
Enhancing DDBMS Performance through RFO-SVM Optimized Data Fragmentation: A Strategic Approach to Machine Learning Enhanced Systems



Abstract
1. Introduction
1.1. Context
1.2. Challenges
1.3. Motivation
1.4. Problem Definition
1.5. Contributions
- ⮚
- The development of an innovative data fragmentation model that integrates the Red Fox Optimization with Support Vector Machine (RFO-SVM) to optimize horizontal fragmentation in distributed database management systems (DDBMS).
- ⮚
- Enhanced data preprocessing techniques that ensure high data quality and effective handling of missing data.
- ⮚
- Advanced classification methods using optimized SVM parameters to accurately identify data fragments.
- ⮚
- Effective allocation of classified data fragments to various nodes using a Genetic Algorithm (GA), optimizing total allocation cost.
2. Literature Review
2.1. Machine Learning-Based Techniques
2.2. Partitioning-Based Techniques
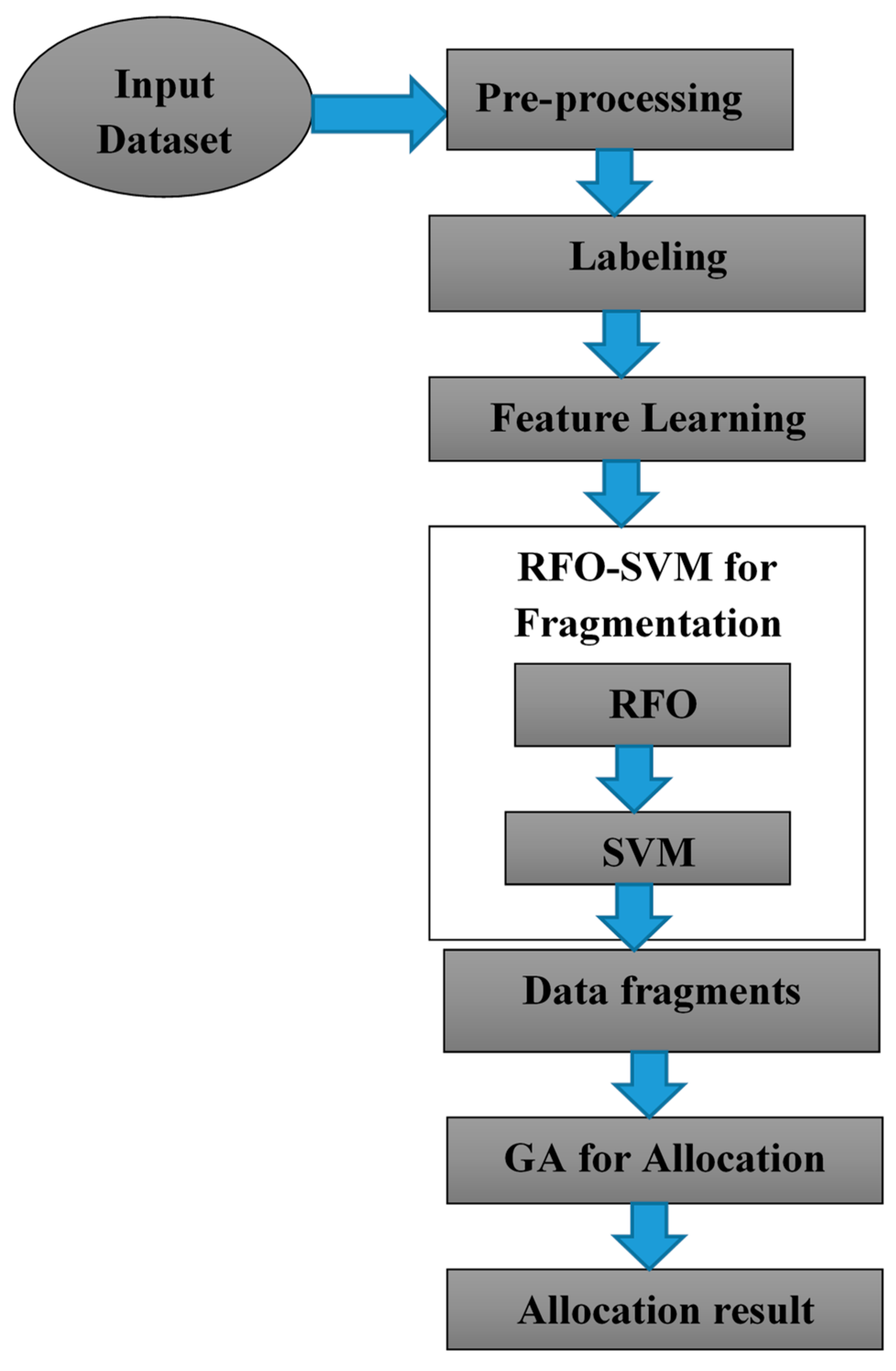
3. Proposed Methodology
3.1. Optimization-Based Machine Learning Algorithms
3.2. Support Vector Machine Algorithm
3.3. Optimization of Support Vector Machine
3.4. RED FOX Optimization
3.4.1. Global Search for Food
3.4.2. Local Search Phase—Navigating within the Local Environment
| Algorithm 1 Red Fox Optimization Algorithm |
| Input: fitness function f(⋅), search space size 〈p, q〉, number of iterations T, maximum population size x, fox observation angle , weather conditions θ Start Generate population consisting of x foxes at random within search space t: = 0 While t ≤ T do Define coefficients for iteration: fox approaching change a, scaling parameter α For each fox in current population do Sort individuals according to the fitness function Select Calculate reallocation of individuals according to Equation (11) If reallocation is better than the previous position then Move the fox else Return the fox to the previous position End If Choose parameter μ value to define noticing the hunting fox If fox is not noticed then Calculate fox observation radius r according to Equation (12) Calculate reallocation according