
Open-Vocabulary Part-Level Detection and Segmentation for Human–Robot Interaction


Abstract
:1. Introduction
2. Related Works
2.1. Part Segmentation
2.2. Open-Vocabulary Segmentation
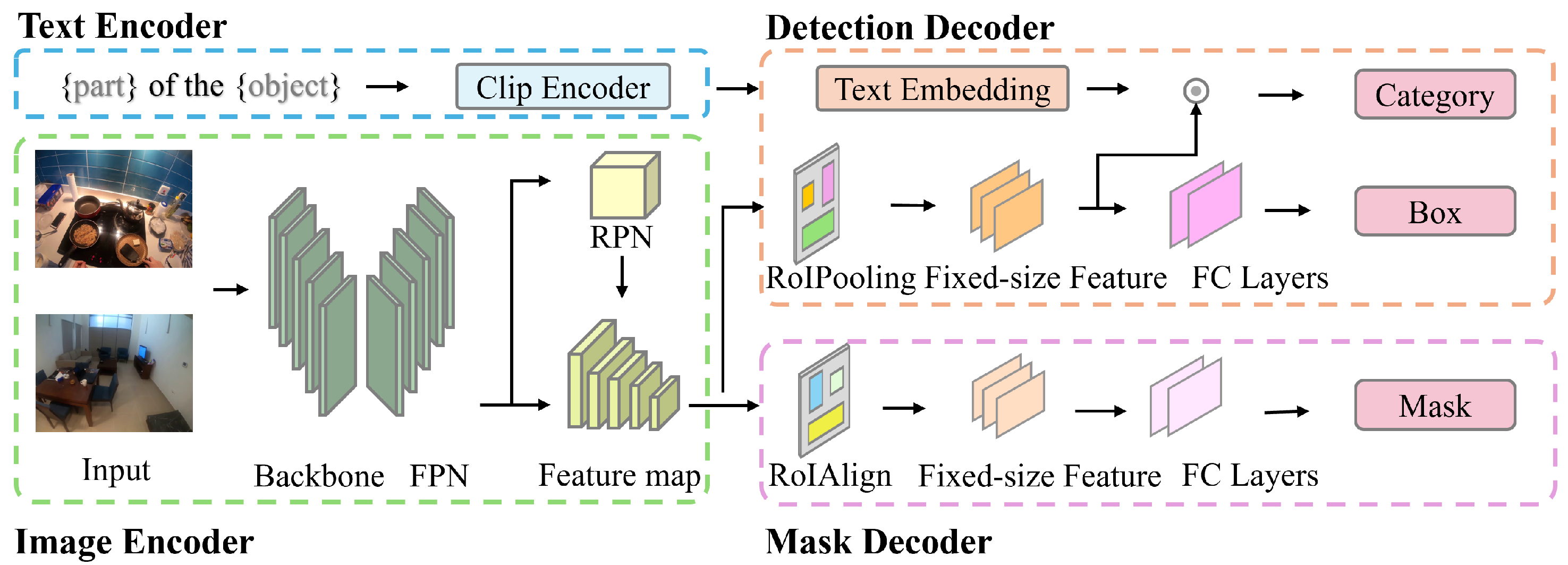
3. Methods
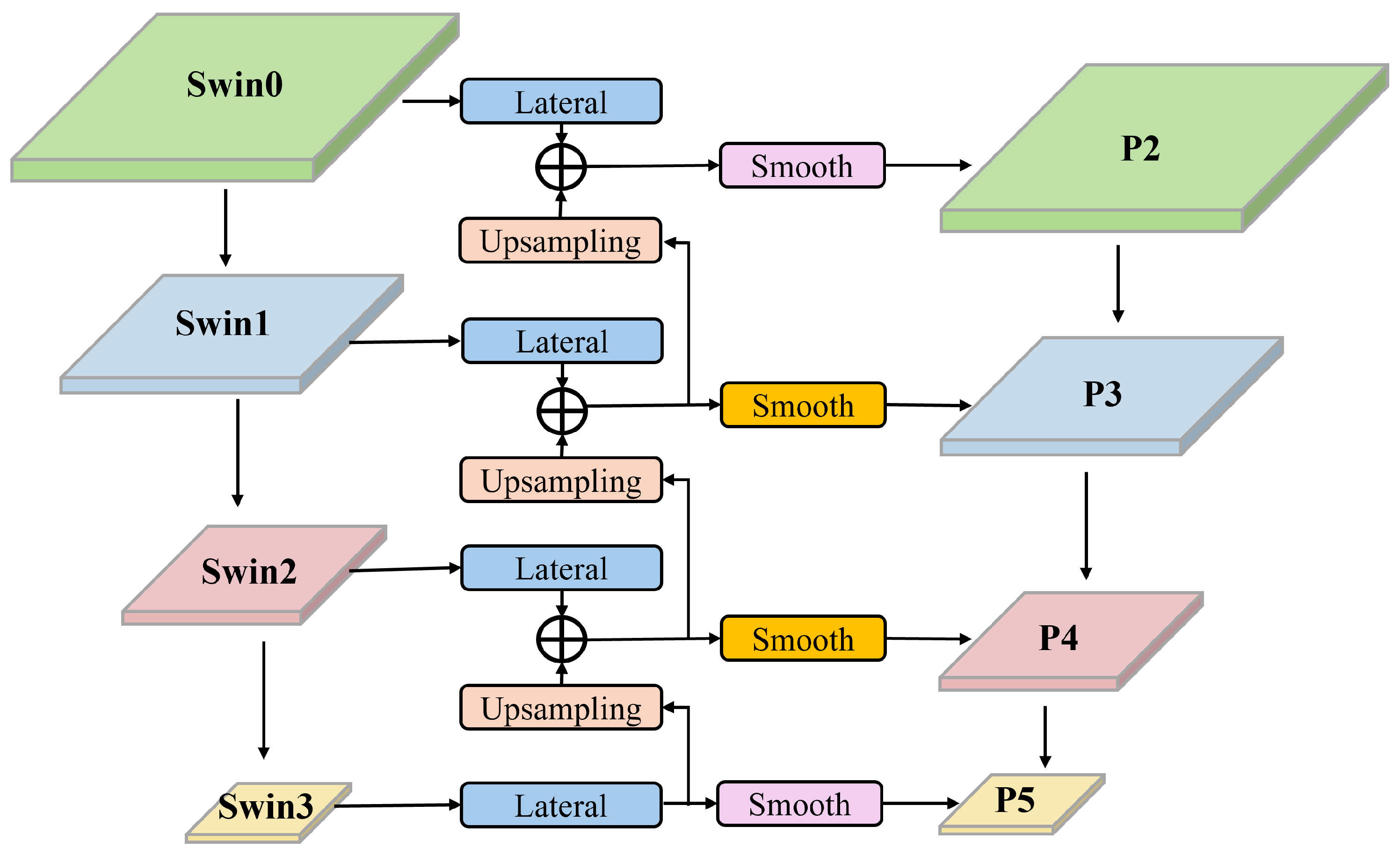
3.1. Image Encoder
3.2. Text Encoder
3.3. Detection Decoder
3.4. Mask Decoder
3.5. Loss Function
4. Results
4.1. Experimental Setup
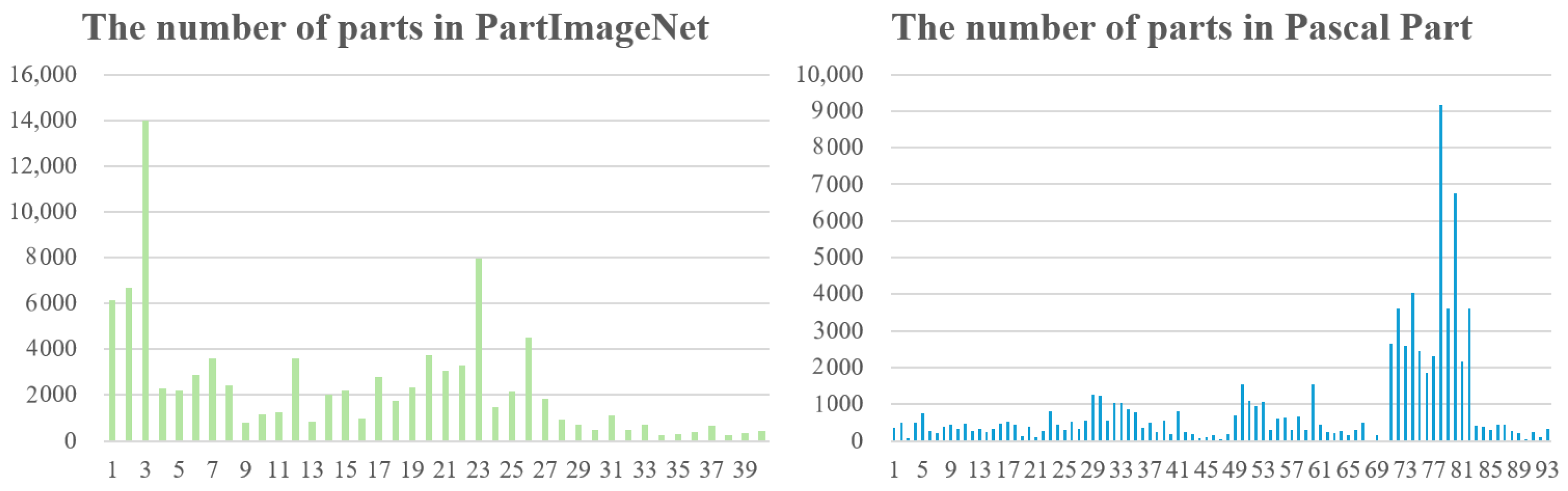
4.2. Datasets
4.3. Main Result
4.4. Comparison of Results
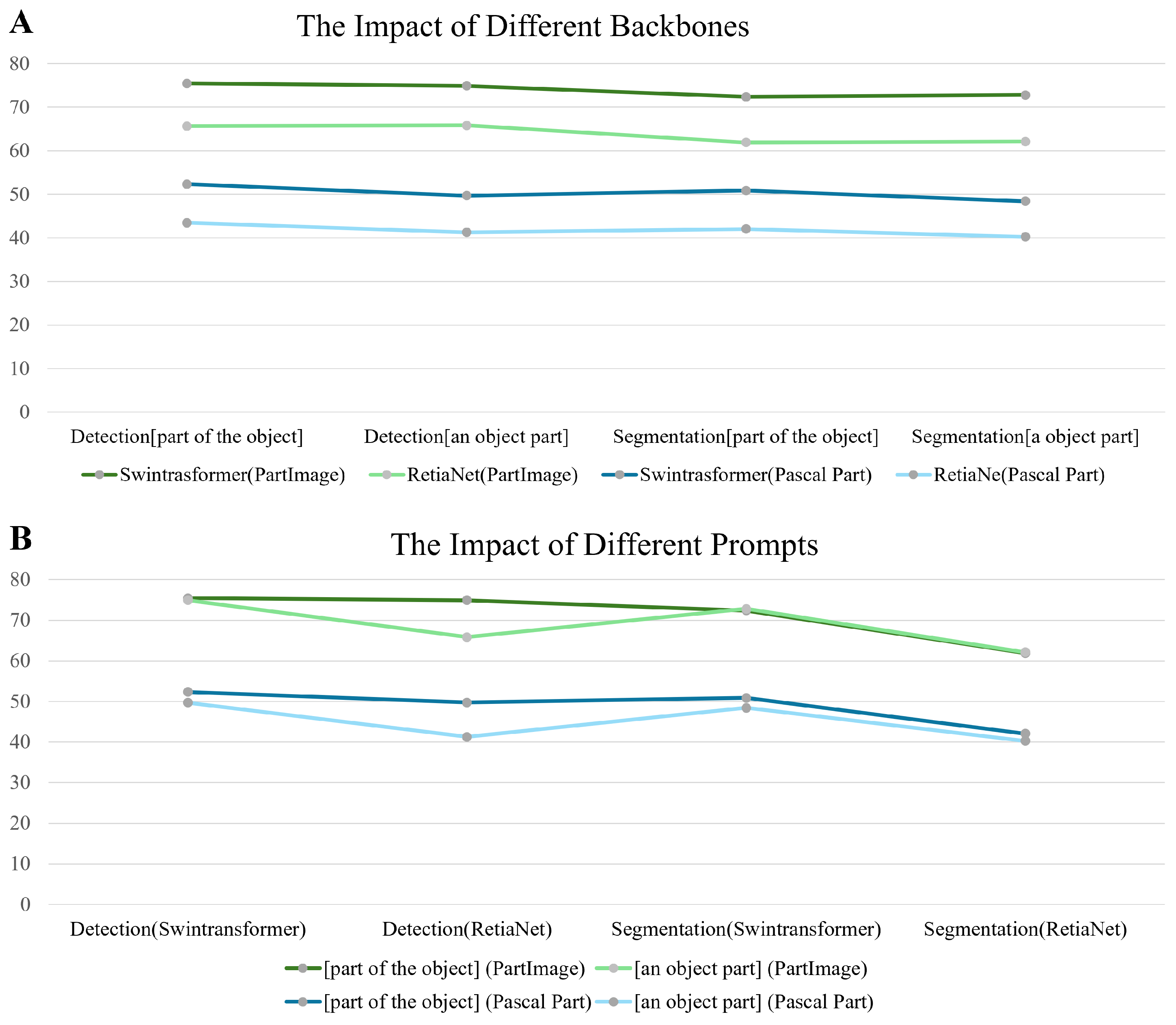
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Matheson, E.; Minto, R.; Zampieri, E.G.; Faccio, M.; Rosati, G. Human–robot collaboration in manufacturing applications: A review. Robotics 2019, 8, 100. [Google Scholar] [CrossRef]
- Mogadala, A.; Kalimuthu, M.; Klakow, D. Trends in integration of vision and language research: A survey of tasks, datasets, and methods. J. Artif. Intell. Res. 2021, 71, 1183–1317. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Learning to prompt for vision-language models. Int. J. Comput. Vis. 2022, 130, 2337–2348. [Google Scholar] [CrossRef]
- Pan, T.Y.; Liu, Q.; Chao, W.L.; Price, B. Towards open-world segmentation of parts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 15392–15401. [Google Scholar]
- Han, M.; Zheng, H.; Wang, C.; Luo, Y.; Hu, H.; Zhang, J.; Wen, Y. PartSeg: Few-shot Part Segmentation via Part-aware Prompt Learning. arXiv 2023, arXiv:2308.12757. [Google Scholar]
- Chen, X.; Mottaghi, R.; Liu, X.; Fidler, S.; Urtasun, R.; Yuille, A. Detect what you can: Detecting and representing objects using holistic models and body parts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1971–1978. [Google Scholar]
