


Innovative Speech-Based Deep Learning Approaches for Parkinson’s Disease Classification: A Systematic Review

Abstract
1. Introduction
- RQ1.
- Which recent speech-based DL approaches are being considered for PD classification?
- RQ2.
- To what extent can speech-based DL approaches classify PD?
- RQ3.
- What are the issues related to bias, explainability, and privacy of speech-based DL approaches for PD classification?
- This review covers the most recent speech-based DL approaches for PD classification, until March 2024, for which the available resources, capabilities, and potential limitations are discussed. The review explicitly focuses on speech-based data and DL approaches.
- This review discusses issues relating to bias, explainability, and privacy associated with speech-based DL approaches for PD classification.
- This review includes an overview of publicly available speech-based datasets and open-source resources for PD classification, up to March 2024.
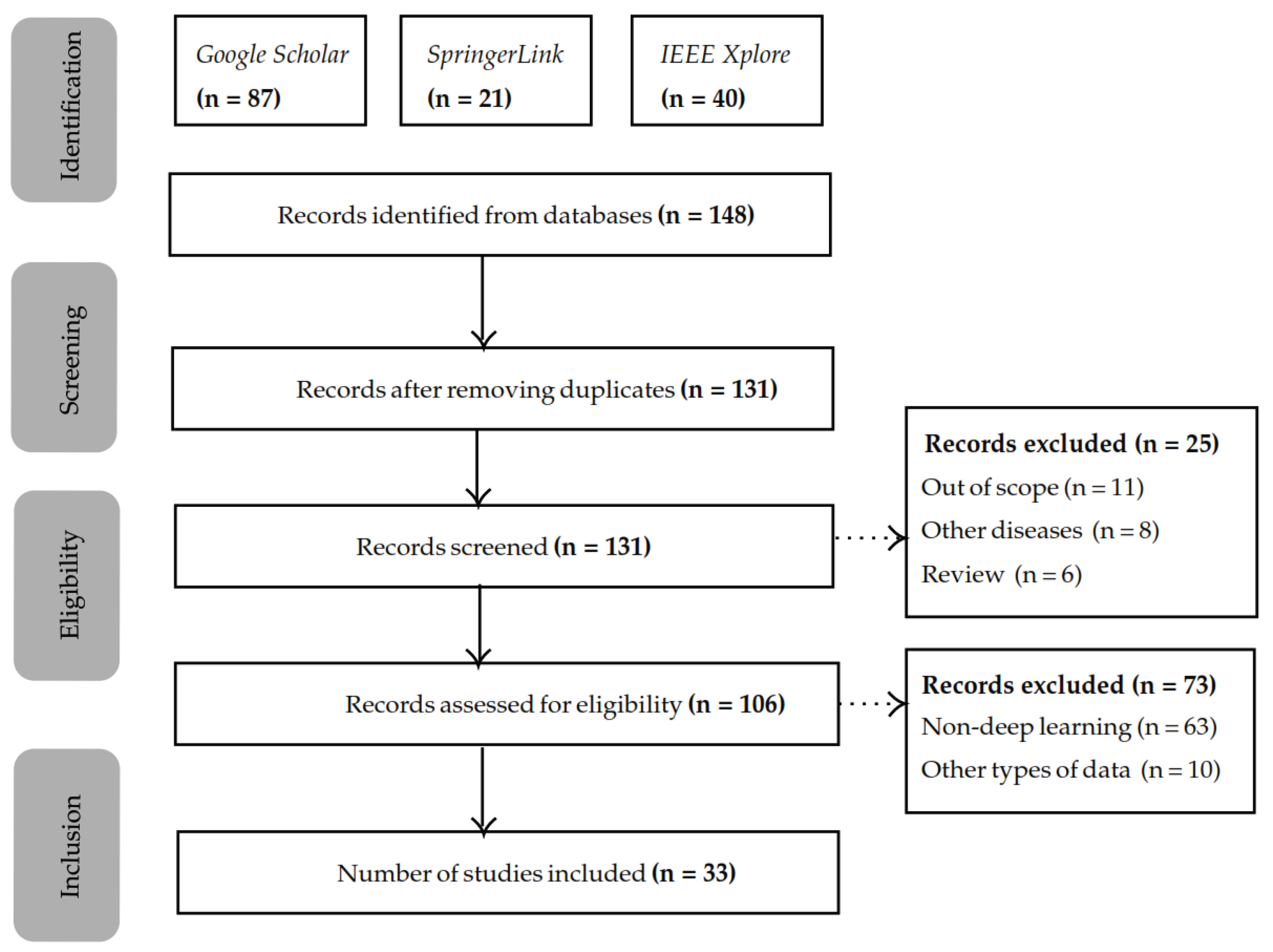
2. Methodology
2.1. Search Procedure and Identification Criteria
2.2. Screening and Exclusion Criteria
2.3. Eligibility and Inclusion Criteria
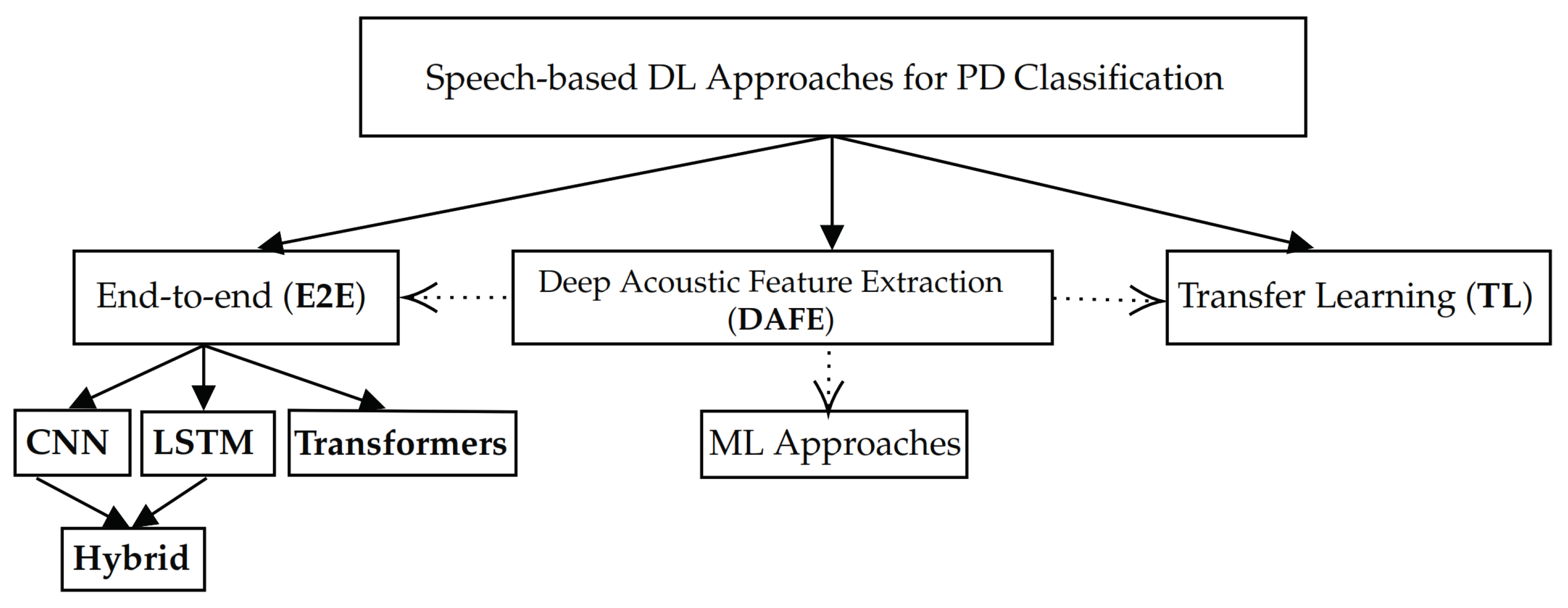
3. E2E Approach
3.1. CNNs and LSTMs
3.2. Hybrid CNN-LSTM Architectures
3.3. Transformers
4. TL Approach
5. DAFE Approach
6. Discussion
6.1. Findings and Implications
6.2. Bias Issues
6.3. Explainability Issues
6.4. Privacy Issues
6.5. Limitations
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 1D | One-dimensional |
| 2D | Two-dimensional |
| ADCNN | Acoustic Deep Convolutional Neural Network |
| ADNN | Acoustic Deep Neural Network |
| ADRNN | Acoustic Deep Recurrent Neural Network |
| AI | Artificial Intelligence |
| ALS | Amyotrophic Lateral Sclerosis |
| AUC | Area Under the Curve |
| CNN | Convolutional Neural Network |
| DAFE | Deep Acoustic Feature Extraction |
| DDK | Diadochokinetic |
| DIDK | monosyllabic targets |
| DL | Deep learning |
| DNN | Deep Neural Network |
| DT | Decision Tree |
| E2E | End-to-end |
| EEG | Electroencephalogram |
| EGSAE | Embedded Stack Group Sparse Auto-encoder |
| F | Female |
| F0 | Fundamental frequency |
| FL | Federated Learning |
| fMRI | Functional Magnetic Resonance Imaging |
| GMM | Gaussian Mixture Models |
| Grad-CAM | Grad-class activation maps |
| GTCCs | Gammatone Cepstral Coefficients |
| HC | Healthy controls |
| HMM | Hidden Markov model |
| H&Y | Hoehn and Yahr scale |
| IFM | Interpretable feature-based models |
| IMAG | Subjects describing images in their native language |
| IMC | Iterative Clustering Algorithm |
| KNN | K-Nearest Neighbours |
| LDA | Linear Discriminant Analysis |
| L-MAC | Listenable Maps for Audio Classifiers |
| LSTM | Long Short-Term Memory networks |
| LSVT | Lee Silverman Voice Treatment |
| M | Male |
| MASS-PCNN | Multiple-Agent Salp Swarm Parkinson Classification Neural Network |
| MFCCs | Mel-frequency cepstral coefficients |
| MFT | Multiple Fine-Tuning |
| ML | Machine learning |
| NA | Not available |
| NIFM | Non-interpretable feature-based models |
| NLP | Natural Language Processing |
| PCA | Principal Component Analysis |
| PD | Parkinson’s Disease |
| PHON | Sustained phonemes |
| PLDA | Probabilistic Linear Discriminant Analysis |
| PRISMA | Preferred Reporting Items for Systematic Reviews and Meta-Analysis |
| PSP | Progressive supranuclear palsy |
| PWP | People with Parkinson |
| RNN | Recurrent Neural Network |
| ROC | Receiver Operating Characteristic |
| RQ | Research question |
| SE module | Squeeze and Excitation module |
| SHAP | SHapley Additive exPlanations |
| SPECT | Single-Photon Emission Computed Tomography |
| SPON | Spontaneous speech |
| SSA | Singular Spectrum Analysis |
| SVM | Support Vector Machine |
| TL | Transfer Learning |
| UPDRS | Unified Parkinson’s Disease Rating Scale |
| ViT | Vision Transformer |
| XAI | Explainable Artificial Intelligence |
Appendix A

{kind=link}
{kind=link}
| Dataset (Year) ↑ | Source & References | # Speakers | Transcripts | Disease Severity | Language | Overall Speech Time | DataQuality | Speech Task(s) |
|---|---|---|---|---|---|---|---|---|
| Saarbruecken Voice Database (2006) | [58,83] & [5] | Total: 1002 912 PWP (F: 548, M: 454). Age: 6–94. 851 HC (F: 428, M: 423). Age: 9–84. | NA | Yes | Native German | ±300 min. | Microphone recordings at 50 kHz with 16-bit resolution | 1. Vowels (i, a, u) at normal, high, and low pitch. 2. Vowels (i, a, u) with rising, falling pitch. 3. ”Sentence Guten Morgen, wie geht es Ihnen?” |
