
Adaptive Feature Refinement and Weighted Similarity for Deep Loop Closure Detection in Appearance Variation

 ,
,
Abstract
1. Introduction
- Dynamic feature selection with self-attention: A novel learning-based LCD framework, incorporating the Channel Weighting Module guided by the insight of inverse document frequency in BoW, is proposed to distill the distinguishable spatial cues and regions of interest.
- Adaptive weighted similarity measurement for appearance variation: To enhance detection accuracy, a weighted similarity score is generated in the Similarity Measurement Module to distinguish positive and negative pairs based on a patch-by-patch matrix.
- Comprehensive multi-dataset validation: MetricNet achieves appealing performance on three typical datasets with drastic illumination and seasonal changes. It also delivers reliable results in scenes with significant viewpoint variations and performs well in localization applications.
2. Related Works
2.1. Feature Extraction
2.1.1. Hand-Crafted Feature Representation
2.1.2. Learned Feature Representation
2.2. Similarity Measurement
2.2.1. Image-to-Image Matching
2.2.2. Sequence-to-Sequence Matching
2.3. Challenges of LCD and Role of Deep Learning
2.3.1. Appearance Variation and Dynamic Environment
2.3.2. Perceptual Aliasing and Viewpoint Variation
3. System Model
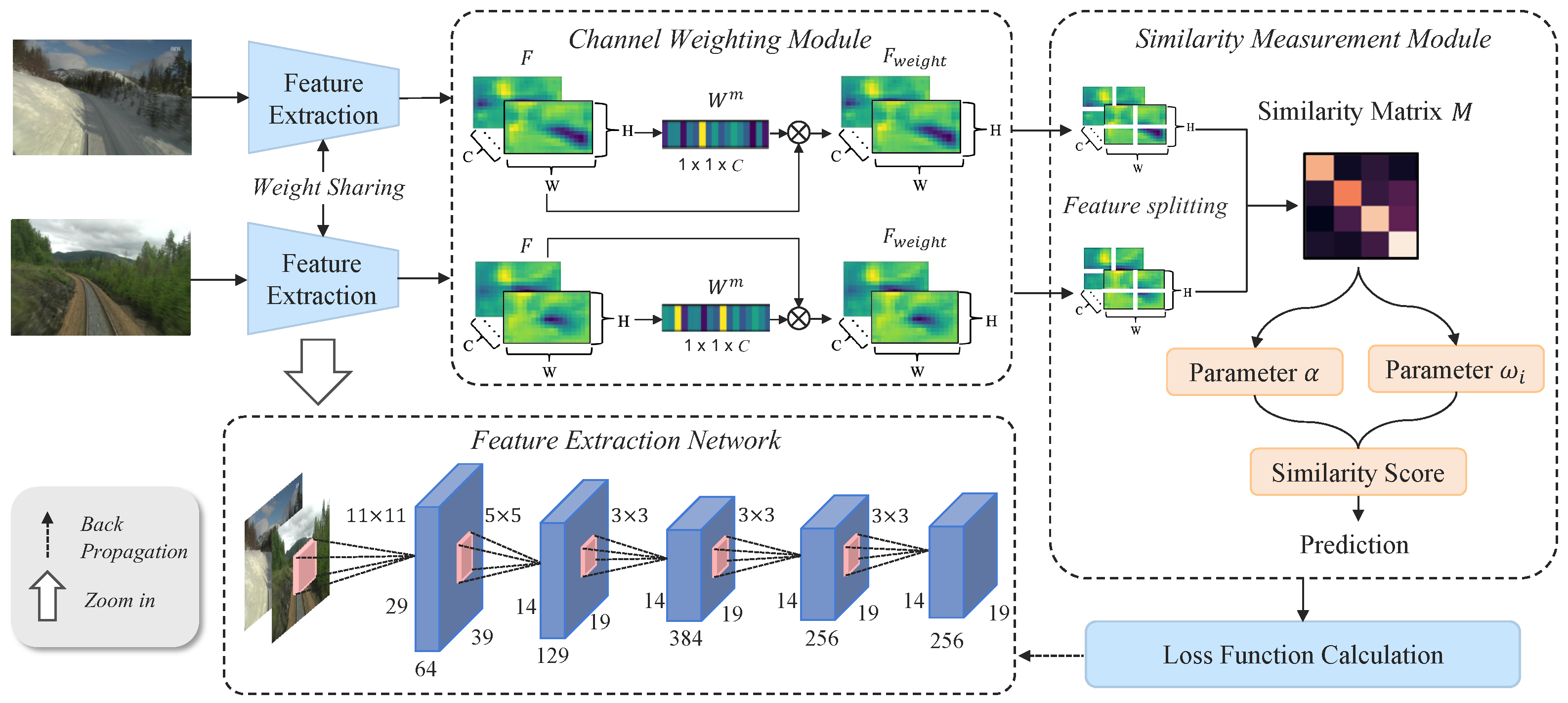
3.1. Feature Extraction and Distillation
3.1.1. Deep Feature Extraction
3.1.2. Channel Weighting Distillation
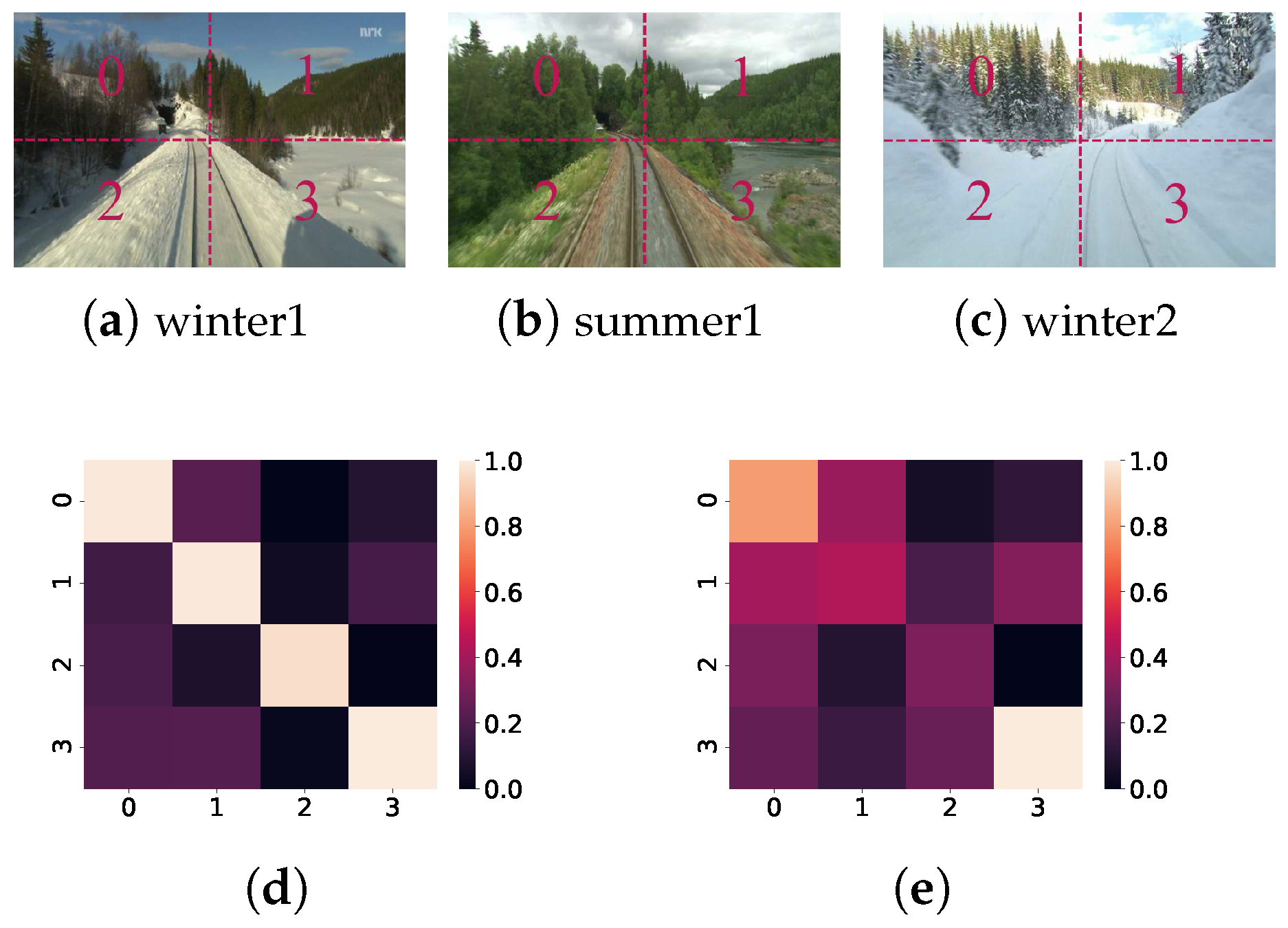
3.2. Similarity Measurement
Adaptive Parameter Weighting
3.3. Training
4. Evaluation and Analysis
4.1. Datasets
4.2. Evaluation Metrics
4.3. Experimental Results
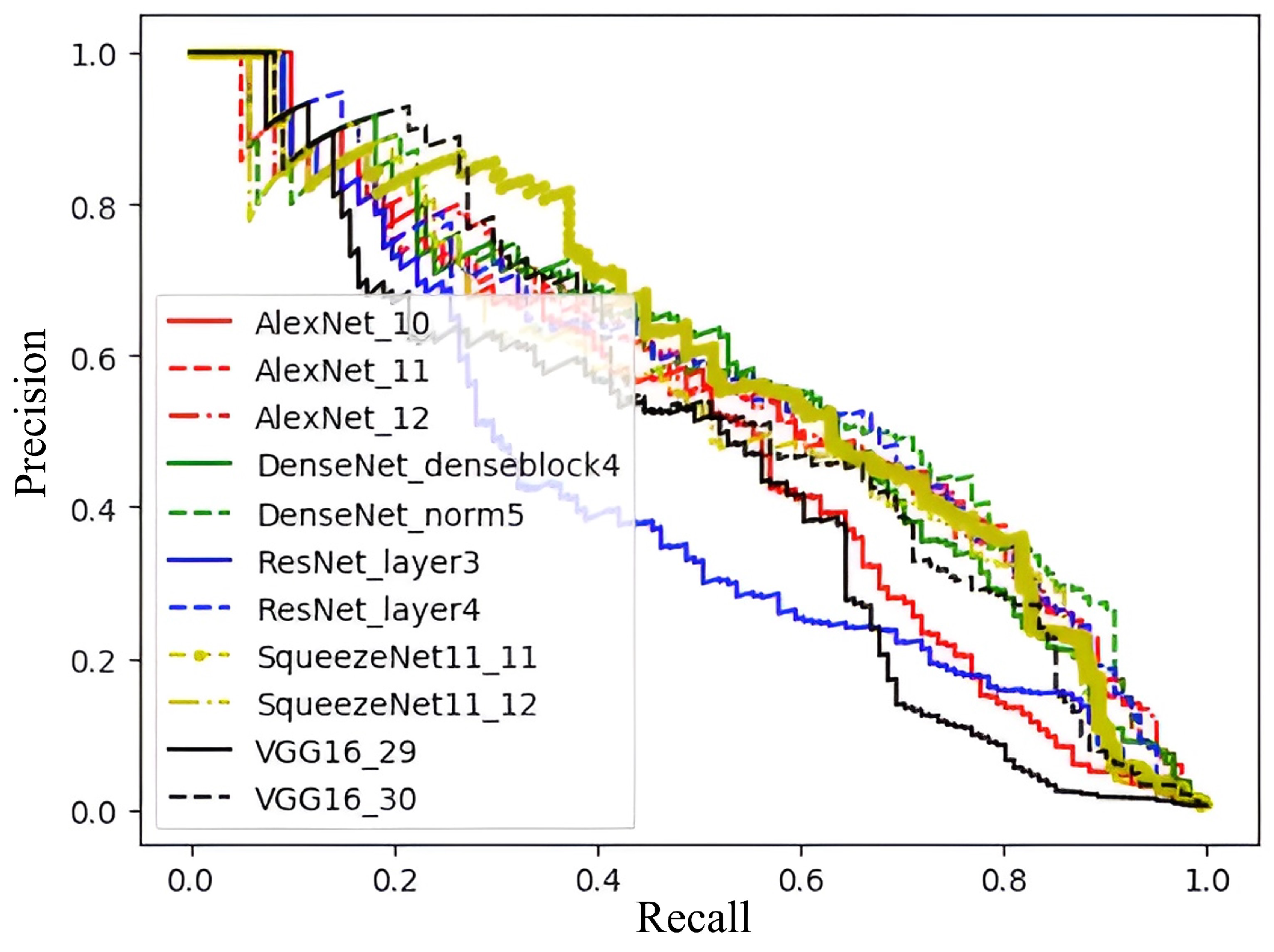
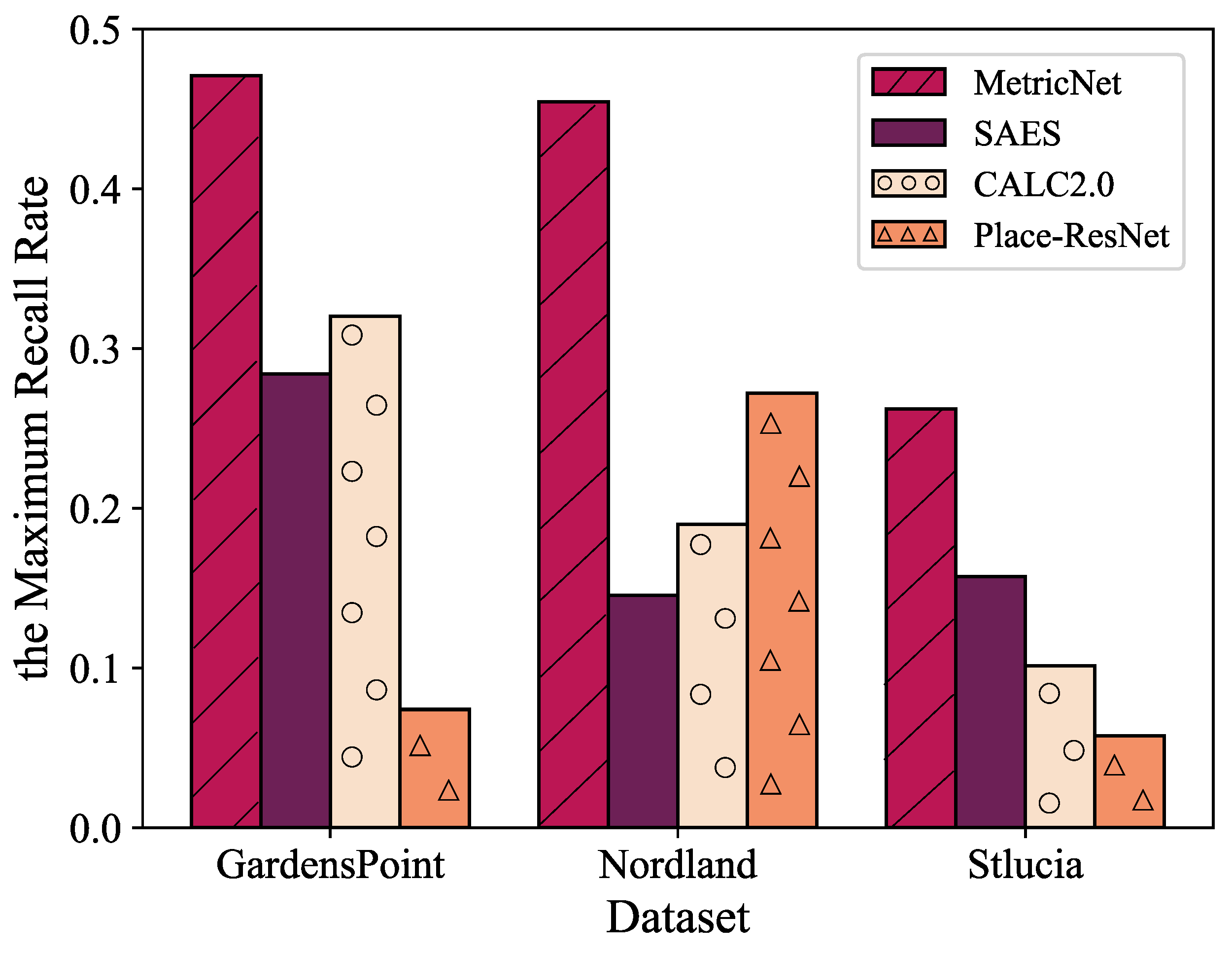
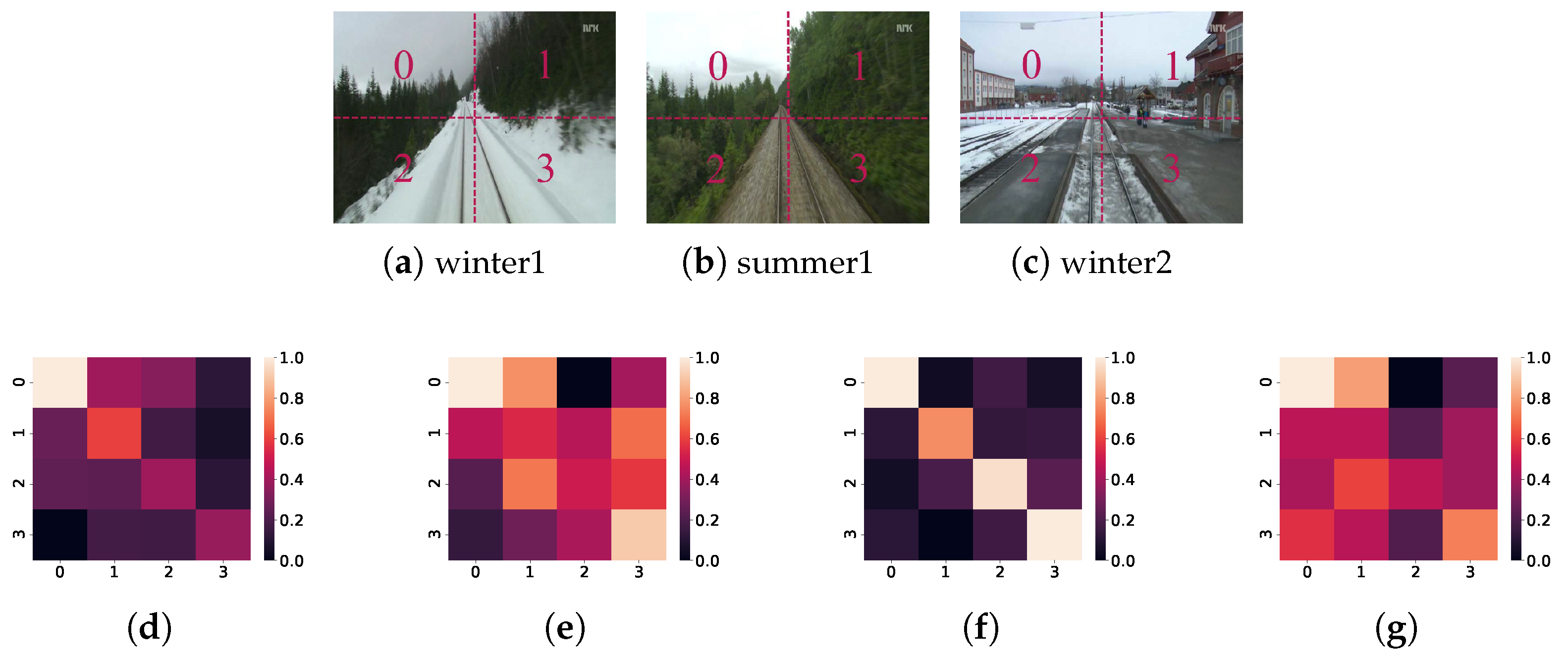
4.3.1. Qualitative and Quantitative Comparisons
