Abstract
In an information-security-assurance system, humans are usually the weakest link. It is partly related to insufficient cybersecurity knowledge and the ignorance of standard security recommendations. Consequently, the required password-strength requirements in information systems are the minimum of what can be done to ensure system security. Therefore, it is important to use up-to-date and context-sensitive password-strength-estimation systems. However, minor languages are ignored, and password strength is usually estimated using English-only dictionaries. To change the situation, a machine learning approach was proposed in this article to support a more realistic model to estimate the strength of Lithuanian user passwords. A newly compiled dataset of password strength was produced. It integrated both international- and Lithuanian-language-specific passwords, including 6 commonly used password features and 36 similarity metrics for each item (4 similarity metrics for 9 different dictionaries). The proposed solution predicts the password strength of five classes with 77% accuracy. Taking into account the complexity of the accuracy of the Lithuanian language, the achieved result is adequate, as the availability of intelligent Lithuanian-language-specific password-cracking tools is not widely available yet.
1. Introduction
Cybersecurity is one of the most important and sensitive topics in the world, as various types of hacking usually have dire consequences. Today, research is being conducted in this area. This includes developing data protection methods or models [], detecting GDPR violations [,], developing or analyzing cyberattacks [,], security, detecting phishing emails [], malware detection [], and many other similar applications.
The human factor plays a crucial role in security assurance []. For an ordinary user, the biggest challenge is to protect their data, devices, and accounts. This is because we live in a time where important information can be leaked and used against us. To balance data and functionality access and security, trusted user authentication is necessary. Password authentication is the most widely used authentication method []. It is easy to use and implement in various systems and is, moreover, inexpensive. Authentication methods can include biometrics [,,,] (fingerprints, face recognition, eye iris recognition, or blinking speed), smart cards, and others, but password authentication remains the most popular. However, password authentication is also one of the most insecure forms of authentication. This is because users often choose easy-to-remember passwords that are easy to decipher [].
Strong passwords are one of the fundamental ways that password authentication can be considered secure. Imperishable passwords are essential, especially given the increasing number of cyberattacks and data leaks []. Password strength is significantly dependent on the user, but password-strength meters are crucial tools that help users create more secure passwords. Passwords are evaluated using password-strength meters based on various factors, for example, password length, complexity, or comparison to common password lists.
Nowadays, there are many different password-strength meters that have been developed. Password-strength-estimation models focus on English passwords by including different dictionaries (popular names, places), common password lists, leaked password lists, or other specific dictionaries. Most of them do not consider the passwords from other languages that could be used in the systems. Usually, statistical-based approaches are used to estimate the strength of a password, without taking into account the language in which the password could be written. Meanwhile, many different investigations can be found to confirm the fact that user passwords depend on the human factor [,] of the user. They are closely related to the language or environment used by the user. The extension of existing tools by providing language-specific data (the language dictionary, common names, passwords) is not enough, as some languages are more complex. For example, the Lithuanian language in comparison to the English language is more difficult morphologically, as the words in Lithuanian have more different forms. Furthermore, the Lithuanian language uses diacritics, which are considered special symbols when estimating the strength of the password. However, in the context of the Lithuanian language, it is not a special symbol. All these facts must be taken into account when evaluating the strength of the password.
In this study, the main objective is to adjust the password-strength-estimation model to accommodate the requirements of the Lithuanian language. Existing password-strength-estimation tools analyze the usage of English words in the password. Therefore, if a Lithuanian word is used in the password, the password-strength tools provide a positively too high security level. Thus, it is important to incorporate the Lithuanian language to estimate the strength of Lithuanian user passwords. Due to the complexity of the Lithuanian language, traditional deterministic approaches are not suitable. Therefore, the novelty of this research is based on several aspects: a machine learning model is proposed to evaluate the strength of passwords of Lithuanian users, and a password-strength dataset is developed, based on separated subsets of passwords in different languages (English and Lithuanian). For dataset development, a heuristic method has been proposed to evaluate the strength of passwords written in the Lithuanian language.
The proposed approach is suitable for English and Lithuanian passwords, but the logic can be easily modified and used for other less popular languages.
The structure of the manuscript is as follows. Section 2 reviews related works. In Section 3, the proposed approach scheme is presented, and all steps are described. In addition, the selected dataset is described. In Section 4, we describe the experimental investigation and validation of the proposed approach to estimate password strength. Five classification algorithms have been used to train the machine learning model and estimate password strength. In Section 5, the discussion and possible limitations of the proposed approach are presented. Section 6 concludes the paper.
2. Related Works
Today, password-strength estimation is usually performed by two different techniques: based on statistical rules and machine learning models. When it comes to estimating the cracking time of a password, brute-force attacks are usually not an option []. As a result, many different password-strength meters can be found and used publicly. Taking into account today’s given threat environment, password strength can be defined as a measure of the effectiveness of a password against brute-force attacks. Most password-strength meters use mathematical-based approaches, such as the password’s length, number of special characters, digits, lowercase and uppercase characters, and dictionary matching.
