

Research on Public Service Request Text Classification Based on BERT-BiLSTM-CNN Feature Fusion


Abstract
1. Introduction
- Single neural network models exhibit shortcomings in handling complex semantic and syntactic structures, difficulties in processing long-range dependencies, and poor generalization capabilities in text classification tasks. The hybrid neural network model BBLC effectively addresses these deficiencies compared to single neural network models.
- The BERT-BiLSTM-CNN model combines multiple structures, enabling comprehensive consideration of language context, sequence dependencies, and local patterns. This integrated feature extraction helps reduce model misjudgments and biases in understanding complex texts, leading to superior classification performance in multi-class tasks compared to other hybrid neural network models.
- BERT-BiLSTM-CNN provides richer contextual information compared to Word2Vec-BiLSTM-CNN. Word2Vec, being a static embedding method based on word embeddings, fails to capture semantic variations of words across different contexts. Consequently, BERT-BiLSTM-CNN achieves higher classification performance than Word2Vec, which is illustrated in Section 4.
2. Related Work
3. Model Design
3.1. BERT
3.2. BiLSTM
3.3. CNN
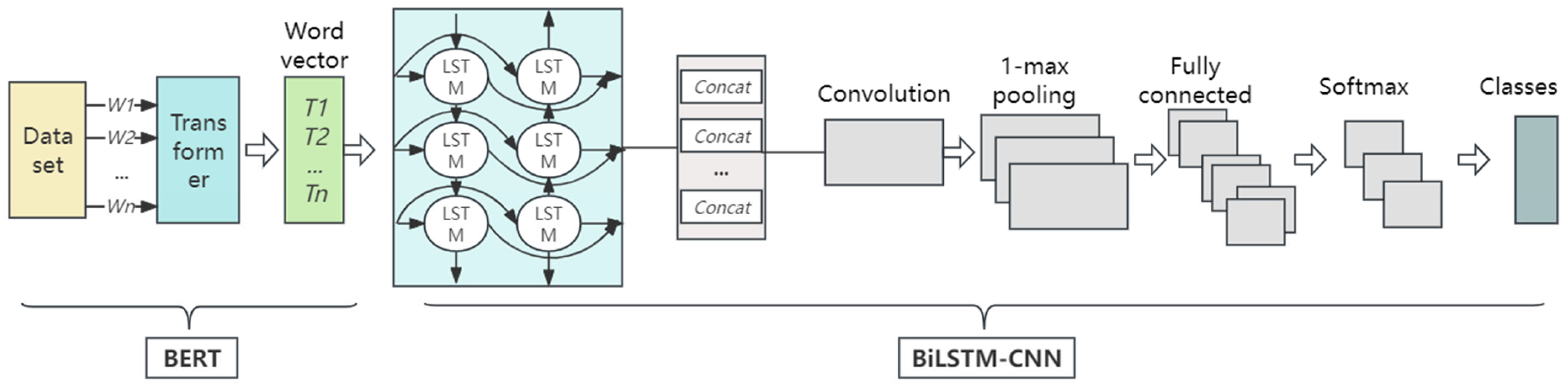
3.4. BERT-BiLSTM-CNN
- (1)
- First, process the data set. is the input text in Figure 3. The input text is converted into word vectors after the Transformer encoder, which can be trained as model parameters.
- (2)
- BERT output continues to feed into a two-way LSTM network. BiLSTM uses forward and backward LSTM units for bidirectional modeling of input sequences. The information included in the input sequence is captured by the hidden states of each time step, which are the BiLSTM outputs. CNN receives the spliced forward and backward outputs of the BiLSTM.
- (3)
- Multiple convolution kernels of the CNN convolution layer extract local features by sliding over the input data. The pooling layer receives local feature maps from the convolutional layer as input and performs max pooling operations for each feature map.
- (4)
- The fully connected layer receives the feature representation from the BiLSTM-CNN module and obtains the output through the linear transformation of the weight matrix. Finally, the Softmax function receives the output of the full connection layer and processes it indexically and normalized to obtain a probability for each category. The calculation formulas are (5) and (6).
