

A Study on Performance Enhancement by Integrating Neural Topic Attention with Transformer-Based Language Model


Abstract
1. Introduction
2. Related Works
2.1. Traditional Topic Modeling
2.2. Neural Topic Modeling
3. Proposed Model
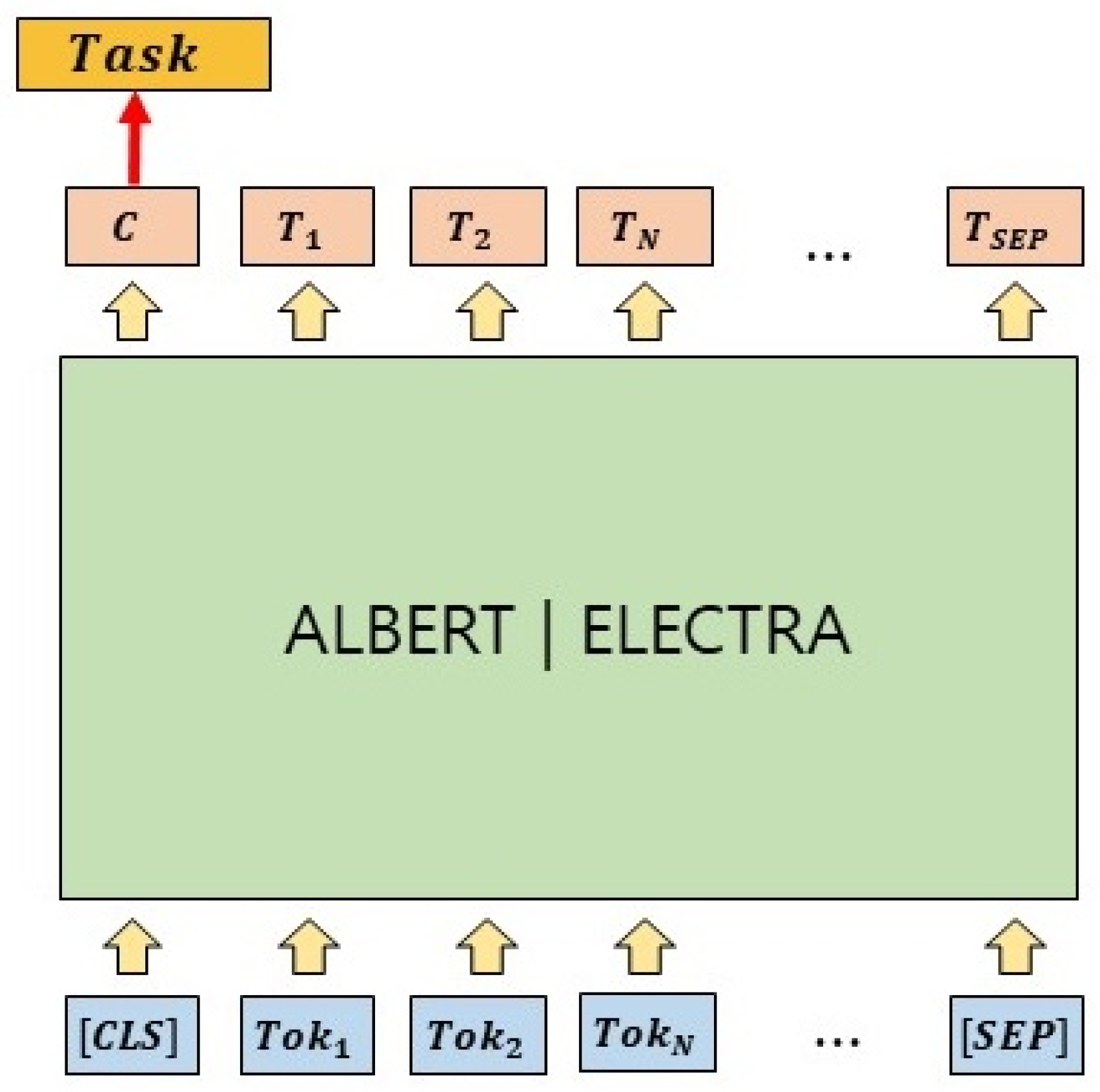
3.1. ALBERT (ELECTRA) Baseline Model
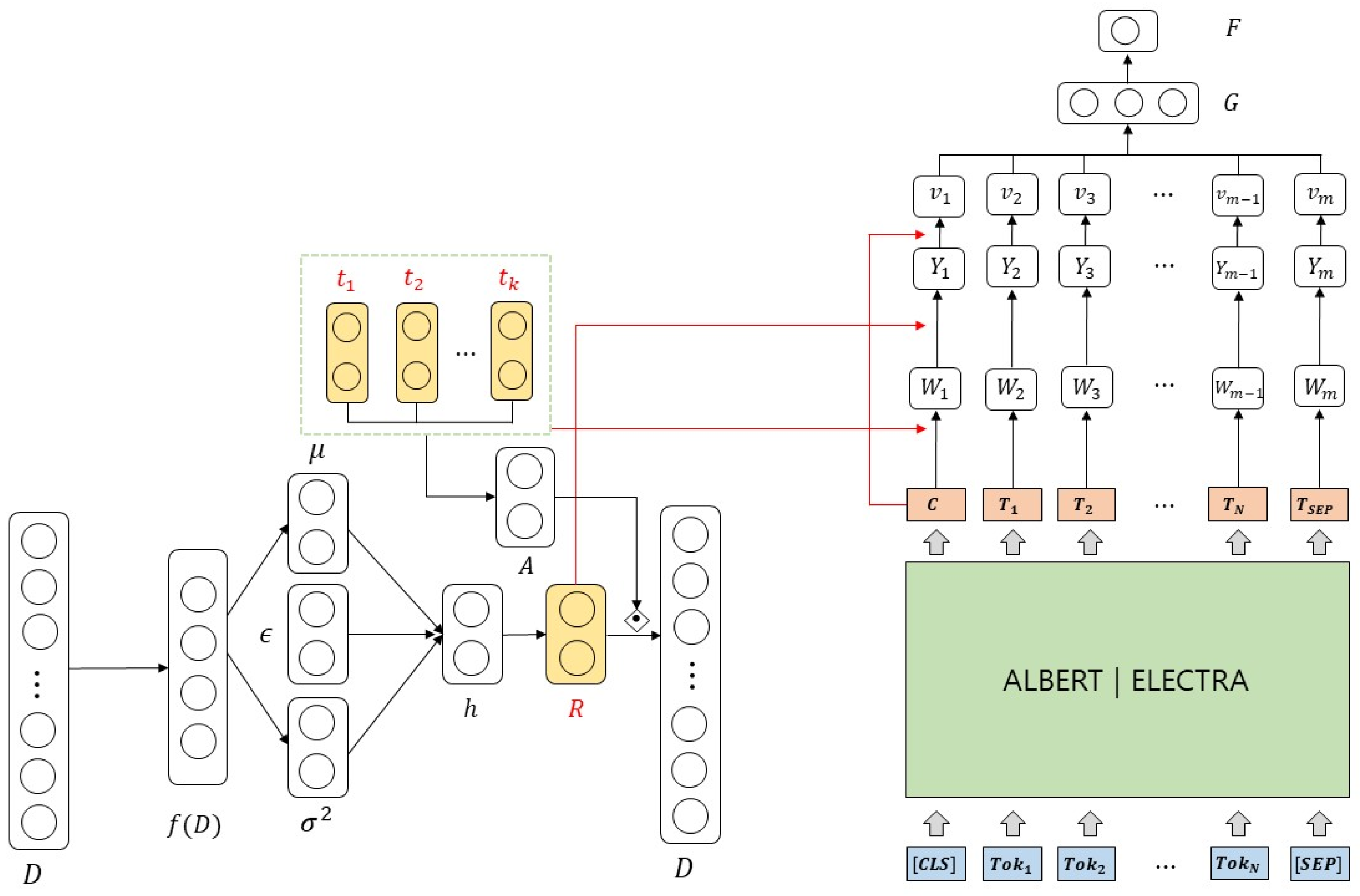
3.2. ALBERT (ELECTRA) Nueral Topic Model
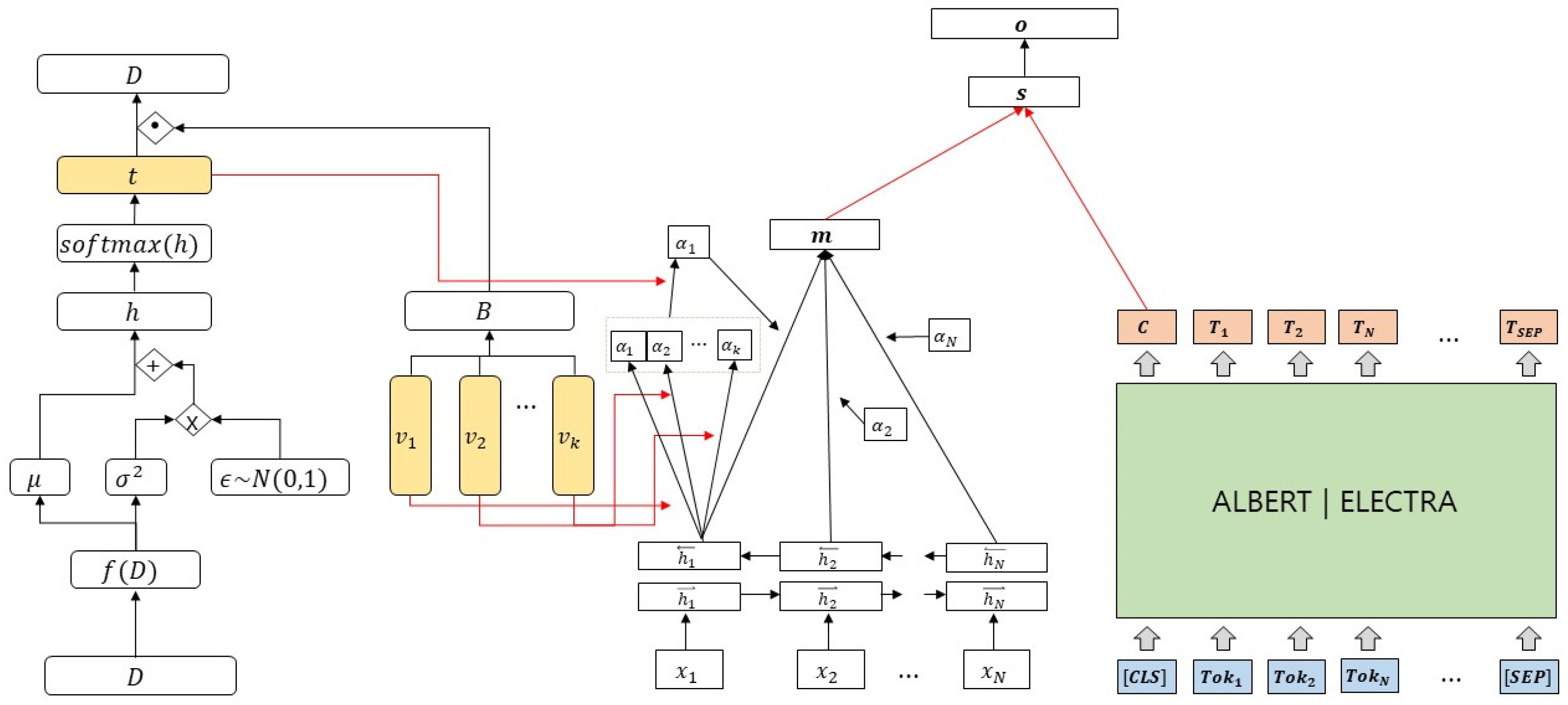
3.3. Model Loss
4. Experiments
4.1. Datasets
4.2. Hyperparameters
4.3. Results
4.4. Number of Topic Effects
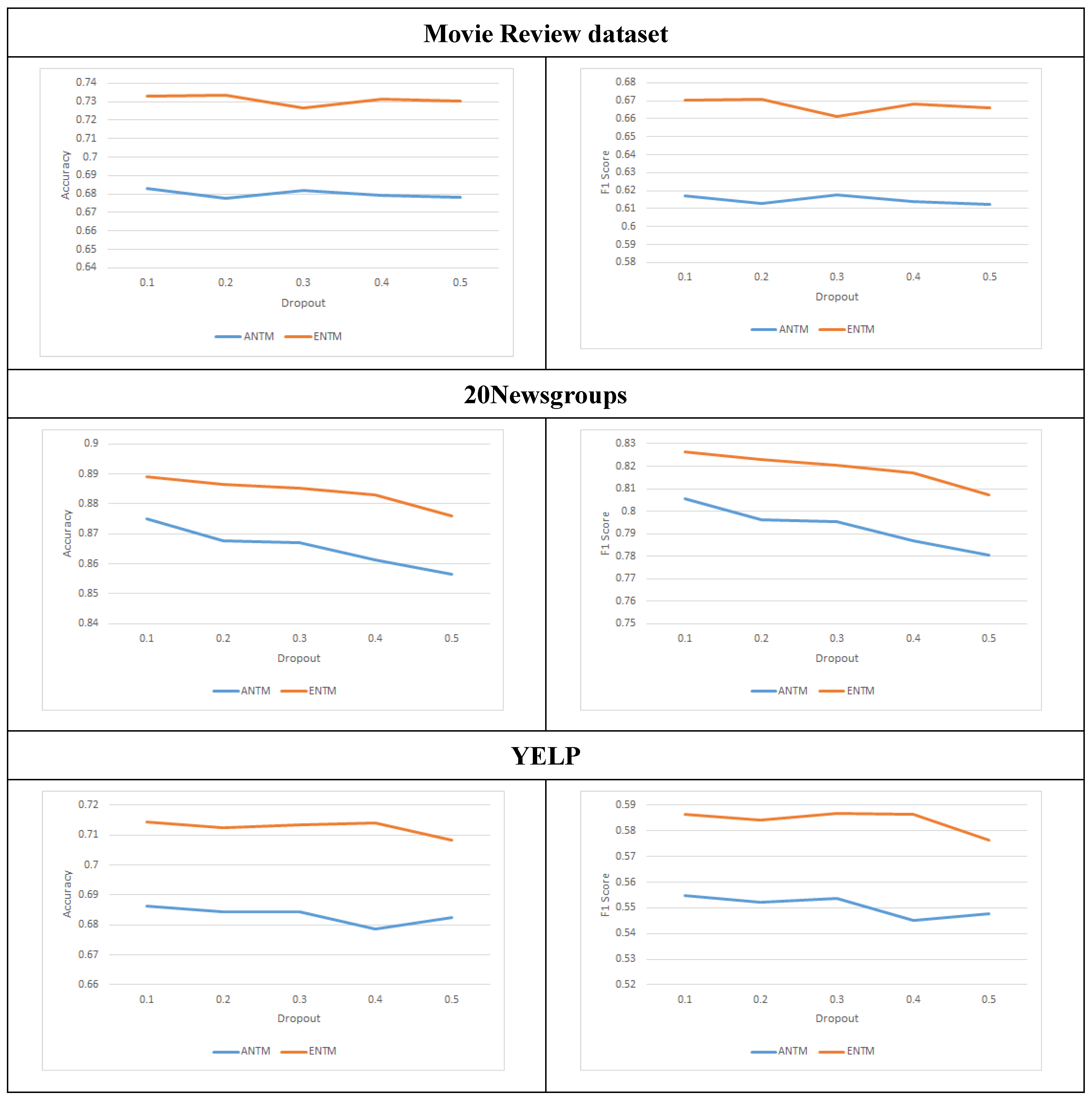
4.5. Dropout Effects
4.6. Neural Topic Ensembel Model
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optim. Bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. GPT-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- He, P.; Gao, J.; Chen, W. DeBERTaV3: Improving DeBERTa using ELECTRA-style pre-training with gradient-disentangled embedding sharing. arXiv 2021, arXiv:2111.09543. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and policy considerations for deep learning in NLP. arXiv 2019, arXiv:1906.02243. [Google Scholar]