The research performed by Golla et al. [] created a list of characteristics that password-strength estimation must possess to be considered accurate. In addition, the authors compared the accuracy of several password-strength meters using a weighted Spearman correlation. The Spearman rank correlation coefficient is used to discover the strength of a link between two sets of data. Both online and standalone solutions were compared to estimate password strength. The comparative analysis of password-strength meters showed the differences between them by extracting their type, method, and evaluation. The results obtained by various password-strength meters based on Markov models, neural networks, and fuzzyPSM allowed us to obtain the highest accuracy.
The zxcvbn password-strength-estimation model [] calculates the strength of a password using a combination of pattern matching and entropy estimation. It provides feedback to users on how to improve their password’s strength. The zxcvbn model evaluates passwords based on a variety of criteria, such as length, character diversity, and common patterns or phrases. To indicate the level of security provided, the tool assigns a score to each password ranging from 0 to 4. The zxcvbn password-strength meter performed better than the Eleven- and LPSE-based password-strength meters, described in the research by Golla et al. The performance of Comprehensive8 based on the Spearman correlation results was the worst in the research. Therefore, the zxcvbn tool is generally used as a framework to estimate the strength of a password.
However, the systematic literature and password-strength-tool analysis has shown that widely known password-strength-estimation models are usually used to assess password strength in English-only environments. There are not many studies that adapt password-strength meters to other languages. In the research by Daucek et al. [], the strength of the Czech and Slovak language password was analyzed. The researchers proposed an approach and reported on the results of adapting the password-strength meter zxcvbn to the Czech and Slovak languages.
Daucek et al. modified the zxcvbn password-strength meter by adding several types of additional dictionaries that fit Czech- and Slovak-language password detection. The authors used a large set of leaked passwords from the Czech environment (approximately 3.1 million), divided into 12 categories, to test the results obtained. The direct results for the Czech and Slovak languages and the method described in the research can be used as a methodology to adapt the zxcvbn password-strength meter to other less widespread European languages.
In the research by Hong et al. [], Korean-language passwords were analyzed. According to their research, existing password-strength meters or proposed models for password-strength estimation are based on the English alphabet. The authors created a Korean-language-based password dictionary and proposed a password-strength-evaluation model based on this for Korean users. As in the research of Daucek et al., Hong et al. conducted experiments to evaluate the security of Korean-language-based passwords using a database of passwords that have been leaked. As a result, the proposed model showed 99.38% accuracy for leaked passwords based on the Korean language. This is superior to the 80.06% accuracy shown by the existing model.
Sarkar et al. [] proposed to predict the strength of new passwords using machine learning models. Therefore, several machine learning algorithms were chosen and experimentally investigated, such as logistic regression, gradient-boosted trees, random forest, multilayer perceptron, and Naïve Bayes. Approximately 80,000 passwords were collected [] and used in the experimental investigation, which was divided into training and testing datasets, respectively, 80/20%. All passwords of the datasets were assigned to three classes: 0–weak, 1–medium, and 2–strong. The research results showed that the highest accuracy was obtained using the gradient-boosted tree algorithm (99%). A slightly smaller accuracy (95%) was obtained by multilayer perceptron, and the smallest accuracy was obtained by Naïve Bayes (only 75% was achieved). Kim et al., in their research [], used the same dataset as Sarkar et al., but only the largest number of passwords was included. The authors proposed a password-strength-estimation model based on deep learning algorithms and multiclass classification, which solves the existing problem that leaked frequency is not considered during the evaluation. To evaluate the performance of the proposed model, an experiment was conducted that compared the password leaked frequency stored in a database using a password list. As a result, the proposed model correctly evaluated 99% of the 345 leaked passwords.
The analysis performed of related works has shown that there is no research focused on Lithuanian-language password analysis, neither using mathematical approaches nor models based on machine learning. The most suitable solution for Lithuanian password-strength estimation is to use existing password meters, such as zxcvbn, and modify them for the language by adding dictionaries. However, in the case of the Lithuanian language, the language is more specific, and common words have many different forms, so it is not enough to use traditional dictionaries such as in English password detection. For this reason, the new approach based on machine learning, similarity measures, and the modification of the password-strength meter zxcvbn has been proposed and is described in the next section.
