1. Introduction
Nanofluids, defined as fluids containing nanometer-sized particles [
1], have gained significant attention in recent years due to their enhanced thermal properties compared to conventional heat transfer fluids. The enhancement in thermal conductivity varies de- pending on the nature of the nanoparticles and the base fluid, with many studies observing increases ranging from 15% to 40% [
2,
3]. Choi et al. [
4] reported that the addition of less than 1% (by volume) of nanotubes increased the thermal conductivity of the base fluid by up to approximately two times. Among nanofluids, those based on aluminum oxide (Al
2O
3) nanoparticles dispersed in ethylene glycol (EG) have been extensively studied for their potential applications in heat transfer systems [
5,
6,
7], cooling systems [
8], electronics [
9], and other industrial processes [
10]. Bozorgan et al. [
5] have compared the cooling ability of TiO
2/EG and Al
2O
3 for double-tube heat exchangers under laminar flow conditions, demonstrating a higher thermal conductivity enhancement of Al
2O
3 compared to TiO
2 in the range of 1–10% volume fraction. Therefore, accurate prediction of the thermal conductivity of EG–Al
2O
3 nanofluids has become a top priority for reducing experimental costs, optimizing material selection, facilitating research, and customizing application solutions.
Classical theoretical models, such as those of Maxwell [
11], Bruggeman [
12], and Hamilton-Crosse [
13,
14], offer foundational approaches to understanding the heat transfer characteristics of nanofluids. However, these models often assume idealized conditions, such as assuming nanoparticles to be perfect spheres, supposing there are no interactions between nanoparticles, and neglecting the movement of nanoparticles. This simplification often makes it difficult to capture the complex dynamics in different experimental conditions. For instance, the Maxwell model presupposes that nanoparticles remain discrete and stationary within a continuous medium, basing its parameters solely on the volume fraction of the nanoparticles and the thermal conductivities of both the fluid and the nanoparticles. Nevertheless, this simplification overlooks critical phenomena. Jang and Choi [
15] have highlighted that Brownian motion significantly contributes to the enhancement of thermal conductivity at small particle sizes, which traditional macroscale models do not account for. Furthermore, Prasher et al. [
16] observed that the thermal conductivity values measured in experiments were substantially higher than those predicted by conventional models. This discrepancy can be attributed to the omission of crucial parameters such as the Hamaker constant, ζ potential, pH, and ion concentration. It has also been reported that the aggregation effect has a non-negligible influence on the thermal behavior of nanofluids. Addressing these gaps, more advanced theoretical models and variables were considered. For example, Abbasov et al. [
17] proposed a new model considering the aggregation of nanoparticles and the presence of a nanolayer. Yu et al. [
18] renovated the Hamilton-Crosser model to include the shape factor and the particle–liquid interfacial layer. However, there remains a lack of consensus regarding the factors influencing the thermal conductivity of nanofluids. For example, the volume fraction of nanoparticles, known to be an important parameter for thermal conductivity enhancement, has been reported to be a positive influencing parameter [
19,
20,
21,
22,
23,
24]. However, some studies indicate that thermal conductivity does not improve until the particle concentration reaches a certain threshold (i.e., the critical concentration). Once the threshold is exceeded, thermal conductivity increases linearly with further increases in concentration [
25,
26]. On the contrary, Altan et al. [
27] reported a decrease of thermal conductivity when adding magnetite nanoparticles to water and EG. These discrepancies make it challenging to establish and gain acceptance for a theoretical model based on physical quantities. Furthermore, there is no unified explanation for the mechanisms underlying the enhancement of thermal conductivity in nanofluids [
28].
On the other hand, simulation techniques such as molecular dynamics (MD) and finite element analysis (FEA) provide a more detailed examination of microscale interactions and energy transfer mechanisms. Sarkar et al. [
29] used MD to model copper–argon nanofluid systems and found that the thermal conductivity increases with copper nanoparticle concentration, primarily due to enhanced liquid atom movement rather than slow nanoparticle Brownian motion. FEA studies conducted by Nazir et al. [
30] showed significant effects of temperature gradients on mass transport and concentration gradients on heat transfer. Although numerical simulations can provide valuable insights, a large number of replicated calculations are inevitable. In addition, the generalization of the numerical models is questioned, i.e., they may not be effectively applied to larger systems or adapt to different fluid components.
