1. Introduction
The National Human Activity Pattern Survey (NHAPS) showed that respondents spent an average of 87% of their time in enclosed buildings, while the remaining 6% was spent in cars and 7% outdoors [
1]. Indoor air pollutants (such as CO
2 and HCHO) can be harmful to human health, leading to drowsiness, headaches, or reduced concentration [
2]. The primary indoor activity area for students is the classroom. Previous studies have shown that indoor air quality in classrooms affects students’ learning efficiency and concentration and may also have long-term effects on the physical health of both students and teachers [
3,
4]. Poor indoor air quality can increase student absences, decrease test scores, and even cause people to develop sick building syndrome [
5,
6,
7]. Ramalho et al. [
8] showed, through measurements, that indoor CO
2 levels are a good indicator for investigating air pollutants in classrooms. The Hygienic Standard for Carbon Dioxide Indoor Air states that the standard for indoor CO
2 concentration is 1000 ppm [
9]. Allen et al. [
10] noted through controlled experiments on the threshold standard for CO
2 concentration (500 ppm to 1500 ppm) that both high and low CO
2 concentrations have an impact on people’s health and productivity. Additionally, Zhang et al. [
11] showed that working in a room with CO
2 at a high concentration of 5000 ppm leads to physical and psychological discomfort, as well as a decrease in cognitive performance. Moreover, it was found that students’ task performance speed, test scores, and attendance increased when the CO
2 concentration decreased [
12,
13]. A prevalent approach to managing indoor CO
2 concentrations is through ventilation [
14]. However, there are identified ventilation shortcomings in American educational institutions [
15]. Assessing the necessity of activating the ventilation system preemptively to address classroom CO
2 levels poses a significant challenge. Therefore, predicting CO
2 concentrations in classrooms is necessary to create a comfortable learning environment for students. Predicting CO