- Han, X.; Zhang, Z.; Ding, N.; Gu, Y.; Liu, X.; Huo, Y.; Qiu, J.; Yao, Y.; Zhang, A.; Zhang, L.; et al. Pre-trained models: Past, present and future. AI Open 2021, 2, 225–250. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Zhao, H.; Phung, D.; Huynh, V.; Jin, Y.; Du, L.; Buntine, W. Topic modelling meets deep neural networks: A survey. arXiv 2021, arXiv:2103.00498. [Google Scholar]
- Mcauliffe, J.; Blei, D. Supervised topic models. Adv. Neural Inf. Process. Syst. 2007, 20, 121–128. [Google Scholar]
- Ramage, D.; Hall, D.; Nallapati, R.; Manning, C.D. Labeled LDA: A supervised topic model for credit attribution in multi-labeled corpora. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–7 August 2009; pp. 248–256. [Google Scholar]
- Moghaddam, S.; Ester, M. ILDA: Interdependent LDA model for learning latent aspects and their ratings from online product reviews. In Proceedings of the 34th International ACM SIGIR Conference on RESEARCH and Development in Information Retrieval, Beijing, China, 24–28 July 2011; pp. 665–674. [Google Scholar]
- Li, X.; Ouyang, J.; Zhou, X. Supervised topic models for multi-label classification. Neurocomputing 2015, 149, 811–819. [Google Scholar] [CrossRef]
- Li, J.; Cardie, C.; Li, S. Topicspam: A topic-model based approach for spam detection. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2013; pp. 217–221. [Google Scholar]
- Amara, A.; Hadj Taieb, M.A.; Ben Aouicha, M. Multilingual topic modeling for tracking COVID-19 trends based on Facebook data analysis. Appl. Intell. 2021, 51, 3052–3073. [Google Scholar] [CrossRef]
- Na, L.; Ming-xia, L.; Hai-yang, Q.; Hao-long, S. A hybrid user-based collaborative filtering algorithm with topic model. Appl. Intell. 2021, 51, 7946–7959. [Google Scholar] [CrossRef]
- Gupta, P.; Chaudhary, Y.; Buettner, F.; Schütze, H. Document informed neural autoregressive topic models with distributional prior. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, No. 01. pp. 6505–6512. [Google Scholar]
- Larochelle, H.; Lauly, S. A neural autoregressive topic model. Adv. Neural Inf. Process. Syst. 2012, 25, 2708–2716. [Google Scholar]