| PC-GITA (2014) | [36] * & [5,21,22,25,30,32,40,44,52,57,65,66] | Total: 100 50 PWP (F: 25, M: 25). Age: 33–77. 50 HC (F: 25, M: 25). Age: 44–75. | NA | 5 to 92 on UPDRS and severity less than 4 on H&Y scale (except 2 patients) | Native Colombian Spanish | ±900 min. | Microphone recordings at 44.1 kHz with 16-bit resolution | 1. Phonation of sustained vowels. 2. Phonation of vowels with changing tone from low to high for each vowel. 3. Rapid repetition of words and phonemes (DDK). 4. Repetition of sets of words. 5. Repetition of sentences. 6. Reading of dialog. 7. Reading of sentences with emphasis on particular words. |
| Parkinson Speech Dataset with Multiple Types of Sound Recordings (2014) | [72,84] & NA | Total: 68 (40-training and 28-testing)
20 PWP (F: 6, M: 14). Age: 43–79. 20 HC (F: 10, M: 10). Age: 45–83. | NA | Yes | Native Turkish | NA | Microphone recordings at 44.1 kHz with 32-bits resolution | Training: 1. Sustained vowels (/a/, /o/, /u/). 2. Numbers (1 to 10). 3. Words. 4. Short sentences. Test: 1. Sustained vowels (a, o). |
| Italian Parkinson’s Voice and Speech (2017) | [61,85] & [51,57] | Total: 65 28 PWP (F: 9, M: 19). Age: 40–80. 37 HC (F: 14, M: 23). Age: 19–29 (15 speakers) and 60–77 (22 speakers). | Prompts available | Severity less than 4 on H&Y scale (except 2 patients) | Native Italian | ±116 min. | Microphone recordings at 16 and 44.1 kHz with 32-bit resolution | 1. Reading of phonetically balanced text. 2. Syllables /pa/ and /ta/. 3. Phonation of the vowels /a/, /e/, /i/, /o/, and /u/. 4. Reading of phonetically balanced words. 5. Reading of phonetically balanced sentences. |
| Parkinson’s Disease Classification (2018) | [45,86] & [40,68] | Total: 252
188 PWP (F: 81, M: 107). Age: 33–87. 64 HC (F: 41, M: 23). Age: 41–82. | NA | NA | Turkish | NA | Microphone recordings at 44.1 kHz with 32-bit resolution | Sustained vowel /a/. |
| Synthetic Vowels of Speakers with Parkinson’s Disease and Parkinsonism (2019) | [46,87] & [26] | Total: 83 22 PWP (F: 12, M: 10). 21 MSA(F: 12, M: 9). 18 PSP (F: 6, M: 12). 22 HC (F: 11, M: 11). | Prompts available | Yes | Native Czech | ±385 min. | Microphone recordings at 48 kHz with 32-bit resolution | Sustained vowels /a/ and /i/. |
| Screening Parkinson’s Diseases Using Sustained Phonemes (2020) | [88,89] & NA | Total: 81 (Gender information: NA). | NA | NA | Native Turkish | ±189 min. | Microphone recordings at 48 kHz with 32-bit resolution | Sustained phonemes /a/, /o/, and /m/. |
| NeuroVoz (2024) | [67,90] & [13] | Total: 108 53 PWP (F: 20, M: 33) -Avg. age: 71.13. 55 HC (F: 26, M: 28, NA: 1)-Avg. age: 64.04. | Both manual and automatic transcriptions | 40 to 60 on UPDRS scale and 2 to 3 on H&Y scale | Native Castillian Spanish | ±106 min. | Microphone recordings at 44.1 kHz with 32-bit resolution | 1. 3 s of sustained vowels. 2. 10 s of DDK. 3. 16 listen-and-repeat utterances. 4. 30 s of free monologues. |
Appendix B
| Cite | Year ↑ | Dataset | Approach | Model (s) | Performance |
|---|---|---|---|---|---|
| [48] | 2020 | Data collected at NIMHANS * | E2E, TL | 1D-CNN and BLSTM | Accuracy of 90.98% |
| [66] | 2020 | PC-GITA [36] | DAFE | Stacked auto-encoder and softmax classifier | Accuracy of 87% (time-frequency deep features from spectograms) |
| [47] | 2020 | Data collected from 60 ALS, 60 PD, and 60 HC subjects at NIMHANS * | E2E | CNN-LSTM | Highest accuracy of 88.5% for spontaneous speech |
| [42] | 2020 | Chinese dataset containing 31 PWP and 30 HC * | E2E | CNN | Best accuracy of 91% |
| [32] | 2021 | PC-GITA [36] | E2E | ResNet-101-LSTM | Highest accuracy of 98.61% |
| [44] | 2021 | PC-GITA [36] | E2E | CNN-based auto-encoder using speaker identity invariant representations and adversarial training | Best accuracy of 75.4% |
| [9] | 2021 | 221 French subjects (121 PD and 100 HC) recruited at Pité-Salpêtrière Hospital * | DAFE | X-vectors extracted from a DNN. To classify into PD and HC, for each subject these x-vectors are compared to the average x-vector for PD and HC, respectively. | X-vectors lead to higher performance than MFCCs, especially for women showing 7-15% point improvement |
| [24] | 2021 | mPower * | TL | SqueezeNet1_1, ResNet50, and DenseNet161 | Best accuracy of 89.75% with DenseNet161 |
| [35] | 2021 | Five different databases containing a varying number of subjects * | E2E | SVM and LSTM | LSTM consistently outperforms SVM, reaching F-scores around 98% for three of the databases |
| [70] | 2021 | Voice calls from 110 English, 185 Greek, and 140 German subjects using the iPrognosis aplication * | DAFE | Single-instance (SVM, Logistic Regression, RF) and MIL classifiers (NSK, STK, sMIL, mi- SVM) | 84%, 93% and 83% AUC for English, Greek and German subjects, respectively |
