
Remote Sensing Image Change Detection Based on Deep Learning: Multi-Level Feature Cross-Fusion with 3D-Convolutional Neural Networks


Abstract
1. Introduction
- (1)
- This paper introduces a novel approach for remote sensing image change detection using 3D-CNNs and Multi-level Feature Cross-Fusion (MFCF). The method combines the temporal dynamics captured by 3D-CNNs with the merging of complementary information through Multi-level Feature Cross-Fusion to achieve accurate detection of changes in remote sensing images.
- (2)
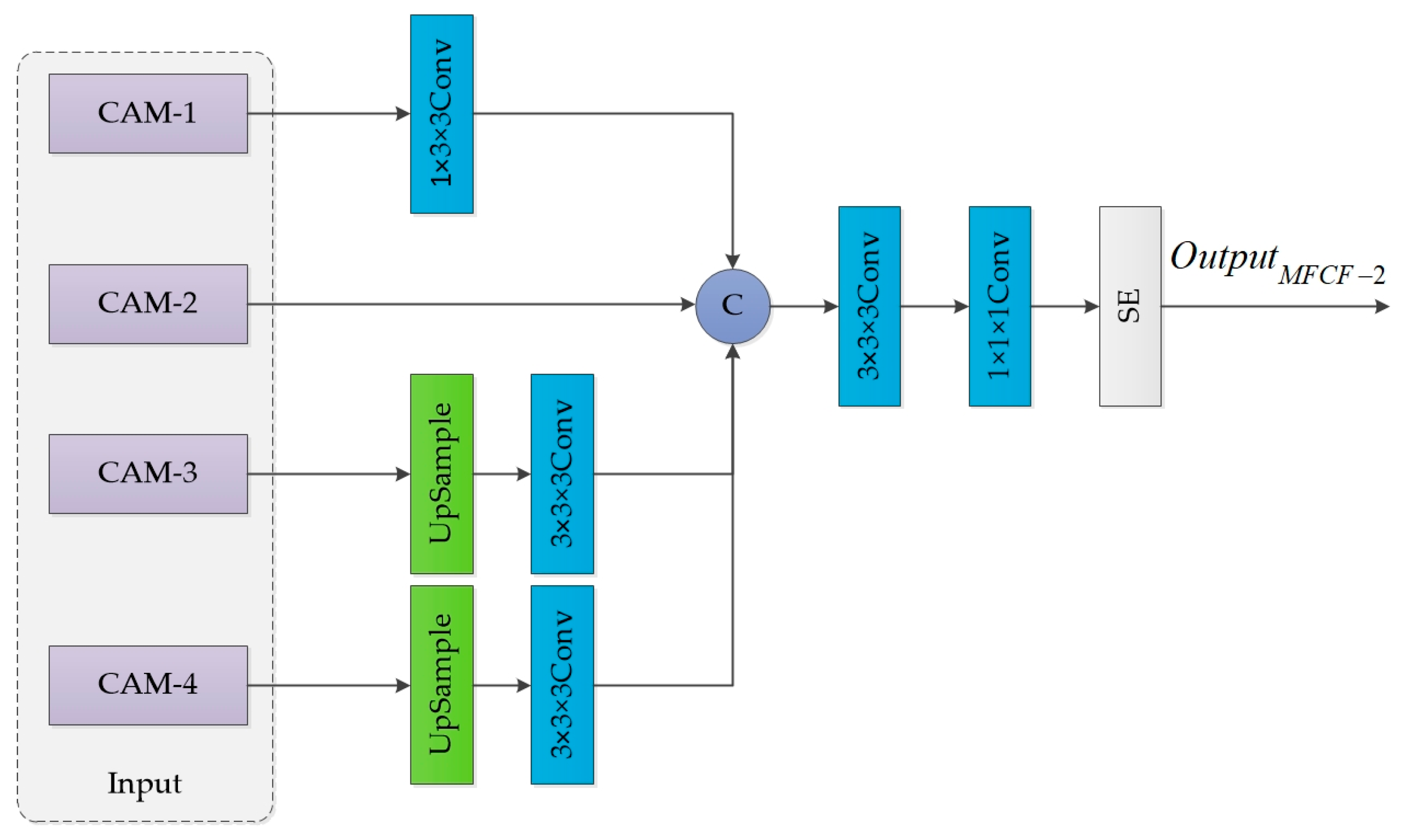
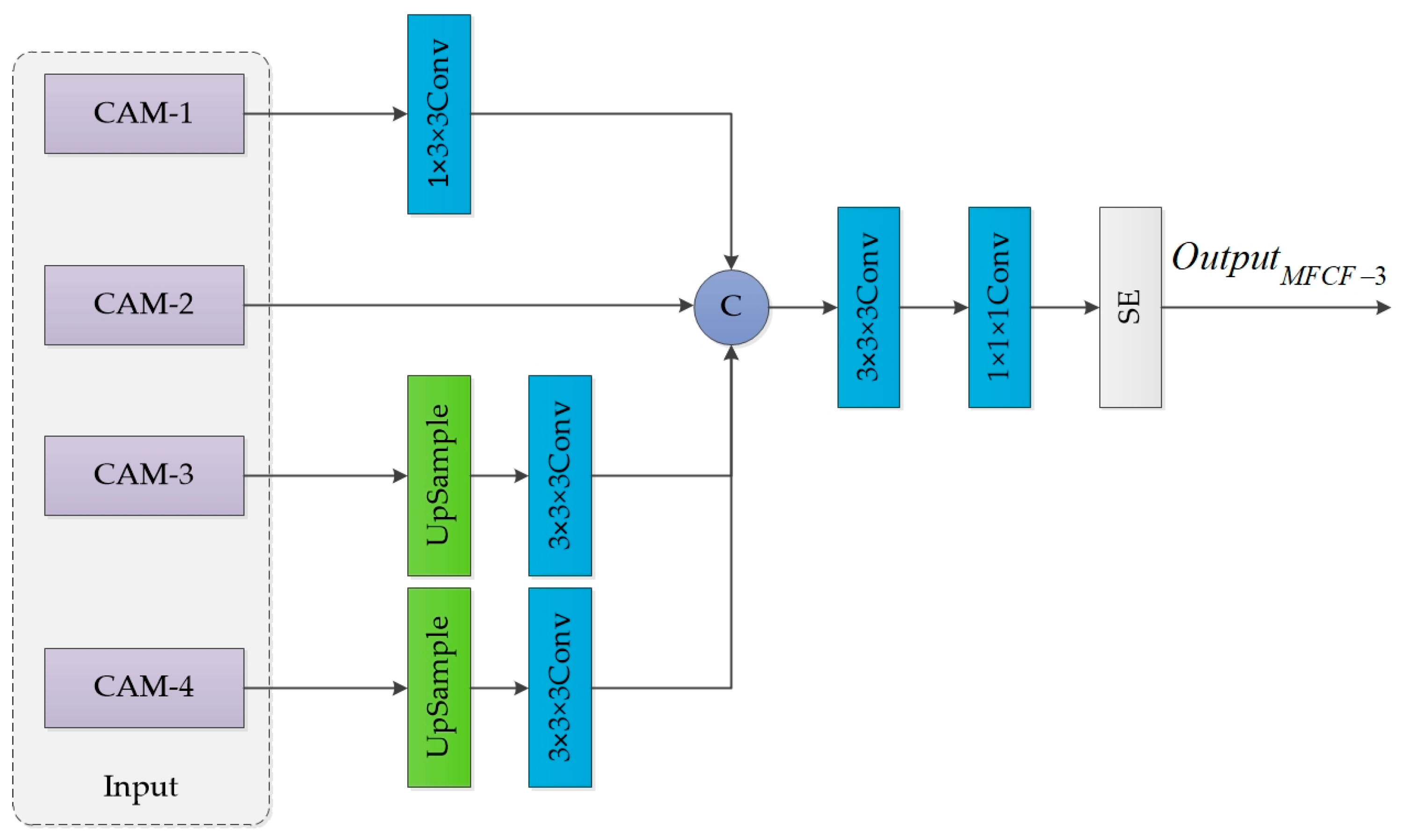
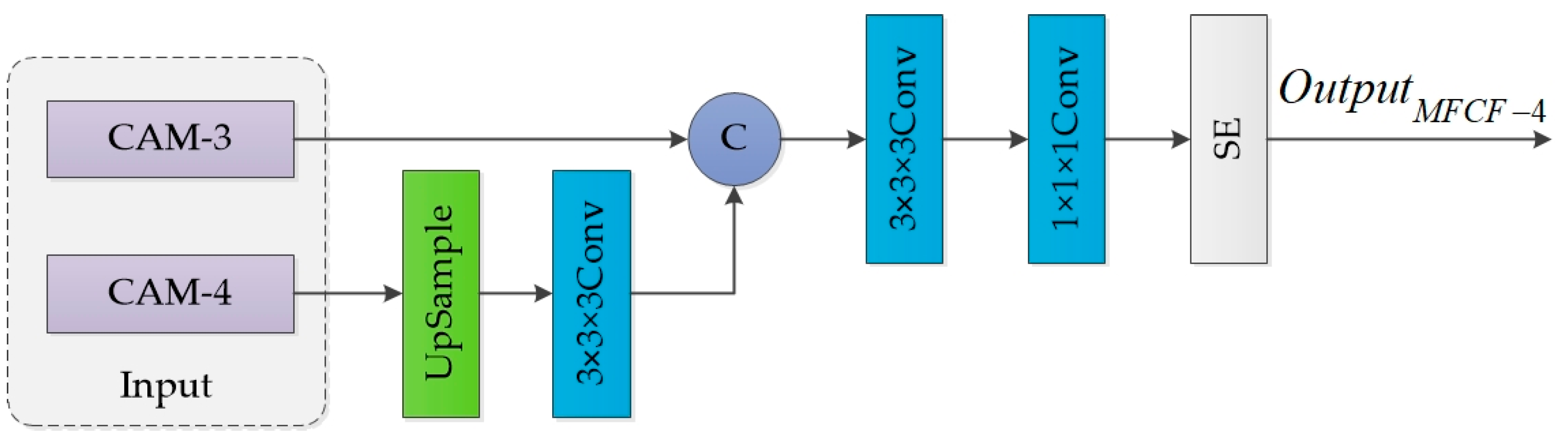
- In convolutional neural networks, MFCF is proposed to merge high and low-level feature maps. This allows for the incorporation of both spatial and semantic information, resulting in a more comprehensive set of feature information.
- (3)
- Add a channel attention mechanism (CAM) module to the convolutional neural network. CAM is a technique that highlights the most important regions in images or time series data that contribute to the model’s decision-making process. Integrating a CAM can enhance the interpretability and reliability of the model.
- (4)
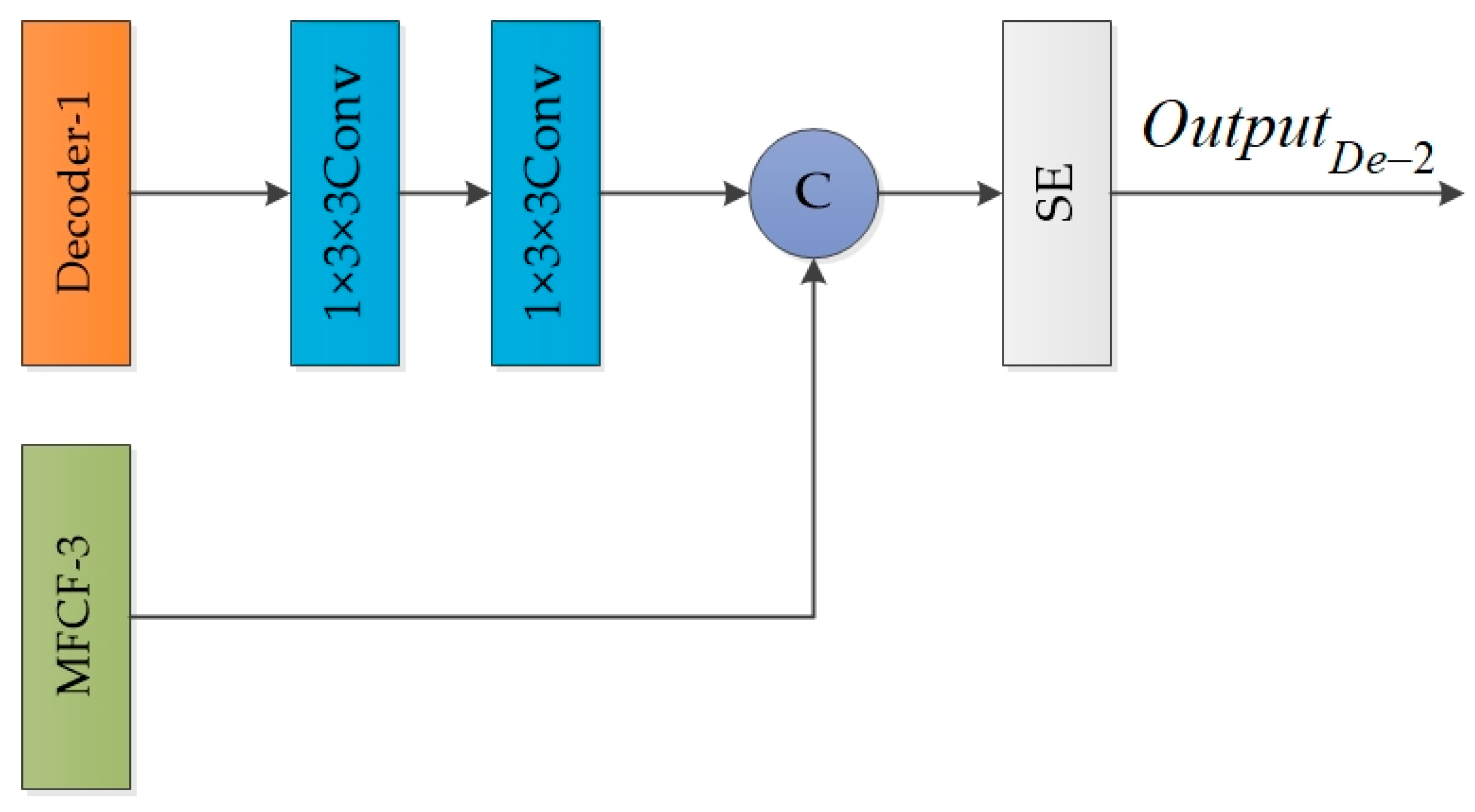
- This paper presents a novel two-stage decoder that incorporates two bilinear up-sampling and convolution blocks to process the feature map and then applies a Squeeze-and-Excitation (SE) attention mechanism for fine-tuning the feature map.
- (5)
- Our proposed method was validated on the LEVIR construction dataset (LEVIR-CD). The experimental results demonstrate that our network exhibits superior performance, showcasing higher accuracy and robustness.
2. Literature Review
3. Methods
3.1. Multi-Level Feature Cross-Fusion Module
3.2. Channel Attention Mechanism
3.3. Decoder Block
