1. Introduction
Advancements in cloud service technology and mobile communication terminals have led to an increased upload of multimedia data to cloud servers for storage via the Industrial Internet of Things (IIoT) [
1]. This trend amplifies security risks concerning users’ private data. In response to this, the technology of reversible data hiding in encrypted images (RDH-EI) [
2,
3] has been developed to enhance data security in cloud environments, and facilitate the authentication and management of encrypted data. This technique allows for the embedding of secret data, such as check digits, into encrypted images while maintaining the privacy of the embedded secrets. Moreover, it enables receivers to fully recover the image and extract the secret data accurately.
The transmission of information in cloud service environments is intricate and diverse. Current RDH-EI algorithms are typically categorized based on their suitability for single-user or multi-user scenarios. Single-user-oriented algorithms fall under three main classes: vacating room after encryption (VRAE) [
4,
5], vacating room before encryption (VRBE) [
6,
7], and vacating room in encryption (VRIE) [
8,
9]. While most VRAE methods [
10] employ lightweight ciphers to preserve pixel correlations when encrypting the carrier image, it has been shown that these ciphers, such as group substitution, are vulnerable under ciphertext-only attacks, as highlighted by Qu et al. [
11]. To mitigate these vulnerabilities, some embedding algorithms based on homomorphic encryption [
12,
13] have been proposed. However, VRAE algorithms often face limitations in embedding capacity due to the high entropy of ciphertext state data. On the other hand, VRBE algorithms [
14,
15] directly utilize correlations between plaintext pixels to embed additional redundancy space. For instance, Wang et al. [
16] employed Huffman coding to compress the most significant bits (MSBs) of image pixels, creating embeddable space and maintaining high-quality image recovery [
17]. Zhang et al.’s algorithm [
18] enhances embedding capacity through weighted prediction techniques, although it remains constrained by image texture features. Breaking through these limitations, VRIE algorithms, like that of Wu et al. [
