
Entity-Alignment Interaction Model Based on Chinese RoBERTa


Abstract
1. Introduction
- This paper puts forward a novel entity-alignment model, RoBERTa-INT, which enhances the accuracy and robustness of entity alignment through the utilization of the additional information associated with entities.
- Traditional entity-alignment models combine the graph-structure information, which often suffers from unreasonable aggregation of neighbor information, leading to the problem of noise matching. This paper presents a solution to the aforementioned problem through the introduction of an interaction model, which utilizes names, attributes, neighbors, and attentions of entities for interaction and captures the matching relationships between neighbors from a fine-grained and semantic perspective.
- We evaluate the model in detail on the Chinese datasets MED-BBK-9K [12], and the results demonstrate that the efficacy of the method proposed in this paper is significantly better than that of baseline models.
2. Related Works
2.1. Methods Based on Graph-Structure Information
2.2. Methods Based on Additional Information
3. Methodology
3.1. Problem Definition
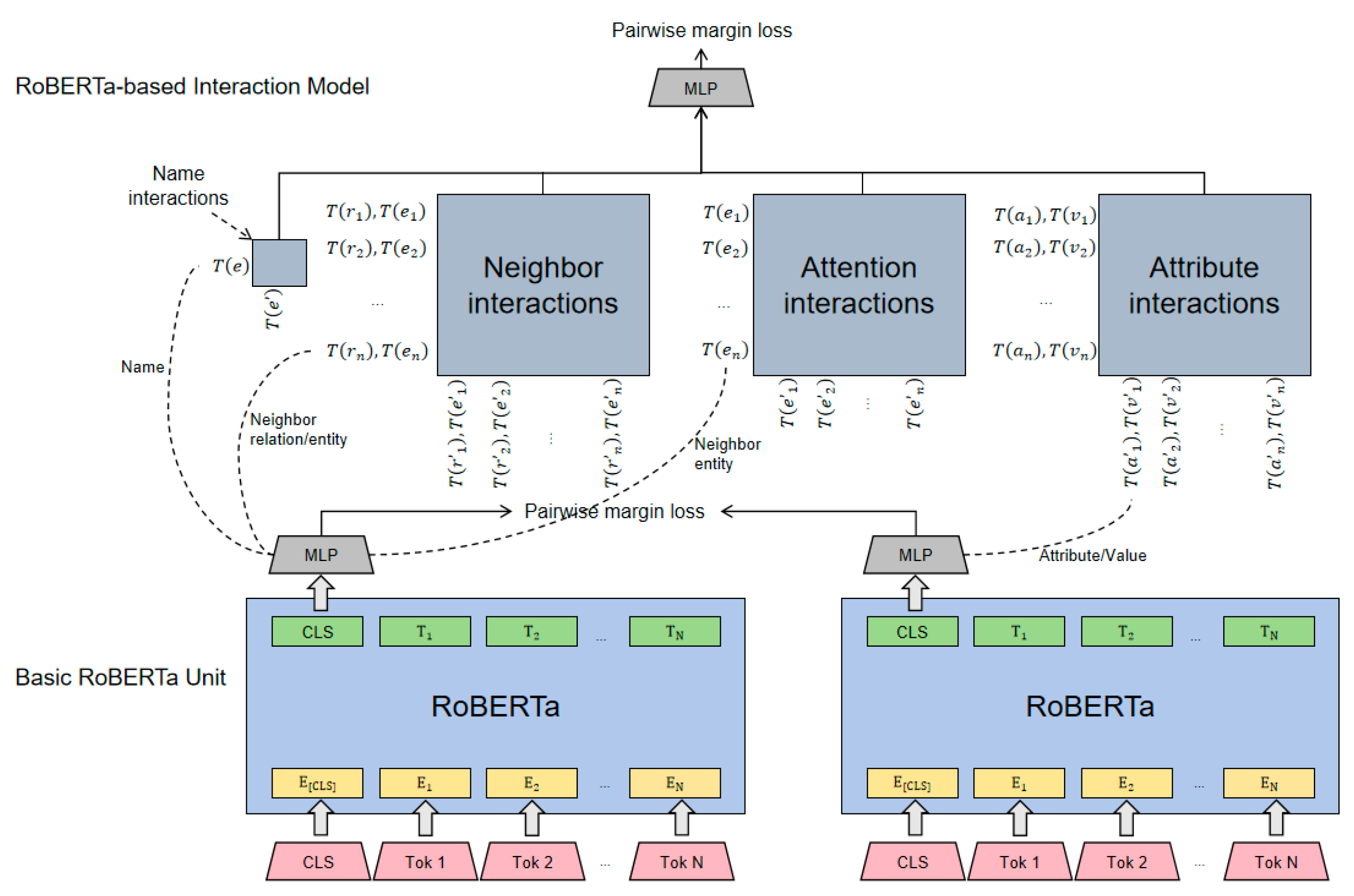
3.2. The Model Framework
3.2.1. Basic RoBERTa Unit
3.2.2. RoBERTa-Based Interaction Model
3.3. Entity Alignment
4. Experiments
4.1. Datasets
4.2. Parameter Settings and Evaluation Metrics
4.3. Experimental Results
4.4. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, Y.; Li, H.; Li, H.; Liu, W.; Wu, Y.; Huang, Q.; Wan, S. An Overview of Knowledge Graph Reasoning: Key Technologies and Applications. J. Sens. Actuator Netw. 2022, 11, 78. [Google Scholar] [CrossRef]
- Shokrzadeh, Z.; Feizi-Derakhshi, M.-R.; Balafar, M.-A.; Bagherzadeh Mohasefi, J. Knowledge Graph-Based Recommendation System Enhanced by Neural Collaborative Filtering and Knowledge Graph Embedding. Ain Shams Eng. J. 2024, 15, 102263. [Google Scholar] [CrossRef]
- Lan, Y.; He, G.; Jiang, J.; Jiang, J.; Zhao, W.X.; Wen, J.-R. A Survey on Complex Knowledge Base Question Answering: Methods, Challenges and Solutions. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; International Joint Conferences on Artificial Intelligence Organization: Montreal, QC, Canada; pp. 4483–4491. [Google Scholar]
- Chen, M.; Tian, Y.; Yang, M.; Zaniolo, C. Multilingual Knowledge Graph Embeddings for Cross-Lingual Knowledge Alignment. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; International Joint Conferences on Artificial Intelligence Organization: Melbourne, Australia; pp. 1511–1517. [Google Scholar]
- Zhu, H.; Xie, R.; Liu, Z.; Sun, M. Iterative Entity Alignment via Joint Knowledge Embeddings. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; International Joint Conferences on Artificial Intelligence Organization: Melbourne, Australia; pp. 4258–4264. [Google Scholar]
