

Multilevel Hierarchical Bayesian Modeling of Cross-National Factors in Vehicle Sales



Abstract
:1. Introduction
2. Materials and Methods
2.1. Datasets
- The average income per person (in USD), based on CEOWORLD magazine’s research about average monthly net salaries around the world from 2022;
- The quality of road infrastructure (on a scale from 1 to 7), based on information from the World Economic Forum 2019;
- Average fuel prices (in USD), based on information from the portal Numbeo.com from 2023;
- The percentage of a country’s area covered in mountains, based on information from the non-profit environmental foundation GRID-Arendal.
2.1.1. Dataset 1—49 Countries
2.1.2. Dataset 2—G20
2.2. Modelling
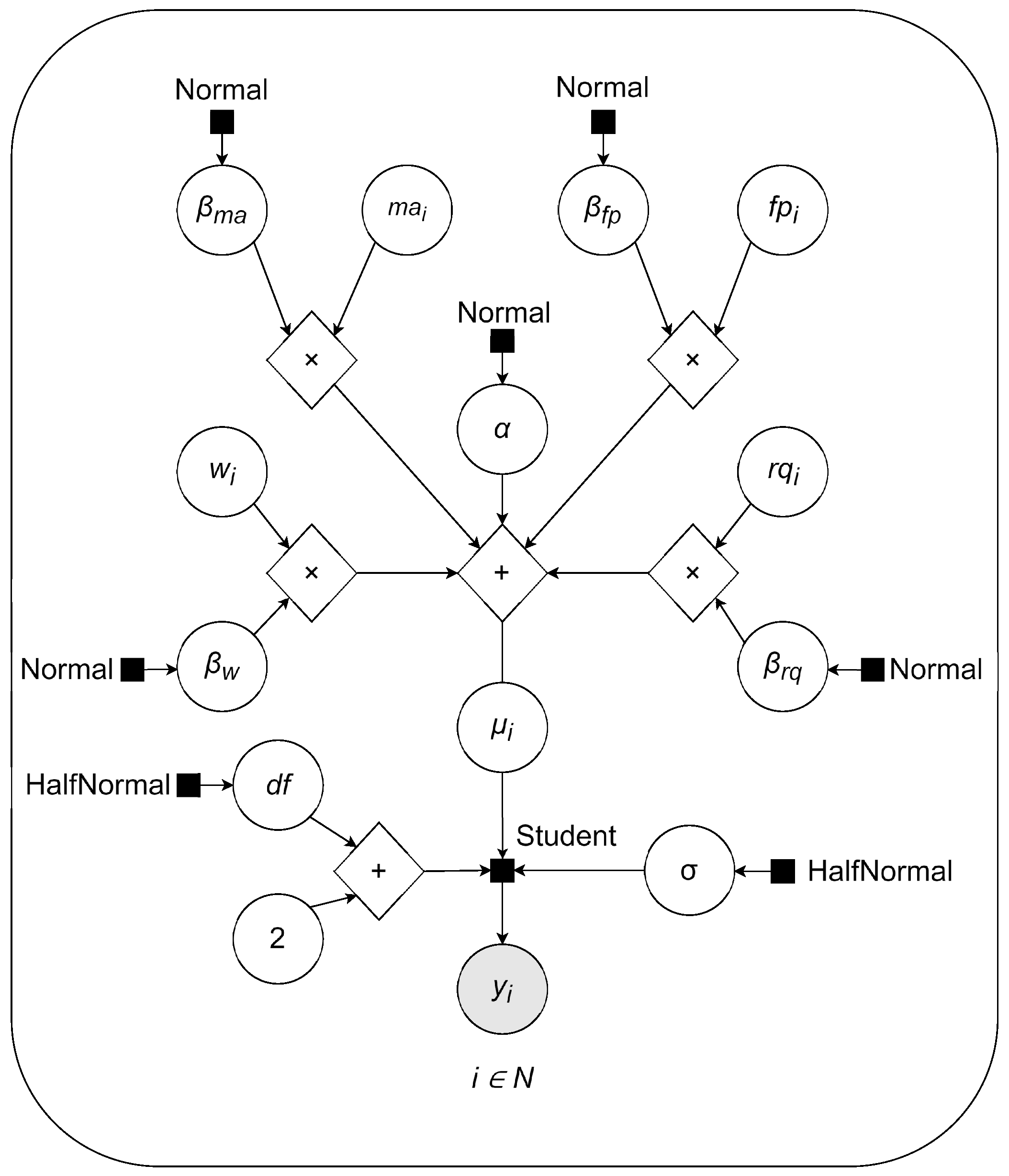
2.2.1. Model 1
- is the intercept of the model.
- is the coefficient for the effect of fuel prices on the response variable.
- is the coefficient for the effect of wages on the response variable.
- is the coefficient for the effect of road quality on the response variable.
- is the coefficient for the effect of mountainous terrain on the response variable.
- is the square root of the standard deviation of the main distribution in the model.
- is the mean response for the i-th observation.
- , , , and are the observed values of fuel prices, wages, road quality, and mountainous areas, respectively, for the i-th observation.
- is the response variable of SUV sales for the i-th observation.
2.2.2. Model 2
- is the dispersion parameter of the beta distribution.
- is the first direct parameter for the beta distribution.
- is the second direct parameter for the beta distribution.
- is the value of variance for the beta distribution.
2.2.3. Model 3
- is the degrees of freedom parameter of Student’s t-distribution.
2.2.4. Model 4
- is a mean value parameter for the intercept ’s normal distribution.
- is a variance parameter for the intercept ’s normal distribution.
3. Results
3.1. Comparison of Models
3.1.1. Results for Model 1
3.1.2. Results for Model 2
3.1.3. Results for Model 3
3.1.4. Results for Model 4
4. Discussion and Conclusions
4.1. Discussion
- The point is skipped;
- The model is fitted again, without the omitted point, to the rest of the data;
- The predicted error is calculated for the missing point.
4.2. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SUV | Sport utility vehicle |
| MCMC | Markov-chain Monte Carlo |
| G20 | Group of 20 |
| EU | European Union |
| w | Values or coefficients related to wage |
| fp | Values or coefficients related to fuel price |
| rq | Values or coefficients related to road quality |
| ma | Values or coefficients related to mountainous areas |
| y | Model output—SUV sales percentage value |
| WAIC | Watanabe–Akaike Information Criterion |
| LOO-CV | Leave-One-Out Cross-Validation |
| ELPD | Expected Log Predictive Density |
References
- Poland Car Sales Data—Sales of New Cars in Poland, 2024. Based on the Data from Manufactures, ANDC (Automotive News Data Center) and JATO Dynamics. Available online: https://www.goodcarbadcar.net/poland-car-sales-data/ (accessed on 16 April 2024).
- Registrations of New Cars and Light Commercial Vehicles up to 3.5 T: January–December 2023. Press Release. 2024. Available online: https://www.pzpm.org.pl/pl/content/download/14071/93625/file/PZPM_CEP_Info_SOiSD_09_2023.pdf (accessed on 16 April 2024).
- Geetharamani, G.; Dhinakaran, K.; Selvaraj, J.; Singh, S. Sport-utility vehicle prediction based on machine learning approach. J. Appl. Res. Technol. 2021, 19, 184–193. [Google Scholar] [CrossRef]
- Punjabi, S.K.; Shetty, V.; Pranav, S.; Yadav, A. Sales Prediction using Online Sentiment with Regression Model. In Proceedings of the 2020 4th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 13–15 May 2020; pp. 209–212. [Google Scholar]
- Wijnhoven, F.; Plant, O. Sentiment Analysis and Google Trends Data for Predicting Car Sales; University of Twente: Enschede, The Netherlands, 2017. [Google Scholar]
- Berger, J.O. Statistical Decision Theory and Bayesian Analysis, 2nd ed.; Springer series in statistics; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 1995. [Google Scholar]
- SUV Sales Determination Dataset GitHub Repository. 2024. Available online: https://github.com/sukiennik-monika/SUV-Sales-Determination-Dataset (accessed on 16 April 2024).
- Hajnal, P.I. The G20: Evolution, Interrelationships, Documentation; Taylor & Francis: Abingdon, UK, 2019. [Google Scholar]
- Lee, M.D.; Wagenmakers, E.J. Bayesian Cognitive Modeling: A Practical Course; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Lambert, B. A Student’s Guide to Bayesian Statistics; Sage Publications Ltd.: Thousand Oaks, CA, USA, 2018; pp. 1–520. [Google Scholar]
- Ferrari, S.; Cribari-Neto, F. Beta regression for modelling rates and proportions. J. Appl. Stat. 2004, 31, 799–815. [Google Scholar] [CrossRef]
- Bayesian Beta Regression. 2023. Available online: https://m-clark.github.io/models-by-example/bayesian-beta-regression.html (accessed on 16 April 2024).
- Kruschke, J. Doing Bayesian Data Analysis: A Tutorial with R, JAGS, and Stan; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Cribari-Neto, F.; Zeileis, A. Beta regression in R. J. Stat. Softw. 2010, 34, 1–24. [Google Scholar] [CrossRef]
- Hurst, S. The Characteristic Function of the Student t-Distribution; Centre for Mathematics and Its Applications, School of Mathematical Sciences, ANU: Canberra, Australia, 1995. [Google Scholar]
- Stan Docs—Stan User’s Guide. 2024. Available online: https://mc-stan.org/docs/stan-users-guide/ (accessed on 16 April 2024).
- Bayesian Models for SUV Sales Determination GitHub Repository. 2024. Available online: https://github.com/sukiennik-monika/Bayesian-Modeling-Of-Cross-National-Factors-In-SUV-Sales (accessed on 9 May 2024).