3.4. Mixed Loss Function
4. Results
4.1. Evaluation Index and Parameter Setting
4.1.1. Evaluation Index
4.1.2. Parameter Setting
4.2. Contrast Experiment
4.2.1. Quantitative Comparison
4.2.2. Qualitative Comparison
4.3. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Abbreviations | Full form |
| CD | Change Detection |
| CNNs | Convolutional Neural Networks |
| MFCF | Multi-Level Feature Cross-Fusion |
| CAM | Channel Attention Mechanism |
| 3D-CNNs | 3D Convolutional Neural Network |
| SE | Squeeze-and-Excitation |
| TC | Temporal Concatenation |
| BCE | Binary Cross-Entropy |
| DICE | Sørensen–Dice |
| VHR | Very High-Resolution |
| GE | Google Earth |
| Pr | Precision |
| IOU | Intersection Over Union |
| 1FN | False Negative |
| TP | True Positive |
| FP | False Positive |
| Re | Recall |
| De | Decoder |
References
- Hegazy, I.R.; Kaloop, M.R. Monitoring urban growth and land use change detection with GIS and remote sensing techniques in Daqahlia governorate Egypt. Int. J. Sustain. Built Environ. 2015, 4, 117–124. [Google Scholar] [CrossRef]
- Paul, F.; Winsvold, S.H.; Kääb, A.; Nagler, T.; Schwaizer, G.J.R.S. Glacier remote sensing using Sentinel-2. Part II: Mapping glacier extents and surface facies, and comparison to Landsat 8. Remote Sens. 2016, 8, 575. [Google Scholar] [CrossRef]
- Yang, B.; Qin, L.; Liu, J.Q.; Liu, X.X. IRCNN: An Irregular-Time-Distanced Recurrent Convolutional Neural Network for Change Detection in Satellite Time Series. IEEE Geosci. Remote Sens. Lett. 2022, 19, 2503905. [Google Scholar] [CrossRef]
- Qu, J.H.; Hou, S.X.; Dong, W.Q.; Li, Y.S.; Xie, W.Y. A Multilevel Encoder-Decoder Attention Network for Change Detection in Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5518113. [Google Scholar] [CrossRef]