- Xu, K.; Wang, L.; Yu, M.; Feng, Y.; Song, Y.; Wang, Z.; Yu, D. Cross-Lingual Knowledge Graph Alignment via Graph Matching Neural Network. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Korhonen, A., Traum, D., Màrquez, L., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3156–3161. [Google Scholar]
- Wu, Y.; Liu, X.; Feng, Y.; Wang, Z.; Zhao, D. Jointly Learning Entity and Relation Representations for Entity Alignment. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 240–249. [Google Scholar]
- Wu, Y.; Liu, X.; Feng, Y.; Wang, Z.; Yan, R.; Zhao, D. Relation-Aware Entity Alignment for Heterogeneous Knowledge Graphs. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 5278–5284. [Google Scholar]
- Ye, R.; Li, X.; Fang, Y.; Zang, H.; Wang, M. A Vectorized Relational Graph Convolutional Network for Multi-Relational Network Alignment. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; International Joint Conferences on Artificial Intelligence Organization: Macao, China, 2019; pp. 4135–4141. [Google Scholar]
- Yang, H.-W.; Zou, Y.; Shi, P.; Lu, W.; Lin, J.; Sun, X. Aligning Cross-Lingual Entities with Multi-Aspect Information. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4431–4441. [Google Scholar]
- Tang, X.; Zhang, J.; Chen, B.; Yang, Y.; Chen, H.; Li, C. BERT-INT:A BERT-Based Interaction Model For Knowledge Graph Alignment. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; International Joint Conferences on Artificial Intelligence Organization: Yokohama, Japan, 2020; pp. 3174–3180. [Google Scholar]
- Zhang, Z.; Liu, H.; Chen, J.; Chen, X.; Liu, B.; Xiang, Y.; Zheng, Y. An Industry Evaluation of Embedding-Based Entity Alignment. In Proceedings of the 28th International Conference on Computational Linguistics: Industry Track, Online, 8–13 December 2020; Clifton, A., Napoles, C., Eds.; International Committee on Computational Linguistics: Barcelona, Spain, 2020; pp. 179–189. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-Relational Data. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, Nevada, USA, 5–10 December 2013; Curran Associates, Inc.: Red Hook, NY, USA, 2013; Volume 26. [Google Scholar]
- Wang, Z.; Lv, Q.; Lan, X.; Zhang, Y. Cross-Lingual Knowledge Graph Alignment via Graph Convolutional Networks. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J., Eds.; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 349–357. [Google Scholar]
- Cao, Y.; Liu, Z.; Li, C.; Liu, Z.; Li, J.; Chua, T.-S. Multi-Channel Graph Neural Network for Entity Alignment. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Korhonen, A., Traum, D., Màrquez, L., Eds.; Association for Computational Linguistics: Florence, Italy, 2019; pp. 1452–1461. [Google Scholar]
