
A Novel Symmetric Fine-Coarse Neural Network for 3D Human Action Recognition Based on Point Cloud Sequences


Abstract
:1. Introduction
- We propose an interval-frequency descriptor to characterize the 3D voxels during action execution, which fully preserves the motion details and provides critical clues for key body parts’ perception. To the best of our knowledge, our work is the first to handle point cloud sequences in this way.
- We construct a deep learning framework named SFCNet, which first employs a symmetric structure to process point cloud sequences. It encodes the local crucial body parts’ dynamics via a fine stream and then supplements these intricate details to the global appearance captured by a coarse stream. The SFCNet can emphasize essential body parts and capture more discriminative motion patterns, addressing the effective action representation problem based on point clouds.
- The presented SFCNet has demonstrated its superior accuracy on two publicly available datasets, NTU RGB+D 60 and NTU RGB+D 120, which proves that our method has considerable potential in recognizing various types of actions such as daily actions, medical-related actions, and two-person interaction actions.
2. Related Works
2.1. Skeleton-Based 3D Action Recognition
2.2. Depth-Based 3D Action Recognition
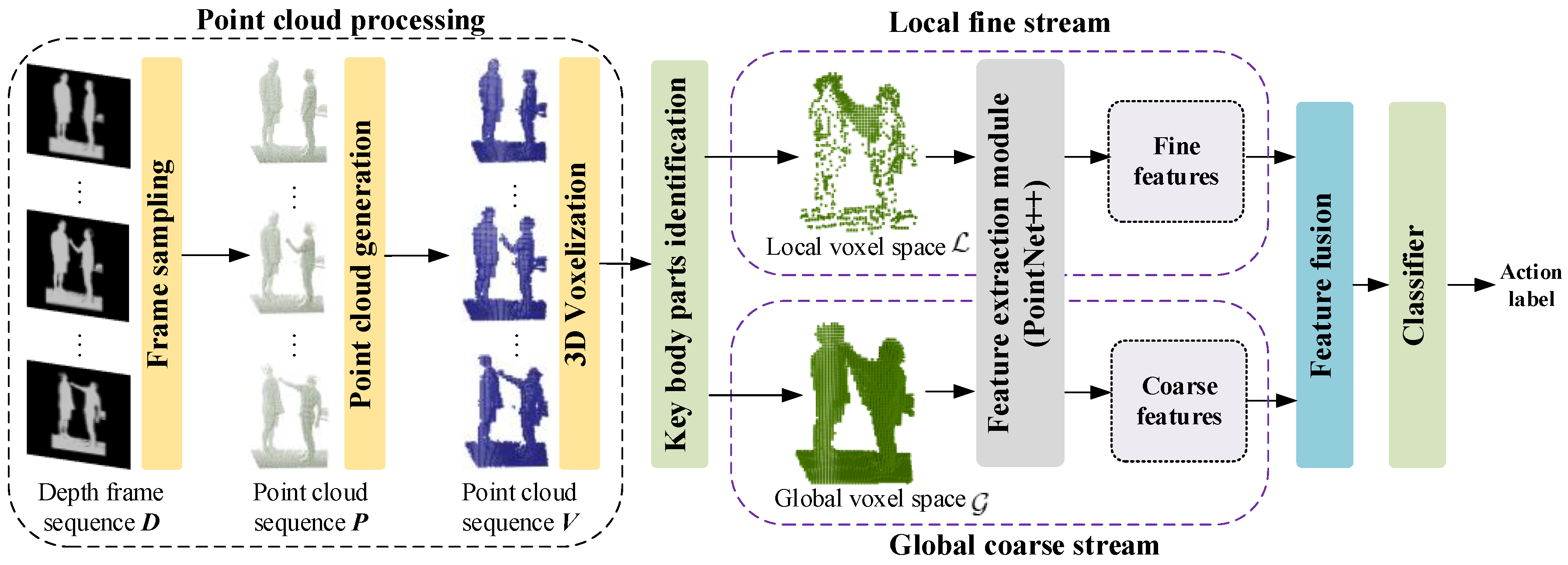
3. Methodology
3.1. Pipeline
3.2. Three-Dimensional Voxel Generation
3.3. Identification and Representation of Key Parts
3.4. Symmetric Feature Extraction
4. Experiments
4.1. Datasets
4.2. Training Details
4.3. Parameter Analysis
4.4. Ablation Study
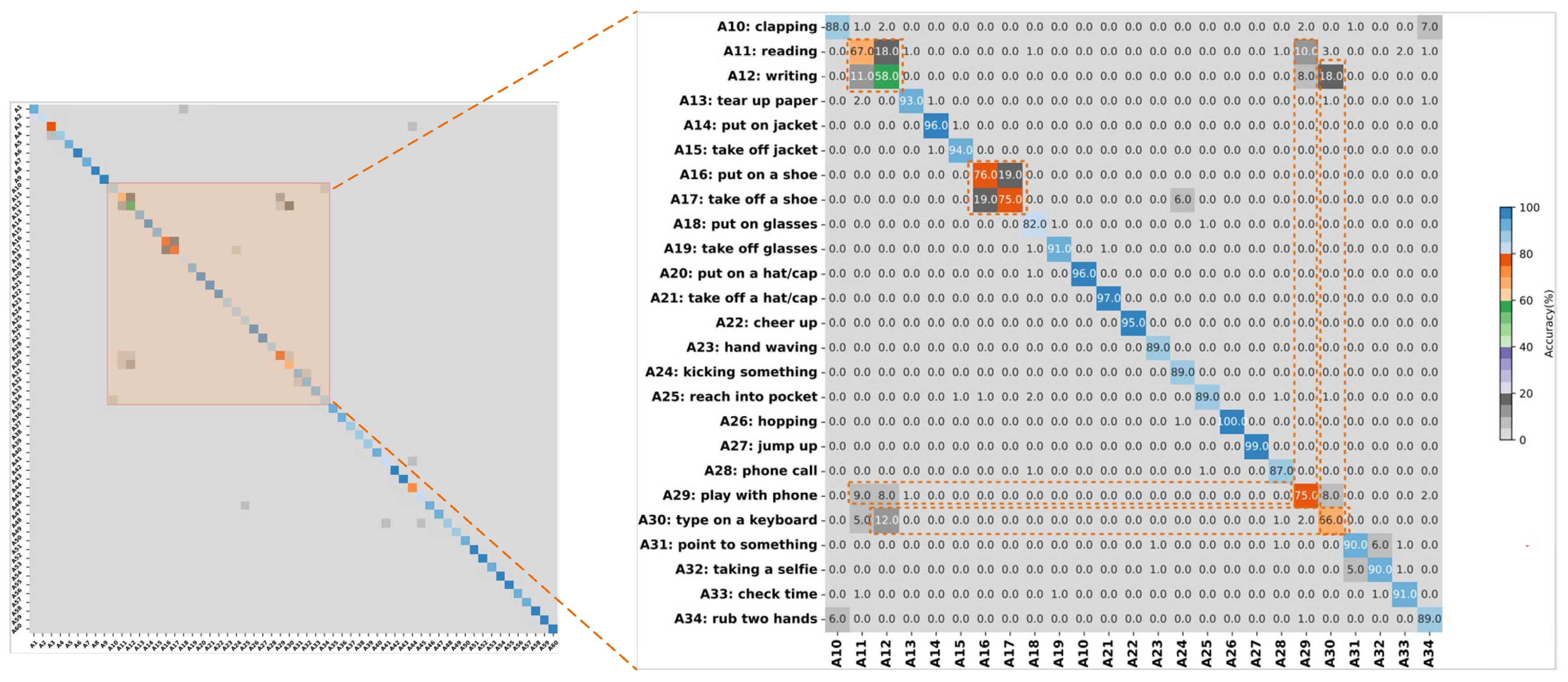
4.5. Comparison with Existing Methods
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Riaz, W.; Gao, C.; Azeem, A.; Saifullah; Bux, J.A.; Ullah, A. Traffic Anomaly Prediction System Using Predictive Network. Remote Sens. 2022, 14, 447. [Google Scholar] [CrossRef]
- Wang, P.; Li, W.; Gao, Z.; Tang, C.; Ogunbona, P.O. Depth pooling based large-scale 3-d action recognition with convolutional neural networks. IEEE Trans. Multimed. 2018, 20, 1051–1061. [Google Scholar] [CrossRef]
- Xiao, Y.; Chen, J.; Wang, Y.; Cao, Z.; Zhou, J.T.; Bai, X. Action recognition for depth video using multi-view dynamic images. Inf. Sci. 2019, 480, 287–304. [Google Scholar] [CrossRef]
- Li, C.; Huang, Q.; Li, X.; Wu, Q. Human action recognition based on multi-scale feature maps from depth video sequences. Multimed. Tools Appl. 2021, 80, 32111–32130. [Google Scholar] [CrossRef]