- Xu, X.T.; Li, J.J.; Chen, Z. TCIANet: Transformer-Based Context Information Aggregation Network for Remote Sensing Image Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1951–1971. [Google Scholar] [CrossRef]
- Yang, X.; Luo, H.C.; Wu, Y.H.; Gao, Y.; Liao, C.Y.; Cheng, K.T. Reactive obstacle avoidance of monocular quadrotors with online adapted depth prediction network. Neurocomputing 2019, 325, 142–158. [Google Scholar] [CrossRef]
- Wang, G.H.; Li, B.; Zhang, T.; Zhang, S.B. A Network Combining a Transformer and a Convolutional Neural Network for Remote Sensing Image Change Detection. Remote Sens. 2022, 14, 2228. [Google Scholar] [CrossRef]
- Shi, Z.S.; Cao, L.J.; Guan, C.; Zheng, H.Y.; Gu, Z.R.; Yu, Z.B.; Zheng, B. Learning Attention-Enhanced Spatiotemporal Representation for Action Recognition. IEEE Access 2020, 8, 16785–16794. [Google Scholar] [CrossRef]
- Arif, S.; Wang, J.; Ul Hassan, T.; Fei, Z.J.F.I. 3D-CNNs-based fused feature maps with LSTM applied to action recognition. Future Internet 2019, 11, 42. [Google Scholar] [CrossRef]
- Tu, J.H.; Liu, M.Y.; Liu, H. Skeleton-based human action recognition using spatial temporal 3D convolutional neural networks. In Proceedings of the IEEE International Conference on Multimedia and Expo (IEEE ICME), San Diego, CA, USA, 23–27 July 2018. [Google Scholar]
- Ye, Y.X.; Wang, M.M.; Zhou, L.; Lei, G.Y.; Fan, J.W.; Qin, Y. Adjacent-Level Feature Cross-Fusion With 3-D CNN for Remote Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5618214. [Google Scholar] [CrossRef]
- Ma, C.; Zhang, Y.T.; Guo, J.Y.; Zhou, G.Y.; Geng, X.R. FusionHeightNet: A Multi-Level Cross-Fusion Method from Multi-Source Remote Sensing Images for Urban Building Height Estimation. Remote Sens. 2024, 16, 958. [Google Scholar] [CrossRef]
- Ke, Q.T.; Zhang, P. MCCRNet: A Multi-Level Change Contextual Refinement Network for Remote Sensing Image Change Detection. Isprs Int. J. Geo-Inf. 2021, 10, 591. [Google Scholar] [CrossRef]