- Sun, Z.; Wang, C.; Hu, W.; Chen, M.; Dai, J.; Zhang, W.; Qu, Y. Knowledge Graph Alignment Network with Gated Multi-Hop Neighborhood Aggregation. Proc. AAAI Conf. Artif. Intell. 2020, 34, 222–229. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, J.; Yu, K.; Wu, X. Independent Relation Representation With Line Graph for Cross-Lingual Entity Alignment. IEEE Trans. Knowl. Data Eng. 2023, 35, 11503–11514. [Google Scholar] [CrossRef]
- Luo, Y.; Chen, Z.; Guo, L.; Li, Q.; Zeng, W.; Cai, Z.; Li, J. ASGEA: Exploiting Logic Rules from Align-Subgraphs for Entity Alignment. arXiv 2024, arXiv:2402.11000. [Google Scholar]
- Azzalini, F.; Jin, S.; Renzi, M.; Tanca, L. Blocking Techniques for Entity Linkage: A Semantics-Based Approach. Data Sci. Eng. 2021, 6, 20–38. [Google Scholar] [CrossRef]
- Ge, C.; Liu, X.; Chen, L.; Zheng, B.; Gao, Y. Make It Easy: An Effective End-to-End Entity Alignment Framework. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2021; ACM: New York, NY, USA, 2021; pp. 777–786. [Google Scholar]
- Zhang, Q.; Sun, Z.; Hu, W.; Chen, M.; Guo, L.; Qu, Y. Multi-View Knowledge Graph Embedding for Entity Alignment. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; International Joint Conferences on Artificial Intelligence Organization: Macao, China, 2019; pp. 5429–5435. [Google Scholar]
- Zhao, X.; Zeng, W.; Tang, J.; Li, X.; Luo, M.; Zheng, Q. Toward Entity Alignment in the Open World: An Unsupervised Approach with Confidence Modeling. Data Sci. Eng. 2022, 7, 16–29. [Google Scholar] [CrossRef]
- Liu, F.; Chen, M.; Roth, D.; Collier, N. Visual Pivoting for (Unsupervised) Entity Alignment. Proc. AAAI Conf. Artif. Intell. 2021, 35, 4257–4266. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Pan, L.; Li, J.; Liu, Z.; Chua, T.-S. Exploring and Evaluating Attributes, Values, and Structures for Entity Alignment. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Webber, B., Cohn, T., He, Y., Liu, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 6355–6364. [Google Scholar]
- Wang, Z.; Yang, J.; Ye, X. Knowledge Graph Alignment with Entity-Pair Embedding. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Webber, B., Cohn, T., He, Y., Liu, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1672–1680. [Google Scholar]
- Yang, K.; Liu, S.; Zhao, J.; Wang, Y.; Xie, B. COTSAE: CO-Training of Structure and Attribute Embeddings for Entity Alignment. Proc. AAAI Conf. Artif. Intell. 2020, 34, 3025–3032. [Google Scholar] [CrossRef]
- Sun, Z.; Hu, W.; Zhang, Q.; Qu, Y. Bootstrapping Entity Alignment with Knowledge Graph Embedding. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; International Joint Conferences on Artificial Intelligence Organization: Stockholm, Sweden, 2018; pp. 4396–4402. [Google Scholar]
- Xiong, C.; Dai, Z.; Callan, J.; Liu, Z.; Power, R. End-to-End Neural Ad-Hoc Ranking with Kernel Pooling. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; ACM: Tokyo, Japan, 2017; pp. 55–64. [Google Scholar]