Consequently, there is a growing interest in applying artificial intelligence methods represented by machine learning (ML) techniques to develop predictive models with obvious advantages in terms of accuracy, reliability, and cost. With its ability to model complex, nonlinear relationships and adapt to diverse datasets, ML models’ predictive performance in enhancing the thermal properties of nanofluids is worthy of investigation [
31]. For ML approaches, leveraging extensive datasets encompassing various conditions and compositions is an effective way to explore the relationships between features. For instance, Ahmadi et al. [
32] combined the least square support vector machine (LSSVM) model and a genetic algorithm (GA) to predict the thermal conductivity ratio of EG–Al
2O
3 nanofluids, resulting in a high accuracy with a correlation coefficient (R
2) value of 0.9902 and a mean squared error (MSE) value of 8.69 × 10
−5. Three variables, namely temperature (T), nanoparticle size, and concentration, were used to train the model, which significantly improved the prediction accuracy over existing models. Ahmadloo et al. [
33] used an artificial neural network (ANN) model to predict the thermal conductivity of various nanofluids developed with water, EG, and transformer oil. A total of 776 experimental data points from 21 sources were used to improve model performance. The results demonstrated that the mean absolute percent error (MAPE) values were 1.26% and 1.44% for training and testing datasets, respectively. Sharma et al. [
34] used gradient boosting (GB), support vector regression (SVR), decision tree (DT), random forest (RF), and ANN models to predict the thermal conductivity of a TiO
2–water nanofluid. The results indicated that the GB model achieved the highest R
2 values (0.99) among all models. Besides, the results also highlighted the significance of nanoparticle shape on thermal conductivity. Ganga et al. [
35] used five ML models to estimate the thermal conductivity and viscosity of water-based nanofluids. The study considered influential nanoparticle properties such as temperature and concentration, and the k-nearest neighbor (KNN) also provided reliable results across both viscosity and thermal conductivity predictions. Khosrojerdi et al. [
36] used a multi-layer perceptron (MLP) model to predict the thermal conductivity of a graphene nanofluid. Note that the influence of temperature (25 °C to 50 °C) and weight percentages (0.00025, 0.0005, 0.001, 0.005) on thermal conductivity was explored. The results showed that the MLP obtained higher prediction accuracy and reliability than experimental and theoretical models, resulting in low values of root mean squared error (RMSE) and MAPE. Said et al. [
37] used extreme gradient boosting (XGBoost) and Gaussian process regression to study the impact of sonication on the thermal conductivity of functionalized multi-walled carbon nanotube nanofluids, finding that the XGBoost model outperformed other models in predicting enhanced dispersion characteristics and stability. Although supervised ML models perform reliably the task of predicting thermal conductivity, there are not yet any comparisons of these models when applied to predict thermal conductivity of EG–Al
2O
3 nanofluids. Despite the traditional supervised ML models, physics-informed machine learning (PIML) [
38] leverages domain knowledge from mathematical physics to enhance predictions and analyses, particularly in contexts where data may be incomplete, uncertain, or high-dimensional. This approach integrates seamlessly with kernel-based and neural network-based regression methods, offering effective, simple, and meshless implementations that are especially powerful in tackling ill-posed and inverse problems. For instance, Wang et al. [
39] present a deep learning-based model for reconstructing space, temperature, and time-related thermal conductivity through measured temperature, achieving precise real-time inversion without commercial software. The model includes data generation with a physics-informed neural network (PINN), noise reduction via a U-net, and inversion using a nonlinear mapping module (NMM), offering a robust and efficient alternative to traditional methods. Zhou et al. [
40] demonstrate the application of PINNs to efficiently and accurately solve the phonon Boltzmann transport equation for mesoscale heat transfer, which excels in handling ballistic–diffusive heat conduction. Although PINNs are capable of operating with minimal training data, they rely heavily on the quality and scope of input data. Their performance and accuracy are contingent on comprehensive and unbiased data coverage; any gaps or biases can significantly impact the model’s generalization and precision. Additionally, training PINNs can be more complex and challenging compared to traditional NNs, as they require the minimization of both data discrepancies and the residuals of physical equations. This task becomes particularly demanding when dealing with highly nonlinear and multiscale physical problems. Furthermore, the successful application of PINNs depends on a thorough understanding of physical laws and the accurate mathematical representation of the problem at hand. In cases where there is insufficient understanding of the physical processes or the physical models are imprecise, PINNs may fail to deliver accurate predictions. As previously mentioned, the physical mechanisms behind the enhancement of the thermal conductivity of nanofluids and influencing parameters remain a topic of debate, which makes developing PINNs that can predict the thermal conductivity of nanofluids a quite challenging task.