3. The Proposed Approach and Data Preparation
3.1. Password-Strength Dataset
As the focus of the research is to estimate the strength of a password specifically in a Lithuanian context, two datasets were constructed and later combined into one used to train models. One is a password dataset taken from international-context passwords and the other from Lithuanian-context passwords. This is because Lithuanian users can use both English and Lithuanian words in their passwords. To build the Lithuanian-context password dataset, the part of passwords that belongs to the most used passwords list in Lithuanian, prepared by Mantas Sasnauskas [], has been taken. The primary list of the most common Lithuanian passwords consists of approximately 500,000 passwords, but in this experimental research, only a part of the list has been used, approximately 110,000. The main reason is that the full Lithuanian password list presented by Mantas Sasnauskas [] contains English passwords, and also, there are many passwords that have been formed by random characters, so it is not possible to understand the context of passwords; it is obvious as the passwords are not word-based. Regarding this problem, the password list has been manually reviewed, eliminating the English-language-word-based passwords and other noise found in the dataset. It was important to keep only unequivocally Lithuanian-context passwords. In the case of Lithuanian-context passwords, the dataset is not labeled; it is a plain list of passwords, with no password-strength labels assigned to it. The dataset of international-context passwords used in this experimental investigation is taken from Kaggle []. The dataset has been chosen because it is well known and widely used in various related works. The full dataset contains a total of almost 700,000 passwords. It is important to maintain the balance between the Lithuanian- and international-password dataset subsets, so the same number of passwords (approximately 110,000) has been randomly chosen. All passwords in the international dataset have initially been assigned to one of three classes (0–weak, 1–medium, 2–strong). Later, in the next steps of the research, both datasets were combined into one, labeled, and used in experimental investigation.
As we can see in Figure 1, only the passwords from the two datasets (international and Lithuanian) are labeled using a password-strength meter (zxcvbn) to measure the strength of the password. In Section 3.2, the description of the labeling process is presented in more detail. For international data, it was decided that zxcvbn is suitable for measuring password strength, as it takes into account many different English dictionaries (Table 1) and is effective according to related works.
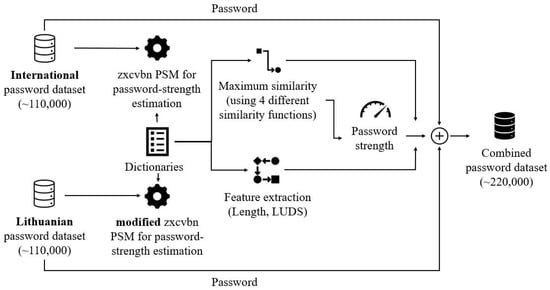
Figure 1.
Schema of the main password-strength labeling and feature extraction.

Table 1.
The list of the dictionaries used in the zxcvbn password-strength meter.
For the Lithuanian dataset, a modified version of the zxcvbn model is applied. The modifications applied to zxcvbn aim to take into account the morphological complexities that make up Lithuanian words (the four similarity measures have been used to find the similarity between the input password and one of the dictionaries). Once the passwords are labeled, the password features are extracted. These features include the maximum similarity of each dictionary used in the tool and four different similarity functions to compare. In addition, it includes simple password features, such as password length, number of lowercase and uppercase characters, digits, and special symbols in a password. Finally, the password dataset is combined into one.
The combined dataset is used for machine learning methods to predict password strength. There is no automated method to detect whether the password has been written in the Lithuanian language, so a machine-learning-based approach is needed (the accuracy of the password language estimation was executed, but the accuracy was very limited and not suitable for practical application). The principle of the proposed approach is presented in the following steps (Figure 2). For each similarity measure, the data is cleaned, and different machine learning models are trained and tested using the cross-validation method. Machine learning models are evaluated by calculating accuracy, precision, recall, and the F1 score. Furthermore, the performance of each machine learning model has been tested against international and Lithuanian subsets. These subsets were not used in the training process to evaluate the effectiveness of the model in simulating a real environment. The international subset consists of 9999 passwords, and the Lithuanian subset, 16,269.
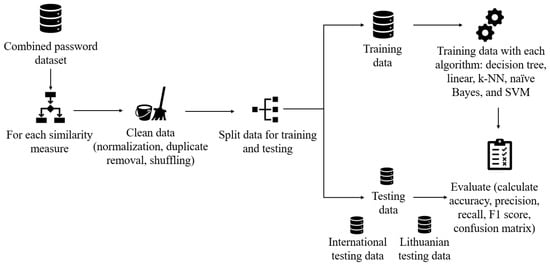
Figure 2.
The principle of the proposed approach to estimate the strength of Lithuanian passwords.
3.2. Labeling of Dataset Items
First, the passwords for the international password dataset are newly labeled using the zxcvbn password-strength meter. The main reason is that the original dataset source provides passwords that are assigned just to one of three classes (weak, medium, and strong), and it does not provide a clear view of password strength. Therefore, in our experimental investigation, we added a new label (0–too guessable, 1–very guessable, 2–somewhat guessable, 3–safely unguessable, 4–very unguessable) by using the zxcvbn password-strength meter. The zxcvbn password meter uses five classes and becomes the main source for the initial estimation of the strength of the password. Therefore, the usage of five classes is more in compliance with the existing password-strength systems based on the usage of zxcvbn. The modification made to zxcvbn can be seen in Figure 3, where the tool has an additional text-matching and one additional fragment-scoring element. For the international dataset, the similarity-scoring component is turned off. Text similarity to defined dictionaries is estimated for further dataset feature construction, but the measures do not affect the password-strength score. For Lithuanian-word-based passwords, similarity metric-based scoring is activated.
