1. Introduction
Bearings are a critical support component in mechanical transmission systems, and their fault diagnosis is key to ensuring the safe operation of equipment and avoiding economic losses. Numerous intelligent fault diagnosis methods have emerged in the research of bearing fault diagnosis [
1,
2]. In the early stages of intelligent fault diagnosis for bearings, scholars proposed diagnostic methods based on shallow machine learning, including extreme learning machines, support vector machines, and Bayesian methods [
3,
4]. In recent years, the accuracy of traditional unsupervised learning methods such as clustering, feature statistics, and random forests in identifying mechanical faults has been significantly lower than that of supervised learning neural networks in fault diagnosis [
5,
6,
7], attracting widespread attention from both industry and academia. Particularly, deep learning, as a representative data-driven method, has been successfully applied to the field of mechanical equipment fault diagnosis. However, supervised deep learning methods have certain limitations, such as the need for sufficient and complete labeled fault samples and the requirement that the distribution of fault sample features used for training is consistent with the distribution of real fault sample features [
8,
9]. In actual industrial production, due to the variable operating states of equipment such as load, speed, and torque, as well as the impact of mechanical wear and external noise variations, the original vibration signals exhibit different feature distributions. Moreover, most of the collected data are unlabeled, and obtaining a complete labeled fault dataset is very difficult and requires significant human and material resources [
10].
Many scholars have conducted extensive research in solving the problem of unlabeled equipment fault diagnosis [
11,
12,
13]. The domain adversarial adaptive method is a transfer learning approach that has made significant contributions to solving the problem of fault recognition with few training samples and missing labels [
14]. Jiao et al. [
15] proposed an adversarial adaptive network with periodic feature alignment to facilitate transferable feature learning. Additionally, numerous researchers have integrated both approaches to enhance diagnostic performance [
16,
17]. Ganin et al. [
18] proposed transfer learning by adding domain discriminators on the basis of Adversarial Generative Networks (GANs). For various types of transfer tasks, the transfer learning can be divided into subdomain transfer learning [
19], closed domain transfer learning [
20], multi-source domain transfer learning, etc. Xu et al. [
21] proposed an unsupervised transfer learning model for multi-source domains by transferring multiple sets of source domain data to the target domain. In order to solve the problem of insufficient fault samples that prevent the practical application of intelligent fault diagnosis methods, Li et al. [
22] proposed a Cyclic Consistent Generative Adversarial Network (Cycle GAN). Wu et al. [
23] introduced a novel approach called Adversarial Multiple-Target Domains Adaptation (AMDA), which utilizes adversarial learning to ensure that the distribution of sample features in multiple target domains is similar to that in the source domain. While these earlier methods have enhanced diagnostic performance, they primarily rely on adversarial learning for feature distribution alignment and do not address fault class-wise alignment [
24].
Most domain adversarial fault identification models focus only on the effect of cross-domain fault identification, paying little attention to the structural issues of network models when the source and target domain distributions cannot strictly coincide. This makes the features prone to defects such as information unidirectionality and focal flattening, leading to bottlenecks in model performance improvement.
To address the issue of training with unlabeled data, Zhao et al. [
25] constructed a deep shrinkage residual network with added soft thresholds to extract feature information from bearing vibration data under noise redundancy, completing fault diagnosis by applying marginal distribution constraints to input features. Shao et al. [
26] transferred the distribution of source domain sample features to the distribution area of target domain sample features, and used sufficient source domain samples to train the recognition model, improving the classification accuracy of the model in the target domain. Li et al. [
27] proposed a joint mean difference matching algorithm to establish a common subspace, thereby completing fault diagnosis for industrial processes. The premise of the above literature research is that the target domain (industrial environment) has a large and balanced sample of fault data. However, the practical utility of the data is weak, leading to insufficient target domain data to train high-accuracy models in industrial production. And traditional adversarial transfer networks include only one feature extractor, which is responsible for mapping both source domain and target domain sample features, significantly compromising the performance of the feature extractor under such demands.