- Liu, H.; Yang, G.Q.; Deng, F.L.; Qian, Y.R.; Fan, Y.Y. MCBAM-GAN: The Gan Spatiotemporal Fusion Model Based on Multiscale and CBAM for Remote Sensing Images. Remote Sens. 2023, 15, 1583. [Google Scholar] [CrossRef]
- Liu, Y.; Petillot, Y.; Lane, D.; Wang, S. Global Localization with Object-Level Semantics and Topology. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4909–4915. [Google Scholar]
- Wang, L.J.; Li, H.J. HMCNet: Hybrid Efficient Remote Sensing Images Change Detection Network Based on Cross-Axis Attention MLP and CNN. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5236514. [Google Scholar] [CrossRef]
- Tokarczyk, P.; Wegner, J.D.; Walk, S.; Schindler, K. Beyond hand-crafted features in remote sensing. In Proceedings of the International-Society-for-Photogrammetry-and-Remote-Sensing Workshop on 3D Virtual City Modeling (VCM), Regina, SK, Canada, 28 May 2013; pp. 35–40. [Google Scholar]
- Khelifi, L.; Mignotte, M. Deep Learning for Change Detection in Remote Sensing Images: Comprehensive Review and Meta-Analysis. IEEE Access 2020, 8, 126385–126400. [Google Scholar] [CrossRef]
- Varghese, A.; Gubbi, J.; Ramaswamy, A.; Balamuralidhar, P. ChangeNet: A Deep Learning Architecture for Visual Change Detection. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 129–145. [Google Scholar]
- Li, Y.; Peng, C.; Chen, Y.; Jiao, L.; Zhou, L.; Shang, R.J.I.T.o.G.; Sensing, R. A deep learning method for change detection in synthetic aperture radar images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5751–5763. [Google Scholar] [CrossRef]
- Zhang, M.; Shi, W.J.I.T.o.G.; Sensing, R. A feature difference convolutional neural network-based change detection method. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7232–7246. [Google Scholar] [CrossRef]