4.3.2. Evaluation of Feature Extraction Component
4.3.3. Evaluation of Similarity Measurement Component
4.3.4. Results for Distinct Viewpoint Variations
4.3.5. Application of Loop Closure Detection
4.3.6. Computational Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fuentes-Pacheco, J.; Ruiz-Ascencio, J.; Rendón-Mancha, J.M. Visual simultaneous localization and mapping: A survey. Artif. Intell. Rev. 2015, 43, 55–81. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Labbe, M.; Michaud, F. Appearance-based loop closure detection for online large-scale and long-term operation. IEEE Trans. Robot. 2013, 29, 734–745. [Google Scholar] [CrossRef]
- Csurka, G.; Dance, C.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. In Proceedings of the Workshop on Statistical Learning in Computer Vision, ECCV, Prague, Czech Republic, 11–14 May 2004; Volume 1, pp. 1–2. [Google Scholar]
- Milford, M.J.; Wyeth, G.F. SeqSLAM: Visual route-based navigation for sunny summer days and stormy winter nights. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, St. Paul, MN, USA, 14–18 May 2012; pp. 1643–1649. [Google Scholar]
- Hou, Y.; Zhang, H.; Zhou, S. Convolutional neural network-based image representation for visual loop closure detection. In Proceedings of the 2015 IEEE International Conference on Information and Automation, Lijiang, China, 8–10 August 2015; pp. 2238–2245. [Google Scholar]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. Brief: Binary robust independent elementary features. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 778–792. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Siam, S.M.; Zhang, H. Fast-SeqSLAM: A fast appearance based place recognition algorithm. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 5702–5708. [Google Scholar]