to Equation (13) else Fox stays at his position to disguise End If End For Sort population according to the fitness function Worst foxes leave the herd or get killed by hunters New foxes are replaced in the population using Equation (17) as a nomadic fox ou- side the habitat or reproduced from the alpha couple inside the herd Equation (18) t: = t + 1 End While Return the fittest fox Stop |
3.4.3. Reproduction and Leaving the Herd
3.5. RFO-SVM
3.5.1. RFO-SVM-Based Data Fragmentation
3.5.2. Data Fragmentation
- ⮚
- The relations that are being considered are expected to be defined and recognized.
- ⮚
- All frequently used queries that are consistently observed to access each relation, regardless of their type (retrieval or update), are retained and individually considered. The frequencies of these queries over sites, as well as the retrieval and update frequencies of queries over data in all sites, are meticulously taken in , , and matrices, respectively. Data fragmentation is initiated using these matrices in conjunction with the fragmentation cost model.
- ⮚
- By utilizing Equation (22), in conjunction with the above-mentioned matrices, Attribute Frequency Accumulation (AFAC) is hosted.
- ⮚
- The Communication Cost Matrix is transformed into a Distance Cost Matrix (DCM) using the Genetic Algorithm. Then, Equation (24) is utilized to multiply DCM by AFAC, resulting in the Total Frequencies of Attributes predicate Matrix (TFAM).
- ⮚
- Next, TFAM is used to calculate the overall access costs for each attribute individually, yielding the total pay. All attributes will then be sorted based on their pay.
- ⮚
- Finally, among these attributes, the attribute with the highest pay is selected as the Candidate Attribute (CA), which initiates the successful execution of the fragmentation process, as depicted in Equation (25).
3.5.3. Genetic Algorithm-Based Data Allocation
Mutation Operator
Crossover Operator
Number of Children
Parameters and Configuration
- ⮚
- Population Size: Determined based on preliminary tests to balance computational efficiency and algorithm performance.