- He, J.; Yang, S.; Yang, S.; Kortylewski, A.; Yuan, X.; Chen, J.N.; Liu, S.; Yang, C.; Yu, Q.; Yuille, A. Partimagenet: A large, high-quality dataset of parts. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 128–145. [Google Scholar]
- de Geus, D.; Meletis, P.; Lu, C.; Wen, X.; Dubbelman, G. Part-aware panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5485–5494. [Google Scholar]
- Michieli, U.; Borsato, E.; Rossi, L.; Zanuttigh, P. Gmnet: Graph matching network for large scale part semantic segmentation in the wild. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VIII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 397–414. [Google Scholar]
- Zhou, T.; Wang, W.; Liu, S.; Yang, Y.; Van Gool, L. Differentiable multi-granularity human representation learning for instance-aware human semantic parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1622–1631. [Google Scholar]
- Li, X.; Xu, S.; Yang, Y.; Cheng, G.; Tong, Y.; Tao, D. Panoptic-partformer: Learning a unified model for panoptic part segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 729–747. [Google Scholar]
- Sun, P.; Chen, S.; Zhu, C.; Xiao, F.; Luo, P.; Xie, S.; Yan, Z. Going denser with open-vocabulary part segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 15453–15465. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Xiao, T.; Fidler, S.; Barriuso, A.; Torralba, A. Semantic understanding of scenes through the ade20k dataset. Int. J. Comput. Vis. 2019, 127, 302–321. [Google Scholar] [CrossRef]
- Li, J.; Zhao, J.; Wei, Y.; Lang, C.; Li, Y.; Sim, T.; Yan, S.; Feng, J. Multiple-human parsing in the wild. arXiv 2017, arXiv:1705.07206. [Google Scholar]