- Cummins, M.; Newman, P. FAB-MAP: Probabilistic localization and mapping in the space of appearance. Int. J. Robot. Res. 2008, 27, 647–665. [Google Scholar] [CrossRef]
- Jégou, H.; Douze, M.; Schmid, C.; Pérez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311. [Google Scholar]
- Gong, Y.; Lazebnik, S.; Gordo, A.; Perronnin, F. Iterative quantization: A procrustean approach to learning binary codes for large-scale image retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2916–2929. [Google Scholar] [CrossRef] [PubMed]
- Yu, F.; Kumar, S.; Gong, Y.; Chang, S.F. Circulant binary embedding. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 22–24 June 2014; pp. 946–954. [Google Scholar]
- Jiang, Q.Y.; Li, W.J. Scalable graph hashing with feature transformation. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- He, Y.; Chen, Y. A Unified Binary Embedding Framework for Image Retrieval. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–7. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Ma, J.; Zhao, J.; Jiang, J.; Zhou, H.; Guo, X. Locality preserving matching. Int. J. Comput. Vis. 2019, 127, 512–531. [Google Scholar] [CrossRef]
- Li, J.; Yang, B.; Yang, W.; Sun, C.; Xu, J. Subspace-based multi-view fusion for instance-level image retrieval. Vis. Comput. 2021, 37, 619–633. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1–9. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1452–1464. [Google Scholar] [CrossRef]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5297–5307. [Google Scholar]
- Liu, Y.; Li, Y.; Zhang, H.; Xiong, N. CAE-VLAD-Net: A Loop Closure Detection System for Mobile Robots Using Convolutional Auto-Encoders Network with VLAD. 2023. Available online: https://www.researchsquare.com/article/rs-2601576/v1 (accessed on 3 June 2024).
- An, S.; Zhu, H.; Wei, D.; Tsintotas, K.A.; Gasteratos, A. Fast and incremental loop closure detection with deep features and proximity graphs. J. Field Robot. 2022, 39, 473–493. [Google Scholar] [CrossRef]