- Wang, R.; Zhou, D.; He, Y. Atm: Adversarial-neural topic model. Inf. Process. Manag. 2019, 56, 102098. [Google Scholar] [CrossRef]
- Wang, R.; Hu, X.; Zhou, D.; He, Y.; Xiong, Y.; Ye, C.; Xu, H. Neural topic modeling with bidirectional adversarial training. arXiv 2002, arXiv:2004.12331. [Google Scholar]
- Miao, Y.; Grefenstette, E.; Blunsom, P. Discovering discrete latent topics with neural variational inference. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2410–2419. [Google Scholar]
- Wu, J.; Rao, Y.; Zhang, Z.; Xie, H.; Li, Q.; Wang, F.L.; Chen, Z. Neural mixed counting models for dispersed topic discovery. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 6159–6169. [Google Scholar]
- Wang, X.; Yang, Y. Neural topic model with attention for supervised learning. In Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics, Online, 26–28 August 2020; pp. 1147–1156. [Google Scholar]
- Peinelt, N.; Nguyen, D.; Liakata, M. tBERT: Topic models and BERT joining forces for semantic similarity detection. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 7047–7055. [Google Scholar]
- Yin, J.; Wang, J. A dirichlet multinomial mixture model-based approach for short text clustering. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 233–242. [Google Scholar]
- Chaudhary, Y.; Gupta, P.; Saxena, K.; Kulkarni, V.; Runkler, T.; Schütze, H. TopicBERT for energy efficient document classification. arXiv 2020, arXiv:2010.16407. [Google Scholar]
- Miao, Y.; Yu, L.; Blunsom, P. Neural variational inference for text processing. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1727–1736. [Google Scholar]
- Bianchi, F.; Terragni, S.; Hovy, D. Pre-training is a hot topic: Contextualized document embeddings improve topic coherence. arXiv 2020, arXiv:2004.03974. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Pang, B.; Lee, L. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. arXiv 2005, arXiv:cs/0506075. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Home Page for 20Newsgroups Data Set. Available online: http://qwone.com/~jason/20Newsgroups/ (accessed on 23 July 2024).
