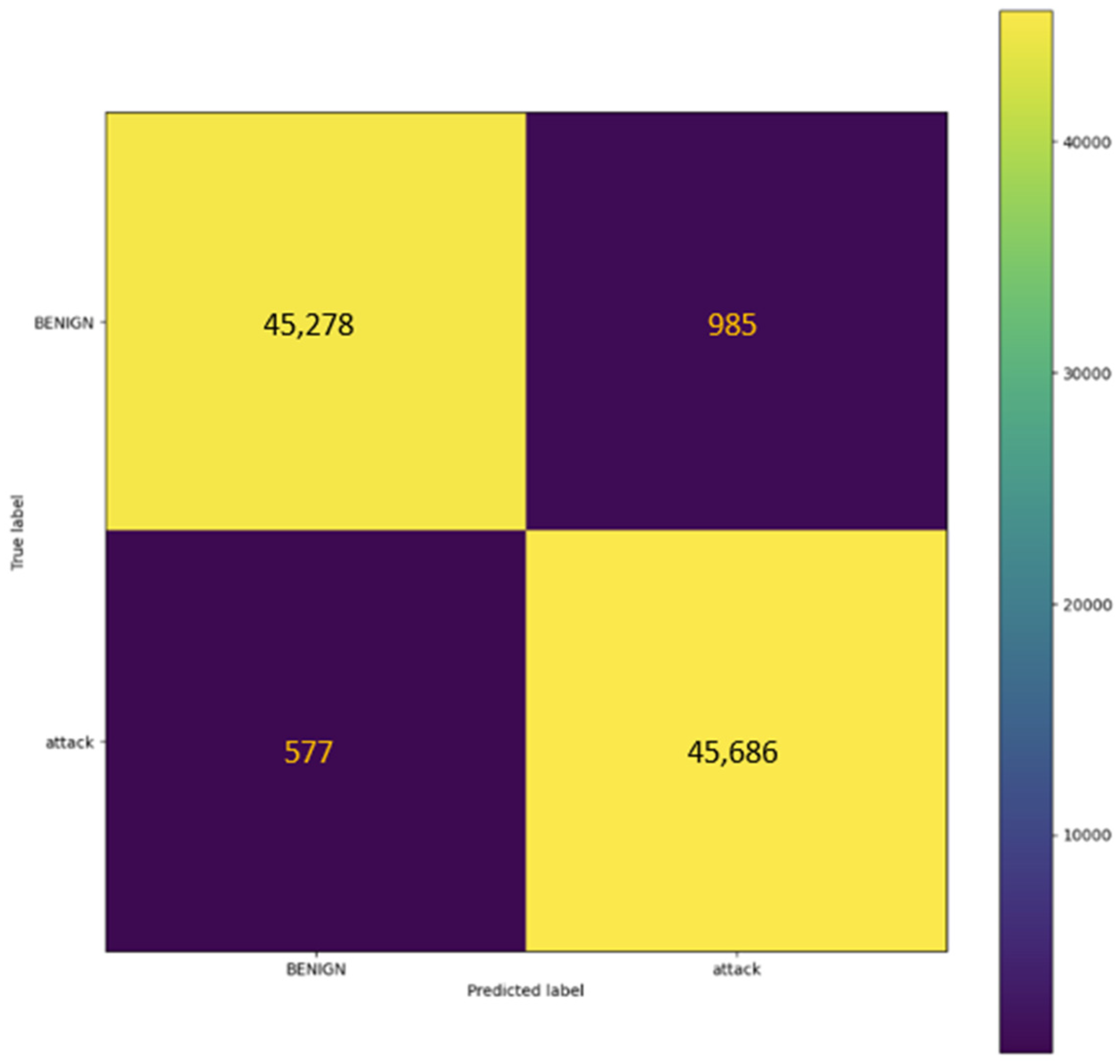
4.2.2. NSL-KDD Dataset
4.2.3. UNSW-NB15 Dataset
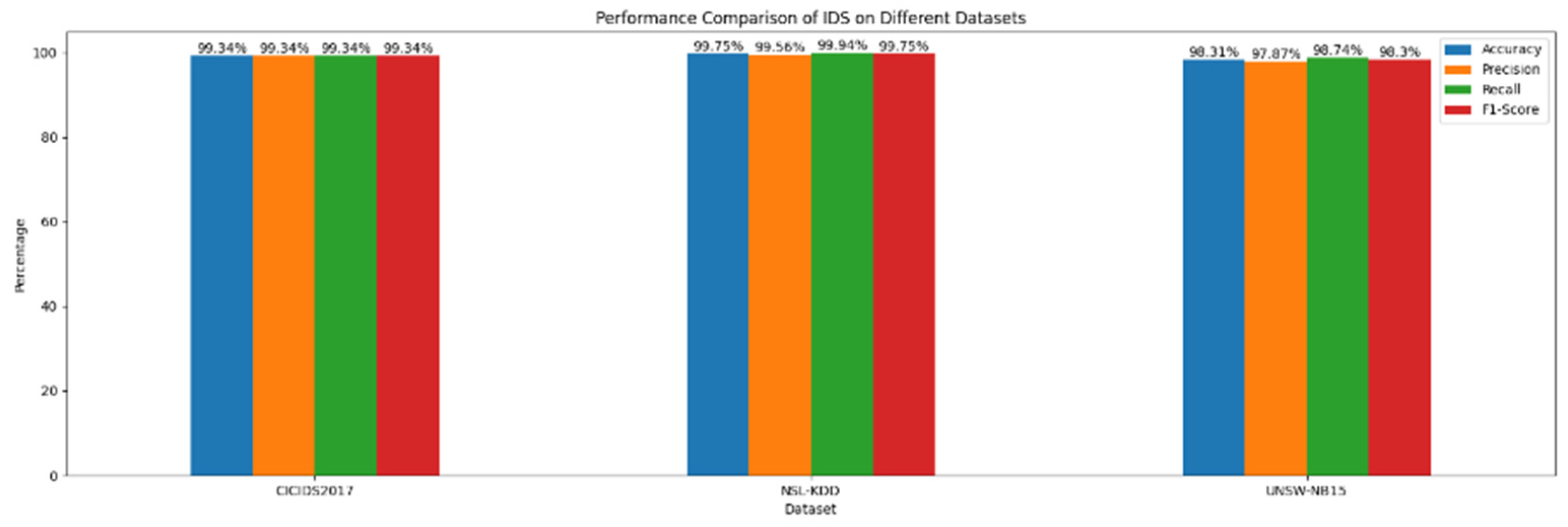
4.2.4. Overall Comparison
- The Focus on the LSTM Model:
- Consideration of Other Models:
- Justification for Future Work:
- Future Research Directions:
- Bi-LSTM Advantages:
- Rationale:
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Malik, N.; Sardaraz, M.; Tahir, M.; Shah, B.; Ali, G.; Moreira, F. Energy-efficient load balancing algorithm for workflow scheduling in cloud data centers using queuing and thresholds. Appl. Sci. 2021, 11, 5849. [Google Scholar] [CrossRef]
- Baiyere, A.; Topi, H.; Venkatesh, V.; Wyatt, J.; Design, R.; Donnellan, B. Communications of the Association for Information Systems Internet of Things (IoT)—A Research Agenda for Information Systems. Available online: https://ssrn.com/abstract=3844214 (accessed on 24 May 2022).