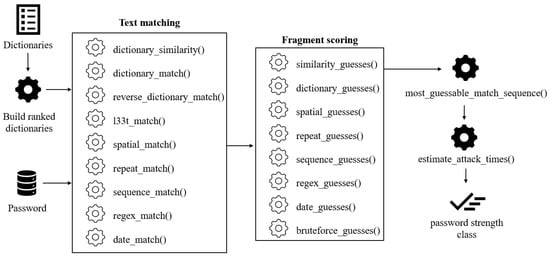
Figure 3.
The scheme of the modified zxcvbn password-strength-meter model.
One of the key components of the zxcvbn tool is dictionaries. A total of six default dictionaries are used, and three additional dictionaries are added, reflecting Lithuanian-language-specific information (see Table 1). Additionally, in the modified version of the tool, the similarity of the password to each dictionary item is measured. The similarity is calculated by four different similarity functions: Fuzz, Levenshtein Jaro, Levenshtein Jaro Winkler, and Levenshtein Ratio. Only the most similar word from each dictionary was selected and used for further password-strength estimation.
The tool has a structure consisting of text matching, scoring, selecting the weakest combination, setting the cracking time, and a password-strength class. The original version of zxcvbn calculates the password strength based on the place of the string of characters located inside a dictionary: the closer the string is to the beginning of the list, the weaker the password. For the Lithuanian password dataset, the similarity of a string in a dictionary is used as the first criterion, followed by the rank in the dictionary, if necessary. This is relevant for Lithuanian words, as there are so many morphological cases of a word. It would be resource-intensive and close to impossible to have a dictionary of Lithuanian words that includes every possible case of each word that is also ranked as the most common. Only the most similar dictionary item is used for scoring. To get the number of guesses needed for the estimated password, the length of the similar fragment L must be estimated. It is achieved by taking the shortest of the compared words, password, or dictionary item:
where L is the length of the text fragment, which is determined by the shortest length of the evaluated password and the most similar word ; password is the password in question; and is the maximum similarity of the dictionary item to the password.
For scoring, the and appropriate scorings are determined for each dictionary. The next phase of zxcvbn is the estimation of the guesses needed to recover the password, on which the password score is based. To estimate how many guesses K will be needed to guess the password according to the rules and specifics of the Lithuanian language, an approximate formula was derived (2). It takes into account how many words in different forms exist in the language and multiplies it by the ratio between the length of the text fragment and the complexity of guessing the fragment by the already known matching part:
where K is the needed guesses, and R is the approximate number of the language words in different forms. Taking into account the variety of words and their forms in the Lithuanian language, the initial value of the R is assigned to 2.5 million, L is the length of the coincident word, and is the similarity of the most similar word in the dictionary. Value 10 was selected taking into account the average number of possible letters to continue the word sequence.
The calculated value of K is used as one of the alternatives to calculate the total number of attempts required to guess the password and, accordingly, the guess time. The password-guessing-time model is the same as in the original zxcvbn model and is performed on the basis of the needed guesses for certain fragments of the passwords. Finally, based on the calculated password-guessing time, the password-security class is evaluated. The distribution of the combined dataset is presented in Figure 4. As we can see, the dataset is not balanced because only a small number of users use very weak passwords. Most of the passwords in the dataset are assigned to Class 2, and the class distribution is similar to a normal distribution, reflecting the real-world situation. A deep analysis of the balanced dataset has not been performed. Class 1 consists of just 405 passwords, so using the same number of passwords to make the dataset balanced leads to the problem that the size of the dataset (2025) will not be enough to train the machine learning model. Artificially generated passwords were not included to balance the dataset either to maintain real-environment conditions.
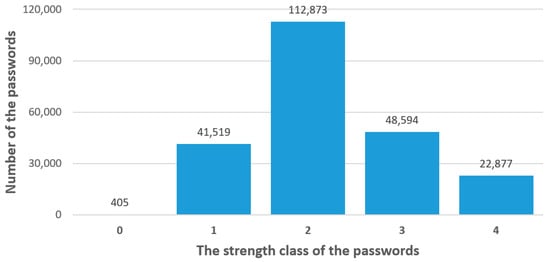
Figure 4.
Password class distribution of the dataset.
4. Password-Strength-Estimation Model
4.1. The Selection of Features for Dataset Items
As mentioned above, there are multiple password features that influence and describe the strength of the password. The description of the characteristics of the analyzed dataset is presented in Table 2. The first five password features can be easily calculated and represented as integer values. The other features are the maximum similarity measure of each dictionary (the dictionaries are presented in Table 1) used by the modified zxcvbn password-strength meter.
Table 2.
Description of password features.
The features were selected taking into account the metrics used by zxcvbn, to prevent the use of the same ones and express them in a more general, ensured form of greater availability. Therefore, the maximum similarities to the items of the analyzed dictionary were selected as metrics. These metrics can help identify weak passwords susceptible to dictionary and brute-force attacks but do not reflect the full set of metrics used by the zxcvbn model.
It was also decided to select four different similarity functions: Fuzz, Levenshtein Jaro, Levenshtein Jaro Winkler, and Levenshtein Ratio. This was to compare whether one or the others can provide better results in terms of machine learning algorithm effectiveness for password-strength estimation. Therefore, the four datasets were prepared and used in the experimental investigation , where is one of the four similarity measures used, , and is the number of dataset items analyzed.