9], use random number substitution to embed secret data during the encryption process. While these algorithms enable covert communication, they are typically limited to single data hiders, falling short in meeting the multi-user data storage demands and thereby limiting their practicality in IIoT scenarios.
In 2020, Chen et al. introduced a hiding model based on secret sharing and multi-party embedding [
19], distributing secret shares among various data hiders to achieve independent embedding. Zhao et al.’s algorithm adeptly conceals communication activities during multi-party data exchanges [
20]. Xiong et al. [
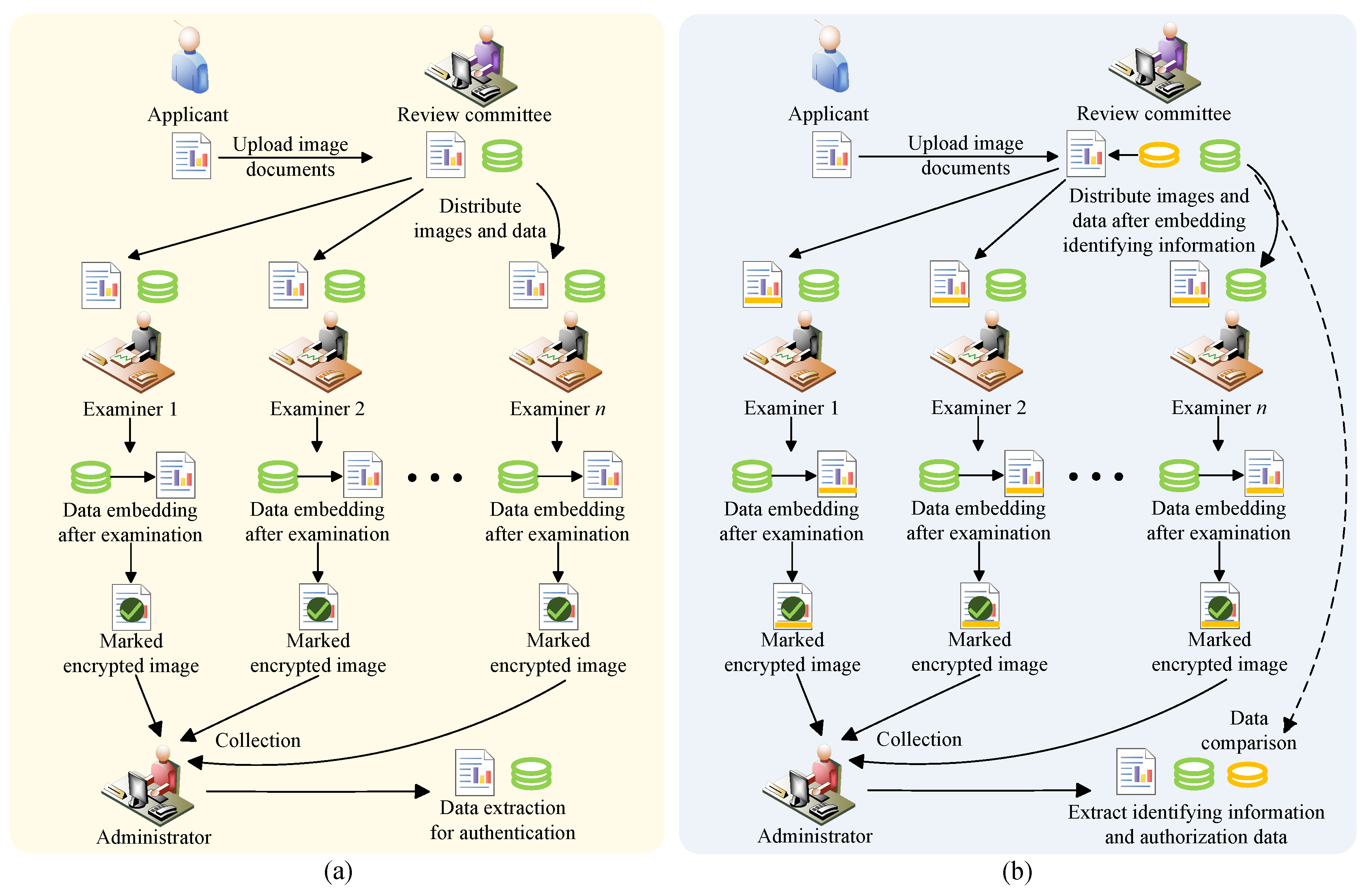
21] elaborated on the application of the RDH-EI algorithm in the context of the double-blind Inter Partes Review (IPR) scenario, as depicted in
Figure 1a. The applicant entrusts the review committee with an encrypted image representing the patent file, which subsequently forwards the patent file and authorization data to each examiner. If the reviewer approves the patent, authorization data will be embedded into encrypted images to produce marked encrypted images. When the administrator extracts sufficient authorization data from the collected marked encrypted images, the patent passes the review. In 2022, Hua et al. [
22] proposed an RDH-EI algorithm based on feedback secret sharing, enhancing the security of existing algorithms. Hua et al. [
23] also proposed an RDH-EI scheme based on matrix-based secret sharing (MSS), enabling the complete restoration of the carrier image. In 2023, Yu et al. [
24] proposed an RDH-EI scheme based on ciphertext sharing and hybrid coding to enhance embedding capacity. Hua et al. [
25] also introduced a high-capacity RDH-EI scheme based on preprocessing-free secret sharing. However, secret sharing may reduce pixel correlation in the sub-secret image, resulting in wasted redundant space and potential security vulnerabilities. In cases of tampering during transmission, these algorithms may struggle to effectively detect such behavior due to the lack of a reference for confirmation, as both tampered and legitimate marked encrypted images appear visually indistinguishable as noisy images. This limitation compromises the ability to verify the authenticity of transmitted data in practical applications, posing security risks.