- Yang, L.; Song, Q.; Wang, Z.; Jiang, M. Parsing r-cnn for instance-level human analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 364–373. [Google Scholar]
- Reddy, N.D.; Vo, M.; Narasimhan, S.G. Carfusion: Combining point tracking and part detection for dynamic 3d reconstruction of vehicles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1906–1915. [Google Scholar]
- Song, X.; Wang, P.; Zhou, D.; Zhu, R.; Guan, C.; Dai, Y.; Su, H.; Li, H.; Yang, R. Apollocar3d: A large 3d car instance understanding benchmark for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5452–5462. [Google Scholar]
- Zheng, S.; Yang, F.; Kiapour, M.H.; Piramuthu, R. Modanet: A large-scale street fashion dataset with polygon annotations. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1670–1678. [Google Scholar]
- Jia, M.; Shi, M.; Sirotenko, M.; Cui, Y.; Cardie, C.; Hariharan, B.; Adam, H.; Belongie, S. Fashionpedia: Ontology, segmentation, and an attribute localization dataset. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 316–332. [Google Scholar]
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6904–6913. [Google Scholar]
- Gurari, D.; Li, Q.; Stangl, A.J.; Guo, A.; Lin, C.; Grauman, K.; Luo, J.; Bigham, J.P. Vizwiz grand challenge: Answering visual questions from blind people. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3608–3617. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Plummer, B.A.; Wang, L.; Cervantes, C.M.; Caicedo, J.C.; Hockenmaier, J.; Lazebnik, S. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 2641–2649. [Google Scholar]
- Xu, J.; Mei, T.; Yao, T.; Rui, Y. Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5288–5296. [Google Scholar]