- Caetano, C.; Sena, J.; Brémond, F.; Dos Santos, J.A.; Schwartz, W.R. Skelemotion: A new representation of skeleton joint sequences based on motion information for 3d action recognition. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance, Taipei, Taiwan, 18–21 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3595–3603. [Google Scholar]
- Yang, X.; Zhang, C.; Tian, Y. Recognizing actions using depth motion maps-based histograms of oriented gradients. In Proceedings of the ACM International Conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 1057–1060. [Google Scholar]
- Elmadany, N.E.D.; He, Y.; Guan, L. Information fusion for human action recognition via biset/multiset globality locality preserving canonical correlation analysis. IEEE Trans. Image Process. 2018, 27, 5275–5287. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, Y.; Xiao, Y.; Xiong, F.; Jiang, W.; Cao, Z.; Zhou, J.T.; Yuan, J. 3DV: 3D Dynamic Voxel for Action Recognition in Depth Video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 508–517. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 5105–5114. [Google Scholar]
- Wang, P.; Li, W.; Gao, Z.; Zhang, J.; Tang, C.; Ogunbona, P.O. Action recognition from depth maps using deep convolutional neural networks. IEEE Trans. Hum.-Mach. Syst. 2015, 46, 498–509. [Google Scholar] [CrossRef]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A new representation of skeleton sequences for 3d action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3288–3297. [Google Scholar]
- Li, C.; Zhong, Q.; Xie, D.; Pu, S. Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation. arXiv 2018, arXiv:1804.06055v1. [Google Scholar]
- Liu, J.; Gang, W.; Ping, H.; Duan, L.Y.; Kot, A.C. Global Context-Aware Attention LSTM Networks for 3D Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3671–3680. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-based action recognition with directed graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7912–7921. [Google Scholar]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1227–1236. [Google Scholar]
- Yu, Z.; Wenbin, C.; Guodong, G. Evaluating spatiotemporal interest point features for depth-based action recognition. Image Vis. Comput. 2014, 32, 453–464. [Google Scholar]
- Oreifej, O.; Liu, Z. Hon4d: Histogram of oriented 4d normals for activity recognition from depth sequences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 716–723. [Google Scholar]