- Lone, A.N.; Mustajab, S.; Alam, M. A comprehensive study on cybersecurity challenges and opportunities in the IoT world. Secur. Priv. 2023, 6, e318. [Google Scholar] [CrossRef]
- Dahou, A.; Abd Elaziz, M.; Chelloug, S.A.; Awadallah, M.A.; Al-Betar, M.A.; Al-Qaness, M.A.; Forestiero, A. Intrusion Detection System for IoT Based on Deep Learning and Modified Reptile Search Algorithm. Comput. Intell. Neurosci. 2022, 2022, 6473507. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Hnamte, V.; Hussain, J. DCNNBiLSTM: An Efficient Hybrid Deep Learning-Based Intrusion Detection System. Telemat. Inform. Rep. 2023, 10, 100053. [Google Scholar] [CrossRef]
- Ashiku, L.; Dagli, C. Network Intrusion Detection System using Deep Learning. In Procedia Computer Science; Elsevier B.V.: Amsterdam, The Netherlands, 2021; pp. 239–247. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Wang, S.; Dai, Y.; Shen, J.; Xuan, J. Research on expansion and classification of imbalanced data based on SMOTE algorithm. Sci. Rep. 2021, 11, 24039. [Google Scholar] [CrossRef] [PubMed]
- Ustebay, S.; Turgut, Z.; Aydin, M.A. Intrusion Detection System with Recursive Feature Elimination by Using Random Forest and Deep Learning Classifier. In Proceedings of the International Congress on Big Data, Deep Learning and Fighting Cyber Terrorism, IBIGDELFT 2018—Proceedings, Ankara, Turkey, 3–4 December 2018; pp. 71–76. [Google Scholar] [CrossRef]
- Darst, B.F.; Malecki, K.C.; Engelman, C.D. Using recursive feature elimination in random forest to account for correlated variables in high dimensional data. BMC Genet. 2018, 19, 65. [Google Scholar] [CrossRef] [PubMed]
- Granitto, P.M.; Furlanello, C.; Biasioli, F.; Gasperi, F. Recursive feature elimination with random forest for PTR-MS analysis of agroindustrial products. Chemom. Intell. Lab. Syst. 2006, 83, 83–90. [Google Scholar] [CrossRef]
- IDS 2017|Datasets|Research|Canadian Institute for Cybersecurity|UNB. Available online: https://www.unb.ca/cic/datasets/ids-2017.html (accessed on 23 July 2023).
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the IEEE Symposium on Computational Intelligence for Security and Defense Applications, CISDA 2009, Ottawa, ON, Canada, 8–10 July 2009. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference, MilCIS 2015—Proceedings, Canberra, Australia, 10–12 November 2015. [Google Scholar] [CrossRef]
- Yang, L.; Moubayed, A.; Hamieh, I.; Shami, A. Tree-based Intelligent Intrusion Detection System in Internet of Vehicles. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Big Island, HI, USA, 9–13 December 2019. [Google Scholar] [CrossRef]
- Yang, L.; Moubayed, A.; Shami, A. MTH-IDS: A Multi-Tiered Hybrid Intrusion Detection System for Internet of Vehicles. IEEE Internet Things J. 2021, 9, 616–632. [Google Scholar] [CrossRef]
- Joloudari, J.H.; Marefat, A.; Nematollahi, M.A.; Oyelere, S.S.; Hussain, S. Effective Class-Imbalance Learning Based on SMOTE and Convolutional Neural Networks. Appl. Sci. 2023, 13, 4006. [Google Scholar] [CrossRef]
- Fatani, A.; Dahou, A.; Abd Elaziz, M.; Al-Qaness, M.A.; Lu, S.; Alfadhli, S.A.; Alresheedi, S.S. Enhancing Intrusion Detection Systems for IoT and Cloud Environments Using a Growth Optimizer Algorithm and Conventional Neural Networks. Sensors 2023, 23, 4430. [Google Scholar] [CrossRef] [PubMed]
- Fu, Y.; Du, Y.; Cao, Z.; Li, Q.; Xiang, W. A Deep Learning Model for Network Intrusion Detection with Imbalanced Data. Electronics 2022, 11, 898. [Google Scholar] [CrossRef]
- Elnakib, O.; Shaaban, E.; Mahmoud, M.; Emara, K. EIDM: Deep learning model for IoT intrusion detection systems. J. Supercomput. 2023, 79, 13241–13261. [Google Scholar] [CrossRef]
- Speiser, J.L. A random forest method with feature selection for developing medical prediction models with clustered and longitudinal data. J. Biomed. Inform. 2021, 117, 103763. [Google Scholar] [CrossRef] [PubMed]
- Jose, J.; Jose, D.V. Deep learning algorithms for intrusion detection systems in internet of things using CIC-IDS 2017 dataset. Int. J. Electr. Comput. Eng. 2023, 13, 1134–1141. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. In Proceedings of the ICISSP 2018—Proceedings of the 4th International Conference on Information Systems Security and Privacy, Funchal, Portugal, 22–24 January 2018; SciTePress: NewBrunswick, Canada, 2018; pp. 108–116. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. The evaluation of Network Anomaly Detection Systems: Statistical analysis of the UNSW-NB15 data set and the comparison with the KDD99 data set. Inf. Secur. J. A Glob. Perspect. 2016, 25, 18–31. [Google Scholar] [CrossRef]
- Chen, R.C.; Dewi, C.; Huang, S.W.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. J. Big Data 2020, 7, 52. [Google Scholar] [CrossRef]
- Vujović, Ž.Đ. Classification Model Evaluation Metrics. Available online: www.ijacsa.thesai.org (accessed on 24 July 2021).