- ⮚
- Crossover Rate: Typically set between 60% and 80%, to ensure sufficient crossover while maintaining some genetic integrity of the parents.
- ⮚
- Mutation Rate: A lower mutation rate of 1% to 5% is used to prevent excessive randomness, which can lead to divergence of the population from optimal regions.
- ⮚
- Elitism: Preserving the best individuals from one generation to the next ensures that the gains obtained are not lost, which is critical for maintaining the quality of solutions.
Fitness Evaluation
| Algorithm 2 Fragmentation and Allocation Algorithm |
| Input: Dataset, RFO parameters, SVM parameters and GA parameters Output: Fragments and optimal allocated database. Step 1: Pre-process the input dataset to handle missing data. Step 2: Optimize SVM parameters using the RFO algorithm: Step 2a. Initialize the RFO algorithm parameters. Step 2b. Set the optimization objective as maximizing the accuracy metric. Step 2c. Perform the RFO algorithm to search for optimal parameter values for SVM. Step 3: Obtain the optimized SVM parameters (). Step 4: Apply the RFO-SVM model for data fragmentation: Step 4a. Analyze the features and target label of the dataset. Step 4b. Classify the data based on the class labels using SVM with the optimized parameter values obtained from the RFO algorithm. Step 4c. Calculate the accuracy metric to evaluate the classification performance. Step 5: Perform data allocation using GA: Step 5a. Allocate the classified data fragments obtained from the RFO-SVM model. Step 5b. Initialize the GA parameters for optimization. Step 5c. Define the fitness function as the total allocation cost. Step 5d. Initialize a population of individuals, each representing a possible allocation. Step 5e. Iterate until a termination condition is met (e.g., selecting nodes or sites for fragmented data): Step 5f. Select the allocation with the lowest fitness score. |
4. Implementation Procedure
4.1. Data Description
4.2. Implementation of Proposed Model
4.2.1. Database Fragmentation
Classification and Fragmentation
Role of Attributes
Matrices and Frequency Analysis
Fragmentation Cost Model
4.2.2. Defining the Existing Sites or Nodes
- ⮚
- SVM model is trained by performing fitness evaluation on each subset and evaluating its accuracy on a validation set.
- ⮚
- The algorithm continues for a specified number of iterations, gradually improving the fitness of the population and finding the best subset of features.
- ⮚
- Once the algorithm completes, the dataset is fragmented into subsets based on the selected features from the best solution found by the RFO-SVM algorithm.
- ⮚
- Each fragment represents a smaller portion of the original dataset, possibly containing a subset of features and corresponding target values.
- ⮚
- Accuracy is used as a metric for efficient optimization of SVM parameters.
4.2.3. Fragments Data Allocation Using GA
- ⮚
- The GA evaluates the fitness of each solution by calculating its total allocation cost based on the given cost function.
- ⮚
- Solutions with lower total allocation costs are considered fit and have a higher probability of being selected for reproduction.
- ⮚
- Once the GA completes, the best solution represents the allocation of fragmented data across the nodes that minimizes the total allocation cost.
- ⮚
- The allocated fragments are evaluated based on various metrics.
- ⮚
- The GA algorithm is implemented by defining functions for initializing the population and updating the population. It is then applied to further optimize the data fragmentation, considering the total allocation cost as the fitness function.
- ⮚
- The GA algorithm efficiently and effectively allocates fragmented data by finding the best sites for data allocation, representing the optimized data allocation.
4.3. Validation
4.3.1. Training
4.3.2. Optimization of SVM Parameters
4.3.3. Successful Data Fragmentation
4.3.4. Optimized Site or Node for Data Allocation
4.3.5. Processing Time
5. Experimental Results
Performance Results
6. Conclusions and Future Work
- ⮚
- Scalability and Performance Optimization: Develop algorithms that can efficiently handle a larger number of nodes, datasets, and workload demands while maintaining high accuracy and minimizing resource utilization.