- Caetano, C.; Brémond, F.; Schwartz, W.R. Skeleton Image Representation for 3D Action Recognition Based on Tree Structure and Reference Joints. In Proceedings of the Thirty-second SIBGRAPI Conference on Graphics, Patterns and Images, Rio de Janeiro, Brazil, 28–31 October 2019; pp. 16–23. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-temporal lstm with trust gates for 3d human action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2022; Springer: Berlin/Heidelberg, Germany, 2016; pp. 816–833. [Google Scholar]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View adaptive neural networks for high performance skeleton-based human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1963–1978. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7444–7452. [Google Scholar]
- Plizzari, C.; Cannici, M.; Matteucci, M. Skeleton-based action recognition via spatial and temporal transformer networks. Comput. Vis. Image Underst. 2021, 208–209, 103219. [Google Scholar] [CrossRef]
- Shotton, J.; Fitzgibbon, A.; Cook, M.; Sharp, T.; Finocchio, M.; Moore, R.; Kipman, A.; Blake, A. Real-time human pose recognition in parts from single depth images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1297–1304. [Google Scholar]
- Xiong, F.; Zhang, B.; Xiao, Y.; Cao, Z.; Yu, T.; Zhou, J.T.; Yuan, J. A2j: Anchor-to-joint regression network for 3d articulated pose estimation from a single depth image. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 793–802. [Google Scholar]
- Kamel, A.; Sheng, B.; Yang, P.; Li, P.; Shen, R.; Feng, D.D. Deep Convolutional Neural Networks for Human Action Recognition Using Depth Maps and Postures. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 1806–1819. [Google Scholar] [CrossRef]
- Sánchez-Caballero, A.; de López-Diz, S.; Fuentes-Jimenez, D.; Losada-Gutiérrez, C.; Marrón-Romera, M.; Casillas-Pérez, D.; Sarker, M.I. 3DFCNN: Real-time action recognition using 3D deep neural networks with raw depth information. Multimed. Tools Appl. 2022, 81, 24119–24143. [Google Scholar] [CrossRef]
- Sánchez-Caballero, A.; Fuentes-Jiménez, D.; Losada-Gutiérrez, C. Real-time human action recognition using raw depth video-based recurrent neural networks. Multimed. Tools Appl. 2022, 82, 16213–16235. [Google Scholar] [CrossRef]
- Kumar, D.A.; Kishore, P.V.V.; Murthy, G.; Chaitanya, T.R.; Subhani, S. View Invariant Human Action Recognition using Surface Maps via convolutional networks. In Proceedings of the International Conference on Research Methodologies in Knowledge Management, Artificial Intelligence and Telecommunication Engineering, Chennai, India, 1–2 November 2023; pp. 1–5. [Google Scholar]
- Ghosh, S.K.; M, R.; Mohan, B.R.; Guddeti, R.M.R. Deep learning-based multi-view 3D-human action recognition using skeleton and depth data. Multimed. Tools Appl. 2022, 82, 19829–19851. [Google Scholar] [CrossRef]