- Girdhar, R.; Ramanan, D. Cater: A diagnostic dataset for compositional actions and temporal reasoning. arXiv 2019, arXiv:1910.04744. [Google Scholar]
- Suhr, A.; Lewis, M.; Yeh, J.; Artzi, Y. A corpus of natural language for visual reasoning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 217–223. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1290–1299. [Google Scholar]
- Liang, F.; Wu, B.; Dai, X.; Li, K.; Zhao, Y.; Zhang, H.; Zhang, P.; Vajda, P.; Marculescu, D. Open-vocabulary semantic segmentation with mask-adapted clip. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Paris, France, 2–6 October 2023; pp. 7061–7070. [Google Scholar]
- Yu, Q.; He, J.; Deng, X.; Shen, X.; Chen, L.C. Convolutions die hard: Open-vocabulary segmentation with single frozen convolutional clip. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; pp. 32215–32234. [Google Scholar]
- Xu, M.; Zhang, Z.; Wei, F.; Hu, H.; Bai, X. Side adapter network for open-vocabulary semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Paris, France, 2–6 October 2023; pp. 2945–2954. [Google Scholar]
- Li, X.; Yin, X.; Li, C.; Zhang, P.; Hu, X.; Zhang, L.; Wang, L.; Hu, H.; Dong, L.; Wei, F.; et al. Oscar: Object-semantics aligned pre-training for vision-language tasks. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXX 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 121–137. [Google Scholar]
- Chen, Y.C.; Li, L.; Yu, L.; El Kholy, A.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. Uniter: Universal image-text representation learning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 104–120. [Google Scholar]