2 concentrations with high accuracy can provide valuable data to support corresponding ventilation measures in classrooms.
Numerous scholars have explored various approaches for predicting indoor CO
2 concentrations. One popular approach for making these predictions in classroom environments relies on traditional mathematical or physical principles. Luther et al. [
16] employed a mass balance equation to create a dynamic calculator that visualizes the impact of the indoor volume, exhalation rate, air exchange rate, carbon dioxide exhalation rate, and initial CO
2 concentration in the environment on the accumulation and decay of CO
2 in a room. Teleszewski et al. [
17] developed an integrated equation based on factors such as the initial CO
2 concentration, air exchange rate, per capita occupancy, and CO
2 exhalation rate for individuals engaged in different activity intensities. The proposed model has the potential to be used when analyzing indoor air quality. Yalcin et al. [
18] controlled variables such as the number of students, physical characteristics, and activity intensity in a faculty building at Sakarya University to validate their developed mathematical model and simulator software. This software can be used to analyze the variation in CO
2 concentration under different indoor conditions considering factors such as various ventilation methods, staffing levels, window and door properties, and room shapes and sizes. Choi et al. [
19] utilized a double exponential smoothing model to predict CO
2 emissions in 50 states and in the U.S. transportation sector and showed that this model is supported by validity tests for pseudo out-of-sample predictions. Traditional prediction methods such as trend extrapolation models, time series models, and multivariate linear regression models perform well when handling original data and exhibit a clear linear relationship. However, these methods have limitations when addressing nonlinear relationships between indoor CO
2 emissions and their influencing factors. Deep learning has gained popularity in predicting environmental states or data because it can extract complex, high-level hidden information from large high-dimensional datasets. Xiang et al. [