- Li, R.; Li, X.; Fu, C.W.; Cohen-Or, D.; Heng, P.A. Pu-gan: A point cloud upsampling adversarial network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7203–7212. [Google Scholar]
- Qi, C.R.; Litany, O.; He, K.; Guibas, L.J. Deep hough voting for 3d object detection in point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9277–9286. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6410–6419. [Google Scholar]
- Ohn-Bar, E.; Trivedi, M.M. Joint Angles Similarities and HOG2 for Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 465–470. [Google Scholar]
- Li, J.; Wong, Y.; Zhao, Q.; Kankanhalli, M.S. Unsupervised learning of view-invariant action representations. Adv. Neural Inf. Process. Syst. 2018, 31, 1262–1272. [Google Scholar]
- Liu, X.; Qi, C.R.; Guibas, L.J. Flownet3d: Learning scene flow in 3d point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 529–537. [Google Scholar]
- Zhai, M.; Xiang, X.; Lv, N.; Kong, X. Optical flow and scene flow estimation: A survey. Pattern Recognit. 2021, 114, 107861. [Google Scholar] [CrossRef]
- Fernando, B.; Gavves, E.; Oramas, J.; Ghodrati, A.; Tuytelaars, T. Rank pooling for action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 773–787. [Google Scholar] [CrossRef]
- Liu, J.; Xu, D. GeometryMotion-Net: A strong two-stream baseline for 3D action recognition. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4711–4721. [Google Scholar] [CrossRef]
- Dou, W.; Chin, W.H.; Kubota, N. Growing Memory Network with Random Weight 3DCNN for Continuous Human Action Recognition. In Proceedings of the IEEE International Conference on Fuzzy Systems, Incheon, Republic of Korea, 13–17 August 2023; pp. 1–6. [Google Scholar]
- Fan, H.; Yu, X.; Ding, Y.; Yang, Y.; Kankanhalli, M. PSTNet: Point spatio-temporal convolution on point cloud sequences. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020; pp. 1–6. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2684–2701. [Google Scholar] [CrossRef]
- Liu, J.; Wang, G.; Duan, L.Y.; Abdiyeva, K.; Kot, A.C. Skeleton-Based Human Action Recognition with Global Context-Aware Attention LSTM Networks. IEEE Trans. Image Process. 2018, 27, 1586–1599. [Google Scholar] [CrossRef]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12026–12035. [Google Scholar]
- Li, X.; Huang, Q.; Wang, Z. Spatial and temporal information fusion for human action recognition via Center Boundary Balancing Multimodal Classifier. J. Vis. Commun. Image Represent. 2023, 90, 103716. [Google Scholar] [CrossRef]
- Zan, H.; Zhao, G. Human Action Recognition Research Based on Fusion TS-CNN and LSTM Networks. Arab. J. Sci. Eng. 2023, 48, 2331–2345. [Google Scholar] [CrossRef]