| [68] | 2021 | LSVT Voice Rehabilitation Dataset [69] * and Parkinson’s Disease Classification dataset [45] | DAFE | Auto-encoder (EGSAE) combined with deep dual-side learning | Accuracies between 98.4% and 99.6% |
| [39] | 2021 | Telemonitoring (40 subjects) and multi- variate sound record dataset (40 subjects) * | E2E | ADNN, ADRNN, ARNN, and ACNN | CNN architecture outperforms regular DNN and RNN (99.92% versus 98.96% and 99.88%, respectively) |
| [30] | 2021 | PC-GITA [36] | E2E | Combination of CNN and MLP | Accuracy of 68.56% |
| [25] | 2021 | PC-GITA [36], PD-Czech, HD-Czech and Kay- elementrics dataset * | TL | CNN | Without TL, highest accuracy of 71.0% for Spanish. With TL, highest accuracy of 77.3% with Spanish as base language |
| [50] | 2022 | Data collected at University Hospital of the Jagiellonian University * | E2E | Pre-trained Wav2Vec2.0 conv layer and GRU layer | Accuracy of 97.92% |
| [5] | 2022 | PC-GITA [36], Saarbruecken Voice Database [58], and Vowels [59] * | E2E, TL | Ensemble of CNNs, using multiple-fine-tuning | 99% accuracy, 86.2% sensitivity, 93.3% specificity, and 89.6% AUC |
| [3] | 2022 | PC-GITA [36] | E2E | Xception | 92.33% accuracy on /a/ vowel and 82.12% accuracy on words |
| [21] | 2022 | Data collected at GYENNO SCIENCE Parkinson’s Disease Research Center (30 PD and 15 HC) *, and PC-GITA [36] | E2E | 2D-CNN followed by 1D-CNN | 2D-CNN followed by 1D-CNN Accuracy of 81.6% and 75.3% on sustained vowels and short sentences in Chinese Accuracy of 92% on PC-GITA |
| [22] | 2022 | PC-GITA [36] (independent test set containing native Colombian Spanish speakers, 20 PD and 20 HC) * | E2E | 1D-CNN followed by LSTM | Accuracy of 77.5% and an F1-score of 75.3% for fusion of speech tasks (vowels, read text, and monologue) |
| [65] | 2023 | PC-GITA [36], 176 German (88 PD and 88 HC) and 100 Czech subjects (50 PD and 50 HC) * | TL | 4 fully connected layers (1024, 256, 64, and 2) using Wav2Vec2.0 embeddings | Accuracy of 83.2%, 78.9%, and 77.8% for Spanish, German, and Czech, respectively |
| [40] | 2023 | PC-GITA [36] and Parkinson’s Disease Classification dataset [45] | E2E | CNN and LSTM | Highest accuracy (100%) reached for CNN on both datasets. |
| [14] | 2023 | 165 Colombian Spanish native speakers, from which 90 PWP * | E2E | 1D-CNN, 2D-CNN, and Wav2Vec2.0 | Best accuracy of 88% with Wav2Vec2.0 |
| [41] | 2023 | 3 datasets containing 16 PWP and 11 HC * | E2E | CNN | CNN Accuracy of 96% on speech energy, 93% on speech, and 92% on Mel spectrograms |
| [13] | 2023 | NeuroLogical Signals (NLS) *, Neurovoz [67], GITA *, GermanPD *, ItalianPVS *, and CzechPD * | DAFE | IFMs using prosodic, linguistic, and cognitive features. SVM, KNN, RF and XGBoost, and BG as classifiers. NIFMs using x- vectors extracted from TRILLsson, Wav2Vec2.0, and HuBERT. PLDA and PCA as classifiers | NIFMs outperform IFMs with 4%, 7% and 5.8% in mono-lingual, multi-lingual and cross-lingual settings, respectively |
| [12] | 2023 | English dataset (MDVR-KCL) * and private Telugu dataset combined with Telugu split of Open SLR * | DAFE | Wav2Vec2.0, VGGish, and Soundnet for extracting deep acoustic features | 90% accuracy for both English and Telegu |
| [52] | 2023 | PC-GITA [36], Hungarian speech database, and Polish vowel database * | E2E | ResNet18, ResNet50, ResNext50, EfficientNet-B1, EfficientNet-B2, Swin Transformer, and Vision Transformer | F1-score of 78% for Vision Transformer. All other architectures reach F1-score ranging from 64 to 72% |
| [57] | 2023 | CzechPD *, PC-GITA [36], Italian Parkinson’s Voice and Speech Database [85], and RMIT-PD * | E2E, TL | CNN and shallow XGBoost | Accuracies between 90.52% and 97.81% when training and testing on one language Accuracies between 43.07% and 72.04% when training and testing on different languages |
| [91] | 2023 | UCI Machine Learning Datasets Repository * | E2E | Acoustic DNN | R-squared of 86% |
| [53] | 2023 | UCI Machine Learning Datasets Repository * | E2E | Vocal Tab Transformer | AUC of 91.7% |
| [43] | 2023 | MVDR-KCL * | E2E | CNN-based auto-encoder | Accuracy of 61.49% |
| [26] | 2024 | Synthetic vowels of speakers with Parkinson’s disease and Parkinsonism [87] | E2E, TL | ViT-L-32, ViT-B-16, MobileNetV2, DenseNet201, DenseNet169, DenseNet121, ResNet152, ResNet50, GoogLeNet, VGG19, and VGG16. | Best accuracy of 98.30% with ResNet152 |