- Tafvizi, A.; Avci, B.; Sundararajan, M. Attributing AUC-ROC to Analyze Binary Classifier Performance. May 2022. Available online: http://arxiv.org/abs/2205.11781 (accessed on 24 May 2022).
- Zhang, R.; Yang, S.; Zhang, Q.; Xu, L.; He, Y.; Zhang, F. Graph-based few-shot learning with transformed feature propagation and optimal class allocation. Neurocomputing 2022, 470, 247–256. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted | ||
|---|---|---|
| Actual | True Positive (TP) | False Negative (FN) |
| False Positive (FP) | True Negative (TN) | |
| Precision | Recall | Fl-Score | Support | |
|---|---|---|---|---|
| BENIGN | 1.00 | 0.99 | 1.00 | 567,830 |
| Attack | 0.97 | 1.00 | 0.98 | 139,139 |
| Accuracy | 0.99 | 706,969 | ||
| Macro avg | 0.98 | 0.99 | 0.99 | 706,969 |
| Weighted avg | 0.99 | 0.99 | 0.99 | 706,969 |
| Precision | Recall | Fl-Score | Support | |
|---|---|---|---|---|
| BENIGN | 1.00 | 1.00 | 1.00 | 67,343 |
| Attack | 1.00 | 1.00 | 1.00 | 67,343 |
| Accuracy | 1.00 | 134,686 | ||
| Macro avg | 1.00 | 1.00 | 1.00 | 134,686 |
| Weighted avg | 1.00 | 1.00 | 1.00 | 134,686 |
| Precision | Recall | Fl-Score | Support | |
|---|---|---|---|---|
| BENIGN | 0.99 | 0.98 | 0.98 | 46,236 |
| Attack | 0.98 | 0.99 | 0.98 | 46,236 |
| Accuracy | 0.98 | 92,526 | ||
| Macro avg | 0.98 | 0.98 | 0.98 | 92,526 |
| Weighted avg | 0.98 | 0.98 | 0.98 | 92,526 |
| Dataset | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| CICIDS2017 | 99.34% | 99.34% | 99.34% | 99.34% |
| NSL-KDD | 99.75% | 99.56% | 99.94% | 99.75% |
| UNSW-NB15 | 98.31% | 97.87% | 98.74% | 98.30% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sayegh, H.R.; Dong, W.; Al-madani, A.M. Enhanced Intrusion Detection with LSTM-Based Model, Feature Selection, and SMOTE for Imbalanced Data. Appl. Sci. 2024, 14, 479. https://doi.org/10.3390/app14020479
Sayegh HR, Dong W, Al-madani AM. Enhanced Intrusion Detection with LSTM-Based Model, Feature Selection, and SMOTE for Imbalanced Data. Applied Sciences. 2024; 14(2):479. https://doi.org/10.3390/app14020479
Chicago/Turabian StyleSayegh, Hussein Ridha, Wang Dong, and Ali Mansour Al-madani. 2024. "Enhanced Intrusion Detection with LSTM-Based Model, Feature Selection, and SMOTE for Imbalanced Data" Applied Sciences 14, no. 2: 479. https://doi.org/10.3390/app14020479
APA StyleSayegh, H. R., Dong, W., & Al-madani, A. M. (2024). Enhanced Intrusion Detection with LSTM-Based Model, Feature Selection, and SMOTE for Imbalanced Data. Applied Sciences, 14(2), 479. https://doi.org/10.3390/app14020479