4. Experiments and Results
4.1. Data Set
4.2. Experimental Environment and Parameters Design
4.3. Experimental Comparison and Result Analysis
4.3.1. Model Comparison
4.3.2. Comparison of the Classification Effects of Different Parameters
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guan, G.; Guo, J.; Wang, H. Varying Naïve Bayes models with applications to classification of chinese text documents. J. Bus. Econ. Stat. 2014, 32, 445–456. [Google Scholar] [CrossRef]
- Moraes, R.; Valiati, J.F.; Neto, W.P.G.O. Document-level sentiment classification: An empirical comparison between SVM and ANN. Expert Syst. Appl. 2013, 40, 621–633. [Google Scholar] [CrossRef]
- Jiang, S.; Pang, G.; Wu, M.; Kuang, L. An improved K-nearest-neighbor algorithm for text categorization. Expert Syst. Appl. 2012, 39, 1503–1509. [Google Scholar] [CrossRef]
- Bilal, M.; Israr, H.; Shahid, M.; Khan, A. Sentiment classification of Roman-Urdu opinions using Naïve Bayesian, Decision Tree and KNN classification techniques. J. King Saud Univ.-Comput. Inf. Sci. 2016, 28, 330–344. [Google Scholar] [CrossRef]
- Soni, S.; Chouhan, S.S.; Rathore, S.S. TextConvoNet: A convolutional neural network based architecture for text classification. Appl. Intell. 2023, 53, 14249–14268. [Google Scholar] [CrossRef]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Yin, W.; Kann, K.; Yu, M.; Schütze, H. Comparative study of CNN and RNN for natural language processing. arXiv 2017, arXiv:1702.01923. [Google Scholar]
- Dirash, A.R.; Bargavi, S.K. LSTM Based Text Classification. IITM J. Manag. IT 2021, 12, 62–65. [Google Scholar]
- Liu, G.; Guo, J. Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 2019, 337, 325–338. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Galassi, A.; Lippi, M.; Torroni, P. Attention in natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4291–4308. [Google Scholar] [CrossRef]
- Sun, X.; Lu, W. Understanding attention for text classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Seattle, WA, USA, 5–10 July 2020; pp. 3418–3428. [Google Scholar]
- Zhang, D.; Xu, H.; Su, Z.; Xu, Y. Chinese comments sentiment classification based on word2vec and SVMperf. Expert Syst. Appl. 2015, 42, 1857–1863. [Google Scholar] [CrossRef]
- Shen, Y.; Liu, J. Comparison of text sentiment analysis based on bert and word2vec. In Proceedings of the 2021 IEEE 3rd International Conference on Frontiers Technology of Information and Computer, Greenville, SC, USA, 12–14 November 2021; pp. 144–147. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Kale, A.S.; Pandya, V.; Di Troia, F.; Stamp, M. Malware classification with word2vec, hmm2vec, bert, and elmo. J. Comput. Virol. Hacking Tech. 2023, 19, 1–16. [Google Scholar] [CrossRef]
- Li, Z.; Yang, X.; Zhou, L.; Jia, H.; Li, W. Text matching in insurance question-answering community based on an integrated BiLSTM-TextCNN model fusing multi-feature. Entropy 2023, 25, 639. [Google Scholar] [CrossRef] [PubMed]
- Jiang, X.; Song, C.; Xu, Y.; Li, Y.; Peng, Y. Research on sentiment classification for netizens based on the BERT-BiLSTM-TextCNN model. PeerJ Comput. Sci. 2022, 8, e1005. [Google Scholar] [CrossRef]
- Li, X.; Cui, M.; Li, J.; Bai, R.; Lu, Z.; Aickelin, U. A hybrid medical text classification framework: Integrating attentive rule construction and neural network. Neurocomputing 2021, 443, 345–355. [Google Scholar] [CrossRef]
- Hernández, G.; Zamora, E.; Sossa, H.; Téllez, G.; Furlán, F. Hybrid neural networks for big data classification. Neurocomputing 2020, 390, 327–340. [Google Scholar] [CrossRef]