20] applied the least absolute shrinkage and selection operator (LASSO) regression and whale optimization to optimize the nonlinear parameters, and Mardani et al. [
21] used dimensionality reduction, clustering, and machine learning algorithms to predict the impact of energy consumption and economic growth on CO
2 emissions. Their study involved clustering the data, reducing the dimensionality via singular value decomposition, and constructing CO
2 prediction models via an adaptive fuzzy inference system and artificial neural networks for each cluster in the self-organizing map. Ahmed et al. [
22] studied the effects of energy consumption, financial development, gross domestic product, population, and renewable energy on CO
2 emissions. They employed long short-term memory (LSTM) [
23] to evaluate the impact of these factors on CO
2 emissions. Qader et al. [
24] employed a nonlinear autoregressive (NAR) neural network, Gaussian process regression (GPR), and the Holt–Winters seasonal method to forecast CO
2 emissions in the context of combating global warming. Jung et al. [
25] conducted a comparative analysis of three deep learning neural network models, namely the artificial neural network (ANN), nonlinear autoregressive network with exogenous inputs (NARX), and LSTM, to determine the most effective model for predicting the temperature, humidity, and CO
2 concentration in greenhouses. However, the model parameters were manually selected, and multiple parameter selection adjustments aimed at further optimizing the model’s performance to a greater degree were not present. Sharma et al. [
26] modified the LSTM structure by removing the forget gate to predict the CO
2 concentration and fine particulate matter (PM