- Jiang, M.; Liang, Y.; Feng, X.; Fan, X.; Pei, Z.; Xue, Y.; Guan, R. Text classification based on deep belief network and softmax regression. Neural Comput. Appl. 2018, 29, 61–70. [Google Scholar] [CrossRef]
- Yelp Open Dataset. Available online: https://www.yelp.com/dataset (accessed on 23 July 2024).
- Tang, D.; Qin, B.; Liu, T. Document modeling with gated recurrent neural network for sentiment classification. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 1422–1432. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | MRD | 20News | YELP |
|---|---|---|---|
| # Train | 4506 | 15,063 | 30,000 |
| # Test | 500 | 3766 | 6000 |
| Task | Multi-classification (3 labels) | Multi-classification (20 labels) | Multi-classification (5 labels) |
| Max Length | 256 | Dropout | 0.1 |
| Batch Size | 8 | Epochs | 5 |
| Learning Rate | 2 × 10−5 | Number of Topic | 50 |
| Optimizer | AdamW | Embedding Size | 100 |
| Weight Decay | 0.01 | Threshold | 0.1 |
| Dataset | MRD | ||||
| Evaluation Model | AUC | Precision | Recall | F1 | Time (s) |
| AVM | 0.6604 | 0.6348 | 0.6233 | 0.5940 | 244 |
| ANTM | 0.6862 | 0.6593 | 0.6506 | 0.6213 | 262 |
| EVM | 0.7303 | 0.7005 | 0.6922 | 0.6677 | 249 |
| ENTM | 0.7390 | 0.7125 | 0.7021 | 0.6795 | 266 |
| Dataset | 20Newsgroups | ||||
| Evaluation Model | AUC | Precision | Recall | F1 | Time (s) |
| AVM | 0.8694 | 0.8026 | 0.8016 | 0.7972 | 853 |
| ANTM | 0.8754 | 0.8121 | 0.8114 | 0.8070 | 929 |
| EVM | 0.8948 | 0.8381 | 0.8372 | 0.8333 | 862 |
| ENTM | 0.8883 | 0.8302 | 0.8295 | 0.8255 | 933 |
| Dataset | YELP | ||||
| Evaluation Model | AUC | Precision | Recall | F1 | Time (s) |
| AVM | 0.6830 | 0.5656 | 0.5743 | 0.5478 | 1666 |
| ANTM | 0.6871 | 0.5751 | 0.5837 | 0.5567 | 1792 |
| EVM | 0.7115 | 0.5956 | 0.6047 | 0.5787 | 1694 |
| ENTM | 0.7145 | 0.6050 | 0.6124 | 0.5871 | 1809 |
| Dataset | ANTM Accuracy | ANTM Precision | ANTM Recall | ANTM F1 | ||||
| Test Statistic | p-Value | Test Statistic | p-Value | Test Statistic | p-Value | Test Statistic | p-Value | |
| MRD | −4.2576 | 0.0018 | −3.4281 | 0.0048 | −4.7978 | 0.0004 | −4.1896 | 0.0011 |
| 20Newsgroups | −2.4514 | 0.0300 | −2.9484 | 0.0112 | −3.0977 | 0.0082 | −2.9638 | 0.0108 |
| YELP | −4.6724 | 0.0003 | −5.7028 | 0.0001 | −5.5028 | 0.0001 | −5.9682 | 0.0001 |
| Dataset | ENTM Accuracy | ENTM Precision | ENTM Recall | ENTM F1 | ||||