- Li, M.; Chen, L.; Zhao, J.; Li, Q. Sentiment analysis of Chinese stock reviews based on BERT model. Appl. Intell. 2021, 51, 5016–5024. [Google Scholar] [CrossRef]
- Cai, R.; Qin, B.; Chen, Y.; Zhang, L.; Yang, R.; Chen, S.; Wang, W. Sentiment Analysis About Investors and Consumers in Energy Market Based on BERT-BiLSTM. IEEE Access 2020, 8, 171408–171415. [Google Scholar] [CrossRef]
- Li, X.; Lei, Y.; Ji, S. BERT-and BiLSTM-based sentiment analysis of online Chinese buzzwords. Future Internet 2022, 14, 332. [Google Scholar] [CrossRef]
- Kaur, K.; Kaur, P. BERT-CNN: Improving BERT for requirements classification using CNN. Procedia Comput. Sci. 2023, 218, 2604–2611. [Google Scholar] [CrossRef]
- Xie, J.; Hou, Y.; Wang, Y.; Wang, Q.; Li, B.; Lv, S.; Vorotnitsky, Y.I. Chinese text classification based on attention mechanism and feature-enhanced fusion neural network. Computing 2020, 102, 683–700. [Google Scholar] [CrossRef]
- Deng, J.; Cheng, L.; Wang, Z. Attention-based BiLSTM fused CNN with gating mechanism model for Chinese long text classification. Comput. Speech Lang. 2021, 68, 101182. [Google Scholar] [CrossRef]
- Letarte, G.; Paradis, F.; Giguère, P.; Laviolette, F. Importance of self-attention for sentiment analysis. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 1 November 2018; pp. 267–275. [Google Scholar]
- Bao, T.; Ren, N.; Luo, R.; Wang, B.; Shen, G.; Guo, T. A BERT-based hybrid short text classification model incorporating CNN and attention-based BiGRU. J. Organ. End User Comput. 2021, 33, 1–21. [Google Scholar] [CrossRef]
- Kaur, K.; Kaur, P. Improving BERT model for requirements classification by bidirectional LSTM-CNN deep model. Comput. Electr. Eng. 2023, 108, 108699. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Text Category | Training Set | Test Set |
|---|---|---|---|
| 0 | Consultation | 14,260 | 3843 |
| 1 | Complaint | 16,246 | 4319 |
| 2 | Help | 9669 | 2549 |
| 3 | Advice | 1207 | 325 |
| Label | Text Content |
|---|---|
| 0 | A citizen called to inquire: What are the epidemic prevention and control measures in Huiyu District, Heyuan City, Guangdong Province? |
| 1 | Xinyu No. 4 Middle School charges fees for extra classes without parents’ consent and does not allow parental objections. They insist that improving students’ education is solely the responsibility and obligation of teachers, emphasizing efficient classroom management to lighten students’ burdens instead of increasing pressure through fees and extra classes for students and parents. |
| 2 | Citizen’s call: Seeking help with a high-speed tire blowout. |
| 0 | Recently, the provincial education department issued a document stating that there will be reforms to the entrance examination for the 2021 graduating class of junior high school students. However, when I visited the provincial education department, they mentioned that local enrollment policies will prevail. Could you please clarify if there are indeed reforms to the entrance examination for this year’s junior high school students? |
| 3 | Mr. Wu called to suggest reducing the volume of freight trucks on NanYuan Road. |
| 1 | A citizen called to report that a BMW 4S dealership in Xiamen refunded a deposit and ceased selling BMW cars, which they find unreasonable. |
| 2 | Citizen’s Call: Can teachers from Changqing Elementary School on Hushan Road (citizen declined to disclose grade) take students to other teaching locations for lessons after extended classes end, around 5 PM? (Teaching content pertains to classroom studies) Citizen mentioned this is a common practice. |
| Hyperparameter | Value | Hyperparameter | Value |
|---|---|---|---|
| Epoch | 15 | Optimizer | Adam |