2.5) concentration, both of which significantly impact the indoor air quality. They proposed the LSTM without the forget gate (LSTM-wF) prediction model, which not only enhanced the prediction performance but also reduced the model complexity in comparison to existing models. Nevertheless, they employed their own selected particles, pollutants, and meteorological parameters as model inputs without conducting a thorough screening of these environmental parameters. Their findings indicated that neural network time series nonlinear autoregressive models outperformed other approaches in terms of predicting future CO
2 concentrations.
In summary, the use of a neural network autoregressive model is suitable for predicting CO
2 concentrations, and the LSTM neural network is usually employed to construct models for addressing time series prediction problems. Nevertheless, there is still room for improvement and enhancement in terms of the prediction accuracy. Additionally, there are various factors influencing CO
2 concentrations in classroom environments. These factors can be broadly categorized into environmental design factors and indoor air quality factors, with each major factor comprising several minor factors, which may exhibit certain correlations with one another [
27]. Furthermore, the number of people indoors is considered to be strongly correlated with the CO
2 concentration [
28]. However, many current studies on CO
2 concentration prediction do not consider the number of people. Therefore, it is essential to compile a comprehensive set of influencing factors that may affect indoor CO
2 concentrations. This study’s preselected set of environmental factors includes the indoor population in a classroom and various other environmental considerations that may impact CO
2 concentrations. The factors included in the final set from among all of the environmental factors should be comprehensive and pivotal to effectively predict and control CO
2 concentrations in the classroom environment.
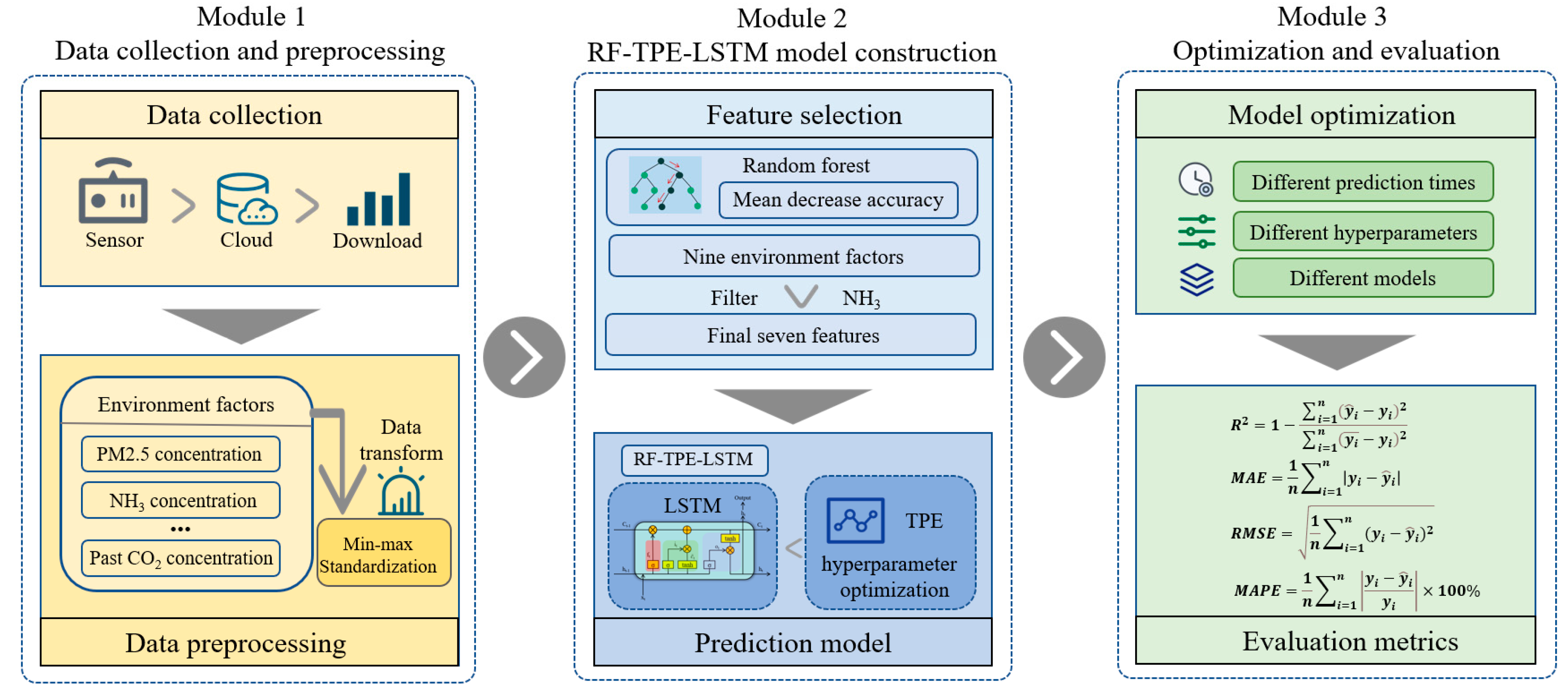
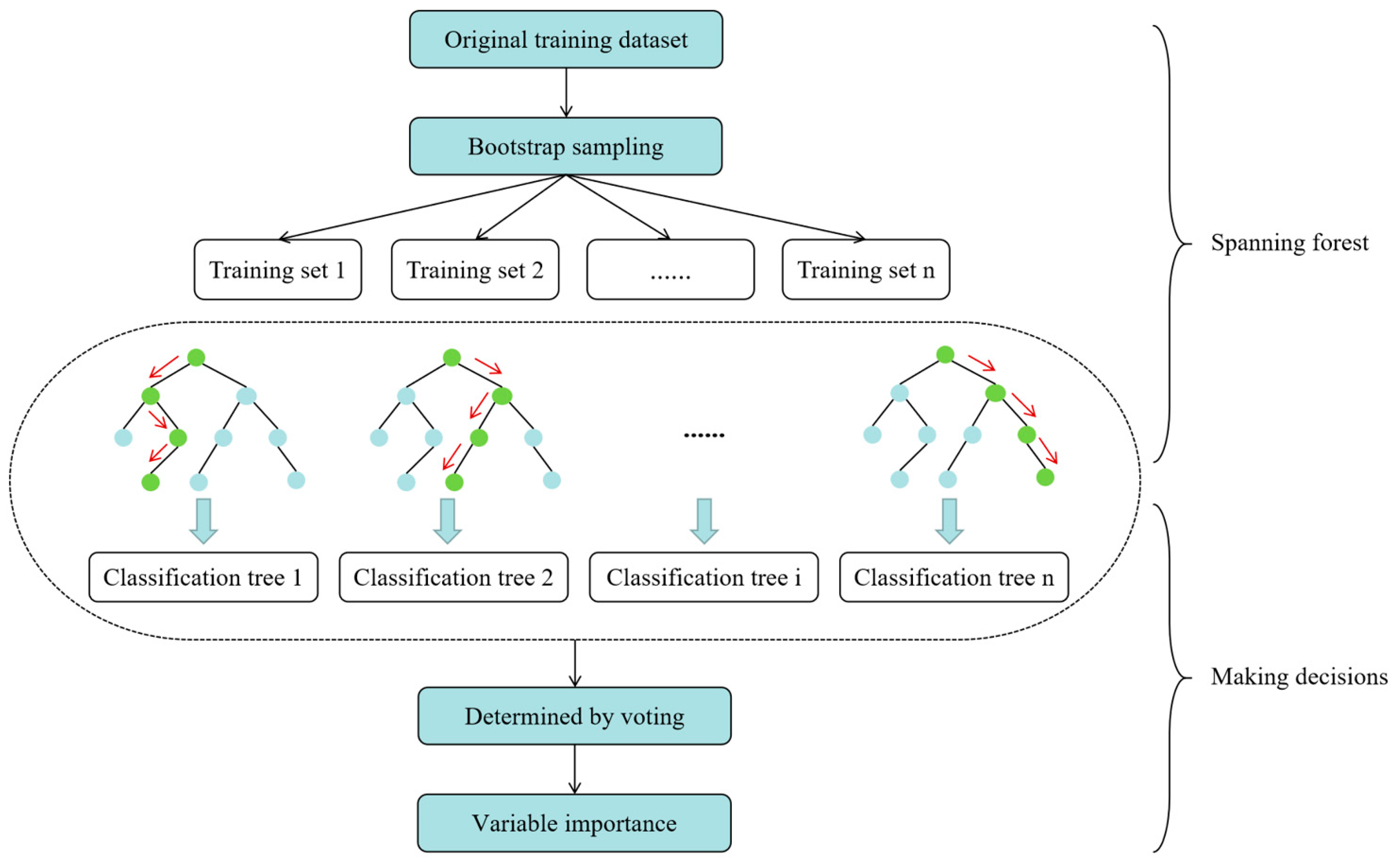
To further enhance the predictive accuracy of the LSTM network model for identifying factors influencing classroom CO
2 concentrations and to address the challenge of hyperparameter selection, which often relies on empirical experience rather than a theoretical foundation in current LSTM models, this study introduces the random forest (RF) model [