- Yu, G.; Li, H.; Wang, Y.; Chen, P.; Zhou, B. A review on cooperative perception and control supported infrastructure-vehicle system. Green Energy Intell. Transp. 2022, 1, 100023. [Google Scholar] [CrossRef]
- Benbihi, A.; Arravechia, S.; Geist, M.; Pradalier, C. Image-based place recognition on bucolic environment across seasons from semantic edge description. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 3032–3038. [Google Scholar]
- Chen, Z.; Maffra, F.; Sa, I.; Chli, M. Only look once, mining distinctive landmarks from convnet for visual place recognition. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 9–16. [Google Scholar]
- Lu, F.; Chen, B.; Zhou, X.D.; Song, D. STA-VPR: Spatio-temporal alignment for visual place recognition. IEEE Robot. Autom. Lett. 2021, 6, 4297–4304. [Google Scholar] [CrossRef]
- Neubert, P.; Schubert, S.; Protzel, P. A neurologically inspired sequence processing model for mobile robot place recognition. IEEE Robot. Autom. Lett. 2019, 4, 3200–3207. [Google Scholar] [CrossRef]
- Huang, G.; Chen, A.; Gao, H.; Yang, P. SMCN: Simplified mini-column network for visual place recognition. J. Phys. Conf. Ser. 2021, 2024, 012032. [Google Scholar] [CrossRef]
- Liu, Y.; Xiang, R.; Zhang, Q.; Ren, Z.; Cheng, J. Loop closure detection based on improved hybrid deep learning architecture. In Proceedings of the 2019 IEEE International Conferences on Ubiquitous Computing & Communications (IUCC) and Data Science and Computational Intelligence (DSCI) and Smart Computing, Networking and Services (SmartCNS), Shenyang, China, 21–23 October 2019; pp. 312–317. [Google Scholar]
- Chen, B.; Yuan, D.; Liu, C.; Wu, Q. Loop closure detection based on multi-scale deep feature fusion. Appl. Sci. 2019, 9, 1120. [Google Scholar] [CrossRef]