The descriptive statistics for each password feature are presented in Figure 5. As we can see, the use of symbols and uppercase characters is rare and is usually not used in passwords at all. Based on the sources of the password dataset, this could show that the password policy implemented on the sites did not have the requirement to include symbols or uppercase characters. The length of the passwords vary, but the most typical password length in the dataset is nine characters. It is interesting that there are passwords that include less than eight characters, which means that the minimum length of a password might also not have been included in the policy.
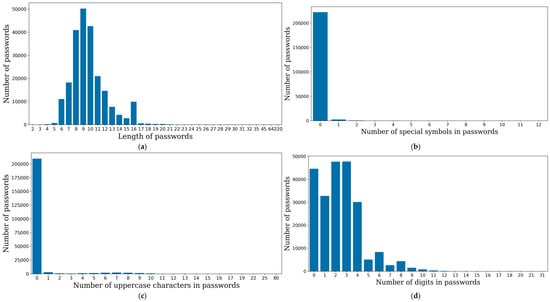
Figure 5.
Distribution of the main features of the password: (a) length of the password, (b) number of special symbols, (c) number of uppercase letters, and (d) number of digits in the password.
4.2. The Results of the Experimental Investigation
Data classification tasks are widely used in various fields, especially when machine learning models must be created. There exist many types of classification algorithms [,], such as neural networks, decision-tree-based, probabilistic algorithms, deep learning algorithms [], or transformers []. The performed related works analysis showed that traditional machine learning algorithms are still frequently used because of the simplicity in the model training or retraining processes and because of their speed when the new dataset item is fed to the model when the model is used in a real environment. Our experimental investigation examined five widely used machine learning algorithms: Naïve Bayes, linear, decision tree, kNN, and SVM. The effectiveness of these methods has already been proven in terms of speed.
All selected classification methods have been trained using the combined dataset constructed from English and Lithuanian passwords. It is necessary to mention that in total, four datasets have been analyzed because some features differ according to the one similarity measure that has been used (Fuzz, Levenshtein Jaro, Levenshtein Jaro Winkler, and Levenshtein Ratio). In the training process, cross-validation has been used, where the k-fold number is equal to 10, and the stratified option has been selected. The accuracy, precision, recall, and F1 scores of each model have been calculated. Figure 6 presents the results of each model’s performance in terms of accuracy.
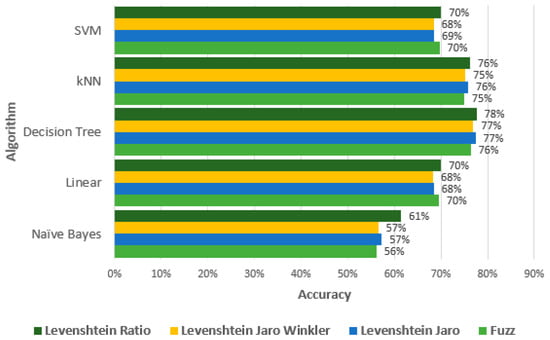
Figure 6.
The performance of each machine learning model in terms of accuracy.
As we can see, the lowest accuracy was obtained using the Naïve Bayes algorithm. Better results are obtained when the Levenshtein Ratio similarity measure is chosen (61%). The linear and SVM algorithms perform similarly and reach 70% accuracy. There is not much influence on the results of the different similarity measures used. The results of the kNN (about 75%) and decision tree algorithms (about 77%) are higher than those of other methods. The best accuracy performance is obtained by the decision tree algorithm, where accuracy reaches 78%. The experimental investigation has shown that the Levenshtein Ratio similarity measure allows us to obtain slightly better accuracy for all algorithms analyzed compared to the other similarity measures used.
Figure 7 presents a deeper analysis of the results of the decision tree algorithm. We can see the results of the precision, recall, and F1 scores of the decision tree algorithm using the Levenshtein Ratio similarity measures. It is obvious that the results of Class 0 (too guessable) are the worst in terms of all the measurements of the machine learning models. This class had a small number of dataset items (Figure 4) because it is not common for users to create and use such simple passwords.
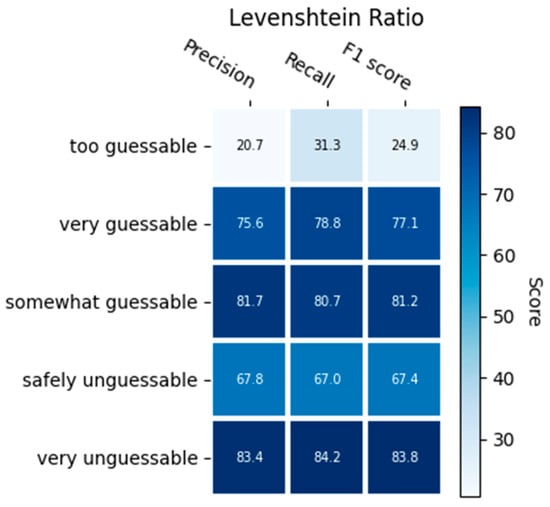
Figure 7.