- Yang, X.; Tian, Y. Super normal vector for activity recognition using depth sequences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 804–811. [Google Scholar]
- Basak, H.; Kundu, R.; Singh, P.K.; Ijaz, M.F.; Woźniak, M.; Sarkar, R. A union of deep learning and swarm-based optimization for 3D human action recognition. Sci. Rep. 2022, 12, 5494. [Google Scholar]
- Qi, Y.; Hu, J.; Zhuang, L.; Pei, X. Semantic-guided multi-scale human skeleton action recognition. Appl. Intell. Int. J. Artif. Intell. Neural Netw. Complex Probl.-Solving Technol. 2023, 53, 9763–9778. [Google Scholar] [CrossRef]
- Ji, X.; Zhao, Q.; Cheng, J.; Ma, C. Exploiting spatio-temporal representation for 3D human action recognition from depth map sequences. Knowl.-Based Syst. 2021, 227, 107040. [Google Scholar] [CrossRef]
- Guo, J.; Liu, J.; Xu, D. 3D-Pruning: A Model Compression Framework for Efficient 3D Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 8717–8729. [Google Scholar] [CrossRef]
- Li, X.; Huang, Q.; Zhang, Y.; Yang, T.; Wang, Z. PointMapNet: Point Cloud Feature Map Network for 3D Human Action Recognition. Symmetry 2023, 15, 363. [Google Scholar] [CrossRef]
- Liu, M.; Yuan, J. Recognizing human actions as the evolution of pose estimation maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1159–1168. [Google Scholar]
- Liu, J.; Shahroudy, A.; Wang, G.; Duan, L.Y.; Kot, A.C. Skeleton-based online action prediction using scale selection network. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1453–1467. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Voxel Size (mm) | Cross-Subject | Cross-View |
|---|---|---|
| 25 × 25 × 25 | 87.1% | 94.9% |
| 35 × 35 × 35 | ||
| 45 × 45 × 45 | 88.1% | 95.5% |
| 55 × 55 × 55 | 86.5% | 93.6% |
| The Value of the Threshold | Cross-Subject | Cross-View |
|---|---|---|
| 15 | 79.5% | 85.1% |
| 20 | 83.5% | 93.2% |
| 25 | 86.5% | 94.4% |
| 30 | ||
| 35 | 87.3% | 94.9% |
| 40 | 86.9% | 93.7% |
| Point Feature | Cross-Subject | Cross-View |
|---|---|---|
| (x, y, z) | 78.0% | 82.3% |
| (x, y, z, o, f, l) |
| Input Stream | Cross-Subject | Cross-View |
|---|---|---|
| 1s-SFCNet (L) | ||
| 1s-SFCNet (G) | ||
| SFCNet (concat) | ||
| SFCNet (add) | ||
| SFCNet (fusion) |
| Method | Cross-Subject | Cross-View | Year |
|---|---|---|---|
| Input: 3D Skeleton | |||
| GCA-LSTM [15] | 74.4 | 82.8 | 2017 |
| Two-stream attention LSTM [46] | 77.1 | 85.1 | 2018 |
| ST-GCN [23] | 81.5 | 88.3 | 2018 |
| SkeleMotion [5] | 69.6 | 80.1 | 2019 |
| AS-GCN [6] | 86.8 | 94.2 | 2019 |
| 2s-AGCN [47] | 88.5 | 95.1 | 2019 |