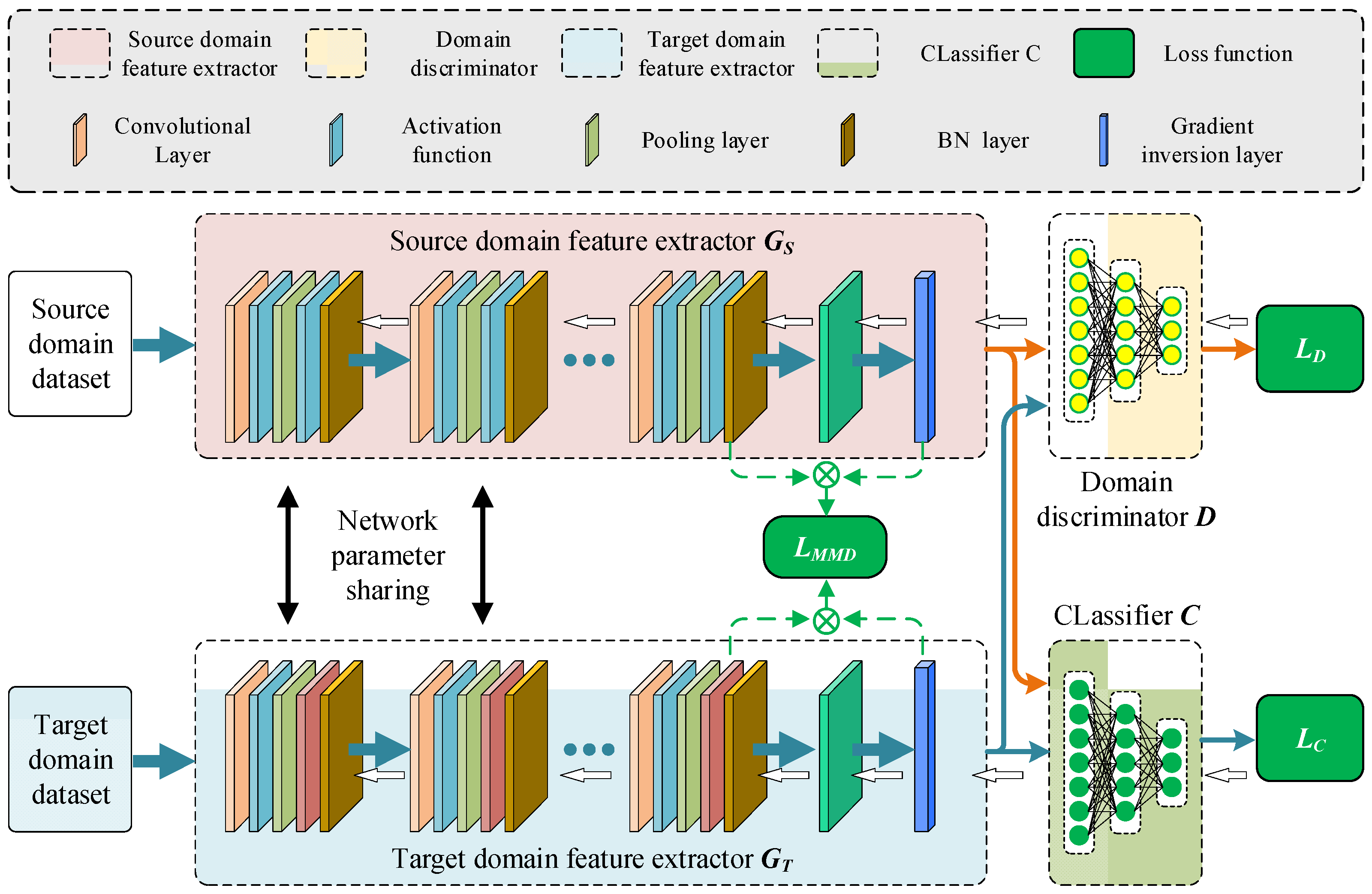
Therefore, this paper proposes a Collaborative Domain Adversarial Network for unlabeled bearing fault diagnosis, which utilizes prior knowledge from the source domain samples (laboratory manual fault samples) and unlabeled target domain samples (fault samples in industrial environments) for adaptive learning, achieving unlabeled bearing intelligent fault diagnosis. Domain adversarial adaptation involves establishing a model to use source domain information for related target domain fault identification. This study sets up two feature extractors for different mapping tasks of the source and target domains, and the main contributions are summarized as follows:
- (1)
This paper proposes a Collaborative Domain Adversarial Network (CDAN) model with two types of feature extractors for unlabeled bearing fault identification, which can transfer the fault characteristics of laboratory artificial fault samples to the distribution area of real fault sample characteristics, and fully train the fault diagnosis model using the rich transferred fault characteristics.
- (2)
A strategy of using multi-kernel clustering to pseudo-label target domain samples has been proposed, which solves the problem of failure diagnosis in mechanical engineering due to lack of labels in actual faults
- (3)
The two types of feature extractors can accurately map the source domain features and target domain features, reducing the difference in sample feature distribution and lowering the negative transfer rate of sample transfer learning, thereby improving the accuracy of unlabeled bearing fault diagnosis.