- ⮚
- Combination of Machine Learning with Rule-Based or Heuristic Approaches: Investigate the integration of machine learning techniques with rule-based or heuristic approaches to create more effective and efficient data fragmentation allocation algorithms.
- ⮚
- Integration with Emerging Technologies: Explore the integration of data fragmentation allocation algorithms with technologies such as edge computing, blockchain, or federated learning. These technologies can introduce new challenges and opportunities in distributed data management, and studying their impact on data fragmentation allocation can provide valuable insights.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Baalbaki, H.; Hazimeh, H.; Harb, H.; Angarita, R. KEMA: Knowledge-graph embedding using modular arithmetic. In Proceedings of the 34th International Conference on Software Engineering and Knowledge Engineering, Pittsburgh, PA, USA, 1–10 July 2022. [Google Scholar]
- Baalbaki, H.; Hazimeh, H.; Harb, H.; Angarita, R. TransModE: Translation-al Knowledge Graph Embedding Using Modular Arithmetic. Procedia Comput. Sci. 2022, 207, 1154–1163. [Google Scholar] [CrossRef]
- Saad, G.; Harb, H.; Abouaiss, A.; Idoumgha, L.; Charara, N. An efficient hadoop-based framework for data storage and fault recovering in large-scale multi-media sensor networks. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; IEEE: New York, NY, USA, 2020; pp. 316–321. [Google Scholar]
- Połap, D.; Woźniak, M. Red fox optimization algorithm. Expert Syst. Appl. 2021, 166, 114107. [Google Scholar] [CrossRef]
- Dahal, A.; Joshi, S.R. A clustering based vertical fragmentation and allocation of a distributed database. In Proceedings of the 2019 Artificial Intelligence for Transforming Business and Society (AITB), Kathmandu, Nepal, 5 November 2019; IEEE: Pistacaway, NJ, USA, 2019; Volume 1, pp. 1–5. [Google Scholar]
- Ramachandran, R.; Ravichandran, G.; Raveendran, A. Vertical fragmentation of high-dimensional data using feature selection. In Proceedings of the Inventive Computation and Information Technologies: Proceedings of ICICIT 2020, Coimbatore, India, 24–25 September 2020; Springer: Singapore, 2021; pp. 935–944. [Google Scholar]
- Amer, A.A. On K-means clustering-based approach for DDBSs design. J. Big Data 2020, 7, 31. [Google Scholar] [CrossRef]
- Abdel Raouf, A.E.; Badr, N.L.; Tolba, M.F. Dynamic data reallocation and replication over a cloud environment. Concurr. Comput. Pract. Exp. 2018, 30, e4416. [Google Scholar] [CrossRef]
- Amer, A.A.; Mohamed, M.H.; Al_Asri, K. ASGOP: An aggregated similarity-based greedy-oriented approach for relational DDBSs design. Heliyon 2020, 6, e03172. [Google Scholar] [CrossRef] [PubMed]
- Dokeroglu, T.; Bayir, M.A.; Cosar, A. Robust heuristic algorithms for exploiting the common tasks of relational cloud database queries. Appl. Soft Comput. 2015, 30, 72–82. [Google Scholar] [CrossRef]
- Wiese, L. Clustering-based fragmentation and data replication for flexible query answering in distributed databases. J. Cloud Comput. 2014, 3, 1–15. [Google Scholar] [CrossRef]