The performance of the decision tree model using the Levenshtein Ratio function.
The confusion matrix of the decision tree model using the Levenshtein Ratio similarity measure is presented in Figure 8. As we can see, the majority of Class 0 (too guessable) data items have not been predicted correctly, and usually dataset items have been considered as Class 1 (very guessable). Class 4 (very unguessable) has been predicted the best, where the model has made the smallest number of incorrect predictions. The prediction of Classes 2 and 3 have also been correctly predicted in a high ratio.
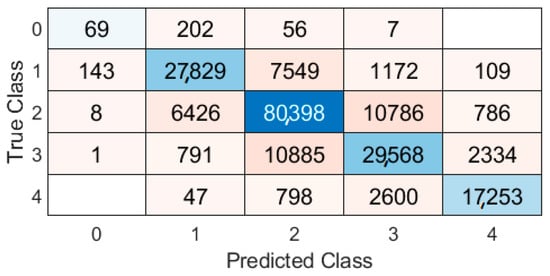
Figure 8.
The confusion matrix of the decision tree model using the Levenshtein Ratio similarity measure.
As was mentioned, to evaluate the machine learning model’s effectiveness in simulating a real environment, two separate subsets of international (9999 passwords) and Lithuanian (16,269) passwords have been hidden from the model’s training and fed to the highest-accuracy-obtained model (decision tree). Figure 9 presents the results of the model’s accuracy. As we can see, the accuracy of the model using testing subsets differs slightly from that of the trained model. In the case of the international-password subset, the accuracy becomes 2–3% lower, and in the case of the Lithuanian-password subset, it slightly increases (1–2%). The results of the model testing using new passwords show that the model is properly trained because the difference is not that high from the accuracy obtained in the model creation process.
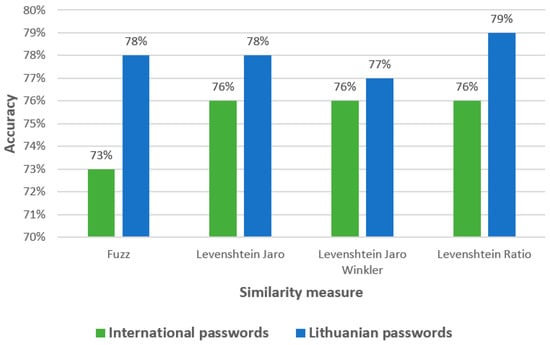
Figure 9.
Accuracy of the decision tree model using the international and Lithuanian password subsets.
The results presented in Figure 10 point to the same problem that shows that the prediction of Class 0 (very guessable) passwords is very bad, especially when the international-password subset is used. The results of the Lithuanian-password subset show that international passwords are more effective in predicting Class 4 (very unguessable) passwords than Lithuanian passwords. Based on the Lithuanian-password subset, the most accurate prediction results are obtained using Class 1 (very guessable) passwords.
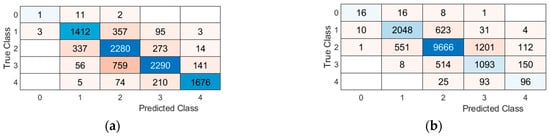
Figure 10.
Confusion matrix of the decision tree model using the Levenshtein Ratio similarity measure: (a) Lithuania-password dataset; (b) international-password dataset.
5. Discussion
The performed experimental investigation of the proposed approach for password-strength estimation has shown that it is suitable to evaluate Lithuanian-context passwords. The proposed modification of the zxcvbn passwords’ strength meter can be used for other less popular languages as well, combining it with machine learning models.
A comparison of the results obtained with other password-strength-estimation models or tools is not possible, as none of the existing models is adapted to Lithuanian users who use the Lithuanian language in their passwords. Consequently, the accuracy of English-only password solutions is higher because of the mentioned complexity of the Lithuanian language and the model’s adaptation to it. This research also differs from other comparable works in that it applies the developed model to previously unexplored data for the model in addition to using a larger dataset. Taking all of the above into account, we can state that the achieved 78% password-strength-estimation accuracy for 5-class password strength is acceptable as a high result. It can be supported even by the fact that the Lithuanian-language text analysis usually obtains very similar results (the recent results in a Lithuanian-text sentiment analysis achieved up to 79% accuracy []).
It should be noted that the experimental investigation has not taken into account all possible classification algorithms and hyperparameter optimizations in the training process. In further studies, this could be improved by implementing other algorithms, for example, deep learning, transformers. The modification of the zxcvbn password-strength meter could also be improved by adding more dictionaries that could be important for analyzing language.
The primary experimental investigation using the balanced dataset but with a small number of dataset items has shown that the data-balance problems do not influence the results much, but a deeper analysis should also be performed in the future as well. All limitations of the experimental investigation do not detract from the research and its results. The results are promising and could be useful for other same-type research, especially for non-English password-strength estimation.