To address this issue, this paper proposes an RDH-EI algorithm based on adaptive median edge detection (AMED) and MSS secret sharing for distributed environments. Firstly, we introduce the innovative AMED pixel prediction technology, which achieves high prediction accuracy. Leveraging AMED technology and Huffman coding, we predict and recode the original image to generate the transitional image. Subsequently, using (
r,
n)-threshold MSS secret sharing in the
domain, the transitional image is fragmented into
n encrypted images, with identifying information embedded. The encrypted images are then distributed to individual data hiders, who independently embed secret data to acquire
n marked encrypted images. Upon collecting
r marked encrypted images, the original image can be reconstructed using the corresponding key, and the embedded data can be extracted. Discrepancies in the embedded identifying information before and after embedding can reveal tampering attacks. The algorithm is illustrated in the context of the IPR scenario in
Figure 1b. Experimental results indicate a marked improvement in the embedding capacity of the proposed algorithm compared to the current algorithms [
5,
14,
21,
22,
23,
24]. Furthermore, the algorithm also possesses resilience, allowing up to
fault points to occur.
Table 1 outlines the limitations of previous algorithms and the solutions provided by the algorithm presented in this paper.
The main contributions of this paper’s algorithm are as follows:
Introduction of the innovative AMED prediction technique, achieving superior prediction accuracy and surpassing the limitations of fixed predictors in existing MED techniques [
15,
26]. This enhancement significantly boosts the embedding capability of the algorithm.
This article introduces an RDH-EI algorithm based on AMED prediction and MSS secret sharing, innovatively executing image segmentation within the
domain. Compared to existing algorithms [
23], the proposed method does not require additional data to store overflow pixels and avoids complex preprocessing, effectively reducing the usage of embedding space.
The creative design of identifying information effectively enhances the monitoring of the security of the transmission environment and ensures the authenticity of the data.
In comparison with existing algorithms, the algorithm proposed in this paper not only guarantees reversibility but also effectively increases embedding rates, thereby enhancing its practicality.
The subsequent sections of this paper unfold as follows:
Section 2 elaborates on key technologies related to the algorithm,
Section 3 specifies implementation details,
Section 4 showcases experimental results and data analyses, and
Section 5 concludes with a summary and outlook.