- Zhao, C.; Ding, R.; Key, H.L. End-To-End Visual Place Recognition Based on Deep Metric Learning and Self-Adaptively Enhanced Similarity Metric. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 275–279. [Google Scholar]
- Merrill, N.; Huang, G. CALC2.0: Combining appearance, semantic and geometric information for robust and efficient visual loop closure. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Venetian Macao, Macau, 3–8 November 2019; pp. 4554–4561. [Google Scholar]
- Schubert, S.; Neubert, P.; Protzel, P. Unsupervised learning methods for visual place recognition in discretely and continuously changing environments. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 4372–4378. [Google Scholar]
- Osman, H.; Darwish, N.; Bayoumi, A. PlaceNet: A multi-scale semantic-aware model for visual loop closure detection. Eng. Appl. Artif. Intell. 2023, 119, 105797. [Google Scholar] [CrossRef]
- Arshad, S.; Kim, G.W. Role of deep learning in loop closure detection for visual and lidar slam: A survey. Sensors 2021, 21, 1243. [Google Scholar] [CrossRef]
- Gao, X.; Zhang, T. Unsupervised learning to detect loops using deep neural networks for visual SLAM system. Auton. Robot. 2017, 41, 1–18. [Google Scholar] [CrossRef]
- Balaska, V.; Bampis, L.; Kansizoglou, I.; Gasteratos, A. Enhancing satellite semantic maps with ground-level imagery. Robot. Auton. Syst. 2021, 139, 103760. [Google Scholar] [CrossRef]
- Jin, S.; Gao, Y.; Chen, L. Improved deep distance learning for visual loop closure detection in smart city. Peer-to-Peer Netw. Appl. 2020, 13, 1260–1271. [Google Scholar] [CrossRef]