- Gong, M.; Zhao, J.; Liu, J.; Miao, Q.; Jiao, L. Change detection in synthetic aperture radar images based on deep neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 125–138. [Google Scholar] [CrossRef]
- Zhan, Y.; Fu, K.; Yan, M.L.; Sun, X.; Wang, H.Q.; Qiu, X.S. Change Detection Based on Deep Siamese Convolutional Network for Optical Aerial Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1845–1849. [Google Scholar] [CrossRef]
- Ghosh, R.; Bovolo, F. TransSounder: A Hybrid TransUNet-TransFuse Architectural Framework for Semantic Segmentation of Radar Sounder Data. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4510013. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.L.; Li, J.X.; Zhou, K.X.; Ma, K. Feature cross-fusion block net for accurate and efficient object detection. J. Electron. Imaging 2021, 30, 013011. [Google Scholar] [CrossRef]
- Xu, R.D.; Tao, Y.T.; Lu, Z.Y.; Zhong, Y.F. Attention-Mechanism-Containing Neural Networks for High-Resolution Remote Sensing Image Classification. Remote Sens. 2018, 10, 1602. [Google Scholar] [CrossRef]
- Hara, K.; Kataoka, H.; Satoh, Y. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6546–6555. [Google Scholar]
- Su, J.; Liu, Z.; Zhang, J.; Sheng, V.S.; Song, Y.Q.; Zhu, Y.; Liu, Y. DV-Net: Accurate liver vessel segmentation via dense connection model with D-BCE loss function. Knowl.-Based Syst. 2021, 232, 107471. [Google Scholar] [CrossRef]
- Li, X.Y.; Sun, X.F.; Meng, Y.X.; Liang, J.J.; Wu, F.; Li, J.W.; Assoc Computat, L. Dice Loss for Data-imbalanced NLP Tasks. In Proceedings of the 58th Annual Meeting of the Association-for-Computational-Linguistics (ACL), Electr Network, Online, 5–10 July 2020; pp. 465–476. [Google Scholar]