3. The Proposed Method
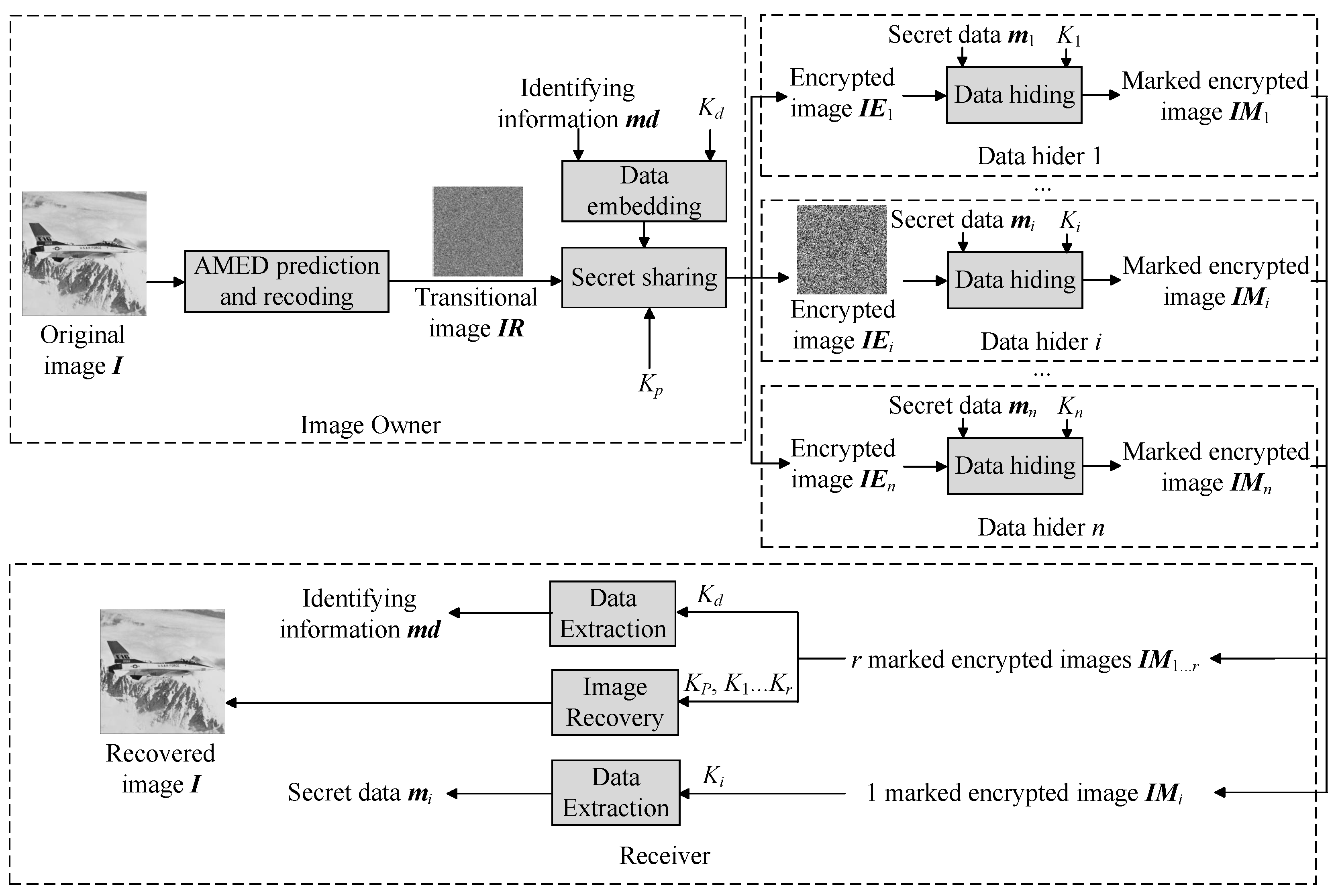
This study proposes an RDH-EI algorithm with a substantial embedding capacity, leveraging the correlation between image pixels and the encryption features of MSS. The algorithm’s framework is illustrated in
Figure 3. Initially, the image owner preprocesses the original image
I using the AMED pixel prediction technique, resulting in the transitional image
IR. Subsequently, the image is shared using an
-threshold MSS, with the concurrent embedding of identifying information. Subsequent to this stage, the resulting
n encrypted images
are distributed to individual data hiders for autonomous embedding, yielding
n marked encrypted images
. The recipient can leverage the key to extract the embedded secret data from each marked encrypted image individually or fully reconstruct the image to accurately extract both the secret data and identifying information by collecting any
r marked encrypted images. Additionally, the recipient can detect tampering attempts in the transmission environment by comparing the identifying information pre- and post-embedding. The algorithm further utilizes the threshold characteristic of secret sharing to enhance data disaster resistance, accommodating up to
failure points.
3.1. AMED Prediction and Recoding
3.1.1. Block-Level Pixel Prediction
To enhance the embedding capacity by leveraging pixel correlation, we employ direct pixel prediction on plaintext images. Initially, the carrier image
I with dimensions
is partitioned into pixel blocks of size
, where
, resulting in
blocks. The block sizes
BM and
BN are determined by the following equation:
To predict all pixels after block segmentation, we extend the pixel blocks as follows, so that edge pixels of the blocks also have reference pixels:
When the pixel block contains the image pixel , the block is not expanded.
When the pixel block does not contain the image pixel but contains the pixel with , we add a column of random pixels to the left side of the pixel block, expanding it to a pixel block of size .
When the pixel block does not contain the image pixel but contains the pixel with , we add a row of random pixels on top of the pixel block, expanding it to a pixel block of size .
Other cases: We add a column and a row of random pixels to the left and above the remaining pixel block, respectively, expanding it to a pixel block of size .
The target pixel
in the
z-th pixel chunk is predicted using the AMED predictor to obtain the predicted value
, as shown in Equation (
6). Initially, the adaptive parameters
,
, and
are determined, with their experimental values set to
,
, and
. These adaptive parameters remain constant when predicting pixels within the same pixel chunk.