29]. The RF model was utilized to assess the significance of each environmental factor on the CO
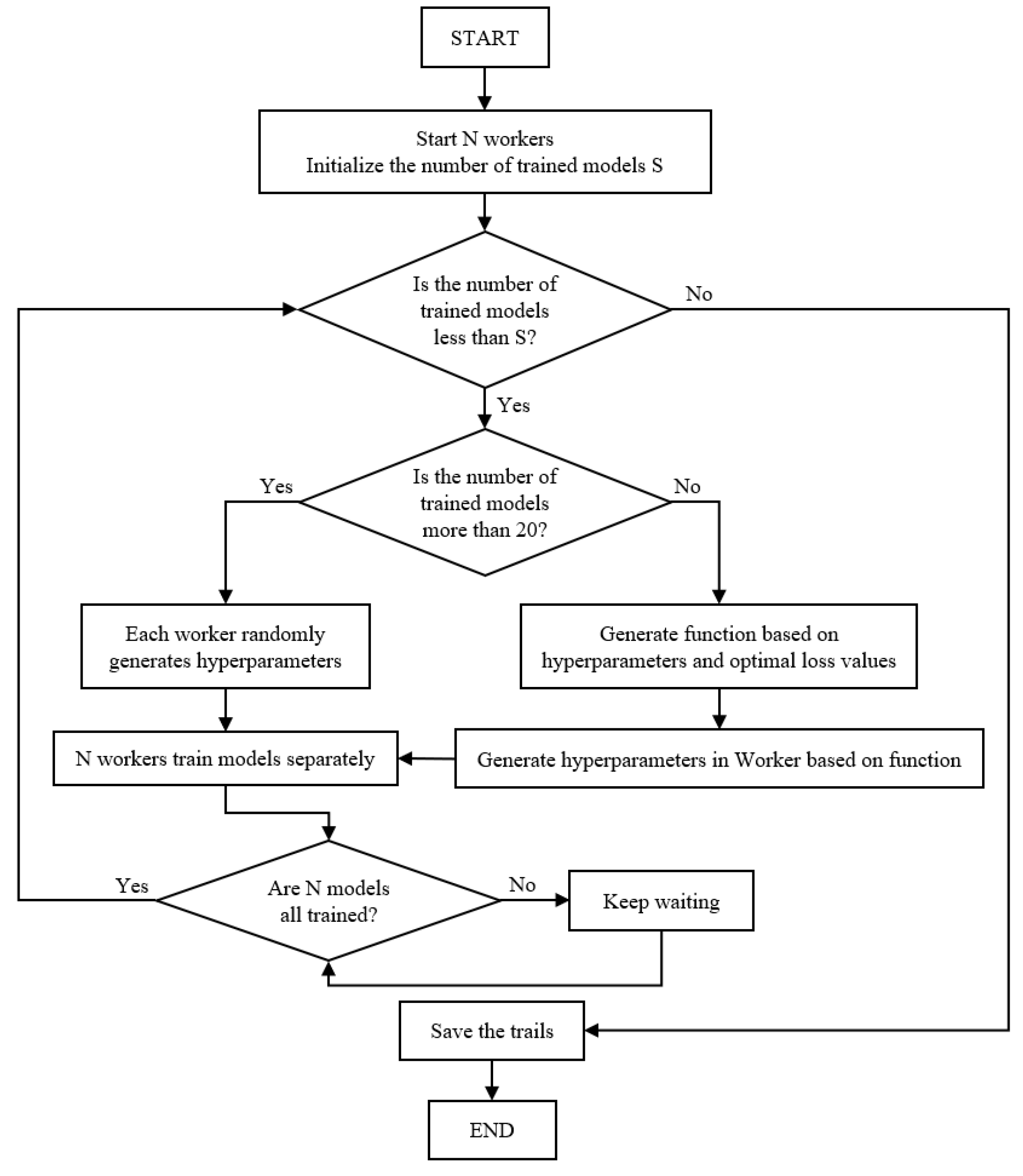
2 concentration and subsequently rank them based on their importance. Based on the outcomes, the input variables for the LSTM model were meticulously chosen, encompassing the most pertinent influencing factors. Furthermore, the tree-structured Parzen estimator (TPE) algorithm [
30] was introduced to enhance the selection of crucial hyperparameters for the LSTM model, culminating in the development of the RF-TPE-LSTM model for CO
2 concentration prediction. In the final stage of experimentation, the RF-TPE-LSTM model was compared with the RF-LSTM model, and the prediction accuracy of the RF-TPE-LSTM model was evaluated using performance metrics such as the coefficient of determination (
R2) [
31], mean absolute error (
MAE) [
32], root mean square error (
RMSE) [
33], and mean absolute percentage error (
MAPE) [
34]. The experimental results clearly demonstrated that the selection of influencing factors had a certain impact on the CO
2 concentration prediction model, and there are also different prediction effects for different prediction times. The optimized model outperformed the unoptimized model, demonstrating significant advantages in terms of predictive accuracy. The
R2 value achieved by the RF-LSTM model was greater than 95%, while that of the RF-TPE-LSTM model significantly surpassed this value, achieving an
R2 exceeding 98%. Moreover, the RF-TPE-LSTM model not only demonstrated better fitting and superior prediction accuracy compared to the RF-LSTM model but also outperformed the unoptimized LSTM model and other models. Hence, the CO
2 prediction model developed in this study proves to be highly effective at forecasting the concentration of CO
2 in indoor environments for future periods. This model provides a dynamic foundation for regulating classroom ventilation rates, thereby helping to create a healthy and productive learning environment for students.