- Li, J.; Selvaraju, R.; Gotmare, A.; Joty, S.; Xiong, C.; Hoi, S.C.H. Align before fuse: Vision and language representation learning with momentum distillation. Adv. Neural Inf. Process. Syst. 2021, 34, 9694–9705. [Google Scholar]
- Wu, C.; Yin, S.; Qi, W.; Wang, X.; Tang, Z.; Duan, N. Visual chatgpt: Talking, drawing and editing with visual foundation models. arXiv 2023, arXiv:2303.04671. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Cong, P.; Li, S.; Zhou, J.; Lv, K.; Feng, H. Research on instance segmentation algorithm of greenhouse sweet pepper detection based on improved mask RCNN. Agronomy 2023, 13, 196. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PartImageNet | [Part of the Object] | [An Object Part] | ||||
|---|---|---|---|---|---|---|
| AP | mAP | AP | mAP | |||
| Detection | 47.63 | 75.46 | 46.04 | 47.40 | 74.92 | 46.42 |
| Segmentation | 44.36 | 72.39 | 42.05 | 44.29 | 72.80 | 42.53 |
| Pascal Part | [Part of the Object] | [An Object Part] | ||||
| AP | mAP | AP | mAP | |||
| Detection | 25.27 | 52.35 | 35.34 | 23.01 | 49.71 | 32.62 |
| Segmentation | 24.04 | 50.86 | 35.05 | 22.53 | 48.41 | 32.85 |
| PartImageNet | [Part of the Object] | [An Object Part] | ||||
|---|---|---|---|---|---|---|
| AP | mAP | AP | mAP | |||
| Detection | 35.99 | 65.68 | 35.83 | 36.36 | 65.82 | 36.07 |
| Segmentation | 35.16 | 61.91 | 33.39 | 35.54 | 62.12 | 33.78 |
| Pascal Part | [Part of the Object] | [An Object Part] | ||||
| AP | mAP | AP | mAP | |||
| Detection | 18.62 | 43.46 | 25.98 | 17.44 | 41.28 | 24.36 |
| Segmentation | 18.96 | 42.06 | 27.43 | 18.09 | 40.26 | 26.64 |
| PartImageNet | AP | mAP | Pascal Part | AP | mAP | ||
|---|---|---|---|---|---|---|---|