- Garg, S.; Suenderhauf, N.; Milford, M. Semantic–geometric visual place recognition: A new perspective for reconciling opposing views. Int. J. Robot. Res. 2022, 41, 573–598. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Z.; Liu, X.J.; Qiao, F.; Wang, Y.; Xie, F.; Wei, Q.; Yang, Y. A DenseNet feature-based loop closure method for visual SLAM system. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; pp. 258–265. [Google Scholar]
- Kulis, B. Metric learning: A survey. Found. Trends® Mach. Learn. 2013, 5, 287–364. [Google Scholar] [CrossRef]
- Chen, Z.; Jacobson, A.; Sünderhauf, N.; Upcroft, B.; Liu, L.; Shen, C.; Reid, I.; Milford, M. Deep learning features at scale for visual place recognition. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3223–3230. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 1–12. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Glover, A. Day and night, left and right. Zenodo, 2014; 10. [Google Scholar] [CrossRef]
- Sünderhauf, N.; Neubert, P.; Protzel, P. Are we there yet? Challenging SeqSLAM on a 3000 km journey across all four seasons. In Proceedings of the Workshop on Long-Term Autonomy, IEEE International Conference on Robotics and Automation (ICRA), Karlsruhe, Germany, 6–10 May 2013; p. 2013. [Google Scholar]
- Glover, A.J.; Maddern, W.P.; Milford, M.J.; Wyeth, G.F. FAB-MAP+ RatSLAM: Appearance-based SLAM for multiple times of day. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–8 May 2010; pp. 3507–3512. [Google Scholar]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Caesar, H.; Uijlings, J.; Ferrari, V. Coco-stuff: Thing and stuff classes in context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1209–1218. [Google Scholar]
- Philbin, J.; Chum, O.; Isard, M.; Sivic, J.; Zisserman, A. Object retrieval with large vocabularies and fast spatial matching. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Philbin, J.; Chum, O.; Isard, M.; Sivic, J.; Zisserman, A. Lost in quantization: Improving particular object retrieval in large scale image databases. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Song, R.; Zhu, R.; Xiao, Z.; Yan, B. ContextAVO: Local context guided and refining poses for deep visual odometry. Neurocomputing 2023, 533, 86–103. [Google Scholar] [CrossRef]