| [23] | 2024 | UCI Machine Learning Repository * | E2E | MASS-PCNN | 99.1% accuracy, 97.8% precision, 94.7% recall, and 99.5% F1-score |
| [51] | 2024 | Italian Parkinson’s Voice and Speech Database [85] | E2E | VGG16, ResNet50, and Swin Transformer | Swin Transformer slightly outperformed VGG16 (98.5% vs. 98.1%) |
Appendix C
| Resources | Cite | Year ↑ |
|---|---|---|
| https://github.com/zhang946/Deep-Dual-Side-Learning-Ensemble-Model-for-Parkinson-Speech-Recognition (accessed on 20 July 2024) | [42] | 2020 |
| https://github.com/idiap/pddetection-reps-learning (accessed on 20 July 2024) | [44] | 2021 |
| https://github.com/jcvasquezc/DisVoice (accessed on 20 July 2024) | [25] | 2021 |
| Code available upon request. | [50] | 2022 |
| https://github.com/Neuro-Logical/speech/tree/main/Cross_Lingual_Evaluation (accessed on 20 July 2024) | [13] | 2023 |
| https://github.com/vincenzo-scotti/voice_analysis_parkinson (accessed on 20 July 2024) | [12] | 2023 |
| Code available upon request. | [51] | 2024 |
References
- Ngo, Q.C.; Motin, M.A.; Pah, N.D.; Drotár, P.; Kempster, P.; Kumar, D. Computerized analysis of speech and voice for Parkinson’s disease: A systematic review. Comput. Methods Programs Biomed. 2022, 226, 107133. [Google Scholar] [CrossRef] [PubMed]
- Toye, A.A.; Kompalli, S. Comparative Study of Speech Analysis Methods to Predict Parkinson’s Disease. arXiv 2021, arXiv:2111.10207. [Google Scholar]
- Hireš, M.; Gazda, M.; Vavrek, L.; Drotár, P. Voice-Specific Augmentations for Parkinson’s Disease Detection Using Deep Convolutional Neural Network. In Proceedings of the 2022 IEEE 20th Jubilee World Symposium on Applied Machine Intelligence and Informatics (SAMI), Poprad, Slovakia, 2–5 March 2022; pp. 000213–000218. [Google Scholar] [CrossRef]
- Moro-Velazquez, L.; Gomez-Garcia, J.A.; Godino-Llorente, J.I.; Villalba, J.; Rusz, J.; Shattuck-Hufnagel, S.; Dehak, N. A forced gaussians based methodology for the differential evaluation of Parkinson’s Disease by means of speech processing. Biomed. Signal Process. Control 2019, 48, 205–220. [Google Scholar] [CrossRef]
- Hireš, M.; Gazda, M.; Drotár, P.; Pah, N.D.; Motin, M.A.; Kumar, D.K. Convolutional Neural Network Ensemble for Parkinson’s Disease Detection from Voice Recordings. Comput. Biol. Med. 2022, 141, 105021. [Google Scholar] [CrossRef]
- Muñoz-Vigueras, N.; Prados-Román, E.; Valenza, M.C.; Granados-Santiago, M.; Cabrera-Martos, I.; Rodríguez-Torres, J.; Torres-Sánchez, I. Speech and Language Therapy Treatment on Hypokinetic Dysarthria in Parkinson Disease: Systematic Review and Meta-Analysis. Clin. Rehabil. 2021, 35, 639–655. [Google Scholar] [CrossRef]
- Moro-Velazquez, L.; Cho, J.; Watanabe, S.; Hasegawa-Johnson, M.A.; Scharenborg, O.; Kim, H.; Dehak, N. Study of the Performance of Automatic Speech Recognition Systems in Speakers with Parkinson’s Disease. Proc. Interspeech 2019, 2019, 3875–3879. [Google Scholar] [CrossRef]
- Junaid, M.; Ali, S.; Eid, F.; El-Sappagh, S.; Abuhmed, T. Explainable Machine Learning Models Based on Multimodal Time-Series Data for the Early Detection of Parkinson’s Disease. Comput. Methods Programs Biomed. 2023, 234, 107495. [Google Scholar] [CrossRef]
- Jeancolas, L.; Petrovska-Delacrétaz, D.; Mangone, G.; Benkelfat, B.E.; Corvol, J.C.; Vidailhet, M.; Benali, H. X-Vectors: New Quantitative Biomarkers for Early Parkinson’s Disease Detection from Speech. Front. Neuroinform. 2021, 15, 578369. [Google Scholar] [CrossRef]
- Saravanan, S.; Ramkumar, K.; Adalarasu, K.; Sivanandam, V.; Kumar, S.R.; Stalin, S.; Amirtharajan, R. A Systematic Review of Artificial Intelligence (AI) Based Approaches for the Diagnosis of Parkinson’s Disease. Arch. Comput. Methods Eng. 2022, 29, 3639–3653. [Google Scholar] [CrossRef]
- Khojasteh, P.; Viswanathan, R.; Aliahmad, B.; Ragnav, S.; Zham, P.; Kumar, D.K. Parkinson’s Disease Diagnosis Based on Multivariate Deep Features of Speech Signal. In Proceedings of the 2018 IEEE Life Sciences Conference (LSC), Montreal, QC, Canada, 28–30 October 2018; pp. 187–190. [Google Scholar] [CrossRef]
- Ferrante, C.; Scotti, V. Cross-Lingual Transferability of Voice Analysis Models: A Parkinson’s Disease Case Study. In Booklet of Abstracts–Spoken Language in the Medical Field: Linguistic Analysis, Technological Applications and Clinical Tools; Politecnico di Milano University: Milan, Italy, 2023; pp. 40–42. [Google Scholar]
- Favaro, A.; Tsai, Y.T.; Butala, A.; Thebaud, T.; Villalba, J.; Dehak, N.; Moro-Velázquez, L. Interpretable Speech Features vs. DNN Embeddings: What to Use in the Automatic Assessment of Parkinson’s Disease in Multi-Lingual Scenarios. Comput. Biol. Med. 2023, 166, 107559. [Google Scholar] [CrossRef]