- Luong, V.N.; Le, V.S.; Doan, V.B. Fragmentation in Distributed Database Design Based on KR Rough Clustering Technique. In Proceedings of the Context-Aware Systems and Applications, and Nature of Computation and Communication, Proceedings of 6th International Conference (ICCASA 2017) and 3rd International Conference (ICTCC 2017), Tam Ky City, Vietnam, 23–24 November 2017; Springer: Cham, Switzerland, 2017; pp. 166–172. [Google Scholar]
- Benmelouka, A.; Ziani, B.; Quinten, Y. Vertical fragmentation and allocation in distributed databases using k-mean algorithm. Int. J. Adv. Stud. Comput. Sci. Eng. 2023, 12, 45–53. [Google Scholar]
- Abdalla, H.I.; Amer, A.A.; Mathkour, H. A Novel Vertical Fragmentation, Replication and Allocation Model in DDBSs. J. Univers. Comput. Sci. 2014, 20, 1469–1487. [Google Scholar]
- Tarun, S.; Batth, R.S.; Kaur, S. A novel fragmentation scheme for textual data using similarity-based threshold segmentation method in distributed network environment. Int. J. Comput. Netw. Appl. 2020, 7, 231. [Google Scholar] [CrossRef]
- Abdel Raouf, A.E.; Badr, N.L.; Tolba, M.F. Distributed database system (DSS) design over a cloud environment. In Multimedia Forensics and Security: Foundations, Innovations, and Applications; Springer: New York, NY, USA, 2017; pp. 97–116. [Google Scholar]
- Wedashwara, W.; Mabu, S.; Obayashi, M.; Kuremoto, T. Combination of genetic network programming and knapsack problem to support record clustering on distributed databases. Expert Syst. Appl. 2016, 46, 15–23. [Google Scholar] [CrossRef]
- Benkrid, S.; Bellatreche, L.; Mestoui, Y.; Ordonez, C. PROADAPT: Proactive framework for adaptive partitioning for big data warehouses. Data Knowl. Eng. 2022, 142, 102102. [Google Scholar] [CrossRef]
- Mai, N.T. Heuristic Algorithm for Fragmentation and Alloca-Tion in Distributed Object Oriented Database. J. Comput. Sci. Cybern. 2016, 32, 47–60. [Google Scholar] [CrossRef]
- Mahi, M.; Baykan, O.K.; Kodaz, H. A new approach based on greedy minimizing algorithm for solving data allocation problem. Soft Comput. 2023, 27, 13911–13930. [Google Scholar] [CrossRef]
- Zhang, D.; Deng, Y.; Zhou, Y.; Li, J.; Zhu, W.; Min, G. MGRM: A Multi-Segment Greedy Rewriting Method to Alleviate Data Fragmentation in Deduplication-Based Cloud Backup Systems. IEEE Trans. Cloud Comput. 2023, 11, 2503–2516. [Google Scholar] [CrossRef]
- Nimbalkar, T.S.; Bogiri, N. A novel integrated fragmentation clustering allocation approach for promote web telemedicine database system. Int. J. Adv. Electron. Comput. Sci. 2016, 2, 1–11. [Google Scholar]
- Peng, P.; Zou, L.; Chen, L.; Zhao, D. Adaptive distributed RDF graph fragmentation and allocation based on query workload. IEEE Trans. Knowl. Data Eng. 2018, 31, 670–685. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, J.; Li, F. MGRM: Multi-Granularity Resource Management for cloud data centers. Future Gener. Comput. Syst. 2022, 126, 223–234. [Google Scholar] [CrossRef]
- Ge, Y.; Xu, Y.; Chen, L. DSGA: Distributed Smart Grid Allocation using machine learning. IEEE Trans. Smart Grid 2022, 13, 1456–1468. [Google Scholar]
- Saverio, D.V. Air Quality Dataset. Available online: https://www.kaggle.com/datasets/fedesoriano/air-quality-data-set (accessed on 10 February 2022).
- Yasser, M. Wine Quality Dataset. Available online: https://www.kaggle.com/datasets/yasserh/wine-quality-dataset (accessed on 27 March 2022).