| None | 47.29 | 75.28 | 46.39 | None | 22.22 | 48.35 | 31.73 |
| [part of the object] | 47.63 | 75.46 | 46.04 | [part of the object] | 25.27 | 52.35 | 35.34 |
| [an object part] | 47.40 | 74.92 | 46.42 | [an object part] | 23.01 | 49.71 | 32.62 |
| BiFPN | FPN with P6 | |||||
|---|---|---|---|---|---|---|
| Detection | AP | mAP | AP | mAP | ||
| PartImageNet | 41.27 | 66.31 | 38.90 | 46.09 | 73.92 | 44.76 |
| Pascal Part | 23.84 | 50.03 | 34.49 | 24.26 | 51.43 | 34.21 |
| Segmentation | AP | mAP | AP | mAP | ||
| PartImageNet | 38.81 | 64.26 | 35.90 | 43.15 | 71.40 | 41.12 |
| Pascal Part | 22.97 | 48.65 | 34.44 | 23.40 | 49.88 | 33.93 |
| Detection | AP | mAP | |
|---|---|---|---|
| PartImageNet | 39.07 | 62.81 | 38.16 |
| Pascal Part | 13.29 | 26.73 | 27.68 |
| Segmentation | AP | mAP | |
| PartImageNet | 37.03 | 60.46 | 34.90 |
| Pascal Part | 13.15 | 26.29 | 29.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Liu, X.; Wei, W. Open-Vocabulary Part-Level Detection and Segmentation for Human–Robot Interaction. Appl. Sci. 2024, 14, 6356. https://doi.org/10.3390/app14146356
Yang S, Liu X, Wei W. Open-Vocabulary Part-Level Detection and Segmentation for Human–Robot Interaction. Applied Sciences. 2024; 14(14):6356. https://doi.org/10.3390/app14146356
Chicago/Turabian StyleYang, Shan, Xiongding Liu, and Wu Wei. 2024. "Open-Vocabulary Part-Level Detection and Segmentation for Human–Robot Interaction" Applied Sciences 14, no. 14: 6356. https://doi.org/10.3390/app14146356
APA StyleYang, S., Liu, X., & Wei, W. (2024). Open-Vocabulary Part-Level Detection and Segmentation for Human–Robot Interaction. Applied Sciences, 14(14), 6356. https://doi.org/10.3390/app14146356