- Escobar-Grisales, D.; Ríos-Urrego, C.D.; Orozco-Arroyave, J.R. Deep Learning and Artificial Intelligence Applied to Model Speech and Language in Parkinson’s Disease. Diagnostics 2023, 13, 2163. [Google Scholar] [CrossRef] [PubMed]
- Prabhavalkar, R.; Hori, T.; Sainath, T.N.; Schlüter, R.; Watanabe, S. End-to-End Speech Recognition: A Survey. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 325–351. [Google Scholar] [CrossRef]
- Taye, M.M. Understanding of Machine Learning with Deep Learning: Architectures, Workflow, Applications and Future Directions. Computers 2023, 12, 91. [Google Scholar] [CrossRef]
- Silcox, C.; Zimlichmann, E.; Huber, K.; Rowen, N.; Saunders, R.; McClellan, M.; Kahn, C.N., III; Salzberg, C.A.; Bates, D.W. The potential for artificial intelligence to transform healthcare: Perspectives from international health leaders. NPJ Digit. Med. 2024, 7, 88. [Google Scholar] [CrossRef]
- Rossin, G.; Zorzi, F.; Ongaro, L.; Piasentin, A.; Vedovo, F.; Liguori, G.; Zucchi, A.; Simonato, A.; Bartoletti, R.; Trombetta, C.; et al. Artificial Intelligence in Bladder Cancer Diagnosis: Current Applications and Future Perspectives. BioMedInformatics 2023, 3, 104–114. [Google Scholar] [CrossRef]
- Jiménez-Luna, J.; Grisoni, F.; Weskamp, N.; Schneider, G. Artificial intelligence in drug discovery: Recent advances and future perspectives. Expert Opin. Drug Discov. 2021, 16, 949–959. [Google Scholar] [CrossRef] [PubMed]
- Porumb, M.; Stranges, S.; Pescapè, A.; Pecchia, L. Precision medicine and artificial intelligence: A pilot study on deep learning for hypoglycemic events detection based on ECG. Sci. Rep. 2020, 10, 170. [Google Scholar] [CrossRef]
- Quan, C.; Ren, K.; Luo, Z.; Chen, Z.; Ling, Y. End-to-end deep learning approach for Parkinson’s disease detection from speech signals. Biocybern. Biomed. Eng. 2022, 42, 556–574. [Google Scholar] [CrossRef]
- Rios-Urrego, C.D.; Moreno-Acevedo, S.A.; Nöth, E.; Orozco-Arroyave, J.R. End-to-end Parkinson’s disease detection using a deep convolutional recurrent network. In International Conference on Text, Speech, and Dialogue; Springer International Publishing: Cham, Switzerland, 2022; pp. 326–338. [Google Scholar] [CrossRef]
- Akila, B.; Nayahi, J. Parkinson Classification Neural Network with Mass Algorithm for Processing Speech Signals. Neural Comput. Appl. 2024, 36, 10165–10181. [Google Scholar] [CrossRef]
- Karaman, O.; Çakın, H.; Alhudhaif, A.; Polat, K. Robust Automated Parkinson Disease Detection Based on Voice Signals with Transfer Learning. Expert Syst. Appl. 2021, 178, 115013. [Google Scholar] [CrossRef]
- Vasquez-Correa, J.C.; Rios-Urrego, C.D.; Arias-Vergara, T.; Schuster, M.; Rusz, J.; Nöth, E.; Orozco-Arroyave, J.R. Transfer Learning Helps to Improve the Accuracy to Classify Patients with Different Speech Disorders in Different Languages. Pattern Recognit. Lett. 2021, 150, 272–279. [Google Scholar] [CrossRef]
- Reddy, N.S.S.; Manoj, A.V.S.; Reddy, V.P.M.S.; Aadhithya, A.; Sowmya, V. Transfer Learning Approach for Differentiating Parkinson’s Syndromes Using Voice Recordings. In Advanced Computing; Garg, D., Rodrigues, J.J.P.C., Gupta, S.K., Cheng, X., Sarao, P., Patel, G.S., Eds.; Springer: Cham, Switzerland, 2024; pp. 213–226. [Google Scholar] [CrossRef]
- Feng, T.; Hebbar, R.; Mehlman, N.; Shi, X.; Kommineni, A.; Narayanan, S. A Review of Speech-centric Trustworthy Machine Learning: Privacy, Safety, and Fairness. APSIPA Trans. Signal Inf. Process. 2023, 12, e17. [Google Scholar] [CrossRef]
- Rahman, W.; Lee, S.; Islam, M.S.; Antony, V.N.; Ratnu, H.; Ali, M.R.; Hoque, E. Detecting Parkinson Disease Using a Web-Based Speech Task: Observational Study. J. Med Internet Res. 2021, 23, e26305. [Google Scholar] [CrossRef] [PubMed]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.T.G. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. PLoS Med. 2009, 6, e1000097. [Google Scholar] [CrossRef] [PubMed]
- Narendra, N.P.; Schuller, B.; Alku, P. The detection of Parkinson’s disease from speech using voice source information. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1925–1936. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NE, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Er, M.B.; Isik, E.; Isik, I. Parkinson’s Detection Based on Combined CNN and LSTM Using Enhanced Speech Signals with Variational Mode Decomposition. Biomed. Signal Process. Control 2021, 70, 103006. [Google Scholar] [CrossRef]