For most ML models developed for solving regression problems, one significant limitation is their ‘black-box’ nature, i.e., the model’s internal workings cannot be easily interpreted. This lack of interpretability poses challenges for further optimizing engineering and experimental design. To address this issue, Shapley additive explanations (SHAP) is usually employed to interpret complex models by attributing the contribution of each feature to the prediction target [
41]. By incorporating SHAP analysis, the practical utility and reliability of ML models in predicting the thermal conductivity of nanofluids can be significantly enhanced. For instance, Kumar et al. [
42] employed SHAP values to interpret models developed for predicting the electrical conductivity (EC), viscosity (VST), and thermal conductivity (TC) of EGO–Mxene hybrid nanofluids. The SHAP analysis revealed that T had a more significant impact on the predictions of all three response variables compared to concentration. Accordingly, the use of SHAP analysis can enable a deeper understanding of how changes in features influence predictions.
In general, the primary objective of this study is to develop several supervised ML models to predict the thermal conductivity of EG–Al
2O
3 nanoparticles. A total of 94 experimental data points collected from four published studies [
43,
44,
45,
46] are used to train and test models. Three data allocation methods are tested to find the best way to divide training and testing. Another separate study [
47] is used to build a validation dataset.
The remainder of this work is organized as follows:
Section 2 highlights the significance of this study.
Section 3 firstly describes the thermal conductivity of EG–Al
2O
3 nanoparticles, data collection, and feature selection, and then each model is discussed to present its characteristics.
Section 4 covers the development of the prediction models.
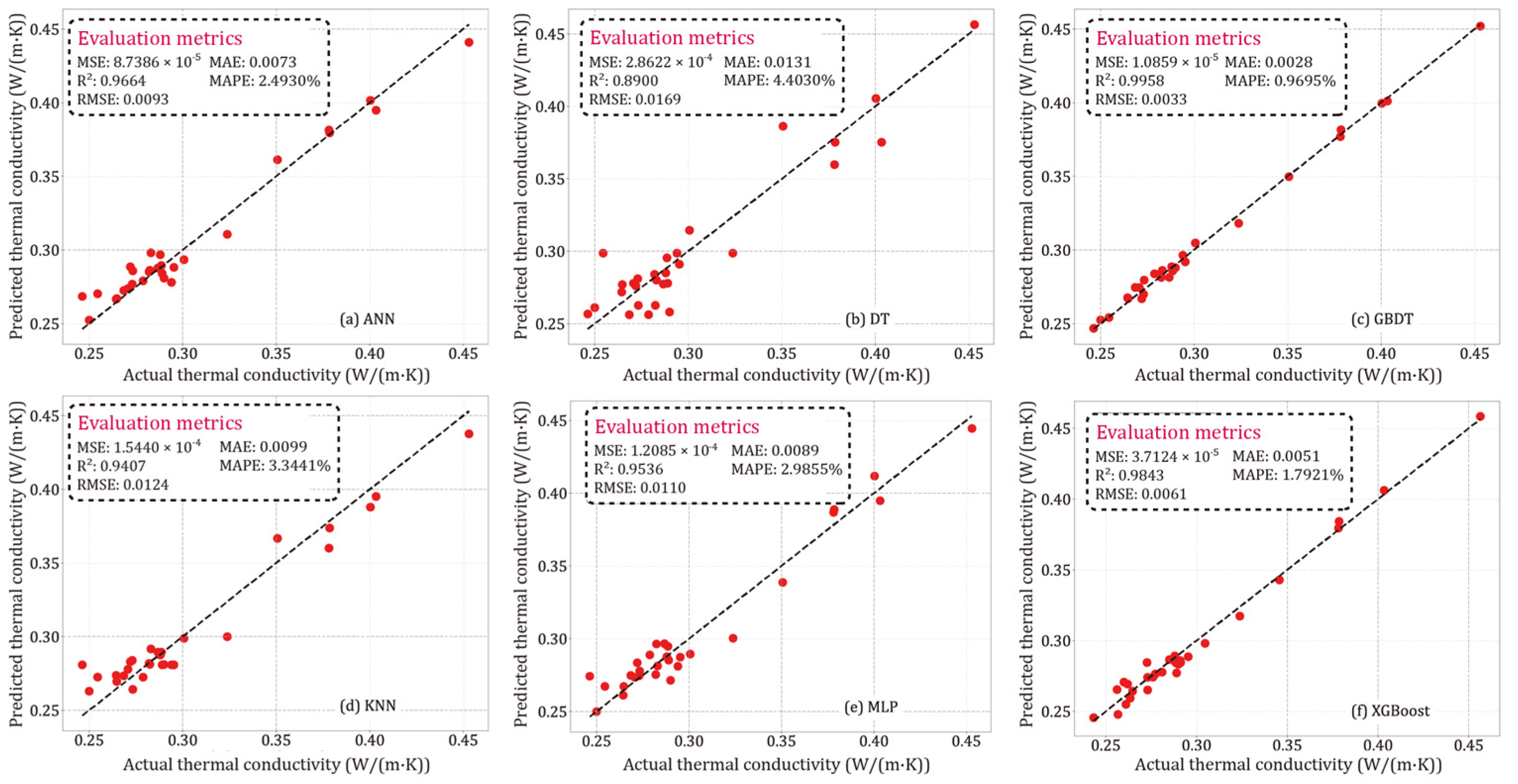
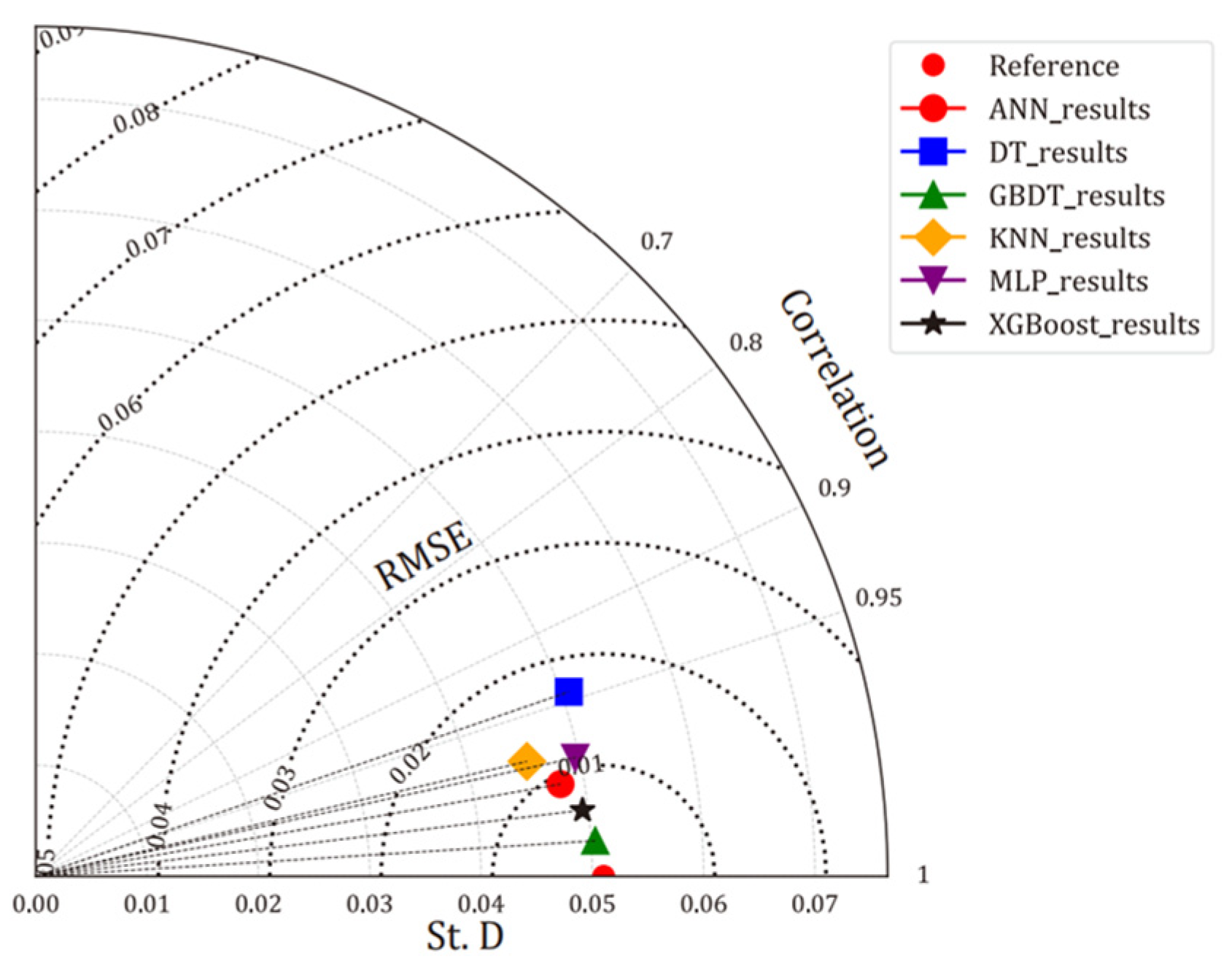
Section 5 presents the results, mainly providing a comparative analysis of model performance in both the training and testing phases, as well as the validation process. The results of parameter sensitivity analysis using SHAP technology is also shown in this section. Finally,
Section 6 discusses key findings in this study, practical implications, and future research directions. The goals and flowchart of this work are shown in