- Kümmerle, R.; Grisetti, G.; Strasdat, H.; Konolige, K.; Burgard, W. G2o: A general framework for graph optimization. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3607–3613. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Type | OutputDim | Size | Stride |
|---|---|---|---|---|
| conv1 | Conv | (4,1) | ||
| pool1 | MaxPool | 2 | ||
| conv2 | Conv | (1,1) | ||
| pool2 | MaxPool | 2 | ||
| conv3 | Conv | (1,1) | ||
| conv4 | Conv | (1,1) | ||
| conv5 | Conv | (1,1) |
| Dataset | Image Resolution & Frequency | Image Type | Environment | Appearance Variation | Viewpoint Variation |
|---|---|---|---|---|---|
| Gardens Point [50] | 1920 × 1080, 30 Hz | RGB | Campus | Day-Night | Moderate |
| Nordland [51] | 1920 × 1080, 25 Hz | RGB | Train journey | Winter-Summer | Small |
| St. Lucia [52] | 640 × 480, 15 Hz | RGB | Suburban | Morning-Afternoon | Moderate |
| Algorithm | Dataset | ||
|---|---|---|---|
| Gardens Point | Nordland | St. Lucia | |
| SAES [35] | 0.6997 | 0.7162 | 0.7098 |
| CALC2.0 [36] | 0.7284 | 0.6348 | 0.5869 |
| Schubert et al. [37] | 0.6900 | 0.7500 | 0.6800 |
| Place-ResNet [23] | 0.3048 | 0.8209 | 0.6860 |
| NetVLAD [24] | 0.7433 | 0.5320 | 0.5660 |
| SeqSLAM [5] | 0.4300 | 0.7233 | 0.2267 |
| MCN [31] | 0.7400 | 0.8211 | 0.6241 |
| SMCN [32] | 0.6500 | 0.5300 | - |
| CAE-VLAD-Net [25] | 0.8400 | 0.7500 | - |
| Jin et al. [42] | 0.8380 | 0.7280 | - |
| Pairwise | 0.5320 | 0.6843 | 0.5781 |
| MetricNet_ | 0.7289 | 0.6389 | 0.6920 |
| MetricNet_ | 0.7793 | 0.8173 | 0.7422 |
| MetricNet | 0.7831 | 0.8458 | 0.7476 |
| Dataset | Algorithm | |||
|---|---|---|---|---|
| Euclidean | Cosine | AVE-SIMI | MetricNet | |
