
Metrics for Evaluating Synthetic Time-Series Data of Battery


Abstract
1. Introduction
- The proposed method can satisfy and compensate for the quality of insufficient datasets in deep learning-based battery estimation and fault diagnosis.
- By evaluating the quality of the data, high-quality data can be obtained for battery estimation and fault diagnosis.
- The proposed method can efficiently evaluate battery data both visually and quantitatively, regardless of the learning environment.
- The proposed method can also evaluate the synthetic battery data generated using data generation techniques other than TimeGAN for similarity.
- The proposed method can be used for data other than battery data to evaluate the similarity of data.
2. TimeGAN
3. Proposed Evaluation Method
3.1. t-SNE
3.2. Rate of Change in Correlation Coefficient of Linear Regression
3.3. Dunn Index
3.4. Silhouette Coefficient
4. Results and Analysis
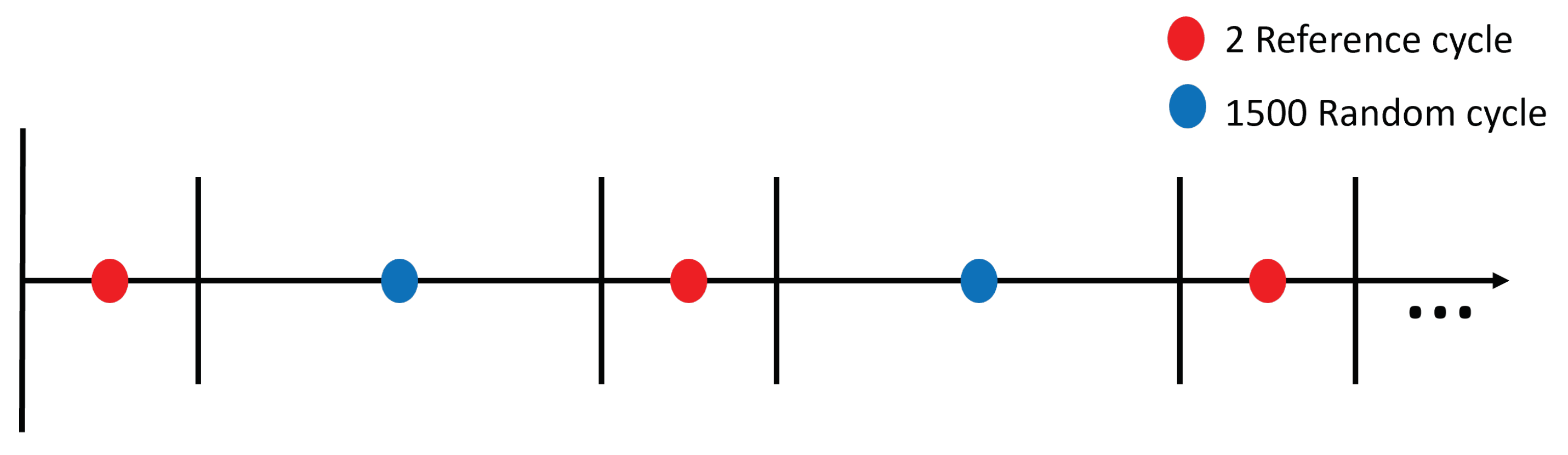
4.1. Test Dataset
4.2. Application of the Proposed Evaluation Method
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yu, W.; Liu, Y.; Dillon, T.; Rahayu, W. Edge computing-assisted IoT framework with an autoencoder for fault detection in manufacturing predictive maintenance. IEEE Trans. Ind. Inform. 2022, 19, 5701–5710. [Google Scholar] [CrossRef]
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Glaeser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1341–1360. [Google Scholar] [CrossRef]
- Li, P.; Zhang, Z.; Xiong, Q.; Ding, B.; Hou, J.; Luo, D.; Rong, Y.; Li, S. State-of-health estimation and remaining useful life prediction for the lithium-ion battery based on a variant long short term memory neural network. J. Power Sources 2020, 459, 228069. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Mogren, O. C-RNN-GAN: Continuous recurrent neural networks with adversarial training. arXiv 2016, arXiv:1611.09904. [Google Scholar]
- Esteban, C.; Hyland, S.L.; Rätsch, G. Real-valued (medical) time series generation with recurrent conditional gans. arXiv 2017, arXiv:1706.02633. [Google Scholar]
- Yoon, J.; Jarrett, D.; Van der Schaar, M. Time-series generative adversarial networks. Adv. Neural Inf. Process. Syst. 2019, 32, 5508–5518. [Google Scholar]
- Bole, B.; Kulkarni, C.S.; Daigle, M. Adaptation of an electrochemistry-based li-ion battery model to account for deterioration observed under randomized use. In Proceedings of the Annual Conference of the PHM Society, Spokane, WA, USA, 22–25 June 2014; Volume 6. [Google Scholar]
- Li, J.; Liu, Y.; Li, Q. Generative adversarial network and transfer-learning-based fault detection for rotating machinery with imbalanced data condition. Meas. Sci. Technol. 2022, 33, 045103. [Google Scholar] [CrossRef]
- Seyfi, A.; Rajotte, J.F.; Ng, R. Generating multivariate time series with COmmon Source CoordInated GAN (COSCI-GAN). Adv. Neural Inf. Process. Syst. 2022, 35, 32777–32788. [Google Scholar]
- Jeon, J.; Kim, J.; Song, H.; Cho, S.; Park, N. GT-GAN: General Purpose Time Series Synthesis with Generative Adversarial Networks. Adv. Neural Inf. Process. Syst. 2022, 35, 36999–37010. [Google Scholar]
- Lee, M.; Seok, J. Score-guided generative adversarial networks. Axioms 2022, 11, 701. [Google Scholar] [CrossRef]
- Guan, S.; Loew, M.H. Measures to evaluate generative adversarial networks based on direct analysis of generated images. arXiv 2020, arXiv:2002.12345. [Google Scholar] [CrossRef]