- Castro, J.; Smith, R.; Johnson, L. FRAGMENT: Fragmentation-based allocation in distributed systems. J. Netw. Comput. Appl. 2020, 123, 102–114. [Google Scholar]
- Ge, Y.; Li, Q.; Wang, X. DMA: Dynamic Memory Allocation for cloud computing environments. IEEE Trans. Cloud Comput. 2020, 8, 345–357. [Google Scholar]
- Ge, Y.; Zhang, P.; Li, Q. KT-DDE: Knowledge Transfer and Dynamic Decision Engine for network optimization. Comput. Netw. 2021, 179, 107–118. [Google Scholar] [CrossRef]
- Lechowicz, P.; Kowalski, M.; Nowak, A. SS-FONs: Secure and Scalable Fiber Optical Networks for data centers. Opt. Fiber Technol. 2021, 57, 102–115. [Google Scholar]
- Mehta, S.; Patel, R.; Sharma, V. DBE-GAM: Dynamic Bandwidth Estimation using Genetic Algorithms and Machine learning. IEEE Access 2022, 10, 4506–4518. [Google Scholar]
- Benkrid, A.; Mohamed, S.; Ali, M. PROADAPT: Adaptive Protocols for efficient resource management in IoT networks. Sensors 2022, 22, 1445. [Google Scholar] [CrossRef]
- Rodríguez, H.; Garcia, M.; Lopez, J. FTree: A Fault-Tolerant tree-based net-work routing protocol. Comput. Commun. 2022, 192, 224–234. [Google Scholar] [CrossRef]
- Benmelouka, M.; Alami, H.; Farid, M. VFAR: Virtualized Fiber Access Net-works for efficient bandwidth management. Opt. Switch. Netw. 2023, 44, 100–111. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Situation | Situation Description | Sample | Training (80%) | Testing (20%) |
|---|---|---|---|---|
| Class 1 | Normal situation | 595 | 476 | 119 |
| Class 2 | Preparing meals | 515 | 412 | 103 |
| Class 3 | Presence of smoke | 195 | 156 | 39 |
| Class 4 | Cleaning | 540 | 432 | 108 |
| Wine Quality | Samples | Training | Testing |
|---|---|---|---|
| Class 3 | 20 | 15 | 5 |
| Class 4 | 163 | 138 | 25 |
| Class 5 | 1457 | 1166 | 291 |
| Class 6 | 2198 | 1766 | 432 |
| Class 7 | 880 | 688 | 192 |
| Class 8 | 175 | 140 | 35 |
| S.NO. | Parameter | Value |
|---|---|---|
| 1. | Maximum iterations | 50 |
| 2. | C range | 0.1–10 |
| 3. | ɣ range | 0.001–1.0 |
| 4. | Kernel | Linear, polynomial, sigmoid rbf |
| 5. | No. of fragments for air quality dataset | 4 |
| 6. | No. of fragments for wine quality dataset | 6 |
| Air Quality Data | |||
|---|---|---|---|
| Fragments | Training | Testing | Final Allocation |
| 1 | 459 | 136 | 0 |
| 2 | 414 | 101 | 1 |
| 3 | 163 | 32 | 2 |
| 4 | 440 | 100 | 3 |
| Wine Quality Data | |||
| Fragments | Training | Testing | Final Allocation |
| 1 | 14 | 6 | 0 |
| 2 | 136 | 27 | 1 |
| 3 | 1171 | 286 | 2 |
| 4 | 1744 | 454 | 3 |
| 5 | 709 | 171 | 4 |
| 6 | 140 | 35 | 5 |
| S.NO. | Evaluation for 50 Iterations | ||
|---|---|---|---|
| Metrics | Air Quality | Wine Quality | |
| 1. | Accuracy (%) | 96.21 | 80.59 |
| 2. | Precision (%) | 96.23 | 84.69 |
| 3. | Recall (%) | 95.65 | 90.69 |
| 4. | F1 Score (%) | 95.93 | 87.59 |
| 5. | Allocation cost per fragment (Mbps) | 801.18 | 2037.4 |