The pixel value
is converted into an eight-bit binary string:
Here,
represents the value in the
k-th bit plane, progressing from the highest bit, with
. Similarly, transforming the predicted pixel value yields
, where
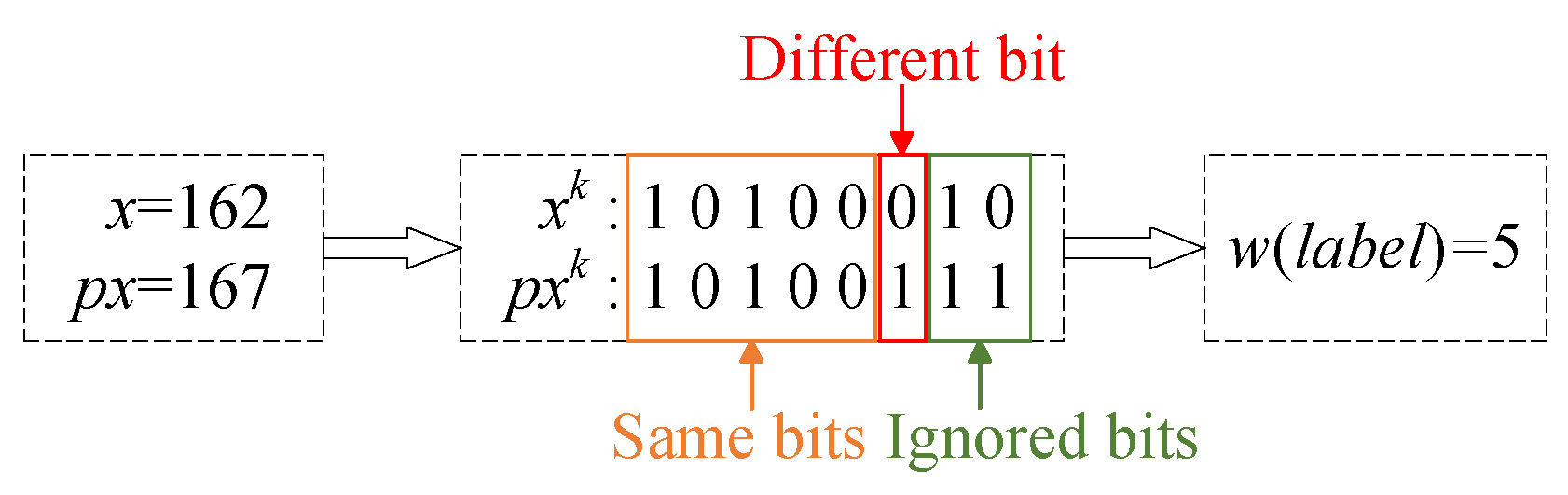
k = 1, 2, …, 8. We compare
to
bit by bit, starting from the most significant bit (MSB), to determine the number of consecutive identical bits and assign this as the label value
until a discrepancy is detected. The label value
ranges from 0 to 8, inclusive, where
indicates
;
indicates
. For instance, considering the target pixel
and the predicted value
. Comparing them reveals that the first five bits are identical, while the sixth bit differs, leading to a labeled value of
w equal to 5. This process is illustrated in
Figure 4:
AMED prediction is applied to all pixels within the pixel block, excluding those in the initial row and column, resulting in a total of tagged values and forming the tag map for the pixel block.
3.1.2. Calculating the Load Capacity for Secret Data of Pixel Blocks
We utilize Huffman coding to compress the labeled value
w. There are nine potential values of
w, thus necessitating nine distinct Huffman codes to represent these variations. Specifically, the codes 00, 01, 100, 101, 1100, 1101, 1110, 11110, 11111 are assigned to represent the nine encodings. The frequency of each label value within the pixel block is calculated, allowing for the use of shorter codes for labels with higher occurrence probabilities and longer codes for those with lower probabilities. Consequently, “0” is assigned to the label with the highest frequency, while “11111” corresponds to the least frequent label. For example, in a
pixel block of a MAN image, following the successful prediction of pixel values, each pixel’s label is determined and encoded using Huffman coding. The statistical results illustrating the frequency distribution of label values within the block are provided in
Table 2 below.