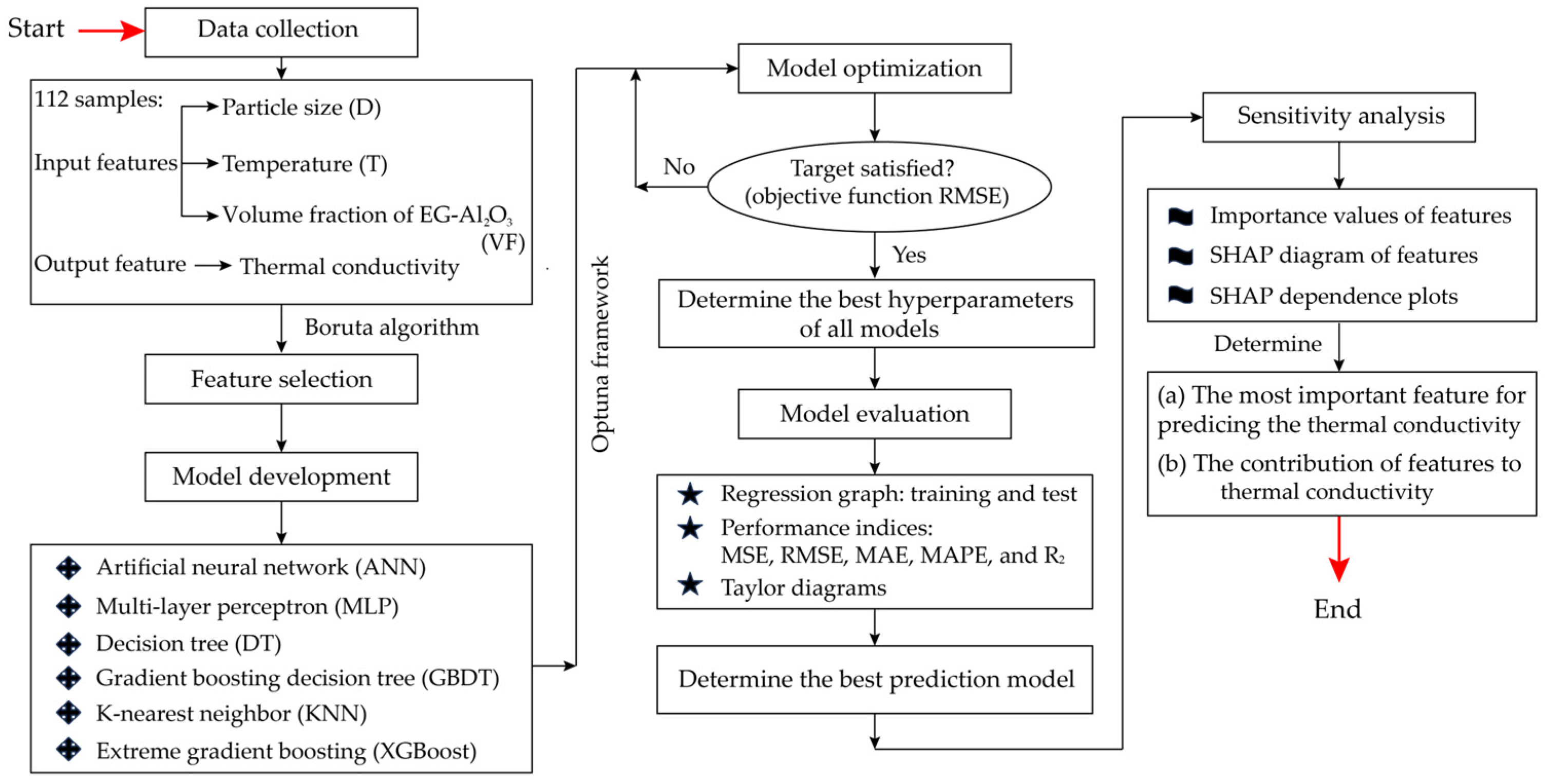
Figure 1.
2. Research Significance
Improving the thermal conductivity of EG–Al2O3 nanofluids is crucial for heat transfer in cooling systems and heat exchangers. This enhancement allows for more efficient energy use, reduces operational costs, and facilitates the design of more compact systems. Additionally, higher thermal conductivity can expand the range of applications in industries requiring effective thermal management, such as electronics and high-performance engines. The accurate prediction of thermal conductivity in EG–Al2O3 nanofluids is pivotal for optimizing energy utilization in various industries, yet it presents significant challenges. Traditional models like those of Maxwell and Hamilton-Crosse have typically simplified complex phenomena such as Brownian motion and particle interactions, leading to significant discrepancies between the predicted and experimental results. This limitation necessitates a shift towards more adaptable and nuanced approaches.
ML models, by virtue of their design, excel in managing complex, nonlinear data interactions without necessitating explicit programmatic formulations of the underlying physical laws. This capability is particularly advantageous in handling the multi-variable nature of nanofluid systems, where factors such as particle size, temperature, and concentration interact in nonlinear ways to affect thermal conductivity. By implementing advanced ML models, this research leverages computational power to derive insights from existing data in a way that is both cost-efficient and robust, offering substantial improvements over conventional methods. This study contributes to the field by: (i) employing six different supervised machine learning models (ANN, DT, GBDT, KNN, MLP, and XGBoost) to predict the thermal conductivity of EG–Al2O3 nanofluids, and (ii) utilizing SHAP sensitivity analysis to provide crucial insights that enhance the theoretical understanding and practical application of thermal management in various industries. The six supervised models were developed using four published studies that focused on temperature, particle size, and volume fraction as the primary analytical parameters. These studies were chosen because they provide high-quality and well-organized data.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}