- Bhati, S.; Velazquez, L.M.; Villalba, J.; Dehak, N. LSTM Siamese Network for Parkinson’s Disease Detection from Speech. In Proceedings of the 2019 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Ottawa, ON, Canada, 11–14 November 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Khaskhoussy, R.; Ayed, Y.B. Detecting Parkinson’s Disease According to Gender Using Speech Signals. In Proceedings of the Knowledge Science, Engineering and Management: 14th International Conference, KSEM 2021, Tokyo, Japan, 14–16 August 2021; Proceedings, Part III. Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 414–425. [Google Scholar] [CrossRef]
- Orozco-Arroyave, J.R.; Arias-Londoño, J.D.; Vargas-Bonilla, J.F.; Gonzalez-Rátiva, M.C.; Nöth, E. New Spanish speech corpus database for the analysis of people suffering from Parkinson’s disease. In LREC; European Language Resources Association (ELRA): Paris, France, 2014; pp. 342–347. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Huang, J.; Ling, C.X. Using AUC and accuracy in evaluating learning algorithms. IEEE Trans. Knowl. Data Eng. 2005, 17, 299–310. [Google Scholar] [CrossRef]
- Nagasubramanian, G.; Sankayya, M. Multi-variate vocal data analysis for detection of Parkinson disease using deep learning. Neural Comput. Appl. 2021, 33, 4849–4864. [Google Scholar] [CrossRef]
- Boualoulou, N.; Drissi, T.B.; Nsiri, B. CNN and LSTM for the classification of parkinson’s disease based on the GTCC and MFCC. Appl. Comput. Sci. 2023, 19, 1–24. [Google Scholar] [CrossRef]
- Faragó, P.; Ștefănigă, S.A.; Cordoș, C.G.; Mihăilă, L.I.; Hintea, S.; Peștean, A.S.; Ileșan, R.R. CNN-Based Identification of Parkinson’s Disease from Continuous Speech in Noisy Environments. Bioengineering 2023, 10, 531. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Zhang, Y.; Cao, Y.; Li, L.; Hao, L. Diagnosing Parkinson’s disease with speech signal based on convolutional neural network. Int. J. Comput. Appl. Technol. 2020, 63, 348–353. [Google Scholar] [CrossRef]
- Sarlas, A.; Kalafatelis, A.; Alexandridis, G.; Kourtis, M.A.; Trakadas, P. Exploring Federated Learning for Speech-Based Parkinson’s Disease Detection. In Proceedings of the 18th International Conference on Availability, Reliability and Security, Benevento, Italy, 29 August–1 September 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Janbakhshi, P.; Kodrasi, I. Supervised Speech Representation Learning for Parkinson’s Disease Classification. In Proceedings of the Speech Communication; 14th ITG Conference, Online, 29 September–1 October 2021; pp. 1–5. [Google Scholar]
- Sakar, C.; Serbes, G.; Gunduz, A.; Nizam, H.; Sakar, B. Parkinson’s Disease Classification. UC Irvine Machine Learning Repository. 2018. [CrossRef]
- Hlavnička, J.; Čmejla, R.; Klempíř, J.; Růžička, E.; Rusz, J. Synthetic Vowels of Speakers with Parkinson’s Disease and Parkinsonism [Dataset]. Figshare, 2019. [Google Scholar] [CrossRef]
- Mallela, J.; Illa, A.; Suhas, B.N.; Udupa, S.; Belur, Y.; Atchayaram, N.; Ghosh, P.K. Voice Based Classification of Patients with Amyotrophic Lateral Sclerosis, Parkinson’s Disease and Healthy Controls with CNN-LSTM Using Transfer Learning. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6784–6788. [Google Scholar] [CrossRef]
- Gope, D.; Ghosh, P.K. Raw Speech Waveform Based Classification of Patients with ALS, Parkinson’s Disease and Healthy Controls Using CNN-BLSTM. Proc. Interspeech 2020, 2020, 4581–4585. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar] [CrossRef]
- Chronowski, M.; Klaczynski, M.; Dec-Cwiek, M.; Porebska, K. Parkinson’s disease diagnostics using AI and natural language knowledge transfer. arXiv 2022, arXiv:2204.12559. [Google Scholar] [CrossRef]
- Malekroodi, H.S.; Madusanka, N.; Lee, B.I.; Yi, M. Leveraging Deep Learning for Fine-Grained Categorization of Parkinson’s Disease Progression Levels Through Analysis of Vocal Acoustic Patterns. Bioengineering 2024, 11, 295. [Google Scholar] [CrossRef]
- Hemmerling, D.; Wodzinski, M.; Orozco-Arroyave, J.R.; Sztaho, D.; Daniol, M.; Jemiolo, P.; Wojcik-Pedziwiatr, M. Vision Transformer for Parkinson’s Disease Classification Using Multilingual Sustained Vowel Recordings. In Proceedings of the 2023 45th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Sydney, Australia, 24–27 July 2023; pp. 1–4. [Google Scholar] [CrossRef]