The rest of this article is organized as follows.
Section 2 describes the theoretical background.
Section 3 introduces the model framework, forward propagation, and parameter optimization process of CDAN.
Section 4 analyzes and verifies the effectiveness of CDAN by experiments.
Section 5 concludes this article.
5. Conclusions
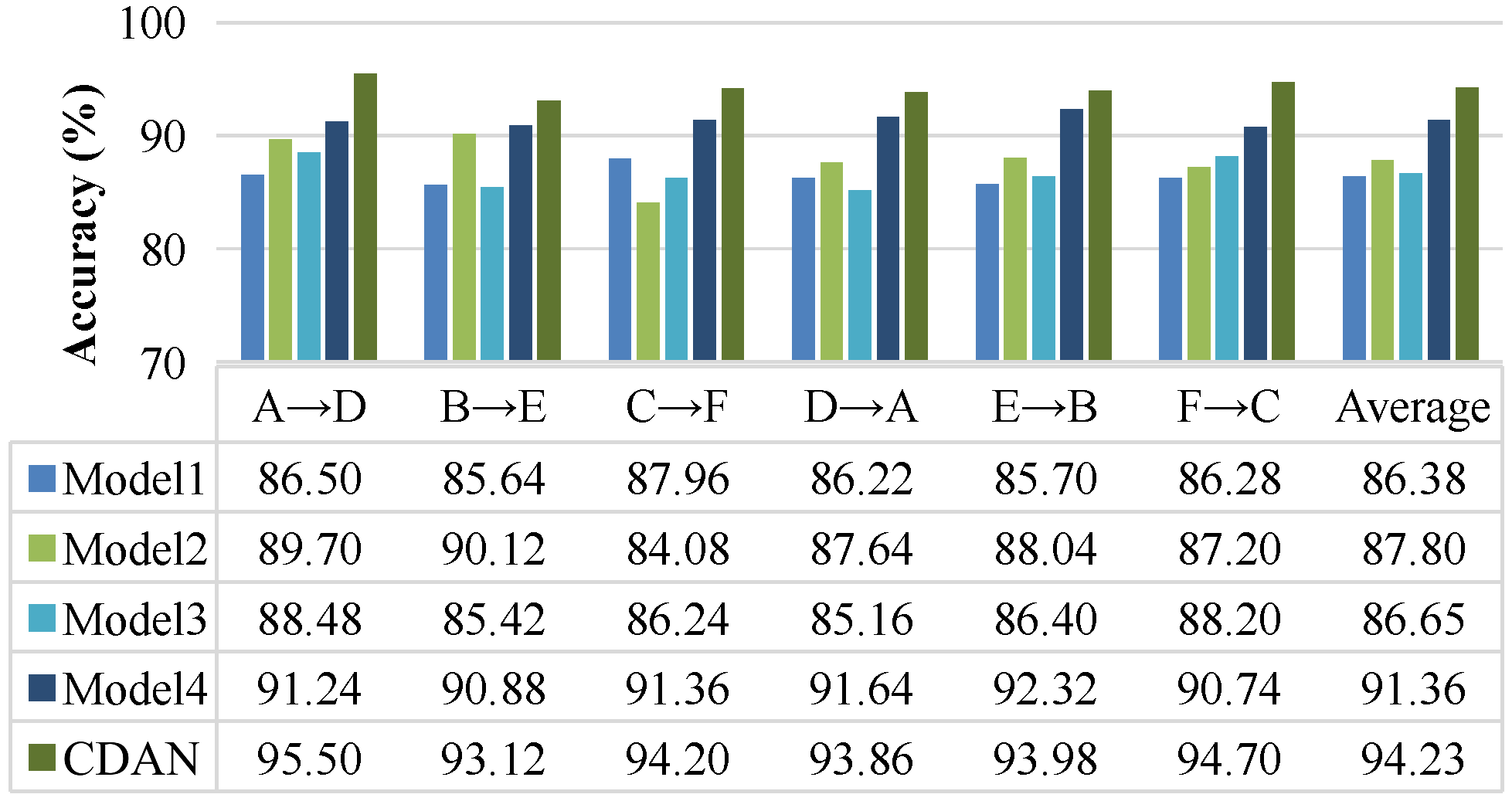
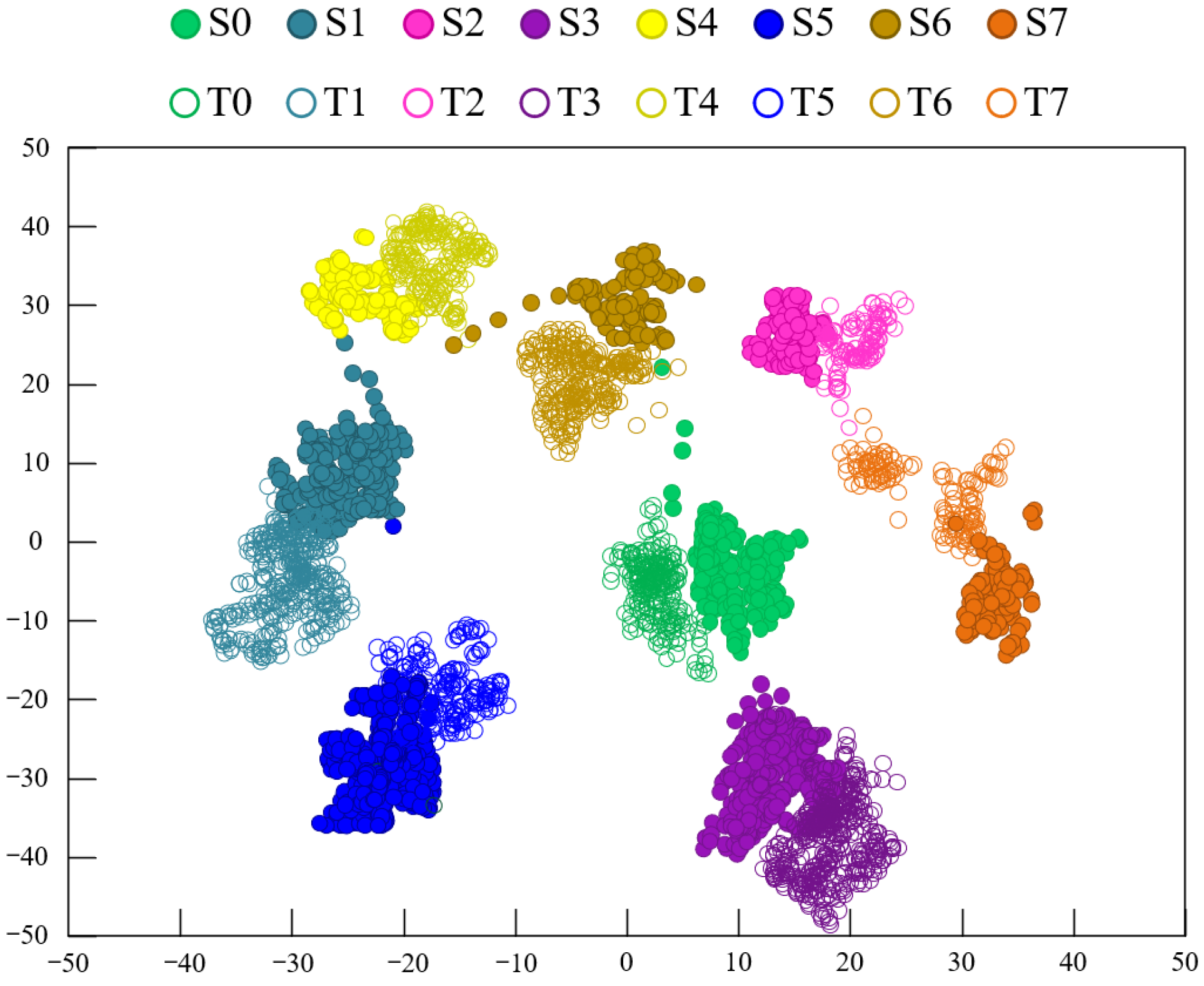
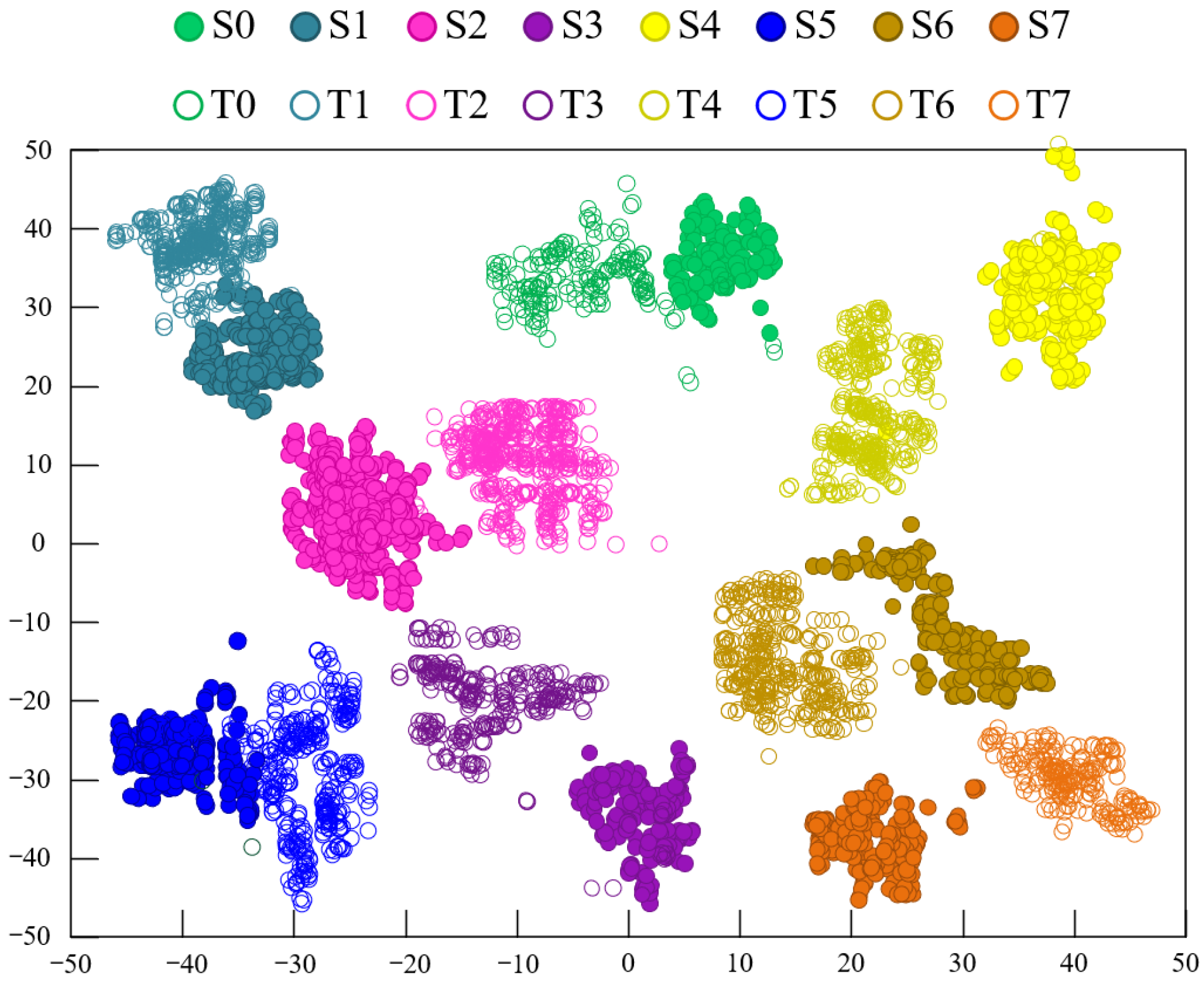
The proposed CDAN aims to solve the negative transfer problem in transfer learning based fault diagnosis models and improve the accuracy of unlabeled bearing fault diagnosis. By employing two types of feature extractors and multi-linear mapping, the classifier’s predicted classification information is fed back to the domain discriminator to enhance the learning of domain-invariant features. To validate the feasibility of this model, experiments were conducted on two datasets. On the CRWU dataset, data under different loads and positions were respectively set as source domain and target domain datasets, verifying the superiority and stability of the CDAN. Similar results were observed on the PU dataset. Using t-SNE, the visualization of classification features learned by different models shows that the CDAN clustering has good intra-class and inter-class compactness. Compared with four other advanced methods, the CDAN improved the average recognition accuracy by 7.85% and 5.22%, respectively. This indirectly proves the effectiveness and superiority of the CDAN in identifying unlabeled bearing faults. The CDAN can be applied for fault diagnosis of supporting bearings in motors. Further research is needed to determine whether it can be used for fault diagnosis of rotors, coils, and other components in motors. These results indicate that the CDAN effectively reduces cross-domain distribution discrepancies in sample transfer learning and is a promising method for rolling bearing fault diagnosis. CDAN requires sufficient laboratory failure samples as support, which requires a lot of manpower and resources. The generation of fault data through digital twins can perfectly solve this problem, which is also the future research direction of this study.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}