The remainder of this paper is structured as follows:
Section 2 describes the dataset used in this study, along with the constructed model.
Section 3 discusses data processing and presents the results of the comparison of different prediction times, hypermeters, and models. Finally, in
Section 4, a summary and future directions for predicting indoor CO
2 concentrations are provided.
4. Discussion
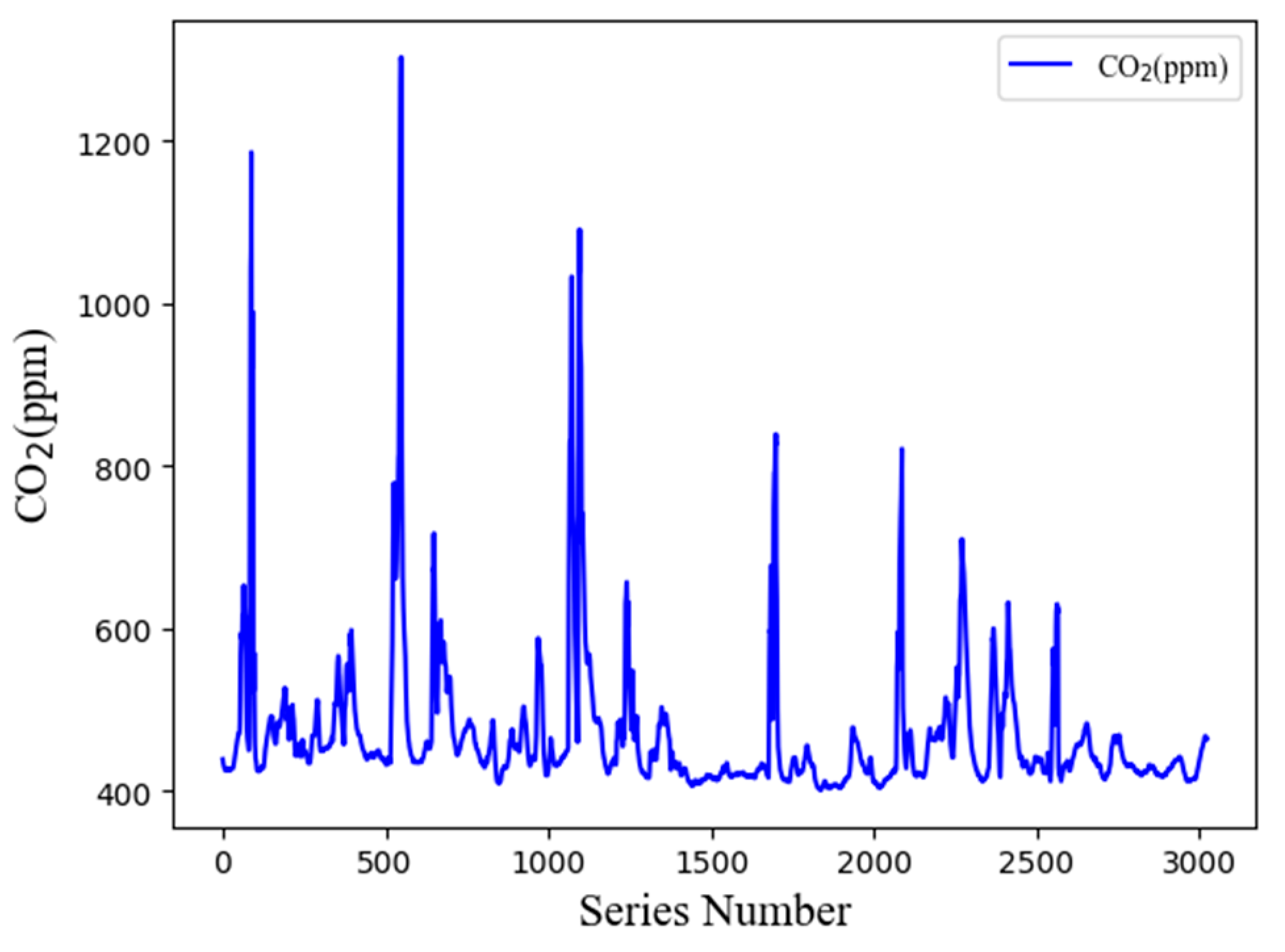
The purpose of this study was to construct a CO2 concentration prediction model based on the screening of influencing factors affecting the CO2 concentration in classrooms, aiming to create a comfortable and efficient classroom environment. We initially performed data preprocessing operations on the collected datasets and identified the factors influencing CO2 concentrations using the RF algorithm. Then, we developed an RF-LSTM model using the final dataset obtained from the screening process. Following hyperparameter optimization with the Bayesian optimization algorithm, TPE, we introduced the RF-TPE-LSTM model. We then used both models to predict the indoor CO2 concentration before and after hyperparameter optimization. The calculation results revealed that the NH3 concentration in the classroom was not an input variable to the CO2 prediction model. Furthermore, the prediction model exhibited excellent fit with the dataset.
In addition, we analyzed the prediction performance of the RF-TPE-LSTM model over time using four evaluation metrics, namely, the R2, MAE, RMSE, and MAPE, which showed that the model has good prediction ability within a certain time range. After evaluating the RF-LSTM and RF-TPE-LSTM with different combinations of hyperparameters, it is concluded that the RF-TPE-LSTM model obtains smaller errors and better R2 values when predicting the CO2 concentration in classrooms. Specifically, compared to the RF-LSTM, the RF-TPE-LSTM model reduces the MAE from 8.27 to 2.96, the RMSE from 11.71 to 5.54, and the MAPE from 1.79% to 0.60%. This indicates that the hyperparameter optimization we used has a significant effect on improving accuracy. Subsequently, we conducted experiments using the RNN, BPNN, and Optuna–LSTM models; the results indicated that