- Nijhawan, R.; Kumar, M.; Arya, S.; Mendirtta, N.; Kumar, S.; Towfek, S.K.; Abdelhamid, A.A. A Novel Artificial-Intelligence-Based Approach for Classification of Parkinson’s Disease Using Complex and Large Vocal Features. Biomimetics 2023, 8, 351. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Peng, X.; Xu, H.; Liu, J.; Wang, J.; He, C. Voice Disorder Classification Using Convolutional Neural Network Based on Deep Transfer Learning. Sci. Rep. 2023, 13, 7264. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Hireš, M.; Drotár, P.; Pah, N.D.; Ngo, Q.C.; Kumar, D.K. On the Inter-Dataset Generalization of Machine Learning Approaches to Parkinson’s Disease Detection from Voice. Int. J. Med Inform. 2023, 179, 105237. [Google Scholar] [CrossRef]
- Barry, W.J.; Putzer, M. Saarbruecken Voice Database. 2007. Available online: https://stimmdb.coli.uni-saarland.de/help_en.php4 (accessed on 13 July 2024).
- Venegas, D. Vowels Dataset. 2018. Available online: https://www.kaggle.com/datasets/darubiano57/dataset-of-vowels (accessed on 13 July 2024).
- Rusz, J.; Cmejla, R.; Tykalova, T.; Ruzickova, H.; Klempir, J.; Majerova, V.; Picmausova, J.; Roth, J.; Ruzicka, E. Imprecise vowel articulation as a potential early marker of Parkinson’s disease: Effect of speaking task. J. Acoust. Soc. Am. 2013, 134, 2171–2181. [Google Scholar] [CrossRef] [PubMed]
- Dimauro, G.; Di Nicola, V.; Bevilacqua, V.; Caivano, D.; Girardi, F. Assessment of Speech Intelligibility in Parkinson’s Disease Using a Speech-To-Text System. IEEE Access 2017, 5, 22199–22208. [Google Scholar] [CrossRef]
- Viswanathan, R.; Khojasteh, P.; Aliahmad, B.; Arjunan, S.P.; Ragnav, S.; Kempster, P.; Wong, K.; Nagao, J.; Kumar, D. Efficiency of voice features based on consonant for detection of Parkinson’s disease. In Proceedings of the 2018 IEEE Life Sciences Conference (LSC), Montreal, QC, Canada, 28–30 October 2018; pp. 49–52. [Google Scholar] [CrossRef]
- Vasquez-Correa, J.C.; Arias-Vergara, T.; Rios-Urrego, C.D.; Schuster, M.; Rusz, J.; Orozco-Arroyave, J.R.; Nöth, E. Convolutional Neural Networks and a Transfer Learning Strategy to Classify Parkinson’s Disease from Speech in Three Different Languages. In Proceedings of the Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications: 24th Iberoamerican Congress, CIARP 2019, Havana, Cuba, 28–31 October 2019; Proceedings 24. Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 697–706. [Google Scholar] [CrossRef]
- Orozco-Arroyave, J.R.; Hönig, F.; Arias-Londono, J.D.; Vargas-Bonilla, J.F.; Daqrouq, K.; Skodda, S.; Rusz, J.; Nöth, E. Automatic Detection of Parkinson’s Disease in Running Speech Spoken in Three Different Languages. J. Acoust. Soc. Am. 2016, 139, 481–500. [Google Scholar] [CrossRef]
- Arasteh, S.T.; Rios-Urrego, C.D.; Noeth, E.; Maier, A.; Yang, S.H.; Rusz, J.; Orozco-Arroyave, J.R. Federated Learning for Secure Development of AI Models for Parkinson’s Disease Detection Using Speech from Different Languages. arXiv 2023, arXiv:2305.11284. [Google Scholar]
- Karan, B.; Sahu, S.S.; Mahto, K. Stacked auto-encoder based Time-frequency features of Speech signal for Parkinson disease prediction. In Proceedings of the 2020 International Conference on Artificial Intelligence and Signal Processing (AISP), Amaravati, India, 10–12 January 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Mendes-Laureano, J.; Gómez-García, J.A.; Guerrero-López, A.; Luque-Buzo, E.; Arias-Londoño, J.D.; Grandas-Pérez, F.J.; Godino-Llorente, J.I. NeuroVoz: A Castillian Spanish corpus of parkinsonian speech [Dataset]. Zenodo 2024. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, Y.; Li, Y.; Zhou, L.; Qin, L.; Zeng, Y.; Lei, Y. Deep Dual-Side Learning Ensemble Model for Parkinson Speech Recognition. Biomed. Signal Process. Control 2021, 69, 102849. [Google Scholar] [CrossRef]
- Tsanas, A. LSVT Voice Rehabilitation [Dataset]. UCI Machine Learning Repository, 2014. [Google Scholar] [CrossRef]
- Laganas, C.; Iakovakis, D.; Hadjidimitriou, S.; Charisis, V.; Dias, S.B.; Bostantzopoulou, S.; Hadjileontiadis, L.J. Parkinson’s Disease Detection Based on Running Speech Data from Phone Calls. IEEE Trans. Biomed. Eng. 2021, 69, 1573–1584. [Google Scholar] [CrossRef] [PubMed]
- Bayestehtashk, A.; Asgari, M.; Shafran, I.; McNames, J. Fully automated assessment of the severity of Parkinson’s disease from speech. Comput. Speech Lang. 2015, 29, 172–185. [Google Scholar] [CrossRef]
- Sakar, B.E.; Isenkul, M.E.; Sakar, C.O.; Sertbas, A.; Gurgen, F.; Delil, S.; Apaydin, H.; Kursun, O. Collection and analysis of a Parkinson speech dataset with multiple types of sound recordings. IEEE J. Biomed. Health Inform. 2013, 17, 828–834. [Google Scholar] [CrossRef]