6. Conclusions
The systematic literature analysis revealed the lack of solutions for estimating password strength in a non-English language. This part can be explained by the usage of English-only, most frequent password- or brute-force-based password-cracking solutions. However, hacking tools are improving, and the usage of weak passwords based on non-English-language word usage should not be ignored. This insight is supported by recently published research papers, where password-strength models are proposed for Czech, Korean, and other languages.
The existing password datasets are not suitable for the Lithuanian language; therefore, a Lithuanian-word password dataset was constructed. The estimated password-strength class for the dataset indicates similarity to real-world situations where normal password-strength distributions can be inspected. The integration of main password-strength-estimating features and maximum password-similarity scores for nine selected dictionaries based on four different text-similarity metrics ensures the dataset’s application extensibility.
The experiments executed with five machine learning methods for the prediction of password strength reveal that the text-similarity metric of text does not have a significant effect on the accuracy of the model. As a result, the classification algorithms show different accuracy scores, which vary by more than 20% when comparing the worst and best models. For the designed password-strength dataset, the decision tree algorithm with Levenshtein Ratio for password similarity to the provided dictionaries demonstrated the highest accuracy of 78%. The results are not comparable to those of other research works. However, the score is very similar to the results that can be achieved for the Lithuanian language in other machine learning tasks.
The password-strength-class estimation model obtained for Lithuanian users was tested with an additional password dataset. This dataset was not used for model training and testing in previous experiments. The results obtained indicate very similar results and show 76% accuracy for international passwords and 79% accuracy for Lithuanian-word-based passwords. This is not a statistically significant difference and shows the stability of the model, and the size of the training data is sufficient to ensure it.
Author Contributions
Conceptualization, E.D., P.S. and S.R.; methodology, P.S.; software, E.D. and S.R.; validation, E.D. and P.S.; formal analysis, E.D.; investigation, P.S.; data curation, S.R.; writing—original draft preparation, E.D.; writing—review and editing, P.S. and S.R.; visualization, E.D.; supervision, P.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The password-strength dataset can be downloaded at https://www.kaggle.com/datasets/pavelstefanovi/password-of-international-and-lithuanian-context. accessed on 1 May 2023.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Huang, C.; Chen, S.; Zhang, Y.; Zhou, W.; Rodrigues, J.J.; de Albuquerque, V.H.C. A robust approach for privacy data protection: IoT security assurance using generative adversarial imitation learning. IEEE Internet Things J. 2021, 9, 17089–17097. [Google Scholar] [CrossRef]
- Li, H.; Yu, L.; He, W. The impact of GDPR on global technology development. J. Glob. Inform. Technol. Manag. 2019, 22, 1–6. [Google Scholar] [CrossRef]
- Kloza, D.; Van Dijk, N.; Casiraghi, S.; Vazquez Maymir, S.; Roda, S.; Tanas, A.; Konstantinou, I. Towards a method for data protection impact assessment: Making sense of GDPR requirements. Policy Brief D. Pia. Lab 2019, 1, 1–8. [Google Scholar]
- Haghshenas, S.H.; Hasnat, M.A.; Naeini, M. A temporal graph neural network for cyber attack detection and localization in smart grids. In Proceedings of the 2023 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 16–19 January 2023. [Google Scholar]
- Inayat, U.; Zia, M.F.; Mahmood, S.; Khalid, H.M.; Benbouzid, M. Learning-based methods for cyber attacks detection in IoT systems: A survey on methods, analysis, and future prospects. Electronics 2022, 11, 1502. [Google Scholar] [CrossRef]
- Rastenis, J.; Ramanauskaitė, S.; Suzdalev, I.; Tunaitytė, K.; Janulevičius, J.; Čenys, A. Multi-Language spam/Phishing classification by Email Body text: Toward automated security Incident investigation. Electronics 2021, 10, 668. [Google Scholar] [CrossRef]
- Čeponis, D.; Goranin, N. Investigation of dual-flow deep learning models LSTM-FCN and GRU-FCN efficiency against single-flow CNN models for the host-based intrusion and malware detection task on univariate times series data. Appl. Sci. 2021, 10, 2373. [Google Scholar] [CrossRef]
- Hughes-Lartey, K.; Li, M.; Botchey, F.E.; Qin, Z. Human factor, a critical weak point in the information security of an organization’s Internet of things. Heliyon 2021, 7, e06522. [Google Scholar] [CrossRef] [PubMed]
- Lal, N.A.; Prasad, S.; Farik, M. A review of authentication methods. Int. J. Sci. Technol. Res. 2016, 5, 246–249. [Google Scholar]