| Dropout | 0.5 | Hidden_size | 768 |
| Learning rate | 10−3 | Max_length | 300 |
| Batch_size | 128 | Kernel_sizes | [7,8,9] |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| BERT-CNN [24] | 0.9509 | 0.9354 | 0.9503 | 0.9395 |
| BERT-BiGRU | 0.9345 | 0.9405 | 0.9126 | 0.9213 |
| BERT-BiLSTM [23] | 0.9306 | 0.9080 | 0.9270 | 0.9129 |
| BERT-BiGRU-CNN [28] | 0.9420 | 0.9385 | 0.9344 | 0.9322 |
| BERT-BiLSTM-CNN | 0.9536 | 0.9541 | 0.9519 | 0.9509 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| BERT-BiGRU | 0.9345 | 0.9405 | 0.9136 | 0.9223 |
| BERT-BiGRU-Attention | 0.9469 | 0.9386 | 0.9448 | 0.9387 |
| BERT-BiLSTM | 0.9306 | 0.9080 | 0.9270 | 0.9129 |
| BERT-BiLSTM-Attention | 0.9391 | 0.9382 | 0.9309 | 0.9314 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| BERT-BiGRU-CNN | 0.9420 | 0.9385 | 0.9344 | 0.9322 |
| BERT-BiGRU-Attention-CNN | 0.9299 | 0.9274 | 0.9062 | 0.9125 |
| BERT-CNN | 0.9509 | 0.9354 | 0.9503 | 0.9395 |
| BERT-Attention-CNN | 0.9446 | 0.9440 | 0.9287 | 0.9335 |
| BERT-BiLSTM-CNN | 0.9536 | 0.9541 | 0.9519 | 0.9509 |
| BERT-BiLSTM-Attention-CNN | 0.9505 | 0.9528 | 0.9457 | 0.9470 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Word2Vec-CNN [5] | 0.9387 | 0.9410 | 0.9340 | 0.9353 |
| BERT-CNN | 0.9509 | 0.9354 | 0.9503 | 0.9395 |
| Word2Vec-Attention-CNN | 0.9335 | 0.9378 | 0.9237 | 0.9282 |
| BERT-Attention-CNN | 0.9446 | 0.9440 | 0.9287 | 0.9335 |
| Word2Vec-BiLSTM-Attention-CNN [25] | 0.9444 | 0.9356 | 0.9351 | 0.9325 |
| BERT-BiLSTM-Attention-CNN | 0.9505 | 0.9528 | 0.9457 | 0.9470 |
| Word2Vec-BiLSTM-CNN [17] | 0.9413 | 0.9407 | 0.9415 | 0.9389 |
| BERT-BiLSTM-CNN | 0.9536 | 0.9541 | 0.9519 | 0.9509 |
| Model | BERT-BiLSTM-CNN | |||||
|---|---|---|---|---|---|---|
| Num_Layers | Kernel_Sizes | Hidden_Sizes | Accuracy | Precision | Recall | F1-Score |
| 1 | [2,3,4] | 768 | 0.9461 | 0.9450 | 0.9454 | 0.9431 |
| 1 | [3,4,5] | 768 | 0.9491 | 0.9510 | 0.9414 | 0.9442 |
| 1 | [4,5,6] | 768 | 0.9467 | 0.9360 | 0.9461 | 0.9378 |
| 1 | [5,6,7] | 768 | 0.9377 | 0.9377 | 0.9485 | 0.9392 |
| 1 | [6,7,8] | 768 | 0.9529 | 0.9521 | 0.9495 | 0.9490 |
| 1 | [7,8,9] | 768 | 0.9536 | 0.9541 | 0.9519 | 0.9509 |
| 1 | [8,9,10] | 768 | 0.9464 | 0.9459 | 0.9474 | 0.9437 |
| 1 | [9,10,11] | 768 | 0.9527 | 0.9532 | 0.9495 | 0.9491 |
| 1 | [10,11,12] | 768 | 0.9519 | 0.9509 | 0.9563 | 0.9487 |
| Model | BERT-BiLSTM-CNN | |||||
|---|---|---|---|---|---|---|
| Num_Layers | Kernel_Sizes | Hidden_Sizes | Accuracy | Precision | Recall | F1-Score |
| 1 | [7,8,9] | 128 | 0.9379 | 0.9440 | 0.9337 | 0.9353 |
| 1 | [7,8,9] | 256 | 0.9483 | 0.9530 | 0.9434 | 0.9459 |
| 1 | [7,8,9] | 512 | 0.9521 | 0.9528 | 0.9469 | 0.9480 |
| 1 | [7,8,9] | 768 | 0.9536 | 0.9541 | 0.9519 | 0.9509 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, Y.; Chen, G.; Cao, J. Research on Public Service Request Text Classification Based on BERT-BiLSTM-CNN Feature Fusion. Appl. Sci. 2024, 14, 6282. https://doi.org/10.3390/app14146282
Xiong Y, Chen G, Cao J. Research on Public Service Request Text Classification Based on BERT-BiLSTM-CNN Feature Fusion. Applied Sciences. 2024; 14(14):6282. https://doi.org/10.3390/app14146282
Chicago/Turabian StyleXiong, Yunpeng, Guolian Chen, and Junkuo Cao. 2024. "Research on Public Service Request Text Classification Based on BERT-BiLSTM-CNN Feature Fusion" Applied Sciences 14, no. 14: 6282. https://doi.org/10.3390/app14146282
APA StyleXiong, Y., Chen, G., & Cao, J. (2024). Research on Public Service Request Text Classification Based on BERT-BiLSTM-CNN Feature Fusion. Applied Sciences, 14(14), 6282. https://doi.org/10.3390/app14146282