- Kim, J.; Nasir, M.; Gupta, R.; Van Segbroeck, M.; Bone, D.; Black, M.P.; Skordilis, Z.I.; Yang, Z.; Georgiou, P.G.; Narayanan, S.S. Automatic estimation of parkinson’s disease severity from diverse speech tasks. Proc. Interspeech 2020, 2020, 914–918. [Google Scholar] [CrossRef]
- Podcasy, J.L.; Epperson, C.N. Considering sex and gender in Alzheimer disease and other dementias. Dialogues Clin. Neurosci. 2016, 18, 437–446. [Google Scholar] [CrossRef] [PubMed]
- Miller, I.N.; Cronin-Golomb, A. Gender differences in Parkinson’s disease: Clinical characteristics and cognition. Mov. Disord. 2010, 25, 2695–2703. [Google Scholar] [CrossRef]
- Gillies, G.E.; Pienaar, I.S.; Vohra, S.; Qamhawi, Z. Sex differences in Parkinson’s disease. Front. Neuroendocrinol. 2014, 35, 370–384. [Google Scholar] [CrossRef] [PubMed]
- Leem, S.; Seo, H. Attention Guided CAM: Visual Explanations of Vision Transformer Guided by Self-Attention. Proc. AAAI Conf. Artif. Intell. 2024, 38, 2956–2964. [Google Scholar] [CrossRef]
- Abnar, S.; Zuidema, W. Quantifying attention flow in transformers. arXiv 2020, arXiv:2005.00928. [Google Scholar]
- Band, S.S.; Yarahmadi, A.; Hsu, C.C.; Biyari, M.; Sookhak, M.; Ameri, R.; Dehzangi, I.; Chronopoulos, A.T.; Liang, H.W. Application of explainable artificial intelligence in medical health: A systematic review of interpretability methods. Inform. Med. Unlocked 2023, 40, 101286. [Google Scholar] [CrossRef]
- Haar, L.V.; Elvira, T.; Ochoa, O. An analysis of explainability methods for convolutional neural networks. Eng. Appl. Artif. Intell. 2023, 117, 105606. [Google Scholar] [CrossRef]
- Paissan, F.; Ravanelli, M.; Subakan, C. Listenable Maps for Audio Classifiers. arXiv 2024, arXiv:2403.13086. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4768–4777. [Google Scholar] [CrossRef]
- Koreman, J.C. A German Database Of Patterns Of Pathological Vocal Fold Vibration. Engineering 1997, 3, 143–153. [Google Scholar]
- Kursun, O.; Sakar, B.; Isenkul, M.; Sakar, C.; Sertbas, A.; Gurgen, F. Parkinson’s Speech with Multiple Types of Sound Recordings [Dataset]. UCI Machine Learning Repository, 2014. [CrossRef]
- Dimauro, G.; Girardi, F. Italian Parkinson’s Voice and Speech [Dataset]. IEEE Dataport, 2019. [Google Scholar] [CrossRef]
- Sakar, C.O.; Serbes, G.; Gunduz, A.; Tunc, H.C.; Nizam, H.; Sakar, B.E.; Tutuncu, M.; Aydin, T.; Isenkul, M.E.; Apaydin, H. A comparative analysis of speech signal processing algorithms for Parkinson’s disease classification and the use of the tunable Q-factor wavelet transform. Appl. Soft Comput. 2019, 74, 255–263. [Google Scholar] [CrossRef]
- Hlavnička, J.; Čmejla, R.; Klempíř, J.; Růžička, E.; Rusz, J. Acoustic Tracking of Pitch, Modal, and Subharmonic Vibrations of Vocal Folds in Parkinson’s Disease and Parkinsonism. IEEE Access 2019, 7, 150339–150354. [Google Scholar] [CrossRef]
- Pah, N.D.; Motin, M.A.; Kempster, P.; Kumar, D.K. Detecting Effect of Levodopa in Parkinson’s Disease Patients Using Sustained Phonemes. IEEE J. Transl. Eng. Health Med. 2021, 9, 1–9. [Google Scholar] [CrossRef]
- Kumar, D.; Kempster, P.; Raghav, S.; Viswanthan, R.; Zham, P.; Arjunan, S. Screening Parkinson’s Diseases Using Sustained Phonemes; RMIT University: Melbourne VIC, Australia, 2020. [Google Scholar] [CrossRef]
- Mendes-Laureano, J.; Gómez-García, J.A.; Guerrero-López, A.; Luque-Buzo, E.; Arias-Londoño, J.D.; Grandas-Pérez, F.J.; Godino-Llorente, J.I. NeuroVoz: A Castillian Spanish corpus of Parkinsonian Speech. arXiv 2024, arXiv:2403.02371. [Google Scholar]
- Mahmood, A.; Mehroz Khan, M.; Imran, M.; Alhajlah, O.; Dhahri, H.; Karamat, T. End-to-end deep learning method for detection of invasive Parkinson’s disease. Diagnostics 2023, 13, 1088. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
van Gelderen, L.; Tejedor-García, C. Innovative Speech-Based Deep Learning Approaches for Parkinson’s Disease Classification: A Systematic Review. Appl. Sci. 2024, 14, 7873. https://doi.org/10.3390/app14177873
van Gelderen L, Tejedor-García C. Innovative Speech-Based Deep Learning Approaches for Parkinson’s Disease Classification: A Systematic Review. Applied Sciences. 2024; 14(17):7873. https://doi.org/10.3390/app14177873
Chicago/Turabian Stylevan Gelderen, Lisanne, and Cristian Tejedor-García. 2024. "Innovative Speech-Based Deep Learning Approaches for Parkinson’s Disease Classification: A Systematic Review" Applied Sciences 14, no. 17: 7873. https://doi.org/10.3390/app14177873
APA Stylevan Gelderen, L., & Tejedor-García, C. (2024). Innovative Speech-Based Deep Learning Approaches for Parkinson’s Disease Classification: A Systematic Review. Applied Sciences, 14(17), 7873. https://doi.org/10.3390/app14177873