- Xiang, Y.; Zhang, Z.; Chen, J.; Chen, X.; Lin, Z.; Zheng, Y. OntoEA: Ontology-Guided Entity Alignment via Joint Knowledge Graph Embedding. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, online, 1–6 August 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 1117–1128. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Dataset | KGs | Entities | Relation | Attribute | ||
|---|---|---|---|---|---|---|
| Relationships | Triples | Attributes | Triples | |||
| MED-BBK-9K | MED | 9162 | 32 | 158,357 | 19 | 11,467 |
| BBK | 9162 | 20 | 50,307 | 21 | 44,987 | |
| Parameter Name | Parameter Information |
|---|---|
| The embedding dimension of CLS | 768 |
| MLP dimension in Formula (1) | 300 |
| MLP dimension in Formula (8) | 11 → 1 |
| The number of candidates returned in Basic RoBERTa Unit | 50 |
| The maximum value of neighbors and attributes | 250 |
| Margin (Fine-tuning RoBERTa) | 3 |
| Margin (Fine-tune MLP in Formula (8)) | 1 |
| The number of RBF kernels | 20 |
| Mean | The range of values is from 0.025 to 0.975, with an interval of 0.05, and the total number is 20 |
| Variance | 0.1 |
| Initial learning rates (Fine-tuning RoBERTa) | 0.00001 |
| Initial learning rates (Interaction model) | 0.0005 |
| Model | MED-BBK-9K | |||
|---|---|---|---|---|
| Hits@1 | Hits@5 | MRR | ||
| Only graph-structure information. | BootEA | 30.7 | 49.5 | 0.399 |
| RDGCN | 30.6 | 42.5 | 0.365 | |
| Graph-structure information and additional information. | GCN-Align | 6.5 | 15.3 | 0.117 |
| OntoEA | 51.7 | 70.3 | 0.604 | |
| Only additional information. | BERT-INT | 53.8 | 60.2 | 0.567 |
| RoBERTa-INT | 59.2 | 66.8 | 0.625 | |
| Model | MED-BBK-9K | ||
|---|---|---|---|
| Hits@1 | Hits@5 | MRR | |
| RoBERTa-INT | 59.2 | 66.8 | 0.625 |
| w/o name interaction | 44.9 | 59.5 | 0.515 |
| w/o neighbor interaction | 55.8 | 64.5 | 0.596 |
| w/o attribute interaction | 56.8 | 66.5 | 0.610 |
| w/o attention interaction | 55.5 | 64.0 | 0.588 |
| BERT | 56.5 | 65.9 | 0.606 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, P.; Zhang, B.; Yang, L.; Feng, S. Entity-Alignment Interaction Model Based on Chinese RoBERTa. Appl. Sci. 2024, 14, 6162. https://doi.org/10.3390/app14146162
Feng P, Zhang B, Yang L, Feng S. Entity-Alignment Interaction Model Based on Chinese RoBERTa. Applied Sciences. 2024; 14(14):6162. https://doi.org/10.3390/app14146162
Chicago/Turabian StyleFeng, Ping, Boning Zhang, Lin Yang, and Shiyu Feng. 2024. "Entity-Alignment Interaction Model Based on Chinese RoBERTa" Applied Sciences 14, no. 14: 6162. https://doi.org/10.3390/app14146162
APA StyleFeng, P., Zhang, B., Yang, L., & Feng, S. (2024). Entity-Alignment Interaction Model Based on Chinese RoBERTa. Applied Sciences, 14(14), 6162. https://doi.org/10.3390/app14146162