- Chen, H.; Shi, Z.W. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully Convolutional Siamese Networks For Change Detection. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Fang, S.; Li, K.Y.; Shao, J.Y.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8007805. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5607514. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Re | F1 | IOU |
|---|---|---|---|
| FC-Siam-conc [32] | 81.64 | 77.49 | 64.48 |
| SNUNet-CD [33] | 88.63 | 87.83 | 75.84 |
| BIT [34] | 88.59 | 89.52 | 80.35 |
| Ours | 89.99 | 90.80 | 83.15 |
| Network Setting | LEVIR-CD | |||
|---|---|---|---|---|
| MFCF | De | F1 | IOU | |
| Base | × | × | 89.85 | 81.79 |
| Base + MFCF | √ | × | 90.07 | 81.94 |
| Base + De | × | √ | 90.80 | 83.29 |
| Our | √ | √ | 90.91 | 83.35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, S.; Tao, C.; Zhang, G.; Xuan, Y.; Wang, X. Remote Sensing Image Change Detection Based on Deep Learning: Multi-Level Feature Cross-Fusion with 3D-Convolutional Neural Networks. Appl. Sci. 2024, 14, 6269. https://doi.org/10.3390/app14146269
Yu S, Tao C, Zhang G, Xuan Y, Wang X. Remote Sensing Image Change Detection Based on Deep Learning: Multi-Level Feature Cross-Fusion with 3D-Convolutional Neural Networks. Applied Sciences. 2024; 14(14):6269. https://doi.org/10.3390/app14146269
Chicago/Turabian StyleYu, Sibo, Chen Tao, Guang Zhang, Yubo Xuan, and Xiaodong Wang. 2024. "Remote Sensing Image Change Detection Based on Deep Learning: Multi-Level Feature Cross-Fusion with 3D-Convolutional Neural Networks" Applied Sciences 14, no. 14: 6269. https://doi.org/10.3390/app14146269
APA StyleYu, S., Tao, C., Zhang, G., Xuan, Y., & Wang, X. (2024). Remote Sensing Image Change Detection Based on Deep Learning: Multi-Level Feature Cross-Fusion with 3D-Convolutional Neural Networks. Applied Sciences, 14(14), 6269. https://doi.org/10.3390/app14146269