| Gardens Point | 0.4932 | 0.5663 | 0.5805 | 0.7831 |
| Nordland | 0.4638 | 0.4885 | 0.4736 | 0.8458 |
| St. Lucia | 0.3828 | 0.5205 | 0.5659 | 0.7476 |
| Algorithm | Dataset | |
|---|---|---|
| Oxford5K | Paris6K | |
| CBE [13] | 0.5829 | 0.6989 |
| SGH [14] | 0.4726 | 0.5647 |
| ITQ [12] | 0.6006 | 0.5980 |
| LPM [18] | 0.6065 | - |
| UBEF [15] | 0.6249 | 0.6642 |
| SMVF-CVT [19] | 0.6514 | 0.7281 |
| Proposed methods | ||
| MetricNet | 0.5908 | 0.5732 |
| MetricNet_3×3 | 0.6007 | 0.5767 |
| Algorithm | Processing Time(s) | ||
|---|---|---|---|
| Feature Extraction | Similarity Matrix Construction | Similarity Calculation | |
| SAES [35] | 0.0218 | 0.0065 | 0.0025 |
| MetricNet | 0.0282 | 0.0045 | 0.0020 |
| MetricNet_3×3 | 0.0282 | 0.0047 | 0.0021 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, Z.; Song, R.; Yang, H.; Li, Y.; Lin, J.; Xiao, Z.; Yan, B. Adaptive Feature Refinement and Weighted Similarity for Deep Loop Closure Detection in Appearance Variation. Appl. Sci. 2024, 14, 6276. https://doi.org/10.3390/app14146276
Peng Z, Song R, Yang H, Li Y, Lin J, Xiao Z, Yan B. Adaptive Feature Refinement and Weighted Similarity for Deep Loop Closure Detection in Appearance Variation. Applied Sciences. 2024; 14(14):6276. https://doi.org/10.3390/app14146276
Chicago/Turabian StylePeng, Zhuolin, Rujun Song, Hang Yang, Ying Li, Jiazhen Lin, Zhuoling Xiao, and Bo Yan. 2024. "Adaptive Feature Refinement and Weighted Similarity for Deep Loop Closure Detection in Appearance Variation" Applied Sciences 14, no. 14: 6276. https://doi.org/10.3390/app14146276
APA StylePeng, Z., Song, R., Yang, H., Li, Y., Lin, J., Xiao, Z., & Yan, B. (2024). Adaptive Feature Refinement and Weighted Similarity for Deep Loop Closure Detection in Appearance Variation. Applied Sciences, 14(14), 6276. https://doi.org/10.3390/app14146276