Taking label
as an illustration, based on the predicted pixel, we can deduce the highest six bits of the target pixel, enabling the substitution of these six bits with secret data for embedding. However, it remains imperative to record the label
w utilizing the encoding “01”. Thus, for a solitary pixel possessing a label value of 5, its capacity to accommodate payload information can be expressed as
. The load capacity of all pixels is computed according to Equation (
8), yielding the data in column 6 of
Table 2.
Next, the load capacity of all pixels within the pixel block, excluding the first row and the first column, is computed to determine the pixel block’s load capacity, denoted as .
During the pixel prediction process, with the adaptive parameters fixed as , , and , the load capacity of the pixel block, represented as , is determined. The optimal parameter combination is identified through adaptive training. By traversing through all feasible values of , , and , where the parameter values are constrained to integers from −3 to 4 (i.e., , , resulting in a total of 24 potential combinations for the adaptive parameters , , and (i.e., possibilities). Consequently, there are 24 distinct values of for a pixel. Once these data reach their maximum value, the corresponding adaptive parameters are recorded as , , and . At this stage, the accuracy of the AMED median predictor is optimized, thereby maximizing the loading capacity of the image pixel block. The label value is then designated as the final label for the pixels within the pixel block.
The method described above is applied to dynamically predict each pixel block of the original image, resulting in the derivation of labels for all pixels in the original image except those in the first row and column. This dataset is referred to as W. Subsequently, we document the optimal adaptive parameters that maximize the loading capacity.
3.1.3. Recoding
Initially, 3 bits are allocated to record the chunk size B. In the experiments outlined in this paper, B takes on values of 512, 256, 128, 64, and 32, which will be thoroughly elaborated on in the experimental section. Following this, bits are utilized to document the adaptive parameter ARP for all pixel blocks within the image, 32 bits are utilized to to record the Huffman coding rule (HCR). We convert W into a binary sequence WS, allocating an additional 22 bits to record the length of WS as . Finally, we concatenate , B, ARP, HCR, and WS in sequence with the pixel values of the first row and the first column of the original image to generate an edge information object identified as O.
Moving forward, we now proceed to integrate the edge information. Initially, we replace the pixel values of the first row and first column of the encrypted image with the first
bits of the edge information
O. Subsequently, leveraging the pixel label as a reference, we embed the remaining edge information into the encrypted image through bit substitution. This embedding takes place within the highest
MSB of the unreplaced pixels in the encrypted image. The embedding formula is detailed as follows:
The pixel value post-information embedding is represented as
, where
denotes the auxiliary information that can be embedded into the current pixel, and
l signifies the load capacity of a single pixel. Following the embedding of all edge information, random noise is generated and embedded into the remaining positions post-edge information, as described in Equation (
9), resulting in the transitional image denoted as
IR.
3.2. Image Sharing and Identifying Information Embedding
In this study, the algorithm opts for to establish a finite field for executing secret sharing of the image within the domain. The image is divided into three parts: part A contains pixels with data WL, part B holds the remaining edge information, and part C encompasses the other pixels. For part B, a -threshold secret sharing scheme is exclusively employed. Initially, a sequence of coefficient matrices is generated based on the key , where LB represents the number of pixels in part B. For segmenting pixel values and embedding identifying information, 8() bits of data are extracted from the identifying information . After encryption with the identifying information hiding key , every 8 bits are converted into decimal numbers, resulting in the sequence .
Then, the sharing vector
= [
,
,
…,
is constructed, and the mapping
is generated by the key
, where
is the sub-secret of the previous pixel of pixel
,
k is the position index of the sub-secret in the vector
f,
. When
is the first pixel in part B,
is a random value. Calculate
with
,
from the following equation:
Determine
,
in the generated sequence of
Xs from the positional ordinal number of pixel
in the pixel of part B. Finally, we perform secret sharing according to the equation, and embed
ms:
Once all pixel values in part B have been shared, of the same identity k are aggregated to obtain n sub-secrets of part B. These are then combined with parts A and C to generate n encrypted images , which are distributed by the image owner to n data hiders.