| ST-TR (new) [24] | 89.9 | 96.1 | 2021 |
| DSwarm-Net (new) [51] | 85.5 | 90.0 | 2022 |
| ActionNet [30] | 73.2 | 76.1 | 2023 |
| SGMSN (new) [52] | 90.1 | 95.8 | 2023 |
| Input: Depth maps | |||
| HON4D [19] | 30.6 | 7.3 | 2013 |
| HOG2 [35] | 32.2 | 22.3 | 2013 |
| SNV [50] | 31.8 | 13.6 | 2014 |
| Li. [36] | 68.1 | 83.4 | 2018 |
| Wang. [2] | 87.1 | 84.2 | 2018 |
| MVDI [3] | 84.6 | 87.3 | 2019 |
| 3DV-PointNet++ [10] | 88.8 | 96.3 | 2020 |
| DOGV (new) [53] | 90.6 | 94.7 | 2021 |
| 3DFCNN [28] | 78.1 | 80.4 | 2022 |
| 3D-Pruning [54] | 83.6 | 92.4 | 2022 |
| ConvLSTM (new) [29] | 80.4 | 79.9 | 2022 |
| CBBMC (new) [48] | 83.3 | 87.7 | 2023 |
| PointMapNet (new) [55] | 89.4 | 96.7 | 2023 |
| SFCNet (ours) | - | ||
| Input: Multimodalities | |||
| ED-MHI [31] | 85.6 | - | 2022 |
| TS-CNN-LSTM [49] | 87.3 | 91.8 | 2023 |
| Method | Cross-Subject | Cross-Set | Year |
|---|---|---|---|
| Input: 3D Skeleton | |||
| GCA-LSTM [15] | 58.3 | 59.3 | 2017 |
| Body pose evolution map [56] | 64.6 | 66.9 | 2018 |
| Two-stream attention LSTM [46] | 61.2 | 63.3 | 2018 |
| ST-GCN [23] | 70.7 | 73.2 | 2018 |
| NTU RGB+D 120 baseline [45] | 55.7 | 57.9 | 2019 |
| FSNet [57] | 59.9 | 62.4 | 2019 |
| SkeleMotion [5] | 67.7 | 66.9 | 2019 |
| TSRJI [20] | 67.9 | 62.8 | 2019 |
| AS-GCN [6] | 77.9 | 78.5 | 2019 |
| 2s-AGCN [47] | 82.9 | 84.9 | 2019 |
| ST-TR (new) [24] | 82.7 | 84.7 | 2021 |
| SGMSN (new) [52] | 84.8 | 85.9 | 2023 |
| Input: Depth maps | |||
| APSR [45] | 48.7 | 40.1 | 2019 |
| 3DV-PointNet++ [10] | 82.4 | 93.5 | 2020 |
| DOGV (new) [53] | 82.2 | 85.0 | 2021 |
| 3D-Pruning [54] | 76.6 | 88.8 | 2022 |
| SFCNet (ours) | - | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Huang, Q.; Mao, Y.; Qian, W.; Li, X. A Novel Symmetric Fine-Coarse Neural Network for 3D Human Action Recognition Based on Point Cloud Sequences. Appl. Sci. 2024, 14, 6335. https://doi.org/10.3390/app14146335
Li C, Huang Q, Mao Y, Qian W, Li X. A Novel Symmetric Fine-Coarse Neural Network for 3D Human Action Recognition Based on Point Cloud Sequences. Applied Sciences. 2024; 14(14):6335. https://doi.org/10.3390/app14146335
Chicago/Turabian StyleLi, Chang, Qian Huang, Yingchi Mao, Weiwen Qian, and Xing Li. 2024. "A Novel Symmetric Fine-Coarse Neural Network for 3D Human Action Recognition Based on Point Cloud Sequences" Applied Sciences 14, no. 14: 6335. https://doi.org/10.3390/app14146335
APA StyleLi, C., Huang, Q., Mao, Y., Qian, W., & Li, X. (2024). A Novel Symmetric Fine-Coarse Neural Network for 3D Human Action Recognition Based on Point Cloud Sequences. Applied Sciences, 14(14), 6335. https://doi.org/10.3390/app14146335