| Test Statistic | p-Value | Test Statistic | p-Value | Test Statistic | p-Value | Test Statistic | p-Value | |
| MRD | −2.2591 | 0.0382 | −2.5513 | 0.0226 | −2.6032 | 0.0200 | −2.7763 | 0.0139 |
| 20Newsgroups | 4.3831 | 0.0011 | 3.8788 | 0.0023 | 4.1705 | 0.0015 | 3.9874 | 0.0020 |
| YELP | −2.5017 | 0.0240 | −4.4778 | 0.0004 | −4.4527 | 0.0004 | −4.5023 | 0.0004 |
| Dataset | MRD | ||||
| Evaluation Model | AUC | Precision | Recall | F1 | Time (s) |
| AVM | 0.6604 | 0.6348 | 0.6233 | 0.5940 | 244 |
| ANTM | 0.6862 | 0.6593 | 0.6506 | 0.6213 | 262 |
| ANEM | 0.6288 | 0.6093 | 0.5977 | 0.5684 | 296 |
| EVM | 0.7303 | 0.7005 | 0.6922 | 0.6677 | 249 |
| ENTM | 0.7390 | 0.7125 | 0.7021 | 0.6795 | 266 |
| ENEM | 0.7279 | 0.6927 | 0.6902 | 0.6697 | 302 |
| Dataset | 20Newsgroups | ||||
| Evaluation Model | AUC | Precision | Recall | F1 | Time (s) |
| AVM | 0.8694 | 0.8026 | 0.8016 | 0.7972 | 853 |
| ANTM | 0.8754 | 0.8121 | 0.8114 | 0.8070 | 929 |
| ANEM | 0.8420 | 0.7678 | 0.7686 | 0.7631 | 1043 |
| EVM | 0.8948 | 0.8381 | 0.8372 | 0.8333 | 862 |
| ENTM | 0.8883 | 0.8302 | 0.8295 | 0.8255 | 933 |
| ENEM | 0.8888 | 0.8293 | 0.8287 | 0.8246 | 1049 |
| Dataset | YELP | ||||
| Evaluation Model | AUC | Precision | Recall | F1 | Time (s) |
| AVM | 0.6830 | 0.5656 | 0.5743 | 0.5478 | 1666 |
| ANTM | 0.6871 | 0.5751 | 0.5837 | 0.5567 | 1792 |
| ANEM | 0.6760 | 0.5499 | 0.5626 | 0.5339 | 2039 |
| EVM | 0.7115 | 0.5956 | 0.6047 | 0.5787 | 1694 |
| ENTM | 0.7145 | 0.6050 | 0.6124 | 0.5871 | 1809 |
| ENEM | 0.7114 | 0.5970 | 0.6063 | 0.5802 | 2061 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Um, T.; Kim, N. A Study on Performance Enhancement by Integrating Neural Topic Attention with Transformer-Based Language Model. Appl. Sci. 2024, 14, 7898. https://doi.org/10.3390/app14177898
Um T, Kim N. A Study on Performance Enhancement by Integrating Neural Topic Attention with Transformer-Based Language Model. Applied Sciences. 2024; 14(17):7898. https://doi.org/10.3390/app14177898
Chicago/Turabian StyleUm, Taehum, and Namhyoung Kim. 2024. "A Study on Performance Enhancement by Integrating Neural Topic Attention with Transformer-Based Language Model" Applied Sciences 14, no. 17: 7898. https://doi.org/10.3390/app14177898
APA StyleUm, T., & Kim, N. (2024). A Study on Performance Enhancement by Integrating Neural Topic Attention with Transformer-Based Language Model. Applied Sciences, 14(17), 7898. https://doi.org/10.3390/app14177898