- Yang, W.; Wang, S.; Hu, J.; Zheng, G.; Valli, C. Security and accuracy of fingerprint-based biometrics: A review. Symmetry 2019, 11, 141. [Google Scholar] [CrossRef]
- Gwyn, T.; Roy, K.; Atay, M. Face recognition using popular deep net architectures: A brief comparative study. Fut. Internet 2021, 13, 164. [Google Scholar] [CrossRef]
- Mehrubeoglu, M.; Nguyen, V. Real-time eye tracking for password authentication. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 12–14 January 2018. [Google Scholar]
- Mahesh, T.R.; Ram, M.S.; Ram, N.S.S.; Gowtham, A.; Swamy, T.N. Real-Time Eye Blinking for Password Authentication. In Proceedings of the International Conference on Intelligent Emerging Methods of Artificial Intelligence & Cloud Computing: Proceedings of IEMAICLOUD 2021, online, 26–29 April 2021. [Google Scholar]
- Juozapavičius, A.; Brilingaitė, A.; Bukauskas, L.; Lugo, R.G. Age and Gender Impact on Password Hygiene. Appl. Sci. 2022, 12, 894. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Q. A comprehensive review study of cyber-attacks and cyber security; Emerging trends and recent developments. Energy Rep. 2021, 7, 8176–8186. [Google Scholar] [CrossRef]
- Awad, M.; Al-Qudah, Z.; Idwan, S.; Jallad, A.H. Password security: Password behavior analysis at a small university. In Proceedings of the 2016 5th International Conference on Electronic Devices, Systems and Applications (ICEDSA), Ras Al Khaimah, United Arab Emirates, 6–8 December 2016. [Google Scholar]
- Katsini, C.; Fidas, C.; Raptis, G.E.; Belk, M.; Samaras, G.; Avouris, N. Influences of human cognition and visual behavior on password strength during picture password composition. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Palais des Congrès de Montréal, Canada, 21–26 April 2018. [Google Scholar]
- Ur, B.; Segreti, S.M.; Bauer, L.; Christin, N.; Cranor, L.F.; Komanduri, S.; Kurilova, D.; Mazurek, M.L.; Melicher, W.; Shay, R.; et al. Measuring real-world accuracies and biases in modeling password guessability. In Proceedings of the 24th {USENIX} Security Symposium ({USENIX} Security 15), Washington, DC, USA, 12–14 August 2015. [Google Scholar]
- Golla, M.; Dürmuth, M. On the Accuracy of Password Strength Meters. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, New York, NY, USA, 15–19 October 2018. [Google Scholar]
- Wheeler, D.L. zxcvbn: Low-Budget Password Strength Estimation. In Proceedings of the 25th USENIX Security, Austin, TX, USA, 10–12 August 2016. [Google Scholar]
- Doucek, P.; Pavlíček, L.; Sedláček, J.; Nedomová, L. Adaptation of password strength estimators to a non-english environment —the Czech experience. Comput. Secur. 2020, 95, 101757. [Google Scholar] [CrossRef]
- Hong, K.H.; Kang, U.G.; Lee, B.M. Enhanced Evaluation Model of Security Strength for Passwords Using Integrated Korean and English Password Dictionaries. Secur. Communicat. Netw. 2021, 2021, 3122627. [Google Scholar] [CrossRef]
- Sarkar, S.; Nandan, M. Password Strength Analysis and its Classification by Applying Machine Learning Based Techniques. In Proceedings of the 2022 Second International Conference on Computer Science, Engineering and Applications (ICCSEA), Gunupur, India, 8 September 2022. [Google Scholar]
- Bansal, B. Password Strength Classifier Dataset. Available online: https://www.kaggle.com/datasets/bhavikbb/password-strength-classifier-dataset (accessed on 25 May 2022).
- Kim, S.J.; Lee, B.M. Multi-Class Classification Prediction Model for Password Strength Based on Deep Learning. J. Multimed. Inf. Syst. 2023, 10, 45–52. [Google Scholar] [CrossRef]
- Mantas Sasnauskas—Lexcor. LT-SecList: Lithuanian Passwords, Wordlists. GitHub. Available online: https://github.com/lexcor/LT-SecList (accessed on 25 May 2023).
- Most Common Last Names in Lithuania. Forebears. Available online: https://forebears.io/lithuania/surnames (accessed on 25 May 2023).
- Most Popular First Names in Lithuania. Forebears. Available online: https://forebears.io/lithuania/forenames (accessed on 25 May 2023).
- Singh, A.; Thakur, N.; Sharma, A. A review of supervised machine learning algorithms. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016. [Google Scholar]
- Sen, P.C.; Hajra, M.; Ghosh, M. Supervised classification algorithms in machine learning: A survey and review. In Proceedings of the Emerging Technology in Modelling and Graphics: Proceedings of IEM Graph 2018, Kolkata, India, 6–7 September 2018. [Google Scholar]
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A survey of deep learning and its applications: A new paradigm to machine learning. Arch. Comput. Methods Eng. 2020, 27, 1071–1092. [Google Scholar] [CrossRef]
- Xie, Z.; Lin, Y.; Yao, Z.; Zhang, Z.; Dai, Q.; Cao, Y.; Hu, H. Self-supervised learning with swin transformers. arXiv 2021, arXiv:2105.04553. [Google Scholar]
- Kapočiūtė-Dzikienė, J.; Salimbajevs, A. Comparison of Deep Learning Approaches for Lithuanian Sentiment Analysis. Baltic J. Mod. Comput. 2022, 10, 283–294. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).