3.3. Secret Data Hiding
As a data hider
, the secret data
is first encrypted using the data hiding key
to produce the encrypted data
. Subsequently, the partial edge information can be extracted from the first row and column of the encrypted image, containing parameters such as
,
B,
ARP, HCR with the partial
WS. By converting pixel values to 8-bit binary according to Equation (
7), based on the partial
WS, and referencing the HCR, the labeled values of the partial pixels can be determined, indicating the embedding positions of these pixels, specifically the high
bits of the pixel values. By iteratively extracting and processing the edge information, all embedded edge information can be obtained.
Then we divide the image
into part A, part
, and part C, and replace the pixel values of part C with
to complete the embedding operation to obtain the embedded image
, and then we perform the double encryption of scrambling encryption and XOR encryption to further improve the security of the embedded image. We first divide the image
into pixel blocks of size
, use the key
to generate a random number sequence, and then sort the random number sequence to obtain the index vector of the pixel blocks. Finally, the image blocks are scrambled according to the index vector to obtain the image
. Then, we perform XOR encryption on the image: generate an
random matrix
according to the key
, and encrypt the image
according to the following equation, finally obtaining marked encrypted images
:
The operation denoted by ⊕ corresponds to modulo 256 addition, with representing the position index where , .
3.4. Data Extraction and Image Recovery
Based on the possession of specific keys, the receiver can extract secret data from any marked encrypted image, or extract identifying data from r marked encrypted images and reconstruct the original image.
3.4.1. Secret Data Extraction
In the role of the recipient, the initial step involves employing the key to perform inverse scrambling and XOR decryption on the marked encrypted image , resulting in the recovery of the image . Subsequently, the receiver implements analogous procedures to those used during the secret data embedding phase to extract both the edge information and the encrypted data . Finally, decryption of is carried out with the key to unveil the secret data .
3.4.2. Image Recovery
The recipient independently conducts the aforementioned procedures on each of the r-marked encrypted images to isolate the portion from the images.
The identifiers for the data hiders are denoted as
,
,
…,
, respectively. Utilizing the key
, we generate
, and then select the
rows from the coefficient matrix
to form the matrix
. The inverse matrix
is then calculated using the following equation:
where
represents the accompanying matrix of
. Next, we utilize the
part of the
r embedded images
to decrypt and restore pixel
. Assuming pixels
,
,
…,
are utilized for decryption,
is obtained from the Equation (
14):
We conduct the recovery operation on all pixels to obtain the transitional image
IR. Subsequently, we replace the corresponding pixel values in image
IR with the first row and column pixels of the original image found in the edge information
O. The adaptive parameters
,
, and
corresponding to pixel
can be obtained from the
ARP in
O. Starting from pixel
, the AMED prediction is performed on pixel
in the order of top-to-bottom and left-to-right, and the predicted value
can be obtained. From the pixel label value
w in the edge information, the load capacity
of the pixel can be obtained so that we can recover the pixel value of the original image because the predicted pixel is the same as the original pixel with the high
w bits, and the
-th MSB is inverted. The recovery process unfolds in the following manner:
where
is the
-th MSB flip value of the predicted pixel
as shown in the following equation:
Upon the successful recovery of all pixels, the original image I can be obtained.
3.4.3. Identifying Information Extraction
To illustrate the extraction process of the identifying information embedded in the transitional image pixel
, consider the extraction of
as per Equation (
14). Subsequently, the key
defines the mapping
, enabling the derivation of
from
. By following the procedure outlined in Equation (
17), the encrypted identifying information
can be obtained:
Following this, the application of Equation (
10) enables the computation of
, …,
. Subsequently, decrypting the data using the key
reveals part of the identifying information
md. This operation is repeated to extract all the identifying information, and it is compared with the
md prior to embedding. Consistency denotes a secure transmission environment, whereas discrepancies point towards a potential data tampering attack during data transmission.
The receiver can independently perform secret data extraction, image recovery, and identifying information extraction based on possessing the key. These operations can be conducted separately.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}