| 6. | Total cost of allocation (Mbps) | 3204.72 | 12,224.4 |
| 7. | Transmission cost per fragment (Mbps) | 1771.2 | 5737.6 |
| 8. | Total transmission cost (Mbps) | 5313.6 | 28,688.0 |
| 9. | Memory utilization per fragment (Bytes) | 17,712 | 57,376 |
| 10. | Total memory utilization (Bytes) | 70,848 | 344,432 |
| 11. | Processing time (Seconds) | 28.36 | 245.53 |
| Methods | Total Allocation Cost (Mbps) | Accuracy (%) | Processing Time (s) | Total Transmission Cost (Mbps) |
|---|---|---|---|---|
| FRAGMENT [28] | 5542.6 | 80.6 | 79.3 | 10,256 |
| DMA [29] | 7256.4 | 87.3 | 82.4 | 11,897 |
| KT-DDE [30] | 6858.2 | 85.4 | 88.2 | 6258 |
| SS-FONs [31] | 7772.5 | 79.6 | 100.5 | 7546 |
| DBE-GAM [32] | 5656.2 | 77.4 | 111.2 | 13,687 |
| PROADAPT [33] | 6112.4 | 75.9 | 98.3 | 8563.9 |
| FTree [34] | 5999.3 | 76.0 | 99 | 10,222.6 |
| MGRM [24] | 4998.8 | 82.3 | 79.8 | 9894 |
| DSGA [25] | 4454.5 | 85.3 | 65.4 | 7791.8 |
| VFAR [35] | 7122.6 | 88.2 | 92.5 | 11,258.2 |
| Proposed RFO-SVM | 3204.72 | 96.21 | 28.36 | 5313.6 |
| Data Fragmentation and Allocation Methods | Total Allocation Cost (Mbps) | Accuracy (%) | Processing Time (s) | Total Transmission Cost (Mbps) |
|---|---|---|---|---|
| FRAGMENT [28] | 25,589.5 | 65.9 | 582 | 58,366 |
| DMA [29] | 20,689 | 72.4 | 556 | 49,732 |
| KT-DDE [30] | 19,872 | 70.6 | 645 | 48,679 |
| SS-FONs [31] | 22,645 | 71.4 | 722 | 39,475 |
| DBE-GAM [32] | 18,476 | 75.6 | 765 | 38,666 |
| PROADAPT [33] | 19,005 | 72 | 693 | 43,584 |
| FTree [34] | 18,679.9 | 69.6 | 579 | 48,002 |
| MGRM [24] | 19,834 | 68 | 509 | 36,761 |
| DSGA [25] | 17,264 | 71 | 456 | 53,576 |
| VFAR [35] | 20,579 | 71.3 | 537 | 59,254 |
| Proposed RFO-SVM | 12,224.4 | 80.59 | 245.53 | 28,688.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Danach, K.; Khalaf, A.H.; Rammal, A.; Harb, H. Enhancing DDBMS Performance through RFO-SVM Optimized Data Fragmentation: A Strategic Approach to Machine Learning Enhanced Systems. Appl. Sci. 2024, 14, 6093. https://doi.org/10.3390/app14146093
Danach K, Khalaf AH, Rammal A, Harb H. Enhancing DDBMS Performance through RFO-SVM Optimized Data Fragmentation: A Strategic Approach to Machine Learning Enhanced Systems. Applied Sciences. 2024; 14(14):6093. https://doi.org/10.3390/app14146093
Chicago/Turabian StyleDanach, Kassem, Abdullah Hussein Khalaf, Abbas Rammal, and Hassan Harb. 2024. "Enhancing DDBMS Performance through RFO-SVM Optimized Data Fragmentation: A Strategic Approach to Machine Learning Enhanced Systems" Applied Sciences 14, no. 14: 6093. https://doi.org/10.3390/app14146093
APA StyleDanach, K., Khalaf, A. H., Rammal, A., & Harb, H. (2024). Enhancing DDBMS Performance through RFO-SVM Optimized Data Fragmentation: A Strategic Approach to Machine Learning Enhanced Systems. Applied Sciences, 14(14), 6093. https://doi.org/10.3390/app14146093