- Patel, P.; Sivaiah, B.; Patel, R. Approaches for finding optimal number of clusters using k-means and agglomerative hierarchical clustering techniques. In Proceedings of the 2022 International Conference on Intelligent Controller and Computing for Smart Power (ICICCSP), Hyderabad, India, 21–23 July 2022; pp. 1–6. [Google Scholar]
- Hartama, D.; Anjelita, M. Analysis of Silhouette Coefficient Evaluation with Euclidean Distance in the Clustering Method (Case Study: Number of Public Schools in Indonesia). J. Mantik 2022, 6, 3667–3677. [Google Scholar]
- van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Patel, S.K.; Surve, J.; Parmar, J.; Natesan, A.; Katkar, V. Graphene-based metasurface refractive index biosensor for hemoglobin detection: Machine learning assisted optimization. IEEE Trans. Nanobiosci. 2022, 22, 430–437. [Google Scholar] [CrossRef] [PubMed]
- Saini, N.; Saha, S.; Bhattacharyya, P. Automatic scientific document clustering using self-organized multi-objective differential evolution. Cogn. Comput. 2019, 11, 271–293. [Google Scholar] [CrossRef]
- Misuraca, M.; Spano, M.; Balbi, S. BMS: An improved Dunn index for Document Clustering validation. Commun. Stat.-Theory Methods 2019, 48, 5036–5049. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic/Parameter | Value |
|---|---|
| Battery properties | 18,650 LIBs |
| Chemistry | 18,650 lithium cobalt oxide vs. graphite |
| Nominal capacity | 2.10 Ah |
| Capacity range | 0.80–2.10 Ah |
| Voltage range | 3.2–4.2 V |
| Data | Evaluation Method | Iteration | |||
|---|---|---|---|---|---|
| 100 | 1000 | 10,000 | |||
| RW9 | Existing | Training loss | 0.3900 | 0.1800 | 0.1200 |
| Proposed | Rate of change in correlation coefficient | Not used | 0.0813 | 0.0027 | |
| Dunn index | 0.3127 | 0.3030 | 0.2540 | ||
| Silhouette coefficient | 0.1053 | 0.0308 | 0.0073 | ||
| RW 10 | Existing | Training loss | 0.2850 | 0.2550 | 0.1450 |
| Proposed | Rate of change in correlation coefficient | Not used | 0.0325 | 0.0291 | |
| Dunn index | 0.2718 | 0.3533 | 0.2719 | ||
| Silhouette coefficient | 0.0381 | 0.0889 | 0.0089 | ||
| RW 11 | Existing | Training loss | 0.4700 | 0.2200 | 0.1050 |
| Proposed | Rate of change in correlation coefficient | Not used | 0.0382 | 0.0320 | |
| Dunn index | 0.3223 | 0.2722 | 0.2639 | ||
| Silhouette coefficient | 0.2172 | 0.0199 | 0.0084 | ||
| RW 12 | Existing | Training loss | 0.2850 | 0.3200 | 0.1540 |
| Proposed | Rate of change in correlation coefficient | Not used | 0.1444 | 0.0414 | |
| Dunn index | 0.6826 | 0.2900 | 0.2938 | ||
| Silhouette coefficient | 0.0267 | 0.0295 | 0.0156 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seol, S.; Yoon, J.; Lee, J.; Kim, B. Metrics for Evaluating Synthetic Time-Series Data of Battery. Appl. Sci. 2024, 14, 6088. https://doi.org/10.3390/app14146088
Seol S, Yoon J, Lee J, Kim B. Metrics for Evaluating Synthetic Time-Series Data of Battery. Applied Sciences. 2024; 14(14):6088. https://doi.org/10.3390/app14146088
Chicago/Turabian StyleSeol, Sujin, Jaewoo Yoon, Jungeun Lee, and Byeongwoo Kim. 2024. "Metrics for Evaluating Synthetic Time-Series Data of Battery" Applied Sciences 14, no. 14: 6088. https://doi.org/10.3390/app14146088
APA StyleSeol, S., Yoon, J., Lee, J., & Kim, B. (2024). Metrics for Evaluating Synthetic Time-Series Data of Battery. Applied Sciences, 14(14), 6088. https://doi.org/10.3390/app14146088