the prediction accuracies of these models improved after considering the influencing factors. Therefore, the use of the RF algorithm to filter the model inputs has some versatility for multiple algorithmic models. Notably, the R2 of the RF-TPE-LSTM model exceeded 98%, indicating its strong ability to predict CO2 concentrations in classrooms. In summary, the key findings of this study are as follows:
- (1)
The model developed in this research demonstrates high accuracy in forecasting classroom CO2 concentrations.
- (2)
The predictions made by the RF-TPE-LSTM model are more robust and efficient than those made by single models or models using only one optimization algorithm.
- (3)
The RF-TPE-LSTM model combines RF for feature importance analysis, TPE for hyperparameter tuning, and LSTM for time series prediction. This integration not only highlights the most significant factors influencing CO2 levels but also fine-tunes the model’s hyperparameters, such as the number of units, learning rate, and training epochs. The collaboration of these techniques enhances the model’s capability to adapt to the dynamic variations in classroom environments, leading to better prediction accuracy and reliability.
Consequently, the model proposed in this paper can serve as an effective method for predicting CO
2 concentrations in classrooms, providing valuable data support for ventilation strategies aimed at controlling indoor CO
2 concentrations. Decision-makers responsible for controlling the physical environment of classrooms can also use our proposed CO
2 concentration prediction model to proactively utilize air-conditioning systems for ventilation, ensuring a comfortable learning environment [
46,
47]. Although our CO
2 concentration prediction model has achieved excellent results, we aim to address some practical issues in future work. For instance, we can develop an intuitive visualization interface to display historical CO
2 concentration data, prediction results, and model performance, making it easier for users to understand and use. This work can serve as an important component in the automatic ventilation control of CO
2 concentration in classrooms.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}