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Country | SUV Sales | Road Quality | Mountain Area | Wage | Fuel Price |
|---|---|---|---|---|---|
| Argentina | 16.13 | 3.60 | 30.00 | 427.94 | 0.90 |
| Australia | 50.65 | 4.90 | 6.00 | 4218.89 | 1.35 |
| Brazil | 21.82 | 3.00 | 30.00 | 402.77 | 1.29 |
| Canada | 43.00 | 5.00 | 24.00 | 3338.62 | 1.18 |
| China | 30.98 | 4.60 | 33.00 | 1122.36 | 1.19 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sukiennik, M.; Baranowski, J. Multilevel Hierarchical Bayesian Modeling of Cross-National Factors in Vehicle Sales. Appl. Sci. 2024, 14, 6325. https://doi.org/10.3390/app14146325
Sukiennik M, Baranowski J. Multilevel Hierarchical Bayesian Modeling of Cross-National Factors in Vehicle Sales. Applied Sciences. 2024; 14(14):6325. https://doi.org/10.3390/app14146325
Chicago/Turabian StyleSukiennik, Monika, and Jerzy Baranowski. 2024. "Multilevel Hierarchical Bayesian Modeling of Cross-National Factors in Vehicle Sales" Applied Sciences 14, no. 14: 6325. https://doi.org/10.3390/app14146325
APA StyleSukiennik, M., & Baranowski, J. (2024). Multilevel Hierarchical Bayesian Modeling of Cross-National Factors in Vehicle Sales. Applied Sciences, 14(14), 6325. https://doi.org/10.3390/app14146325